Redfin werkt bij nadat ze live zijn gegaan. Die snelheid is goud waard voor iedereen die een vastgoed-datapijplijn bouwt — en precies daarom richten zoveel scrapers zich op Redfin en lopen ze binnen enkele minuten tegen een blokkade aan.
Ik werk al jaren aan data-extractietools bij , en ik kan je dit vertellen: het verschil tussen "Redfin scrapen" en "Redfin scrapen zonder geblokkeerd te worden" is precies waar de meeste handleidingen uit elkaar vallen. Ze laten je de BeautifulSoup-code zien, slaan het stuk over waar Cloudflare je verzoeken de nek omdraait, en laten je achter met een 403-pagina terwijl je je afvraagt wat er misging. Deze gids doet het anders. Ik neem je mee langs drie echte aanpakken — HTML-parsing, Redfin’s verborgen API en een no-code route met Thunderbit — en ga uitgebreid in op de anti-botbeveiliging die er écht toe doet. Aan het einde weet je precies welke methode past bij jouw vaardigheidsniveau, schaal en tolerantie voor onderhoudsproblemen.
Wat is Redfin en waarom is die data zo belangrijk?
Redfin is een technologiegedreven vastgoedmakelaar met medewerkers in loondienst die listings rechtstreeks uit MLS-feeds haalt. Het platform dekt en trekt bijna 50 miljoen maandelijkse bezoekers. In tegenstelling tot portals die alleen aggregeren, is Redfin’s data door makelaars geverifieerd, en de eigen Redfin Estimate AVM omvat met een mediane fout van slechts 1,96% voor woningen die actief in de markt staan.
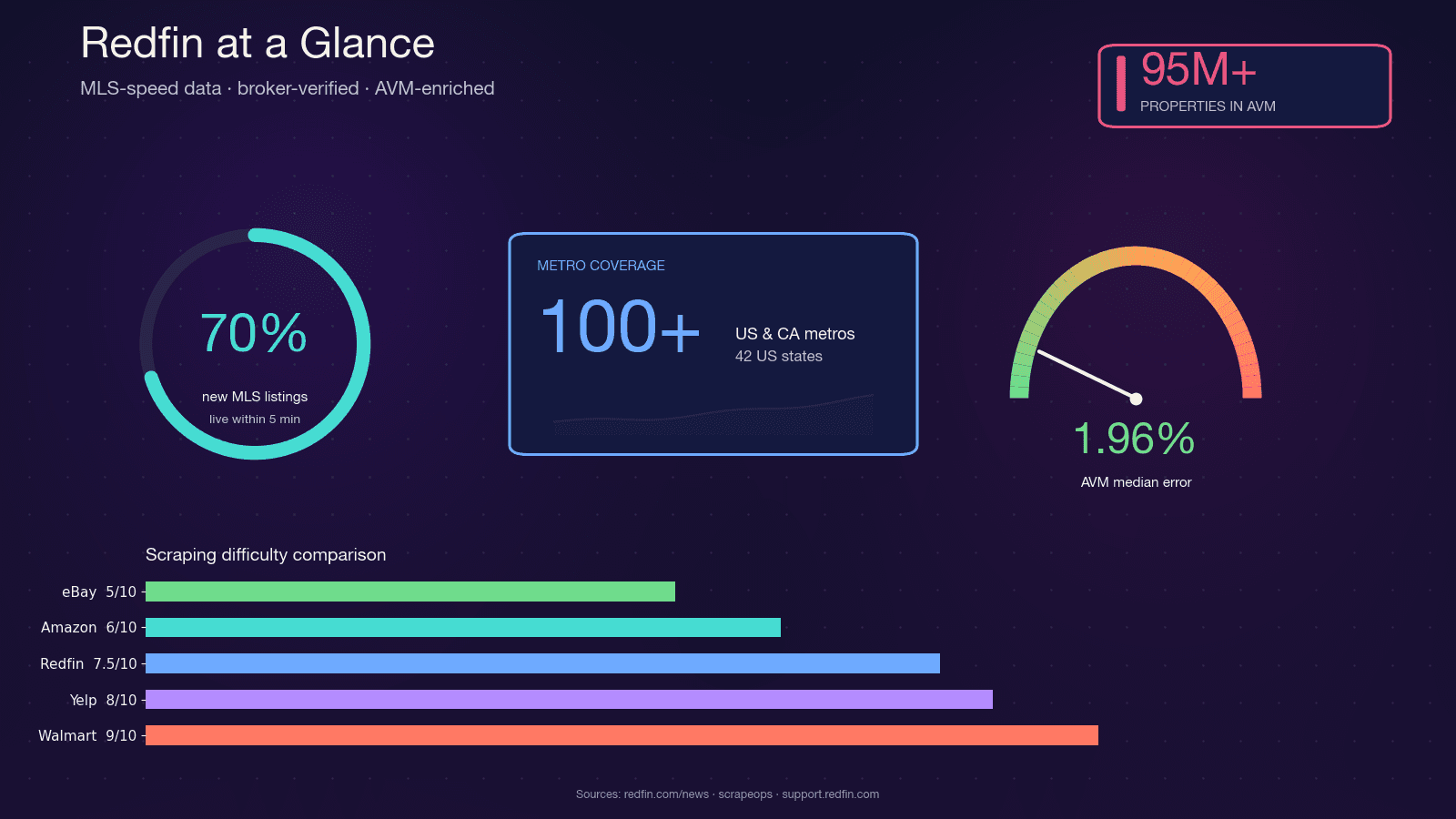
Die combinatie — razendsnelle MLS-updates, door makelaars geverifieerde kwaliteit en een strakke AVM — is waarom vastgoedinvesteerders, makelaars, proptech-startups en data-analisten allemaal programmatische toegang tot Redfin-data willen. Python is daarvoor de logische keuze: het scraping-ecosysteem (requests, BeautifulSoup, Selenium, Playwright) is volwassen, de community is enorm, en het sluit naadloos aan op pandas en Jupyter voor analyses.
Waarom Redfin scrapen met Python?
De use cases zijn net zo uiteenlopend als de mensen die die data nodig hebben. Zo gebruiken verschillende doelgroepen Redfin-data meestal:
| Doelgroep | Hoofddoel van scraping | Voorbeeldtoepassing |
|---|---|---|
| Makelaars | Leadgeneratie, marktinformatie | Nieuwe listings en verlopen listings in het werkgebied; makelaarsdirectory voor concurrentieanalyse |
| Vastgoedinvesteerders | Dealflow, cap-rate analyse | Screens op huurrendement, detectie van ondergewaardeerde panden, dagelijkse alerts voor nieuwe listings |
| Proptech-startups | Product-datapijplijnen | Trainingsdata voor AVM, marktdashboards, acquisitiemotoren voor iBuyers |
| Data-analisten | Marktonderzoek, BI | Mediane prijstrends op ZIP-code-niveau, tijdreeksen van dagen op de markt, verkoop-/vraagprijsverhoudingen |
| Wholesalers / flippers | Tracking van noodlijdende panden | Detectie van prijsverlagingen, executieveilingen, vergelijkbare off-market panden |
De bredere trend bevestigt dit: gebruikt inmiddels predictive analytics om kansen te vinden en risico’s te beheren. De proptech-markt groeit naar verwachting naar met een CAGR van 16,4%. Gestructureerde vastgoeddata is allang geen leuke extra meer — het is de basis.
Alle Redfin-gegevensvelden die je kunt scrapen (volledige referentie)
Voordat je ook maar één regel code schrijft, moet je weten wat er eigenlijk beschikbaar is. Ik heb de zoekresultaatpagina’s, detailpagina’s en makelaarsprofielen van Redfin geanalyseerd — en vergeleken met open-source Stingray API-wrappers zoals de projecten en . De totale uitkomst komt uit op 117 unieke velden over verschillende paginatypes.
Deze tabel is er eentje om te bewaren. Als je je dataschema al kent vóórdat je code schrijft, scheelt dat uren aan trial-and-error met selectors.
Velden op de zoekresultatenpagina
Dit zijn de lichte velden op listing cards — vaak uit te lezen zonder volledige JS-rendering:
| Veld | Datatype | Opmerkingen |
|---|---|---|
| Property ID | Nummer | Interne Redfin-int, geparsed uit /home/{id} in de href |
| Vraagprijs | Nummer | |
| Volledig adres | Tekst | |
| Slaapkamers / badkamers / m² | Nummer | Drie waarden op volgorde |
| Type woning | Enkele keuze | SFH, Condo, Townhouse, Multi |
| Status | Tekst | Active, Pending, Contingent |
| Dagen op de markt | Nummer | |
| Indicator prijsverlaging | Nummer | Verschil t.o.v. oorspronkelijke vraagprijs |
| Primaire foto | Afbeeldings-URL | Eén foto per kaart |
| Hot Home-badge | Booleaans | |
| Datum/tijd open huis | Tekst | |
| Makelaarstoewijzing | Tekst |
Velden op de detailpagina van een woning
De detailpagina bevat de echte diepgang. Veel van deze velden vereisen JavaScript-rendering of de Stingray API:
| Veld | Datatype | Opmerkingen |
|---|---|---|
| Redfin Estimate (op de markt) | Nummer | Via /stingray/api/home/details/avm |
| Redfin Estimate (off-market) | Nummer | Via /stingray/api/home/details/owner-estimate; mediane fout 7,52% |
| Bouwjaar / renovatiejaar | Nummer | |
| Perceelgrootte | Nummer | |
| VvE-bijdrage | Nummer | Maandelijks, indien van toepassing |
| Onroerendezaakbelasting (jaarlijks) | Nummer | |
| Getaxeerde waarde | Nummer | |
| Verkoopgeschiedenis-tabel | Tabel | Prijs, datum, type gebeurtenis |
| Omschrijving van de woning | Tekst | Marketingtekst |
| Foto-URL’s (carousel) | Afbeeldings-URL’s | 20+ per listing |
| Naam, telefoon, e-mail van listing agent | Tekst / Telefoon / E-mail | Telefoon is vaak afgeschermd |
| Schoolratings (basis/middelbaar/voortgezet) | Nummer | Inclusief districtnaam |
| Walk / Transit / Bike Score | Nummer | |
| Klimaatrisicoscores | Nummer | Overstroming, brand, hitte, wind |
| Vergelijkbare actieve / verkochte / nabijgelegen woningen | URL’s | Carouseldata |
| Parkeren, garage, verwarming, koeling | Tekst | Voorzieningengroepen |
Velden op het makelaarsprofiel
| Veld | Datatype | Opmerkingen |
|---|---|---|
| Naam van de agent, foto, makelaarskantoor, bio | Tekst / Afbeelding | |
| Telefoon, contactformulier | Telefoon / Tekst | Pas zichtbaar na klik |
| Aantal actieve listings | Nummer | |
| Verkopen in de laatste 12 maanden / totaal volume | Nummer | |
| Gemiddelde verhouding vraagprijs-verkoopprijs | Nummer | |
| Sterrenrating / aantal reviews | Nummer | |
| Jaren ervaring / licentienummer | Tekst / Nummer |
Wanneer je in Thunderbit op een Redfin-pagina de functie AI Suggest Fields gebruikt, herkent het systeem automatisch de meeste van deze kolommen en koppelt het de juiste datatypes — zonder handmatig CSS-selectors te hoeven mappen. Daarover later meer.
Redfin’s anti-botmaatregelen ontleed (en het is meer dan alleen "gebruik een proxy")
Hier wil ik echt even een punt maken, want de meeste tutorials gaan te makkelijk voorbij aan het blokkadeprobleem en springen meteen naar "koop proxies via onze sponsor." Dat helpt niet. Als je niet begrijpt wat Redfin doet om scrapers te detecteren, blaas je je proxytegoed op en word je alsnog geblokkeerd. , en — "minder agressief dan Zillow’s enterprise WAF, met aangepaste rate limiting en JavaScript-challenges."
Redfin gebruikt een gelaagde stack: Cloudflare aan de rand (JS challenge, Turnstile, TLS/JA3-fingerprinting) plus een Redfin-specifieke limiter op applicatieniveau. In hun robots.txt staat geen Crawl-delay, omdat handhaving plaatsvindt op WAF-niveau.
Waarom simpele requests + BeautifulSoup op Redfin falen
Als je met standaardheaders een simpele requests.get() naar een Redfin-woningpagina stuurt, gebeurt meestal het volgende:
- HTTP 403 — de JavaScript-challenge van Cloudflare is niet opgelost, dus je krijgt de challenge-pagina in plaats van de listing.
- Een tussenscherm met challenge — de HTML-body bevat de Turnstile-widget van Cloudflare, niet de woningdata.
- HTTP 200 met deels HTML — je krijgt een shell met een grote ingebedde JSON-blob onder
root.__reactServerState.InitialContext, maar geen vooraf gerenderde cards, geen prijsverloop en geen schoolratings.
Redfin gebruikt een eigen (geen Next.js), en de hydration key is Redfin-specifiek — root.__reactServerState.InitialContext met listingdata genest onder ReactServerAgent.cache.dataCache. Dat is dus niet __NEXT_DATA__ of window.__INITIAL_STATE__.
De meest voorkomende oorzaak van stille 403’s? Ontbrekende Sec-Fetch-* headers. Redfin/Cloudflare valideert expliciet Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest en Sec-Fetch-User. Als die ontbreken, ben je meteen verdacht.
Het mitigatieplan: vertragingen, headers, proxies en sessies
Hier volgt de volledige verdediging-per-verdediging-analyse, met concrete maatregelen per onderdeel:
| Redfin-verdediging | Wat het doet | Detectiesignaal | Mitigatiestrategie |
|---|---|---|---|
| Cloudflare JS challenge | Tussenscherm dat een cf_clearance cookie afgeeft | 403 + HTML-body van Cloudflare | curl_cffi met impersonate="chrome120"; sessie opwarmen via homepage; Amerikaanse residential proxy |
| Cloudflare Turnstile | Interactieve CAPTCHA bij risicovolle sessies | 403 + Turnstile-widget | Headless browser met stealth + residential proxy |
| Cloudflare Error 1020 (ASN-ban) | Blokkeert verdachte IP’s/ASN’s op WAF-niveau | 403-body "Error 1020 Access Denied" | Schakel over naar residential/mobile proxy; gebruik nooit datacenter-ASN’s |
| TLS/JA3-fingerprinting | Detecteert niet-browser TLS-stacks | Stille 403, zelfs met perfecte headers | curl_cffi-impersonatie of echte browser |
| HTTP/2-fingerprinting | Controleert HTTP/2 SETTINGS en HPACK-volgorde | Stille blokkade | curl_cffi spreekt HTTP/2 zoals Chrome |
| Header-validatie (UA, Sec-Fetch-*) | Browser-consistente header-set | 403 bij eerste verzoek | Volledige Chrome-header-set inclusief Sec-Fetch-Site/Mode/Dest/User, realistische Referer |
| Cookie-/sessiecontinuïteit | Volgt cf_clearance, RF_BROWSER_ID | Challenges bij koude deep-URL-hits | Persistente sessie; eerst homepage opwarmen |
| Rate limiting op app-niveau | Limiet per IP voor requests | 429 | 2–5 seconden vertraging met jitter; exponentiële backoff |
| Reputatie van datacenter-IP’s | Blokkeert bekende DC-ASN’s | Directe 1020/403 | Alleen Amerikaanse residential of mobile proxies |
| Detectie van concurrency | Meerdere parallelle requests vanaf één IP | Plotselinge escalatie naar Turnstile | Maximaal 2 gelijktijdige requests per IP |
Praktische drempels uit community-tests:
- Veilige cadence: 1 request per 2–3 seconden per IP
- Meer dan 20–30 requests per minuut vanaf één datacenter-IP triggert binnen enkele minuten een challenge
- Zachte rate limits verdwijnen vaak binnen 5–15 minuten als het verkeer stopt
- Bans op datacenter-IP’s (AWS, GCP, Azure, OVH) kunnen uren tot dagen aanhouden
Standaard Python requests (urllib3 + OpenSSL) produceert een — en wordt zelfs met perfecte headers stilletjes geblokkeerd. De oplossing in de praktijk is curl_cffi met impersonate="chrome120", waarmee je TLS en HTTP/2 nabootst zoals Chrome ze spreekt.
Drie manieren om Redfin te scrapen met Python (en welke je moet kiezen)
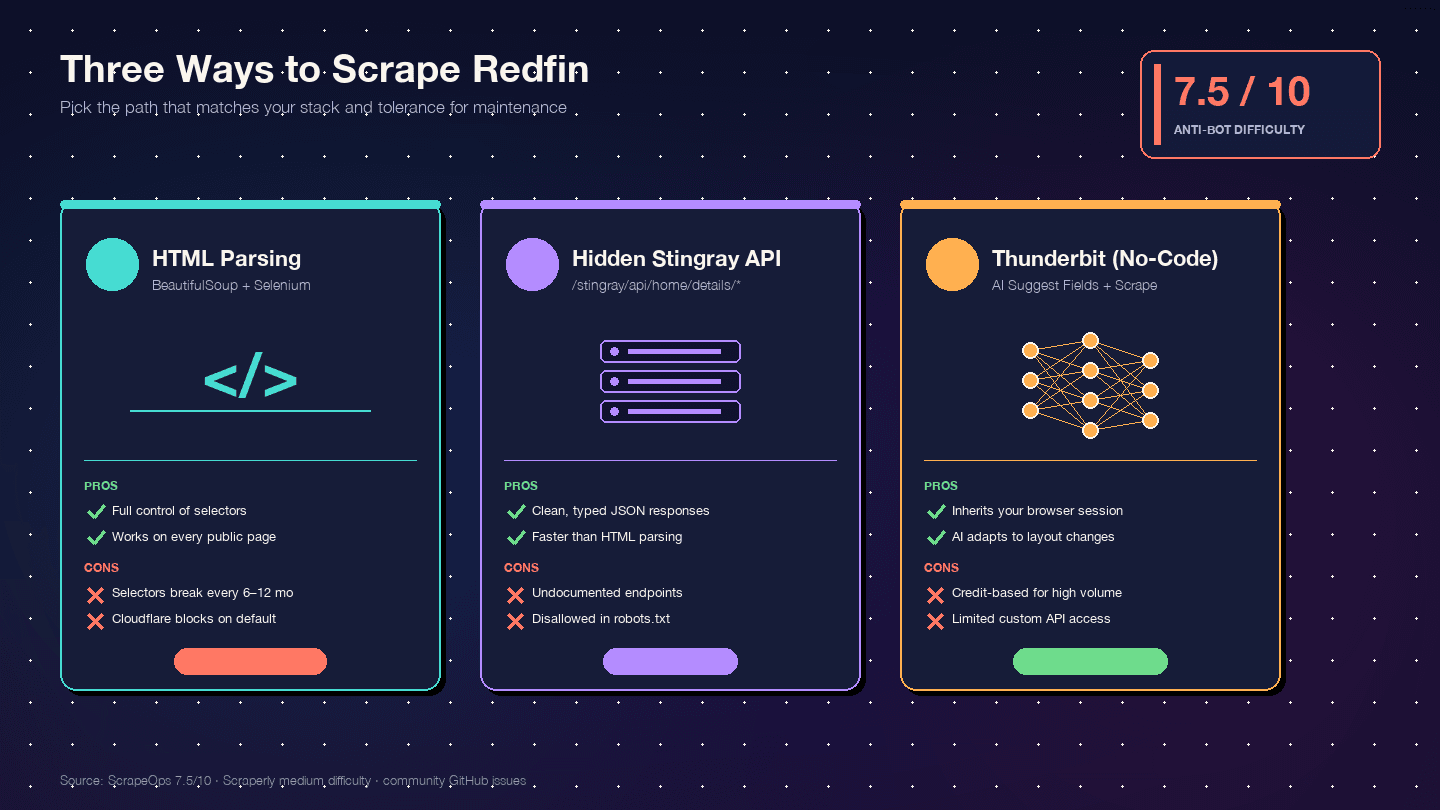
Ik heb nog geen enkele andere handleiding gevonden die alle drie de aanpakken naast elkaar zet. Dit is de beslismatrix:
| Criteria | HTML-parsing (BS4 + Selenium) | Verborgen Stingray API | Thunderbit (no-code) |
|---|---|---|---|
| Moeilijkheid bij opzet | Gemiddeld (Python-omgeving + browserdriver) | Hoog (endpoints reverse-engineeren) | Laag (Chrome-extensie installeren) |
| Anti-botrisico | Hoog (DOM-requests zijn het meest zichtbaar) | Gemiddeld (API-achtige requests ogen netter) | Laagst (gebruikt je echte browsersessie) |
| Kwaliteit van datastructuur | Gemiddeld (ongestructureerde HTML → handmatige parsing) | Uitstekend (voorgestructureerde JSON) | Hoog (AI herkent velden + types automatisch) |
| Onderhoudslast | Hoog — een lay-outwijziging breekt selectors | Gemiddeld — endpoints kunnen ongemerkt veranderen | Laagst — AI past zich aan lay-outwijzigingen aan |
| Schaal | Laag-middelgroot (honderden met proxies) | Middelgroot-hoog (duizenden, schonere requests) | Middelgroot (50 pagina’s per batch via cloud scraping) |
| Het beste voor | Developers die volledige controle willen | Developers die schone JSON nodig hebben | Niet-developers, snelle projecten, doorlopende data zonder dev-resources |
De onderhoudscomponent is belangrijk. Redfin heeft twee generaties van listing-cards uitgebracht — legacy (homecardV2Price) en huidig (span.bp-Homecard__Price--value). Uit de GitHub-issuehistorie van de community blijkt dat CSS-selectorbreuken ongeveer elke 6–12 maanden voorkomen. Als dat gebeurt, breekt een BeautifulSoup-scraper van de ene op de andere dag. Een AI-gebaseerde veldendetector past zich aan.
Voordat je begint
- Moeilijkheid: Gemiddeld (aanpak 1 & 2), Beginner (aanpak 3)
- Benodigde tijd: ~30 minuten voor aanpak 1 of 2; ~5 minuten voor aanpak 3
- Wat je nodig hebt:
- Python 3.8+ met pip (aanpak 1 & 2)
- Chrome-browser (alle aanpakken)
- (aanpak 3)
- Amerikaanse residential proxies voor grootschalig scrapen (aanpak 1 & 2)
Aanpak 1: Redfin scrapen met Python via HTML-parsing (BeautifulSoup + Selenium)
Dit is de route met "volledige controle". Jij schrijft de selectors, jij beheert de browser, jij vangt de fouten op.
Het is de meest leerzame aanpak. Ook meteen de kwetsbaarste.
Stap 1: Stel je Python-omgeving in
Maak een virtuele omgeving aan en installeer de benodigde libraries:
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # Op Windows: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cfficurl_cffi is hier essentieel — daarmee kunnen je HTTP-verzoeken het TLS-profiel van een echte Chrome-browser imiteren, in plaats van het standaard Python requests-profiel dat Cloudflare meteen blokkeert.
Stap 2: Configureer browserheaders en sessie
Hier gaat het bij de meeste beginners mis. Je hebt de volledige Chrome-header-set nodig, inclusief de Sec-Fetch-* headers die Redfin/Cloudflare expliciet valideert:
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# Sessie opwarmen — verzamel cf_clearance- en RF_BROWSER_ID-cookies
17session.get("https://www.redfin.com/")Het opwarmen van de sessie is cruciaal — direct een diepe property-URL openen zonder voorafgaande cookies of Referer wordt door Cloudflare lager beoordeeld.
Begin altijd met de homepage.
Stap 3: Redfin-zoekresultaten scrapen
Als je sessie eenmaal is opgewarmd, kun je een stadspagina ophalen en de listing cards parsen. Huidige selectors (2024–2026):
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # Pagina's 1-5
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"Geblokkeerd op pagina {page_num}: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # Willekeurige pauze tussen 2 en 5 seconden
28 time.sleep(random.uniform(2, 5))
29print(f"{len(listings)} listings gescrapet")Je zou een groeiende lijst met dictionaries moeten zien, elk met prijs, adres, slaapkamers/badkamers/m² en de detail-URL van een woning in San Francisco. Krijg je 0 cards, controleer dan de HTTP-statuscode — een 403 betekent dat Cloudflare je heeft gepakt, en dan heb je waarschijnlijk residential proxies nodig.
Stap 4: Scrape individuele detailpagina’s van woningen
Zoekresultaten geven je de basis. Detailpagina’s geven je de Redfin Estimate, bouwjaar, VvE, verkoopgeschiedenis, agentinfo en foto’s. Deze pagina’s vereisen JavaScript-rendering, dus schakel over naar Selenium:
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # Verrijk de eerste 10
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # Wacht op JS-rendering
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()Na deze stap zouden je eerste 10 listings verrijkt moeten zijn met Redfin Estimate-waarden en bouwjaar. XPath-selectors zijn voor dit soort geneste voorzieningen vaak robuuster dan CSS, maar ze blijven fragiel — elke herstructurering van de DOM kan ze breken.
Stap 5: Omgaan met blokkades en fouten
Implementeer retry-logica met exponentiële backoff:
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"Geblokkeerd ({resp.status_code}). Opnieuw proberen over {wait:.1f}s...")
10 time.sleep(wait)
11 else:
12 print(f"Onverwachte status: {resp.status_code}")
13 break
14 return NoneTekenen dat je bent geblokkeerd: HTTP 403 met Cloudflare-HTML in de body, HTTP 429 (expliciete rate limit), een lege response-body of "Error 1020 Access Denied" in de pagina-inhoud. Als je hier steeds tegenaan loopt, is het tijd om residential proxies toe te voegen of over te stappen op de API-aanpak.
Aanpak 2: Redfin scrapen met Python via de verborgen Stingray API
Dit is mijn favoriete aanpak. De frontend van Redfin praat met een interne JSON API op /stingray/api/home/details/*, en de responses komen terug als nette, getypeerde JSON — geen HTML-parsing nodig.
Hoe je Redfin’s verborgen API-endpoints ontdekt
Open Chrome DevTools → tab Network → filter op Fetch/XHR → navigeer naar een Redfin-woningpagina. Je ziet requests naar endpoints zoals:
api/home/details/initialInfo— zet URL om naar propertyId, listingIdapi/home/details/aboveTheFold— prijs, slaapkamers, badkamers, m², foto’s, status, agent, MLS#api/home/details/belowTheFold— voorzieningen, VvE, belastingen, parkeren, bouwjaar, perceel, geschiedenisapi/home/details/avm— Redfin Estimate voor woningen in de marktapi/home/details/owner-estimate— Redfin Estimate voor off-market woningenapi/home/details/descriptiveParagraph— marketingomschrijving
Voor huurpagina’s wordt de rentalId (een UUID van 36 tekens) uit de URL van de <meta property="og:image">-tag gehaald.
Woningdata scrapen via de Stingray API
Er is een belangrijke eigenaardigheid: Stingray JSON-responses beginnen met de letterlijke string {}&& als anti-CSRF-maatregel. Je moet dat verwijderen vóór het parsen:
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# Sessie opwarmen
6session.get("https://www.redfin.com/")
7# Haal een woningpagina op om cookies en property ID te krijgen
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Raak nu de Stingray API aan
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# Verwijder het anti-CSRF-prefix
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# Extraheer gestructureerde data
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))De response bevat getypeerde velden: prijs als integer, slaapkamers/badkamers als getallen, foto-URL’s als arrays, agentinformatie als geneste objecten. Geen BeautifulSoup, geen CSS-selectors, geen giswerk.
Pluspunten en beperkingen van de verborgen API-aanpak
Pluspunten:
- Voorgestructureerde JSON — veel schoner dan HTML-parsing
- Sneller per request (kleinere payloads, geen render-overhead)
- Lager blokkeringsrisico (API-achtige requests met goede headers ogen natuurlijker)
Beperkingen:
- Endpoints kunnen zonder waarschuwing veranderen — er is geen officiële documentatie
robots.txtverbiedt expliciet/stingray/voor de wildcard user-agent- Reverse-engineering is nodig om nieuwe endpoints te vinden
- Je hebt nog steeds sessie-opwarming en correcte headers nodig om Cloudflare te vermijden
Het no-code alternatief: Redfin scrapen met Thunderbit
Als je Redfin-data nodig hebt en geen Python-scripts wilt onderhouden — of gewoon binnen vijf minuten resultaat wilt — begin hier. Wij hebben precies hiervoor gebouwd: gestructureerde data-extractie van elke website, zonder code.
Stap 1: Installeer Thunderbit en ga naar Redfin
Installeer de vanuit de Chrome Web Store. Open Redfin en ga naar een zoekresultatenpagina — bijvoorbeeld woningen te koop in San Francisco.
Stap 2: Klik op "AI Suggest Fields"
Klik op het Thunderbit-icoon in je browserwerkbalk en vervolgens op "AI Suggest Fields." De AI leest de Redfin-pagina en doet automatisch voorstellen voor kolommen zoals "Address", "Price", "Beds", "Baths", "SqFt", "Property Type" en "Listing Photo" — inclusief correcte datatypes.
Je kunt kolommen die je niet nodig hebt verwijderen of extra kolommen toevoegen door op "+ Add Column" te klikken en in gewoon Engels te beschrijven wat je wilt, bijvoorbeeld "listing agent name" of "days on market".
Je zou een tabelvoorbeeld moeten zien met je ingestelde kolommen, klaar om gevuld te worden.
Stap 3: Klik op "Scrape" en zie de data binnenkomen
Klik op de knop "Scrape". Thunderbit verwerkt de zichtbare listings en vult je tabel. Voor pagina’s met paginering wordt dat automatisch afgehandeld — je hoeft geen looplogica te schrijven.
In mijn test vulde een tabel met 50 rijen zich in ongeveer 45 seconden. Gestructureerde data, klaar om te exporteren.
Hoe Thunderbit omgaat met Redfin’s anti-botbescherming
Omdat Thunderbit in je eigen browser draait, gebruikt het automatisch je bestaande Redfin-cookies, sessie en browser fingerprint. Voor Cloudflare ziet het eruit als normaal gebruik van Redfin — en technisch gezien is dat ook zo. Er is geen headless browser, geen datacenter-IP en geen afwijkende TLS-fingerprint. Voor publiek beschikbare pagina’s kan Thunderbit’s cloud scraping-modus 50 pagina’s tegelijk verwerken.
Dat is fundamenteel iets anders dan requests vanaf een Python-script op een server versturen.
Je browsersessie is al vertrouwd.
Redfin-subpagina’s scrapen met Thunderbit
Na het scrapen van zoekresultaten klik je op "Scrape Subpages" zodat de AI elke detail-URL bezoekt en je tabel verrijkt met extra velden — Redfin Estimate, bouwjaar, VvE-bijdrage, agentinfo, woningfoto’s en verkoopgeschiedenis.
Dat is het equivalent van de Selenium-loop van 40 regels uit aanpak 1 — alleen kost het één klik en geen onderhoud.
Wanneer Redfin zijn DOM verandert van homecardV2Price naar span.bp-Homecard__Price--value, past de AI zich aan. Jouw Python-selectors niet.
Verder dan CSV: Redfin-data exporteren naar Google Sheets, Airtable en Notion
De meeste handleidingen stoppen bij df.to_csv(). Prima voor een eenmalige analyse. Maar als je in een vastgoedteam werkt, heb je samenwerkende, levende data nodig — niet statische bestanden die op iemands bureaublad stof verzamelen.
Exporteren met Python (gspread + Airtable API)
Google Sheets via gspread:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# Toon woningfoto's inline via de IMAGE()-formule
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')Let op: Sheets heeft een harde limiet van 10 miljoen cellen per spreadsheet, en de API staat . Gebruik ws.batch_update() in plaats van per-cel-loops zodra je verder gaat dan een paar dozijn rijen.
Airtable via pyairtable:
Belangrijke wijziging in 2024: Airtable heeft . Je moet nu Personal Access Tokens (PAT’s) gebruiken — elke handleiding die nog api_key=... laat zien, is verouderd.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable haalt op en host opnieuw
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)Airtable’s rate limit is , met een lockout van 30 seconden bij overschrijding. Het bijlageveld accepteert payloads in de vorm [{"url": ...}] — Airtable’s servers halen de URL op, hosten die opnieuw op hun CDN en maken automatisch thumbnails aan.
Exporteren met Thunderbit (1 klik naar Sheets, Airtable, Notion)
Thunderbit heeft native export met één klik naar Google Sheets, Airtable en Notion — en dit deel ben ik oprecht trots op: woningfoto’s worden geüpload en inline weergegeven als afbeeldingen in Notion en Airtable. Geen =IMAGE()-trucs, geen kapotte CDN-links. Je klikt op "Export to Airtable" en je team krijgt een visuele woningdatabase met thumbnails die ze onderweg op hun telefoon kunnen bekijken.
Voor vastgoedteams die visueel listings willen filteren, is dit het verschil tussen een bruikbaar hulpmiddel en een stapel CSV-rijen.
Is het legaal om Redfin te scrapen? Wat ToS, robots.txt en jurisprudentie zeggen
Ik ben geen advocaat, en dit is geen juridisch advies. Maar na jaren in data-extractie kan ik je wel zeggen: "is het legaal?" is de vraag die iedereen stelt en die de meeste tutorials ontwijken.
Redfin’s robots.txt
Redfin’s is gedetailleerd. Belangrijkste punten:
- Volledig geblokkeerde bots:
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent— Redfin noemt expliciet de populaire scrapingdienst uit het LLM-tijdperk - Belangrijke
Disallow-regels voor wildcardUser-agent: *:/stingray/(de volledige interne API-namespace),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - Geen
Crawl-delay:-directive voor welke user agent dan ook - Meer dan 50 sitemaps gedeclareerd — sitemaps zijn de schoonste en minst WAF-zware manier om URL’s te enumereren
Redfin’s gebruiksvoorwaarden
zegt: "You may not automatedly crawl or query the Services for any purpose or by any means... unless you have received prior express written permission."
Dit is een browsewrap-overeenkomst — acceptatie door voortgezet gebruik, niet door expliciet klikken. Amerikaanse rechtbanken zijn historisch gezien terughoudend geweest met het afdwingen van browsewrap tegen gebruikers die geen daadwerkelijke kennis hadden (zie Nguyen v. Barnes & Noble, 9e Cir. 2014).
Relevante jurisprudentie (kort)
- Van Buren v. United States (Hooggerechtshof, 2021): de CFAA-clausule "exceeds authorized access" gebruikt een "gates-up-or-down"-test. Een open deur gebruiken voor een ongewenst doel is geen federale hacking.
- hiQ Labs v. LinkedIn (9e Cir., 2022): het scrapen van publiek beschikbare data is geen CFAA-schending. Maar hiQ betaalde uiteindelijk $500.000 in een schikking op contractbreukgronden — omdat hiQ LinkedIn-accounts had aangemaakt en op "I agree" had geklikt.
- Meta Platforms v. Bright Data (N.D. Cal., jan. 2024): de rechtbank wees summary judgment toe aan Bright Data — uitgelogd scrapen van openbare data maakte Bright Data niet tot een "user" die gebonden was aan Meta’s ToS.
- X Corp. v. Bright Data (N.D. Cal., mei 2024): rechter Alsup verwierp de claims van X en oordeelde dat staatsrechtelijke claims die het kopiëren van publieke content wilden controleren, werden voorgegaan door de Copyright Act.
Praktisch advies
- Scrape alleen publiek toegankelijke data — maak nooit een account aan en ga daarna scrapen (dat creëert blootstelling aan clickwrap-contracten)
- Houd je aan rate limits — agressieve volumes ondersteunen claims van trespass to chattels
- Herpubliceer geen ruwe data of foto’s op grote schaal — de -rechtszaak (aangespannen in juli 2025, potentiële schadevergoeding van meer dan $1 miljard) laat zien dat auteursrecht op foto’s serieus is
- Thunderbit’s browsergebaseerde aanpak — draaien in je eigen geauthenticeerde sessie — ligt dichter bij "handmatig browsen op machinesnelheid" dan bij een headless datacenter-bot, en dat is juridisch gezien de beter verdedigbare positie, kort van een gelicentieerde API
Tips en veelvoorkomende valkuilen
Een paar harde lessen uit het bouwen van extractietools en het zien van duizenden gebruikers die vastgoedsites scrapen:
- Warm je sessie altijd op. Bezoek eerst
redfin.com/vóór elke diepe URL. Koude deep-URL-hits zijn de belangrijkste trigger voor Cloudflare-challenges. - Roteer User-Agent strings realistisch. Gebruik niet steeds dezelfde — wissel tussen 5–10 actuele Chrome/Firefox UAs. Maar roteer ook niet te agressief (een andere UA bij elk verzoek ziet er verdacht uit).
- Dedupliceer op property ID. De paginering van Redfin overlapt soms. Haal de
/home/{id}uit elke listing-URL en dedupliceer vóór je verrijkt. - Scrape niet tijdens piekuren als je het kunt vermijden. In mijn ervaring is er laat in de nacht / vroeg in de ochtend Amerikaanse tijd minder WAF-controle.
- Krijg je een 429, trek dan exponentieel terug. Probeer niet meteen opnieuw — zo ga je van een zachte rate limit naar een harde IP-ban.
- Voor grootschalige projecten (1.000+ pagina’s) moet je residential proxies budgetteren. Datacenter-IP’s (AWS, GCP, Azure, OVH) worden door Cloudflare’s ASN-reputatiesysteem zwartgelijst. Je loopt vrijwel meteen tegen Error 1020 aan.
De juiste manier kiezen om Redfin te scrapen
Welke aanpak moet je kiezen? Dat hangt af van wie je bent en wat je nodig hebt.
HTML-parsing (BeautifulSoup + Selenium): het beste voor developers die volledige controle willen, comfortabel zijn met het onderhouden van CSS-selectors en het niet erg vinden om opnieuw te bouwen wanneer Redfin zijn DOM verandert. Reken erop dat je je code elke 6–12 maanden opnieuw moet bekijken.
Verborgen Stingray API: het beste voor developers die schone, gestructureerde JSON nodig hebben en reverse-engineering van ongedocumenteerde endpoints aankunnen. Minder onderhoud dan HTML-parsing, maar endpoints kunnen zonder waarschuwing wijzigen. Vergeet niet dat /stingray/ expliciet verboden is in robots.txt.
Thunderbit (no-code): het beste voor niet-developers, snelle projecten en teams die doorlopend Redfin-data nodig hebben zonder ontwikkelcapaciteit. AI past zich aan lay-outwijzigingen aan, subpage scraping verrijkt data met één klik en export naar , Airtable of Notion zit ingebouwd. Als je een vastgoedteam bent dat een levende property database nodig heeft — niet een eenmalige CSV-dump — dan is dit de route met de minste weerstand.
Welke route je ook neemt: begrijp Redfin’s anti-botbeveiliging voordat je begint, weet welke velden je nodig hebt, kies een exportformaat dat past bij de workflow van je team en blijf aan de veilige kant van .
Klaar om de no-code route te proberen? laat je experimenteren met Redfin-scraping en binnen enkele minuten resultaat zien. Voor de Python-aanpakken zijn de codefragmenten hierboven een werkend vertrekpunt — voeg daar alleen proxies en geduld aan toe.
FAQ’s
Heeft Redfin een openbare API?
Nee. Redfin biedt geen officiële publieke API aan. De verborgen Stingray API (/stingray/api/home/details/*) levert gestructureerde JSON en wordt gebruikt door Redfin’s eigen frontend, maar is niet officieel, niet gedocumenteerd, kan zonder waarschuwing veranderen en is expliciet verboden in Redfin’s robots.txt. Open-source wrappers zoals op PyPI geven Python-toegang, maar gebruik ze met begrip van de risico’s.
Kan ik Redfin scrapen zonder Python?
Ja. is een AI Chrome-extensie die je browsersessie overneemt voor betere bescherming tegen anti-botmaatregelen — installeer het, ga naar Redfin, klik op "AI Suggest Fields" en exporteer naar Excel, Google Sheets, Airtable of Notion. Er zijn ook andere no-code scrapingtools en vooraf gebouwde datasetproviders op de markt als je alternatieven wilt verkennen.
Hoe vaak verandert de lay-out van Redfin?
Uit de GitHub-issuehistorie van de community blijkt dat CSS-selectors ongeveer elke 6–12 maanden breken. Redfin heeft twee generaties listing-cards uitgebracht — legacy (homecardV2Price, homeAddressV2) en huidig (bp-Homecard__Price--value, bp-Homecard__Address). Volwassen scrapers proberen beide sequentieel.
AI-tools zoals Thunderbit omdat ze velden herkennen op basis van inhoud in plaats van CSS-selectors.
Wat is het beste proxytype voor Redfin-scraping?
Amerikaanse residential proxies voor grootschalig scrapen — communitybenchmarks zetten het succespercentage rond de 80%. Datacenter-proxies lopen vrijwel meteen tegen Cloudflare Error 1020 aan; AWS-, GCP-, Azure- en OVH-IP-ranges zijn zwartgelijst. Mobile proxies hebben het hoogste succespercentage, maar kosten 5–10 keer meer.
Voor kleinschalig persoonlijk scrapen (<100 pagina’s) kunnen goede headers + curl_cffi-impersonatie + vertragingen van 2–5 seconden soms werken zonder proxies.
Kan ik verkochte of off-market woningdata van Redfin scrapen?
Ja. Verkochte woningdata en de off-market Redfin Estimate (mediane fout ) zijn beschikbaar op detailpagina’s met dezelfde scrapingaanpakken. De velden verschillen van actieve listings: off-marketpagina’s tonen verkoopprijs, verkoopdatum, woninggeschiedenis en het owner-estimate-endpoint, maar missen de huidige vraagprijs, dagen op de markt en openhuisinformatie. Het Stingray API-endpoint voor off-market estimates is api/home/details/owner-estimate in plaats van api/home/details/avm.
Meer lezen