

Laat me je even meenemen naar de eerste keer dat ik productgegevens van een ecommerce-site probeerde te scrapen. Ik had Python klaarstaan, een kop koffie erbij en een droom: een prijstracker voor Amazon bouwen. Een paar uur later was mijn “snelle project” veranderd in een wirwar van XPath-selectors, gedoe met paginering en meer debugwerk dan ik wil toegeven. Als je ooit webdata met code hebt proberen te temmen, ken je dat gevoel waarschijnlijk wel: evenveel enthousiasme als “waarom is dit zó ingewikkeld?”
Het punt is: webscraping is allang niet meer alleen iets voor data scientists of engineers. Het is een onmisbare vaardigheid geworden voor salesteams, e-commerce managers, marketeers en iedereen die de chaos van het web wil omzetten in business intelligence. Sterker nog, de markt voor webscrapingsoftware bereikte $1,01 miljard in 2024 en zal naar verwachting $2,49 miljard in 2032 bereiken, en die curve vlakt voorlopig nog niet af. Maar hoewel Python en frameworks zoals Scrapy nog steeds de gouden standaard zijn voor grootschalige, maatwerk-scraping, zijn ze niet bepaald beginnersvriendelijk. Daarom neem ik je in deze tutorial stap voor stap mee door Scrapy — met een echte Amazon-usecase — en laat ik je een veel eenvoudiger, AI-gedreven alternatief zien voor niet-codeurs: Thunderbit.
Wat is Scrapy Python? Je krachtige tool voor webscraping
Laten we bij de basis beginnen. Scrapy is een open-source Python-framework dat speciaal is gebouwd voor webcrawling en webscraping. Zie het als je alles-in-één toolkit voor het bouwen van maatwerkspiders (zo noemt Scrapy zijn crawlers) die websites kunnen doorlopen, links kunnen volgen, paginering kunnen verwerken en gestructureerde data op schaal kunnen extraheren.
Hoe verschilt Scrapy van alleen Python’s requests en BeautifulSoup gebruiken? Nou, die libraries zijn prima voor eenvoudige, eenmalige scrapes, maar Scrapy is ontworpen voor grote, complexe projecten — het soort waarbij je:
- Duizenden pagina’s moet crawlen (denk: elk product in een e-commercecatalogus)
- Automatisch links moet volgen en paginering moet afhandelen
- Data asynchroon moet verwerken voor snelheid
- Data op een herhaalbare manier moet structureren, opschonen en exporteren
Kortom, Scrapy is als het Zwitserse zakmes voor webscraping: krachtig, flexibel en, hoe je het ook wendt of keert, voor beginners een beetje intimiderend.
Waarom Scrapy Python gebruiken voor webscraping?
Waarom grijpen ontwikkelaars en datateams steeds weer naar Scrapy? Hier is een korte samenvatting van wat het onderscheidt:
| Toepassing | Sterke punten van Scrapy | Bedrijfswaarde |
|---|---|---|
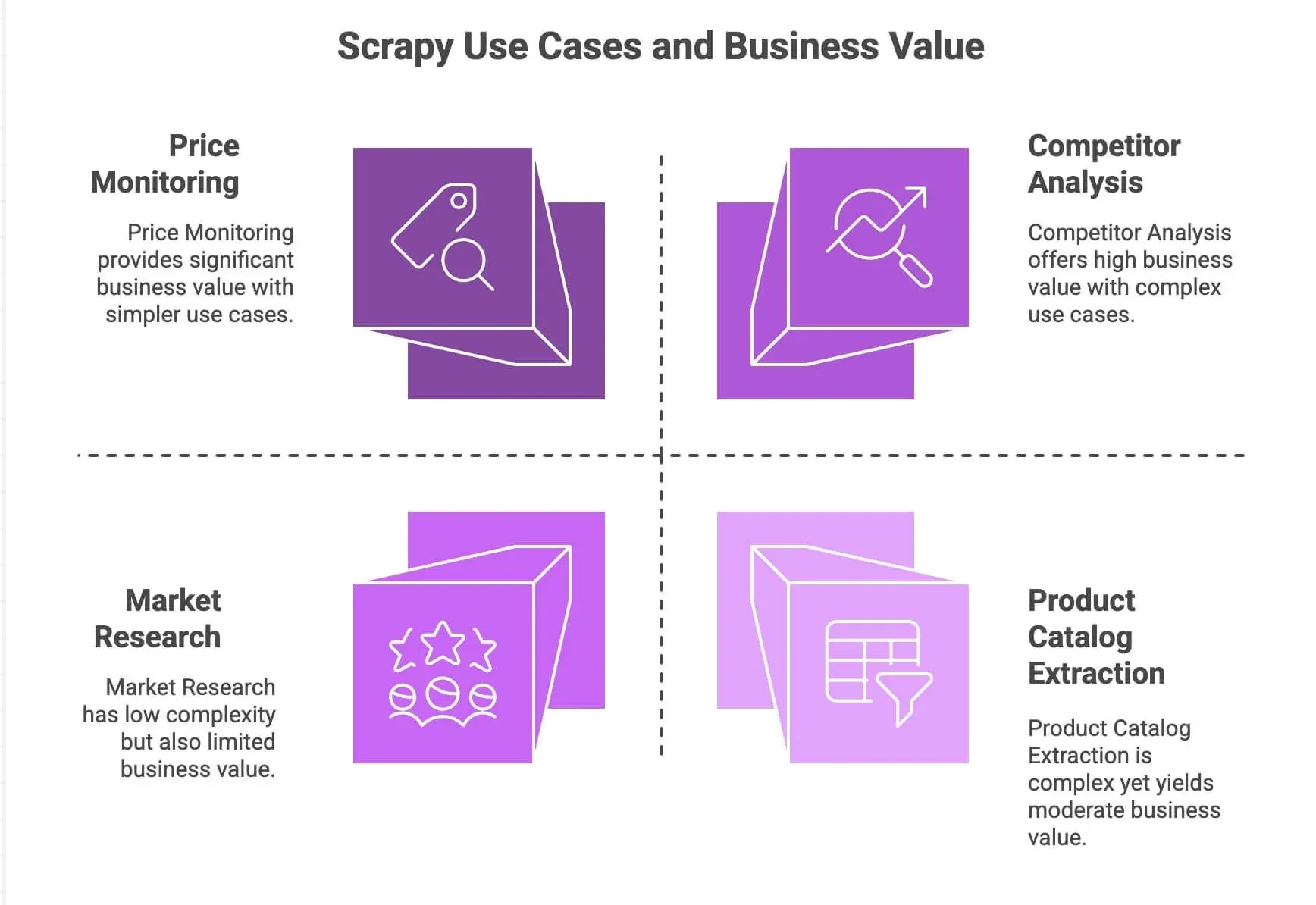
| Prijsmonitoring | Verwerkt paginering, asynchrone requests, planning | Blijf concurrenten voor, dynamische prijsstelling |
| Extractie van productcatalogi | Volgt links, extraheert gestructureerde data | Bouw productdatabases, voed analytics |
| Concurrentieanalyse | Schaalbaar, robuust bij sitewijzigingen | Volg trends, nieuwe lanceringen, voorraadniveaus |
| Marktonderzoek | Modulaire pipelines voor opschonen/transformeren van data | Bundel reviews, voer sentimentanalyse uit |
Scrapy’s asynchrone engine (gebouwd op Twisted) zorgt ervoor dat het meerdere pagina’s parallel kan ophalen, waardoor het snel en schaalbaar is. Het modulaire ontwerp laat je eigen logica inpluggen, zoals proxies, user-agents of stappen voor datacleaning. En met pipelines kun je data verwerken, valideren en exporteren zoals jij wilt — CSV, JSON, databases, noem maar op.
Voor teams met Python-ervaring is Scrapy een krachtpatser. Maar laten we eerlijk zijn: het is niet bepaald “plug-and-play” voor de gemiddelde zakelijke gebruiker.
Je Scrapy Python-omgeving instellen
Klaar om de handen uit de mouwen te steken? Zo zet je Scrapy helemaal vanaf nul op:
1. Scrapy installeren
Zorg eerst dat je Python 3.10+ hebt geïnstalleerd (Scrapy 2.15.x stopte in 2026 met ondersteuning voor 3.9). Open daarna je terminal en voer uit:
pip install scrapy
Controleer je installatie met:
scrapy version
Als je op Windows werkt of Anaconda gebruikt, is het slim om een virtuele omgeving in te stellen om conflicten te voorkomen. Scrapy werkt op Windows, macOS en Linux.
2. Een nieuw Scrapy-project maken
Laten we een nieuw project starten met de naam amazonscraper:
scrapy startproject amazonscraper
Je krijgt dan een mappenstructuur zoals deze:
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
Wat doen deze bestanden?
scrapy.cfg: projectconfiguratie (hier kom je zelden aan)items.py: definieer je datamodellen (zoals een Product met naam, prijs, enz.)pipelines.py: hier opschoon, valideer en exporteer je je datamiddlewares.py: geavanceerdere zaken (proxies, custom headers)settings.py: pas het gedrag van Scrapy aan (concurrency, vertragingen, enz.)spiders/: hier leeft je echte scrapinglogica
Als je je nu al een beetje overweldigd voelt, ben je niet de enige. Dit is het punt waarop veel niet-codeurs beginnen te zweten.
Een Python-webscraper bouwen: Amazon-productdata scrapen met Scrapy
Laten we een echt voorbeeld doornemen: productdata scrapen uit de zoekresultaten van Amazon. (Let op: de gebruiksvoorwaarden van Amazon staan scraping niet toe, en ze zijn streng met anti-botmaatregelen. Dit is alleen voor educatieve doeleinden!)
1. Een spider maken
Maak in de map spiders/ een bestand aan met de naam amazon_spider.py:
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
Wat gebeurt hier?
- We beginnen op een Amazon-zoekresultatenpagina voor “smartphones”.
- Voor elk product extraheren we de naam, prijs en beoordeling met XPath-selectors.
- We zoeken naar de link “volgende pagina” en laten Scrapy die volgen, zodat het meer producten kan scrapen.
2. Je spider draaien
Voer vanuit de hoofdmap van je project uit:
scrapy crawl amazon_example -o products.json
Klaar — Scrapy doorloopt de zoekresultaten, volgt de paginering en slaat je data op in een JSON-bestand.
Paginering en dynamische content afhandelen
De ingebouwde ondersteuning van Scrapy voor het volgen van links en verwerken van paginering is een van zijn superkrachten. Maar hoe zit het met dynamische content — pagina’s die data laden met JavaScript? Standaard ziet Scrapy alleen statische HTML. Als je content wilt scrapen die door JavaScript wordt geladen (zoals infinite scroll of pop-upreviews), moet je Scrapy koppelen aan tools zoals Selenium of Splash. Dat is weer een heel ander konijnenhol.
Data verwerken en exporteren met Scrapy Python
Zodra je je data hebt gescraped, wil je die waarschijnlijk opschonen en ergens nuttigs naartoe exporteren.
- Pipelines: In
pipelines.pykun je Python-klassen schrijven om je data op te schonen, te valideren of te verrijken (zoals prijzen omzetten naar getallen, onvolledige rijen verwijderen of zelfs een vertaal-API aanroepen). - Exporteren: Scrapy kan rechtstreeks exporteren naar CSV, JSON of XML met de
o-flag. Voor geavanceerdere exports (zoals naar Google Sheets pushen) moet je extra code schrijven of externe libraries gebruiken.
Wil je sentimentanalyse doen of productbeschrijvingen vertalen? Dan moet je externe API’s of Python-libraries koppelen — niets daarvan zit standaard ingebouwd.
De verborgen kosten: uitdagingen van Scrapy Python voor zakelijke gebruikers
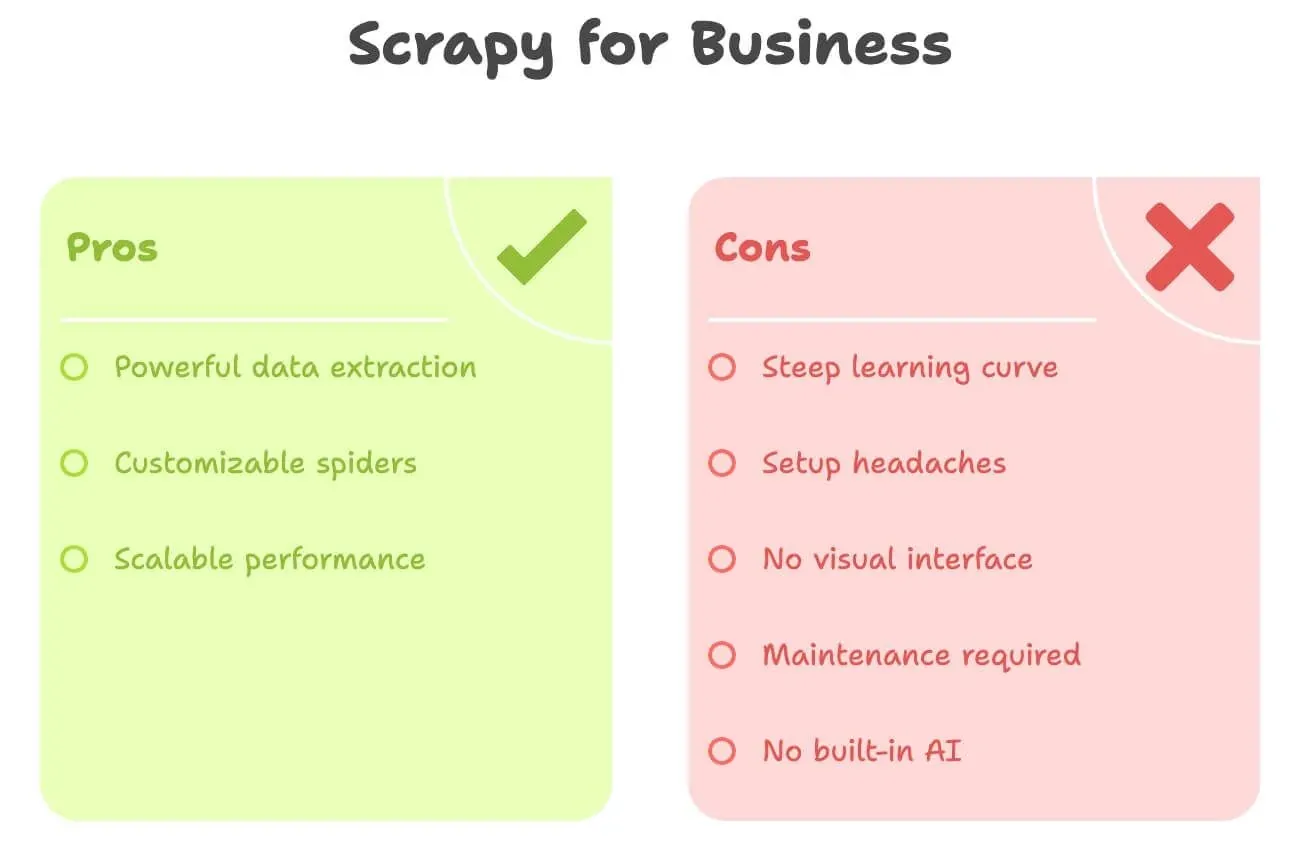
Laten we eerlijk zijn: Scrapy is krachtig, maar voor niet-ontwikkelaars niet bepaald gebruiksvriendelijk. Hier is waar de meeste zakelijke gebruikers op vastlopen:
- Steile leercurve: Je moet Python, HTML, XPath/CSS-selectors en de projectstructuur van Scrapy kennen. Het kan dagen of zelfs weken duren voordat je je er comfortabel mee voelt.
- Installatiehoofdpijn: Python installeren, afhankelijkheden beheren en fouten oplossen kan lastig zijn — zeker op Windows.
- Geen visuele interface: Alles is code. Je kunt niet zomaar op een pagina klikken om data te selecteren.
- Onderhoud: Als de website verandert, breekt je spider. Jij moet het oplossen.
- Geen ingebouwde AI: Wil je vertalen, samenvatten of sentiment analyseren? Dan is dat allemaal extra code.
Hier is een snelle vergelijking:
| Uitdaging | Scrapy (Python) | Behoefte van zakelijke gebruiker |
|---|---|---|
| Coderen vereist | Ja | Liever geen code |
| Insteltijd | Uren (of dagen) | Minuten |
| Onderhoud | Doorlopend (sitewijzigingen) | Minimaal |
| Data-export | CSV/JSON (handmatige koppeling) | Rechtstreeks naar Excel/Sheets/Notion |
| AI-functies | Geen (zelf koppelen) | Ingebouwde vertaling/sentimentanalyse |
Als je een solo marketeer, salesmedewerker of operations manager bent, kan Scrapy voelen als een bazooka meenemen naar een waterballonnengevecht.
Maak kennis met Thunderbit: het no-code alternatief voor Scrapy Python
Hier komt Thunderbit in beeld. Als iemand die jarenlang automationtools heeft gebouwd, kan ik je dit vertellen: de meeste zakelijke gebruikers willen niet coderen — ze willen gewoon snel data.
Thunderbit is een AI-webscraper als Chrome-extensie. Hij is gemaakt voor niet-technische gebruikers die willen:
- In een paar klikken data van elke website scrapen
- In gewone taal beschrijven wat ze willen (“Productnaam, prijs, beoordeling”)
- Paginering en subpagina’s automatisch laten verwerken
- Data direct exporteren naar Excel, Google Sheets, Airtable of Notion
- Vertalen, samenvatten of sentiment analyseren terwijl je werkt
Geen Python. Geen selectors. Geen onderhoudsproblemen.
Hoe je met AI elke website kunt scrapen Get Started Free
Thunderbit is ontworpen voor zakelijke gebruikers die snel willen schakelen en AI het zware werk willen laten doen.
Thunderbit versus Scrapy Python: vergelijking naast elkaar
Laten we ze tegenover elkaar zetten:
| Aspect | Scrapy (Python) | Thunderbit (AI-tool) |
|---|---|---|
| Vereiste vaardigheid | Python, HTML, selectors | Geen — point-and-click, natuurlijke taal |
| Insteltijd | Uren (installeren, coderen, debuggen) | Minuten (Chrome-extensie installeren, inloggen) |
| Datastructurering | Handmatig (items, pipelines definiëren) | AI detecteert automatisch kolommen en stelt velden voor |
| Paginering/subpagina’s | Code vereist | 1 klik (AI regelt het) |
| Vertaling | Aangepaste code of API-koppeling | Ingebouwd — zet gewoon “Vertalen” aan |
| Sentimentanalyse | Externe library/API | Ingebouwd — voeg een kolom “Sentiment” toe |
| Exportopties | CSV/JSON (handmatig importeren in Sheets/Excel) | 1 klik exporteren naar Excel, Google Sheets, Airtable, Notion |
| Onderhoud | Handmatig (code bijwerken als de site verandert) | AI past zich automatisch aan kleine sitewijzigingen aan |
| Schaal | Het best voor grote, doorlopende projecten | Het best voor snelle taken, middelgrote schaal (honderden/duizenden rijen) |
| Kosten | Gratis (maar kost tijd/ontwikkelresources) | Gratis tier + betaalde abonnementen (vanaf $9/maand, maar bespaart enorm veel tijd en gedoe) |
Wanneer kies je Scrapy Python versus Thunderbit voor webscraping?
Mijn vuistregel is als volgt:
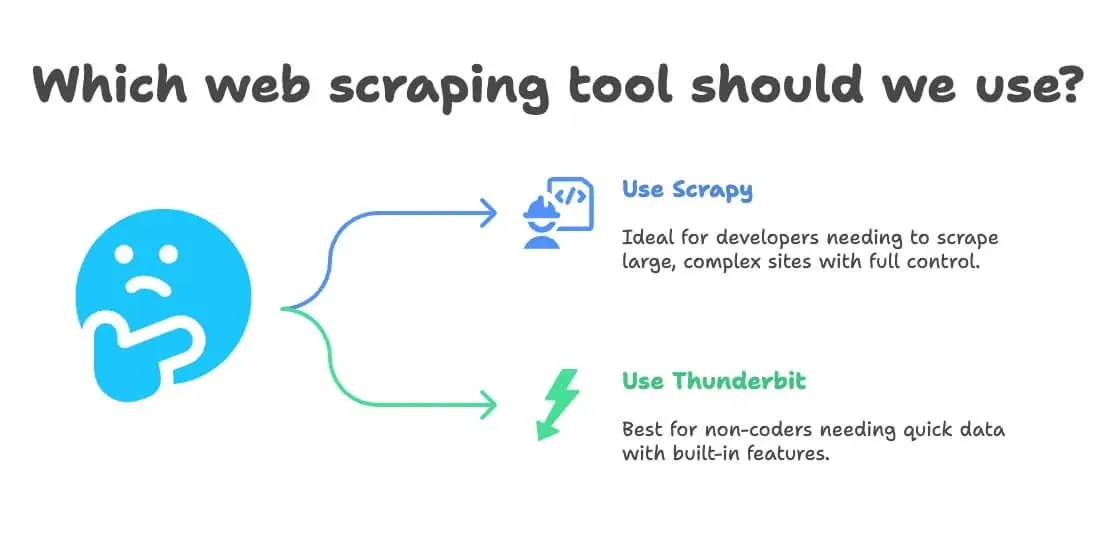
- Gebruik Scrapy als:
- Je een ontwikkelaar bent, of er een in je team hebt
- Je tienduizenden pagina’s moet scrapen, of een maatwerk-pipeline voor de lange termijn moet bouwen
- De site erg complex is of geavanceerde logica vereist
- Je volledige controle wilt (en onderhoud geen probleem vindt)
- Gebruik Thunderbit als:
- Je niet codeert (of dat niet wilt)
- Je snel data nodig hebt, voor een eenmalige of terugkerende zakelijke taak
- Je ingebouwde vertaling, sentiment of dataverrijking wilt
- Je snelheid en flexibiliteit belangrijker vindt dan maximale maatwerkopties
Hier is een snelle beslisboom:
- Kun je in Python coderen?
- Ja → Scrapy of Thunderbit (voor snelle winst)
- Nee → Thunderbit
- Is je project enorm en doorlopend?
- Ja → Scrapy
- Nee → Thunderbit
- Heb je vertaling of sentimentanalyse nodig?
- Ja → Thunderbit
- Nee → Beide
Stap voor stap: Amazon-productdata scrapen met Thunderbit (geen code nodig)
Laten we ons Amazon-voorbeeld nog eens doen — maar deze keer op de makkelijke manier.
1. Thunderbit installeren
- Download de Thunderbit Chrome-extensie
- Meld je aan (gratis tier beschikbaar)
Probeer de Thunderbit Chrome-extensie gratis
2. Ga naar Amazon en zoek je product
- Open Amazon.com en zoek naar “laptops” (of welk product dan ook)
3. Start Thunderbit op de pagina
- Klik op het Thunderbit-icoon in je browser
- Het zijpaneel opent en herkent de Amazon-pagina
4. Gebruik AI om velden voor te stellen
- Klik op “AI Suggest Fields”
- Thunderbit’s AI scant de pagina en stelt kolommen voor zoals “Productnaam”, “Prijs”, “Beoordeling”, “Aantal reviews”
- Voeg kolommen toe of verwijder ze indien nodig (wil je “Product-URL” of “Prime-geschiktheid”? Typ het gewoon in)
5. Schakel paginering en subpaginacraping in
- Zet Paginering aan: Thunderbit klikt automatisch op “Volgende” en scrapt alle pagina’s
- Zet Subpaginacrapping aan: Thunderbit bezoekt de detailpagina van elk product en haalt extra informatie op (zoals beschrijvingen of ASIN-nummers)
6. Voer de scrape uit
- Klik op Scrapen
- Kijk hoe Thunderbit de data in realtime verzamelt, pagina voor pagina
7. Vertaal en analyseer sentiment (optioneel)
- Productbeschrijvingen vertalen? Zet voor die kolom “Vertalen” aan
- Reviews op sentiment analyseren? Voeg een kolom “Sentiment” toe — Thunderbit’s AI vult die in
8. Exporteer je data
- Klik op Exporteren
- Kies Excel, Google Sheets, Airtable of Notion
- Je data is klaar voor gebruik — geen handmatige import, geen CSV-gedoe
9. Plan terugkerende scrapes in (optioneel)
- Stel een schema in (bijv. dagelijks om 8:00 uur)
- Thunderbit voert de scrape automatisch uit en werkt je gekozen bestemming bij
Dat is alles. Geen code, geen selectors, geen onderhoud. Gewoon data, klaar voor zakelijk gebruik.
Bonustips: haal meer uit je webscrapingprojecten
Of je nu Scrapy, Thunderbit of een andere tool gebruikt, hier zijn een paar best practices die ik met vallen en opstaan heb geleerd:
- Valideer je data: controleer altijd op ontbrekende of vreemde waarden (zoals prijzen van $0 of lege namen)
- Blijf compliant: controleer de gebruiksvoorwaarden van de site, respecteer
robots.txten overbelast servers niet - Automatiseer verstandig: gebruik planning om data actueel te houden, maar scrape niet vaker dan nodig
- Maak gebruik van gratis tools: Thunderbit bevat gratis e-mail-, telefoon- en afbeeldingsextractors — ideaal voor leadgeneratie of contentcuratie
- Organiseer voor analyse: exporteer direct naar Sheets/Excel zodat je snel kunt filteren, pivoteren en visualiseren
Voor meer tips, bekijk Thunderbit’s blog of hun gids voor het scrapen van elke website met AI.
Hoe je websitegegevens met AI naar Excel scrapt Get Started Free
Voor meer tips, bekijk Thunderbit’s blog of hun gids voor het scrapen van elke website met AI.
Conclusie: webscraping eenvoudig gemaakt — kies de juiste tool voor je team
De kern is dit: Scrapy is een krachtpatser voor ontwikkelaars, maar voor de meeste zakelijke gebruikers is het overkill. Als je vertrouwd bent met Python en een maatwerk-scraper op grote schaal wilt bouwen, is Scrapy een prima keuze. Maar als je snel wilt bewegen, code wilt overslaan en data wilt krijgen met vertaling en sentimentanalyse ingebouwd, dan is Thunderbit de juiste weg.
Ik heb uit eerste hand gezien hoeveel tijd en frustratie Thunderbit bespaart voor niet-technische teams. Je gaat in minuten — niet uren of dagen — van “ik wou dat ik deze data had” naar “het staat in mijn spreadsheet”. En met functies zoals AI Suggest Fields, subpaginacrapping en export met één klik is het nog nooit zo makkelijk geweest om van het web business intelligence te maken.
Dus vraag jezelf de volgende keer dat je productdata moet scrapen, prijzen wilt monitoren of een leadlijst wilt opbouwen af: wil je Python schrijven, of wil je resultaat? Probeer Thunderbit’s gratis tier eens uit en ontdek hoe veel makkelijker webscraping kan zijn.
Nieuwsgierig naar meer? Bekijk Thunderbit’s officiële site, download de Chrome-extensie of verdiep je verder in best practices voor webscraping op de Thunderbit-blog.
Verder lezen:
- Wat is data scraping en hoe doe je het in 2026
- Hoe je websitegegevens met AI naar Excel scrapt
- De beste webscrapingtools en software in 2026
- State of Web Scraping-rapport
Disclaimer: zorg er altijd voor dat je webscrapingactiviteiten voldoen aan de voorwaarden van websites en de lokale wetgeving. Bij twijfel: vraag juridisch advies — niemand wil de “scraper” zijn die een ingebrekestelling krijgt vanwege een spreadsheet.
Geschreven door Shuai Guan, medeoprichter en CEO bij Thunderbit. Ik heb jarenlang ervaring in SaaS, automation en AI — zodat jij dat niet hoeft te hebben.
Probeer AI-webscraper Get Started Free




