

Stel je voor: het is maandagochtend, je koffie is nog lekker warm, en je HR-team zit alweer tot over hun oren in een Excel-sheet, handmatig vacatures te kopiëren van allerlei verschillende websites. LinkedIn, Indeed, werken-bij-pagina’s, niche vacaturebanken—elk met hun eigen opmaak en eigenaardigheden. Tegen de tijd dat je een fractie van de benodigde vacatures hebt verzameld, is je koffie koud, zijn je ogen vierkant en vraag je je af of dit niet slimmer kan (spoiler: dat kan dus echt).
Na jaren in SaaS en automatisering heb ik van dichtbij gezien hoe de digitale arbeidsmarkt is geëxplodeerd. Op elk moment staan er tientallen miljoenen vacatures online, waarvan alleen al op LinkedIn zo’n 60 miljoen actieve vacatures. De schaal is gigantisch—en HR-teams staan onder steeds grotere druk om bij te blijven. Maar het probleem: de meeste HR-professionals zijn geen programmeurs, en traditionele scrapingtools of API’s zijn daar niet op ingericht. Hier komen AI-gedreven tools zoals Thunderbit om de hoek kijken, waarmee vacatures scrapen niet alleen mogelijk, maar zelfs leuk wordt (ja, echt waar).
Scrape vacatures van elke website met AI Get Started Free
Laten we eens kijken waarom vacatures scrapen zo belangrijk is, waarom het tot nu toe zo lastig was voor HR-teams, en hoe AI het speelveld verandert—vooral als je klaar bent met eindeloos knippen en plakken.
Wat betekent vacatures scrapen eigenlijk?
In de basis betekent vacatures scrapen dat je software inzet om automatisch vacaturedata van websites te verzamelen—denk aan functietitel, bedrijf, locatie, salaris, omschrijving, eisen en meer. In plaats van alles handmatig over te typen, ‘leest’ een webscraper de pagina en haalt gestructureerde data op die je direct kunt analyseren of in je HR-systemen kunt zetten.
De bronnen zijn net zo divers als de vacatures zelf:
- LinkedIn (de grootste)
- Werken-bij-pagina’s (zoals Netflix of OpenAI)
- Grote vacaturebanken (Indeed, Monster)
- Niche jobboards (voor tech, zorg, onderwijs, enz.)
Het mooie? Je bouwt je eigen dataset van de arbeidsmarkt, klaar voor salarisvergelijkingen, concurrentieanalyse of om simpelweg te volgen wie waar naar mensen zoekt.
Waarom vacatures scrapen? Belangrijkste toepassingen en voordelen
Waarom zou je überhaupt vacatures willen scrapen? Voor HR- en recruitmentteams draait het om ruwe vacaturedata omzetten in bruikbare inzichten. Dit zijn de meest waardevolle toepassingen:
| Toepassing | Voordeel | ROI / Impact Voorbeeld |
|---|---|---|
| Salarisbenchmarking | Aantrekkelijke arbeidsvoorwaarden bieden | Voorkomt onderbetaling; zorgt dat je aanbod marktconform is—minder afgewezen aanbiedingen. Actuele salarisdata voorkomt dat je kandidaten verliest aan beter betalende concurrenten. |
| Concurrentie volgen | Inzicht in wervingsstrategie van concurrenten | Vroegtijdig signaleren van groei of nieuwe functies bij concurrenten. Zie je dat een concurrent 50+ engineers zoekt? Dan kun je je eigen strategie aanpassen. Analyse van vacaturedata onthult trends en gevraagde skills. |
| Interne vacaturedatabase | Centraal inzicht in de arbeidsmarkt voor HR | Enorme tijdwinst bij dataverzameling. Automatisch scrapen levert 10.000+ vacatures per dag op, versus ~100 handmatig, waardoor HR zich kan richten op analyse. Automatisering haalt duizenden vacatures per dag binnen. |
| Skills gap analyse | Training en werving afstemmen op marktvraag | Data-gedreven talentontwikkeling. Zie je dat 70% van de vacatures in jouw branche Python vraagt? Dan kun je daarop inspelen met training of werving. Helpt bedrijven bij het plannen van opleidings- of wervingsbeleid. |
Kortom: vacatures scrapen helpt moderne HR-teams om niet langer op onderbuikgevoel te sturen, maar op data. En met 38% van de HR-beslissers die inmiddels AI inzetten, groeit deze trend razendsnel.
Traditionele manieren waarop HR-teams vacatures scrapen (en de nadelen)
Hoe hebben HR-teams tot nu toe geprobeerd vacatures te scrapen—en waarom was dat zo frustrerend?
De API-route
Veel HR-teams zonder programmeerkennis proberen het via officiële API’s (als die er al zijn). Het idee: je koppelt aan de API van een vacaturebank, haalt gestructureerde data op, en klaar. In de praktijk? Niet echt.
De grootste nadelen van vacatures scrapen via API’s:

- Beperkte toegang: Veel grote sites (zoals LinkedIn) hebben geen publieke API voor vacatures.
- Strenge limieten: Als je al toegang krijgt, mag je vaak maar een beperkt aantal vacatures per dag ophalen.
- Ontbrekende velden: API’s geven niet altijd alle gewenste data (zoals volledige omschrijvingen of salarisinformatie).
- Technische drempel: API’s integreren vraagt om ontwikkelaars, kennis van JSON/XML en onderhoud.
- Constante veranderingen: API’s kunnen wijzigen of verdwijnen, waardoor je workflow ineens niet meer werkt.
Voor de meeste HR’ers voelt het als de sleutels van een ruimteschip krijgen—leuk, maar je hebt een pilotenbrevet en veel geduld nodig.
Zelf scrapers coderen
Teams met ontwikkelaars bouwen soms eigen Python-scripts met libraries als BeautifulSoup of Scrapy. Je hebt dan alles in eigen hand, maar het is tijdrovend en kwetsbaar. Elke keer dat een website verandert, moet je script opnieuw. En inloggen, infinite scroll of anti-botmaatregelen zijn een nachtmerrie.
Zoals iemand het omschreef: “Het is als IKEA-meubels in elkaar zetten zonder handleiding”—het kan, maar het is vaak frustrerend en langzaam (meer hierover).
No-code scrapingtools (zonder AI)
Dan zijn er de klassieke no-code tools. Je klikt velden aan op een webpagina, maar je moet nog steeds per site patronen instellen. Beter dan zelf coderen, maar je hebt alsnog technisch inzicht en veel trial-and-error nodig. Verandert een site? Dan kun je opnieuw beginnen. En bij complexe sites met pop-ups of infinite scroll raak je snel het overzicht kwijt (zie gebruikersreviews).
Handmatig kopiëren en plakken
En natuurlijk is er de ouderwetse manier: vacatures kopiëren naar Excel. Traag, foutgevoelig en, eerlijk is eerlijk, “zielsvermoeiend” (ik spreek uit ervaring). Met geluk haal je 100 vacatures per dag, maar met miljoenen online is dat onbegonnen werk.
Maak kennis met Thunderbit: de no-code AI-oplossing voor vacatures scrapen
Hier komt Thunderbit in beeld. Als medeoprichter en CEO ben ik misschien bevooroordeeld, maar ik heb Thunderbit gebouwd omdat ik zag hoe HR-teams worstelden met traditionele scrapingtools. Thunderbit is een AI-gedreven, no-code webscraper speciaal voor zakelijke gebruikers—vooral HR- en recruitmentteams die snel resultaat willen, zonder afhankelijk te zijn van IT.
Dit is hoe Thunderbit het verschil maakt:
- No-code, twee klikken: Klik op “AI Suggest Fields”, laat de AI de pagina lezen, en klik op “Scrape”. Geen selectors, geen scripts, geen gedoe.
- Geen IT meer nodig: HR kan zelf vacatures scrapen, zonder te wachten op ontwikkelaars.
- Werkt op elke vacaturebank of werken-bij-pagina: Thunderbit’s AI snapt verschillende paginavormen, dus je hoeft niet telkens een nieuwe template te maken.
- Verrijkte, gepersonaliseerde data: Thunderbit kan data labelen, vertalen, samenvatten en formatteren tijdens het scrapen.
Laten we zien hoe dat er in de praktijk uitziet.
Thunderbit in actie: vacatures scrapen van elke website
Een van de grootste uitdagingen bij vacatures scrapen is de enorme variatie aan bronnen. LinkedIn, Netflix, OpenAI—ze zien er allemaal anders uit, gebruiken andere labels en veranderen regelmatig van opmaak.
Met Thunderbit hoef je je daar geen zorgen over te maken. De AI leest de pagina als een mens, herkent de belangrijkste velden en haalt ze eruit—ongeacht de structuur van de site.
Voorbeeld: Netflix en OpenAI werken-bij-pagina’s scrapen
Laten we twee praktijkvoorbeelden bekijken:
1. Netflix Machine Learning Engineer vacature
Netflix gebruikt een ATS-systeem, met secties als:

- Functietitel: “Machine Learning Engineer”
- Locatie: “USAStel je voor: het is maandagochtend, je koffie is nog lekker warm, en je HR-team zit alweer tot over hun oren in een Excel-sheet, handmatig vacatures te kopiëren van allerlei verschillende websites. LinkedIn, Indeed, werken-bij-pagina’s, niche jobboards—elk met hun eigen opmaak en eigenaardigheden. Tegen de tijd dat je een fractie van de benodigde vacatures hebt verzameld, is je koffie koud, zijn je ogen vierkant en vraag je je af: kan dit niet slimmer? (Spoiler: dat kan dus echt.)
Na jaren in de SaaS en automatisering heb ik van dichtbij gezien hoe de digitale arbeidsmarkt is geëxplodeerd. Op elk moment staan er tientallen miljoenen vacatures online, waarvan alleen al op LinkedIn zo’n 60 miljoen actieve vacatures. De schaal is gigantisch—en HR-teams staan onder steeds grotere druk om bij te blijven. Maar het probleem: de meeste HR-professionals zijn geen programmeurs, en traditionele scrapingtools of API’s zijn daar niet op ingericht. Hier komen AI-gedreven tools zoals Thunderbit om de hoek kijken, waarmee vacatures scrapen niet alleen mogelijk, maar zelfs leuk wordt (ja, echt waar).
Scrape vacatures van elke website met AI Get Started Free
Laten we eens kijken waarom vacatures scrapen zo belangrijk is, waarom het tot nu toe zo’n gedoe was voor HR-teams, en hoe AI het speelveld compleet verandert—vooral als je klaar bent met eindeloos knippen en plakken.
Wat houdt vacatures scrapen precies in?
Heel simpel gezegd betekent vacatures scrapen dat je software inzet om automatisch vacaturedata van websites te verzamelen—denk aan functietitel, bedrijf, locatie, salaris, omschrijving, eisen en meer. In plaats van alles handmatig over te typen, ‘leest’ een webscraper de pagina en haalt gestructureerde data op die je direct kunt analyseren of in je HR-systemen kunt zetten.
De bronnen zijn net zo divers als de vacatures zelf:
- LinkedIn (de allergrootste)
- Werken-bij-pagina’s (zoals Netflix of OpenAI)
- Grote vacaturebanken (Indeed, Monster)
- Niche jobboards (voor tech, zorg, onderwijs, enz.)
Het mooie? Je bouwt je eigen dataset van de arbeidsmarkt, klaar voor salarisvergelijkingen, concurrentieanalyse of gewoon om te volgen wie waar naar mensen zoekt.
Waarom vacatures scrapen? De belangrijkste toepassingen en voordelen
Waarom zou je überhaupt vacatures willen scrapen? Voor HR- en recruitmentteams draait het om ruwe vacaturedata omzetten in bruikbare inzichten. Dit zijn de meest waardevolle toepassingen:
| Toepassing | Voordeel | ROI / Impact Voorbeeld |
|---|---|---|
| Salarisbenchmarking | Aantrekkelijke arbeidsvoorwaarden bieden | Voorkomt onderbetaling; zorgt dat je aanbod marktconform is—minder afgewezen aanbiedingen. Actuele salarisdata voorkomt dat je kandidaten verliest aan beter betalende concurrenten. |
| Concurrentie volgen | Inzicht in wervingsstrategie van concurrenten | Vroegtijdig signaleren van groei of nieuwe functies bij concurrenten. Zie je dat een concurrent 50+ engineers zoekt? Dan kun je je eigen strategie aanpassen. Analyse van vacaturedata onthult trends en gevraagde skills. |
| Interne vacaturedatabase | Centraal inzicht in de arbeidsmarkt voor HR | Enorme tijdwinst bij dataverzameling. Automatisch scrapen levert 10.000+ vacatures per dag op, versus ~100 handmatig, waardoor HR zich kan richten op analyse. Automatisering haalt duizenden vacatures per dag binnen. |
| Skills gap analyse | Training en werving afstemmen op marktvraag | Data-gedreven talentontwikkeling. Zie je dat 70% van de vacatures in jouw branche Python vraagt? Dan kun je daarop inspelen met training of werving. Helpt bedrijven bij het plannen van opleidings- of wervingsbeleid. |
Kortom: vacatures scrapen helpt moderne HR-teams om niet langer op onderbuikgevoel te sturen, maar op data. En met 38% van de HR-beslissers die inmiddels AI inzetten, groeit deze trend razendsnel.
Hoe HR-teams tot nu toe vacatures scrapen (en waarom dat zo frustrerend is)
Hoe hebben HR-teams tot nu toe geprobeerd vacatures te scrapen—en waarom was dat zo’n gedoe?
De API-route
Veel HR-teams zonder programmeerkennis proberen het via officiële API’s (als die er al zijn). Het idee: je koppelt aan de API van een vacaturebank, haalt gestructureerde data op, en klaar. In de praktijk? Niet echt.
De grootste nadelen van vacatures scrapen via API’s:
- Beperkte toegang: Veel grote sites (zoals LinkedIn) hebben geen publieke API voor vacatures.
- Strenge limieten: Als je al toegang krijgt, mag je vaak maar een beperkt aantal vacatures per dag ophalen.
- Ontbrekende velden: API’s geven niet altijd alle gewenste data (zoals volledige omschrijvingen of salarisinformatie).
- Technische drempel: API’s integreren vraagt om ontwikkelaars, kennis van JSON/XML en onderhoud.
- Constante veranderingen: API’s kunnen wijzigen of verdwijnen, waardoor je workflow ineens niet meer werkt.
Voor de meeste HR’ers voelt het als de sleutels van een ruimteschip krijgen—leuk, maar je hebt een pilotenbrevet en veel geduld nodig.
Zelf scrapers bouwen
Teams met ontwikkelaars bouwen soms eigen Python-scripts met libraries als BeautifulSoup of Scrapy. Je hebt dan alles in eigen hand, maar het is tijdrovend en kwetsbaar. Elke keer dat een website verandert, moet je script opnieuw. En inloggen, infinite scroll of anti-botmaatregelen zijn een nachtmerrie.
Zoals iemand het omschreef: “Het is als IKEA-meubels in elkaar zetten zonder handleiding”—het kan, maar het is vaak frustrerend en langzaam (meer hierover).
No-code scrapingtools (zonder AI)
Dan zijn er de klassieke no-code tools. Je klikt velden aan op een webpagina, maar je moet nog steeds per site patronen instellen. Beter dan zelf coderen, maar je hebt alsnog technisch inzicht en veel trial-and-error nodig. Verandert een site? Dan kun je opnieuw beginnen. En bij complexe sites met pop-ups of infinite scroll raak je snel het overzicht kwijt (zie gebruikersreviews).
Handmatig kopiëren en plakken
En natuurlijk is er de ouderwetse manier: vacatures kopiëren naar Excel. Traag, foutgevoelig en, eerlijk is eerlijk, “zielsvermoeiend” (ik spreek uit ervaring). Met geluk haal je 100 vacatures per dag, maar met miljoenen online is dat onbegonnen werk.
Maak kennis met Thunderbit: de no-code AI-oplossing voor vacatures scrapen
Hier komt Thunderbit in beeld. Als medeoprichter en CEO ben ik misschien bevooroordeeld, maar ik heb Thunderbit gebouwd omdat ik zag hoe HR-teams worstelden met traditionele scrapingtools. Thunderbit is een AI-gedreven, no-code webscraper speciaal voor zakelijke gebruikers—vooral HR- en recruitmentteams die snel resultaat willen, zonder afhankelijk te zijn van IT.
Dit is hoe Thunderbit het verschil maakt:
- No-code, twee klikken: Klik op “AI Suggest Fields”, laat de AI de pagina lezen, en klik op “Scrape”. Geen selectors, geen scripts, geen gedoe.
- Geen IT meer nodig: HR kan zelf vacatures scrapen, zonder te wachten op ontwikkelaars.
- Werkt op elke vacaturebank of werken-bij-pagina: Thunderbit’s AI snapt verschillende paginavormen, dus je hoeft niet telkens een nieuwe template te maken.
- Verrijkte, gepersonaliseerde data: Thunderbit kan data labelen, vertalen, samenvatten en formatteren tijdens het scrapen.
Laten we zien hoe dat er in de praktijk uitziet.
Thunderbit in actie: vacatures scrapen van elke website
Een van de grootste uitdagingen bij vacatures scrapen is de enorme variatie aan bronnen. LinkedIn, Netflix, OpenAI—ze zien er allemaal anders uit, gebruiken andere labels en veranderen regelmatig van opmaak.
Met Thunderbit hoef je je daar geen zorgen over te maken. De AI leest de pagina als een mens, herkent de belangrijkste velden en haalt ze eruit—ongeacht de structuur van de site.
Voorbeeld: Netflix en OpenAI werken-bij-pagina’s scrapen
Laten we twee praktijkvoorbeelden bekijken:
1. Netflix Machine Learning Engineer vacature
Netflix gebruikt een ATS-systeem, met secties als:
- Functietitel: “Machine Learning Engineer”
- Locatie: “USA, Remote”
- Team: “Machine Learning Platform”
- Omschrijving: Een uitgebreide sectie met eisen, verantwoordelijkheden en voordelen.
Thunderbit’s AI scant de pagina, stelt velden voor als “Functietitel”, “Locatie”, “Team”, “Omschrijving” en kan zelfs eisen en voordelen apart halen—zonder dat je alles handmatig hoeft aan te klikken.
2. OpenAI Machine Learning Engineer (Integrity)

De werken-bij-pagina van OpenAI is heel anders—statische content, met secties als “About the Role”, “You might thrive in this role if you” en “Benefits”.
Thunderbit herkent dat “You might thrive in this role if you” in feite de “Eisen” zijn, ook al heet het bij Netflix “What we are looking for”. De AI maakt deze velden gelijk, zodat je output altijd een consistente kolom “Eisen” heeft, ongeacht hoe bedrijven het noemen.
Kortom: Met Thunderbit kun je zowel Netflix- als OpenAI-vacatures (en honderden andere) scrapen met exact dezelfde workflow—zonder maatwerk.
Data verrijken en standaardiseren: AI-powered post-processing in Thunderbit
Scrapen is pas het begin. De echte waarde zit in opschonen, standaardiseren en verrijken van je vacaturedata—anders blijft het een rommelige spreadsheet.
Thunderbit laat je per veld AI-prompts toevoegen, zodat je bijvoorbeeld:
- Salarissen standaardiseren: Zet “$4,000/month” en “£50k per annum” om naar een jaarlijks bedrag in USD.
- Eisen samenvoegen: Combineer “What we are looking for”, “You might thrive in this role if you” en “Qualifications” tot één kolom “Eisen”.
- Omschrijvingen vertalen of samenvatten: Laat AI direct vertalen of een korte samenvatting maken.
- Skills of functiegroepen taggen: Gebruik AI om gevraagde skills te labelen of functies te categoriseren.
Voorbeeld: Salarisinformatie standaardiseren
Stel, je scraped twee vacatures:
- Netflix: “$4,000/month”
- OpenAI: “£50,000 per annum”
Met Thunderbit kun je een prompt instellen om alle salarissen om te rekenen naar een jaarlijks bedrag in USD. De AI geeft dan:
- Netflix: “$48,000”
- OpenAI: “$62,000”
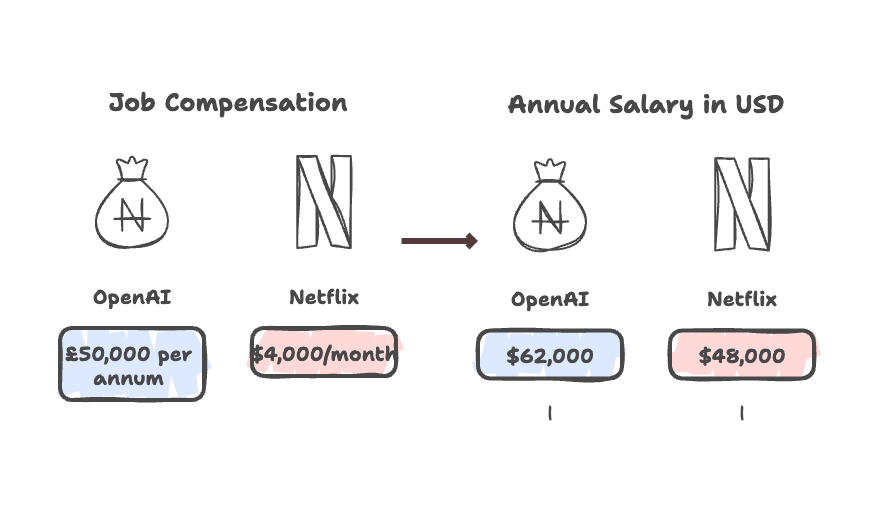
Zo kun je direct appels met appels vergelijken, zonder uren handmatig werk (zie hoe Propellum’s AI-suite dit aanpakt).
Voorbeeld: Eisen uniformeren ondanks verschillende labels
Stel Netflix gebruikt “What we are looking for” en OpenAI “You might thrive in this role if you”. Thunderbit’s AI herkent beide als “Eisen” en voegt ze samen tot één kolom. Geen zoekwerk meer—je data is direct klaar voor analyse.
LinkedIn vacatures scrapen met Thunderbit: zo werkt het
LinkedIn is dé bron voor vacaturedata, maar ook berucht lastig om te scrapen. Geen publieke API, infinite scroll, dynamische content. Handmatig scrapen? Vergeet het maar.
Thunderbit is gemaakt om LinkedIn’s uitdagingen aan te kunnen:
- Scrollt en klikt automatisch door vacatures: De AI-agent navigeert als een mens, laadt details en klikt door elke vacature.
- Gaat door paginering en subpagina’s: Klik op “Scrape Subpages” en Thunderbit bezoekt elke detailpagina, haalt omschrijvingen, bedrijfsinfo en meer op.
- Haalt contactgegevens op (indien aanwezig): Staat er een e-mail of telefoonnummer in de vacature? Thunderbit pikt het automatisch op.
Tip: Gebruik bij voorkeur openbare LinkedIn-vacatures (zonder inloggen), scroll wat om vacatures te laden, en laat Thunderbit zijn werk doen. Binnen enkele minuten heb je een gestructureerde tabel met titels, bedrijven, locaties, omschrijvingen en meer.
Thunderbit versus traditionele job scraper oplossingen
Laten we Thunderbit vergelijken met de klassieke alternatieven:
| Factor | Thunderbit (AI-webscraper) | Traditionele scraper (API/Handmatig/No-code) |
|---|---|---|
| Gebruiksgemak | No-code, twee klikken. Ook niet-technische medewerkers kunnen ermee werken. | Vereist coderen, API-integratie of handmatig velden selecteren. Steile leercurve. |
| Insteltijd | Seconden—AI detecteert velden automatisch. | Uren—handmatig instellen per site. |
| Aanpasbaarheid | Werkt op elke site, ook bij layout-wijzigingen. | Kwetsbaar—breekt bij HTML-wijzigingen. |
| Data-kwaliteit | Hoog—AI begrijpt context en labels. | Foutgevoelig als niet perfect ingesteld. |
| Snelheid & schaal | Snel op te zetten en uit te voeren; honderden pagina’s efficiënt scrapen. | Traag op te zetten; opschalen vraagt complexe configs of dure abonnementen. |
| Technische kennis | Minimaal—gemaakt voor niet-technische gebruikers. | Gemiddeld tot hoog—vaak IT-ondersteuning nodig. |
| Kosten | Freemium; gratis instap mogelijk. | Varieert; kan duur zijn bij grote volumes. |
Voor HR-teams voelt Thunderbit als een slimme assistent die nooit moe wordt of in de war raakt van vreemde websites.
Stappenplan: zo scrape je vacatures met Thunderbit
Zelf aan de slag? Zo kunnen HR-teams binnen enkele minuten vacatures scrapen met Thunderbit.
Stap 1: Installeer de Thunderbit Chrome-extensie
Ga naar de Thunderbit Chrome Extension Download Page en voeg de extensie toe aan je browser. Snel, lichtgewicht en gratis te proberen.
Probeer Thunderbit voor vacatures scrapen
Stap 2: Navigeer naar de gewenste vacaturepagina
Open de vacaturebank of werken-bij-pagina die je wilt scrapen—LinkedIn, Netflix, OpenAI of een andere site.
Stap 3: Gebruik “AI Suggest Fields” om data te herkennen
Klik op het Thunderbit-icoon en kies “AI Suggest Fields”. De AI scant de pagina en stelt voor welke velden je kunt ophalen—functietitel, bedrijf, locatie, salaris, eisen, enzovoort.
Stap 4: Klik op “Scrape” om vacaturedata te verzamelen
Tevreden met de velden? Klik op “Scrape”. Thunderbit verzamelt de data in een gestructureerde tabel en regelt automatisch paginering en subpagina’s.
Stap 5: Exporteer of verrijk je data

Exporteer je data met één klik naar Excel, Google Sheets, Notion of Airtable. Wil je data opschonen, salarissen standaardiseren of skills taggen? Voeg een AI-prompt toe en Thunderbit regelt het tijdens het scrapen.
Meer weten? Bekijk onze gids over scrapen met AI of de stap-voor-stap uitleg voor data naar Excel.
Samenvatting & belangrijkste punten
- Vacatures scrapen is onmisbaar voor HR-teams die willen concurreren, salarissen benchmarken, concurrenten volgen en een rijke talentdatabase willen opbouwen.
- Traditionele scrapingmethodes zijn traag, technisch en kwetsbaar—vooral voor niet-programmeurs in HR.
- Thunderbit’s AI-gedreven, no-code aanpak maakt vacatures scrapen voor iedereen toegankelijk. Twee klikken en klaar.
- Thunderbit werkt op elke vacaturebank of werken-bij-pagina, verrijkt en standaardiseert je data en exporteert het waar je wilt.
- HR-teams winnen aan snelheid, nauwkeurigheid en zelfstandigheid—geen IT meer nodig, geen handmatig knip- en plakwerk, geen rommelige spreadsheets meer.
Meer webscraping-gidsen voor HR Get Started Free
Wil je zelf ervaren hoe makkelijk vacatures scrapen kan zijn? Download Thunderbit en ontdek hoe je van vacaturedata een strategisch voordeel maakt.
Meer tips over webscraping, automatisering en AI voor HR? Bekijk de Thunderbit Blog voor handleidingen, reviews en best practices.
Vacatures scrapen met Thunderbit AI
Succes met scrapen—en moge je koffie warm blijven en je spreadsheets overzichtelijk.
FAQ:
1. Waarom zou een HR-team vacatures willen scrapen?
Door vacatures te scrapen kan HR gestructureerde vacaturedata verzamelen van verschillende bronnen—zoals LinkedIn, Indeed en werken-bij-pagina’s—zonder handmatig te kopiëren. Dit maakt betere salarisvergelijkingen, concurrentieanalyse, skills gap analyse en het opbouwen van een interne vacaturedatabase mogelijk.
2. Wat zijn de grootste uitdagingen bij traditionele scrapingmethodes?
Traditionele methodes—zoals API’s, eigen code of no-code tools—vereisen technische kennis, zijn kwetsbaar bij layout-wijzigingen en missen vaak belangrijke data. Handmatig kopiëren is traag en foutgevoelig, en niet schaalbaar voor grote datasets.
3. Hoe maakt Thunderbit vacatures scrapen eenvoudig voor niet-technische gebruikers?
Thunderbit gebruikt AI om automatisch relevante vacaturevelden te herkennen en te extraheren van elke website. Je klikt simpelweg op “AI Suggest Fields” en daarna op “Scrape”. Het werkt op LinkedIn, werken-bij-pagina’s en vacaturebanken—zonder coderen of instellen.
4. Kan Thunderbit omgaan met complexe sites zoals LinkedIn of Netflix?
Ja. Thunderbit kan automatisch scrollen door lijsten, subpagina’s openen, omschrijvingen ophalen en velden als functietitel, locatie en salaris herkennen—zelfs als de layout sterk verschilt. Het werkt zoals een mens zou browsen, maar dan op schaal.
5. Wat maakt Thunderbit anders dan andere no-code scrapingtools?
In tegenstelling tot point-and-click tools gebruikt Thunderbit AI om content contextueel te begrijpen. Het past zich aan bij layout-wijzigingen, verrijkt gescrapete data (zoals salarissen standaardiseren, skills taggen) en ondersteunt export naar Google Sheets of Airtable—met minimale setup.
Probeer AI-webscraper voor vacatures Get Started Free




