Walmart past de prijzen van sommige artikelen aan. Als je ooit hebt geprobeerd dat programmatisch bij te houden, ken je de frustratie: je script werkt 20 minuten en begint daarna stilletjes CAPTCHA-pagina's terug te geven die eruitzien als normale 200 OK-responses.
Ik heb veel tijd besteed aan het doorgronden van Walmart's anti-botverdediging als onderdeel van ons data-extractiewerk bij , en ik wil alles delen wat ik heb geleerd — de methoden die in 2025 echt werken, de stille fouten die je data verpesten, en de eerlijke afwegingen tussen je eigen scraper schrijven, betalen voor een scraping API, of gewoon een no-code tool gebruiken. Deze gids behandelt drie extractiemethoden (HTML-parsing, __NEXT_DATA__-JSON en interceptie van interne API's), foutafhandeling die productie aankan en die de meeste tutorials volledig overslaan, en een nuchter besliskader om de juiste aanpak te kiezen. Er zit hier iets tussen, of je nu Python schrijft of gewoon vóór de lunch een spreadsheet vol prijzen wilt hebben.
Waarom Walmart schrapen met Python?
Walmart is wereldwijd de grootste retailer op omzet — in FY2025, en staat . De site host ruwweg , terwijl Walmart's CFO sprak over op de marketplace. Ongeveer , wat betekent dat de catalogus voortdurend verandert — verkopers komen en gaan, varianten wijzigen en voorraad verschuift dagelijks.
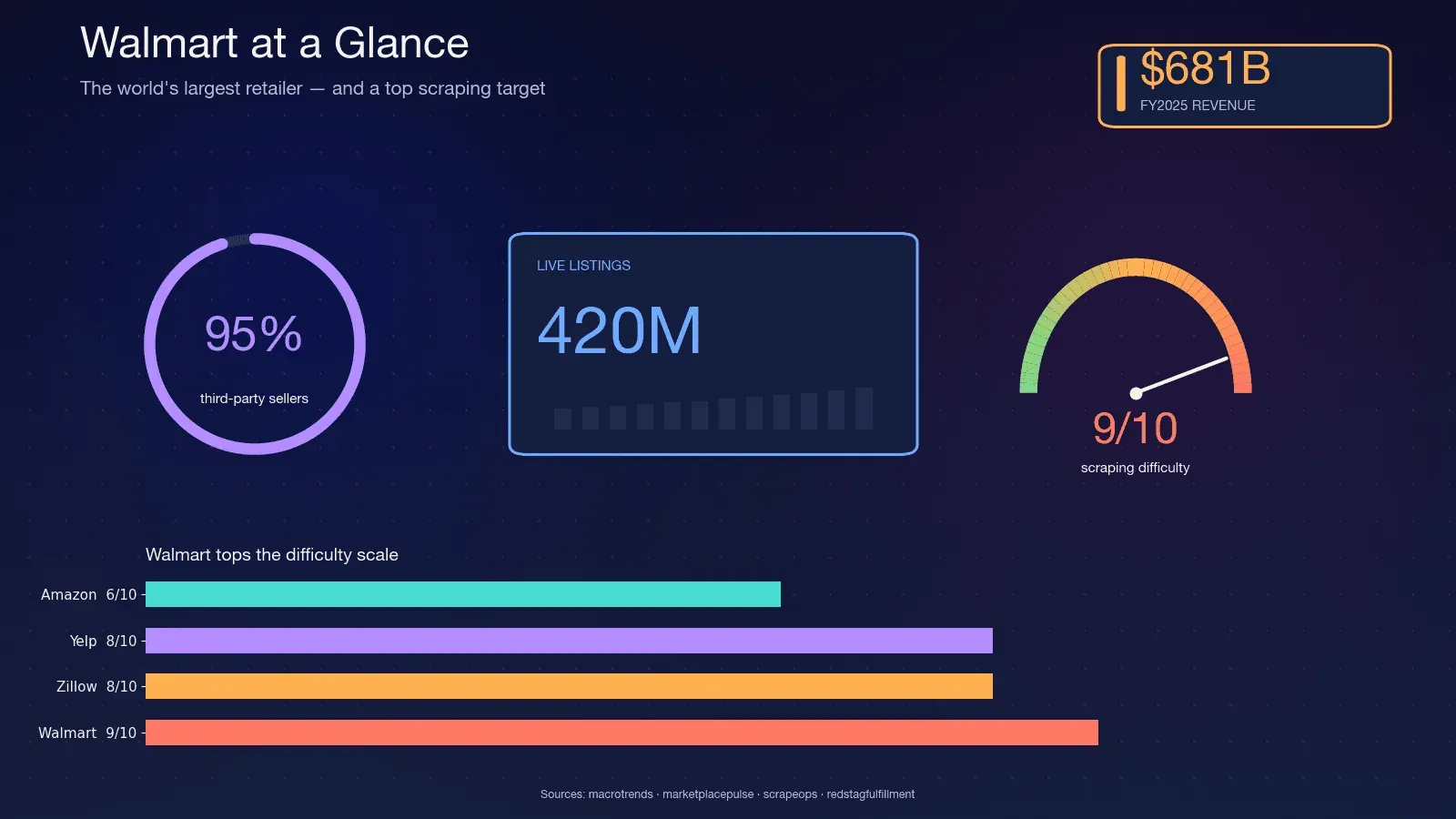
Juist die volatiliteit maakt scraping belangrijk. Een kwartaalrapport vangt niet wat een nachtelijke scrape wel kan vastleggen. Dit zijn de meest voorkomende toepassingen die ik zie:
| Toepassing | Wie het nodig heeft | Wat ze extraheren |
|---|---|---|
| Monitoring van concurrentieprijzen | E-commerce operations, repricing-tools | Prijzen, promoties, MAP-naleving |
| Verrijken van productcatalogus | Sales- en merchandisingteams | Beschrijvingen, afbeeldingen, specificaties, varianten |
| Voorraadbeschikbaarheid volgen | Supply chain, dropshippers | Voorraadstatus, verkopersinformatie |
| Marktonderzoek en trendanalyse | Marketing, productmanagers | Beoordelingen, reviews, assortiment per categorie |
| Leadgeneratie | Salesteams | Namen van verkopers, aantallen producten, categorieën |
Alleen al de en wordt naar verwachting $5,09 miljard in 2033. Consumentengedrag drijft die uitgaven: , en 83% vergelijkt prijzen op meerdere sites.
Python is de standaardtaal voor dit werk. Apify's Infrastructure Report 2026 schat , en de kernbibliotheek (requests) wordt . Als je op enige schaal scrape't, doe je het vrijwel zeker in Python.
Waarom Walmart een van de moeilijkste sites is om te schrapen
Walmart is vooral lastig omdat het twee commerciële anti-botproducten achter elkaar gebruikt: als edge-WAF en TLS-fingerprintlaag, en als gedragsmatige JavaScript-uitdagingslaag. Scrape.do noemt die combinatie "zeldzaam en extreem moeilijk te omzeilen".
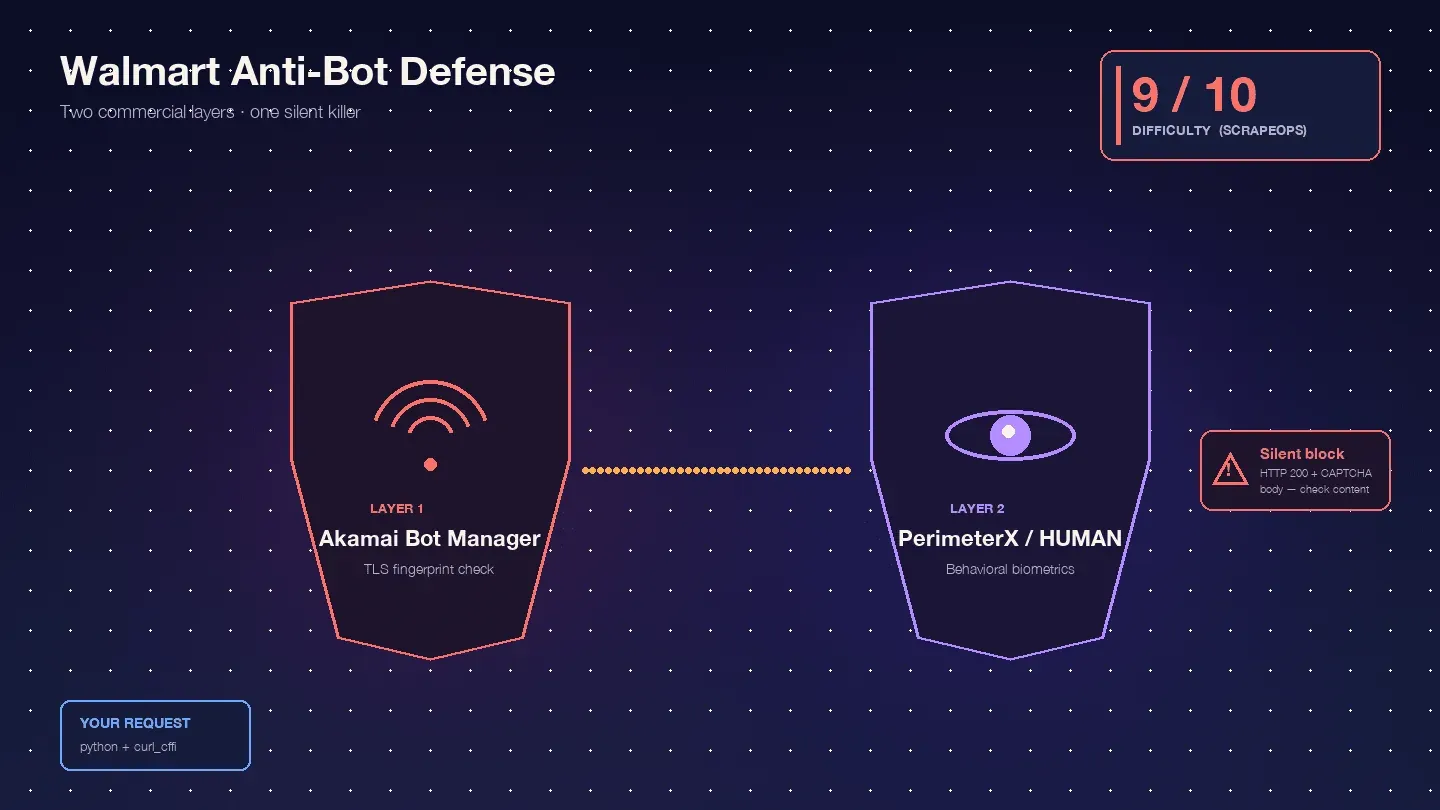
, met Akamai alleen al op 9/10. In mijn ervaring klopt dat aardig.
Dit is waar je in de praktijk tegenaan loopt:
Akamai Bot Manager inspecteert je TLS-fingerprint (JA3/JA4-hash), de volgorde van HTTP/2-frames, de volgorde en hoofdlettergebruik van headers, en sessiecookies (_abck, ak_bmsc). Een standaard Python-requests-call stuurt een TLS-fingerprint uit die geen echte browser produceert — Akamai markeert die al voordat je verzoek de servers van Walmart bereikt.
PerimeterX/HUMAN draait ná Akamai en voert JavaScript-fingerprinting uit (px.js) die navigator-eigenschappen, canvas-rendering, WebGL, audio context en gedragsbiometrie (muisbeweging, scrollsnelheid, toetsaanslagpatronen) controleert. De zichtbare mislukking is de beruchte — een knop die je ongeveer 10 seconden ingedrukt moet houden terwijl gedragsignalen worden gemeten. Oxylabs is daar heel direct over: "Walmart uses the 'Press & Hold' model of CAPTCHA, offered by PerimeterX, which is known to be almost impossible to solve from your code."
Het echt gevaarlijke gedrag is de stille blokkade. Walmart geeft HTTP 200 met een CAPTCHA-body terug in plaats van een 403. : "Walmart returns a 200 OK status code even when it serves a CAPTCHA page. You can't rely on the status code alone to know if your request succeeded." Je script parseert de CAPTCHA-HTML vrolijk als "product niet gevonden" en gaat verder. De helft van je dataset is rommel, en je weet het niet.
Dan is er nog het store-scoped dataprobleem. Walmart-prijzen en voorraad zijn locatiegebonden en worden gestuurd door cookies zoals locDataV3 en assortmentStoreId. Zonder de juiste cookies krijg je "standaard nationale" data die er compleet uitziet maar niet overeenkomt met wat echte shoppers zien. Ontbrekende cookies leveren geen blokpagina op — ze leveren verkeerde data zonder zichtbare fout op, en dat is erger.
Drie methoden om data van Walmart te extraheren (en hoe ze zich verhouden)
Voordat we stap voor stap aan de slag gaan: dit zijn de drie belangrijkste extractie-aanpakken. De meeste concurrerende tutorials behandelen er maar één of twee. Ik loop ze alle drie door, zodat je de aanpak kunt kiezen die bij jouw situatie past.
| Methode | Betrouwbaarheid | Volledigheid van data | Moeilijkheid anti-bot | Onderhoudsbelasting |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ Laag (selectors breken per deploy) | Matig | Hoog | Hoog |
__NEXT_DATA__ JSON | ✅ Goed | Hoog | Midden-hoog | Gemiddeld |
| Interceptie van interne API's | ✅ Beste | Hoogst (varianten, voorraad, reviews) | Midden-hoog | Laag (gestructureerde JSON) |
| Thunderbit (no-code) | ✅ Goed | Hoog | Laag (afgehandeld door AI) | Geen |
HTML-parsing is de slechtste optie voor Walmart — de site levert Next.js-bundles met gehashte CSS-klassen die bij elke deploy veranderen. De __NEXT_DATA__-JSON-methode is de pragmatische keuze die elke serieuze open-source Walmart scraper uit 2024–2026 gebruikt. Interceptie van interne API's is het krachtigst, maar heeft kanttekeningen die de meeste tutorials gemakshalve overslaan. En Thunderbit is de juiste keuze als je helemaal geen custom pipeline nodig hebt.
Je Python-omgeving instellen om Walmart te schrapen
Dit heb je nodig:
- Moeilijkheidsgraad: Gemiddeld
- Benodigde tijd: ~30 minuten voor de setup, plus codeertijd
- Wat je nodig hebt: Python 3.10+, pip, een code-editor en, voor productiegebruik, een proxyservice of scraping API
Maak je projectmap en virtuele omgeving aan:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # On Windows: venv\Scripts\activateInstalleer de vereiste bibliotheken:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi is in 2025 de standaard voor het scrapen van lastige doelen. Het is een libcurl-binding die exacte browser-TLS-fingerprints kan nabootsen. : "Walmart uses TLS fingerprinting as part of its bot detection, and even setting the User-Agent to simulate a real browser won't bypass it." Gewone requests of httpx komen Akamai niet door, ongeacht de headers die je zet. curl_cffi met impersonate="chrome124" maakt het verschil.
Daarnaast wil je json (ingebouwd), csv (ingebouwd), time, random en logging voor de productiepatronen die we later behandelen.
Stap voor stap: Walmart-productpagina's schrapen met Python
Stap 1: Haal de productpagina van Walmart op
Je eerste taak is een HTTP-verzoek maken dat niet meteen wordt geblokkeerd. Hier is de standaardset headers die in 2024–2026 wordt gebruikt door Scrapfly, Scrapingdog, Oxylabs en ScrapeOps:
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)De parameter impersonate="chrome124" doet hier het zware werk. Die vertelt curl_cffi om precies Chrome 124's TLS ClientHello, HTTP/2-framevolgorde en pseudo-headersequentie te matchen. Zonder dat ziet Akamai een Python-specifieke JA3-hash en blokkeert het je voordat je verzoek ooit de applicatielaag van Walmart bereikt.
Hoe een geblokkeerde response eruitziet: Als je "Robot or human?" ziet in de titel van de response-HTML, of als de response doorstuurt naar walmart.com/blocked, ben je gepakt. Het lastige is dat Walmart vaak een 200-statuscode teruggeeft met de CAPTCHA-body — dus alleen op response.ok vertrouwen is niet genoeg.
Voor elk productie- of herhaald gebruik heb je residential proxies nodig. Datacenter-IP's worden direct verbrand door Akamai's IP-reputatiesysteem. Ik behandel de volledige foutafhandeling en proxystrategie verderop in het productiehoofdstuk.
Stap 2: Parse productdata uit de __NEXT_DATA__-JSON
Walmart.com is een Next.js-applicatie en de server-rendered HTML embedt de volledige hydration-payload in één script-tag: <script id="__NEXT_DATA__" type="application/json">. Dit is de goudmijn.
: "In 2026, Walmart uses Next.js with structured JSON in __NEXT_DATA__ script tags, making hidden data extraction more reliable than traditional CSS selector parsing." Elke prominente open-source Walmart scraper — , , — gebruikt deze methode.
Zo extraheer je het:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})De meeste tutorials stoppen hier. Hieronder staat een volledige JSON-padmapping voor de velden die je echt nodig hebt — geverifieerd op live Walmart-pagina's in 2024–2026:
| Dataveld | JSON-pad (onder initialData) | Type | Opmerkingen |
|---|---|---|---|
| Productnaam | data > product > name | String | — |
| Merk | data > product > brand | String | — |
| Huidige prijs (nummer) | data > product > priceInfo > currentPrice > price | Float | Kan per store-cookie verschillen |
| Huidige prijs (string) | data > product > priceInfo > currentPrice > priceString | String | Geformatteerd, bijvoorbeeld "$9.99" |
| Korte beschrijving | data > product > shortDescription | HTML-string | Parse met BeautifulSoup voor tekst |
| Lange beschrijving | data > idml > longDescription | HTML-string | Staat op idml, NIET binnen product — dit is de valkuil waar oudere tutorials de mist in gaan |
| Alle afbeeldingen | data > product > imageInfo > allImages | Array | Lijst van objecten {id, url} |
| Gemiddelde beoordeling | data > product > averageRating | Float | De sleutel is averageRating, niet het oudere rating |
| Aantal reviews | data > product > numberOfReviews | Integer | — |
| Varianten | data > product > variantCriteria | Array | Optiegroepen (maat, kleur) |
| Beschikbaarheid | data > product > availabilityStatus | String | IN_STOCK, OUT_OF_STOCK, LIMITED_STOCK |
| Verkoper | data > product > sellerDisplayName | String | — |
| Fabrikant | data > product > manufacturerName | String | — |
Het longDescription-pad is de valkuil waar mensen over struikelen. Een blogpost van ScrapeHero uit 2023 plaatste het onder product.longDescription, maar bronnen vanaf 2024 plaatsen het consequent op de zusterkey idml. Lees altijd eerst idml.longDescription en val voor oudere pagina's terug op product.longDescription.
Hier is het veilige extractiepatroon met .get()-ketens:
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }Voor gebruikers die helemaal geen JSON-padnavigatie willen, identificeert en structureert deze velden automatisch — handmatige padmapping is niet nodig. Je klikt op "AI Suggest Fields", de tool leest de pagina en je krijgt een tabel. Maar als je een custom pipeline bouwt, is de mapping hierboven je referentie.
Stap 3: Intercepteer Walmart's interne API-endpoints voor rijkere data
Geen enkel concurrerend artikel behandelt deze methode goed. Het is het krachtigste extractiepad — en het meest ingewikkelde.
Walmart's front-end roept een . De endpoints leven onder www.walmart.com/orchestra/*:
/orchestra/pdp/graphql/...— productdetail-hydratatie + variantwissels/orchestra/snb/graphql/...— zoek-en-browse-paginering/orchestra/reviews/graphql/...— gepagineerde reviews
Deze geven schone, gestructureerde JSON terug met data die __NEXT_DATA__ soms afkapt — prijzen op variantniveau, realtime voorraadaantallen, volledige review-paginering.
De adder onder het gras waar blogposts omheen dansen: Walmart gebruikt . De request body stuurt alleen een SHA-256-hash (persistedQuery.sha256Hash) mee, niet de querytekst. Als die hash niet bekend is op de server, krijg je PersistedQueryNotFound. Walmart roteert die hashes bij deploys. Daarom publiceren geen van de bekende open-source Walmart scrapers copy-pastebare /orchestra/-code.
De praktische, eerlijke versie van deze methode is een oefening in DevTools:
- Open een Walmart-productpagina in Chrome
- Open DevTools → Network-tab, filter op "Fetch/XHR"
- Navigeer normaal door de pagina — klik op varianten, scroll naar reviews, wijzig de storelocatie
- Let op requests naar
/orchestra/*-endpoints die JSON met productdata teruggeven - Klik met rechts op de request → "Copy as cURL"
- Zet het cURL-commando om naar Python met
curl_cffi
Zo ziet een herhaalde API-call eruit:
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# Eerst de sessie opwarmen door de productpagina te bezoeken
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# Daarna de interne API-call herhalen (gekopieerd uit DevTools)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "your-copied-correlation-id",
14}
15payload = {
16 # Plak hier exact de request body uit DevTools
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "the-hash-you-copied"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()De sessie-opwarmstap is cruciaal. Walmart's PerimeterX-cookies (_px3, _pxhd, ACID) moeten door de eerste HTML-fetch gezet worden voordat de API-call kan slagen. Zonder die cookies krijg je een 412 of 403.
Wanneer je deze methode gebruikt: Als je data nodig hebt die __NEXT_DATA__ niet bevat — diepe variantprijzen, gepagineerde reviews voorbij de eerste batch, of realtime voorraadniveaus. Voor de meeste gebruikssituaties is __NEXT_DATA__ voldoende en veel eenvoudiger.
Walmart-zoekresultaten en meerdere pagina's schrapen
Zoekresultaten volgen een vergelijkbaar __NEXT_DATA__-patroon, maar met een ander JSON-pad:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# Gesponsorde producten eruit filteren
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))Paginering werkt door de parameter page op te hogen: &page=1, &page=2, enzovoort. Maar hier zit de ongedocumenteerde limiet: Walmart beperkt zoekresultaten tot 25 pagina's, ongeacht het werkelijke totaal. : "Walmart sets the maximum number of result pages that can be accessed to 25 regardless of the total number of pages available."
Workarounds om dieper te gaan:
- Sorteervolgorde omwisselen: voer dezelfde query uit met
&sort=price_lowen daarna met&sort=price_highom ongeveer 50 pagina's dekking te krijgen - Prijsklassen splitsen: voeg
&min_price=X&max_price=Ytoe om de catalogus in kleinere vensters op te delen - Categorieën splitsen: zoek binnen specifieke categorieën in plaats van sitebreed
Let op: itemStacks is een array. Scrapfly hardcodeert [0] in hun repo, maar categorie- en browsepagina's bevatten soms meerdere stacks ("Top picks," "More results"). Het robuuste patroon loopt alle stacks af:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # verwerk item
5 passOok het vermelden waard: Walmart's robots.txt . Productdetailpagina's (/ip/...) en de meeste categoriepagina's (/cp/...) zijn niet uitgesloten. Als je je zorgen maakt over naleving, begin dan met productpagina's en categorietakken in plaats van zoekresultaten.
Laat stille blokkades je data niet verpesten: foutafhandeling die productie aankan
De meeste tutorials vallen hier uit elkaar. Ze laten zien hoe je één pagina ophaalt, één product parse't en het daarbij laat. In productie haal je duizenden pagina's op, en Walmart probeert je actief te stoppen. Het verschil tussen een demo-scraper en een scraper die echt werkt, is hoe die met fouten omgaat.
Detecteer stille blokkades voordat ze je data corrumperen
De belangrijkste functie in een Walmart-scraper is de block-detector. Op basis van consensus tussen , , en heb je vier onafhankelijke controles nodig:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. Redirect naar het speciale blok-endpoint
10 if "/blocked" in str(response.url):
11 return True
12 # 2. Harde statuscodes
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK met CAPTCHA-body (het geval van stille blokkade)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. Controle op responslengte — echte PDP's zijn 300-900 KB
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return FalseDie vierde controle — responslengte — vangt gevallen waarin Walmart een uitgeklede pagina teruggeeft die geen duidelijke CAPTCHA-markers bevat, maar ook niet de productdata die je nodig hebt.
Retry-logica met exponentiële backoff en jitter
Als een verzoek mislukt, wil je Walmart niet meteen opnieuw bestoken. Het standaardpatroon gebruikt exponentiële backoff met jitter om retries te ontkoppelen:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttled: \{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("Stille blokkade gedetecteerd")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"Poging {attempt + 1} mislukt: \{e\}. Opnieuw proberen over {wait:.1f}s")
20 time.sleep(wait)
21 return NoneDe jitter (random.uniform(0, 3)) is niet cosmetisch — die ontkoppelt workers zodat een vloot scrapers niet allemaal in dezelfde seconde opnieuw proberen en Akamai's snelheidsdetectoren triggeren.
Rate limiting
Zowel als komen uit op een gerandomiseerde vertraging van 3–6 seconden per request voor Walmart: "throttle your requests by waiting 3–6 seconds between page loads and randomize your delays."
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return responseOp schaal kun je aiolimiter overwegen voor async rate limiting:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 10 requests per minuteDatavalidatie
Zelfs als de response niet geblokkeerd is, kan de geparste data verkeerd zijn (verkeerde store, verslechterde payload). Valideer vóór je naar output schrijft:
1def validate_product(product):
2 """Geeft True terug als de productdata legitiem lijkt."""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return TrueSessielogging
Houd je succespercentage per sessie bij. Wanneer dat 10 minuten lang onder 80% zakt, is er iets veranderd — je IP is gebrand, je cookies zijn verlopen, of Walmart heeft een nieuwe anti-botregel uitgerold.
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"Succespercentage is gedaald naar {self.success_rate:.1f}% — overweeg proxies te roteren of te pauzeren")Niet glamoureus. Maar wel wat je data schoon houdt.
DIY Python versus scraping API versus no-code: de juiste aanpak kiezen om Walmart te schrapen
Veel ontwikkelaars duiken meteen in het schrijven van een custom scraper zonder zich af te vragen of dat wel de juiste keuze is. . Forumgebruikers noemen het "basically 9/10" en vragen zich af "if a dedicated web scraping API would be overkill." Het antwoord hangt af van volume, budget en engineeringcapaciteit.
| Factor | DIY Python (requests + proxies) | Scraping API (Oxylabs, Bright Data, enz.) | No-code tool (Thunderbit) |
|---|---|---|---|
| Setup-tijd tot eerste rij | Uren | 15–60 min | ~2 min |
| Setup-tijd tot productie | 40–80 uur | 4–16 uur | ~30 min |
| Afhandeling anti-bot | Jij beheert het (moeilijk) | Door provider afgehandeld | Automatisch afgehandeld |
| Kosten op kleine schaal (<1K pagina's/maand) | Laag (proxykosten ~$4–8/GB) | Instaptarieven $40–$49/maand | Gratis–$15/maand |
| Kosten op schaal (100K+ pagina's/maand) | Lagere kosten per request | Hogere kosten per request | Variabel |
| Aanpasbaarheid | Volledige controle | API-parameters | Beperkt door UI/velden |
| Doorlopend onderhoud | 4–8 uur/maand | Bijna nul | Geen (AI past zich aan) |
| Beste voor | Ontwikkelaars die custom pipelines bouwen | Productiescraping op middenschaal | Zakelijke gebruikers, snelle eenmalige extracties |
Wanneer DIY Python logisch is
DIY wint als je al een proxycontract hebt, strakke controle nodig hebt over headers, postcode-targeting of verkopersegementen, miljoenen pagina's per maand indexeert waarbij kosten per record zich opstapelen, of on-premise/compliance-garanties nodig hebt. De afweging is echte engineeringtijd: een production-ready Scrapy-spider met paginering, retries, proxyrotatie, TLS-imitatie en meerdere pagina-type schema's kost , plus 4–8 uur onderhoud per maand terwijl Walmart fingerprints roteert.
Wanneer een scraping API je tijd bespaart
Scraping API's nemen de anti-botlaag voor je uit handen. laten succespercentages zien van en 98% voor Scrape.do op Walmart. Instaptarieven liggen rond $40–$49 per maand voor tools als , en . Als je een team van 2–5 engineers hebt en je scrapevolume ligt tussen 10K en 1M pagina's per maand, is een API bijna altijd de juiste keuze. Je ruilt kosten per request in voor vrijwel geen onderhoud.
Wanneer no-code de juiste keuze is
past bij een heel ander profiel. Als je een PM, analist of e-commerceoperator bent die vanmiddag Walmart-productdata in een spreadsheet nodig heeft — niet in de volgende sprint — dan is een no-code tool het eerlijke antwoord.
De workflow: installeer de , navigeer naar een Walmart-product- of zoekpagina, klik op "AI Suggest Fields", en Thunderbit's AI leest de pagina en stelt kolommen voor (productnaam, prijs, beoordeling, enz.). Klik op "Scrape" en de data wordt in een tabel gezet. Exporteer naar Excel, Google Sheets, Airtable of Notion — allemaal gratis, zonder betaalmuur.
Thunderbit handelt anti-bot in de cloud af, dus je hebt geen last van CAPTCHA's, proxies of TLS-fingerprinting. De AI past zich automatisch aan layoutwijzigingen aan, dus er is geen onderhoud. Voor gebruikers die helemaal geen JSON-padnavigatie willen, is dit de route met de minste weerstand.
Eerlijke beperkingen: Thunderbit is niet gebouwd voor 100K+ pagina's per dag. Kredietbudgetten en cloudlimieten maken hoge-volume-inname economisch minder aantrekkelijk dan ruwe API's. Je kunt ook geen specifieke postcode of ASN vastpinnen, tenzij de tool dat ondersteunt. Voor doorlopende, hoogvolume pipelines blijf je dus beter bij DIY of een scraping API.
Ruwe prijsinschatting: 1.000 Walmart-productregels op Thunderbit kosten ongeveer 2.000 credits (~$0,60–$1,10 op Starter/Pro-plannen). Dat is vergelijkbaar met Oxylabs' Walmart API en goedkoper dan de meeste scraping-API's in de hobbyklasse bij laag volume. voor de actuele details.
Je geschraapte Walmart-data exporteren
Zodra je de data hebt, moet die ergens bruikbaar terechtkomen. Drie formaten dekken de meeste behoeften:
CSV — het laagste gemene format dat analisten daadwerkelijk openen:
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Gebruik utf-8-sig-codering voor Excel-compatibiliteit. De BOM-marker voorkomt dat Excel speciale tekens beschadigt.
JSONL — het productieformaat voor scraping-pipelines:
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(bij een onderbroken schrijfbeurt raak je alleen de laatste regel kwijt), kan als stream met constant geheugen worden verwerkt en houdt geneste data zoals varianten en reviews intact.
Excel — voor eenmalige overdracht aan een analist:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["Naam", "Prijs", "Beschikbaarheid", "Beoordeling", "Reviews", "Verkoper"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)Thunderbit dekt het exportverhaal voor niet-Python-gebruikers: met één klik exporteren naar Google Sheets, Airtable, Notion, Excel, CSV en JSON — allemaal gratis in de basistier. Voor doorlopende monitoring kan Thunderbit's geplande scraperfunctie herhaalde extracties automatisch uitvoeren.
Eén kanttekening bij plannen: . GitHub Actions-runners draaien op Azure-IP-ranges die Walmart's anti-bot meteen blokkeert. Gebruik APScheduler op een VPS, of route al het verkeer via residential proxies.
Juridische en ethische richtlijnen voor het schrapen van Walmart
Forumgebruikers spreken die zorg expliciet uit: "I'm fine with playing cat and mouse with developers, but wary of playing with their legal team."
Walmart's Terms of Use het gebruik van "any robot, spider… or other manual or automatic device to retrieve, index, 'scrape,' 'data mine' or otherwise gather any Materials" zonder "express prior written consent."
Walmart's robots.txt /search, /account, /api/ en tientallen interne endpoints niet toe. Productdetailpagina's (/ip/...) en reviews (/reviews/product/) zijn niet uitgesloten.
Het hiQ v. LinkedIn-precedent (9th Circuit, ) stelde vast dat het scrapen van publiek beschikbare data waarschijnlijk niet in strijd is met de federale CFAA. Maar datzelfde hof oordeelde later dat en legde een op. Recentere beslissingen uit 2024 (, ) versmalden de CFAA verder en creëerden auteursrecht-preemptionverweren, maar die uitspraken draaiden om specifieke ToU-taal die niet één-op-één op Walmart toepasbaar is.
Praktische richtlijnen: Overbelast servers niet. Respecteer rate limits. Scrape geen persoonlijke of gebruikersdata. Ga verantwoord om met de data. Publieke Walmart-productpagina's op bescheiden snelheid schrapen voor eigen onderzoek is een heel ander risicoprofiel dan op commerciële schaal scrapen tegen Walmart's voorwaarden in. Als je een product bouwt op Walmart-data, praat dan met een jurist en kijk naar Walmart's officiële .
Disclaimer: Dit is educatieve informatie, geen juridisch advies.
Conclusie en belangrijkste inzichten
Walmart schrapen met Python is een dankzij de dubbele anti-botstack van Akamai + PerimeterX. Niet onmogelijk — maar je hebt wel de juiste tools en patronen nodig.
Belangrijkste inzichten:
__NEXT_DATA__-JSON-extractie is de pragmatische keuze voor de meeste use cases. Dit is wat elke serieuze open-source Walmart scraper uit 2024–2026 gebruikt. Het basispad isprops.pageProps.initialData.data.productvoor PDP's ensearchResult.itemStacksvoor search/browse.curl_cffimetimpersonate="chrome124"is verplicht. Gewonerequestsofhttpxkomen Akamai's TLS-fingerprinting niet door, ongeacht de headers.- Stille blokkades zijn het echte gevaar. Walmart geeft 200 OK met CAPTCHA-bodies terug. Controleer de response-inhoud, niet alleen statuscodes.
- Productiescrapers hebben meer nodig dan happy-path code. Exponentiële backoff met jitter, block-detectie op vier signalen, rate limiting op 3–6 seconden per request, datavalidatie en monitoring van sessiegezondheid zijn allemaal essentieel.
- Interne API-interceptie via
/orchestra/*is krachtig maar fragiel. Gebruik het als DevTools-oefening voor specifieke databehoeften, niet als primaire extractiemethode. - Walmart zet zoekresultaten af op 25 pagina's. Ga breder met het omwisselen van sorteervolgorde en het opsplitsen van prijsklassen.
- Kies je aanpak eerlijk: DIY Python voor ontwikkelaars met custom behoeften en hoog volume. Scraping API's voor teams op middenschaal zonder scraping engineer. voor zakelijke gebruikers die vanmiddag data in Google Sheets willen hebben.
Als je de no-code route wilt proberen, heeft de een gratis tier — je kunt een handvol Walmart-pagina's schrapen en zelf de resultaten zien. Als je de Python-route kiest, zijn de codepatronen in dit artikel productiegetest. Hoe dan ook: je hebt nu een kaart van Walmart's verdediging en drie paden erdoorheen.
Voor meer over webscrapingtechnieken kun je onze gidsen bekijken over , en . Je kunt ook tutorials bekijken op het .
FAQ's
Is het legaal om Walmart-productdata te schrapen?
Walmart's Terms of Use verbieden geautomatiseerd scrapen zonder schriftelijke toestemming. Het hiQ v. LinkedIn-oordeel van het 9th Circuit (2022) stelde vast dat de federale CFAA waarschijnlijk niet van toepassing is op het scrapen van publieke pagina's, maar dezelfde zaak eindigde met een tegen de scraper. Publieke productpagina's op bescheiden snelheid schrapen voor eigen onderzoek heeft een heel ander risicoprofiel dan commerciële extractie op schaal. Raadpleeg een jurist als je een bedrijf bouwt op Walmart-data.
Waarom wordt mijn Walmart-scraper steeds geblokkeerd?
De meest voorkomende oorzaken zijn: gewone requests of httpx gebruiken (die een Python-specifieke TLS-fingerprint uitsturen die Akamai direct markeert), ontbrekende of onjuiste headers, geen proxyrotatie, een verzoektempo sneller dan 3–6 seconden per pagina, en ontbrekende sessiecookies (_px3, _abck, locDataV3). Stap over op curl_cffi met impersonate="chrome124", gebruik residential proxies en implementeer de block-detectie- en retrypatronen die in dit artikel worden beschreven.
Welke data kan ik met Python van Walmart schrapen?
Productnamen, prijzen (actueel en rollback), afbeeldingen, korte en lange beschrijvingen, beoordelingen, aantallen reviews, voorraadsstatus, verkopersnamen, fabrikantinformatie, variantopties (maat, kleur) en categorieplaatsing. Met de __NEXT_DATA__-methode is dit allemaal beschikbaar als gestructureerde JSON. Interceptie van interne API's kan daarbovenop prijzen op variantniveau, realtime voorraadniveaus en gepagineerde reviewdata teruggeven.
Heb ik proxies nodig om Walmart te schrapen?
Ja, voor elk productie- of herhaald gebruik. — zelfs met perfecte headers wordt een niet-residential IP door Akamai's IP-reputatiesysteem gemarkeerd. Residential of mobile proxies zijn vereist. Datacenter-IP's raken vrijwel meteen verbrand. Reken grofweg op $3–$17 per 1.000 pagina's, afhankelijk van je proxyprovider en pakket.
Kan ik Walmart schrapen zonder code te schrijven?
Ja. is een AI-aangedreven Chrome-extensie die Walmart in twee klikken schraapt: "AI Suggest Fields" om automatisch productdatakolommen te detecteren, daarna "Scrape" om de data te extraheren. De tool handelt anti-botuitdagingen in de cloud af en exporteert direct naar Excel, Google Sheets, Airtable of Notion — allemaal gratis. Het is vooral geschikt voor analisten, PM's en zakelijke gebruikers die snel data nodig hebben zonder een custom pipeline te bouwen. Voor hoog volume of sterk aangepaste scraping zijn Python of een scraping API nog steeds beter geschikt.
Meer weten