

Het internet groeit sneller dan mijn liefde voor koffie—en dat wil wat zeggen. In 2026 is webdata-extractie allang geen niche meer voor data-nerds; het is de basis van business intelligence, AI-training en automatisering. Of je nu markttrends volgt, je nieuwste LLM traint of gewoon de prijzen van je concurrenten checkt, de vraag naar actuele, gestructureerde webdata is nog nooit zo groot geweest. En in het hart van deze datarevolutie? Python. Dankzij het enorme ecosysteem en de toegankelijke syntax blijft Python dé taal voor webscraping, van snelle scripts tot grote crawlers.
Maar let op: de juiste python webscraping-pakketten kiezen maakt het verschil tussen soepel werken of eindeloos frustratie. Ik heb teams dagen zien verliezen aan anti-botmaatregelen met de verkeerde tool, of uren verspild zien worden aan het handmatig parsen van rommelige HTML terwijl een slimmere bibliotheek het in minuten had gekund. Na jaren ervaring in SaaS, automatisering en AI (en het bouwen van Thunderbit om scraping voor iedereen makkelijk te maken), heb ik de 12 beste python webscraping-pakketten voor 2026 op een rij gezet—elk met hun eigen sterke punten, eigenaardigheden en ideale toepassingen. Laten we samen kijken welk pakket het beste past bij jouw volgende dataproject.
Waarom de Juiste Python Webscraping-pakketten Zo Belangrijk Zijn
Gebruik AI om data van elke website te halen Get Started Free
Eerlijk is eerlijk: geen enkel webscraping-project is hetzelfde. Soms wil je gewoon een paar productprijzen van een simpele pagina halen. Andere keren zit je te stoeien met een JavaScript-zware site die koppiger is dan een kat die in bad moet. Het juiste pakket bespaart je uren (of dagen), voorkomt fouten en helpt je om valkuilen als anti-botblokkades of kapotte HTML te vermijden.
Python is niet voor niets zo populair voor webscraping. Bibliotheken als requests en urllib3 worden maandelijks meer dan 1 miljard keer gedownload, en bijna elke grote scraping-tool is Python-first. Maar met die kracht komt ook verantwoordelijkheid: kies je het verkeerde gereedschap, dan zit je zo vast in een traag project. Kies slim, en je zwemt in schone, gestructureerde data voordat je koffie koud is.
Hoe We de Beste Python Webscraping-pakketten Hebben Geselecteerd
Ik heb niet zomaar een willekeurige PyPI-lijst gepakt. Dit zijn de punten waarop ik elk pakket heb beoordeeld:
- Prestaties & Gelijktijdigheid: Kan het honderden of duizenden pagina’s snel ophalen?
- Gebruiksgemak: Is het geschikt voor beginners, of heb je een informaticadiploma nodig?
- HTML Parsing Kracht: Kan het omgaan met rommelige markup, ondersteunt het XPath/CSS-selectors en maakt het data-extractie makkelijk?
- Ondersteuning voor Dynamische Content: Kan het overweg met JavaScript-rijke sites, of alleen met statische pagina’s?
- Community & Documentatie: Is er een actieve gebruikersgroep en goede documentatie, of blijf je eindeloos zoeken op Stack Overflow?
- Beste Toepassing: Is het voor snelle scripts, grootschalige crawlers, of iets daartussenin?
Daarnaast heb ik feedback van ontwikkelaars, recente benchmarks en mijn eigen (soms pijnlijke) praktijkervaringen meegenomen. Tijd om de toppers te leren kennen.
1. Thunderbit
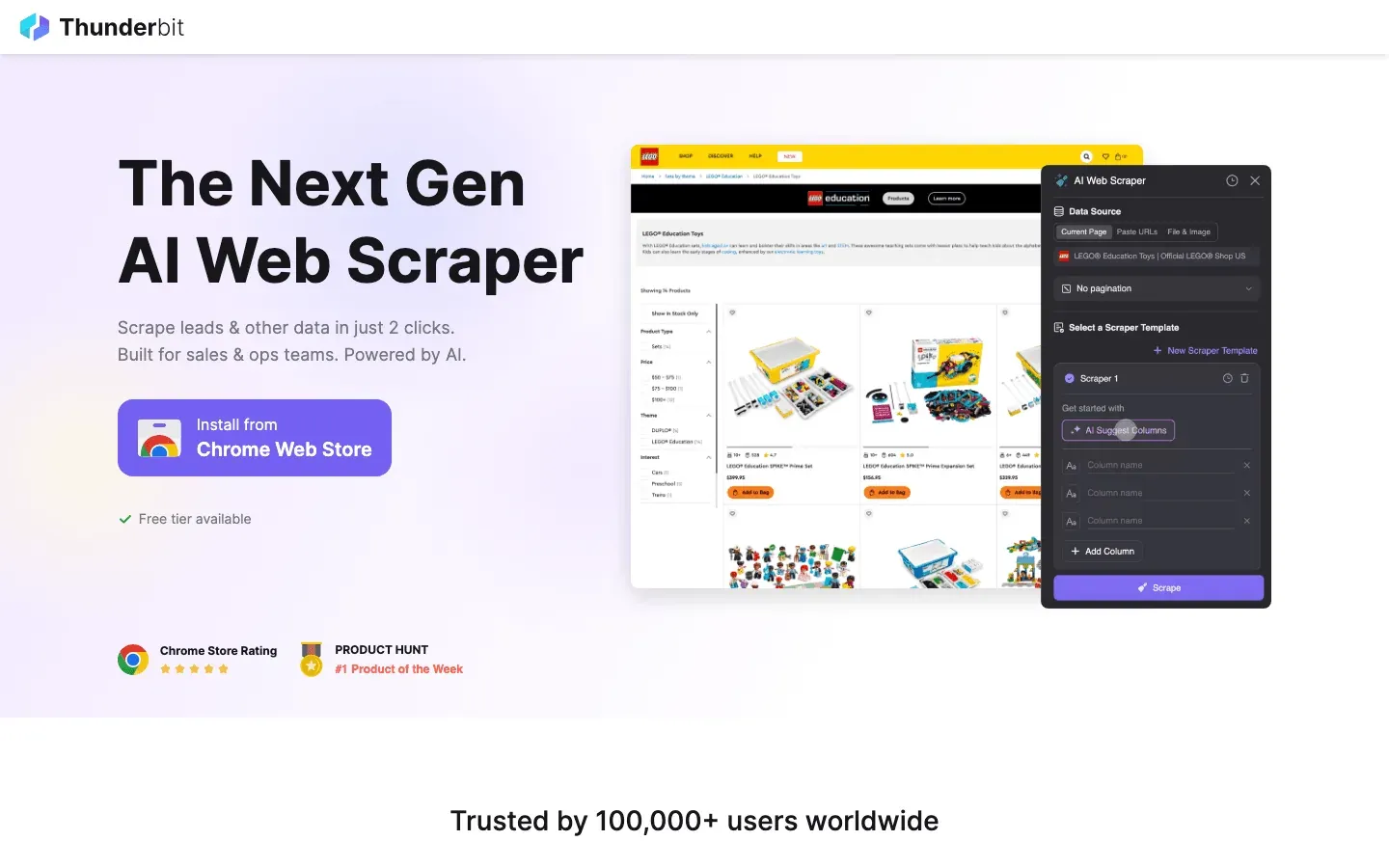 Thunderbit is geen standaard Python-bibliotheek—het is een AI-gedreven Chrome-extensie die webscraping opnieuw uitvindt, vooral voor Python-ontwikkelaars die snelheid, nauwkeurigheid en een vleugje AI willen. Wat maakt Thunderbit uniek? Je geeft met gewone taal aan welke data je zoekt, en de AI regelt alles: veldsuggesties, subpagina’s, paginering en exporteren naar Excel, Google Sheets, Notion of Airtable.
Thunderbit is geen standaard Python-bibliotheek—het is een AI-gedreven Chrome-extensie die webscraping opnieuw uitvindt, vooral voor Python-ontwikkelaars die snelheid, nauwkeurigheid en een vleugje AI willen. Wat maakt Thunderbit uniek? Je geeft met gewone taal aan welke data je zoekt, en de AI regelt alles: veldsuggesties, subpagina’s, paginering en exporteren naar Excel, Google Sheets, Notion of Airtable.
Thunderbit is ideaal voor het scrapen van complexe, ongestructureerde data—denk aan rommelige bedrijvengidsen, productoverzichten of sites waarvan de HTML meer op abstracte kunst lijkt dan op een gestructureerd document. De AI Suggest Fields-functie leest de pagina en stelt de beste kolommen voor, terwijl Subpage Scraping je dataset verrijkt door automatisch gelinkte detailpagina’s te bezoeken. En als je klaar bent met anti-botproblemen, bieden de browser- en cloud-scrapingopties van Thunderbit uitkomst.
Python-ontwikkelaars waarderen Thunderbit voor snelle prototypes, leadgeneratie en marktonderzoek. Je kunt de output direct in je Python-datapijplijn gebruiken, of scraping automatiseren via de API. Het is geen traditionele codebibliotheek, maar het wordt snel favoriet bij iedereen die minder tijd aan coderen en meer tijd aan data-analyse wil besteden.
Belangrijkste kenmerken:
- AI-gestuurde veldsuggesties en data-extractie
- Ondersteunt subpagina’s, paginering en zelfs PDF’s/afbeeldingen
- Exporteert naar CSV, Excel, Google Sheets, Notion, Airtable
- Geen code nodig—ideaal voor zowel niet-technische gebruikers als Python-pro’s die snel willen werken
- Gratis instapniveau; betaalde plannen groeien mee met je behoeften
Ideaal voor: Leadgeneratie, marktonderzoek, snelle prototypes en het scrapen van complexe of rommelige webdata.
Probeer Thunderbit AI-webscraper gratis
2. Beautiful Soup
 Beautiful Soup is dé klassieker voor HTML-parsing in Python. Als je net begint of data wilt halen van statische webpagina’s, is dit je beste vriend. Beautiful Soup blinkt uit in het navigeren en parsen van slecht gestructureerde HTML (“tag soup”), en is daarmee een redder in nood voor sites die zich niet aan de regels houden.
Beautiful Soup is dé klassieker voor HTML-parsing in Python. Als je net begint of data wilt halen van statische webpagina’s, is dit je beste vriend. Beautiful Soup blinkt uit in het navigeren en parsen van slecht gestructureerde HTML (“tag soup”), en is daarmee een redder in nood voor sites die zich niet aan de regels houden.
De API is erg toegankelijk—denk aan .find(), .select() en .text—en werkt perfect samen met requests om webpagina’s op te halen. Je kunt verschillende parsers kiezen (zoals lxml voor snelheid of html5lib voor maximale compatibiliteit). De documentatie is uitstekend en de community enorm.
Belangrijkste kenmerken:
- Intuïtieve, Python-achtige API voor HTML/XML
- Kan omgaan met kapotte of inconsistente markup
- Werkt met meerdere parsers voor snelheid of compatibiliteit
- Grote community en veel tutorials
Ideaal voor: Snelle scripts, statische pagina’s en beginners die een zachte leercurve willen.
3. Scrapy
 Scrapy is de zwaargewicht voor grootschalig, geautomatiseerd webcrawlen. Moet je honderden of duizenden pagina’s scrapen, pipelines beheren of periodieke taken plannen? Dan is Scrapy jouw framework. Gebouwd op de Twisted-engine is het razendsnel, ondersteunt asynchroon crawlen, item pipelines voor datacleaning en export naar JSON, CSV of databases.
Scrapy is de zwaargewicht voor grootschalig, geautomatiseerd webcrawlen. Moet je honderden of duizenden pagina’s scrapen, pipelines beheren of periodieke taken plannen? Dan is Scrapy jouw framework. Gebouwd op de Twisted-engine is het razendsnel, ondersteunt asynchroon crawlen, item pipelines voor datacleaning en export naar JSON, CSV of databases.
Scrapy is uitbreidbaar, met plugins voor proxies, caching en zelfs beperkte JavaScript-rendering (via Splash of Selenium-integratie). De leercurve is steiler dan bij Beautiful Soup, maar als je serieus met webdata aan de slag wilt, groei je vanzelf naar Scrapy toe.
Belangrijkste kenmerken:
- Asynchroon, zeer snel crawlen
- Ingebouwde pipelines voor datacleaning en opslag
- Export naar meerdere formaten (JSON, CSV, DB)
- Grote, actieve community en plugin-ecosysteem
Ideaal voor: Grootschalige, terugkerende scraping-projecten, datapijplijnen en iedereen die snelheid en betrouwbaarheid zoekt.
4. Selenium
 Selenium is dé tool voor het scrapen van JavaScript-rijke of interactieve sites. Het automatiseert echte browsers (Chrome, Firefox, enz.), zodat je gebruikersacties zoals klikken, scrollen en formulieren invullen kunt nabootsen. Verschijnt de data pas na het uitvoeren van JavaScript? Selenium krijgt het voor elkaar, hoe lastig de site ook is.
Selenium is dé tool voor het scrapen van JavaScript-rijke of interactieve sites. Het automatiseert echte browsers (Chrome, Firefox, enz.), zodat je gebruikersacties zoals klikken, scrollen en formulieren invullen kunt nabootsen. Verschijnt de data pas na het uitvoeren van JavaScript? Selenium krijgt het voor elkaar, hoe lastig de site ook is.
Het nadeel? Selenium is traag en vraagt veel van je systeem. Je draait immers voor elke scrape een volledige browser. Verwacht dus geen duizenden pagina’s per minuut. Maar voor die gevallen waar geen enkel ander pakket werkt, is Selenium onmisbaar.
Belangrijkste kenmerken:
- Volledige browserautomatisering (Chrome, Firefox, Edge, enz.)
- Kan omgaan met JavaScript-content en interactieve elementen
- Ondersteunt headless-modus voor snellere, UI-loze scraping
- Grote community en uitgebreide documentatie
Ideaal voor: Scrapen van dynamische, JavaScript-rijke sites, automatiseren van loginflows en omgaan met CAPTCHAs of complexe interacties.
Meer over Selenium’s voor- en nadelen
5. PyQuery
 PyQuery brengt jQuery-achtige syntax naar Python, waardoor HTML-parsing vertrouwd aanvoelt voor iedereen die met jQuery in JavaScript heeft gewerkt. Het gebruikt de snelle
PyQuery brengt jQuery-achtige syntax naar Python, waardoor HTML-parsing vertrouwd aanvoelt voor iedereen die met jQuery in JavaScript heeft gewerkt. Het gebruikt de snelle lxml-parser en laat je CSS-selectors gebruiken zoals $('div.classname') om elementen te vinden.
PyQuery is ideaal voor snelle prototypes en ontwikkelaars die compacte, leesbare code willen. Het is sneller dan Beautiful Soup bij complexe queries en integreert makkelijk met async-tools of Selenium voor geavanceerdere workflows.
Belangrijkste kenmerken:
- jQuery-achtige selectors en syntax in Python
- Snelle parsing met lxml-backend
- Ideaal voor ontwikkelaars die overstappen van JavaScript
- Ondersteunt chaining en compacte queries
Ideaal voor: Prototyping, jQuery-fans en iedereen die minder code wil schrijven voor HTML-parsing.
PyQuery tutorial en vergelijking
6. LXML
 LXML is de snelheidsduivel onder de HTML- en XML-parsers in Python. Gebouwd op de C-bibliotheken
LXML is de snelheidsduivel onder de HTML- en XML-parsers in Python. Gebouwd op de C-bibliotheken libxml2 en libxslt, staat het bekend om zijn prestaties en krachtige ondersteuning voor XPath en CSS-selectors. Werk je met grote documenten of complexe queries? Dan is lxml je beste keuze.
Je kunt het direct gebruiken of als backend voor Beautiful Soup of PyQuery. De API is wat geavanceerder, maar de snelheid en flexibiliteit zijn het waard voor grote klussen.
Belangrijkste kenmerken:
- Snelste parsing in Python
- Volledige ondersteuning voor XPath en CSS-selectors
- Efficiënt bij grote en complexe documenten
- Kan zelfstandig of als parser voor andere bibliotheken gebruikt worden
Ideaal voor: Hoge prestaties, grootschalige scraping en projecten met geavanceerde queries.
Waarom lxml uitblinkt in parsing
7. Requests
 Requests is dé standaard voor HTTP-verzoeken in Python. Dankzij de eenvoudige, intuïtieve API haal je webpagina’s op met slechts
Requests is dé standaard voor HTTP-verzoeken in Python. Dankzij de eenvoudige, intuïtieve API haal je webpagina’s op met slechts requests.get(url). Het regelt cookies, sessies en zelfs JSON-decodering automatisch.
Requests werkt synchroon (elke aanvraag wacht tot de vorige klaar is), maar is perfect voor snelle scripts en kleinschalige scraping. Combineer het met Beautiful Soup of lxml voor een klassieke scraping-workflow.
Belangrijkste kenmerken:
- Simpele, Python-achtige API voor HTTP-verzoeken
- Regelt cookies, sessies en redirects
- Integreert naadloos met parsing-bibliotheken
- Enorme community en documentatie
Ideaal voor: Simpele scripts, statische pagina’s en beginners die snel aan de slag willen.
Waarom Requests zo populair is
8. MechanicalSoup
 MechanicalSoup is een lichte bibliotheek die eenvoudige browserinteracties automatiseert—zoals formulieren invullen of door meerstaps-loginflows navigeren—zonder een volledige browser te starten. Het bouwt voort op
MechanicalSoup is een lichte bibliotheek die eenvoudige browserinteracties automatiseert—zoals formulieren invullen of door meerstaps-loginflows navigeren—zonder een volledige browser te starten. Het bouwt voort op requests en Beautiful Soup, waardoor het veel sneller en lichter is dan Selenium voor sites die weinig JavaScript gebruiken.
Moet je inloggen, formulieren versturen of door een paar pagina’s klikken (en is de site niet te dynamisch)? Dan is MechanicalSoup een mooie middenweg.
Belangrijkste kenmerken:
- Automatiseert formulieren en navigatie
- Gebouwd op Requests en Beautiful Soup
- Lichtgewicht en snel (geen browser-overhead)
- Eenvoudig te gebruiken voor matige interactiviteit
Ideaal voor: Sites met login of formulieren, simpele automatisering en iedereen die Selenium’s overhead wil vermijden.
9. Aiohttp
 Aiohttp is de asynchrone krachtpatser voor razendsnelle, gelijktijdige webverzoeken. Moet je honderden pagina’s snel scrapen? Met aiohttp kun je verzoeken parallel uitvoeren, waardoor de totale tijd flink daalt. In een benchmark duurde het scrapen van 50 pagina’s slechts 3 seconden met aiohttp, tegenover 16 seconden met synchrone requests (zie het snelheidsverschil).
Aiohttp is de asynchrone krachtpatser voor razendsnelle, gelijktijdige webverzoeken. Moet je honderden pagina’s snel scrapen? Met aiohttp kun je verzoeken parallel uitvoeren, waardoor de totale tijd flink daalt. In een benchmark duurde het scrapen van 50 pagina’s slechts 3 seconden met aiohttp, tegenover 16 seconden met synchrone requests (zie het snelheidsverschil).
Aiohttp vereist dat je async def-code schrijft en await gebruikt, maar de snelheidswinst is het waard voor grote projecten.
Belangrijkste kenmerken:
- Asynchrone HTTP client/server framework
- Ondersteunt sessies, cookies en HTTP/2
- Enorme snelheidswinst bij gelijktijdige verzoeken
- Integreert met async parsing-bibliotheken
Ideaal voor: Supersnelle, grootschalige scraping, API-harvesting en iedereen die comfortabel is met async-programmeren.
10. Twisted
 Twisted is de event-driven netwerkengine achter Scrapy. Het is geen scraping-bibliotheek op zich, maar gevorderde gebruikers kunnen Twisted direct inzetten voor het bouwen van eigen crawlers, het afhandelen van niet-HTTP-protocollen of het implementeren van hyper-gelijktijdige spiders.
Twisted is de event-driven netwerkengine achter Scrapy. Het is geen scraping-bibliotheek op zich, maar gevorderde gebruikers kunnen Twisted direct inzetten voor het bouwen van eigen crawlers, het afhandelen van niet-HTTP-protocollen of het implementeren van hyper-gelijktijdige spiders.
Twisted is krachtig, maar heeft een steile leercurve. Het is vooral geschikt voor zeer maatwerk scenario’s of als je frameworks vanaf nul wilt bouwen.
Belangrijkste kenmerken:
- Event-driven netwerken voor HTTP, WebSockets, SSH en meer
- Ondersteunt SSL, gelijktijdigheid en eigen protocollen
- Vormt de basis van Scrapy’s async-engine
- Zeer flexibel voor geavanceerde toepassingen
Ideaal voor: Eigen protocollen, bouwen van scraping-frameworks en gevorderde gebruikers die maximale controle willen.
11. Grab
 Grab is een alles-in-één scraping-toolkit die HTTP-verzoeken, parsing, automatisering, proxy-rotatie en CAPTCHA-afhandeling combineert. Het lijkt op Scrapy, maar is eenvoudiger te leren en te gebruiken, met ingebouwde ondersteuning voor proxies, caching en asynchrone spiders.
Grab is een alles-in-één scraping-toolkit die HTTP-verzoeken, parsing, automatisering, proxy-rotatie en CAPTCHA-afhandeling combineert. Het lijkt op Scrapy, maar is eenvoudiger te leren en te gebruiken, met ingebouwde ondersteuning voor proxies, caching en asynchrone spiders.
Het paradepaardje van Grab is het Grab:Spider-systeem, waarmee je duizenden verzoeken parallel kunt uitvoeren via multicurl. Zoek je een totaaloplossing met minder setup dan Scrapy, dan is Grab het proberen waard.
Belangrijkste kenmerken:
- Ingebouwde ondersteuning voor proxies, user-agent rotatie en caching
- Asynchroon spidersysteem voor hoge gelijktijdigheid
- XPath-parsing en modulaire architectuur
- Wordt in productie gebruikt voor grootschalige scraping
Ideaal voor: Alles-in-één scraping-projecten, proxy-intensieve taken en gebruikers die kracht willen zonder de complexiteit van Scrapy.
12. Urllib3
 Urllib3 is de low-level HTTP-engine die veel Python-clients aandrijft, waaronder Requests. Het biedt connection pooling, thread safety, retries en gedetailleerde controle over HTTP-verbindingen. De meeste ontwikkelaars gebruiken het indirect, maar urllib3 is je keuze als je maximale prestaties wilt of zelf hogere bibliotheken bouwt.
Urllib3 is de low-level HTTP-engine die veel Python-clients aandrijft, waaronder Requests. Het biedt connection pooling, thread safety, retries en gedetailleerde controle over HTTP-verbindingen. De meeste ontwikkelaars gebruiken het indirect, maar urllib3 is je keuze als je maximale prestaties wilt of zelf hogere bibliotheken bouwt.
Het is minder toegankelijk dan Requests, maar zeer betrouwbaar en uitvoerig getest.
Belangrijkste kenmerken:
- Connection pooling en thread safety
- Gedetailleerde controle over HTTP-verbindingen
- Vormt de basis voor veel andere bibliotheken
- Hoge prestaties bij herhaalde verzoeken
Ideaal voor: Eigen HTTP-clients, multi-threaded crawlers en ontwikkelaars die bouwen op de Python HTTP-stack.
De rol van urllib3 bij scraping
Vergelijkingstabel: Python Webscraping-pakketten in één Oogopslag
| Pakket | Gebruiksgemak | Prestaties | Dynamische Content | Parsing Kracht | Community/Docs | Ideaal voor |
|---|---|---|---|---|---|---|
| Thunderbit | ★★★★☆ (GUI/AI) | Snel (cloud/lokaal) | Ja (via AI) | Auto-velden, subpagina | Groeit (AI-trend) | Lead-gen, marktonderzoek, no-code gebruikers |
| Beautiful Soup | ★★★★★ (makkelijk) | Gemiddeld | Nee | HTML/XML, vergevingsgezind | Enorm | Statische pagina’s, beginners |
| Scrapy | ★★☆☆☆ (stijl) | ★★★★★ (zeer hoog) | Alleen plugins | CSS/XPath, pipelines | Groot, actief | Grootschalig, terugkerend scrapen |
| Selenium | ★★☆☆☆ (gemiddeld) | ★☆☆☆☆ (traag) | Ja (volledig) | Volledige DOM, JS | Volwassen | JS-rijke, interactieve sites |
| PyQuery | ★★★★☆ (jQuery) | Snel (lxml) | Nee* | jQuery-selectors | Gemiddeld | Prototyping, jQuery-ontwikkelaars |
| LXML | ★★★☆☆ (gevorderd) | ★★★★★ (snelst) | Nee | XPath/CSS, XML | Gemiddeld | Grote docs, geavanceerde queries |
| Requests | ★★★★★ (zeer makkelijk) | ★★☆☆☆ (sync) | Nee | HTTP, JSON | Massaal | Simpele scripts, statische pagina’s |
| MechanicalSoup | ★★★★☆ (makkelijk) | ★★☆☆☆ (sync) | Nee | Formulieren, navigatie | Klein | Loginflows, formulierautomatisering |
| Aiohttp | ★★☆☆☆ (async) | ★★★★★ (gelijktijdig) | Nee | Async HTTP | Groot (async) | Supersnel, gelijktijdig scrapen |
| Twisted | ★☆☆☆☆ (complex) | ★★★★★ (maatwerk) | Nee | Netwerken, protocollen | Niche | Eigen frameworks, gevorderde gebruikers |
| Grab | ★★★☆☆ (modulair) | ★★★★☆ (async) | Nee | Proxies, XPath | Klein | Alles-in-één, proxy/captcha intensief |
| Urllib3 | ★★★★☆ (low-level) | ★★★★☆ (gepoold) | Nee | HTTP, pooling | Massaal | Eigen clients, multi-threaded crawlers |
*PyQuery kan gecombineerd worden met Selenium voor dynamische sites.
Hoe Kies je het Juiste Python Webscraping-pakket voor Jouw Doel?
Wat is Data Scraping en Hoe Doe Je Het in 2026 Get Started Free
Dus, welk pakket kies je? Hier is mijn spiekbriefje:
- Statische pagina’s, kleine klussen of nieuw met scraping: Begin met Requests + Beautiful Soup.
- Grootschalig, terugkerend of productie-scraping: Scrapy of Grab (voor alles-in-één).
- JavaScript-rijke of interactieve sites: Selenium (of Thunderbit als je AI-gedreven, no-code scraping wilt).
- Supersnel, gelijktijdig scrapen: Aiohttp (als je vertrouwd bent met async).
- Formulierautomatisering of loginflows: MechanicalSoup (voor simpele sites), Selenium (voor complexe JS).
- Geavanceerd parsen of enorme documenten: LXML of PyQuery.
- Eigen netwerken of protocolwerk: Twisted.
- Snel prototypen, lead-gen of rommelige/ongestructureerde data: Thunderbit.
En wees niet bang om te combineren—veel workflows gebruiken meerdere tools voor maximale efficiëntie. Je kunt bijvoorbeeld Selenium gebruiken om een pagina te renderen en daarna de HTML parsen met Beautiful Soup of PyQuery.
Conclusie: Haal Meer uit Webscraping met de Juiste Python-tools
Webscraping in 2026 is krachtiger—en noodzakelijker—dan ooit. Met de juiste python webscraping-pakketten verander je de chaos van het web in bruikbare, gestructureerde data voor je bedrijf, onderzoek of volgende grote idee. Of je nu een ervaren ontwikkelaar bent of net begint met data, er staat een tool in deze lijst die bij je past.
Wil je zien hoe AI-gedreven, no-code scraping werkt? Probeer Thunderbit. En voor meer tips, diepgaande uitleg en tutorials, bezoek de Thunderbit Blog voor het laatste nieuws over webscraping, automatisering en dataworkflows.
Probeer Thunderbit AI-webscraper
Veel succes met scrapen—moge je selectors altijd matchen, je proxies nooit falen en je data net zo schoon zijn als je code.
Veelgestelde Vragen
1. Wat is het beste Python webscraping-pakket voor beginners?
Voor de meeste beginners is de combinatie van Requests en Beautiful Soup de makkelijkste manier om te starten. Beide hebben intuïtieve APIs, veel tutorials en zijn geschikt voor de meeste statische scraping-taken.
2. Hoe scrape ik JavaScript-rijke websites met Python?
Gebruik Selenium om een echte browser te automatiseren, of probeer Thunderbit voor AI-gedreven, no-code scraping die dynamische content aankan. Voor grootschalige projecten kun je Scrapy combineren met Splash of Selenium.
3. Welk pakket is het beste voor grootschalig, supersnel scrapen?
Scrapy is gemaakt voor grootschalig, asynchroon crawlen. Wil je nóg meer snelheid en ben je vertrouwd met async-code, dan is aiohttp een uitstekende keuze voor gelijktijdige verzoeken.
4. Kan ik deze pakketten combineren in mijn workflow?
Zeker! Veel ontwikkelaars gebruiken Requests of Selenium om pagina’s op te halen en parsen daarna met Beautiful Soup, lxml of PyQuery. De exports van Thunderbit kun je direct in Python-scripts gebruiken voor verdere analyse.
5. Is Thunderbit een Python-bibliotheek of een losstaande tool?
Thunderbit is een AI-gedreven Chrome-extensie en platform, geen traditionele Python-bibliotheek. De output (CSV, Excel, Sheets, Notion, Airtable) integreert echter naadloos in Python-datapijplijnen, waardoor het een krachtige aanvulling is voor Python-ontwikkelaars.
Altijd op de hoogte blijven van webscraping? Abonneer je op het Thunderbit YouTube-kanaal en houd de Thunderbit Blog in de gaten voor meer gidsen, vergelijkingen en automatiseringstips.
Probeer Thunderbit AI-webscraper gratis Get Started Free
Meer weten




