

Het web staat vol data, en de vraag om die data binnen te halen groeit hard — al zul je, als je op zoek gaat naar één marktgetal, schattingen vinden die sterk uiteenlopen, afhankelijk van of een analist software, diensten, proxies of alle drie meetelt. De eerlijke conclusie: webscraping is een saai, maar onmisbaar onderdeel van de datastack geworden.
Of je nu businessanalist, marketeer of gewoon een nieuwsgierige beginner bent, de vaardigheid om gegevens van een website te halen wordt snel onmisbaar. En als je net als ik bent, sla je die eindeloze copy-paste-rondes het liefst over en ga je meteen naar het leuke deel: bruikbare inzichten, nette spreadsheets en misschien zelfs een beetje automatiseringsmagie.
Daar komt Python om de hoek kijken. Het is het Zwitserse zakmes van de dataruimte — simpel genoeg voor beginners, maar krachtig genoeg voor alles, van het scrapen van één pagina tot het crawlen van duizenden. In deze praktische tutorial laat ik je de basis van webscraping met Python zien, leer ik je hoe je dynamische websites aanpakt, en maak ik je ook kennis met Thunderbit, onze AI-gedreven webscraper zonder code die data-extractie net zo makkelijk maakt als eten bestellen. Of je hier bent om te leren coderen of gewoon een shortcut zoekt: je zit hier goed.
Wat is webscraping en waarom Python gebruiken om gegevens van een website te halen?
Gegevens van elke website halen met AI Get Started Free
Webscraping is het geautomatiseerd extraheren van informatie van websites en die omzetten naar een gestructureerd formaat — denk aan spreadsheets, CSV-bestanden of databases — voor analyse of zakelijk gebruik (PromptCloud). In plaats van handmatig data te kopiëren en plakken, doet een scraper na wat een mens zou doen, maar dan razendsnel en op grote schaal.
Waarom is dat zo waardevol? Omdat in de huidige zakenwereld datagedreven besluitvorming allesbepalend is. Hoe groter je organisatie, hoe meer beslissingen je met echte cijfers wilt onderbouwen in plaats van gevoel — en veel van die cijfers beginnen hun leven op de webpagina van iemand anders.
Stel je voor dat je dagelijks concurrentieprijzen kunt volgen, woningaanbod kunt bundelen of een eigen leadlijst kunt opbouwen — zonder er zelf veel werk aan te hebben.
Dus waarom Python? Dit is waarom het de favoriete taal voor webscraping is:
- Leesbaarheid en eenvoud: De syntaxis van Python is overzichtelijk en beginnersvriendelijk, waardoor het makkelijk is om scraping-scripts te schrijven en te begrijpen (PromptCloud).
- Rijk ecosysteem: Bibliotheken als
requests,BeautifulSoup,ScrapyenSeleniummaken scrapen, parsen en browseracties automatiseren een fluitje van een cent. - Sterke community: Omdat Python consequent wordt gerangschikt als de populairste programmeertaal ter wereld, zijn er eindeloos veel tutorials, forums en codevoorbeelden om je op weg te helpen.
- Schaalbaarheid: Python kan alles aan, van eenvoudige eenmalige scripts tot grootschalige crawlers.
Kortom: Python is je toegangsbewijs tot de wereld van webdata, of je nu een totale beginner bent of een ervaren analist.
Aan de slag: basis van een Python-webscraping-tutorial
Voordat we de code induiken, zetten we eerst de basisworkflow voor het halen van gegevens van een website met Python op een rij:
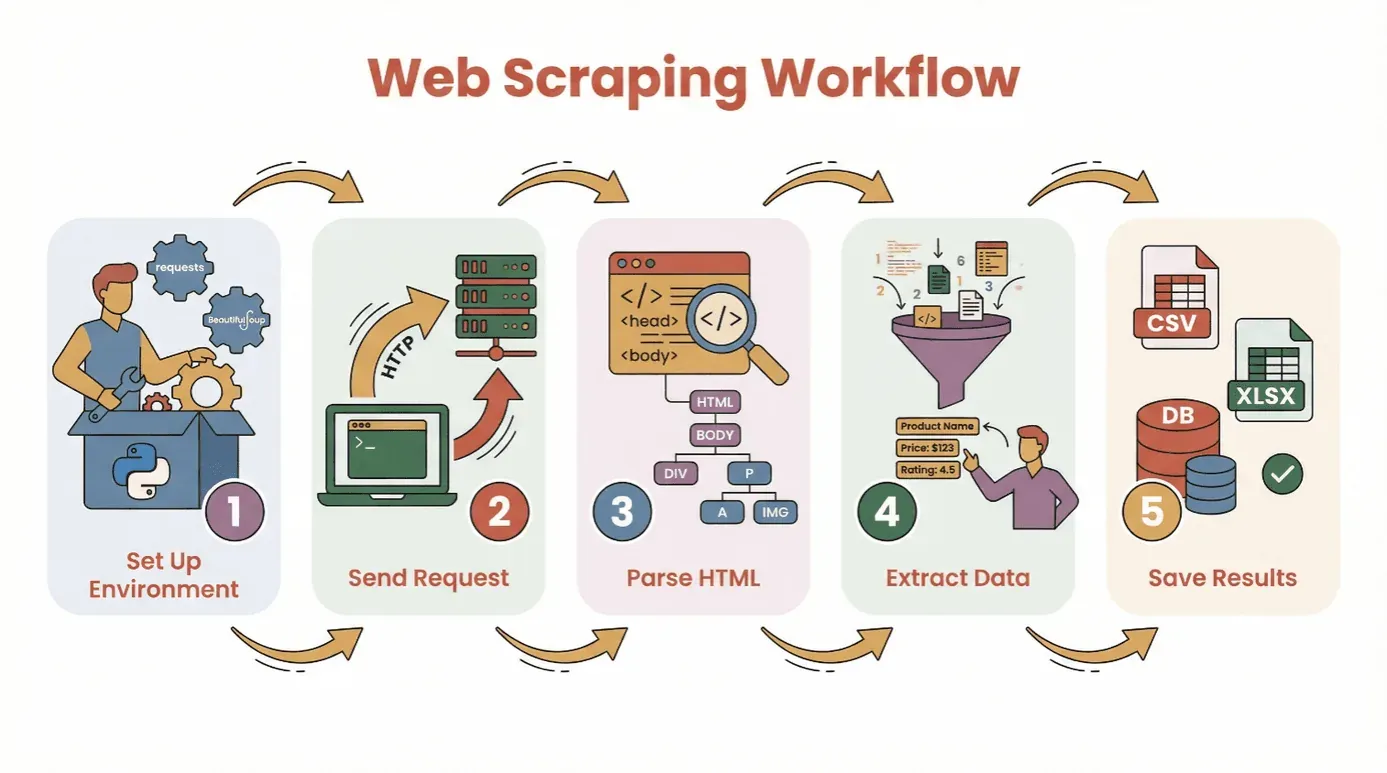
- Zet je omgeving op: Installeer Python en de benodigde bibliotheken (
requests,BeautifulSoup, enzovoort). - Stuur een request: Gebruik Python om de HTML-inhoud van je doelpagina op te halen.
- Parse de HTML: Gebruik een parser om door de structuur van de pagina te navigeren.
- Extraheer de data: Zoek de informatie die je nodig hebt en haal die eruit.
- Sla de resultaten op: Bewaar je data in een CSV, Excel-bestand of database voor analyse.
Je hoeft geen codegoochelaar te zijn om te beginnen. Als je Python kunt installeren en een script kunt draaien, ben je al halverwege. Voor totale beginners raad ik aan een virtuele omgeving of een Jupyter-notebook te gebruiken, maar een eenvoudige teksteditor is ook prima.
Essentiële bibliotheken:
requests— om webpagina’s op te halenBeautifulSoup— om HTML te parsenpandas— om data op te slaan en op te schonen (optioneel, maar sterk aanbevolen)
De juiste Python-bibliotheek voor webscraping kiezen: BeautifulSoup, Scrapy of Selenium?
Niet alle Python-scrapingtools zijn gelijk. Hier is een snelle uitleg van de drie populairste opties:
| Tool | Waarvoor het het beste is | Sterke punten | Nadelen |
|---|---|---|---|
| BeautifulSoup | Eenvoudige, statische pagina’s; beginners | Makkelijk te gebruiken, weinig installatie, uitstekende documentatie | Minder geschikt voor grote crawls of dynamische content |
| Scrapy | Crawlen op grote schaal, over meerdere pagina’s | Snel, asynchroon, ingebouwde pipelines, kan crawlen en dataopslag aan | Steilere leercurve, overkill voor kleine taken, draait geen JavaScript |
| Selenium | Dynamische sites / sites met veel JavaScript, automatisering | Kan JS renderen, gebruikersacties simuleren, ondersteunt logins en klikken | Langzamer, zwaarder qua resources, complexere installatie |
BeautifulSoup: de favoriet voor simpele HTML-parsing
BeautifulSoup is perfect voor beginners en kleine projecten. Je kunt HTML parsen en elementen extraheren met maar een paar regels code. Als je doelsite vooral statisch is (zonder ingewikkelde JavaScript-lading), dan heb je met BeautifulSoup + requests genoeg.
Voorbeeld:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
Wanneer gebruiken: eenmalige scrapes, simpele blogs, productpagina’s of directory’s.
Scrapy: voor grootschalig of gestructureerd crawlen
Scrapy is een volwaardig framework voor het crawlen van complete websites of het verwerken van duizenden pagina’s. Het is asynchroon (oftewel: snel), ondersteunt pipelines voor het opschonen en opslaan van data, en kan automatisch links volgen.
Voorbeeld:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
Wanneer gebruiken: grote projecten, geplande crawls, of als je snelheid en structuur nodig hebt.
Selenium: dynamische en JavaScript-zware websites aanpakken
Selenium bedient een echte browser (zoals Chrome of Firefox), dus het kan overweg met sites die data via JavaScript laden, logins vereisen of waarbij je op knoppen moet klikken.
Voorbeeld:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
Wanneer gebruiken: sociale media, beurssites, infinite scroll of alles wat er leeg uitziet als je “bron weergeven” kiest.
Stap voor stap: hoe je met Python gegevens van een website haalt (beginnershandleiding)
Laten we een echt voorbeeld bekijken met requests en BeautifulSoup. We scrapen een eenvoudige boekensite voor titels, auteurs en prijzen.
Stap 1: je Python-omgeving instellen
Installeer eerst de bibliotheken die je nodig hebt:
pip install requests beautifulsoup4 pandas
Daarna importeer je ze in je script:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Stap 2: een request naar de website sturen
Haal de HTML-inhoud op:
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"Pagina ophalen mislukt: {response.status_code}")
Stap 3: HTML-inhoud parsen
Maak een BeautifulSoup-object aan:
soup = BeautifulSoup(html, 'html.parser')
Zoek alle boekcontainers:
books = soup.find_all('article', class_='product_pod')
print(f"Op deze pagina zijn {len(books)} boeken gevonden.")
Stap 4: de data extraheren die je nodig hebt
Loop door elk boek en haal de details op:
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"Titel": title, "Prijs": price})
Stap 5: data opslaan voor analyse
Zet het om naar een DataFrame en sla het op:
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
Nu heb je een nette CSV-bestand klaar voor analyse!
Tips voor probleemoplossing:
- Als je lege resultaten krijgt, controleer dan of de data door JavaScript wordt geladen (zie het volgende gedeelte).
- Inspecteer altijd de HTML-structuur met de ontwikkelaarstools van je browser.
- Handel ontbrekende data af met
get_text(strip=True)en voorwaardelijke checks.
Dynamische content overwinnen: gegevens halen van websites die JavaScript renderen
Moderne websites zijn dol op JavaScript. Soms staat de data die je wilt niet in de initiële HTML — die wordt pas geladen nadat de pagina is verschenen. Als je scraper niets teruggeeft, heb je waarschijnlijk te maken met dynamische content.
Zo pak je het aan:
- Selenium: simuleert een echte browser, wacht tot content geladen is en kan op knoppen klikken of scrollen.
- Playwright/Puppeteer: geavanceerder, maar vergelijkbaar idee (headless browsers).
Mini-handleiding voor Selenium:
- Installeer Selenium en een browserdriver (bijvoorbeeld ChromeDriver).
- Gebruik expliciete waits om content te laten laden.
- Extraheer de gerenderde HTML en parse die indien nodig met BeautifulSoup.
Voorbeeld:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Extraheer data zoals eerder
driver.quit()
Wanneer heb je Selenium nodig?
- Als
requests.get()HTML zonder data teruggeeft, maar je die data wel in je browser ziet. - Als de site infinite scroll, pop-ups of login vereist.
Webscraping eenvoudiger maken met AI: Thunderbit gebruiken om gegevens van een website te halen
Probeer Thunderbit AI-webscraper Haal gegevens van elke website in 2 klikken op — geen code nodig. Get Started Free
Laten we eerlijk zijn: soms wil je gewoon de data, niet de code. Daar komt Thunderbit om de hoek kijken. Thunderbit is een AI-aangedreven Chrome-extensie waarmee je met een paar klikken gegevens van elke website kunt halen — zonder Python nodig te hebben.
Hoe Thunderbit werkt:
- Installeer de Thunderbit Chrome-extensie.
- Open je doelwebsite.
- Klik op het Thunderbit-icoon en kies ‘AI Suggest Fields’. De AI van Thunderbit scant de pagina en doet suggesties voor welke data je moet extraheren (bijv. productnamen, prijzen, e-mails).
- Pas velden aan indien nodig en klik op ‘Scrape’.
- Exporteer je data direct naar Excel, Google Sheets, Notion of Airtable.
Waarom Thunderbit zo goed werkt:
- Geen code nodig. Zelfs mijn moeder kan het gebruiken (en zij belt me nog steeds als de wifi het niet doet).
- Ondersteunt subpagina’s en paginering. Wil je productdetails van meerdere pagina’s scrapen? Thunderbit klikt erdoorheen en voegt de data voor je samen.
- Instructies in gewone taal. Zeg gewoon wat je wilt (“haal alle producttitels en prijzen op”) en laat de AI het uitzoeken.
- Directe templates voor populaire sites. Amazon, Zillow, LinkedIn en meer — één klik en je bent klaar.
- Gratis data-export. Download als CSV, Excel of stuur het direct naar je favoriete tools.
Thunderbit wordt vertrouwd door meer dan 100.000 gebruikers wereldwijd. Er is een gratis laag die je zonder te betalen kunt uitproberen — kijk op de prijspagina voor de actuele gebruiksruimte, omdat de limieten al een paar keer zijn gewijzigd. Voor zakelijke gebruikers is het een enorme tijdbesparing; voor Python-gebruikers is het een handige manier om een klus af te bakenen voordat je beslist of het de moeite waard is om je eigen scraper te schrijven.
Probeer Thunderbit gratis – geen code nodig
Na het scrapen: data opschonen en analyseren met Pandas en NumPy
Data ophalen is pas de eerste stap. Ruwe webdata is vaak rommelig — duplicaten, ontbrekende waarden, vreemde formaten. Daar blinken Python’s pandas- en NumPy-bibliotheken in uit.
Veelvoorkomende opschoontaken:
- Duplicaten verwijderen:
df.drop_duplicates(inplace=True) - Ontbrekende waarden afhandelen:
df.fillna('Unknown')ofdf.dropna() - Datatypes omzetten:
df['Price'] = df['Price'].str.replace('$','').astype(float) - Datums parsen:
df['Date'] = pd.to_datetime(df['Date']) - Uitschieters filteren:
df = df[df['Price'] > 0]
Basisanalyse:
- Samenvattende statistiek:
df.describe() - Groeperen per categorie:
df.groupby('Category')['Price'].mean() - Snelle grafieken:
df['Price'].hist()ofdf.groupby('Category')['Price'].mean().plot(kind='bar')
Voor geavanceerdere wiskunde of snelle arraybewerkingen is NumPy je vriend. Maar voor de meeste zakelijke gebruikers dekt pandas 95% van wat je nodig hebt.
Bronnen: Ben je nieuw met pandas, bekijk dan de gids 10 Minutes to pandas.
Beste praktijken en tips voor succesvol Python-webscraping
Webscraping is krachtig, maar brengt ook verantwoordelijkheid met zich mee. Hier is mijn checklist om het professioneel aan te pakken (en niet geblokkeerd of aangeklaagd te worden):
- Respecteer robots.txt en de servicevoorwaarden. Controleer altijd of de site scrapen toestaat (PromptCloud).
- Overbelast servers niet. Voeg vertragingen toe tussen requests (
time.sleep(2)) en scrape op menselijk tempo. - Gebruik realistische headers. Stel een User-Agent in om een browser na te bootsen.
- Ga netjes om met fouten. Gebruik try/except-blokken en probeer mislukte requests opnieuw.
- Roteer proxies indien nodig. Voor grootschalig scrapen kun je proxy-pools overwegen om IP-bans te vermijden.
- Wees ethisch en juridisch verantwoord. Scrape geen persoonlijke gegevens of content achter logins zonder toestemming.
- Documenteer je proces. Houd bij wat je hebt gescrapet, van waar en wanneer.
- Gebruik officiële API’s wanneer die beschikbaar zijn. Soms is er een betere manier dan HTML scrapen.
Voor meer tips, bekijk de Ultimate Web Scraping Guide.
Conclusie en belangrijkste inzichten
Webscraping met Python is een superkracht voor iedereen die de chaos van het web wil omzetten in gestructureerde, bruikbare data. Of je nu code gebruikt (met requests, BeautifulSoup, Scrapy of Selenium) of een no-code tool zoals Thunderbit, je hebt de middelen om gegevens van een website te halen en nieuwe inzichten te ontsluiten.
Onthoud:
- Begin simpel — scrape eerst één pagina voordat je grote projecten aanpakt.
- Kies de juiste tool voor je doel (BeautifulSoup voor de basis, Scrapy voor schaal, Selenium voor dynamische sites, Thunderbit voor no-code).
- Maak je data schoon en analyseer die met pandas en NumPy.
- Scrape altijd verantwoord en ethisch.
Klaar om het zelf te proberen? Begin met een klein project — scrape bijvoorbeeld de headlines van vandaag of een productlijst — en kijk hoe snel je van ruwe webpagina naar een nette spreadsheet gaat. En als je de code wilt overslaan, download Thunderbit en laat AI het zware werk doen.
Voor meer tutorials, tips en webscraping-inzichten, bekijk de Thunderbit Blog.
Lees meer webscraping-tutorials
Veelgestelde vragen
1. Wat is webscraping en waarom is Python daar populair voor?
Webscraping is het geautomatiseerd extraheren van data van websites. Python is populair voor webscraping vanwege de leesbare syntaxis, krachtige bibliotheken (zoals BeautifulSoup, Scrapy en Selenium) en de sterke community-ondersteuning (PromptCloud).
2. Welke Python-bibliotheek moet ik gebruiken voor webscraping?
Gebruik BeautifulSoup voor eenvoudige, statische pagina’s; Scrapy voor grootschalig of meerpagina-crawlen; en Selenium voor dynamische websites of sites met veel JavaScript. Elke tool heeft zijn eigen sterke punten, afhankelijk van wat je nodig hebt (IPRoyal).
3. Hoe ga ik om met websites die data met JavaScript laden?
Voor content die door JavaScript wordt gerenderd, gebruik je Selenium (of Playwright) om een browser te simuleren en te wachten tot de content geladen is voordat je data extraheert. Soms kun je een onderliggend API-endpoint vinden door netwerkverkeer te inspecteren.
4. Wat is Thunderbit en hoe maakt het webscraping eenvoudiger?
Thunderbit is een AI-gedreven Chrome-extensie waarmee je zonder code gegevens van elke website kunt halen. Het gebruikt AI om velden voor te stellen, subpagina’s en paginering af te handelen en data direct naar Excel, Google Sheets, Notion of Airtable te exporteren.
5. Hoe kan ik gescrapete data opschonen en analyseren in Python?
Gebruik pandas om duplicaten te verwijderen, ontbrekende waarden af te handelen, datatypes om te zetten en analyses uit te voeren. NumPy is ideaal voor numerieke bewerkingen. Voor visualisatie werkt pandas samen met Matplotlib voor snelle grafieken (10 Minutes to pandas).
Veel succes met scrapen — en moge je data altijd schoon, gestructureerd en klaar voor actie zijn.
Probeer AI-webscraper Get Started Free
Meer lezen




