Data is goud waard en overleeft de systemen waarin het wordt opgeslagen.
- , computerwetenschapper en uitvinder van het World Wide Web
Elke dag verwerkt Google zoekopdrachten. Dat zijn niet alleen antwoorden op simpele vragen, maar ook een enorme bron van inzichten: markttrends, concurrentie-informatie en waardevolle consumentendata. Of je nu in de sales zit, specialist bent of marketeer, je kunt deze data omzetten in slimme strategieën voor je bedrijf.
Ben je nog steeds bezig met ouderwets knippen en plakken om data te verzamelen? Tijd om dat achter je te laten.
In deze blog leggen we uit wat een Google SERP precies is, welke waardevolle data je eruit kunt halen, en laten we je drie manieren zien om een Google SERP te scrapen – waaronder de meest toegankelijke: de no-code AI-webscraper .
Wat is een Google Zoekresultatenpagina (SERP)?
Een (search engine results page) is de pagina die je te zien krijgt nadat je een zoekopdracht hebt ingevoerd in zoekmachines zoals , of . Het is de poort naar al het verkeer en het eerste wat je ziet voordat je ergens op klikt.
Een belangrijk kenmerk van de SERP is dat deze constant verandert: algoritme-updates, nieuwe SERP-functies, trends in zoekwoorden en aanpassingen op websites hebben allemaal invloed op de resultaten. Daarnaast worden zoekresultaten gepersonaliseerd op basis van je zoekgeschiedenis en locatie, waardoor verschillende mensen op hetzelfde moment andere SERP’s kunnen zien. Dit maakt het voor niet-technische gebruikers lastig om efficiënt data te verzamelen uit deze ongestructureerde webpagina’s.
Omdat Google meer dan van het wereldwijde marktaandeel in zoekmachines heeft, is het snappen van de opbouw van Google SERP’s en het benutten ervan onmisbaar voor zakelijk succes.
Welke Data Staat er op een Google SERP?
Opbouw van de Google SERP
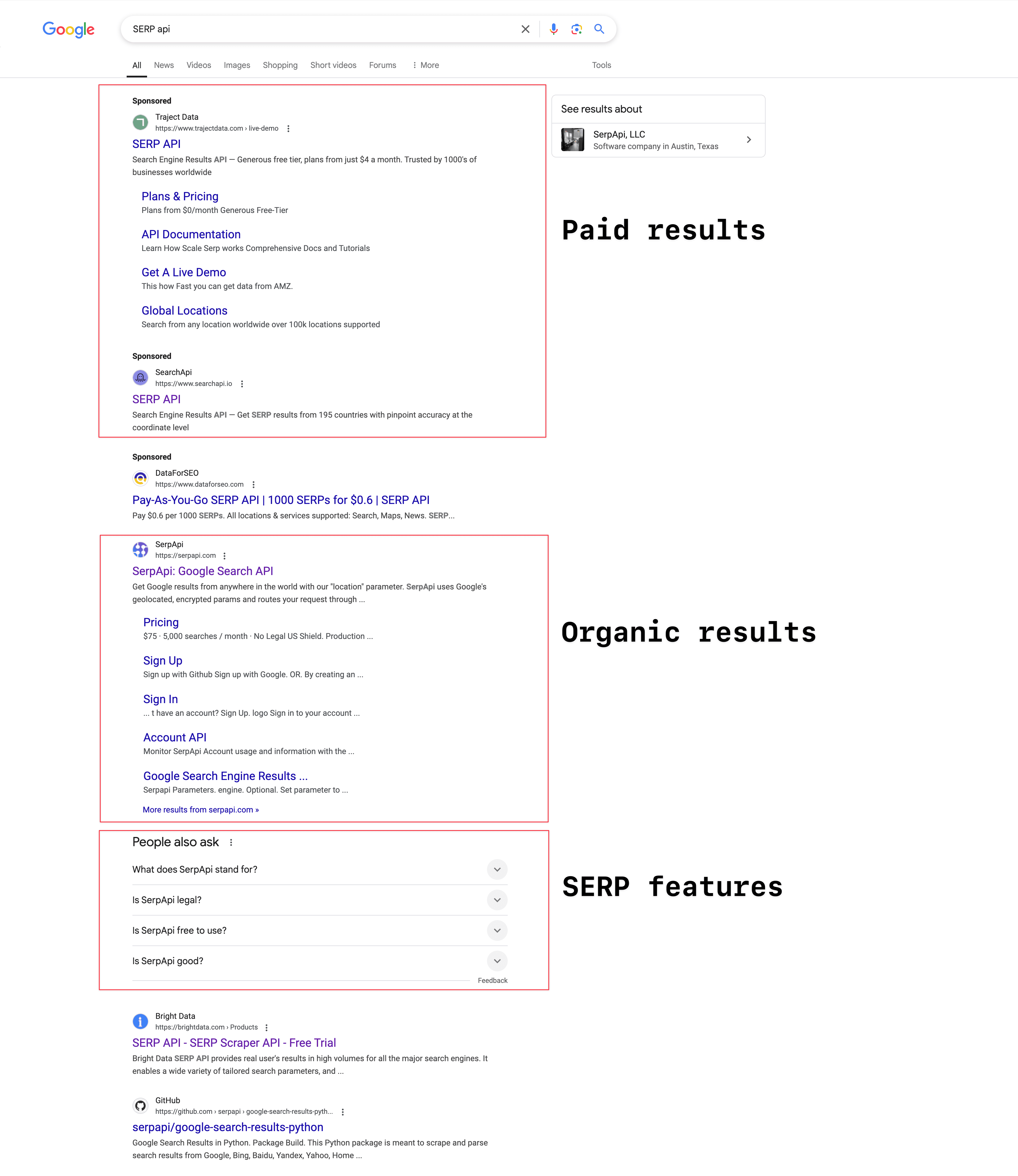
Afhankelijk van je zoekopdracht ziet de SERP er telkens anders uit. Meestal bestaat deze uit drie hoofdonderdelen:
-
Betaalde Resultaten: Dit zijn zoekresultaten met het label "Advertentie" of "Gesponsord". Bedrijven betalen Google om boven of onder de organische resultaten te verschijnen. Gesponsorde advertenties zijn niet altijd zichtbaar, dat hangt af van de zoekopdracht. In 2023 haalde Google volgens een advertentie-omzet van 264,59 miljard dollar binnen.
-
Organische Resultaten: Dit zijn de niet-betaalde resultaten, gerangschikt op relevantie en autoriteit van de pagina. Elk resultaat bevat een titel, meta-omschrijving en URL.
-
SERP-functies: Google voegt steeds meer extra’s toe om de gebruikerservaring te verbeteren. Denk aan featured snippets, AI-overzichten, People Also Ask-boxen (PAA), kennispanelen, lokale pakketten (voor lokale zoekopdrachten), video’s, afbeeldingen en shoppingresultaten.
Soorten Data
Als je weet hoe een SERP is opgebouwd, weet je ook welke informatie je eruit kunt halen, zoals:
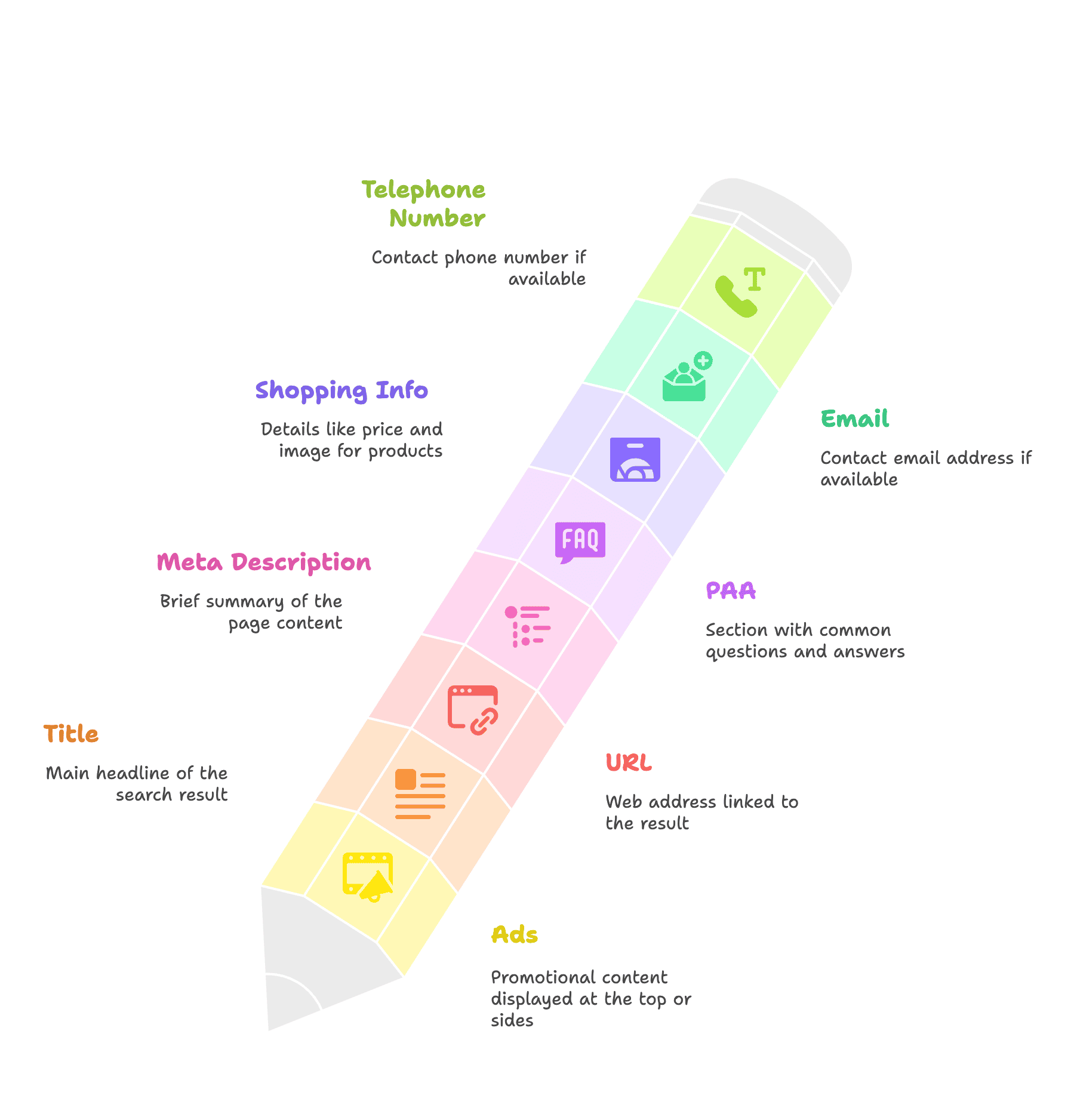
- Advertenties
- Titel
- URL
- Meta-omschrijving
- PAA-box
- Shoppinginformatie: prijs, afbeelding
- E-mailadres
- Telefoonnummer
Wat Kun je met SERP-data Doen?
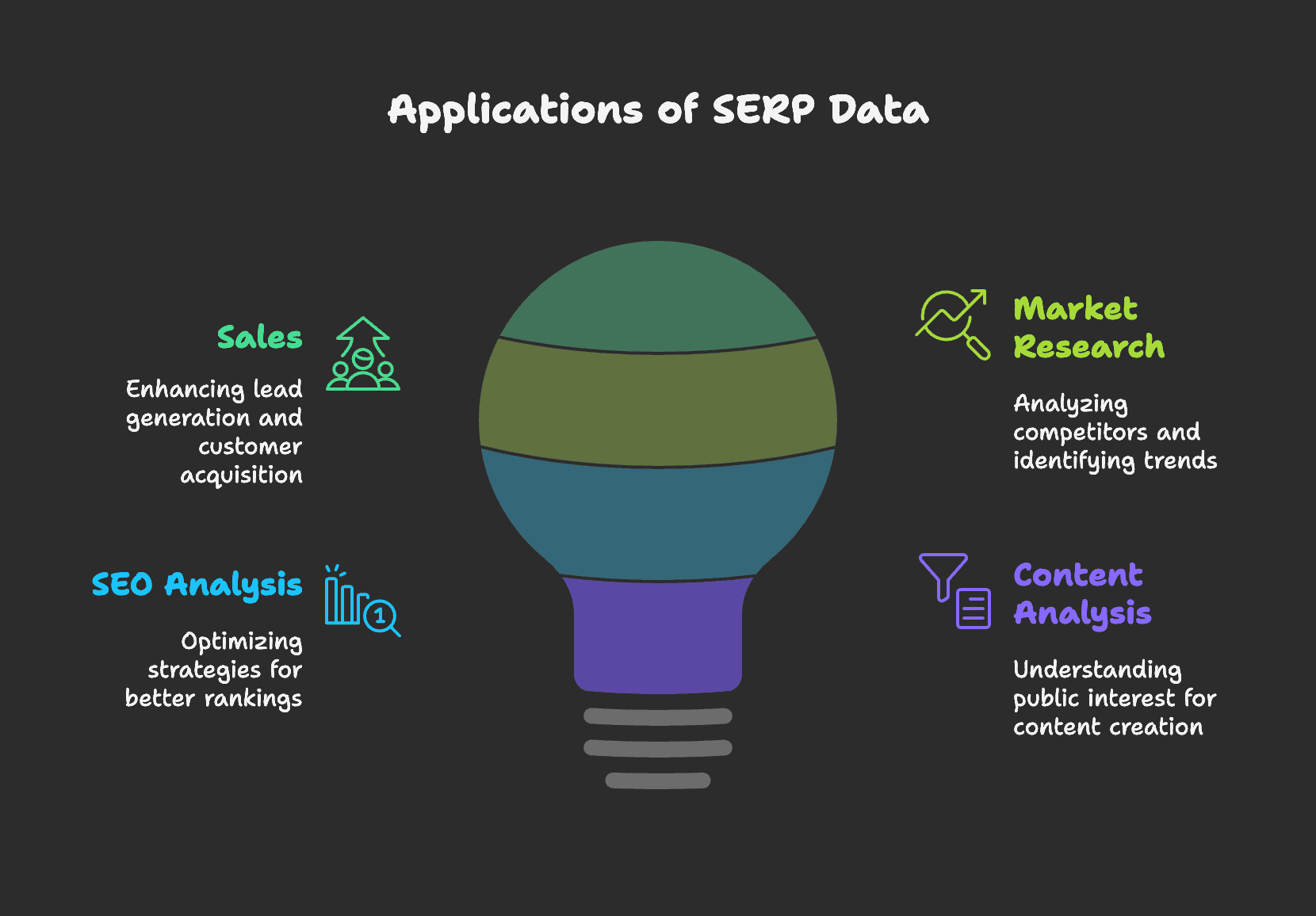
Sales
Met gerichte zoekopdrachten kunnen sales-teams snel en efficiënt leads verzamelen en verkoopkansen ontdekken die anderen missen. Google helpt je om contactgegevens van potentiële klanten te vinden op sociale platforms, zoals e-mailadressen en telefoonnummers. Hieronder vind je een praktische uitleg over het verzamelen van leads via Instagram met SERP-data.
Marktonderzoek
SERP-resultaten zijn een goudmijn voor marketeers. Door bijvoorbeeld advertenties en productinformatie van concurrenten te scrapen, krijg je inzicht in hun strategieën en kun je je eigen campagnes aanscherpen.
SERP’s geven ook inzicht in markttrends. Door zoekwoordtrends te analyseren, ontdek je nieuwe kansen. Een plotselinge stijging in zoekvolume voor een bepaald onderwerp kan wijzen op een opkomende trend. Bijvoorbeeld: als je een kledingwinkel hebt en je ziet dat “duurzame mode” steeds vaker wordt gezocht, is het slim om je assortiment daarop aan te passen.
SEO-analyse
Voor SEO-specialisten is de SERP het startpunt. Door SERP-data te analyseren, kun je je zoekwoordstrategie en website-inhoud optimaliseren om hoger te scoren in Google.
Neem bijvoorbeeld de PAA-box. Door deze gerelateerde vragen te scrapen en te analyseren, ontdek je waar gebruikers nog meer naar zoeken en kun je je content daarop afstemmen.
Contentanalyse
Voor journalisten is het scrapen van Google Nieuws-resultaten een manier om trends te spotten en te ontdekken welke onderwerpen leven bij het publiek. In onze handleiding lees je hoe je met een webscraper artikelen kunt verzamelen.
Hoe Scrape je een Google Zoekresultatenpagina?
Nu je weet wat je met SERP-data kunt doen, is de volgende vraag: hoe haal je die data binnen?
Handmatig kopiëren en plakken is een optie, maar niet te doen als je veel data wilt verzamelen. Dankzij technologische ontwikkelingen, en vooral AI, kun je met webscrapers eenvoudig grote hoeveelheden data ophalen. Hieronder vind je drie geautomatiseerde methoden:
Met Thunderbit AI-webscraper
is een no-code AI-webscraper waarmee je zonder gedoe alles van een website kunt halen wat je nodig hebt. Je kunt gebruikmaken van of zelf de kolommen instellen. We nemen als voorbeeld een sales use case, Leads Generatie, en laten stap voor stap zien hoe je met Thunderbit gekwalificeerde leads vindt.
-
Stap 1: Voeg Thunderbit toe als Chrome-extensie en log in met je Google-account of e-mailadres.
-
Stap 2: Voer je zoekopdracht in.
Om je zoekresultaten te verfijnen, kun je gebruiken.
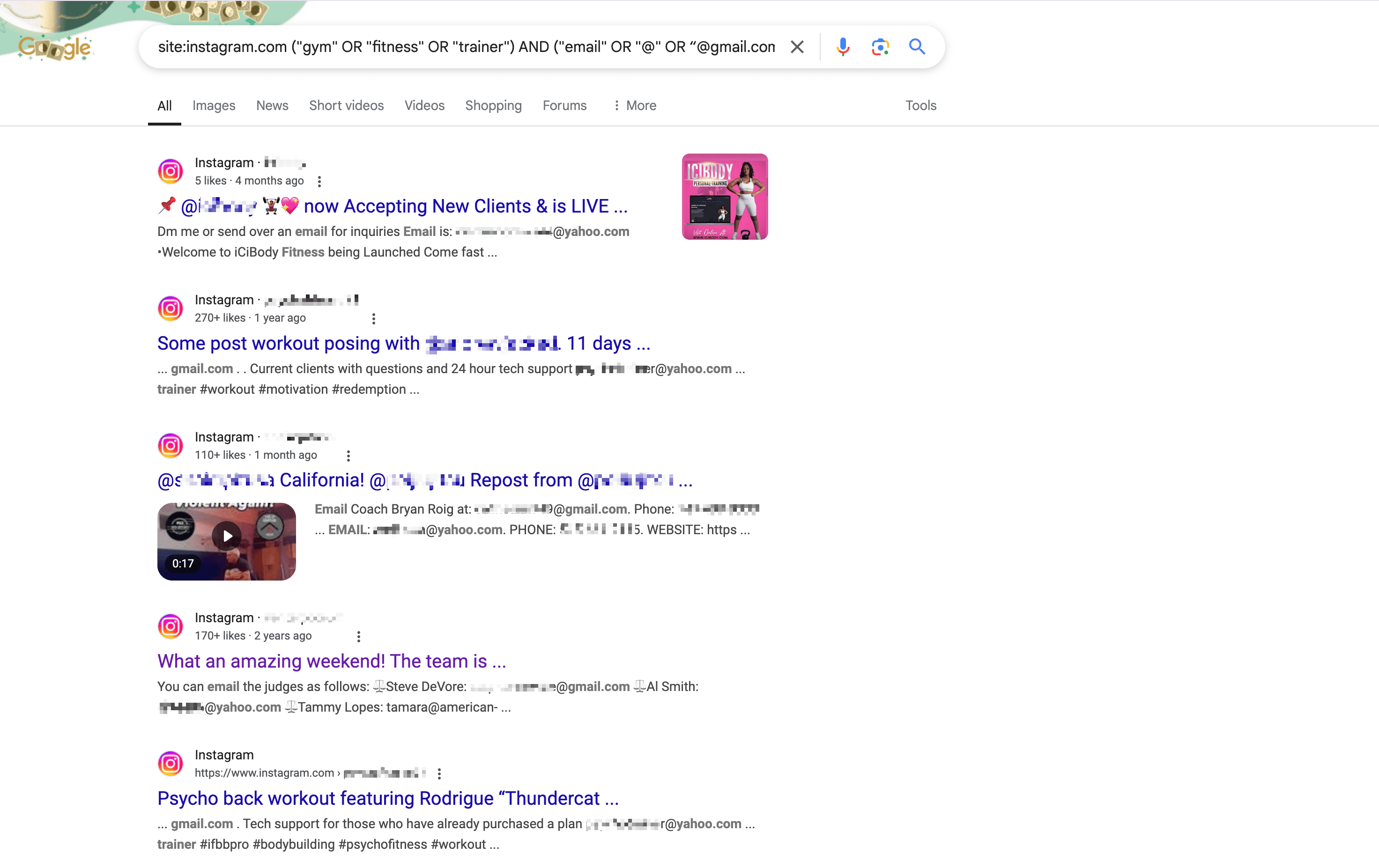
Bijvoorbeeld, deze zoekopdracht is door gegenereerd om e-mailadressen te vinden van mensen die met sportscholen in LA te maken hebben op Instagram:
1site:instagram.com ("gym" OR "fitness" OR "trainer") AND ("email" OR "@" OR “@gmail.com“ or ”@yahoo.com“ ) AND ("Los Angeles" OR "LA" OR "California")Plak deze zoekopdracht in Google en druk op Enter – je ziet nu alle relevante informatie in de resultaten.
-
Stap 3: Start Thunderbit en begin met scrapen
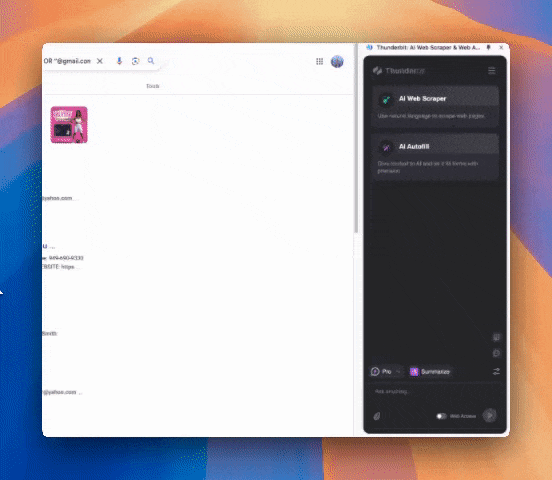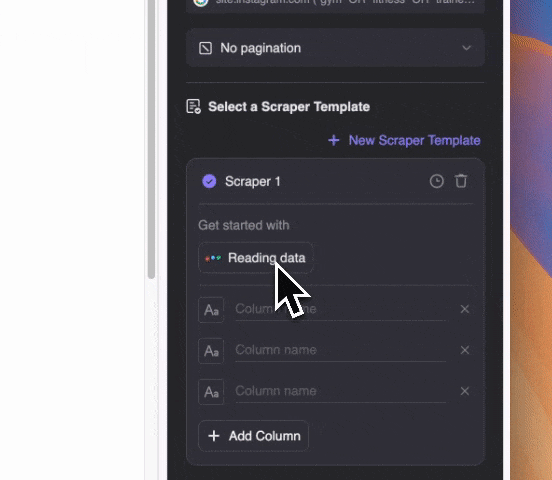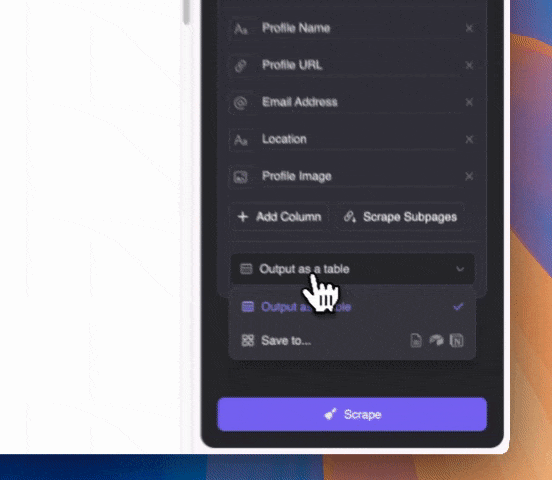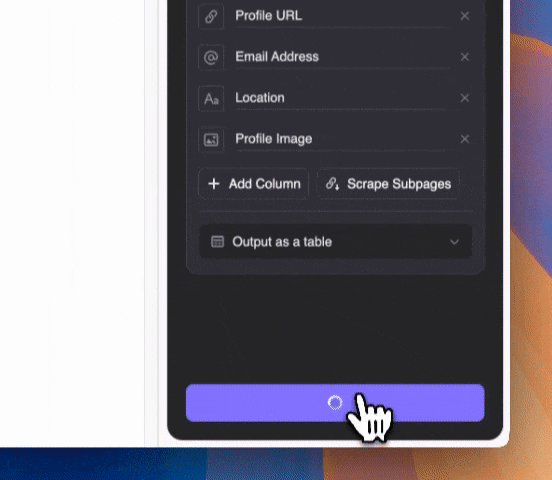 Beschrijf in gewone taal welke informatie je wilt scrapen (je kunt ook op "Gedetailleerde instructie toevoegen" klikken voor meer specificaties). Kies of je het wilt exporteren als tabel, of direct naar Notion, Airtable of Google Sheets.
Beschrijf in gewone taal welke informatie je wilt scrapen (je kunt ook op "Gedetailleerde instructie toevoegen" klikken voor meer specificaties). Kies of je het wilt exporteren als tabel, of direct naar Notion, Airtable of Google Sheets.Thunderbit gebruikt AI om je te helpen scrapen. Dus zelfs als e-mailadressen in de snippet op de Google SERP zijn verwerkt met andere tekst, kan de AI deze toch nauwkeurig voor je eruit halen.
Klik op de Scrape-knop en wacht op het resultaat!
Met een traditionele webscraper
Ook met traditionele webscrapers kun je Google SERP-data in bulk verzamelen. Zo werkt het met WebScraper.io:
- Installeer de Web Scraper-extensie en open Chrome Developer Tools.
- Klik op “Create new sitemap” en stel de start-URL in op je Google zoekresultatenpagina.
- Stel selectors in om specifieke data te selecteren.
| Selector Name | Type | Selector | Multiple? |
|---|---|---|---|
| name | Tekst | selecteer de naam van de gebruiker | Nee ❌ |
| profile | Tekst | selecteer de meta-omschrijving op deze pagina | Nee ❌ |
-
Start de scraper en exporteer de data.
-
Na het scrapen van bio’s moet je e-mailadressen uit Excel halen met een regex-formule:
1text=REGEXEXTRACT(A2,"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")(ervan uitgaande dat A2 je profieltekst bevat)
Zo kun je eenvoudig e-mailadressen uit de data halen.
Het nadeel van deze methode is dat je enige kennis van webstructuren nodig hebt. En als de website verandert (wat zelfs binnen een dag kan gebeuren), moet je de selectors opnieuw instellen.
Met de officiële Google API of externe SERP API’s
Google biedt een officiële API, de , waarmee je geautomatiseerd toegang krijgt tot zoekresultaten. Je moet hiervoor een aanmaken, een API-sleutel genereren en met Python een verzoek doen. Je krijgt echter alleen toegang tot de data die Google beschikbaar stelt, en het aantal verzoeken is beperkt. Wil je meer maatwerk, dan is deze methode minder geschikt.
Een veelgebruikte optie is het inzetten van externe SERP scraper API’s (zoals Zen SERP, SerpApi, ScrapingBee). Ook dit vraagt om een technische setup en het schrijven van code. Na installatie moet je code schrijven om alle relevante Instagram-profiel-URL’s te verzamelen en vervolgens e-mailadressen uit de bio te halen. Voor niet-technische zakelijke gebruikers is dit vaak te complex.
1import requests
2from bs4 import BeautifulSoup
3import re
4# SerpApi-gegevens
5SERP_API_KEY = "your_serpapi_key"
6SEARCH_QUERY = "marketing consultant site:instagram.com"
7# Stap 1: Instagram-profielen ophalen via SerpApi
8def get_instagram_profiles(query):
9 url = "https://serpapi.com/search"
10 params = {
11 "engine": "google",
12 "q": query,
13 "api_key": SERP_API_KEY
14 }
15 response = requests.get(url, params=params)
16 data = response.json()
17 profile_urls = []
18 for result in data.get("organic_results", []):
19 link = result.get("link")
20 if "instagram.com" in link:
21 profile_urls.append(link)
22 return profile_urls
23# Stap 2: E-mail uit Instagram-bio halen
24def extract_email_from_bio(profile_url):
25 headers = {"User-Agent": "Mozilla/5.0"}
26 response = requests.get(profile_url, headers=headers)
27 if response.status_code != 200:
28 return None
29 soup = BeautifulSoup(response.text, "html.parser")
30 bio_section = soup.find("meta", attrs={"name": "description"})
31 if bio_section:
32 bio_content = bio_section.get("content", "")
33 emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", bio_content)
34 return emails if emails else None
35 return None
36# Voorbeeldgebruik
37if __name__ == "__main__":
38 profiles = get_instagram_profiles(SEARCH_QUERY)
39 print("Gevonden Instagram-profielen:", profiles)
40 for profile in profiles:
41 emails = extract_email_from_bio(profile)
42 if emails:
43 print(f"E-mails gevonden in \{profile\}: \{emails\}")
44 else:
45 print(f"Geen e-mail gevonden in \{profile\}")Vergelijking van de 3 Methoden
Wil je snel en zonder technische kennis data verzamelen? → Kies voor
Wil je volledige controle over de data en heb je kennis van HTML/CSS? → Gebruik een traditionele webscraper
Wil je miljoenen datapunten verzamelen tegen lage kosten en heb je een techneut in huis? → Ga voor een externe SERP API
Is het Legaal om Google te Scrapen?
De legaliteit van webscraping is een veelgestelde vraag. ? Het korte antwoord: het hangt ervan af. De wet verschilt per land, het doel van de scraping, de gebruiksvoorwaarden en de aard van de data. Er is dus geen eenduidig antwoord.
Volgens de is automatisch scrapen van hun diensten niet toegestaan. Toch geldt in het algemeen dat . Ook het doel van de scraping (commercieel of niet-commercieel) speelt een grote rol.
Wil je zeker weten dat je ethisch en legaal bezig bent? Lees altijd de gebruiksvoorwaarden, scrape alleen openbare data en gebruik de verzamelde informatie niet voor illegale doeleinden. Voor grootschalige scraping is het verstandig juridisch advies in te winnen.
Conclusie
Data is “, en Google SERP is een onbenutte goudmijn. Wie SERP-data snel weet om te zetten in actie, heeft een voorsprong in de markt. Leads genereren, marktonderzoek en zoekmachineoptimalisatie zijn typische toepassingen van SERP-data.
Afhankelijk van je technische kennis, budget, hoeveelheid data en doel, hebben we je kennis laten maken met de nieuwste AI-webscraper Thunderbit, traditionele webscrapers en SERP API’s.
Wil je als ondernemer met één klik alle resultaten scrapen? Dan is Thunderbit zonder twijfel de beste keuze – waar wacht je nog op? .
FAQ
1. Welke soorten data kan ik van een Google Zoekresultatenpagina (SERP) halen?
Je kunt onder andere titels, URL’s, meta-omschrijvingen, advertenties, featured snippets, shoppinginformatie (zoals prijs en afbeeldingen), People Also Ask-vragen, e-mailadressen, telefoonnummers en meer verzamelen.
2. Wat maakt Thunderbit anders dan traditionele webscrapers of SERP API’s?
is een no-code, AI-gedreven Chrome-extensie waarmee je gestructureerde data kunt verzamelen met gewone taal – je hoeft geen selectors in te stellen of te programmeren. Traditionele scrapers vereisen technische kennis en API’s vragen om code en hebben limieten qua data.
3. Heb ik technische kennis nodig om met Thunderbit Google-resultaten te scrapen?
Nee. Thunderbit is speciaal ontwikkeld voor niet-technische gebruikers. Je beschrijft simpelweg in gewone taal welke data je wilt, en de AI doet de rest.
4. Kan ik de gescrapete data exporteren naar bijvoorbeeld Google Sheets of Notion?
Ja. Met Thunderbit kun je direct exporteren naar Google Sheets, Airtable, Notion of als downloadbare tabel – zo kun je direct aan de slag met je data.
5. Wat zijn praktische toepassingen van het scrapen van Google SERP-data?
Veelvoorkomende toepassingen zijn leadgeneratie, concurrentieonderzoek, SEO-analyse, trendonderzoek en contentplanning. Denk aan sales-teams die contactgegevens zoeken, marketeers die advertentieposities analyseren en SEO-specialisten die zoekwoordprestaties en gerelateerde vragen volgen.