Stel je voor: het is 2025, je zit lekker aan je ochtendkoffie en je bent benieuwd of Walmart eindelijk de prijs heeft laten zakken van die 65-inch tv waar je al een tijd op aast. Of misschien heb je een eigen webshop en wil je altijd up-to-date zijn over de prijzen, voorraad en reviews bij Walmart. Elke dag handmatig alle producten op Walmart checken? Dat is echt monnikenwerk (en niemand wordt daar vrolijk van). Gelukkig kun je met een beetje Python en wat webscraping-skills dit saaie klusje automatiseren en een schat aan data binnenhalen.
Na jaren ervaring met het bouwen van automatiserings- en AI-tools voor bedrijven weet ik: walmart scrapen is zo’n ‘geheime hack’ die urenlang handmatig zoeken terugbrengt tot een paar regels code. In deze gids neem ik je stap voor stap mee in de wereld van walmart scraping, waarom het in 2025 zo waardevol is voor bedrijven, en hoe je zelf een krachtige walmart-scraper bouwt in Python – inclusief echte code en praktische tips. Pak je koffie (of je favoriete snack voor tijdens het debuggen) en laten we aan de slag gaan.
Wat is Walmart Scraping? De Basis in 2025
Heel simpel: walmart scraping betekent automatisch product-, prijs- en reviewdata van Walmart’s website halen met software – meestal een script dat zich voordoet als een supersnelle browser. In plaats van handmatig kopiëren en plakken (waar niemand blij van wordt), schrijf je een Python-script dat Walmart-pagina’s ophaalt, de data eruit filtert en opslaat voor analyse.
Waarom Python? Python is dé alleskunner voor webscraping: makkelijk te lezen, krachtige libraries (zoals Requests, BeautifulSoup en pandas) en een grote community die kennis en code deelt. Of je nu solo werkt of in een team, met Python is walmart scrapen toegankelijk – ook als je geen hardcore programmeur bent.
Let op het verschil tussen scrapen voor eigen gebruik (bijvoorbeeld prijzen volgen voor je eigen aankopen) en zakelijk gebruik (zoals het monitoren van duizenden producten voor concurrentieanalyse). Voor bedrijven wordt het snel complexer – zeker omdat Walmart in 2025 nog steeds geen publieke product-API aanbiedt ().
Waarom Walmart Scrapen? Zakelijke Meerwaarde
Walmart is allang niet meer alleen Amerika’s grootste fysieke retailer – het is nu ook een digitale reus, met online verkopen van meer dan en e-commerce goed voor bijna 18% van de totale omzet (). Dat betekent: bergen aan producten, prijzen, reviews en trends – ideaal om te analyseren.
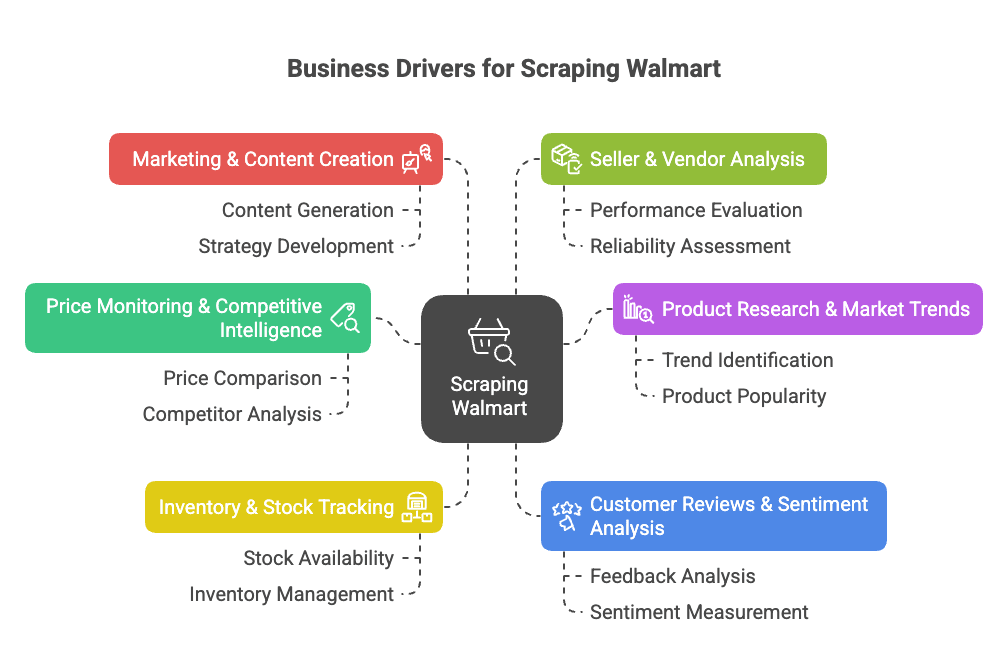
Waarom zou je Walmart scrapen? Dit zijn de belangrijkste zakelijke redenen:
- Prijsmonitoring & Concurrentieanalyse: Direct inzicht in Walmart’s prijzen, acties en assortiment om je eigen prijs- en productstrategie te verbeteren ().
- Productonderzoek & Markttrends: Analyseer het aanbod, specificaties en trends om kansen of gaten in de markt te ontdekken ().
- Voorraad- & Beschikbaarheidstracking: Houd bij wat op voorraad is om je supply chain te optimaliseren of in te spelen op tekorten bij concurrenten ().
- Klantreviews & Sentimentanalyse: Verzamel en analyseer beoordelingen om producten te verbeteren of pijnpunten te signaleren ().
- Marketing & Contentcreatie: Bekijk welke producten als ‘Bestseller’ worden aangeduid, hoe ze gepresenteerd worden en welke content conversie oplevert ().
- Verkoper- & Leveranciersanalyse: Identificeer topverkopers of ongeautoriseerde listings ().
Hieronder een overzichtstabel van de toepassingen, wie er baat bij heeft en wat het oplevert:
| Toepassing | Voor wie | Voordelen & ROI |
|---|---|---|
| Prijsmonitoring | Prijs- & Salesteams | Direct inzicht in concurrentieprijzen, dynamische prijsstelling, marges beschermen |
| Assortiment- & Catalogusanalyse | Productmanagement, Inkoop | Ontdek hiaten, lanceer nieuwe producten, verbeter catalogus |
| Voorraadtracking | Operations & Supply Chain | Betere vraagvoorspelling, voorkom out-of-stock, optimaliseer distributie |
| Klantreviews & Sentiment | Productontwikkeling, Klantbeleving | Datagedreven productverbetering, hogere klanttevredenheid |
| Markttrends & Analyse | Strategie & Marktonderzoek | Signaleer trends, onderbouw strategische keuzes, betrek nieuwe segmenten vroeg |
| Content- & Prijsstrategie | Marketing & E-commerce | Optimaliseer prijzen, leer van best presterende content |
| Verkoperbewaking | Sales & Partnerships | Vind partners, bescherm merk, monitor ongeautoriseerde verkopers |
Kortom: walmart scraping bespaart tijd, verhoogt je omzet en geeft je een voorsprong met data. In plaats van elke ochtend 50 pagina’s handmatig te checken, haalt je script in een paar minuten duizenden producten binnen ().
Walmart scrapen is een echte gamechanger voor e-commerce, sales en marktonderzoek. Met de juiste tools automatiseer je het verzamelen van data en kun je je focussen op inzichten, niet op handwerk.
Walmart Scrapen met Python: Wat Heb Je Nodig?
Voor je begint, moet je je Python-omgeving klaarzetten. Dit heb je nodig:
- Python 3.9 of hoger (liefst 3.11 of 3.12 in 2025)
- Requests: Om webpagina’s op te halen
- BeautifulSoup (bs4): Voor het parsen van HTML
- pandas: Voor het structureren en exporteren van data
- json: Voor het verwerken van JSON-data (standaard in Python)
- Een browser met Developer Tools: Om de structuur van Walmart-pagina’s te inspecteren (F12 is je beste vriend)
- pip: Om Python-pakketten te installeren
Installeren doe je zo:
1pip install requests beautifulsoup4 pandasWil je het netjes houden? Maak dan een virtuele omgeving aan:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Op Mac/Linux
3# of
4walmart-scraper\\Scripts\\activate.bat # Op WindowsTest je setup met:
1import requests, bs4, pandas
2print("Libraries loaded successfully!")Zie je deze melding? Dan ben je klaar om te starten.
Stap 1: Je Python Walmart-scraper Opzetten
Zo begin je gestructureerd:
- Maak een projectmap aan (bijv.
walmart_scraper/). - Open je code-editor (VSCode, PyCharm of zelfs Notepad++ – alles werkt).
- Start een nieuw script (bijv.
walmart_scraper.py).
Een basis-template om te starten:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import jsonNu ben je klaar voor het echte werk: Walmart-productpagina’s ophalen.
Stap 2: Walmart-productpagina’s Ophalen met Python
Om Walmart te scrapen, heb je de HTML van een productpagina nodig. Maar let op: Walmart beschermt zich actief tegen bots. Gebruik je simpelweg requests.get(url), dan krijg je waarschijnlijk snel een ‘Robot of mens?’-melding.
De truc? Doe je voor als een echte browser. Stel headers in zoals User-Agent en Accept-Language zodat je lijkt op Chrome of Firefox.
Zo doe je dat:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.textTip: Gebruik een requests.Session() om cookies te bewaren en nog meer op een echte gebruiker te lijken:
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # Homepage bezoeken voor cookies
4response = session.get(product_url)Check altijd response.status_code (moet 200 zijn). Krijg je een vreemde pagina of CAPTCHA? Doe het rustiger aan, probeer een ander IP of neem een pauze. Walmart’s anti-botmaatregelen zijn niet mals ().
Omgaan met Walmart’s Anti-Botmaatregelen
Walmart gebruikt onder andere Akamai en PerimeterX om bots te detecteren via je IP, headers, cookies en zelfs je TLS-fingerprint. Zo blijf je onder de radar:
- Gebruik altijd realistische headers (zie hierboven).
- Vertraag je verzoeken – wacht 3–6 seconden tussen pagina’s.
- Varieer je wachttijden zodat je niet als een robot overkomt.
- Gebruik proxies als je op grote schaal scrapt (later meer hierover).
- Zie je een CAPTCHA? Stop dan even – probeer niet door te rammen.
Wil je helemaal onzichtbaar zijn, dan kun je libraries als curl_cffi gebruiken om je requests nog meer op Chrome te laten lijken (). Maar voor de meeste toepassingen kom je met headers en geduld al een heel eind.
Stap 3: Walmart-productdata Extracten met BeautifulSoup
Nu het leuke deel: de data eruit halen die je nodig hebt. Walmart’s site draait op Next.js, dus de meeste productinformatie zit in een <script id="__NEXT_DATA__">-tag als een grote JSON-blob.
Zo pak je die eruit:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)Nu heb je een Python-dictionary met alle productinformatie. Voor een standaard productpagina vind je de details onder:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]Daarna kun je de gewenste velden pakken:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") of product_data.get("description")Waarom de JSON gebruiken? Omdat deze gestructureerd is, minder snel breekt bij HTML-wijzigingen en vaak meer details bevat dan zichtbaar op de pagina ().
Werken met Dynamische Content en JSON-data
Soms worden zaken als reviews of voorraadstatus dynamisch geladen via JavaScript of aparte API-calls. Goed nieuws: de initiële JSON bevat vaak al een snapshot van wat je zoekt. Zo niet, check dan de Network-tab in je browser om de API-endpoints te vinden en die na te bootsen.
Voor de meeste productdata is de __NEXT_DATA__ JSON je beste vriend.
Stap 4: Walmart-data Opslaan en Exporteren
Als je de data hebt, wil je die gestructureerd opslaan – CSV, Excel of JSON zijn prima opties. Met pandas doe je dat zo:
1import pandas as pd
2product_record = {
3 "Productnaam": name,
4 "Prijs (USD)": current_price,
5 "Beoordeling": average_rating,
6 "Aantal reviews": review_count,
7 "Beschrijving": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)Scrape je meerdere producten? Voeg elk record toe aan een lijst en maak aan het eind de DataFrame.
Excel nodig? Gebruik df.to_excel("walmart_products.xlsx", index=False) (zorg dat openpyxl geïnstalleerd is). Voor JSON: df.to_json("walmart_products.json", orient="records", indent=2).
Tip: Controleer altijd steekproefsgewijs je geëxporteerde data. Het is zonde als je denkt 1.000 prijzen te hebben, maar alles ‘None’ blijkt omdat Walmart een veldnaam heeft aangepast.
Stap 5: Je Walmart-scraper Opschalen
Klaar voor het echte werk? Zo scrape je meerdere productpagina’s:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...meer URLs
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...parsen en extracten zoals eerder...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # Wees beleefd!Heb je geen lijst met URLs? Begin dan bij een zoekresultaatpagina, haal de productlinks op en scrape ze één voor één ().
Let op: Snel honderden of duizenden pagina’s scrapen leidt vrijwel zeker tot IP-blokkades. Dan zijn proxies nodig.
Proxies en Scraper APIs voor Walmart
Proxies laten je IP-adres wisselen, zodat Walmart je minder snel blokkeert. Je kunt residentiële proxies kopen (die lijken op echte gebruikers) of een proxy pool gebruiken. Zo gebruik je een proxy met requests:
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)Voor grootschalig scrapen kun je een scraper API overwegen – deze diensten regelen proxies, CAPTCHAs en zelfs JavaScript-rendering voor je. Jij stuurt een Walmart-URL, zij sturen de data terug (soms al als JSON).
Hier een vergelijking:
| Aanpak | Voordelen | Nadelen | Ideaal voor |
|---|---|---|---|
| Zelf Python + Proxies | Volledige controle, voordelig bij kleine volumes | Onderhoud, proxykosten, kans op blokkades | Developers, maatwerk |
| Externe Scraper API | Makkelijk, regelt anti-bot, goed schaalbaar | Duurder bij grote volumes, minder flexibel, afhankelijk van derde partij | Zakelijk gebruik, grote volumes, snel resultaat |
Geen developer of wil je snel data? Tools zoals de regelen alles in een paar klikken – geen code, geen proxies, geen gedoe. (Daarover zo meer.)
Veelvoorkomende Uitdagingen bij Walmart-scraping (en Oplossingen)
Walmart scrapen is niet altijd een feestje. Dit zijn de grootste struikelblokken – en hoe je ze tackelt:
- Strenge anti-botmaatregelen: Walmart checkt IP, headers, cookies, TLS-fingerprint, JavaScript. Oplossing: realistische headers, sessions, vertragingen en proxies gebruiken ().
- CAPTCHAs: Krijg je een CAPTCHA? Pauzeer en probeer later opnieuw. Blijft het terugkomen, overweeg dan CAPTCHA-oplossers (maar dat is duurder en complexer) ().
- Wijzigingen in de site-structuur: Walmart past de site regelmatig aan. Breekt je scraper? Inspecteer de JSON-structuur opnieuw en pas je code aan. Houd je code modulair.
- Paginering & subpagina’s: Veel data scrapen betekent omgaan met paginering. Gebruik lussen met goede stopcondities en check altijd of je het einde hebt bereikt ().
- Datavolume & limieten: Bij grote scrapes: batch je requests en schrijf tussentijds weg naar disk. Probeer niet 100.000 producten tegelijk in het geheugen te laden.
- Juridische & ethische kwesties: Scrape alleen openbare data, respecteer Walmart’s voorwaarden en overbelast hun servers niet. Bouw je een business op deze data? Check de regels goed.
Wanneer overstappen op een managed oplossing? Als je meer tijd kwijt bent aan CAPTCHAs oplossen dan aan data-analyse, is het tijd voor een tool als Thunderbit of een scraper API. Voor niet-developers zijn no-code tools vaak de slimste keuze ().
Walmart Scrapen met Python: Volledig Voorbeeldscript
Alles bij elkaar? Hier een compleet, becommentarieerd Python-script om Walmart-productpagina’s te scrapen:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# Zet sessie en headers op
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# Bezoek homepage voor cookies
14session.get("<https://www.walmart.com/>")
15# Lijst met product-URLs om te scrapen
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # Voeg meer URLs toe indien nodig
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"Request error for \{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"Failed to fetch \{url\} (status \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"No data script found for \{url\} - possibly blocked or changed page format.")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"JSON parse error for \{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"Product data not found in JSON for \{url\}.")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "Naam": name,
59 "Merk": brand,
60 "Prijs": price,
61 "Valuta": currency,
62 "OriginelePrijs": orig_price,
63 "GemiddeldeBeoordeling": avg_rating,
64 "AantalReviews": review_count,
65 "Beschrijving": desc
66 }
67 all_products.append(product_record)
68 # Willekeurige vertraging om detectie te voorkomen
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)Aanpassen:
- Voeg meer URLs toe aan
product_urls. - Pas de velden aan die je wilt extraheren.
- Stel de vertraging in naar eigen inzicht.
Samenvatting & Belangrijkste Inzichten
Nog even kort:
- Walmart scraping is dé manier om prijs-, product- en reviewdata te verzamelen – essentieel voor concurrentieanalyse, prijsstrategie en productontwikkeling in 2025.
- Python is je beste maatje: Met Requests, BeautifulSoup en pandas bouw je snel een robuuste scraper, ook zonder diepgaande programmeerkennis.
- Anti-botmaatregelen zijn pittig: Gebruik browser-headers, sessions, vertragingen en proxies als je opschaalt.
- Haal data uit de
__NEXT_DATA__JSON: Dat is stabieler en minder foutgevoelig dan HTML-tags scrapen. - Exporteer je data voor analyse: Gebruik pandas om op te slaan als CSV, Excel of JSON.
- Schaal slim op: Voor grote projecten zijn proxies of een scraper API handig. Niet technisch? regelt Walmart (en andere sites) in een paar klikken – zonder code. Je kunt zelfs gratis exporteren naar Excel, Google Sheets, Airtable of Notion ().
Mijn tip:
Begin klein – scrape één product, dan een paar. Check of je data klopt. Respecteer Walmart’s voorwaarden en overbelast hun servers niet. Groeit je behoefte? Overweeg dan managed tools of APIs om tijd en frustratie te besparen. En ben je het debuggen zat? Met Thunderbit scrape je Walmart (en bijna elke site) in twee klikken, waarbij AI al het zware werk doet ().
Wil je verder de diepte in met webscraping, data-automatisering of AI-productiviteit? Check meer gidsen op de .
Veel succes met scrapen – en moge je data altijd vers, accuraat en CAPTCHA-vrij zijn.
P.S. Zit je ooit om 2 uur ‘s nachts Walmart te scrapen en mopper je op je scherm? Geen stress, dat hoort erbij. Debuggen is karaktervorming voor datamensen.
Veelgestelde Vragen
1. Is het legaal om data van Walmart te scrapen met Python?
Het scrapen van publiek toegankelijke data voor persoonlijk of niet-commercieel gebruik is meestal toegestaan, maar zakelijk gebruik kan juridische en ethische vragen oproepen. Check altijd Walmart’s gebruiksvoorwaarden en zorg dat je hun servers niet overbelast of gevoelige data verzamelt.
2. Welke data kan ik van Walmart halen met Python-scraping?
Je kunt productnamen, prijzen, merkinfo, beschrijvingen, klantreviews, beoordelingen, voorraadstatus en meer extraheren – vooral door de gestructureerde JSON in de <script id="__NEXT_DATA__">-tag te parsen.
3. Hoe voorkom ik blokkades bij het scrapen van Walmart?
Gebruik realistische headers, werk met sessions, voeg willekeurige vertragingen toe (3–6 seconden), roteer proxies en vermijd te veel verzoeken in korte tijd. Voor grotere projecten kun je scraper APIs of tools als Thunderbit gebruiken die anti-botmaatregelen automatisch afhandelen.
4. Kan ik honderden of duizenden Walmart-productpagina’s scrapen?
Ja, maar je moet proxies beheren, verzoeken vertragen en mogelijk een scraper API inzetten voor efficiëntie. Walmart heeft sterke anti-botmaatregelen, dus zonder voorbereiding loop je kans op blokkades of CAPTCHAs.
5. Wat is de makkelijkste manier om Walmart te scrapen als ik niet kan programmeren?
Met tools als de Thunderbit AI-webscraper Chrome-extensie kun je Walmart-productpagina’s scrapen zonder een regel code te schrijven. De tool regelt anti-botbescherming, ondersteunt export naar Excel, Notion en Sheets, en is ideaal voor niet-developers of zakelijke teams die snel inzichten willen.