Iets rond mijn vijftigste kopieer-plakactie van een functietitel van Indeed naar een spreadsheet begon ik mijn carrièrekeuzes in twijfel te trekken. Als je ooit geprobeerd hebt om gestructureerde data programmatisch uit Indeed te halen, ken je de clou al: de 403-fout is geen bug — het is een functie van Indeed's verdedigingssysteem.
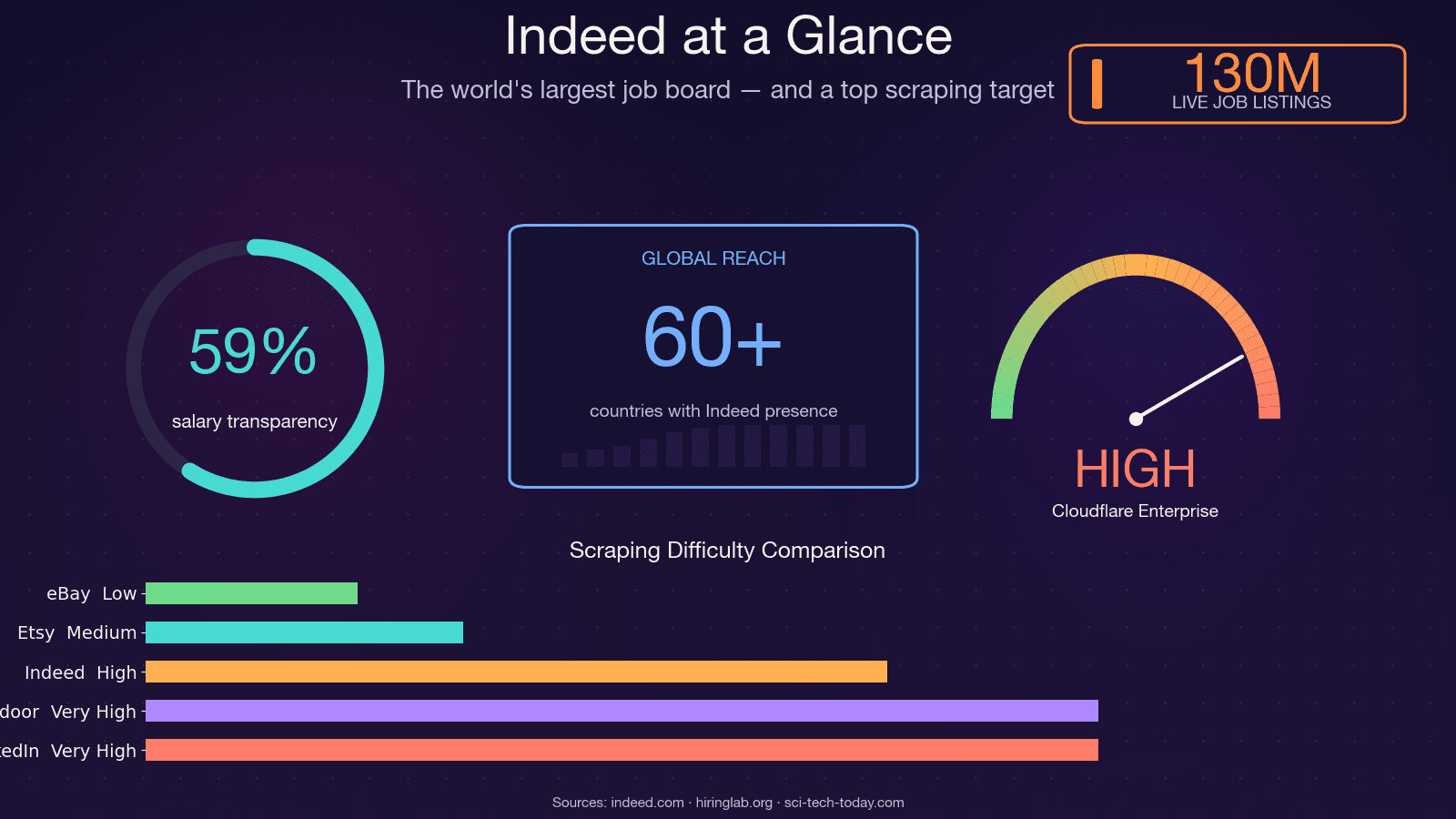
Indeed is 's werelds grootste vacaturebank, met ongeveer , op elk moment, en activiteiten in . Daarmee is het een van de rijkste bronnen voor arbeidsmarktdata op aarde — en een van de lastigste om te scrapen. De open-source scraper JobFunnel (duizenden GitHub-stars) werd in december 2025 letterlijk na jaren van verliezen in de anti-bot-wapenwedloop. In de woorden van de maintainer zelf: "Alle gebruikers kunnen een deel van de vacatures scrapen, maar worden al snel geraakt door captcha, waarna het scrapen faalt en er geen vacatures overblijven." Een andere bijdrager meldde zelfs een CAPTCHA . Dus ja — dit is geen simpel scrapingdoel. In deze gids loop ik door alle praktische manieren om Indeed met Python te scrapen, laat ik zien hoe je de 403-horde daadwerkelijk kunt overleven, en — voor wie liever het debuggen helemaal overslaat — demonstreer ik een no-code alternatief met .
Wat betekent het om Indeed met Python te scrapen?
Webscraping is in de kern het geautomatiseerd extraheren van gestructureerde data uit webpagina's. Als we het hebben over Indeed scrapen met Python, bedoelen we het schrijven van een script dat Indeed's zoekresultaten en vacaturepagina's bezoekt, de onderliggende HTML (of ingesloten data) leest, en velden als functietitel, bedrijf, locatie, salaris en beschrijving ophaalt in een bruikbaar formaat — een CSV, een database, een Google Sheet.
De gebruikelijke Python-bibliotheken hierbij zijn Requests (voor HTTP-calls), BeautifulSoup (voor HTML-parsing) en Selenium of Playwright (voor browserautomatisering). Maar Indeed is geen simpele statische site. Het is een hybride: server-side gerenderde HTML met een ingebedde JSON-stateblob, beveiligd door Cloudflare Bot Management. Dat betekent dat je scraper moet omgaan met JavaScript-gerenderde content, wisselende CSS-klassen en agressieve anti-botbescherming — nog vóór je één functietitel kunt parseren.
Er is in 2026 ook geen officiële, gratis, read-only Indeed API. De oude Publisher Jobs API werd rond 2020 uitgefaseerd, en wat resteert is alleen voor werkgevers (Job Sync, Sponsored Jobs). Scrapen of betalen voor een externe dataprovider zijn dus de enige realistische opties.
Waarom Indeed-vacaturedata scrapen?
De zakelijke reden om Indeed te scrapen is eenvoudig: handmatig door duizenden vacatures bladeren is onpraktisch, en de data in die vacatures is echt waardevol.
| Gebruiksscenario | Wie profiteert | Voorbeeld |
|---|---|---|
| Leadgeneratie | Sales- en recruitingteams | Lijsten bouwen van bedrijven die aannemen, met contactgegevens |
| Onderzoek naar de arbeidsmarkt | Analisten, HR-teams | Trendende vaardigheden en salarismarkeringen per regio identificeren |
| Concurrentie-informatie | Werkgevers, uitzendbureaus | Inhuurpatronen en salarisaangeboden van concurrenten volgen |
| Automatisering van persoonlijke baanzoektocht | Werkzoekenden | Vacatures bundelen die aan je criteria voldoen, over meerdere locaties |
| Trainingsdata voor ML-modellen | Data scientists | Salarisvoorspellingsmodellen bouwen op basis van historische vacaturedata |
Indeed Hiring Lab bevestigt in eigen onderzoek vacaturedata nauw samenhangt met BLS JOLTS en kan dienen als een bijna realtime afspiegeling van de Amerikaanse arbeidsmarkt. Hedgefondsen gebruiken de snelheid waarmee vacatures worden geplaatst als alternatieve datasignaal. HR-teams benchmarken compensatie met behulp van gescrapete salarisschalen. En recruiters bouwen prospectlijsten op van bedrijven die actief personeel zoeken.
Een praktische opmerking: salarisdata op Indeed wordt beter, maar is nog steeds onvolledig. Medio 2025 bevat ongeveer salarisinformatie, maar slechts ongeveer geeft een exact bedrag; de rest zijn bandbreedtes. Elke salarisanalyse op basis van Indeed-data moet rekening houden met die schaarste.
Je methode kiezen om Indeed met Python te scrapen
Er is niet één "juiste" manier om Indeed te scrapen. De beste aanpak hangt af van je vaardigheidsniveau, hoeveel data je nodig hebt en hoeveel onderhoud je wilt accepteren. Ik heb alle vier de belangrijkste aanpakken getest, en dit is hoe ze zich verhouden:
| Criteria | BS4 + Requests | Selenium | Verborgen JSON (window.mosaic) | No-code (Thunderbit) |
|---|---|---|---|---|
| Moeilijkheidsgraad | Beginner | Gemiddeld | Gemiddeld-gevorderd | Geen (2 klikken) |
| Snelheid | Snel | Traag (browser renderen) | Snel | Snel (cloudscraping) |
| JS-gerenderde content | Nee | Ja | Ja (ingesloten data) | Ja |
| Weerbaarheid tegen anti-bot | Laag | Midden (detecteerbaar) | Midden-hoog | Hoog (automatisch afgehandeld) |
| Onderhoud bij HTML-wijzigingen | Hoog (selectors breken) | Hoog | Gemiddeld (JSON-structuur stabieler) | Geen (AI past zich aan) |
| Het beste voor | Snelle prototypes | Dynamische pagina's, login-afgeschermd | Grote hoeveelheden gestructureerde data | Niet-developers, snelle resultaten |
Deze gids loopt door elke methode. Ben je Python-developer, lees dan vooral de BS4-, Verborgen JSON- en Selenium-secties. Ben je geen codeur (of ben je gewoon moe van 403-debugging), sla dan door naar het Thunderbit-gedeelte.
Voor je begint
- Moeilijkheidsgraad: Beginner tot gemiddeld (Python-gedeelten); geen (Thunderbit-gedeelte)
- Benodigde tijd: ~20–60 minuten voor Python-setup en eerste scrape; ~2 minuten met Thunderbit
- Wat je nodig hebt: Python 3.9+, een code-editor, Chrome-browser en (voor de no-code route) de
Je Python-omgeving instellen voor Indeed-scraping
Voordat je scrapingcode schrijft, zet je omgeving goed klaar.
Installeer de vereiste bibliotheken
Maak een virtuele omgeving en installeer de pakketten die je nodig hebt:
1python -m venv indeed_env
2source indeed_env/bin/activate # Op Windows: indeed_env\Scripts\activate
3# Voor de HTTP + parsing-aanpak
4pip install requests beautifulsoup4 lxml httpx
5# Voor de verborgen JSON-aanpak (aanbevolen)
6pip install curl_cffi parsel tenacity
7# Voor de browserautomatiseringsaanpak
8pip install seleniumEen paar opmerkingen:
curl_cffiis in 2026 de standaard voor het scrapen van sites achter Cloudflare. Het imiteert echte browser-TLS-fingerprints, iets wat gewonerequestsenhttpxniet kunnen. Meer over waarom dit belangrijk is in de anti-botsectie.- Selenium 4.6+ wordt geleverd met Selenium Manager, dus je hoeft ChromeDriver niet langer handmatig te downloaden — het beheert de browserbinary automatisch.
- Gebruik
lxmlals parser-backend voor BeautifulSoup. Die is ongeveer dan de standaardhtml.parser.
Maak je projectstructuur aan
Houd het simpel:
1indeed_scraper/
2├── scraper.py
3├── requirements.txt
4└── output/Alle codevoorbeelden hieronder bouwen verder op scraper.py.
Hoe je Indeed met Python scrapt met BeautifulSoup
Dit is de beginnersvriendelijke aanpak: gebruik requests om de pagina op te halen en BeautifulSoup om de HTML te parsen. Het is het snelst om op te zetten, maar ook het kwetsbaarst op Indeed.
Stap 1: Bouw de Indeed-zoek-URL
Indeed's zoek-URL's volgen een voorspelbaar patroon:
1https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>Bijvoorbeeld, zoeken naar "data analyst" in "Austin, TX", beginnend op de eerste pagina:
1from urllib.parse import urlencode
2params = {
3 "q": "data analyst",
4 "l": "Austin, TX",
5 "start": 0,
6}
7url = f"https://www.indeed.com/jobs?{urlencode(params)}"
8print(url)
9# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0Indeed pagineert in stappen van 10, met een harde limiet van 1.000 resultaten (start <= 990). Elke offset boven 990 geeft stilzwijgend dezelfde pagina terug.
Stap 2: Stuur een HTTP-verzoek met de juiste headers
Indeed blokkeert requests met standaard Python user-agent strings direct. Je hebt realistische headers nodig:
1import requests
2headers = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
5 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.indeed.com/",
11}
12response = requests.get(url, headers=headers, timeout=30)
13print(response.status_code)Als je een 200 krijgt, zit je erin — voorlopig. Krijg je een 403, dan heeft Cloudflare je gepakt. (Meer over hoe je daar doorheen komt hieronder.)
Stap 3: Parse vacatures uit de HTML
Gebruik BeautifulSoup om vacaturekaart-elementen te selecteren. Richt je op data-testid-attributen — die zijn stabieler dan Indeed's willekeurig veranderende CSS-klassen:
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(response.text, "lxml")
3cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
4jobs = []
5for card in cards:
6 title_el = card.find("h2", class_="jobTitle")
7 title = title_el.get_text(strip=True) if title_el else None
8 company = card.find(attrs={"data-testid": "company-name"})
9 location = card.find(attrs={"data-testid": "text-location"})
10 link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
11 jobs.append({
12 "title": title,
13 "company": company.get_text(strip=True) if company else None,
14 "location": location.get_text(strip=True) if location else None,
15 "url": f"https://www.indeed.com\{link\}" if link else None,
16 })
17print(f"Gevonden vacatures: {len(jobs)}")Stap 4: Omgaan met paginering
Loop door de pagina's door de start-parameter te verhogen:
1import time, random
2all_jobs = []
3for page in range(0, 50, 10): # Eerste 5 pagina's
4 params["start"] = page
5 url = f"https://www.indeed.com/jobs?{urlencode(params)}"
6 response = requests.get(url, headers=headers, timeout=30)
7 # ... parse zoals hierboven ...
8 all_jobs.extend(jobs)
9 time.sleep(random.uniform(3, 6))Beperkingen van deze aanpak
Ik ben daar eerlijk over: BS4 + Requests is in 2026 de zwakste methode voor Indeed. Gewone requests gebruikt Python's standaard TLS-bibliotheek, die een produceert die Cloudflare direct herkent als "geen browser". Bovendien ondersteunt het geen HTTP/2, terwijl Indeed dat wel aanbiedt. Je loopt waarschijnlijk tegen blokkades aan na een handvol pagina's. En die CSS-selectors? Indeed roteert klassen als css-1m4cuuf en jobsearch-JobComponent-embeddedBody-1n0gh5s — elke selector daarop is dus een tikkende tijdbom.
Gebruik deze methode voor snelle prototyping op één pagina. Voor iets op schaal gebruik je beter de verborgen JSON-aanpak.
Hoe je Indeed met Python scrapt met verborgen JSON-data
Dit is de methode die ik de meeste Python-developers aanraad. In plaats van fragiele HTML-elementen te parsen, haal je gestructureerde data uit een JavaScript-variabele die in de broncode van Indeed zit: window.mosaic.providerData["mosaic-provider-jobcards"].
Elk veld dat je nodig hebt — functietitel, bedrijf, locatie, salaris, vacaturekey, publicatiedatum, remote-indicator — zit al in die JSON-blob. Geen JavaScript-uitvoering nodig. Het schema is , waardoor het veel robuuster is dan DOM-selectors.
Stap 1: Haal de HTML van de pagina op
Gebruik curl_cffi in plaats van requests — het imiteert echte browser-TLS-fingerprints, wat cruciaal is om Cloudflare te overleven:
1from curl_cffi import requests as cffi_requests
2response = cffi_requests.get(
3 "https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
4 impersonate="chrome124",
5 headers={
6 "Accept-Language": "en-US,en;q=0.9",
7 "Referer": "https://www.indeed.com/",
8 },
9 timeout=30,
10)
11print(response.status_code, len(response.text))Waarom curl_cffi? Het is een Python-binding rond curl-impersonate, die exact de TLS ClientHello, HTTP/2 SETTINGS-frame en header-volgorde van echte browsers reproduceert. Het is de enige actief onderhouden Python HTTP-client die in één call omzeilt. Ondersteunde impersonatie-doelen zijn onder andere chrome120, chrome124, chrome131, Safari en Edge-varianten.
Stap 2: Extraheer de JSON met een reguliere expressie
De JSON-blob zit ingebed in een <script>-tag. Haal hem eruit met een regex:
1import re, json
2MOSAIC_RE = re.compile(
3 r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
4 re.DOTALL,
5)
6match = MOSAIC_RE.search(response.text)
7if match:
8 data = json.loads(match.group(1))
9 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
10 print(f"Gevonden vacatures in verborgen JSON: {len(results)}")
11else:
12 print("Verborgen JSON niet gevonden — mogelijk blokkade of paginawijziging")Stap 3: Parse vacaturevelden uit de JSON
Elk item in results bevat meer data dan wat zichtbaar is op de pagina:
1jobs = []
2for job in results:
3 jobs.append({
4 "jobkey": job["jobkey"],
5 "title": job["title"],
6 "company": job.get("company"),
7 "location": job.get("formattedLocation"),
8 "remote": job.get("remoteLocation"),
9 "salary": (job.get("salarySnippet") or {}).get("text"),
10 "posted": job.get("formattedRelativeTime"),
11 "job_type": job.get("jobTypes"),
12 "easy_apply": job.get("indeedApplyEnabled"),
13 "url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
14 })De JSON bevat vaak ook salarisinschattingen, taxonomie-attributen (vaardigheidstags) en bedrijfsbeoordelingen die niet altijd zichtbaar zijn in de gerenderde HTML.
Stap 4: Scrape meerdere pagina's
Gebruik tierSummaries in de JSON om het totale aantal resultaten te begrijpen, en loop dan door de pagina's:
1import time, random
2all_jobs = []
3for start in range(0, 50, 10): # Eerste 5 pagina's
4 url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=\{start\}&sort=date"
5 response = cffi_requests.get(
6 url,
7 impersonate="chrome124",
8 headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
9 timeout=30,
10 )
11 match = MOSAIC_RE.search(response.text)
12 if match:
13 data = json.loads(match.group(1))
14 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
15 all_jobs.extend([{
16 "jobkey": j["jobkey"],
17 "title": j["title"],
18 "company": j.get("company"),
19 "location": j.get("formattedLocation"),
20 "salary": (j.get("salarySnippet") or {}).get("text"),
21 "url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
22 } for j in results])
23 time.sleep(random.uniform(3, 7))
24print(f"Totaal: {len(all_jobs)} vacatures gescrapet")Waarom verborgen JSON robuuster is
De window.mosaic.providerData-structuur verandert minder vaak dan CSS-klassen. Je krijgt schone, gestructureerde data zonder rommelige HTML te hoeven parsen. Dat gezegd hebbende: je hebt nog steeds anti-botmaatregelen nodig (headers, vertragingen, proxies) — en die komen straks aan bod.
Hoe je Indeed met Python scrapt met Selenium
Selenium is de browserautomatiseringsaanpak. Die is handig wanneer je met de pagina moet interacteren — doorklikken naar vacaturedetailpanelen, content achter login afhandelen, of dynamisch geladen beschrijvingen scrapen die niet in de initiële HTML staan.
Wanneer Selenium gebruiken in plaats van HTTP-clients
- Indeed laadt bepaalde content dynamisch (volledige vacaturebeschrijvingen in het rechterpaneel)
- Je moet pagina's scrapen waarvoor sessiestatus of login nodig is
- Je doet kleinschalig scrapen waarbij snelheid niet cruciaal is
Snelle walkthrough
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.chrome.options import Options
4import time
5options = Options()
6options.add_argument("--disable-blink-features=AutomationControlled")
7# options.add_argument("--headless=new") # Headless is beter detecteerbaar — gebruik voorzichtig
8driver = webdriver.Chrome(options=options)
9driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
10time.sleep(3)
11cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
12for card in cards:
13 try:
14 title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
15 company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
16 location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
17 print(f"\{title\} | \{company\} | \{location\}")
18 except Exception:
19 continue
20driver.quit()Beperkingen
Selenium is traag — elke pagina moet volledig in de browser worden gerenderd. Headless Chrome is (Cloudflare controleert navigator.webdriver, WebGL-vendor strings, pluginaantallen en meer). Zelfs undetected-chromedriver vertraagt detectie slechts; het voorkomt die niet permanent. En net als bij BS4 breken je selectors wanneer Indeed zijn UI aanpast.
Voor de meeste use-cases levert de verborgen JSON-aanpak dezelfde data, sneller en met minder onderhoud. Bewaar Selenium voor edge cases waarin je echt een browser nodig hebt.
Hoe je 403-fouten vermijdt bij het scrapen van Indeed met Python
Dit is de sectie die het belangrijkst is. Als je hier bent beland na een gefrustreerde Google-zoekopdracht, zit je op de juiste plek.
Waarom Indeed je scraper blokkeert
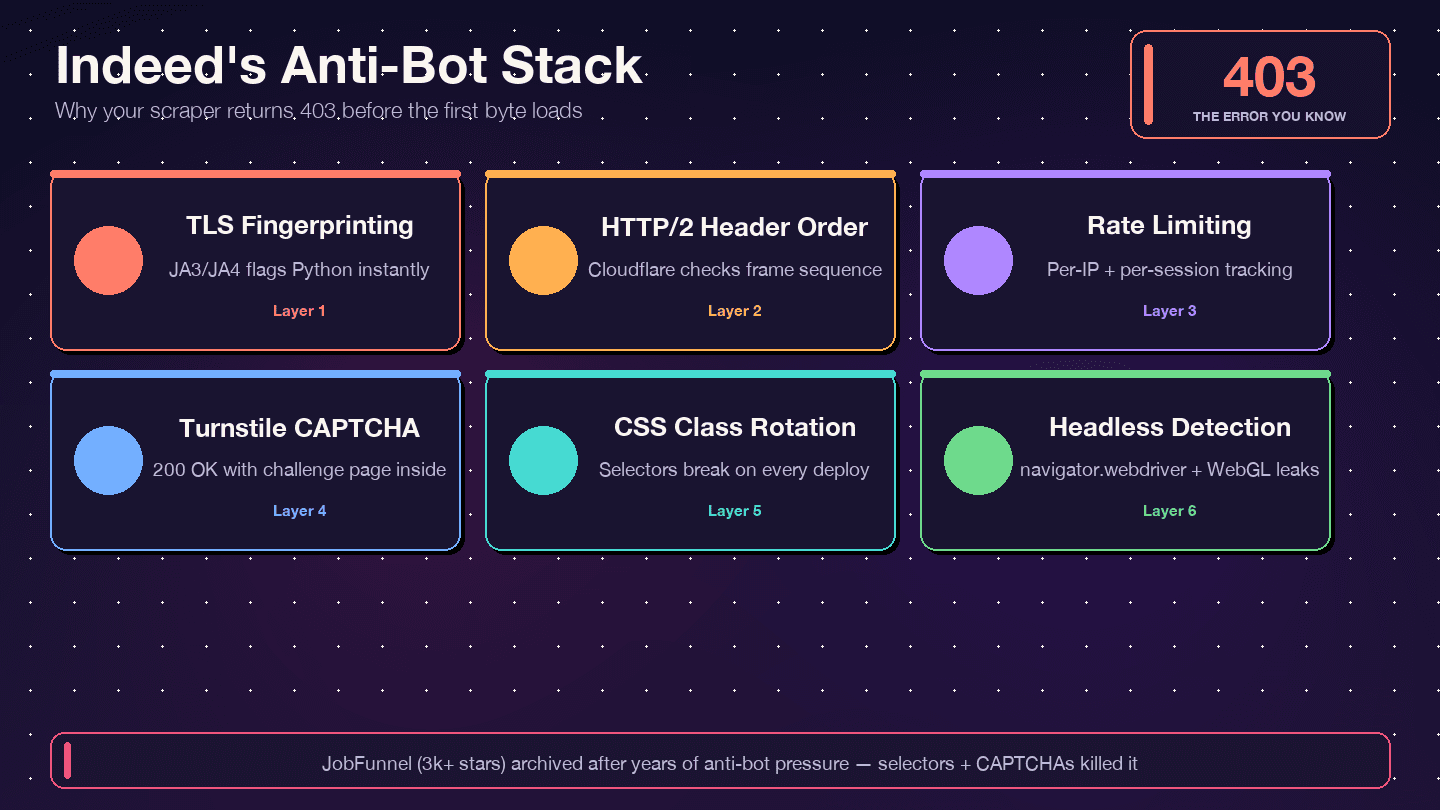
Indeed gebruikt — niet DataDome, niet PerimeterX. Dat zie je terug in de responseheaders: server: cloudflare, cf-ray en de __cf_bm-cookie voor botmanagement. Cloudflare inspecteert je TLS-fingerprint (JA3/JA4), de volgorde van HTTP/2-headers, requestpatronen en signalen van browsergedrag. Als iets daarvan niet menselijk lijkt, krijg je een 403, 429, 503 of — het sluwste geval — een 200 OK met een Turnstile-uitdagingspagina in plaats van echte vacaturedata.
Roteer User-Agent en requestheaders
Eén statische User-Agent is de snelste manier om geblokkeerd te worden. Roteer uit een pool van actuele, realistische strings. Belangrijk: de minor-versionvelden van Chrome zijn sinds User-Agent Reduction — verzin geen niet-nul minor-versies, anders gaan anti-bots daar direct op af.
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
6 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
7 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
8 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
9 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
10 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
11 "(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
12]
13headers = {
14 "User-Agent": random.choice(USER_AGENTS),
15 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
16 "Accept-Language": "en-US,en;q=0.9",
17 "Accept-Encoding": "gzip, deflate, br, zstd",
18 "Referer": "https://www.indeed.com/",
19 "Sec-Fetch-Dest": "document",
20 "Sec-Fetch-Mode": "navigate",
21 "Sec-Fetch-Site": "same-origin",
22}Zorg er ook voor dat je sec-ch-ua Client Hints overeenkomen met de UA-versie. Een sec-ch-ua: "Chrome";v="131" naast een User-Agent die Chrome 145 claimt, is een directe rode vlag.
Voeg willekeurige vertragingen tussen requests toe
Vaste intervallen worden door patroonherkenning opgepikt. Gebruik willekeurige jitter:
1import time, random
2# Tussen elke request
3time.sleep(random.uniform(3, 6))
4# Bij opnieuw proberen na een blokkade
5def backoff_sleep(attempt):
6 base = 4
7 sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
8 time.sleep(min(sleep_time, 60))De consensus uit en is 3–6 seconden tussen requests per IP, met een harde limiet van ongeveer 100 requests per IP per sessie voordat je roteert.
Gebruik proxyrotatie
Dit is veruit de grootste succesfactor. Datacenterproxies uit AWS/GCP bereiken op Cloudflare Enterprise-doelen slechts ongeveer 5–15% succes — in de praktijk onbruikbaar op Indeed. Residential proxies plus correcte TLS-fingerprinting brengen dat op 80–95% succes.
1PROXIES = [
2 "http://user:pass@us.residential.example:7777",
3 "http://user:pass@us.residential.example:7778",
4 "http://user:pass@us.residential.example:7779",
5]
6proxy = random.choice(PROXIES)
7response = cffi_requests.get(
8 url,
9 impersonate="chrome124",
10 headers=headers,
11 proxies={"https": proxy},
12 timeout=30,
13)De prijs van residential proxies in 2026 ligt ruwweg op , afhankelijk van aanbieder en contractniveau. Voor Indeed specifiek kun je het best beginnen met een kleine pool en die uitbouwen wanneer nodig.
Ga netjes om met 403-, 429- en 503-statuscodes
Herhaal niet blind. Verschillende statuscodes betekenen verschillende dingen:
1def fetch_with_retry(url, proxy_pool, max_retries=5):
2 for attempt in range(max_retries):
3 proxy = random.choice(proxy_pool)
4 headers["User-Agent"] = random.choice(USER_AGENTS)
5 try:
6 r = cffi_requests.get(
7 url,
8 impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
9 headers=headers,
10 proxies={"https": proxy},
11 timeout=30,
12 )
13 # Controleer op het sluwe "200 met challenge"-geval
14 if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
15 return r
16 if r.status_code == 403:
17 print(f"403 — geblokkeerd. Proxy roteren, poging {attempt + 1}")
18 elif r.status_code == 429:
19 print(f"429 — rate limited. Langzamer gaan.")
20 elif r.status_code == 503:
21 print(f"503 — server overbelast of JS-challenge.")
22 backoff_sleep(attempt)
23 except Exception as e:
24 print(f"Verzoekfout: \{e\}")
25 backoff_sleep(attempt)
26 raise RuntimeError(f"Mislukt na \{max_retries\} pogingen: \{url\}")Het 200-met-challenge-geval is het lastigst. Scan altijd de responsebody op cf-turnstile of Just a moment voordat je een 200 als succes behandelt.
Het eenvoudigere alternatief: laat Thunderbit de anti-botafhandeling doen
Voor gebruikers die geen proxy-pools, headerrotatie en TLS-fingerprint-imitatie willen bouwen en onderhouden, handelt cloudscraping CAPTCHA's, proxyrotatie en anti-botbescherming automatisch af. Geen proxy-instelling, geen curl_cffi-configuratie, geen CAPTCHA-oplossingsbibliotheken. Het is de weg van de minste weerstand wanneer je gewoon de data nodig hebt.
Waarom je Indeed-scraper steeds kapotgaat (en hoe je dat oplost)
De 403-muur is de acute pijn. De chronische pijn is onderhoud — scrapers die vandaag werken, vallen volgende week uit en geven stilletjes lege data of verouderde resultaten terug.
Hoe Indeed je selectors kapotmaakt
Indeed roteert CSS-klassen agressief. Bright Data's gids dat klassen als css-1m4cuuf en css-1rqpxry "willekeurig gegenereerd lijken — waarschijnlijk tijdens build-tijd." A/B-testen zorgen ervoor dat verschillende sessies andere paginalay-outs zien. En DOM-herstructurering gebeurt zonder waarschuwing.
De JobFunnel-saga is leerzaam. Een bijdrager meldde: "CaptchaBuster heeft de captcha succesvol gemitigeerd, en de reden dat de pagina nog steeds niet succesvol werd gescrapet [is] verouderde Beautiful Soup-selectors." De scraper werd dus niet geblokkeerd — hij parseerde gewoon de verkeerde elementen.
Strategie: geef voorkeur aan verborgen JSON boven DOM-parsing
De window.mosaic.providerData-blob is qua schema stabiel sinds minstens 2023. Het pad metaData.mosaicProviderJobCardsModel.results[] is in 2026 . DOM-selectors breken maandelijks. JSON-extractie breekt hooguit jaarlijks, als het al gebeurt.
Strategie: gebruik data-attributen in plaats van klassennamen
Als je toch de DOM moet aanraken, richt je dan op functionele attributen:
| Selector | Doel |
|---|---|
[data-testid="slider_item"] | Container van elke vacaturekaart |
[data-testid="job-title"] of h2.jobTitle > a | Link naar de functietitel |
[data-testid="company-name"] | Naam van de werkgever |
[data-testid="text-location"] | Locatietekst |
data-jk="<jobkey>" op elke kaart | De meest stabiele hook — onveranderd sinds 2019 |
Voeg assertion-checks toe om verouderde selectors te detecteren
Laat je scraper nooit stilletjes met nul resultaten draaien. Voeg na elke fetch een controle toe:
1results = parse_hidden_json(html)
2assert len(results) > 0, (
3 f"Indeed gaf een lege resultatenreeks terug bij start=\{start\} — "
4 "mogelijke blokkade, CAPTCHA of selector-drift. "
5 f"Eerste 500 tekens van de response: {html[:500]}"
6)Log bij fouten de eerste 500–2000 tekens van de ruwe response. Dan zie je meteen of je een Turnstile-challenge, een inlogmuur of een schemawijziging hebt gekregen. Draai dagelijks een eenvoudige CI-test tegen een vaste query (bijv. q=python&l=remote) die controleert op niet-nul resultaten.
Het AI-alternatief: scrapers die nooit kapotgaan
Thunderbit's AI leest elke keer opnieuw de structuur van de pagina — het is niet afhankelijk van hardcoded selectors of regex-patronen. Als Indeed zijn HTML wijzigt, past Thunderbit zich automatisch aan. Daarmee pakt het precies die onderhoudslast aan die forumgebruikers steeds als hun grootste frustratie noemen. Als je ooit wakker werd met een Slack-bericht dat "de scraper weer lege rijen teruggeeft", weet je hoe waardevol het is om dat niet te hoeven oplossen.
Indeed scrapen zonder Python te schrijven: het no-code alternatief
Elke concurrerende gids gaat ervan uit dat je Python-code gaat schrijven. Maar de forumdata vertelt een ander verhaal. Gebruikers zeggen dingen als "het is gewoon zo moeilijk met constante bugs en fouten" en sommigen stellen voor iemand op Fiverr in te huren om de data überhaupt binnen te krijgen. Klinkt dat herkenbaar, dan is dit jouw uitweg.
Hoe je Indeed met Thunderbit scrapt (stap voor stap)
Stap 1: Installeer de vanuit de Chrome Web Store. Je kunt gratis beginnen.
Stap 2: Ga in je browser naar een Indeed-zoekresultatenpagina — bijvoorbeeld https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX.
Stap 3: Klik op het Thunderbit-pictogram in je browserwerkbalk en klik daarna op "AI-velden voorstellen." Thunderbit's AI scant de pagina en detecteert automatisch kolommen als functietitel, bedrijf, locatie, salaris, vacature-URL en publicatiedatum. Je kunt de voorgestelde velden bekijken en aanpassen — kolommen verwijderen die je niet nodig hebt, of aangepaste kolommen toevoegen door in gewone taal te beschrijven wat je wilt.
Stap 4: Klik op "Scrapen." Thunderbit haalt de data van de pagina en toont die in een gestructureerde tabel. Je zou rijen met vacatures moeten zien, inclusief de velden die je hebt ingesteld.
Verrijking met subpagina-scraping
Na het scrapen van de lijstpagina klik je op "Subpagina's scrapen" zodat Thunderbit elke individuele vacaturedetailpagina bezoekt. Het haalt volledige vacaturebeschrijvingen, vereisten, voordelen en sollicitatielinks op — zonder extra configuratie. Dit is het equivalent van het schrijven van een tweede Python-scraper die elke /viewjob?jk=<jobkey>-URL bezoekt, maar dan met één klik.
Paginering automatisch afhandelen
Thunderbit handelt Indeed's paginering op basis van klikken automatisch af. Je hoeft geen offset-URL's handmatig samen te stellen of pagineringslussen te schrijven. Het klikt door de pagina's heen en voegt de resultaten samen.
Exporteren naar je favoriete tools
Exporteer gescrapete data naar CSV, Excel, Google Sheets, Airtable of Notion — . Je hoeft geen code te schrijven voor csv.writer() of pandas.to_csv().
Wanneer Python gebruiken en wanneer Thunderbit
| Scenario | Beste tool |
|---|---|
| Aangepaste datapijplijnen, geplande automatisering via cron/Airflow | Python |
| Integratie in een grotere codebase | Python |
| Sterk aangepaste parsingslogica | Python |
| Eenmalig onderzoek of marktanalyse | Thunderbit |
| Niet-technische teamleden hebben data nodig | Thunderbit |
| Nu data ophalen zonder 403-fouten te debuggen | Thunderbit |
| Verrijking van subpagina's zonder setup | Thunderbit |
Tijdvergelijking: Python-setup + anti-botdebugging = uren tot dagen (zeker de eerste keer). Thunderbit = minder dan 2 minuten voor dezelfde data. Ik zeg niet dat Python verkeerd is — ik zeg dat het afhangt van wat je nodig hebt.
Is Indeed scrapen legaal? Wat je moet weten
Geen van de best scorende gidsen over Indeed-scraping gaat in op legaliteit, wat opvallend is gezien hoe vaak "Is Indeed scrapen legaal?" opduikt in forums. Dit is geen juridisch advies, maar dit is het speelveld.
Indeed's servicevoorwaarden
Indeed's ToS () bevat geen algemene "niet scrapen"-clausule. De enige expliciete verbodsbepaling rond automatisering staat in Sectie A.3.5, waar "gebruik van automatisering, scripting of bots om het Indeed Apply-proces te automatiseren" wordt verboden. Dat is beperkt tot de Apply-flow, niet tot het passief lezen van publieke vacaturelijsten. Indeed's belangrijkste handhavingsmiddel is technisch — Cloudflare-challenges, IP-bans, device fingerprinting — niet de rechtszaal.
Relevant juridisch precedent
De vaakst aangehaalde Amerikaanse zaak is hiQ Labs v. LinkedIn. Het 9th Circuit dat het scrapen van publiek toegankelijke data "waarschijnlijk niet in strijd is met de CFAA" (Computer Fraud and Abuse Act). Later werd hiQ echter omdat medewerkers nep-LinkedIn-profielen hadden aangemaakt en de ToS hadden geaccepteerd.
Meer recent leverde Meta v. Bright Data (N.D. Cal., jan. 2024) een nog duidelijker uitspraak op. Rechter Chen dat de voorwaarden van Facebook en Instagram "het scrapen van publieke data wanneer men is uitgelogd niet verbieden." Meta trok de resterende claims de maand erna vrijwillig in.
Indeed's robots.txt
Indeed's verbiedt in algemene zin /jobs/ en /job/ voor de standaard User-agent: *, maar staat Googlebot en Bingbot expliciet toe om /viewjob? te benaderen — de individuele vacaturedetailpagina's. AI-trainingscrawlers (GPTBot, CCBot, anthropic-ai) worden sterk beperkt. robots.txt is in de VS niet juridisch bindend, maar het respecteren ervan is wel een best practice en een bewijs van goede trouw.
Praktische richtlijnen voor verantwoord scrapen
- Scrape alleen publiek beschikbare data — log nooit in, maak nooit nepaccounts aan
- Respecteer rate limits: 1 request per 3–6 seconden per IP, lage gelijktijdigheid
- Herpubliceer gescrapete data niet als je eigen vacaturebank
- Gebruik data voor persoonlijke of interne research, niet voor commerciële doorverkoop zonder toestemming
- Gooi onnodige PII weg of hash die; hanteer een bewaartermijn voor persoonsgegevens en daaraan gerelateerde data
- Als je op grote schaal werkt of in de EU/het VK actief bent, raadpleeg een jurist — GDPR's transparantieverplichtingen uit artikel 14 gelden voor gescrapete persoonsgegevens
Het risicospectrum: persoonlijke automatisering van je baanzoektocht zit aan de lage kant. Commerciële doorverkoop op grote schaal van Indeed-data zit aan de hoge kant.
Conclusie en belangrijkste lessen
Indeed scrapen met Python is zeker mogelijk, maar het is geen weekendproject dat je één keer opzet en daarna vergeet. Indeed's Cloudflare-bescherming, wisselende selectors en agressieve anti-botmaatregelen betekenen dat je dit met de juiste tools en verwachtingen moet aanpakken.
Dit is wat ik hieruit zou meenemen:
- Indeed is de rijkste bron van arbeidsmarktdata op het web — 350 miljoen maandelijkse bezoekers, 130 miljoen vacatures — maar het vecht hard terug tegen scrapers.
- Extractie via verborgen JSON (
window.mosaic.providerData) is de meest robuuste Python-aanpak. Het schema is al jaren stabiel, terwijl CSS-selectors maandelijks breken. curl_cffimet browser-impersonatie is in 2026 de standaard HTTP-client voor sites achter Cloudflare. Gewonerequestsenhttpxworden al op basis van de TLS-fingerprint geblokkeerd.- Gebruik altijd roterende headers, willekeurige vertragingen en residential proxies om 403-fouten te vermijden. Datacenterproxies zijn bijna waardeloos tegen Cloudflare Enterprise.
- Voeg assertion-checks toe zodat je meteen weet wanneer selectors breken of wanneer je in plaats van vacaturedata een challenge-pagina krijgt.
- Voor niet-technische gebruikers of iedereen die snel resultaat wil, biedt een no-code, AI-gedreven route die automatisch meebeweegt met sitewijzigingen — geen proxies, geen debugging, geen onderhoud.
Wil je de no-code-route proberen, dan zodat je het zonder verplichtingen op Indeed kunt testen. En kies je voor Python, dan zijn de codevoorbeelden hierboven een solide startpunt — onthoud alleen dat anti-botweerbaarheid een eerste prioriteit moet zijn, niet iets voor later.
Voor meer informatie over webscraping-aanpakken en -tools, bekijk onze gidsen over , , en . Je kunt ook tutorials bekijken op het .
FAQ's
Welke Python-bibliotheken zijn het beste voor het scrapen van Indeed?
Voor HTTP-verzoeken is curl_cffi in 2026 de sterkste keuze — het imiteert echte browser-TLS-fingerprints, wat essentieel is om Cloudflare te omzeilen. httpx met HTTP/2 is een degelijke fallback voor minder goed beveiligde doelen. Voor HTML-parsing blijft BeautifulSoup4 met lxml de standaard. Voor browserautomatisering werken Playwright (met playwright-stealth) of undetected-chromedriver, al worden beide steeds beter detecteerbaar. De verborgen JSON-regexaanpak (window.mosaic.providerData) maakt zware parsing helemaal overbodig.
Waarom krijg ik steeds 403-fouten bij het scrapen van Indeed?
Indeed gebruikt Cloudflare Bot Management, dat je TLS-fingerprint (JA3/JA4), HTTP/2-header-volgorde, requestpatronen en browsergedrag inspecteert. Als je gewone requests gebruikt, verraadt je TLS-fingerprint je direct als Python-script — de 403 komt al voordat je headers überhaupt worden gelezen. Los dit op door over te stappen op curl_cffi met browser-impersonatie, realistische roterende User-Agent-strings, willekeurige vertragingen (3–6 seconden) en residential proxies. Controleer ook op het geval "200 met Turnstile-challenge" — scan response bodies op cf-turnstile-markeringen.
Kan ik Indeed scrapen zonder te coderen?
Ja. Tools zoals laten je Indeed-vacatures in een paar klikken extraheren — installeer de Chrome-extensie, ga naar een Indeed-zoekpagina, klik op "AI-velden voorstellen" en daarna op "Scrapen." Thunderbit's AI detecteert automatisch velden als functietitel, bedrijf, locatie en salaris. Het handelt paginering, verrijking van subpagina's (volledige vacaturebeschrijvingen) en anti-botbescherming automatisch af. Exporteer gratis naar CSV, Google Sheets, Airtable of Notion.
Hoe vaak verandert Indeed zijn HTML-structuur?
Indeed roteert regelmatig CSS-klassen (bijv. css-1m4cuuf, willekeurig gehashte strings) en herstructureert DOM-elementen zonder waarschuwing. A/B-testen zorgen ervoor dat verschillende gebruikers tegelijk andere lay-outs kunnen zien. De verborgen JSON-aanpak (window.mosaic.providerData) is aanzienlijk stabieler — het schema is sinds minstens 2023 consistent. Wanneer je toch DOM-selectors moet gebruiken, richt je op data-testid-attributen en data-jk (vacaturekey) in plaats van CSS-klassen.
Is het legaal om Indeed te scrapen?
Scraping terwijl je bent uitgelogd en publiek toegankelijke Indeed-vacature-URL's bekijkt, leidt in de VS waarschijnlijk niet tot CFAA-aansprakelijkheid, op basis van het 9th Circuit-oordeel in hiQ v. LinkedIn (2022) en de Meta v. Bright Data-uitspraak (2024). Indeed's voorwaarden verbieden specifiek het automatiseren van het Apply-proces, niet het passief lezen van openbare lijsten. Toch geldt: scrape altijd verantwoord. Log niet in, maak geen nepaccounts aan, respecteer rate limits, herpubliceer data niet als je eigen vacaturebank en ga zorgvuldig om met persoonsgegevens (zoals recruitersnamen en e-mails) onder GDPR/CCPA. Voor commerciële activiteiten op schaal: raadpleeg een jurist.
Meer leren