Zillow staat bovenop , en die data op grote schaal binnenhalen is een van de meest gevraagde — én meest frustrerende — taken binnen vastgoeddata. Heb je ooit geprobeerd Zillow scrapen met Python en keek je uiteindelijk vooral naar een CAPTCHA-pagina in plaats van naar listingdata? Dan ben je zeker niet de enige.
Ik heb flink wat tijd gestoken in het uitzoeken en testen van verschillende manieren om Zillow te scrapen — zowel met Python als met no-code tools die we bij Thunderbit hebben gebouwd. Deze gids behandelt beide routes. Of je nu een complete Python-handleiding met anti-botstrategieën wilt, of gewoon voor de lunch 200 listings in een spreadsheet nodig hebt: hier vind je wat je zoekt. We leggen uit waarom Zillow-data belangrijk is, hoe de site technisch in elkaar zit, geven een stap-voor-stap Python-tutorial, laten zien waarom scrapers stukgaan en hoe je terugkerende scrapes automatiseert voor prijsmonitoring.
Waarom zou je überhaupt Zillow-data scrapen?
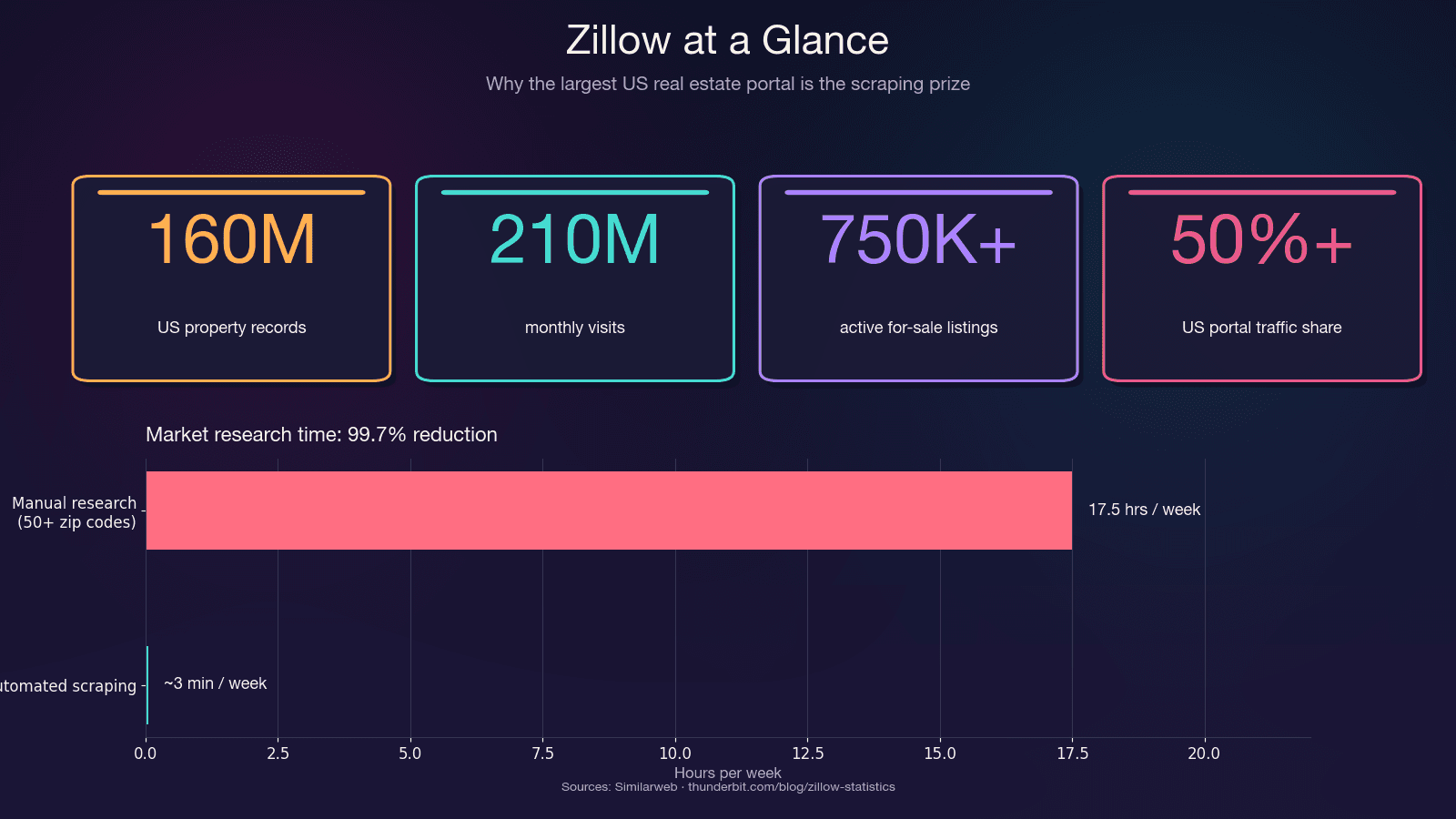
Zillow is de grootste databron voor Amerikaanse residentiële vastgoeddata. De site trekt en bevat ongeveer 750.000+ actieve koopaanbiedingen plus 1,9 miljoen huurwoningen. Het platform is goed voor meer dan 50% van al het vastgoedportaalverkeer in de VS — meer dan het dubbele van de eerstvolgende concurrent.
Voordat we in de Python-code duiken, is het goed om te weten dat Zillow scrapen met Python niet je enige optie is. De verkeerde aanpak kiezen kan je uren kosten. Python-tools zoals httpx en BeautifulSoup vragen om een gemiddeld technisch niveau, handmatig beheer van headers en proxies, en werken met gematigde snelheid (1–3 seconden per pagina); ze vragen bovendien regelmatig onderhoud, al zijn ze gratis. Selenium of Playwright verbeteren de anti-botaanpak doordat JavaScript wordt gerenderd, maar zijn trager (5–15 seconden per pagina) en nog steeds onderhoudsgevoelig. Scraping-API’s zoals ScraperAPI of ScrapFly zijn sneller en hebben ingebouwde anti-botondersteuning, met gemiddeld onderhoud, maar kosten $30–599 per maand. Zillow’s officiële API via Bridge Interactive is snel en onderhoudsarm, maar beperkt beschikbaar en kost rond de $500 per maand. En no-code tools zoals Thunderbit zijn gebruiksvriendelijk, snel, onderhoudsvrij dankzij AI-adaptatie en werken meestal met een freemium-model.
De tijdwinst alleen al is enorm. Handmatig onderzoek over 50+ postcodes kan 15–20 uur per week opslokken. Geautomatiseerd scrapen doet hetzelfde werk in minuten — een tijdsbesparing van 99,7%.
Alle manieren om Zillow te scrapen: Python vs. API vs. no-code (vergeleken)
Voordat je in Python-code duikt: "Zillow scrapen met Python" is niet de enige mogelijkheid. De verkeerde methode kost je onnodig veel tijd. Hieronder staat een vergelijking naast elkaar zodat je zelf kunt kiezen:
| Methode | Niveau | Anti-botaanpak | Snelheid | Onderhoud | Kosten |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | Gemiddeld | Handmatig (headers, proxies) | Gemiddeld (1–3s/pagina) | Hoog (selectors breken) | Gratis |
| Python + Selenium/Playwright | Gemiddeld | Beter (rendert JS) | Traag (5–15s/pagina) | Hoog | Gratis |
| Scraping API (ScraperAPI, ScrapFly) | Gemiddeld | Ingebouwd | Snel | Gemiddeld | $30–599/maand |
| Officiële Zillow API (Bridge Interactive) | Beginner–Gemiddeld | N.v.t. | Snel | Laag | ~$500/maand, beperkte toegang |
| No-code tool (Thunderbit) | Beginner | Ingebouwd (AI past zich aan) | Snel | Geen (AI leest pagina opnieuw) | Freemium |
Als je meteen data nodig hebt zonder code te schrijven, begin dan met Thunderbit. Wil je juist de techniek begrijpen of volledige controle hebben, lees dan verder voor de Python-uitwerking.
De 2-minutenmethode: scrape Zillow met Thunderbit (geen code nodig)
Voordat we de Python-kant induiken, is dit de snelste route voor iedereen die gewoon snel Zillow-data nodig heeft — geen Python-installatie, geen proxyconfiguratie, geen selector-onderhoud. We hebben deze workflow bij Thunderbit gebouwd voor gestructureerde vastgoeddata zonder technische rompslomp.
Moeilijkheid: Beginner
Benodigde tijd: ~2 minuten
Wat heb je nodig: Chrome-browser, (gratis versie werkt)
Stap 1: installeer Thunderbit en open Zillow
Installeer de Thunderbit-extensie via de Chrome Web Store. Ga naar een Zillow-pagina met zoekresultaten — bijvoorbeeld woningen in Houston, TX.
Stap 2: klik op "AI Suggest Fields"
Open de Thunderbit-zijbalk en klik op "AI Suggest Fields". De AI leest de pagina en stelt automatisch kolommen voor: prijs, adres, slaapkamers, badkamers, vierkante meters, Zestimate, listing-URL en meer. In mijn tests detecteert het meestal 20+ velden zonder enige handmatige configuratie.
Stap 3: klik op "Scrape"
Druk op de Scrape-knop. De data verschijnt in een gestructureerde tabel in de extensie. Thunderbit verwerkt Zillow’s paginering automatisch — zowel via klikken als via oneindig scrollen.
Stap 4: verrijk met subpage scraping
Wil je detailgegevens zoals belastinghistorie, schoolbeoordelingen of prijshistorie? Gebruik "Scrape Subpages" om je tabel verder aan te vullen. Thunderbit volgt elke listing-URL en haalt de extra velden op — zonder extra code.
Stap 5: exporteren
Exporteer naar Google Sheets, Excel, Airtable of Notion. Exporteren is gratis.
Waarom Thunderbit goed werkt voor Zillow
Het echte voordeel is de robuustheid. Thunderbit’s AI leest de paginastuctuur elke keer opnieuw wanneer je scrape uitvoert. Als Zillow zijn layout aanpast — wat regelmatig gebeurt — hoef je geen fragiele CSS-selectors te repareren. De AI past zich automatisch aan. Daarmee wordt het probleem van de van nature kwetsbare coded scrapers echt opgelost.
Welke data kun je van Zillow scrapen? (20+ velden)
De meeste gidsen pakken alleen prijs en adres en stoppen dan. In Zillow-listings zit eigenlijk veel meer uitleesbare data dan je denkt — hieronder staat een handige referentietabel:
| Veld | Waar het te vinden is | Moeilijkheidsgraad |
|---|---|---|
| Vraagprijs | Zoekresultaten + detailpagina | Makkelijk |
| Adres / postcode | Zoekresultaten + detailpagina | Makkelijk |
| Zestimate | Zoekresultaten + detailpagina | Makkelijk |
| Prijshistorie (elk event) | Detailpagina | Moeilijk (geneste JSON) |
| Belastinghistorie | Detailpagina | Moeilijk (geneste JSON) |
| Slaapkamers / badkamers / m² | Zoekresultaten + detailpagina | Makkelijk |
| Bouwjaar | Detailpagina | Makkelijk |
| VvE-kosten | Detailpagina | Gemiddeld |
| Walk Score / Transit Score | Detailpagina (iframe) | Moeilijk (JS-rendering nodig) |
| Schoolbeoordelingen | Detailpagina | Gemiddeld |
| Perceelgrootte | Detailpagina | Makkelijk |
| Dagen op Zillow | Zoekresultaten | Makkelijk |
| Listingagent / makelaarskantoor | Zoekresultaten + detailpagina | Gemiddeld |
| MLS-nummer | Detailpagina | Makkelijk |
| Woningtype | Zoekresultaten + detailpagina | Makkelijk |
| Breedtegraad / lengtegraad | __NEXT_DATA__ JSON | Gemiddeld |
| Omschrijvingstekst | Detailpagina | Makkelijk |
| Foto-URL’s | Zoekresultaten + detailpagina | Gemiddeld |
| Rent Zestimate | Detailpagina | Gemiddeld |
| Vergelijkbare verkopen in de buurt | Detailpagina | Moeilijk |
De "moeilijke" velden — prijshistorie, belastinghistorie, vergelijkbare verkopen — zitten in geneste JSON op detailpagina’s. Het Python-gedeelte hieronder laat precies zien hoe je die eruit haalt. En als je liever de code overslaat, detecteert Thunderbit’s AI Suggest Fields de meeste van deze kolommen automatisch, terwijl Scrape Subpages de detailpagina-velden voor je ophaalt.
Je Python-omgeving instellen om Zillow te scrapen
Moeilijkheid: Gemiddeld
Benodigde tijd: ~5 minuten voor de setup, ~30 minuten voor de volledige tutorial
Wat heb je nodig: Python 3.8+, Chrome-browser (om pagina’s te inspecteren), een teksteditor of IDE
Installeer de benodigde libraries:
1pip install httpx beautifulsoup4 pandas lxmlWat doet elk pakket?
- httpx — HTTP-client met betere prestaties dan
requestsen ondersteuning voor async - beautifulsoup4 + lxml — HTML-parsing
- pandas — data exporteren naar CSV/Excel
- Optioneel: selenium of playwright als je JavaScript-zware pagina’s moet renderen
Begrijp eerst Zillow’s paginastuctuur voordat je begint te scrapen
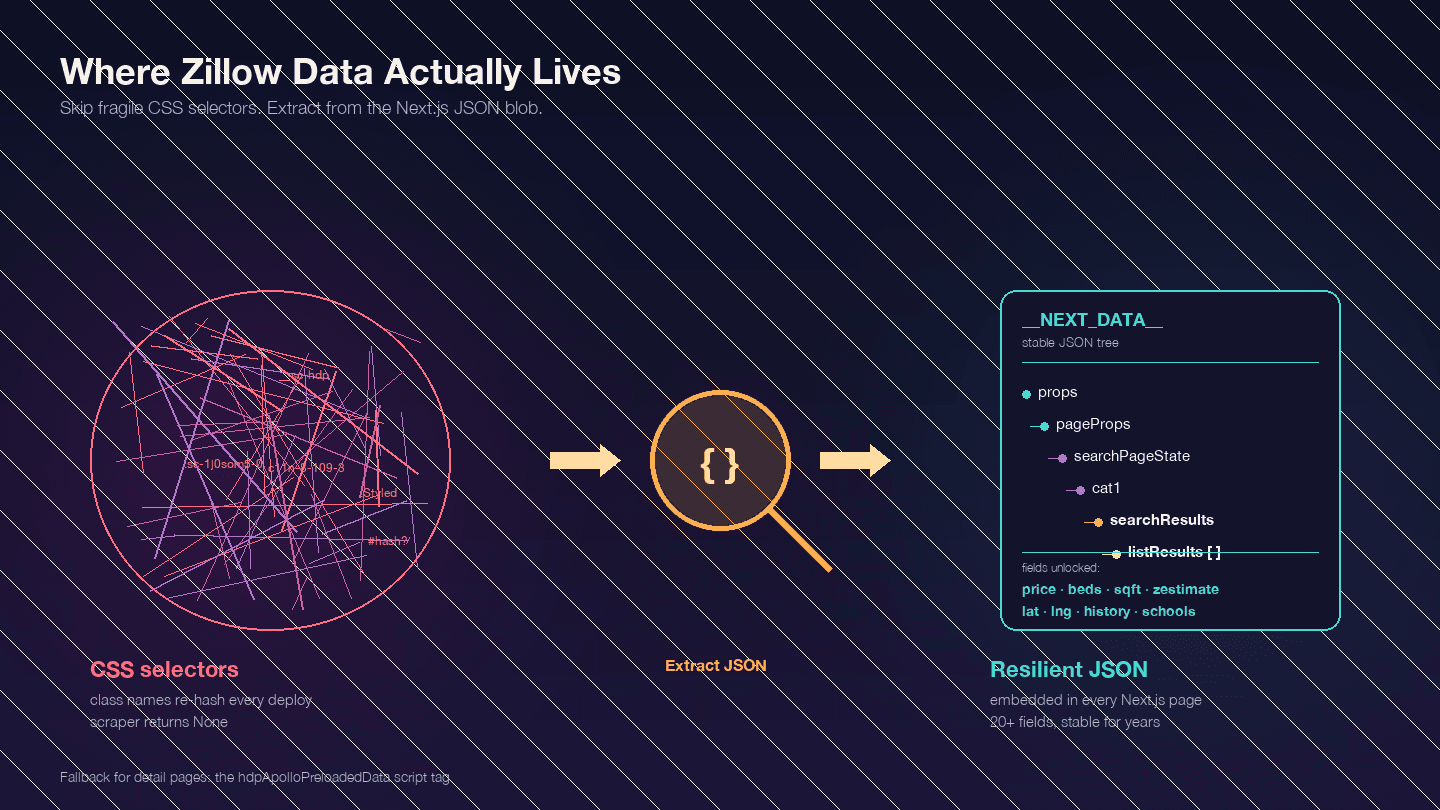
Dit is het belangrijkste om te begrijpen voordat je code schrijft. Zillow is een Next.js-applicatie — bevestigd door . Dat betekent dat de meeste data die je zoekt niet in de zichtbare HTML-elementen zit. Ze zijn ingebed in een JSON-blok in <script id="__NEXT_DATA__">.
Open een willekeurige Zillow-propertypagina, druk op F12, ga naar Elements en zoek naar __NEXT_DATA__. Je vindt daar een enorme JSON-structuur met alle listingdata — prijzen, coördinaten, woningdetails, prijshistorie, belastinggegevens, schoolbeoordelingen en meer.
Waarom is dit belangrijk? Zillow’s CSS-classnamen zijn gehasht (gegenereerd door styled-components) en veranderen bij elke deployment. Een class zoals StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 ziet er volgende week compleet anders uit. Elke scraper die op CSS-selectors leunt, breekt daardoor regelmatig.
De JSON-aanpak via __NEXT_DATA__ is veel stabieler, omdat die helemaal niet afhankelijk is van de HTML-structuur.
Belangrijke JSON-paden voor zoekresultaten:
| Pad | Inhoud |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | Array met zoekresultaten |
props.pageProps.searchPageState.cat1.searchResults.mapResults | Resultaten in kaartweergave |
props.pageProps.searchPageState.cat1.searchList.totalPages | Totaal aantal beschikbare pagina’s |
Voor detailpagina’s gebruiken sommige pagina’s __NEXT_DATA__ en andere een alternatieve script-tag hdpApolloPreloadedData. De code hieronder vangt beide gevallen af.
Stap voor stap: hoe je Zillow scrapt met Python
Stap 1: stel HTTP-headers in om directe blokkades te vermijden
Als je simpelweg een httpx.get() naar Zillow stuurt, krijg je geen listingdata maar een CAPTCHA-pagina. Zillow gebruikt PerimeterX (HUMAN Security) naast Cloudflare — beide krijgen in scraping-benchmarks een . Het systeem controleert je TLS-fingerprint, HTTP-headers en IP-reputatie.
Dit zijn de minimale headers die in 2025 werken:
1import httpx
2headers = {
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
5 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
6 "image/avif,image/webp,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
10 "Sec-Ch-Ua-Platform": '"Windows"',
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "none",
14 "Sec-Fetch-User": "?1",
15 "Upgrade-Insecure-Requests": "1",
16}De Sec-Ch-Ua-headers zijn cruciaal. Veel tutorials laten die weg — en precies daarom werkt hun code niet tegen PerimeterX.
Stap 2: scrape Zillow-zoekresultaten
Zillow-zoek-URL’s volgen een voorspelbaar patroon. Voor Houston, TX:
- Pagina 1:
https://www.zillow.com/houston-tx/ - Pagina 2:
https://www.zillow.com/houston-tx/2_p/ - Pagina 3:
https://www.zillow.com/houston-tx/3_p/
Elke pagina bevat ongeveer 41 listings. Zillow beperkt de resultaten tot 20 pagina’s (~820 listings). Voor grotere datasets moet je de data opdelen per regio (daarover later meer).
Hier is de code om zoekresultaten te scrapen door data uit de __NEXT_DATA__ JSON te halen:
1from bs4 import BeautifulSoup
2import json
3import time
4import random
5def scrape_zillow_search(url):
6 """Listingdata van een Zillow-zoekresultatenpagina scrapen."""
7 response = httpx.get(url, headers=headers, timeout=15)
8 if response.status_code != 200:
9 print(f"Status {response.status_code} voor {url}")
10 return []
11 soup = BeautifulSoup(response.text, "lxml")
12 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
13 if not script_tag:
14 print("Geen __NEXT_DATA__ gevonden — waarschijnlijk geblokkeerd door CAPTCHA")
15 return []
16 next_data = json.loads(script_tag.string)
17 try:
18 results = (
19 next_data["props"]["pageProps"]["searchPageState"]
20 ["cat1"]["searchResults"]["listResults"]
21 )
22 except KeyError:
23 print("Onverwachte JSON-structuur — mogelijk heeft Zillow het formaat aangepast")
24 return []
25 listings = []
26 for item in results:
27 listing = {
28 "zpid": item.get("zpid"),
29 "address": item.get("addressStreet"),
30 "city": item.get("addressCity"),
31 "state": item.get("addressState"),
32 "zipcode": item.get("addressZipcode"),
33 "price": item.get("unformattedPrice") or item.get("price"),
34 "beds": item.get("beds"),
35 "baths": item.get("baths"),
36 "sqft": item.get("area"),
37 "zestimate": item.get("zestimate"),
38 "days_on_zillow": item.get("daysOnZillow"),
39 "listing_url": item.get("detailUrl"),
40 "img_src": item.get("imgSrc"),
41 "property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
42 "latitude": item.get("latLong", {}).get("latitude"),
43 "longitude": item.get("latLong", {}).get("longitude"),
44 }
45 listings.append(listing)
46 return listingsOm meerdere pagina’s te scrapen, gebruik je een lus met vertraging:
1all_listings = []
2base_url = "https://www.zillow.com/houston-tx/"
3for page in range(1, 6): # Eerste 5 pagina's
4 url = base_url if page == 1 else f"{base_url}{page}_p/"
5 print(f"Pagina {page} aan het scrapen...")
6 page_listings = scrape_zillow_search(url)
7 all_listings.extend(page_listings)
8 # Willekeurige pauze tussen 3 en 7 seconden
9 delay = random.uniform(3, 7)
10 time.sleep(delay)
11print(f"Totaal aantal gescrapete listings: {len(all_listings)}")Je zou nu gestructureerde listingdata moeten zien opbouwen in all_listings. Als je lege resultaten krijgt, kijk dan naar de sectie "Waarom scrapers stukgaan" hieronder.
Stap 3: scrape Zillow-detailpagina’s
Zoekresultaten geven je de basisinformatie. Detailpagina’s bevatten de diepere data: prijshistorie, belastinghistorie, schoolbeoordelingen, agentinformatie en woningbeschrijvingen. Elke listing-URL uit stap 2 verwijst naar een detailpagina.
Zillow-detailpagina’s gebruiken twee mogelijke datavormen. Hieronder staat code die beide ondersteunt:
1def scrape_zillow_detail(url):
2 """Gedetailleerde woningdata scrapen van een Zillow-listingpagina."""
3 response = httpx.get(url, headers=headers, timeout=15)
4 if response.status_code != 200:
5 return None
6 soup = BeautifulSoup(response.text, "lxml")
7 # Probeer eerst __NEXT_DATA__ (meest voorkomend)
8 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
9 if script_tag:
10 next_data = json.loads(script_tag.string)
11 try:
12 cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
13 cache = json.loads(cache_str)
14 first_key = next(iter(cache))
15 prop = cache[first_key]["property"]
16 return extract_property_fields(prop)
17 except (KeyError, StopIteration):
18 pass
19 # Fallback: hdpApolloPreloadedData
20 apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
21 if apollo_tag:
22 raw = json.loads(apollo_tag.string)
23 api_cache = json.loads(raw["apiCache"])
24 for key, value in api_cache.items():
25 if "ForSale" in key or "property" in str(value)[:100]:
26 prop = value.get("property", value)
27 return extract_property_fields(prop)
28 return None
29def extract_property_fields(prop):
30 """Extraheer gestructureerde velden uit een Zillow-property-JSON-object."""
31 return {
32 "zpid": prop.get("zpid"),
33 "zestimate": prop.get("zestimate"),
34 "rent_zestimate": prop.get("rentZestimate"),
35 "description": prop.get("description"),
36 "year_built": prop.get("yearBuilt"),
37 "lot_size": prop.get("lotSize"),
38 "hoa_fee": prop.get("monthlyHoaFee"),
39 "mls_id": prop.get("mlsid"),
40 "broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
41 "price_history": [
42 {
43 "date": event.get("date"),
44 "event": event.get("event"),
45 "price": event.get("price"),
46 }
47 for event in prop.get("priceHistory", [])
48 ],
49 "tax_history": [
50 {
51 "year": record.get("time"),
52 "tax_paid": record.get("taxPaid"),
53 "value": record.get("value"),
54 }
55 for record in prop.get("taxHistory", [])
56 ],
57 "schools": [
58 {
59 "name": school.get("name"),
60 "rating": school.get("rating"),
61 "distance": school.get("distance"),
62 }
63 for school in prop.get("schools", [])
64 ],
65 }Loop vervolgens door je listing-URL’s met vertraging:
1detail_data = []
2for listing in all_listings[:10]: # Begin met 10 om te testen
3 detail_url = listing.get("listing_url")
4 if not detail_url:
5 continue
6 if not detail_url.startswith("http"):
7 detail_url = f"https://www.zillow.com{detail_url}"
8 print(f"Detail aan het scrapen: {detail_url}")
9 detail = scrape_zillow_detail(detail_url)
10 if detail:
11 detail_data.append({**listing, **detail})
12 time.sleep(random.uniform(3, 8))Na deze stap heb je een lijst met dictionaries met zowel zoekresultaat- als detailniveau-data per woning.
Stap 4: paginering verwerken om meerdere pagina’s te scrapen
Voor gebieden met meer dan 820 listings (de limiet van 20 pagina’s) moet je de data geografisch opsplitsen. Zillow’s interne API accepteert mapBounds-parameters. De strategie: verdeel de kaart in kwadranten en scrape elk deel afzonderlijk.
1def split_bounds(bounds):
2 """Splits kaartgrenzen op in 4 kwadranten."""
3 mid_lat = (bounds["north"] + bounds["south"]) / 2
4 mid_lng = (bounds["east"] + bounds["west"]) / 2
5 return [
6 {"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
7 {"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
8 {"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
9 {"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
10 ]Voor de meeste toepassingen — bijvoorbeeld 50–200 listings in een specifiek gebied monitoren — is standaard-URL-paginering voldoende. De kwadrantmethode is vooral bedoeld voor scraping op stads- of staatsniveau.
Stap 5: exporteer je gescrapete Zillow-data
Sla alles op als CSV met pandas:
1import pandas as pd
2df = pd.DataFrame(detail_data)
3df.to_csv("zillow_houston_listings.csv", index=False)
4print(f"{len(df)} listings geëxporteerd naar zillow_houston_listings.csv")Voor JSON-export:
1with open("zillow_houston_listings.json", "w") as f:
2 json.dump(detail_data, f, indent=2)Als je het exporteren helemaal wilt overslaan, zet Thunderbit data gratis door naar Google Sheets, Airtable en Notion — handig als je de data direct in een samenwerkingsomgeving wilt gebruiken.
Waarom Zillow scrapers stukgaan (en hoe je robuuste scrapers bouwt)
Dit is de survivalgids.
In mijn ervaring gaan scrapers op Zillow om drie specifieke redenen stuk — en voor elk probleem is er een concrete oplossing.
PerimeterX en CAPTCHA’s: waarom je verzoeken lege data teruggeven
Zillow’s PerimeterX-integratie controleert meerdere signalen tegelijk: TLS-fingerprint, HTTP-headers, IP-reputatie en requestpatronen. Als het systeem automatisering detecteert, krijg je een "Press & Hold" CAPTCHA-pagina in plaats van listingdata.
Het exacte faalscenario: je stuurt een request met standaard Python-headers. De HTML-response bevat PerimeterX-challengescripts in plaats van woningdata — en je BeautifulSoup-parse vindt geen __NEXT_DATA__-tag.
De oplossing: gebruik de volledige browser-achtige headers uit stap 1. Als je meer dan een paar dozijn verzoeken doet, heb je ook proxy-rotatie nodig (hieronder besproken). Voor zware scraping kun je een library zoals curl_cffi gebruiken met impersonate="chrome" — het is de enige Python HTTP-client die een echte Chrome TLS-fingerprint echt dicht benadert.
Dynamische CSS-selectors: waarom BeautifulSoup None teruggeeft
Als je CSS-selectors gebruikt zoals .list-card-price of classnamen met hashes, gaat je scraper stuk telkens wanneer Zillow nieuwe code uitrolt.
Zillow gebruikt styled-components, die classnamen genereren zoals StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0. Het hash-gedeelte verandert bij elke build.
De oplossing: gebruik helemaal geen CSS-selectors. Haal data uit het __NEXT_DATA__-JSON-blok zoals in de code hierboven. Deze aanpak is al jaren stabiel, omdat de JSON-structuur veel minder vaak verandert dan de HTML-markup.
Als je toch HTML-parsing moet gebruiken, kijk dan naar data-test-attributen (bijv. data-test="property-card") of gebruik class-matching op basis van een deel van de naam, zoals [class*="PropertyCard"]. Maar JSON-extractie is betrouwbaarder.
Proxy-rotatie en exponentiële backoff: code die IP-bans overleeft
Datacenter-IP’s worden door Zillow . Je hebt residential proxies nodig voor betrouwbare toegang. Veilige snelheid: 1 request per 3–8 seconden per IP, onder ongeveer 500 requests per uur.
Hier is een retry-decorator met exponentiële backoff en jitter:
1import random
2import time
3def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
4 """AWS-stijl exponential backoff met full jitter."""
5 delay = min(max_delay, base_delay * (2 ** attempt))
6 return random.uniform(0, delay)
7def fetch_with_retry(url, max_retries=5):
8 for attempt in range(max_retries):
9 try:
10 response = httpx.get(url, headers=headers, timeout=15)
11 if response.status_code == 200:
12 return response
13 if response.status_code in (403, 429):
14 delay = backoff_with_jitter(attempt, base_delay=5)
15 print(f"Geblokkeerd ({response.status_code}). Opnieuw proberen over {delay:.1f}s...")
16 time.sleep(delay)
17 continue
18 except Exception as e:
19 if attempt == max_retries - 1:
20 raise
21 time.sleep(backoff_with_jitter(attempt))
22 return NoneEn een eenvoudige proxy-rotatiepool:
1class ProxyPool:
2 def __init__(self, proxies):
3 self.proxies = proxies
4 self.index = 0
5 self.failures = {}
6 def get_next(self):
7 proxy = self.proxies[self.index % len(self.proxies)]
8 self.index += 1
9 return {"http://": proxy, "https://": proxy}
10 def report_failure(self, proxy):
11 self.failures[proxy] = self.failures.get(proxy, 0) + 1
12 if self.failures[proxy] > 3:
13 self.proxies.remove(proxy)
14# Gebruik:
15pool = ProxyPool(proxies=[
16 "http://user:pass@residential1.example.com:8080",
17 "http://user:pass@residential2.example.com:8080",
18])Voor proxyproviders biedt residential proxies vanaf ongeveer $1/GB (de goedkoopste optie), terwijl IPRoyal en Smartproxy degelijke middenklasse-opties zijn rond $4–7/GB.
Het onderhoudsvrije alternatief
Als je Zillow regelmatig scrapt en het zat bent om kapotte selectors of proxy-pools te beheren, leest Thunderbit’s AI de paginastuctuur opnieuw bij elke scrape. Geen selectors om te onderhouden, geen proxyconfiguratie. Daarmee wordt het fragiliteitsprobleem waar gecodeerde scrapers zo vaak tegenaan lopen, echt opgelost.
Automatiseer Zillow scraping: planning en prijsmonitoring
Elke vastgoedbelegger met wie ik heb gesproken wil dit, en geen enkele andere Zillow-scrapinggids behandelt het goed: terugkerende automatische scrapes voor prijsmonitoring.
Voor Python-gebruikers: cronjobs en prijswijzigingen detecteren
Stel een cronjob in die je scraper wekelijks draait en prijsveranderingen markeert:
1import pandas as pd
2from datetime import datetime
3def detect_price_changes(new_data, historical_file, threshold=0.05):
4 """Vergelijk een nieuwe scrape met historische data en markeer veranderingen groter dan de drempel."""
5 try:
6 old = pd.read_csv(historical_file)
7 except FileNotFoundError:
8 new_data.to_csv(historical_file, index=False)
9 print("Eerste run — basisdata opgeslagen.")
10 return pd.DataFrame()
11 merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
12 merged["price_change_pct"] = (
13 (merged["price_new"] - merged["price_old"]) / merged["price_old"]
14 )
15 alerts = merged[merged["price_change_pct"].abs() > threshold]
16 # Nieuwe data met timestamp toevoegen
17 new_data["scraped_at"] = datetime.now().isoformat()
18 new_data.to_csv(historical_file, mode="a", header=False, index=False)
19 return alertsVoeg dit toe aan je crontab voor wekelijkse runs op maandag om 6:00 uur:
10 6 * * 1 cd /path/to/scraper && python zillow_monitor.pyEen praktisch voorbeeld: monitor 50 listings in Austin, TX wekelijks. Elke maandag scrape het script de actuele prijzen, vergelijkt die met de voorgaande week en maakt een CSV met alle prijsverlagingen groter dan 5%.
Voor niet-coders: Thunderbit Scheduled Scraper
Thunderbit’s Scheduled Scraper laat je het interval in gewone taal beschrijven ("elke maandag om 9 uur"), je Zillow-zoek-URL’s invoeren en op Schedule klikken. Data wordt bij elke run automatisch naar Google Sheets geëxporteerd. Geen Python, geen cron, geen server om te beheren. Dit is vooral handig voor makelaars of operationele teams die consistente prijsmonitoring nodig hebben zonder ondersteuning van engineers.
Tips om Zillow verantwoord te scrapen
Een paar aandachtspunten om binnen de grenzen te blijven:
- Scrape alleen publiek toegankelijke data. Ga niet achter loginmuren of authenticatiepagina’s aan.
- Gebruik redelijke request-snelheden. 3–8 seconden tussen requests. Overbelast de server niet.
- Scrape geen persoonlijke of privégebruikersdata. Agentnamen en makelaarsinformatie op listings zijn publiek; accountgegevens van gebruikers niet.
- Bewaar en gebruik data ethisch. Marktonderzoek, investeringsanalyse en leadgeneratie zijn legitieme toepassingen. Spam niet.
- Juridische context: de uitspraak in stelde vast dat het scrapen van publiek toegankelijke data niet in strijd is met de CFAA. De uitspraak in Meta v. Bright Data (2024) bevestigde vergelijkbare principes. Dat gezegd hebbende: Zillow’s voorwaarden beperken geautomatiseerde toegang, en zij handhaven dat met IP-bans en CAPTCHA’s in plaats van rechtszaken. Controleer altijd de actuele richtlijnen en respecteer .
Kies de juiste aanpak om Zillow te scrapen met Python
De beste route hangt af van je situatie:
Snel data nodig, geen code? brengt je van een Zillow-zoekpagina naar een gestructureerd spreadsheet in ongeveer 2 minuten. De AI past zich aan layoutwijzigingen aan, verwerkt paginering en exporteert gratis. Installeer de en probeer het op een Zillow-zoekpagina.
Volledige controle nodig? Gebruik de Python-code in deze gids. Haal data uit __NEXT_DATA__-JSON (niet uit CSS-selectors) voor meer stabiliteit. Stel browser-achtige headers correct in. Roteer residential proxies en gebruik exponentiële backoff voor betrouwbaarheid.
Opschalen? Scraping-API’s zoals (99% succespercentage op Zillow) of ScraperAPI nemen de proxy- en CAPTCHA-infrastructuur voor je uit handen, voor $30–599 per maand afhankelijk van volume.
Prijzen in de tijd volgen? Zet een cronjob op met het script voor prijswijzigingen, of gebruik Thunderbit’s Scheduled Scraper voor een onderhoudsvrije aanpak.
De data is er. De enige vraag is hoeveel engineeringtijd je erin wilt steken om die eruit te halen. Voor meer informatie over webdata in spreadsheets zetten, bekijk onze gids over of onze voor de nieuwste platformdata. Je kunt ook tutorials bekijken op het .
Veelgestelde vragen
Kun je Zillow gratis scrapen met Python?
Ja — httpx, BeautifulSoup en pandas zijn allemaal gratis en open source. De keerzijde is tijd: je moet headers, proxyrotatie en selector-onderhoud zelf beheren. Reken op 4–8 uur voor de eerste opzet en 4–10 uur per maand aan onderhoud zodra Zillow zijn site aanpast. Thunderbit biedt ook een gratis versie als je de technische overhead helemaal wilt vermijden.
Heeft Zillow een officiële API?
Zillow heeft zijn gratis publieke API in september 2021 uitgefaseerd. Toegang loopt nu via Bridge Interactive, waarvoor goedkeuring nodig is, ongeveer $500 per maand kost en vooral bedoeld is voor erkende vastgoedprofessionals. Voor de meeste gebruikers — beleggers, onderzoekers, makelaars die marktanalyse doen — is scrapen het praktische alternatief. Zillow publiceert overigens nog steeds gratis onderzoeksdata als downloadbare CSV’s op , waaronder de Zillow Home Value Index en de Zillow Observed Rent Index.
Hoe voorkom ik dat ik geblokkeerd word bij het scrapen van Zillow?
Drie dingen: (1) gebruik realistische browserheaders, inclusief Sec-Ch-Ua — dit is de header die de meeste tutorials overslaan, en die PerimeterX als eerste controleert; (2) roteer residential proxies — datacenter-IP’s worden vrijwel direct geblokkeerd; (3) haal data uit __NEXT_DATA__-JSON in plaats van HTML-selectors om breuken door layoutwijzigingen te voorkomen. Houd de requestfrequentie op 1 per 3–8 seconden per IP. Of gebruik een tool zoals Thunderbit die anti-botbescherming automatisch afhandelt.
Wat is de beste manier om Zillow te scrapen zonder te coderen?
Thunderbit’s AI Web Scraper is de snelste route. Installeer de , ga naar een Zillow-zoekpagina, klik op "AI Suggest Fields" om kolommen automatisch te laten herkennen en klik daarna op "Scrape". Exporteer naar Google Sheets, Excel, Airtable of Notion zonder code. De AI leest de pagina elke keer opnieuw, dus hij breekt niet wanneer Zillow zijn layout aanpast.
Hoe vaak verandert Zillow zijn websitestructuur, en wat betekent dat voor scrapers?
Zillow brengt regelmatig updates uit — soms wekelijks. Omdat ze styled-components gebruiken, veranderen CSS-classnamen bij elke deployment en breken scrapers die op CSS-selectors zijn gebouwd daardoor vaak. Voor Python is de meest robuuste aanpak het extraheren uit het __NEXT_DATA__-JSON-blok, omdat die structuur veel minder vaak verandert. Voor een onderhoudsvrije aanpak leest Thunderbit’s AI de paginastuctuur bij elke scrape opnieuw en past zich automatisch aan layoutwijzigingen aan.
Meer weten