Facebook scrapen is in 2026 nog steeds de moeite waard, maar alleen als je het juiste verzamelmodel kiest. Pew Research Center meldde op 20 november 2025 dat , en Meta zei op 29 april 2026 dat zijn . Die schaal houdt Facebook relevant voor Marketplace-monitoring, onderzoek naar openbare pagina’s, leadgeneratie en het volgen van concurrenten. Het lastige is niet het vinden van use cases. Het lastige is schone data binnenhalen zonder vast te lopen op inlogschermen, dynamische content, tijdelijke blokkades of fragiele scraping-opzetten.
Deze jaarlijkse shortlist is gemaakt voor snelle besluitvorming. Op 8 mei 2026 heb ik de officiële productpagina’s, documentatie en prijssignalen opnieuw gecontroleerd en de lijst vervolgens beperkt tot tools die nog steeds logisch zijn voor echte zakelijke gebruikers. Als je workflow vooral is: “haal de data van deze pagina en stuur die naar een sheet”, begin dan met Thunderbit. Als je API-schaalinfrastructuur nodig hebt, horen Bright Data, Apify en Nimble van Nimbleway bovenaan de lijst. Als je werk cloud-automatisering of vervolgstappen na het verzamelen omvat, verdient PhantomBuster een nadere blik.
Snelle keuzes per taak
- Snelste no-code export van Facebook of Marketplace nodig? Begin met .
- Enterprise API-schaal en managed unblocking nodig? Zet op de shortlist.
- Flexibele cloud-scrapingworkflows nodig? Kijk goed naar .
- API-first openbare webverzameling met minder onderhoud aan scrapers nodig? Overweeg .
- Een budgetvriendelijke API voor lichtere taken nodig? is nog steeds relevant.
- Scraping plus workflow-automatisering nodig? past beter.
- Een point-and-click workflowbouwer met planning nodig? blijft een solide no-code-optie.
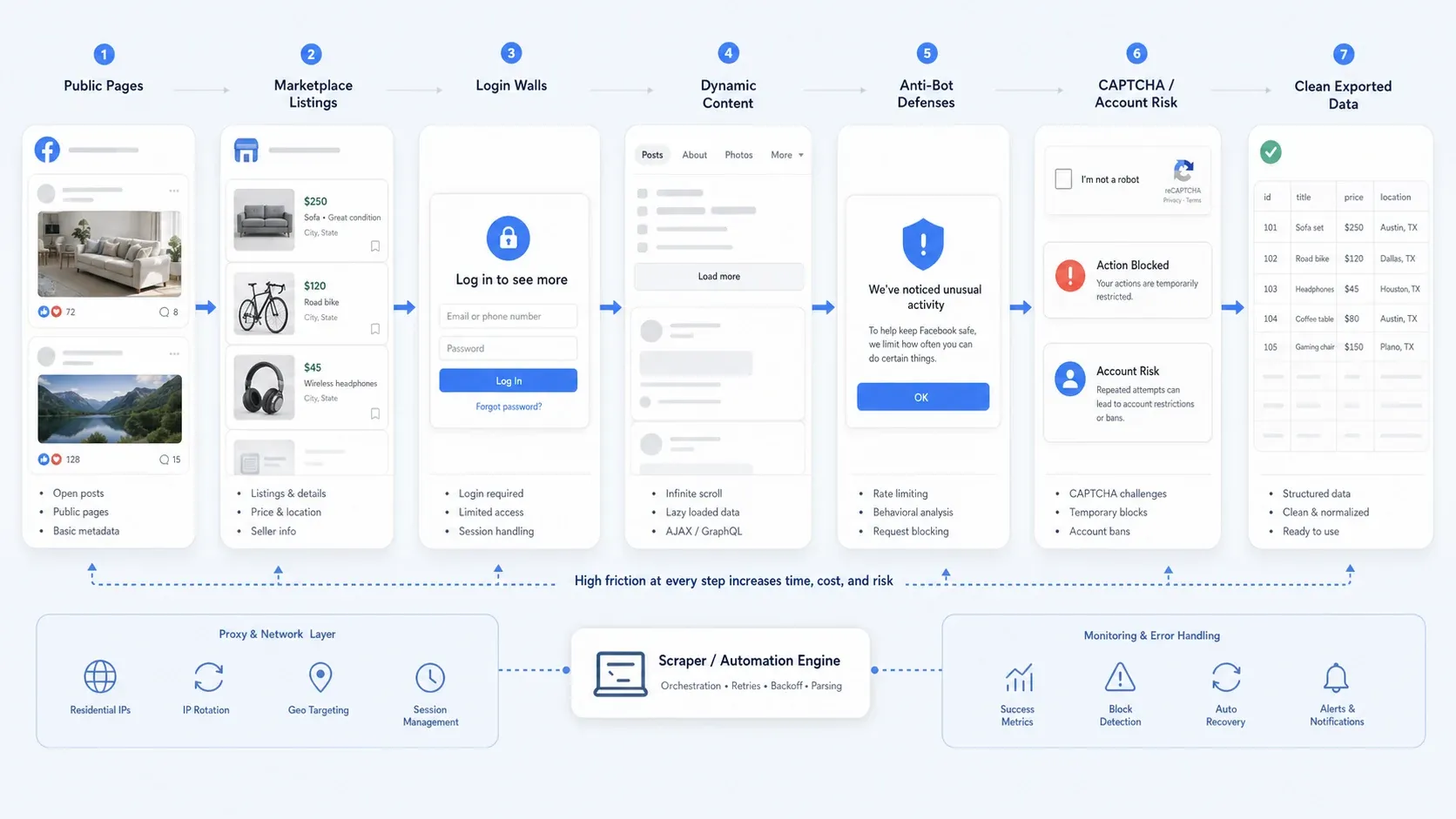
Waarom Facebook scrapen in 2026 nog steeds lastig is
Facebook-data verzamelen is tegenwoordig zelden nog alleen een selectorprobleem. In de praktijk lopen de meeste teams tegen een of meer van deze problemen aan:
- Gedeeltelijke openbare toegang: Sommige pagina’s blijven openbaar, terwijl andere stromen je naar inloggen sturen voor meer details.
- Dynamische content: Marketplace-weergaven, lange commentaardraden en pagina-inhoud laden vaak stapsgewijs.
- Anti-botmaatregelen: Rate limiting, gedragcontroles, CAPTCHA’s en tijdelijke actiebeschrijvingen breken simpele automatiseringen.
- Operationeel risico: Verzamelen met alleen een login is veel risicovoller dan scrapen van openbare pagina’s, vooral als accountveiligheid en herhaalbaarheid belangrijk zijn.
Hoe ik deze tools heb beoordeeld
Ik heb deze pagina geoptimaliseerd voor het samenstellen van een shortlist, niet voor extra feature-opvulling. De tools hier zijn vergeleken op:
- Workflowfit: Sluit het product echt aan op Facebook- en Marketplace-verzamelklussen die echte teams uitvoeren?
- Gebruiksgemak: Kunnen niet-ontwikkelaars of kleine teams snel bruikbare output krijgen?
- Schaal en betrouwbaarheid: Blijft de tool logisch zodra je verder gaat dan een eenmalige scrape?
- Anti-bot- en sessieafhandeling: Hoeveel infrastructuurgedoe neemt het product weg?
- Outputkwaliteit: Krijg je gestructureerde data naar CSV, Sheets of downstream-systemen zonder grote opschoning?
- Prijssignaal: Is het product praktisch te evalueren, of vraagt het om een zwaar enterprise-traject?
- Compliancehouding: Is de tool duidelijk gericht op verzameling van openbare data en verantwoord gebruik?
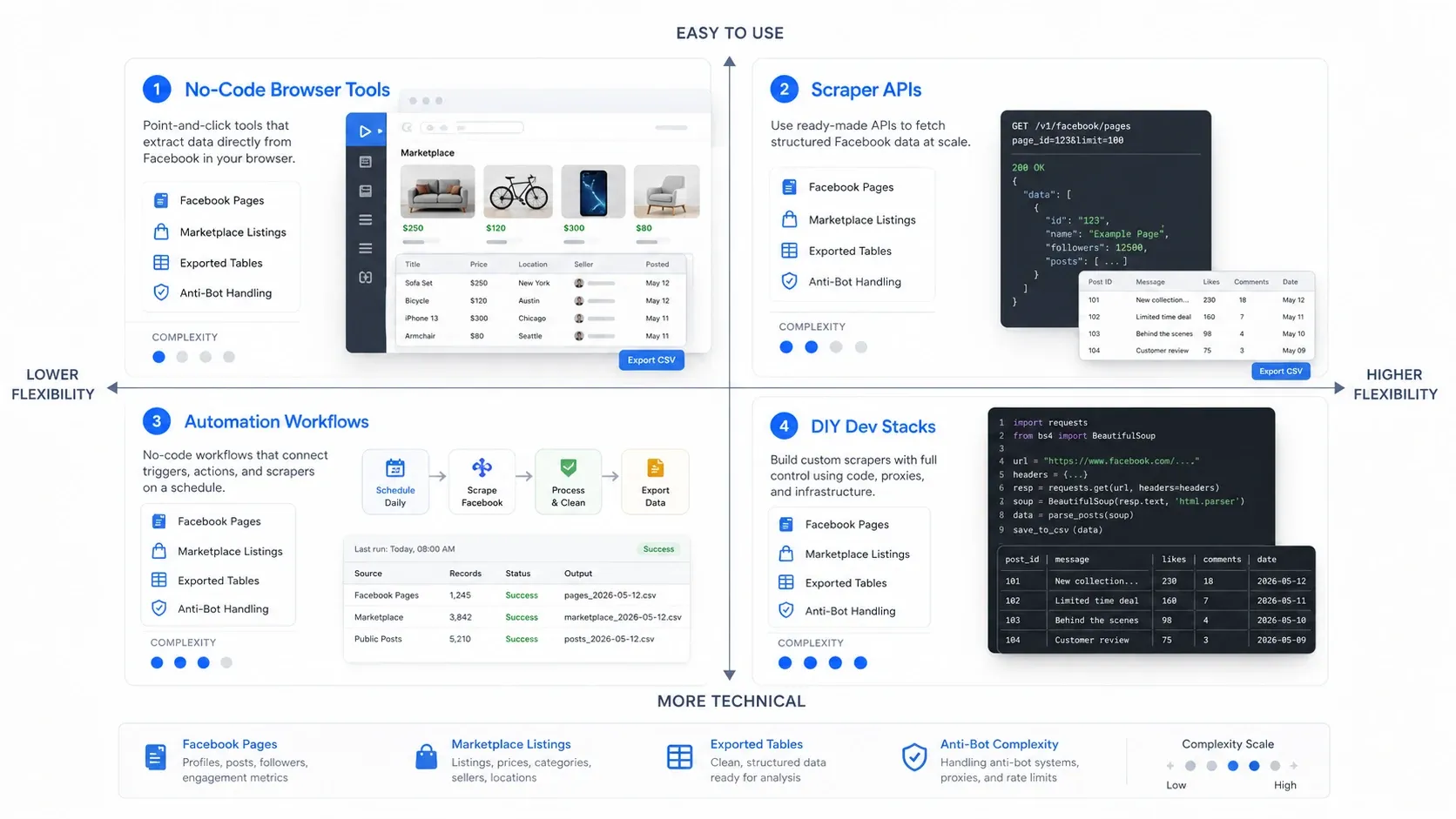
Welk type Facebook scraper heb je nodig?
De snelste manier om goed te kiezen, is eerst de juiste categorie kiezen. Facebook scraping-tools vallen meestal in vier werkmodellen uiteen:
- No-code browsertools: Beste keuze als je snel wilt extraheren van de pagina die al voor je openstaat.
- Scraper-API’s: Beste keuze als je betrouwbare, herhaalbare verzameling op grotere schaal nodig hebt.
- Automatiseringsworkflows: Beste keuze als scrapen slechts één stap is in een breder go-to-marketproces.
- DIY-devstacks: Beste keuze als je team maximale controle wil en bereid is het onderhoud zelf te dragen.
Vergelijkingstabel
| Tool | Het beste voor | Waarom het op de shortlist staat | Prijssignaal |
|---|---|---|---|
| Thunderbit | Niet-technische teams en snelle ad-hoc taken | AI-veldherkenning, dynamische pagina-afhandeling in de browser, snelle exports | Gratis proefperiode; betaalde abonnementen op basis van credits |
| Bright Data | Grootschalige publieke socialmediadata-pijplijnen | Specifieke scraper-API’s voor social media, managed unblocking, sterke schaalbaarheid | Prijs op basis van gebruik en enterprise pricing |
| Apify | Flexibele cloud-scrapingworkflows | Kant-en-klare Facebook-actors, planning, API-toegang, ruimte voor maatwerk | Betaalde platformabonnementen plus gebruiksafrekening |
| Nimble by Nimbleway | API-first openbare webverzameling | URL-first API-flow en minder onderhoud aan scrapers | Verkoopgestuurde pricing |
| ScrapingBot | Kleine openbare-datataken en prototypes | Simpele API, ondersteuning voor rendering, lagere instapprijs | Gratis tier; betaalde abonnementen vanaf ongeveer $22/maand |
| PhantomBuster | GTM-automatiseringsworkflows | Cloud-automatisering, browseractie-workflows, geschikt voor leadgeneratie | Gratis proefperiode; betaalde abonnementen vanaf ongeveer $56/maand |
| Octoparse | Visueel no-code scrapen met planning | Point-and-click bouwer, cloud-extractie, herhaalbare workflows | Gratis plan; betaalde abonnementen vanaf ongeveer $119/maand |
1. Thunderbit
is hier de sterkste keuze als je een Facebookpagina of Marketplace-resultatenlijst snel wilt omzetten in gestructureerde data zonder een scraper te bouwen of te onderhouden. Het belangrijkste voordeel is semantische extractie: de tool leest de pagina, stelt nuttige velden voor en laat je het resultaat exporteren zonder selectorwerk, proxies of code.
Waarom het eruit springt:
- AI Suggest Fields: Thunderbit herkent waarschijnlijk relevante velden zoals titel, prijs, verkoper, locatie, contactgegevens en URL’s.
- Browser-native afhandeling: Omdat het draait waar de pagina wordt weergegeven, werkt het goed op dynamische, scroll-intensieve pagina’s.
- Subpagina-verrijking: Je kunt eerst lijstdata verzamelen en vervolgens elke vermelding of pagina openen voor meer detail.
- Handige exports: Excel, Google Sheets, Airtable en Notion zijn allemaal natuurlijke eindbestemmingen.
Als je eerst één video wilt bekijken voordat je zelf een browser-native workflow test, is deze praktische Thunderbit-uitleg de beste plek om te beginnen, omdat die het echte extractieproces laat zien in plaats van alleen op functieniveau te blijven:
Beste voor: niet-technische gebruikers, salesteams, operators en onderzoekers die snel resultaat willen.
Prijssignaal: Gratis proefperiode beschikbaar; betaalde abonnementen zijn credit-based. Bekijk de .
2. Bright Data
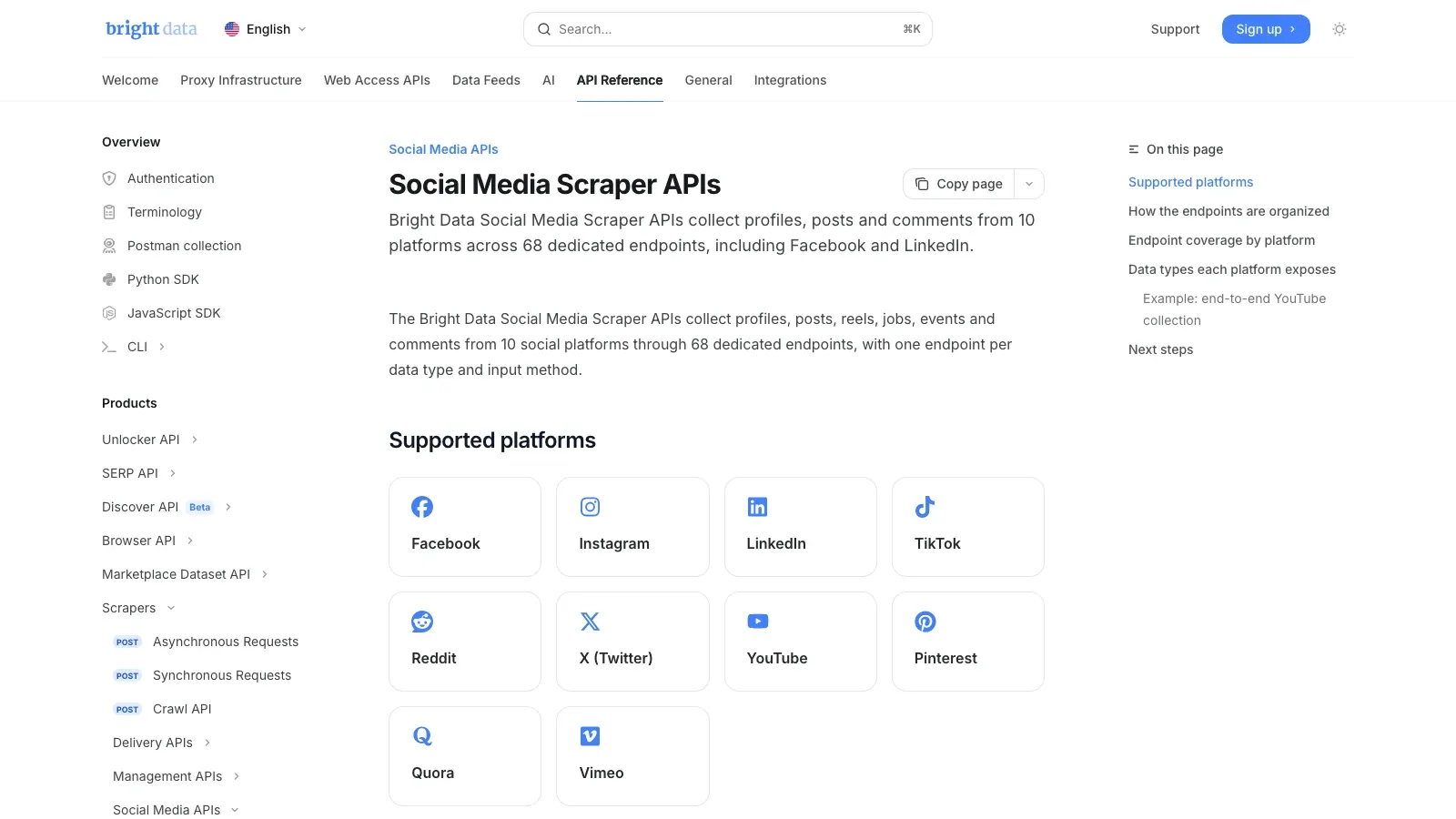
is de infrastructuur-eerst keuze. In de eigen documentatie zegt Bright Data dat de 10 platforms en 68 specifieke endpoints dekken, waaronder Facebook. Als je taak grootschalige openbare dataverzameling is, is zo’n managed API-stack meestal realistischer dan proberen een browserextensie of handgemaakte scraper op te schalen.
Waarom het op de shortlist staat:
- Toegewijde scraping-endpoints voor social media
- Managed unblocking en extractie
- Gestructureerde outputlevering voor datapijplijnen
- Beter geschikt voor monitoring- en analysetaken waar betrouwbaarheid cruciaal is
Beste voor: analisten, datateams, grote monitoringprojecten en openbare socialdatastromen op schaal.
Prijssignaal: Prijzen variëren per product en volume. Controleer de .
3. Apify
blijft relevant omdat het een sterke middenweg biedt tussen templates en volledige maatwerkoplossingen. De Facebook Pages Scraper-actor is een handig startpunt, terwijl het bredere Apify-platform cloud-runs, planning, API’s en ruimte biedt om de workflow uit te breiden als je behoeften complexer worden.
Waarom het op de lijst staat:
- Kant-en-klare Facebook-actors
- Cloud-uitvoering en terugkerende planningen
- Flexibele exports en API-toegang
- Makkelijker uit te breiden dan een pure no-code browserworkflow
Beste voor: technische marketeers, bureaus, operationele teams en terugkerende verzamelklussen over meerdere sites.
Prijssignaal: Platformabonnementen zijn betaald en actorgebruik wordt apart afgerekend. Bekijk de .
4. Nimble by Nimbleway
is de API-first optie voor teams die een URL willen doorgeven en het platform toegang, rendering en levering laten afhandelen. Nimble positioneert zijn als end-to-end verzameling van openbare webdata, wat het nuttig maakt wanneer Facebook scrapen slechts één onderdeel is van een bredere datastack.
Waarom het de moeite waard is om te evalueren:
- URL-first API-workflow
- Minder onderhoud aan scrapers voor engineeringteams
- Goede fit voor robuuste extractie van openbare webdata
- Handig wanneer gescrapete data interne producten of dashboards voedt
Beste voor: engineeringgedreven teams, productdatapijplijnen en organisaties die infrastructuurabstractie willen in plaats van losse puntoplossingen.
Prijssignaal: Nimble benadrukt geen openbare self-serviceprijzen op de kern-API-pagina’s, dus reken op verkoopgestuurde pricing en verifieer dit rechtstreeks bij .
5. ScrapingBot
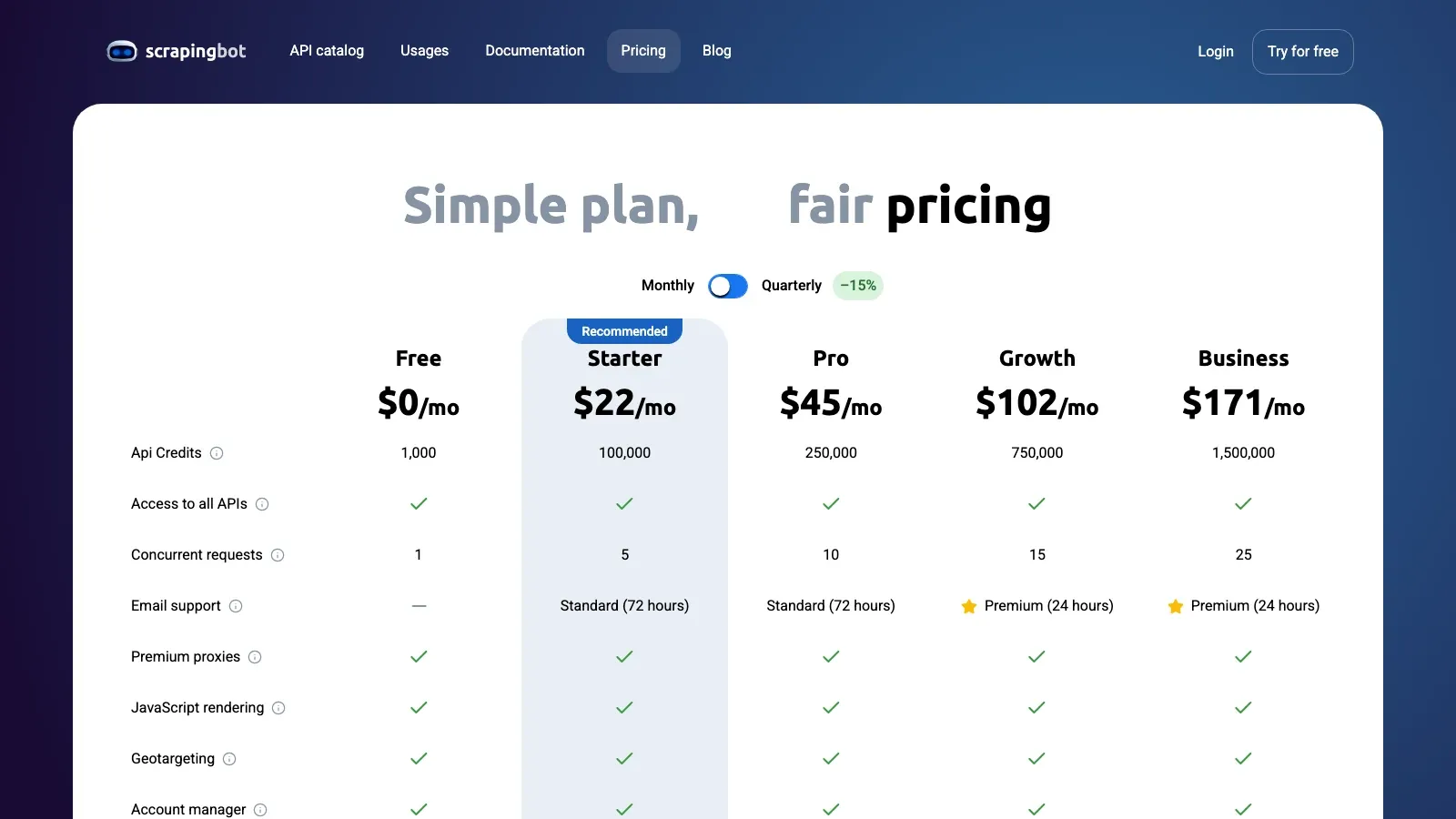
is de budgetbewuste API-optie in deze lijst. Het is hier niet het meest gespecialiseerde Facebook-platform, maar het is nog steeds logisch voor kleinere openbare-datataken waarbij je een API, rendering-ondersteuning en een lager kostenminimum wilt dan enterprise scraping-infrastructuur.
Waar het past:
- Eenvoudig API-gedreven openbaar scrapen
- Lagere instapprijs
- Rendering en proxy-afhandeling inbegrepen
- Beter voor prototypes en lichte terugkerende pulls dan voor grote intelligence-programma’s
Beste voor: startups, mkb’s en ontwikkelaars die lichtere use cases voor openbare pagina’s testen.
Prijssignaal: Gratis tier beschikbaar; de huidige openbare prijspagina start betaalde abonnementen vanaf ongeveer .
6. PhantomBuster
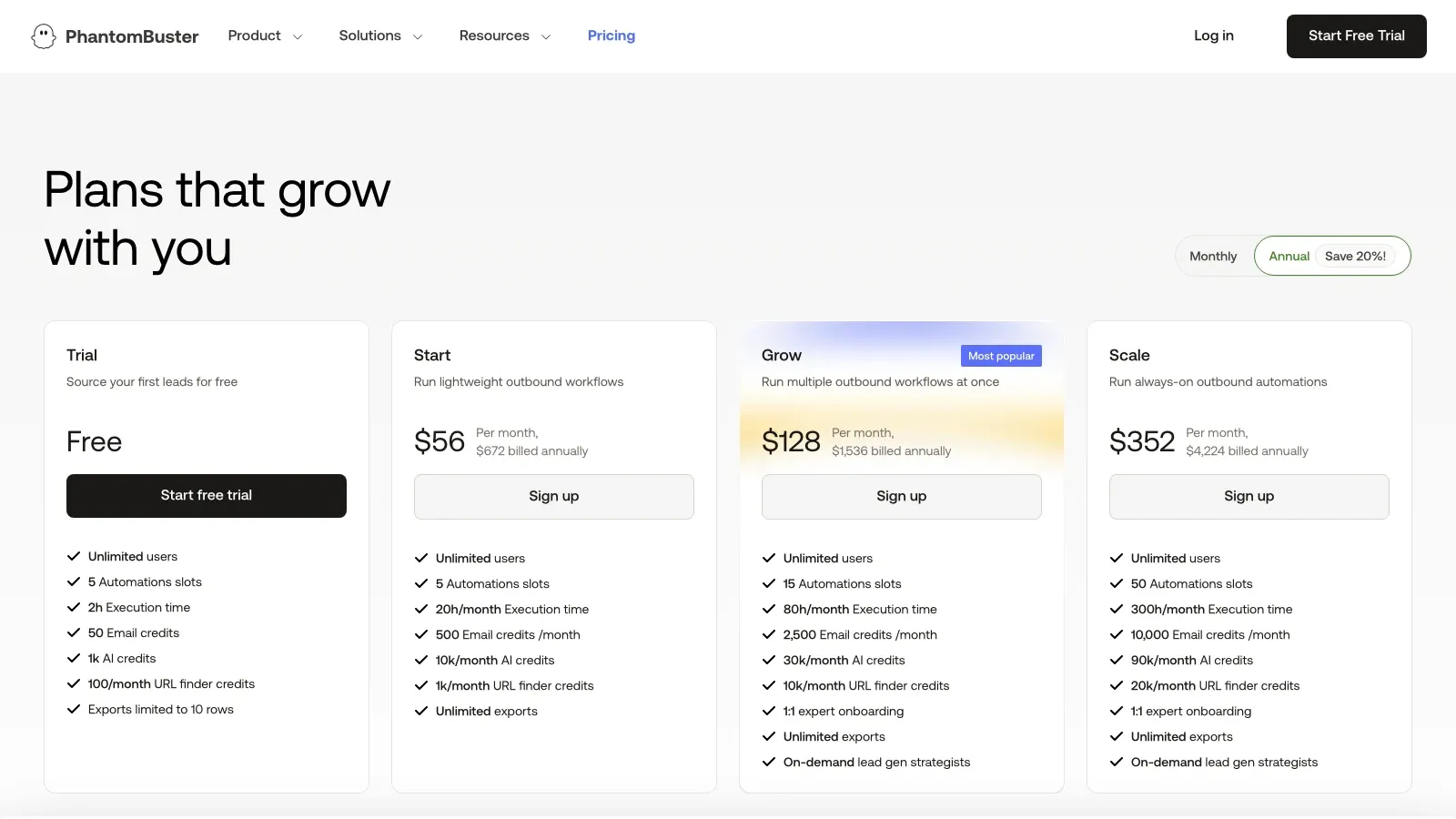
draait minder om ruwe scraping-infrastructuur en meer om wat er na het verzamelen gebeurt. Als je use case is: “verzamel de data en trigger daarna outreach, verrijking of vervolgstappen”, dan is PhantomBuster vaak nuttiger dan een simpele extractor, omdat het is ontworpen rond cloud-automatisering en browseractie-workflows.
Waarom teams het nog steeds shortlistten:
- Cloudgebaseerde automatiseringsworkflows
- Handig voor leadgeneratie en GTM-operaties
- Sterkere fit wanneer scrapen één stap is in een breder proces
- Praktisch voor operators die om acties geven, niet alleen om exports
Beste voor: GTM-teams, growth-teams, recruiters en operators die verzameling koppelen aan vervolgstappen.
Prijssignaal: Gratis proefperiode beschikbaar; betaalde abonnementen op de huidige prijspagina beginnen bij ongeveer .
7. Octoparse
blijft een van de betere visuele no-code scrapingtools voor gebruikers die herhaalbare workflows en geplande cloud-runs willen. Het is niet zo lichtgewicht als Thunderbit voor snelle eenmalige Facebook-taken, maar het geeft niet-ontwikkelaars meer expliciete controle over hoe de extractielogica wordt opgebouwd en herhaald.
Waarom het relevant blijft:
- Visuele point-and-click workflowbouwer
- Cloud-extractie en planning
- Goed voor gestructureerde terugkerende taken
- Beter geschikt voor analisten die herhaalbaarheid willen zonder code
Beste voor: niet-technische analisten, operationele mkb-teams en herhaalbare verzamelklussen met explicietere workflowlogica.
Prijssignaal: De openbare prijspagina van Octoparse vermeldt betaalde abonnementen vanaf ongeveer .
Shortlist per team
Als je al weet welk team de workflow gaat beheren, begin hier:
- Solo-operator of klein bedrijf: Thunderbit, ScrapingBot of Octoparse
- Sales / GTM-team: Thunderbit of PhantomBuster
- Ops-analist: Thunderbit, Apify of Octoparse
- Growth-automatiseringsteam: PhantomBuster of Apify
- Data-engineeringteam: Bright Data, Nimble of Apify

Hoe kies je de juiste Facebook scraper
- Kies Thunderbit als snelheid en eenvoud belangrijker zijn dan maximale schaal.
- Kies Bright Data als je schaal voor openbare data en managed betrouwbaarheid nodig hebt.
- Kies Apify als je platformflexibiliteit en actor-gebaseerde workflows wilt.
- Kies Nimble als je een API-first abstractielaag wilt met minder onderhoud aan scrapers.
- Kies PhantomBuster als scrapen slechts één stap is in een bredere GTM-automatiseringsworkflow.
- Kies Octoparse als je visuele herhaalbaarheid zonder code wilt.
- Kies ScrapingBot als budget belangrijk is en de taak relatief eenvoudig is.
Eindconclusie
De marktverdeling is in 2026 duidelijker dan een jaar geleden. Je kiest eigenlijk niet één universele “beste Facebook scraper”. Je kiest een verzamelmodel: snelle no-code extractie, managed API-schaal, cloud-automatisering of praktische visuele workflowcontrole. Begin daar, en de shortlist wordt meteen veel eenvoudiger.
Als je team de snelste route wil van een Facebookpagina of Marketplace-vermelding naar bruikbare gestructureerde data, blijft Thunderbit de makkelijkste plek om te beginnen. Als je volume of technische eisen veel zwaarder zijn, hebben Bright Data, Apify en Nimble meer zin. Als je workflow begint met scrapen maar eindigt met vervolgstappen, is PhantomBuster de slimmere shortlist.
FAQs
1. Wat is de makkelijkste Facebook scraping-tool voor niet-technische gebruikers?
Thunderbit is voor de meeste niet-technische gebruikers het makkelijkste startpunt, omdat het in de browser werkt, automatisch velden suggereert en data snel exporteert zonder code.
2. Welke Facebook scraping-tool is het beste voor grootschalige openbare dataverzameling?
Bright Data is in deze lijst de sterkste infrastructuurkeuze wanneer de taak grootschalige verzameling van openbare social data is en betrouwbaarheid belangrijker is dan gebruiksgemak.
3. Wat als ik scraping plus vervolgstappen-automatisering nodig heb?
PhantomBuster past beter wanneer dataverzameling slechts één stap is in een bredere leadgeneratie- of GTM-workflow.
4. Is Facebook scrapen in 2026 nog steeds moeilijk?
Ja. Dynamische content, inlogschermen, rate limits, anti-botsystemen en accountrisico maken Facebook nog steeds lastiger dan het scrapen van eenvoudigere openbare websites.
5. Hoe moeten teams omgaan met compliance?
Blijf gericht op openbare data, gebruik redelijke snelheden, vermijd misbruik van inloggegevens en bekijk de platformvoorwaarden en toepasselijke privacyregels voordat je een workflow opschaalt.
Verder lezen: