

Google Shopping verwerkt elke maand meer dan 1,2 miljard productzoekopdrachten. Dat is een enorme berg prijsdata, producttrends en verkopersinformatie — allemaal meteen beschikbaar in je browser, verzameld uit duizenden webshops.
Die data uit Google Shopping halen en in een spreadsheet krijgen? Dáár begint het gedoe. Ik heb flink wat tijd gestoken in het testen van verschillende aanpakken — van no-code browserextensies tot complete Python-scripts — en de uitkomst liep uiteen van “wauw, dat was simpel” tot “ik ben al drie dagen CAPTCHAs aan het debuggen en ik wil ermee kappen”. De meeste handleidingen gaan ervan uit dat je een Python-ontwikkelaar bent, maar in mijn ervaring werkt een groot deel van de mensen die Google Shopping-data nodig hebben juist in ecommerce, pricing of marketing en willen ze gewoon de cijfers hebben zonder code te schrijven. Daarom behandelt deze gids drie methodes, van het makkelijkst tot het meest technisch, zodat je de aanpak kunt kiezen die past bij jouw niveau en beschikbare tijd.
Wat is Google Shopping-data?
Google Shopping is een productzoekmachine. Typ “wireless noise-cancelling headphones” in en Google haalt vermeldingen op uit tientallen webshops — producttitels, prijzen, verkopers, beoordelingen, afbeeldingen, links. Een live catalogus die continu wordt bijgewerkt met wat er online te koop is.
Waarom Google Shopping-data scrapen?
Eén productpagina vertelt je bijna niks. Honderden van die pagina’s, netjes gestructureerd in een spreadsheet — daar worden patronen zichtbaar.
Dit zijn de meest voorkomende toepassingen die ik ben tegengekomen:
| Use Case | Wie profiteert | Waar je naar zoekt |
|---|---|---|
| Concurrentieanalyse voor prijzen | Ecommerce-teams, prijsanalisten | Concurrentprijzen, kortingspatronen, prijswijzigingen door de tijd |
| Ontdekking van producttrends | Marketingteams, productmanagers | Nieuwe producten, snelgroeiende categorieën, reviewtempo |
| Advertentie-intelligentie | PPC-managers, growth teams | Gesponsorde vermeldingen, welke verkopers bieden, advertentiefrequentie |
| Verkoper-/leadonderzoek | Sales-teams, B2B | Actieve merchants, nieuwe verkopers in een categorie |
| MAP-monitoring | Brand managers | Retailers die minimum advertised price-beleid overtreden |
| Voorraad- en assortimentsmonitoring | Category managers | Voorraadbeschikbaarheid, hiaten in assortiment |
78% van de Amerikaanse retailers gebruikt inmiddels AI-gestuurde prijstools. Bedrijven die investeren in concurrentie-informatie over prijzen rapporteren rendementen tot wel 29x. Amazon past prijzen ongeveer elke 10 minuten aan. Als je nog steeds handmatig concurrentprijzen controleert, is de rekensom niet in jouw voordeel.
Google Shopping-data scrapen met AI Get Started Free
Thunderbit is een AI Web Scraper Chrome-extensie waarmee zakelijke gebruikers data van websites kunnen scrapen met behulp van AI. Het is vooral handig voor ecommerce-teams, prijsanalisten en marketeers die gestructureerde Google Shopping-data willen zonder code te schrijven.
Welke data kun je eigenlijk uit Google Shopping scrapen?
Voordat je een tool kiest of ook maar één regel code schrijft, is het handig om precies te weten welke velden beschikbaar zijn — en welke net wat meer moeite kosten om te bereiken.
Velden uit Google Shopping zoekresultaten
Wanneer je een zoekopdracht uitvoert in Google Shopping, bevat elke productkaart op de resultatenpagina:
| Field | Type | Example | Notes |
|---|---|---|---|
| Producttitel | Tekst | "Sony WH-1000XM5 Wireless Headphones" | Altijd aanwezig |
| Prijs | Getal | $278,00 | Kan een kortingsprijs + originele prijs tonen |
| Verkoper/Winkel | Tekst | "Best Buy" | Meerdere verkopers per product mogelijk |
| Beoordeling | Getal | 4,7 | Van 5 sterren; niet altijd zichtbaar |
| Aantal reviews | Getal | 12.453 | Soms afwezig bij nieuwere producten |
| Productafbeelding-URL | URL | https://... | Kan bij eerste laden een base64-placeholder retourneren |
| Productlink | URL | https://... | Linkt naar de productpagina van Google of direct naar de winkel |
| Verzendinformatie | Tekst | "Gratis verzending" | Niet altijd aanwezig |
| Gesponsorde tag | Boolean | Ja/Nee | Geeft betaalde plaatsing aan — handig voor advertentie-informatie |
Velden uit productdetailpagina’s (subpagedata)
Als je doorklikt naar de detailpagina van een individueel product in Google Shopping, kun je rijkere data ophalen:
| Field | Type | Notes |
|---|---|---|
| Volledige beschrijving | Tekst | Vereist dat je de productpagina bezoekt |
| Alle verkopersprijzen | Getal (meerdere) | Prijsvergelijking naast elkaar tussen retailers |
| Specificaties | Tekst | Verschilt per productcategorie (afmetingen, gewicht, enz.) |
| Individuele reviewtekst | Tekst | Volledige reviewinhoud van kopers |
| Voor- en nadelen-samenvatting | Tekst | Google genereert dit soms automatisch |
Om deze velden op te halen, moet je na het scrapen van de zoekresultaten elke subpagina van een product bezoeken. Tools met subpage scraping kunnen dit automatisch afhandelen — hieronder laat ik de workflow zien.
Drie manieren om Google Shopping-data te scrapen (kies jouw route)

Drie methodes, van eenvoudig tot technisch. Kies de rij die bij jouw situatie past en spring er direct in:
| Method | Niveau | Insteltijd | Anti-bot afhandeling | Beste voor |
|---|---|---|---|---|
| No-code (Thunderbit Chrome-extensie) | Beginner | ~2 minuten | Automatisch afgehandeld | Ecommerce-operations, marketeers, eenmalig onderzoek |
| Python + SERP API | Gemiddeld | ~30 minuten | Afgehandeld door de API | Ontwikkelaars die programmeerbare, herhaalbare toegang nodig hebben |
| Python + Playwright (browserautomatisering) | Gevorderd | ~1 uur+ | Jij regelt het zelf | Aangepaste pipelines, randgevallen afhandelen |
Methode 1: Google Shopping-data scrapen zonder code (met Thunderbit)
- Moeilijkheidsgraad: Beginner
- Benodigde tijd: ~2–5 minuten
- Wat je nodig hebt: Chrome-browser, Thunderbit Chrome-extensie (de gratis versie werkt), een Google Shopping-zoekopdracht
De snelste weg van “ik heb Google Shopping-data nodig” naar “hier is mijn spreadsheet”. Geen code, geen API-sleutels, geen proxyconfiguratie. Ik heb deze workflow tientallen keren aan niet-technische collega’s uitgelegd — niemand bleef vastlopen.
Stap 1: Installeer Thunderbit en open Google Shopping
Installeer de Thunderbit AI Web Scraper vanuit de Chrome Web Store en maak een gratis account aan.
Ga daarna naar Google Shopping. Je kunt direct naar shopping.google.com gaan of het Shopping-tabblad gebruiken in een gewone Google-zoekopdracht. Zoek naar het product of de categorie die je interessant vindt — bijvoorbeeld “wireless noise-cancelling headphones”.
Je zou nu een raster met productvermeldingen moeten zien, inclusief prijzen, verkopers en beoordelingen.
Stap 2: Klik op “AI Suggest Fields” om kolommen automatisch te detecteren
Klik op het Thunderbit-extensie-icoon om de zijbalk te openen en kies “AI Suggest Fields.” De AI scant de Google Shopping-pagina en stelt kolommen voor: Producttitel, Prijs, Verkoper, Beoordeling, Aantal reviews, Afbeelding-URL, Productlink.
Controleer de voorgestelde velden. Je kunt kolommen hernoemen, velden verwijderen die je niet nodig hebt of eigen velden toevoegen. Als je iets specifieks wilt — bijvoorbeeld “haal alleen de numerieke prijs op, zonder valutasymbool” — kun je aan die kolom een Field AI Prompt toevoegen.
Je zou een voorbeeld van de kolomstructuur moeten zien in het Thunderbit-paneel.
Stap 3: Klik op “Scrape” en bekijk de resultaten
Klik op de blauwe “Scrape”-knop. Thunderbit haalt alle zichtbare productvermeldingen op en zet ze in een gestructureerde tabel.
Meerdere pagina’s? Thunderbit handelt paginering automatisch af — door pagina’s door te klikken of te scrollen om meer resultaten te laden, afhankelijk van de lay-out. Heb je veel resultaten, dan kun je kiezen tussen Cloud Scraping (sneller, tot 50 pagina’s tegelijk, draait op Thunderbit’s gedistribueerde infrastructuur) of Browser Scraping (gebruikt je eigen Chrome-sessie — handig als Google regio-afhankelijke resultaten toont of een login vereist).
In mijn tests duurde het scrapen van 50 productvermeldingen ongeveer 30 seconden. Dezelfde taak handmatig — elke vermelding openen, titel, prijs, verkoper en beoordeling kopiëren — had me meer dan 20 minuten gekost.
Stap 4: Verrijk de data met subpage scraping
Na de eerste scrape klik je in het Thunderbit-paneel op “Scrape Subpages.” De AI bezoekt de detailpagina van elk product en voegt extra velden toe — volledige beschrijvingen, alle verkopersprijzen, specificaties en reviews — aan de oorspronkelijke tabel.
Geen extra configuratie nodig — de AI herkent de structuur van elke detailpagina en haalt de relevante data op. Ik heb op deze manier in minder dan 5 minuten een volledige matrix voor concurrentieprijzen gebouwd (product + alle verkopersprijzen + specificaties) voor 40 producten.
Probeer Thunderbit voor Google Shopping-scraping
Stap 5: Exporteer naar Google Sheets, Excel, Airtable of Notion
Klik op “Export” en kies je bestemming — Google Sheets, Excel, Airtable of Notion. Alles gratis. CSV- en JSON-downloads zijn ook beschikbaar.
Twee klikken om te scrapen, één klik om te exporteren. Het bijbehorende Python-script? Ongeveer 60 regels code, proxyconfiguratie, CAPTCHA-afhandeling en doorlopend onderhoud.
Methode 2: Google Shopping-data scrapen met Python + een SERP API
- Moeilijkheidsgraad: Gemiddeld
- Benodigde tijd: ~30 minuten
- Wat je nodig hebt: Python 3.10+, de libraries
requestsenpandas, een SERP API-sleutel (ScraperAPI, SerpApi of iets vergelijkbaars)
Als je programmatische, herhaalbare toegang tot Google Shopping-data nodig hebt, is een SERP API de meest betrouwbare Python-aanpak. Anti-botmaatregelen, JavaScript-rendering, proxyrotatie — allemaal op de achtergrond geregeld. Jij stuurt een HTTP-verzoek, en krijgt gestructureerde JSON terug.
Stap 1: Stel je Python-omgeving in
Installeer Python 3.12 (in 2025–2026 de veiligste standaard voor productie) en de benodigde packages:
pip install requests pandas
Meld je aan bij een SERP API-provider. SerpApi biedt 100 gratis zoekopdrachten per maand; ScraperAPI geeft 5.000 gratis credits. Haal je API-sleutel op uit het dashboard.
Stap 2: Configureer je API-verzoek
Hier is een minimaal voorbeeld met het Google Shopping-endpoint van ScraperAPI:
import requests
import pandas as pd
API_KEY = "YOUR_API_KEY"
query = "wireless noise cancelling headphones"
resp = requests.get(
"https://api.scraperapi.com/structured/google/shopping",
params={"api_key": API_KEY, "query": query, "country_code": "us"}
)
data = resp.json()
De API geeft gestructureerde JSON terug met velden zoals title, price, link, thumbnail, source (verkoper) en rating.
Stap 3: Parse de JSON-respons en haal de velden eruit
products = data.get("shopping_results", [])
rows = []
for p in products:
rows.append({
"title": p.get("title"),
"price": p.get("price"),
"seller": p.get("source"),
"rating": p.get("rating"),
"reviews": p.get("reviews"),
"link": p.get("link"),
"thumbnail": p.get("thumbnail"),
})
df = pd.DataFrame(rows)
Stap 4: Exporteer naar CSV of JSON
df.to_csv("google_shopping_results.csv", index=False)
Geschikt voor batchverwerking: loop door 50 zoekwoorden en bouw in één script-run een complete dataset op. De keerzijde is de prijs — SERP API’s rekenen per query, en bij duizenden queries per dag loopt de rekening snel op. Hieronder lees je meer over de kosten.
Methode 3: Google Shopping-data scrapen met Python + Playwright (browserautomatisering)
- Moeilijkheidsgraad: Gevorderd
- Benodigde tijd: ~1 uur+ (plus doorlopend onderhoud)
- Wat je nodig hebt: Python 3.10+, Playwright, residential proxies, geduld
De aanpak met “volledige controle”. Je start een echte browser, gaat naar Google Shopping en haalt data op uit de gerenderde pagina. Het meest flexibel, maar ook het kwetsbaarst — Google’s anti-botsystemen zijn agressief en de paginastructuur verandert meerdere keren per jaar.
Waarschuwing: ik heb gebruikers gesproken die weken hebben gevochten met CAPTCHAs en IP-blokkades met deze aanpak. Het werkt, maar reken op doorlopend onderhoud.
Stap 1: Stel Playwright en proxies in
pip install playwright
playwright install chromium
Je hebt residential proxies nodig. Datacenter-IP’s worden bijna direct geblokkeerd — een forumgebruiker zei het heel duidelijk: “Alle AWS-IP’s worden geblokkeerd of krijgen CAPTCHA na 1/2 resultaten.” Diensten zoals Bright Data, Oxylabs of Decodo bieden residential proxy-pools vanaf ongeveer $1–5/GB.
Configureer Playwright met een realistische user-agent en je proxy:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={"server": "http://your-proxy:port", "username": "user", "password": "pass"}
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ..."
)
page = context.new_page()
Stap 2: Navigeer naar Google Shopping en ga om met anti-botmaatregelen
Bouw de Google Shopping-URL en ga ernaartoe:
query = "wireless noise cancelling headphones"
url = f"https://www.google.com/search?udm=28&q={query}&gl=us&hl=en"
page.goto(url, wait_until="networkidle")
Accepteer de EU-cookie-popup als die verschijnt:
try:
page.click("button#L2AGLb", timeout=3000)
except:
pass
Voeg menselijke vertragingen toe tussen acties — 2 tot 5 seconden willekeurige wachttijd tussen pagina’s. Google detecteert snelle, uniforme aanvraagpatronen.
Stap 3: Scroll, paginate en haal productdata op
Google Shopping laadt resultaten dynamisch. Scroll om lazy loading te activeren en haal vervolgens productkaarten op:
import time, random
# Scroll om alle resultaten te laden
for _ in range(3):
page.evaluate("window.scrollBy(0, 1000)")
time.sleep(random.uniform(1.5, 3.0))
# Productkaarten ophalen
cards = page.query_selector_all("[jsname='ZvZkAe']")
results = []
for card in cards:
title = card.query_selector("h3")
price = card.query_selector("span.a8Pemb")
# ... andere velden ophalen
results.append({
"title": title.inner_text() if title else None,
"price": price.inner_text() if price else None,
})
Een belangrijke opmerking: de CSS-selectors hierboven zijn bij benadering en zullen veranderen. Google wisselt class names regelmatig. Alleen al tussen 2024 en 2026 zijn drie verschillende sets selectors gedocumenteerd. Vertrouw liever op stabielere attributen zoals jsname, data-cid, <h3>-tags en img[alt] dan op class names.
Stap 4: Sla op als CSV of JSON
import json
from datetime import datetime
filename = f"shopping_{datetime.now().strftime('%Y%m%d_%H%M')}.json"
with open(filename, "w") as f:
json.dump(results, f, indent=2)
Reken erop dat je dit script regelmatig moet onderhouden. Wanneer Google de paginastructuur wijzigt — en dat gebeurt meerdere keren per jaar — breken je selectors en ben je weer aan het debuggen.
De grootste frustratie: CAPTCHAs en anti-botblokkades
Forum na forum, steeds hetzelfde verhaal: “Ik heb er een paar weken aan gewerkt maar gaf op door Google’s anti-botmaatregelen.” CAPTCHAs en IP-blokkades zijn de belangrijkste reden dat mensen afhaken bij zelfgemaakte Google Shopping scrapers.
Hoe Google scrapers blokkeert (en wat je eraan kunt doen)
| Anti-Bot Challenge | Wat Google doet | Workaround |
|---|---|---|
| IP-fingerprinting | Blokkeert datacenter-IP’s na een paar verzoeken | Residential proxies of browsergebaseerd scrapen |
| CAPTCHAs | Geactiveerd door snelle of geautomatiseerde aanvraagpatronen | Rate limiting (10–20 sec tussen verzoeken), menselijke vertragingen, CAPTCHA-oplossingsdiensten |
| JavaScript-rendering | Shopping-resultaten worden dynamisch via JS geladen | Headless browser (Playwright) of API die JS rendert |
| User-agent-detectie | Blokkeert veelvoorkomende bot-user-agents | Roteer realistische, actuele user-agent strings |
| TLS-fingerprinting | Detecteert niet-browser TLS-signaturen | Gebruik curl_cffi met browser-imitatie of een echte browser |
| AWS/cloud IP-blokkering | Blokkeert bekende IP-ranges van cloudproviders | Vermijd datacenter-IP’s volledig |
In januari 2025 maakte Google JavaScript-uitvoering verplicht voor SERP- en Shopping-resultaten, waardoor veel statische HTML-scrapers stukliepen — inclusief pipelines die werden gebruikt door SemRush en SimilarWeb. Vervolgens verouderde Google in september 2025 de oude productdetail-URL’s en leidde ze door naar een nieuwe “Immersive Product”-weergave die via async AJAX laadt. Elke handleiding die vóór eind 2025 is geschreven, is inmiddels grotendeels achterhaald.
Hoe elke methode met deze uitdagingen omgaat
SERP API’s regelen alles op de achtergrond — proxies, rendering, CAPTCHA-oplossing. Jij hoeft er niet over na te denken.
Thunderbit Cloud Scraping gebruikt gedistribueerde cloudinfrastructuur in de VS, EU en Azië om JS-rendering en anti-botmaatregelen automatisch af te handelen. De Browser Scraping-modus gebruikt je eigen geauthenticeerde Chrome-sessie, waardoor detectie in feite wordt omzeild omdat het eruitziet als normaal browsen.
Zelfbouw met Playwright legt de volledige last bij jou — proxybeheer, afstemsnelheden, CAPTCHA-oplossing, selectoronderhoud en voortdurende controle op breuken.
Wat kost het echt om Google Shopping-data te scrapen? Een eerlijke vergelijking
“$50 voor ongeveer 20k verzoeken… best prijzig voor mijn hobbyproject.” Die klacht zie je constant in forums. Maar meestal blijft de grootste kostenpost buiten beeld.
Kostentabel
| Approach | Initiële kosten | Kosten per query (schatting) | Onderhoudslast | Verborgen kosten |
|---|---|---|---|---|
| DIY Python (zonder proxy) | Gratis | $0 | HOOG (breuken, CAPTCHAs) | Je eigen tijd voor debugging |
| DIY Python + residential proxies | Gratis code | ~$1–5/GB | GEMIDDELD-HOOG | Kosten van de proxyprovider |
| SERP API (SerpApi, ScraperAPI) | Beperkte gratis laag | ~$0,50–5,00/1K queries | LAAG | Snel duur bij volume |
| Thunderbit Chrome-extensie | Gratis laag (6 pagina’s) | Credit-based, ~1 credit/rij | ZEER LAAG | Betaald plan bij grotere volumes |
| Thunderbit Open API (Extract) | Credit-based | ~20 credits/pagina | LAAG | Betalen per extractie |
De verborgen kosten die iedereen negeert: je tijd
Een DIY-oplossing van $0 die 40 uur debugging kost, is niet gratis. Bij $50 per uur is dat $2.000 aan arbeid — voor een scraper die volgende maand alweer kan stuklopen wanneer Google de DOM wijzigt.

McKinsey’s Technology Outlook stelt dat de break-even tussen zelf bouwen en kopen pas komt boven 3,6 miljoen dagelijkse verzoeken. Onder die drempel “kost intern bouwen budget zonder ROI op te leveren.” Voor de meeste ecommerce-teams die een paar honderd tot een paar duizend zoekopdrachten per week doen, is een no-code tool of SERP API duidelijk kostenefficiënter dan zelf iets bouwen.
Hoe stel je geautomatiseerde Google Shopping-prijsmonitoring in?
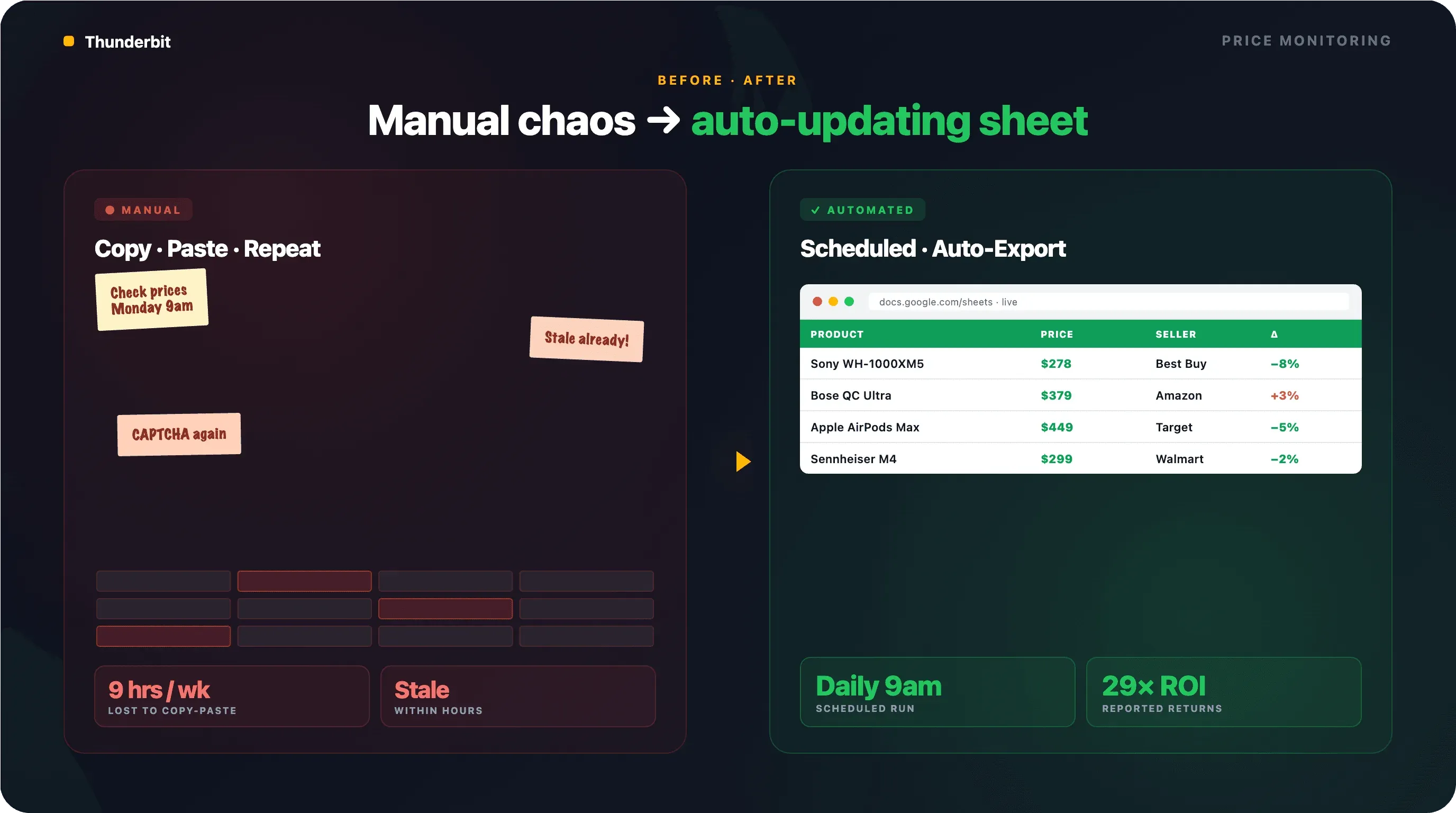
De meeste gidsen behandelen scrapen als een eenmalige taak. De echte use case voor ecommerce-teams is doorlopende, geautomatiseerde monitoring. Je hebt niet alleen de prijzen van vandaag nodig — je wilt die van gisteren, vorige week en morgen.
Geplande scraping instellen met Thunderbit
Met Thunderbit’s Scheduled Scraper kun je het tijdsinterval in gewone taal beschrijven — “elke dag om 9 uur” of “elke maandag en donderdag om 12 uur” — en de AI zet dat om in een terugkerend schema. Voer je Google Shopping-URL’s in, klik op “Schedule”, en je bent klaar.
Elke run exporteert automatisch naar Google Sheets, Airtable of Notion. Het resultaat: een spreadsheet die dagelijks vanzelf wordt gevuld met concurrentprijzen, klaar voor draaitabellen of alerts.
Geen cronjobs. Geen serverbeheer. Geen gedoe met Lambda-functies. (Ik heb forumposts gezien van ontwikkelaars die dagen bezig waren om Selenium in AWS Lambda werkend te krijgen — Thunderbit’s planner slaat dat allemaal over.)
Voor meer over het opzetten van price monitoring workflows, hebben we daar een aparte deep dive over.
Plannen met Python (voor ontwikkelaars)
Als je de SERP API-aanpak gebruikt, kun je runs plannen met cronjobs (Linux/Mac), Windows Task Scheduler of cloud-schedulers zoals AWS Lambda of Google Cloud Functions. Python-bibliotheken zoals APScheduler werken ook.
De afweging: jij bent nu verantwoordelijk voor het bewaken van de scriptgezondheid, foutafhandeling, het op schema roteren van proxies en het bijwerken van selectors wanneer Google de pagina verandert. Voor de meeste teams is de engineeringtijd die nodig is om een geplande Python-scraper te onderhouden hoger dan de kosten van een dedicated tool.
Tips en best practices voor het scrapen van Google Shopping-data
Welke methode je ook kiest, een paar dingen besparen je veel gedoe.
Respecteer rate limits
Bestook Google niet met honderden snelle verzoeken — dan word je geblokkeerd en kan je IP nog een tijd gemarkeerd blijven. DIY-methodes: spreid verzoeken met 10–20 seconden ertussen en voeg willekeurige variatie toe. Tools en API’s regelen dit voor je.
Stem je methode af op je volume
Een korte beslisgids:
- < 10 queries per week → Thunderbit gratis laag of SerpApi gratis laag
- 10–1.000 queries per week → betaald SERP API-plan of Thunderbit betaald plan
- 1.000+ queries per week → SERP API enterprise-plan of Thunderbit Open API
Maak je data schoon en valideer die
Prijzen bevatten valutasymbolen, landspecifieke notaties (1.299,00 € versus $1,299.00) en af en toe rommeltekens. Gebruik Thunderbit’s Field AI Prompts om tijdens het extraheren te normaliseren, of maak het daarna schoon met pandas:
df["price_num"] = df["price"].str.replace(r"[^\d.]", "", regex=True).astype(float)
Controleer op dubbele vermeldingen tussen organische en gesponsorde resultaten — die overlappen vaak. Dedupliceer op de combinatie van (titel, prijs, verkoper).
Ken het juridische speelveld
Het scrapen van publiek beschikbare productdata is in het algemeen legaal, maar het juridische landschap ontwikkelt zich snel. De belangrijkste recente ontwikkeling: Google klaagde SerpApi in december 2025 aan onder DMCA § 1201 wegens het omzeilen van Google’s “SearchGuard”-anti-scrapingsysteem. Dit is een nieuwe handhavingsroute die om eerdere verdedigingslijnen heen gaat, zoals hiQ v. LinkedIn en Van Buren v. United States.
Praktische richtlijnen:
- Scrape alleen publiek beschikbare data — log niet in om afgeschermde content te openen
- Extraheer geen persoonlijke informatie (namen van reviewers, accountgegevens)
- Houd rekening met het feit dat Google’s Servicevoorwaarden geautomatiseerde toegang verbieden — het gebruik van een SERP API of browserextensie verkleint de juridische grijze zone, maar neemt die niet volledig weg
- Houd voor EU-activiteiten rekening met de AVG, al gaat het bij productvermeldingen meestal om niet-persoonlijke commerciële data
- Overweeg juridisch advies als je een commercieel product bouwt op basis van gescrapete data
Voor een diepere blik op juridische overwegingen rond webscraping, hebben we dat onderwerp apart behandeld.
Welke methode moet je gebruiken om Google Shopping-data te scrapen?
Na alle drie de methodes op dezelfde productcategorieën te hebben getest, kwam ik hierop uit:
Als je geen technische gebruiker bent en snel data nodig hebt — gebruik Thunderbit. Open Google Shopping, klik twee keer, exporteer. Binnen 5 minuten heb je een nette spreadsheet. De gratis laag laat je het zonder verplichting proberen, en de subpage scraping-functie levert rijkere data op dan de meeste Python-scripts.
Als je een ontwikkelaar bent en herhaalbare, programmeerbare toegang nodig hebt — gebruik een SERP API. De betrouwbaarheid is de kosten per query waard, en je vermijdt alle anti-botproblemen. SerpApi heeft de beste documentatie; ScraperAPI heeft de ruimste gratis laag.
Als je maximale controle nodig hebt en een aangepaste pipeline bouwt — Playwright werkt, maar ga er met open ogen in. Reserveer flink wat tijd voor proxybeheer, selectoronderhoud en CAPTCHA-afhandeling. In 2025–2026 is de minimale werkbare omzeil-stack curl_cffi met Chrome-imitatie + residential proxies + een tempo van 10–20 seconden. Een simpel requests-script met roterende user-agents is verleden tijd.
De beste methode is degene die je nauwkeurige data geeft zonder je hele week op te slokken. Voor de meeste mensen is dat geen Python-script van 60 regels — maar twee klikken.
Bekijk Thunderbit’s pricing als je volume nodig hebt, of bekijk onze tutorials op het Thunderbit YouTube-kanaal om de workflow in actie te zien.
Probeer Thunderbit voor Google Shopping-scraping Get Started Free
Veelgestelde vragen
Is het legaal om Google Shopping-data te scrapen?
Het scrapen van publiek beschikbare productdata is over het algemeen legaal onder precedenten zoals hiQ v. LinkedIn en Van Buren v. United States. Wel verbieden Google’s Servicevoorwaarden geautomatiseerde toegang, en Google’s rechtszaak tegen SerpApi in december 2025 introduceerde een nieuwe DMCA § 1201-theorie over anti-omzeiling. Het gebruik van gerenommeerde tools en API’s verlaagt het risico. Voor commerciële toepassingen is juridisch advies verstandig.
Kan ik Google Shopping scrapen zonder geblokkeerd te worden?
Ja, maar de methode maakt veel uit. SERP API’s handelen anti-botmaatregelen automatisch af. Thunderbit’s Cloud Scraping gebruikt gedistribueerde infrastructuur om blokkades te vermijden, terwijl de Browser Scraping-modus je eigen Chrome-sessie gebruikt (wat eruitziet als normaal browsen). DIY Python-scripts vereisen residential proxies, menselijke vertragingen en TLS-fingerprintbeheer — en zelfs dan komen blokkades vaak voor.
Wat is de makkelijkste manier om Google Shopping-data te scrapen?
Thunderbit’s Chrome-extensie. Navigeer naar Google Shopping, klik op “AI Suggest Fields”, klik op “Scrape” en exporteer naar Google Sheets of Excel. Geen code, geen API-sleutels, geen proxyconfiguratie. Het hele proces duurt ongeveer 2 minuten.
Hoe vaak kan ik Google Shopping scrapen voor prijsmonitoring?
Met Thunderbit’s Scheduled Scraper kun je dagelijkse, wekelijkse of aangepaste monitoring instellen in gewone taal. Bij SERP API’s hangt de frequentie af van je creditlimiet — de meeste providers bieden genoeg voor dagelijkse monitoring van enkele honderden SKU’s. DIY-scripts kunnen zo vaak draaien als je infrastructuur aankan, maar hogere frequentie betekent meer anti-botgedoe.
Kan ik Google Shopping-data exporteren naar Google Sheets of Excel?
Ja. Thunderbit exporteert gratis rechtstreeks naar Google Sheets, Excel, Airtable en Notion. Python-scripts kunnen exporteren naar CSV of JSON, die je daarna in elk spreadsheetprogramma kunt importeren. Voor doorlopende monitoring zorgen Thunderbit’s geplande exports naar Google Sheets voor een live, automatisch bijgewerkt dataset.
- Meer lezen




