
Als je in 2026 webdata nodig hebt, is de lastige vraag niet langer: “kan dit worden gescrapet?” Het is: “welke tool levert bruikbare data op met de minste verspilde tijd aan setup, onderhoud en infrastructuurkosten?” Daarom is deze pagina vooral opgebouwd rond de juiste match: AI-webscrapers voor snelheid, no-code tools voor herhaalbare browsertaken, API’s voor schaal en anti-botwerk, en Python-bibliotheken voor teams die volledige controle willen.
Het korte antwoord
- Kies een AI-webscraper als je zo snel mogelijk van pagina naar spreadsheet wilt, met minimale setup.
- Kies een no-code scraper als je expliciete paginering, planning, login-afhandeling of herhaalbare taakcontrole nodig hebt.
- Kies een scraping-API als rendering, anti-botbescherming, concurrency en unblock-rate belangrijker zijn dan een simpele interface.
- Kies een Python-bibliotheek als je team volledige zeggenschap wil over requests, parsing, browserautomatisering, retries en deployment.
Voor de meeste zakelijke teams gaat het mis als ze te vroeg naar een zwaardere laag springen. Begin met de lichtste tool die het werk betrouwbaar kan doen, en stap pas van AI naar no-code, naar API’s en code als je workflow dat echt vraagt.
Download hier het volledige visuele pakket: .
Snelle vergelijkingstabel: website-scrapingtools in één oogopslag
De prijsindicaties hieronder zijn gecontroleerd aan de hand van officiële product-, prijs- of documentatiepagina’s op 12 mei 2026. Waar leveranciers werken met maatwerk- of gebruiksafhankelijke facturatie, beschrijf ik het prijsmodel in plaats van een neppe vergelijkbare maandprijs te forceren.
| Tool | Categorie | Beste match | Waarom deze 2026-lijst | Prijsindicatie (gecontroleerd in mei 2026) |
|---|---|---|---|---|
| Thunderbit | AI-webscraper | Sales, operations, ecommerce, vastgoed | Snelste niet-technische route van webpagina naar gestructureerde tabel | Gratis plan, betaalde niveaus, zakelijke prijzen |
| Kadoa | AI-extractieplatform | Datateams en grotere terugkerende programma’s | Sterke fit voor zelfherstellende, agentachtige extractieworkflows | Gratis evaluatie, gebruiksafhankelijke en enterprise-plannen |
| Octoparse | No-code scraper | Analisten en terugkerende operationele taken | Volwassen cloudscraping en visuele taakbouwer | Gratis plan, Standard vanaf $69/maand, hogere niveaus |
| ParseHub | Low-code scraper | Technische non-coders en onderzoekers | Flexibele navigatielogica voor lastigere sites | Gratis plan, betaalde plannen vanaf $189/maand |
| Web Scraper | Browser no-code scraper | Beginners en lichte herhaalbare taken | Eenvoudig sitemap-model met optionele cloudlaag | Gratis extensie, Cloud vanaf $50/maand |
| Browse AI | No-code robot scraper | Monitoring en teams die eerst met spreadsheets werken | Sterk voor herhaalbare monitoring en wijzigingsalerts | Gratis plan, betaalde plannen, managed tier |
| Bardeen | AI-browserautomatisering | GTM- en revops-automatisering | Het beste wanneer scrapen slechts één stap is in een grotere workflow | Gratis plan, Basic vanaf $10/maand, Premium en Enterprise |
| ScrapeStorm | Visuele scraper met AI-ondersteuning | Gebruikers die snel visueel willen instellen | Handige brug tussen handmatige selectors en AI-hulp | Gratis proefperiode, betaalde plannen, enterprise-prijzen |
| ScraperAPI | Scraping-API | Developers die request-volume opschalen | Eenvoudige API plus proxy, CAPTCHA en rendering-offload | 7-daagse proef, betaald vanaf $49/maand |
| Bright Data Web Scraper | Enterprise-scrapingplatform | Inkoop-intensieve en compliance-gedreven programma’s | Meest brede dataverzamelingsstack in de groep | Productgebaseerde en gebruiksgebaseerde prijzen |
| Zyte | API + anti-botstack | Developer- en datateams | Sterke browseracties, JS-rendering en IP-rotatie | $5 gratis proeftegoed, gebruiksafhankelijke plannen |
| ZenRows | Scraping-API | Start-ups en developmentteams | Strakke anti-bot-API met minder wrijving bij adoptie | Gratis proef, Developer vanaf $69/maand |
| ScrapingBee | Scraping-API | Teams die JS-zware sites scrapen | Handig wanneer rendering het grootste pijnpunt is | Gratis proef, betaald vanaf $49/maand |
| Selenium | Open-source browserautomatisering | QA-achtige flows en interactierijk scrapen | Nog steeds relevant waar precieze gebruikersinteractie telt | Gratis en open-source |
| Beautiful Soup | Python parsing-bibliotheek | Lichtgewicht Python-scraping | De makkelijkste parser in de stack voor rommelige HTML | Gratis en open-source |
| Playwright | Moderne browserautomatisering | Moderne webapps en developmentteams | De beste moderne keuze voor gescripte browserscraping | Gratis en open-source |
| urllib3 | Python HTTP-bibliotheek | Developers die low-level requestcontrole willen | Handige basis wanneer je transportgedrag direct zelf wilt beheren | Gratis en open-source |
Hoe kies je de juiste website-scrapingtool
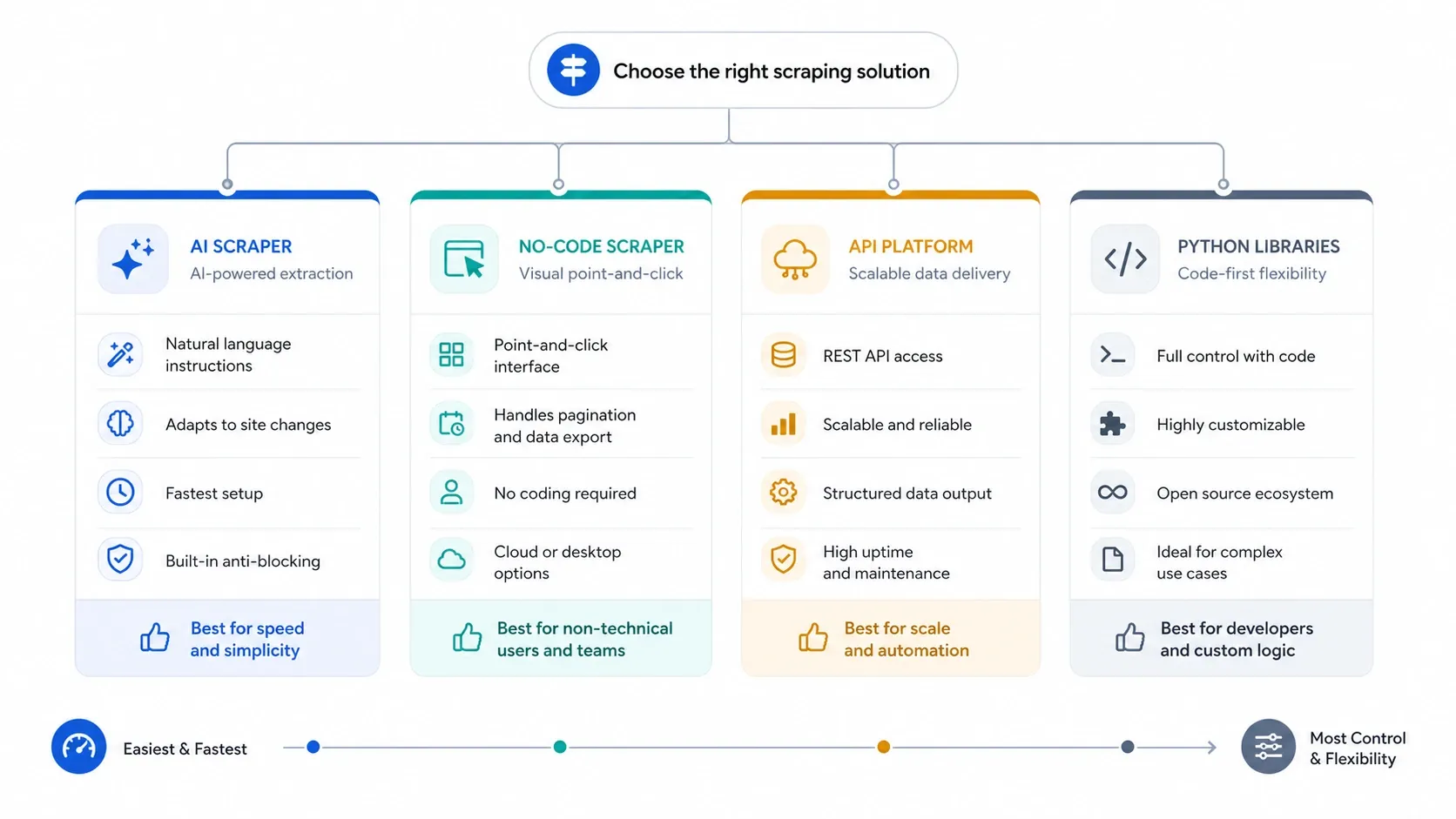
Gebruik vier filters voordat je merken met elkaar vergelijkt:
- Tijd tot eerste bruikbare output
Als de tool niet snel een echte tabel kan opleveren, valt hij voor de meeste zakelijke use-cases meteen af. - Onderhoudslast
Een goedkope scraper die stukgaat zodra de layout verandert, is in de praktijk niet goedkoop. - Schaallimiet
Een browserextensie kan perfect zijn voor 50 pagina’s per week en rampzalig voor 5 miljoen maandelijkse requests. - Workflow-fit
De beste scraper voor revops is zelden de beste voor een platform engineer.
Het besliskader is meestal eenvoudiger dan teams het maken:
- Als je leads, listings of productpagina’s wilt scrapen zonder selectors aan te raken, begin dan met AI.
- Als je herhaalbare taken, cloudruns en meer expliciete controle nodig hebt, stap dan over naar no-code visuele builders.
- Als anti-bot, JavaScript-rendering en concurrency het echte probleem zijn, ga dan direct naar API’s.
- Als je elke laag zelf wilt beheren, gebruik dan Python-bibliotheken en neem de onderhoudslast erbij.
Beste AI-webscrapers voor snelle zakelijke workflows
Dit is de eerste categorie die ik zou testen als je spreadsheetklare data wilt met zo min mogelijk configuratie.
1. Thunderbit
Thunderbit is hier nog steeds het makkelijkste startpunt voor niet-coders. Het belangrijkste voordeel is niet alleen “AI” in abstracte zin; het is vooral dat het product de setup-lus inkort. Je opent een pagina, laat AI velden voorstellen, verrijkt via subpagina’s wanneer dat nodig is, en stuurt het resultaat direct naar de tools die je team al gebruikt.
- Beste voor: sales prospecting, ecommerce-monitoring, vastgoedverzameling en operationele teams die in de browser werken.
- Waarom het opvalt: de snelste route van rommelige pagina naar gestructureerde tabel.
- Let op: als je crawler-grade logica of sterk aangepaste engineeringflows nodig hebt, kom je uiteindelijk uit bij API’s of code.
- Prijsindicatie: gratis plan, zelf te gebruiken betaalde niveaus en zakelijke prijzen.
Deze walkthrough is nog steeds de snelste manier om te beoordelen of AI-first scraping genoeg is voor jouw workflow:
2. Kadoa
Kadoa is de meer infrastructuurgerichte AI-optie in deze groep. Die past goed wanneer je zelfherstellende extractie en terugkerende jobs wilt op een grotere operationele schaal dan de meeste browserextensies aankunnen.
- Beste voor: datateams, interne intelligence-programma’s en grotere terugkerende extractieworkloads.
- Waarom het opvalt: agentachtige orkestratie en een sterker verhaal rond minder onderhoud.
- Let op: zwaarder dan wat de meeste zakelijke gebruikers nodig hebben voor snelle eenmalige scraping.
- Prijsindicatie: gratis evaluatie, gebruiksafhankelijke en enterprise-plannen.
Beste no-code website-scrapingtools voor herhaalbare taken
Zodra de scrapingtaak terugkerend wordt, krijgen visuele workflowbouwers en clouduitvoering meer gewicht dan pure snelheid van één klik.
3. Octoparse
Octoparse blijft een van de meest geloofwaardige no-code tools wanneer de taak groter is dan een browserextensie, maar nog geen maatwerk-engineeringproject. De kracht zit in de combinatie van cloudruns, templates en een volwassen visuele taakbouwer.
- Beste voor: analisten, prijsteams en terugkerende verzamelopdrachten met echte operationele waarde.
- Waarom het opvalt: meer diepgang dan browserplugins, zonder dat je code hoeft te schrijven.
- Let op: die flexibiliteit betaal je met een steilere leercurve dan bij AI-first tools.
- Prijsindicatie: gratis plan, Standard vanaf $69/maand, hogere betaalde niveaus.
Als je eerst een traditionelere no-code werkruimte wilt bekijken voordat je in AI-first tooling investeert, is dit officiële Octoparse-overzicht nog steeds nuttig:
4. ParseHub
ParseHub blijft relevant omdat genoeg teams meer stapsgewijze taaklogica willen dan een lichte AI-scraper biedt. Het is niet het mooiste product in de categorie, maar het blijft flexibel.
- Beste voor: onderzoekers, journalisten en technische non-coders die wat meer setup aankunnen.
- Waarom het opvalt: sterkere conditionele logica en navigatiecontrole dan veel beginnerstools.
- Let op: trager om te leren en minder modern aanvoelend dan nieuwere producten.
- Prijsindicatie: gratis plan, betaalde plannen vanaf $189/maand.
5. Web Scraper
Web Scraper is een van de nette opties om de basis te leren zonder meteen een platform te kopen. Als je het sitemap-model prettig vindt, is dit nog steeds een prima instappunt.
- Beste voor: beginners, hobbyprojecten en kleinere browsergestuurde taken.
- Waarom het opvalt: eenvoudige setup en een soepele overstap van lokale extensie naar cloudplannen.
- Let op: wordt beperkend zodra je adaptievere logica of sterkere unblock-afhandeling nodig hebt.
- Prijsindicatie: gratis extensie, Cloud vanaf $50/maand.
6. Browse AI
Browse AI blijft een sterke keuze wanneer scrapen en monitoring even belangrijk zijn. Het robotmodel is intuïtief voor zakelijke gebruikers die denken in termen van: “volg deze pagina en vertel me wat er is veranderd.”
- Beste voor: concurrentiemonitoring, prijsbewaking en teams die eerst met spreadsheets werken.
- Waarom het opvalt: gepolijste onboarding, terugkerende monitoring en output die goed werkt voor automatisering.
- Let op: complexe taken met hoge volumes kunnen sneller duur worden dan bij API-first stacks.
- Prijsindicatie: gratis plan, betaalde plannen, managed tier.
Voor teams die paginamonitoring evalueren in plaats van eenmalige extractie, is dit korte officiële overzicht nog steeds een goede check:
7. Bardeen
Bardeen draait minder om pure scrapingdiepte en meer om wat er ná het scrapen gebeurt. Het is het sterkst wanneer webextractie slechts één stap is binnen een grotere browserautomatiseringsworkflow.
- Beste voor: GTM-operations, leadrouting, CRM-overdracht en browser-native automatisering.
- Waarom het opvalt: sterk verhaal rond workflow-automatisering rondom het scrapen zelf.
- Let op: niet de beste keuze wanneer alleen extractienauwkeurigheid telt.
- Prijsindicatie: gratis plan, Basic vanaf $10/maand, Premium- en Enterprise-niveaus.
8. ScrapeStorm
ScrapeStorm vult nog steeds een nuttige middenpositie in voor gebruikers die AI-hulp willen, maar ook een meer traditionele visuele scrapingomgeving verwachten.
- Beste voor: directory-scraping, ecommerce-paginaverzameling en visueel geconfigureerde terugkerende taken.
- Waarom het opvalt: makkelijker om mee te starten dan veel oudere visuele tools.
- Let op: minder gepolijst dan de marktleiders en soms beperkter op lastigere sites.
- Prijsindicatie: gratis proefperiode, betaalde plannen, enterprise-prijzen.

Beste scraping-API’s wanneer schaal en anti-botafhandeling belangrijk zijn
Dit is de categorie waar je naartoe gaat wanneer de echte beperking niet langer is: “hoe selecteer ik de data?” maar: “hoe houd ik dit betrouwbaar onder belasting?”
9. ScraperAPI
ScraperAPI blijft een van de toegankelijkste API-first producten voor developers die niet meer willen nadenken over proxies en request-succespercentages.
- Beste voor: developers die snel van prototype naar productie willen opschalen.
- Waarom het opvalt: eenvoudige API plus ondersteuning voor proxy, CAPTCHA en rendering.
- Let op: parsing, retries en downstream datakwaliteit blijven wel jouw verantwoordelijkheid.
- Prijsindicatie: 7-daagse proef, betaald vanaf $49/maand.
10. Bright Data Web Scraper
Bright Data is de zwaargewichtkeuze wanneer unblock-capaciteit, proxy-inventaris, compliancehouding en managed opties belangrijker zijn dan eenvoud.
- Beste voor: dataverzameling op enterpriseschaal en compliancegevoelige programma’s.
- Waarom het opvalt: de breedste stack in deze vergelijking, van proxies tot managed collection-producten.
- Let op: je koopt snel te veel in als je team nog een vrij eenvoudige workflow heeft.
- Prijsindicatie: productgebaseerde en gebruiksgebaseerde prijzen.
11. Zyte
Zyte blijft een serieuze optie voor developmentteams die browseracties, JS-rendering, roterende IP’s en anti-bothouding in één platformverhaal willen.
- Beste voor: engineering-gedreven scrapingprogramma’s en herhaalbare extractiesystemen.
- Waarom het opvalt: sterke anti-detectiestack en API-first workflows.
- Let op: beter voor teams met engineering-eigenaarschap dan voor zakelijke gebruikers.
- Prijsindicatie: $5 gratis proeftegoed, gebruiksafhankelijke plannen.
12. ZenRows
ZenRows is een van de prettigste developerervaringen in de API-categorie als je anti-botafhandeling wilt zonder enterprise-achtig inkoopproces.
- Beste voor: start-ups, developers en lean interne toolingteams.
- Waarom het opvalt: relatief lage drempel om te starten plus sterke anti-botpositionering.
- Let op: het blijft een API-product, dus je houdt de applicatielogica en QA-last zelf.
- Prijsindicatie: gratis proef, Developer vanaf $69/maand.
13. ScrapingBee
ScrapingBee is logisch wanneer je echte behoefte een gerenderde pagina is en minder infrastructuurwerk, vooral voor JS-zware sites.
- Beste voor: developers die dynamische sites scrapen en rendering willen uitbesteden.
- Waarom het opvalt: eenvoudige API rond headless browsing en proxies.
- Let op: het haalt infrastructuurwerk weg, niet de noodzaak van goede scrapinglogica.
- Prijsindicatie: gratis proef, betaald vanaf $49/maand.
Beste Python-webscrapingbibliotheken voor maatwerkstacks
Deze groep is nog steeds het juiste antwoord wanneer controle belangrijker is dan gemak en je team klaar is om onderhoud zelf te dragen.
14. Selenium
Selenium is niet de nieuwste browsertool, maar het blijft relevant waar gebruikersinteractie precies moet kloppen en belangrijker is dan ruwe scraping-throughput.
- Beste voor: interactierijke flows, overlap met QA en sites waar browsergedrag de kernuitdaging is.
- Waarom het opvalt: volwassen ecosysteem en brede browserondersteuning.
- Let op: zwaarder en trager dan nieuwere automatiseringsstacks voor veel scrapingworkloads.
- Prijsindicatie: gratis en open-source.
15. Beautiful Soup

Beautiful Soup blijft de makkelijkste parser in de Python-scrapingstack. Het is geen compleet scrapingplatform, maar wel nog steeds de simpelste manier om rommelige HTML om te zetten in bruikbare structuur.
- Beste voor: lichte Python-taken, statische HTML-pagina’s en snelle prototypes.
- Waarom het opvalt: lage cognitieve belasting en vergevingsgezinde parsing.
- Let op: combineer het met
requests, een browserlaag of een crawler; op zichzelf parseert het alleen. - Prijsindicatie: gratis en open-source.
16. Playwright
Playwright is mijn standaard moderne aanbeveling voor developmentteams die robuuste browserautomatisering nodig hebben op het web van vandaag.
- Beste voor: JS-zware sites, moderne browserautomatisering en teams die al comfortabel code schrijven.
- Waarom het opvalt: sterk wachtgedrag, ondersteuning voor meerdere browsers en nette API’s.
- Let op: concurrency, selectors, browserinfrastructuur en datavalidatie blijven wel jouw verantwoordelijkheid.
- Prijsindicatie: gratis en open-source.
17. urllib3
urllib3 hoort op de lijst omdat sommige teams directe controle over transportgedrag willen in plaats van een hogere abstractielaag. Het is geen beginnersvriendelijke scraper, maar wel een nuttige basisbibliotheek wanneer je je eigen stack bouwt.
- Beste voor: developers die strakke controle willen over retries, proxies, sessions en HTTP-gedrag.
- Waarom het opvalt: lichtgewicht, betrouwbaar en veel gebruikt als infrastructuur.
- Let op: je bouwt het grootste deel van de stack zelf.
- Prijsindicatie: gratis en open-source.
Gratis website-scrapingtools die het waard zijn om eerst te testen
Als je eerst wilt testen voordat je koopt, zijn de beste gratis startpunten in deze lijst Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright en urllib3. De gratis ervaring is goed genoeg om te leren welk type scraper je echt nodig hebt, en dat is meestal belangrijker dan op dag één obsessief focussen op een perfecte featurelijst.
Mijn shortlist per teamtype

- Sales-, operations- en ecommerce-teams: begin met Thunderbit en vergelijk daarna Browse AI als monitoring belangrijker is dan verrijking van subpagina’s.
- Analisten en terugkerende handmatige operators: eerst Octoparse, daarna ParseHub als je meer aangepaste taaklogica nodig hebt.
- GTM-automatiseringsteams: Bardeen als de scrape direct moet doorstromen naar CRM, Sheets of browserworkflows.
- Developmentteams die interne tooling bouwen: ScraperAPI, ZenRows, Zyte of Playwright, afhankelijk van hoeveel eigenaarschap over de stack je wilt.
- Enterprise-dataprogramma’s: Bright Data en Zyte zijn hier de serieuzere infrastructuurgesprekken, met Kadoa als AI-geleid alternatief wanneer minder onderhoud het hoofddoel is.
Wanneer je naar een zwaardere laag moet gaan
Gebruik dit upgradepad:
- Blijf bij AI-webscrapers totdat je tegen grenzen van herhaalbaarheid of edge-cases aanloopt.
- Stap over naar no-code builders wanneer planning, paginering en clouduitvoering belangrijker worden dan eenvoud van één klik.
- Stap over naar API’s wanneer unblock-rate, rendering en concurrency de bottleneck worden.
- Stap over naar Python-bibliotheken wanneer vendor-abstrahering duurder wordt dan het hele systeem zelf bezitten.
De meeste teams doen dit in de verkeerde volgorde. Ze bouwen eerst te zwaar en beseffen pas later dat een lichtere tool het echte workflowprobleem had kunnen oplossen.
Eindconclusie
De beste website-scrapingtool in 2026 is niet de tool met de langste functielijst. Het is de tool die accurate data met de minste onderhoudslast in de volgende workflow krijgt. Daarom blijven AI-first tools winnen voor operators, blijven no-code tools waardevol voor herhaalbare browsertaken, domineren API’s wanneer schaal en blokkering tellen, en behouden Python-bibliotheken de hoge-controlelaag van de stack.
Als je doel is om deze week bruikbare data te krijgen, houd het dan simpel. Als je workload je al vertelt dat unblock-rate, browser-rendering en technische controle het echte probleem zijn, ga dan bewust naar een zwaardere laag in plaats van uit gewoonte.
FAQ’s
1. Wat is in 2026 de beste website-scrapingtool voor niet-technische gebruikers?
Voor de meeste niet-technische teams zijn AI-first tools zoals Thunderbit en Browse AI nog steeds de snelste route, omdat ze setup-tijd, selectorwerk en onderhoudslast verminderen.
2. Wat moet ik kiezen voor sites met veel JavaScript of anti-botbescherming?
Dan worden ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright of Selenium meestal logischer dan browserextensies.
3. Zijn no-code scrapingtools nog relevant nu AI-scrapers beter zijn?
Ja. Octoparse, ParseHub, Web Scraper en Browse AI blijven belangrijk wanneer je meer expliciete taakcontrole, terugkerende runs of browserzichtbare debugging nodig hebt.
4. Welke tools zijn het meest logisch voor developmentteams?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup en urllib3 passen het meest natuurlijk wanneer engineering de workflow beheert.
Gerelateerde lectuur