Yelp bevat verspreid over — en die data bruikbaar maken is nog nooit zo lastig geweest. Yelp’s anti-botcampagne van 2024–2025 heeft de meeste bestaande Python-scrapingtutorials stilletjes om zeep geholpen.
Als je onlangs een Yelp scraper hebt geprobeerd en vastliep op een muur van 403-fouten, lege HTML-antwoorden of CAPTCHA’s die er zes maanden geleden nog niet waren, dan beeld je je dat niet in. Yelp gebruikt nu TLS/JA3-fingerprinting, roterende geobfusceerde CSS-klassen en agressieve IP-reputatiescores — waardoor de oude requests + BeautifulSoup-aanpak, die in bijna elke tutorial nog steeds wordt aangeraden, al bij het eerste verzoek faalt. Ik heb weken besteed aan het testen van verschillende aanpakken tegen Yelp’s huidige stack, en in deze gids staat alles wat in 2025 écht werkt: de officiële Fusion API (en waarom die waarschijnlijk niet genoeg is), een complete Python-scrapingworkflow met een gelaagde anti-blokstrategie, en een no-code alternatief met 2 klikken via voor lezers die gewoon de data willen, zonder de debugmarathon.
Waarom Yelp scrapen met Python (en wie daar echt voordeel van heeft)
Voordat je ook maar één regel code schrijft: wat is eigenlijk de businesscase voor Yelp-data? Het platform is niet alleen een site met restaurantreviews — het is in feite een live database van lokale bedrijven met gestructureerde contactgegevens, beoordelingen, categorieën, openingstijden en honderden miljoenen klantreviews.
Dit zijn de partijen die er het meeste aan hebben, en wat ze eruit halen:
| Use case | Belangrijkste datavelden | Waarom dit telt |
|---|---|---|
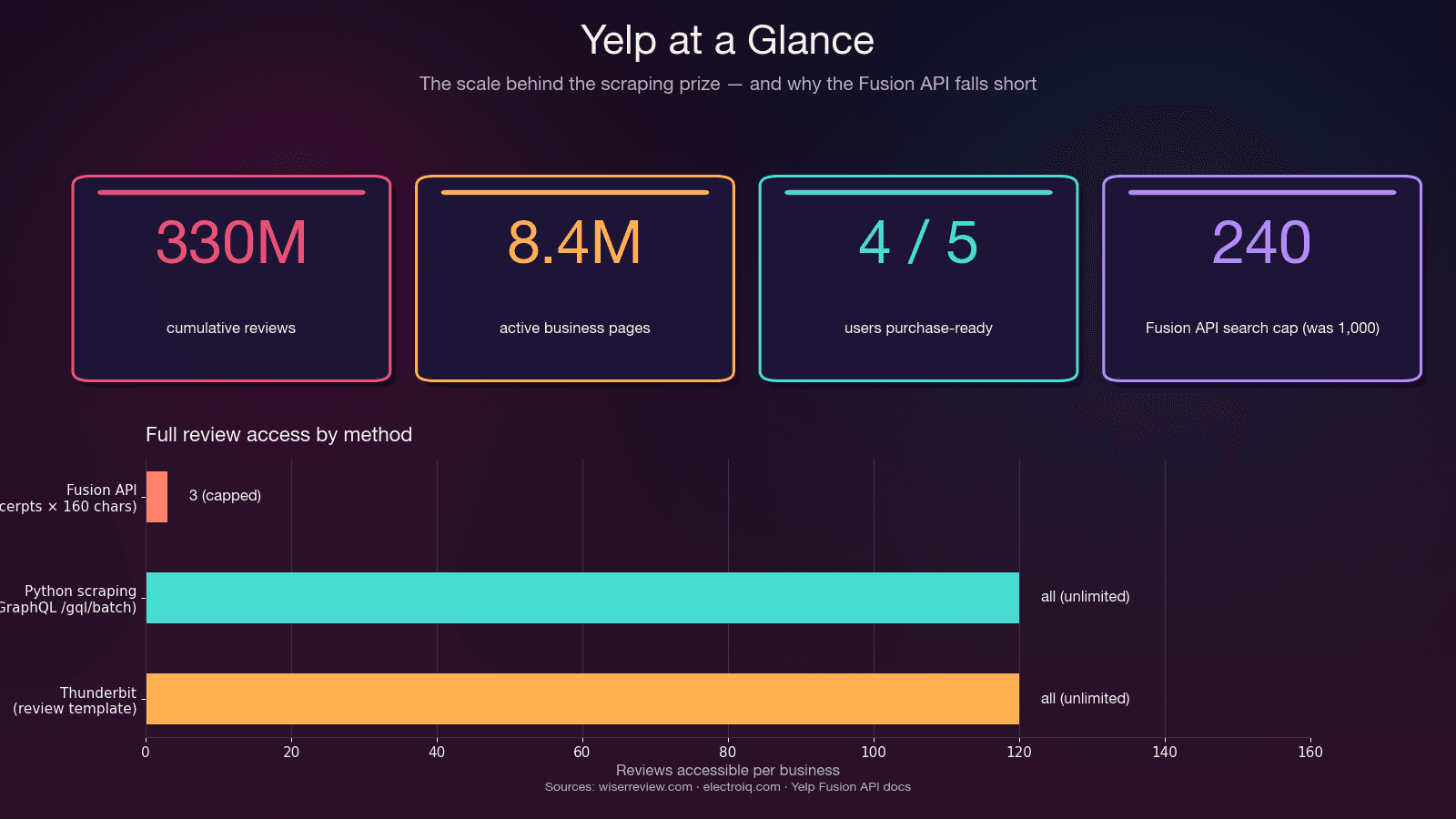
| Sales & leadgeneratie | Bedrijfsnaam, telefoon, website, adres, categorie, rating | Bouw gerichte prospectlijsten van lokale mkb’s — 4 van de 5 Yelp-gebruikers zijn klaar om te kopen zodra ze binnenkomen |
| Concurrentieanalyse | Reviews, sterrenbeoordelingen, aantal reviews, sentiment | Monitor reputatie van concurrenten, ontdek servicegaten, volg trends |
| Marktonderzoek & NLP | Volledige reviewtekst, datums, metadata van reviewers | Sentimentanalyse, topic modeling — Yelp-reviews zijn een van de meest gebruikte NLP-corpora in academisch onderzoek |
| Vastgoed & locatiekeuze | Bedrijfsdichtheid, categorie-mix, reviewkwaliteit per gebied | Franchise- en retail-locatieselectie — Yelp verkoopt hiervoor precies Location Intelligence als gelicentieerd B2B-product |
| E-commerce & operations | Prijs-signalen, klachten van klanten, openingstijden | Volg hoe concurrenten beoordeeld worden en ontdek operationele patronen |
De rode draad: het echte doel is gestructureerde data, en Python is slechts één manier om daar te komen. Sommige lezers willen volledige programmatische controle. Anderen hebben gewoon een spreadsheet nodig met contactgegevens van loodgieters in Austin. Beide routes komen hier aan bod.
Yelp Fusion API vs. Python webscraping: wat moet je kiezen?
De meeste gidsen slaan deze keuze helemaal over en duiken meteen in code, zonder eerst te beoordelen of de officiële — inmiddels hernoemd naar de “Yelp Places API” — al voldoende zou zijn. In mijn ervaring bespaart die afweging uren verspilde moeite, omdat de API voor sommige dingen prima is, maar voor andere totaal tekortschiet.
Wat de Fusion API daadwerkelijk levert
De Fusion API biedt gestructureerde bedrijfszoekopdrachten, bedrijfsdetails, autocomplete en een reviews-endpoint. Het is toegestaan, goed gedocumenteerd en je hoeft geen anti-botkunstjes uit te halen.
Maar bij het reviews-endpoint loopt het spaak. Dit heeft Yelp’s eigen team op GitHub bevestigd:
“The Yelp API does not return full review text. Three review excerpts of 160 characters are provided by default.” —
Dat is geen bug — dat is bewust zo ontworpen. De API stopt fysiek bij 3 reviewfragmenten (7 op Premium), elk ingekort tot ongeveer 160 tekens. Geen reviewmetadata (zoals useful/funny/cool-votes), geen historie van reviewers, geen reacties van eigenaars. En de — van 5.000. De instapprijs begint bij .
Het besliskader
| Factor | Yelp Fusion API | Python webscraping | Thunderbit (no-code) |
|---|---|---|---|
| Volledige reviews | ❌ Slechts 3 fragmenten (~160 tekens elk) | ✅ Alle reviews via GraphQL | ✅ Alle zichtbare reviews |
| Rate limits | 300–500/dag (nieuw); 5.000 (legacy) | Zelf beheren (proxybudget) | Credit-based |
| Opzetinspanningen | ~15 min (API-key + SDK) | Uren tot dagen | ~2 minuten |
| Bedrijfsvelden | ~20 gestructureerde velden | Onbeperkt (HTML/JSON parsen) | AI-voorgestelde velden |
| Anti-botafhandeling | N.v.t. (toegestaan) | Zelf bouwen | Automatisch geregeld |
| Juridisch risico | ✅ Toegestaan | ⚠️ Grijs gebied qua ToS | ⚠️ Zelfde als scraping |
| Kosten | Minimaal $29/mnd | Gratis (+ proxykosten $0,75–$4/GB) | Gratis tier beschikbaar |
| Onderhoud | Laag (API stabiel) | Hoog (selectors breken, anti-bot wordt strenger) | Laag (AI past zich opnieuw aan) |
Gebruik de Fusion API als: je basis bedrijfsinformatie nodig hebt, kleine opvragingen doet of een geautoriseerde integratie bouwt — en 3 reviewfragmenten per bedrijf genoeg zijn.
Gebruik Python-scraping als: je volledige reviewtekst nodig hebt, alle reviews van een bedrijf wilt, reviewmetadata nodig hebt, meer dan 240 resultaten per zoekopdracht wilt, of je budget onder de $29 per maand ligt.
Gebruik Thunderbit als: je snel data wilt zonder code te schrijven of te onderhouden. Meer hierover in het no-code-gedeelte hieronder.
De no-code snelweg: scrape Yelp met Thunderbit (zonder Python)
Voordat we de Python-diepduik doen, hier de snelste route voor lezers wiens echte doel de data is, niet de code-oefening. Elke concurrentiegids gaat uit van Python-vaardigheden, maar in mijn werk bij Thunderbit zie ik dat een groot deel van de mensen die zoeken op “scrape Yelp” salesmedewerkers, operationeel managers en ondernemers zijn die gewoon een spreadsheet met lokale bedrijven willen — geen spoedcursus TLS-fingerprinting.
levert al kant-en-klare Yelp-templates:
- — haalt bedrijfsnaam, rating, contactgegevens, adres, openingstijden en categorie op
- — haalt gebruikersnaam van de reviewer, reviewtekst, rating, datum en locatie van de reviewer op
Hoe het in de praktijk werkt
- Open een Yelp-zoekresultatenpagina of bedrijfspagina in Chrome
- Klik op AI Suggest Fields in de — de AI leest de pagina en stelt kolommen voor (bedrijfsnaam, rating, aantal reviews, prijsklasse, categorie, adres, telefoon, URL)
- Klik op Scrape — klaar
Met de vooraf gebouwde Yelp-templates is het nog eenvoudiger: open de template, klik op Scrape.
Subpage scraping regelt automatisch de verrijkingslus — begin vanaf een Yelp-zoekresultatenpagina, zet subpage scraping aan, en Thunderbit bezoekt elke bedrijfspagina om openingstijden, volledige reviews, website, foto’s en voorzieningen op te halen. Geen extra configuratie nodig.
Paginering is automatisch — zowel via klikken als scrollen, standaard ingebouwd. (Voor meer hierover, zie onze .)
Export is gratis op elk plan — Excel, Google Sheets, Airtable, Notion, CSV, JSON. Geen pandas, geen code om CSV-bestanden weg te schrijven.
Tijdvergelijking
| Tijd | Python scraper | Thunderbit |
|---|---|---|
| Eerste run | Uren tot dagen (selectors schrijven, paginering, proxies en retry-logica afhandelen) | ~30 seconden met de kant-en-klare Yelp-template |
| Wanneer Yelp de markup wijzigt | Handmatig selectors herschrijven | Opnieuw klikken op AI Suggest Fields — past zich automatisch aan |
| Wanneer je IP geblokkeerd raakt | Debuggen, proxy-pools roteren, opnieuw testen | Cloud-modus handelt IP-rotatie af |
| Export naar Google Sheets | OAuth + pandas-koppeling schrijven | Eén klik, gratis |
Als je Thunderbit eerst probeert en merkt dat het aan je wensen voldoet, kun je de rest van dit artikel overslaan. Als je volledige programmatische controle, custom fields of schaal boven enkele duizenden records per maand nodig hebt — lees dan verder.
Python-bibliotheken voor het scrapen van Yelp: welke kies je?
“Moet ik Scrapy, BS4+requests of Selenium gebruiken?” is een van de meest gestelde vragen in r/webscraping-threads over Yelp. Toch kiest elke tutorial gewoon zijn favoriete bibliotheek en gaat verder, zonder uit te leggen waarom. Hier is de eerlijke afweging.
De realiteit in 2025: requests + BeautifulSoup werkt niet meer voor Yelp
De stack die elke klassieke Yelp-tutorial aanraadt — pip install requests beautifulsoup4 — wordt in 2025 al bij het eerste verzoek geblokkeerd. Niet bij de 50e. Bij de eerste.
De reden: Python’s requests-bibliotheek heeft een TLS/JA3-fingerprint die niet overeenkomt met echte browsers. Yelp’s anti-botlaag herkent dat al op TLS-handshakeniveau, nog voordat je User-Agent-header wordt gelezen. Ik heb dit herhaaldelijk getest — met een vers IP, realistische headers, willekeurige vertragingen — en toch direct een 403 Forbidden gekregen met standaard requests.
De bibliotheekbeslismatrix
| Bibliotheek | Beste voor | Ondersteunt JS? | Anti-bot? | Leercurve | Snelheid |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Zeer laag | Snel (tot blokkade) | |
httpx async + parsel | Grootschalige async scraping | ❌ | ❌ | Laag | Zeer snel |
curl_cffi + parsel | Yelp-specifiek: TLS-impersonatie | ❌ | ✅ TLS/JA3/HTTP2 | Laag | Zeer snel |
Scrapy 2.14 | Volledige crawl-pipelines met paginering | Gedeeltelijk (via scrapy-playwright) | AutoThrottle, retry-middleware | Middel-hoog | Snel |
Selenium 4.43 / Playwright 1.58 | Pagina’s met veel JS, CAPTCHA-workarounds | ✅ | Gedeeltelijk | Middel | Traag (~10–30 pagina’s/min) |
| Thunderbit | Niet-programmeurs, snelle extractie | ✅ (browser) | Ingebouwd (Cloud-modus) | Zeer laag | Snel |
De curl_cffi-doorbraak
De bibliotheek die mijn Yelp-scrapingworkflow echt veranderde, is — een Python-binding voor curl-impersonate. Die geeft exact dezelfde TLS/JA3- en HTTP/2-fingerprint als echte Chrome, en de API is een bijna directe vervanging van requests:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))Met die ene wijziging — from curl_cffi import requests plus impersonate="chrome131" — omzeil je Yelp’s zonder een browser te starten. In mijn tests is dat het verschil tussen directe 403’s en nette 200-responses.
Mijn aanbevolen stack voor Yelp in 2025: curl_cffi + parsel + jmespath + residential proxies. Als je een volledige crawl-pipeline met planning nodig hebt, wikkel het dan in Scrapy 2.14 met een downloader-middleware gebaseerd op curl_cffi.
Je Python-omgeving instellen om Yelp te scrapen
- Moeilijkheidsgraad: Gemiddeld
- Benodigde tijd: ~15 minuten voor de setup, 1–2 uur voor een werkende scraper
- Wat je nodig hebt: Python 3.10+ (3.12 aanbevolen), een terminal en optioneel een residential proxyprovider
Stap 1: Maak een virtuele omgeving aan en installeer packages
1python3.12 -m venv .venv
2source .venv/bin/activate # Op Windows: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasWat elk pakket doet:
curl_cffi— doet HTTP-verzoeken met Chrome’s TLS-fingerprint (de anti-bot-omzeiling)parsel— CSS/XPath-selectors voor het parseren van HTML (zelfde engine als Scrapy, maar lichter)jmespath— declaratieve JSON-query’s (netter dan diep geneste dict-toegang voor Yelp’s embedded JSON)pandas— data exporteren naar CSV/Excel
Optioneel maar handig:
1pip install fake-useragent # Let op: de repo is in april 2026 gearchiveerd, maar nog steeds te installerenStap voor stap: hoe je Yelp scrapt met Python
Dit is de kern van de tutorial. De belangrijkste insight voor meer robuustheid: sla CSS-selectors over en haal verborgen JSON op. Yelp randomiseert CSS-klassen bij elke build (y-css-14xwok2 de ene week, y-css-hcq7b9 de volgende), dus elke scraper die daarop leunt, breekt binnen enkele weken. De ingesloten JSON-payloads — application/ld+json schema en react-root-props — zijn stabiel.
Stap 2: Scrape Yelp-zoekresultaten
Yelp-zoek-URL’s volgen een voorspelbaar patroon: https://www.yelp.com/search?find_desc={term}&find_loc={location}. De data uit de zoekresultaten zit als JSON in een <script data-id="react-root-props">-tag — niet verstopt in een soep van CSS-klassen.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4HEADERS = {
5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
6 "AppleWebKit/537.36 (KHTML, like Gecko) "
7 "Chrome/124.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
9 "image/avif,image/webp,image/apng,*/*;q=0.8",
10 "accept-language": "en-US,en;q=0.9",
11 "accept-encoding": "gzip, deflate, br",
12 "cookie": "intl_splash=false",
13}
14def scrape_search(term: str, location: str, max_pages: int = 3):
15 results = []
16 for page in range(max_pages):
17 url = (f"https://www.yelp.com/search?"
18 f"find_desc={term}&find_loc={location}&start={page * 10}")
19 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
20 if r.status_code != 200:
21 print(f"Geblokkeerd op pagina {page}: {r.status_code}")
22 break
23 sel = Selector(text=r.text)
24 script = sel.xpath(
25 "//script[@data-id='react-root-props']/text()"
26 ).get() or ""
27 m = re.search(r"react_root_props\s*=\s*(\{.*?\});", script, re.S)
28 if not m:
29 print(f"Geen react-root-props gevonden op pagina {page} — mogelijk soft block")
30 break
31 data = json.loads(m.group(1))
32 businesses = jmespath.search(
33 "legacyProps.searchAppProps.searchPageProps"
34 ".mainContentComponentsListProps"
35 "[?searchResultBusiness].searchResultBusiness.{"
36 "name: name, url: businessUrl, rating: rating, "
37 "reviews: reviewCount, phone: phone, "
38 "neighborhoods: neighborhoods}",
39 data,
40 ) or []
41 results.extend(businesses)
42 import time, random
43 time.sleep(random.uniform(3, 7))
44 return resultsJe zou een lijst met dicts moeten krijgen met bedrijfsnamen, URL’s, ratings en aantallen reviews. Als react-root-props ontbreekt in het antwoord, dan heb je een block shell gekregen — roteer je IP en probeer opnieuw.
De header Cookie: intl_splash=false is een standaard workaround voor Yelp’s land-splash-redirect. Zonder die header komen niet-Amerikaanse IP’s op een splashpagina uit die op een soft block lijkt, maar dat niet is.
Stap 3: Scrape Yelp-bedrijfspagina’s
Elke bedrijfs-URL uit de zoekresultaten leidt naar een detailpagina met rijkere data. Het meest stabiele extractiedoel is het <script type="application/ld+json">-blok — daarin staat gestructureerde schema.org-data die Yelp voor SEO onderhoudt en niet obfusceert.
1def scrape_business(biz_url: str) -> dict:
2 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
3 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
4 if r.status_code != 200:
5 return {"url": url, "error": r.status_code}
6 sel = Selector(text=r.text)
7 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
8 for raw in sel.css('script[type="application/ld+json"]::text').getall():
9 try:
10 data = json.loads(raw)
11 except json.JSONDecodeError:
12 continue
13 for node in (data if isinstance(data, list) else [data]):
14 if node.get("@type") in (
15 "Restaurant", "LocalBusiness", "FoodEstablishment",
16 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
17 ):
18 return {
19 "biz_id": biz_id,
20 "name": node.get("name"),
21 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
22 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
23 "address": node.get("address"),
24 "telephone": node.get("telephone"),
25 "price_range": node.get("priceRange"),
26 "hours": node.get("openingHours"),
27 "url": url,
28 }
29 return {"biz_id": biz_id, "url": url}De waarde van meta[name="yelp-biz-id"] is de gecodeerde business-ID die je nodig hebt voor het reviews-endpoint. Haal die hier op — je gebruikt hem in de volgende stap.
Stap 4: Scrape Yelp-reviews met paginering
Hier schiet de Fusion API tekort en blinkt scraping uit. Yelp’s interne GraphQL batch-endpoint geeft volledige reviewtekst, gegevens van reviewers, datums, ratings en stem-aantallen terug — alles wat de API achterhoudt.
Het endpoint is https://www.yelp.com/gql/batch, en het gebruikt een statische documentId voor de GetBusinessReviewFeed-operatie. Paginering werkt via een base64-gecodeerde cursor.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4def fetch_reviews(enc_biz_id: str, num_pages: int = 5):
5 all_reviews = []
6 for page in range(num_pages):
7 offset = page * 10
8 cursor = base64.b64encode(
9 json.dumps({"version": 1, "offset": offset}).encode()
10 ).decode()
11 payload = [{
12 "operationName": "GetBusinessReviewFeed",
13 "variables": {
14 "encBizId": enc_biz_id,
15 "reviewsPerPage": 10,
16 "after": cursor,
17 "sortBy": "DATE_DESC",
18 "language": "en",
19 },
20 "extensions": {
21 "operationType": "query",
22 "documentId": DOC_ID,
23 },
24 }]
25 r = requests.post(
26 GQL_URL,
27 json=payload,
28 headers={
29 **HEADERS,
30 "content-type": "application/json",
31 "x-apollo-operation-name": "GetBusinessReviewFeed",
32 "apollographql-client-name": "yelp-main-frontend",
33 },
34 impersonate="chrome131",
35 )
36 if r.status_code != 200:
37 print(f"Review-opvraag mislukt bij offset {offset}: {r.status_code}")
38 break
39 data = r.json()
40 # Navigeer door de responsstructuur om reviews te extraheren
41 try:
42 reviews = data[0]["data"]["business"]["reviews"]["edges"]
43 for edge in reviews:
44 node = edge.get("node", {})
45 all_reviews.append({
46 "reviewer": node.get("author", {}).get("displayName"),
47 "rating": node.get("rating"),
48 "date": node.get("localizedDate"),
49 "text": node.get("text", {}).get("full"),
50 })
51 except (KeyError, IndexError, TypeError):
52 break
53 import time, random
54 time.sleep(random.uniform(3, 7))
55 return all_reviewsElke pagina levert 10 reviews op. Verhoog de offset in de base64-cursor om te pagineren. De parameter sortBy accepteert DATE_DESC (nieuwste eerst), RATING_ASC, RATING_DESC en andere waarden.
Stap 5: Exporteer je gescrapete Yelp-data
1import pandas as pd
2# Stel dat je businesses en reviews al hebt verzameld
3df_businesses = pd.DataFrame(businesses)
4df_businesses.to_csv("yelp_businesses.csv", index=False)
5df_reviews = pd.DataFrame(all_reviews)
6df_reviews.to_csv("yelp_reviews.csv", index=False)
7# Of sla het op als JSON voor meer flexibiliteit
8import json
9with open("yelp_data.json", "w") as f:
10 json.dump({"businesses": businesses, "reviews": all_reviews}, f, indent=2)Voor lezers die de no-code-route kiezen, exporteert Thunderbit dezelfde data rechtstreeks naar Excel, Google Sheets, Airtable of Notion — zonder pandas of code om bestanden weg te schrijven.
Het anti-blokplan: hoe je Yelp scraped zonder geblokkeerd te worden
Dit onderdeel is precies waarom dit artikel bestaat. Yelp’s anti-botmaatregelen zijn sinds eind 2024 flink strenger geworden — spelen allemaal mee. De meeste bestaande gidsen zijn achterhaald omdat ze vóór deze aanpak zijn geschreven.
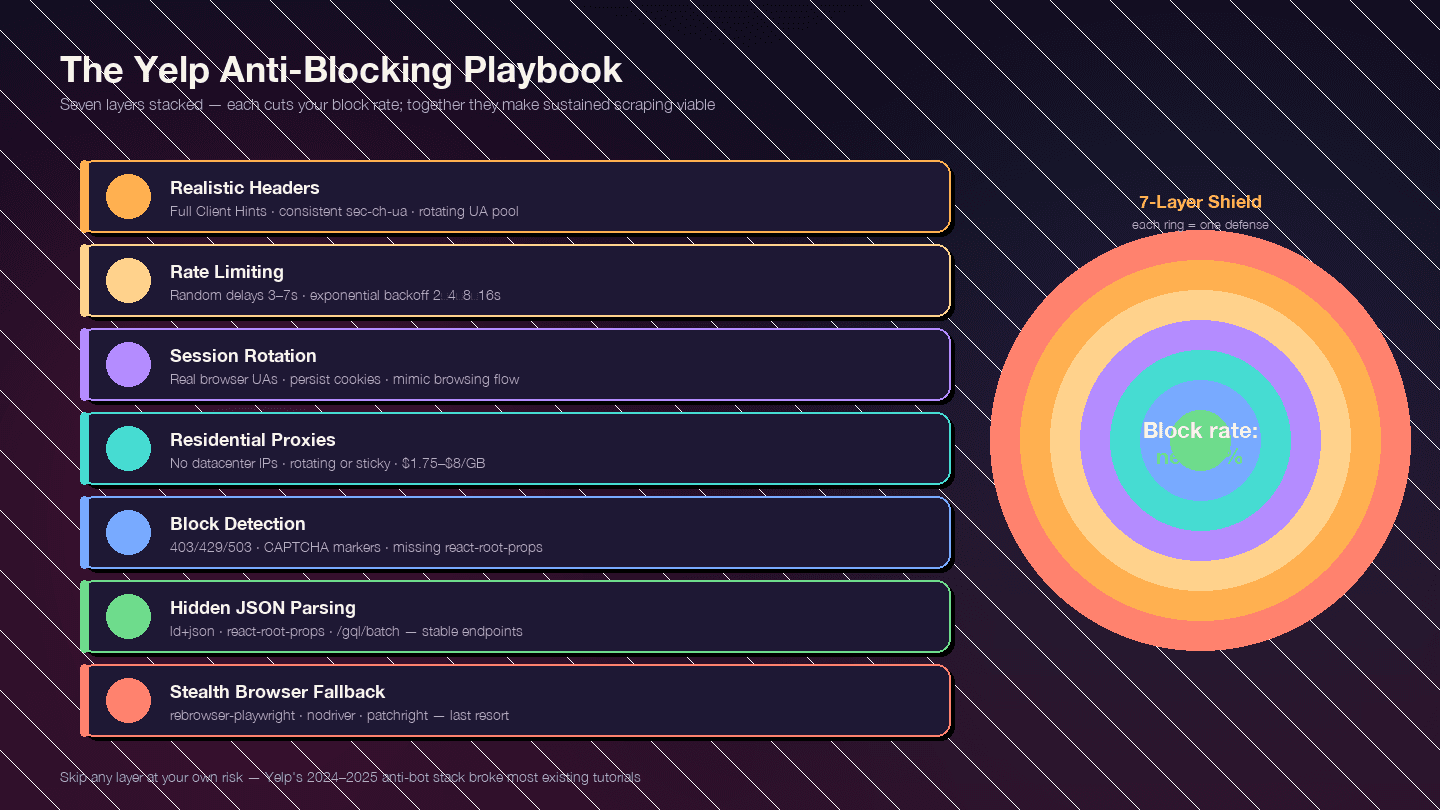
De strategie is gelaagd. Elke laag verlaagt je blokkadepercentage; samen maken ze duurzaam scrapen haalbaar.
Laag 1: Realistische request-headers
Standaard Python requests-headers sturen User-Agent: python-requests/2.x — direct geblokkeerd. Maar zelfs een realistische User-Agent is niet genoeg. Yelp controleert de volledige set headers op consistentie.
1FULL_HEADERS = {
2 "authority": "www.yelp.com",
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36",
6 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
7 "image/avif,image/webp,image/apng,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 "accept-encoding": "gzip, deflate, br",
10 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
11 "sec-ch-ua-mobile": "?0",
12 "sec-ch-ua-platform": '"Windows"',
13 "sec-fetch-dest": "document",
14 "sec-fetch-mode": "navigate",
15 "sec-fetch-site": "same-origin",
16 "sec-fetch-user": "?1",
17 "upgrade-insecure-requests": "1",
18 "referer": "https://www.yelp.com/",
19 "cookie": "intl_splash=false",
20}Drie fouten waardoor je meteen verdacht bent:
- De UA zegt Chrome, maar
sec-ch-uaontbreekt of botst met de browser-versie sec-ch-ua-platformzegt "Windows", maar de UA-string zegt macOS- Exact dezelfde UA op duizenden requests vanaf één IP — roteer een pool van 10–20 recente Chrome/Firefox/Safari-strings
Laag 2: Rate limiting en willekeurige vertragingen
Voorspelbare timingpatronen zijn een alarmsignaal. Voeg willekeurige slaapintervallen toe en implementeer exponentiële backoff bij foutresponses.
1import random, time
2def polite_get(client_get, url, attempt=0):
3 r = client_get(url, headers=FULL_HEADERS, impersonate="chrome131")
4 if r.status_code in (403, 429, 503):
5 if attempt >= 4:
6 raise RuntimeError(f"Geblokkeerd na {attempt + 1} pogingen op {url}")
7 backoff = 2 ** (attempt + 1) + random.random()
8 print(f" Kreeg {r.status_code}, backoff {backoff:.1f}s (poging {attempt + 1})")
9 time.sleep(backoff)
10 return polite_get(client_get, url, attempt + 1)
11 time.sleep(random.uniform(3, 7))
12 return r| Parameter | Aanbevolen waarde |
|---|---|
| Willekeurige slaap tussen requests | random.uniform(3, 7) seconden |
| Backoff bij 429/403/503 | 2 → 4 → 8 → 16 s, max. 5 pogingen |
| Gelijktijdige workers per IP | 1 (serialiseer per IP; gebruik proxies voor parallelisme) |
| Maximale duurzame snelheid per residential IP | ~1 request / 5 s (~12 rpm) |
Laag 3: User-Agent- en sessierotatie
Roteer door een pool van echte browser-User-Agents. Behoud sessies en cookies om echt surfgedrag te simuleren — Yelp gebruikt cookie-gebaseerde detectie, dus voor elk verzoek een volledig nieuwe sessie aanmaken is op zichzelf al verdacht.
1UA_POOL = [
2 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
3 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
6 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
7 # Voeg nog 5-10 recente strings toe
8]Laag 4: Proxy-rotatie
Bij echt volume heb je residential proxies nodig. Datacenter- en gratis proxies werken niet op Yelp — Yelp’s IP-reputatielaag geeft AWS-, GCP- en DigitalOcean-IP’s preventief een 403.
| Provider | Instapprijs $/GB | Opmerking |
|---|---|---|
| IPRoyal | $1,75/GB | Goedkoopste; draait de meest geciteerde Yelp-tutorial |
| Decodo (ex-Smartproxy) | $3,20–$3,50 | Beste GB/$-verhouding op schaal |
| Bright Data | $4,00 (PAYG) | Pool van 150M+ IP’s; speciale Yelp Proxies-pagina |
| Oxylabs | $6,00–$8,00 | Premium; 10M+ IP’s |
| Aluvia (mobile SIM) | $3,00 | Echte mobiele IP’s van Amerikaanse carriers, speciaal gepositioneerd voor Yelp |
Roterende residential proxies (een nieuw IP per request) werken het best voor crawls met hoge volumes. Sticky sessions (één IP 10 minuten vasthouden) zijn beter wanneer je cookies wilt behouden over een flow van bedrijfspagina → reviews → paginering.
Laag 5: Blokkades detecteren en afhandelen
Niet elke blokkade ziet er hetzelfde uit. Yelp serveert vaak een generieke “page not available”-shell in plaats van een CAPTCHA, waardoor naïeve scrapers denken dat ze data krijgen terwijl ze in werkelijkheid lege responses ontvangen.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # Als dit een search- of businesspagina is maar react-root-props ontbreekt,
12 # heeft Yelp een gestript blokantwoord geleverd
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Signaal | Betekenis |
|---|---|
| HTTP 403 | Harde blokkade — IP/header/TLS verbrand |
| HTTP 429 | Rate limited — vaak herstelbaar met backoff |
| HTTP 503 | Algemene blokkade of load shedding |
Redirect naar /error of body met “page not available” | Soft block |
| Lege met alleen | Challengepagina wacht op JS |
captcha / g-recaptcha / px-captcha in body | Escalatie — CAPTCHA vereist |
Ontbrekende react-root-props op een listingpagina | Gestript blokantwoord |
Laag 6: De robuuste parsingtruc — verborgen JSON boven CSS-selectors
Nogmaals: Yelp randomiseert CSS-klassen bij elke build. Een scraper die vastzit op h3.y-css-14xwok2 breekt binnen weken wanneer Yelp opnieuw uitrolt met h3.y-css-hcq7b9.
De payloads die niet veranderen:
<script type="application/ld+json">— schema.org-gestructureerde data (naam, adres, telefoon, rating, openingstijden)<script data-id="react-root-props">— volledige zoekresultaten als JSONhttps://www.yelp.com/gql/batch— GraphQL reviews-endpoint met een stabieledocumentId
Als je CSS-klassen parseert, bouw je op drijfzand. Parse in plaats daarvan de JSON.
Laag 7: De stealth browser fallback
Schakel alleen over naar een headless browser wanneer curl_cffi + residential proxies er niet doorheen komen — meestal wanneer Yelp een JavaScript-challenge of CAPTCHA toont.
Voor 95% van het scrapen van bedrijven/zoekresultaten/reviews is curl_cffi + verborgen JSON + residential proxies sneller, goedkoper en betrouwbaarder dan een browser. Maar als je toch een browser nodig hebt:
| Tool | Status (2025) | Opmerking |
|---|---|---|
| rebrowser-playwright | Aanbevolen startpunt | Direct bruikbare Playwright-patch om CDP-lekken te verhelpen |
| nodriver | Beste in zijn klasse voor Chrome-stealth | Opvolger van undetected-chromedriver; vermijdt het WebDriver-protocol volledig |
| patchright | Actief onderhouden Playwright-fork | Slaat moderne detectietests door |
| playwright-stealth | Volwassen | Patcht navigator.webdriver, verwijdert HeadlessChrome uit de UA |
Sla vanilla Selenium over voor Yelp. Het is te makkelijk te fingerprinten.
Yelp Fusion API vs. Python scraping vs. Thunderbit: volledige vergelijking
| Dimensie | Yelp Fusion API | Python scraping | Thunderbit |
|---|---|---|---|
| Volledige reviewtekst | ❌ 3 fragmenten × ~160 tekens | ✅ Onbeperkt (GraphQL) | ✅ Ingebouwde reviewtemplate |
| Reviewmetadata (votes, reacties van eigenaars) | ❌ | ✅ | ✅ Via AI-voorgestelde velden |
| Foto’s | ❌ (0 op Base) | ✅ Onbeperkt | ✅ |
| Max. resultaten per zoekopdracht | 240 (was 1.000 vóór 2024) | Onbeperkt (gepagineerd) | Onbeperkt |
| Dagelijkse rate limit | 300–500 (nieuw) / 5.000 (legacy) | Alleen proxybudget | Credit-based (3.000/maand op Pro) |
| Opzetinspanningen | ~15 min | Uren tot dagen | ~2 minuten |
| Anti-botafhandeling | N.v.t. | Jouw probleem | Afgehandeld (Cloud-modus) |
| Juridisch risico | Laag (toegestaan) | Middel (grijs gebied binnen ToS) | Middel (zelfde als scraping) |
| Kosten (instap) | $29/mnd | ~$0,75–$4/GB aan proxies + ontwikkeltijd | Gratis tier |
| Kosten bij zwaar gebruik | $643+/mnd | $50–$500/mnd aan proxies + ontwikkeltijd | $38–$49/mnd |
| Data-export | JSON | CSV/JSON (zelf schrijven) | Excel / Sheets / Airtable / Notion — gratis |
| Onderhoud | Laag | Hoog (selectors breken, anti-bot wordt strenger) | Laag (AI past zich opnieuw aan) |
Juridische en ethische tips voor Yelp-scraping
Ik ben geen advocaat, en dit is geen juridisch advies. Maar het juridische landschap is in de afgelopen twee jaar genoeg veranderd om de basis te kennen voordat je tijd in een Yelp-scrapingproject steekt.
Wat Yelp’s voorwaarden zeggen: De verbiedt expliciet het gebruik van “any robot, spider... or other automated device” om “access, retrieve, copy, scrape, or index any portion of the Service” uit te voeren. Er is ook extra taal toegevoegd over “AI Technologies and/or other automated tools.”
: “Yelp does not allow any scraping of the site.”
Wat robots.txt zegt: Yelp’s heeft een wildcard User-agent: * / Disallow: / en blokkeert specifiek GPTBot, ClaudeBot, PerplexityBot, CCBot en Meta-ExternalAgent. Alleen Googlebot, Bingbot en een paar social-media crawlers staan op de whitelist.
Het relevante juridische precedent: In (N.D. Cal. jan 2024) oordeelde de rechtbank dat het scrapen van publiek beschikbare, uitgelogde data Meta’s voorwaarden niet schond. Het sleutelverschil: publieke data zonder login versus data achter login. De zaak stelde vast dat het scrapen van publieke data waarschijnlijk niet in strijd is met de CFAA, maar hiQ verloor alsnog op staatsrechtelijke claims (trespass to chattels, misappropriation) en kreeg een vonnis van $500.000 opgelegd.
Praktische richtlijnen:
- Scrape alleen publiek beschikbare, uitgelogde pagina’s
- Rate-limit je verzoeken (de vertragingen in deze gids werken ook als ethische rate limits)
- Verkoop geen ruwe reviewtekst opnieuw onder naam van gebruikers — respecteer de privacy van reviewers
- Houd je aan lokale gegevensbeschermingswetten (CCPA, GDPR)
- Log niet in om te scrapen — dan ga je over de autorisatielijn heen
- Behandel bedrijfsinformatie (naam/adres/telefoon/rating) als publieke feitelijke data; beschouw reviewtekst als gevoeliger
Raadpleeg een juridisch professional voor jouw specifieke situatie.
Tot slot
Drie routes, één doel.
De Yelp Fusion API is de geautoriseerde, onderhoudsarme optie — maar hij stopt bij 3 reviewfragmenten en begint bij $29 per maand. Python-scraping geeft je volledige controle over elk datapunt op Yelp, maar vereist serieuze investering: curl_cffi voor TLS-impersonatie, residential proxies, willekeurige vertragingen, het parsen van verborgen JSON en doorlopend onderhoud naarmate Yelp’s verdediging evolueert. Thunderbit brengt je in ongeveer 30 seconden van “ik heb Yelp-data nodig” naar “hier is mijn spreadsheet”, zonder code en zonder proxyconfiguratie.
De anti-blokbasis die in 2025 echt werkt: realistische headers met volledige Client Hints, curl_cffi voor TLS-fingerprint-impersonatie, willekeurige vertragingen met exponentiële backoff, rotatie van residential proxies en — bovenal — verborgen JSON (application/ld+json en react-root-props) parsen in plaats van fragiele CSS-selectors.
Niet zeker welke route bij je past? Probeer eerst . Als dat genoeg is, heb je jezelf uren werk bespaard. Heb je meer controle nodig — volledige programmatische pipelines, custom fields, strakke CRM-integratie — dan helpt de Python-gids hierboven je verder. En voor een bredere blik op het landschap van scrapingtools, bekijk onze roundup van de of onze gids over .
Veelgestelde vragen
Kan ik Yelp gratis scrapen met Python?
Ja — met gratis bibliotheken zoals curl_cffi, parsel en jmespath. Maar bij echt volume (meer dan een paar dozijn pagina’s) heb je betaalde residential proxies nodig, die beginnen rond . Thunderbit biedt ook een gratis tier met 6 pagina’s per maand voor snelle, no-code extractie.
Blokkeert Yelp scrapers?
Ja, agressief. Yelp gebruikt . Standaard requests wordt al bij de eerste hit geblokkeerd. De gelaagde anti-blokstrategie in deze gids — curl_cffi voor TLS-impersonatie, realistische headers, willekeurige vertragingen en residential proxies — is wat in 2025 werkt.
Is de Yelp Fusion API beter dan scrapen?
Dat hangt af van je behoeften. De API is toegestaan en heeft weinig risico, maar hij levert alleen , beperkt zoekresultaten tot 240 en begint bij $29 per maand. Als je volledige reviewtekst, reviewmetadata of meer dan een paar honderd records per dag nodig hebt, is scrapen de enige optie.
Hoe scrape ik Yelp-reviews met Python?
Gebruik curl_cffi met impersonate="chrome131" om de bedrijfspagina op te halen, haal de gecodeerde business-ID uit <meta name="yelp-biz-id">, en POST vervolgens naar https://www.yelp.com/gql/batch met de GetBusinessReviewFeed-operatie en pagineer via een base64-gecodeerde after-cursor. De code stap voor stap staat hierboven in de tutorialsectie. De is ook een solide referentie-implementatie.
Kan ik Yelp scrapen zonder te coderen?
Ja — levert vooraf gebouwde - en -templates. Open een Yelp-pagina, klik op AI Suggest Fields, klik op Scrape. Export naar Google Sheets, Excel, Airtable en Notion is gratis op elk plan, inclusief het gratis plan.
Meer weten