Als je ooit een gerichte saleslijst hebt willen opbouwen, nieuwe markten hebt verkend of concurrenten hebt vergeleken, weet je dat Google Maps een goudmijn is. Maar hier komt de clou: met meer dan 1,5 miljard “near me”-zoekopdrachten per maand en 76% van de lokale zoekers die binnen 24 uur een bedrijf bezoeken (), is de vraag naar actuele, locatiegebonden bedrijfsdata nog nooit zo groot geweest.
Of je nu in sales, marketing of operations werkt: gestructureerde data uit Google Maps halen kan het verschil maken tussen een koude benadering en een warme lead met hoge kans op conversie.
Ik werk al jaren in SaaS en automatisering, en ik heb van dichtbij gezien hoe teams Python gebruiken (en nu ook AI-gedreven tools zoals ) om Google Maps om te zetten in een strategisch voordeel.
In deze gids leg ik stap voor stap uit hoe je in 2026 Google Maps-gegevens scrapt met Python — inclusief code, compliance-tips en een vergelijking met no-code-oplossingen. Of je nu een Python-pro bent of gewoon de snelste weg naar bruikbare data zoekt, je zit hier goed.
Wat betekent het om Google Maps te scrapen met Python?
Laten we bij de basis beginnen: Google Maps scrapen met Python betekent dat je programmatisch bedrijfsinformatie — zoals namen, adressen, beoordelingen, reviews, telefoonnummers en coördinaten — uit Google Maps haalt, zodat je die kunt analyseren, filteren en exporteren voor zakelijk gebruik.

Er zijn twee hoofdmanieren om dit te doen:
- Google Maps Places API: de officiële, gelicentieerde manier. Je gebruikt een API-sleutel om Google’s servers te bevragen en krijgt gestructureerde JSON-data terug. Dit is stabiel, voorspelbaar en (meestal) compliant, maar er gelden quota en kosten.
- Webscraping van de HTML: je automatiseert een browser (met tools zoals Playwright of Selenium) om Google Maps te laden, zoekopdrachten uit te voeren en de gerenderde pagina te parseren. Dit is flexibeler, maar ook fragiel — Google past de sitestructuur regelmatig aan, en HTML scrapen kan in strijd zijn met de voorwaarden van Google.
Typische data die je kunt ophalen:
- Bedrijfsnaam
- Categorie/type
- Volledig adres (plus stad, staat, postcode, land)
- Breedte- en lengtegraad
- Telefoonnummer
- Website-URL
- Beoordeling en aantal reviews
- Prijsniveau
- Bedrijfsstatus (open/gesloten)
- Openingstijden
- Place ID (Google’s unieke identificatie)
- Google Maps-URL
Waarom is dit belangrijk? Omdat deze velden alles aandrijven: van leadgeneratie en territoriumplanning tot concurrentieanalyse en marktonderzoek. De sleutel is om de juiste data te targeten voor je bedrijfsdoelen — scrape dus niet zomaar blind.
Waarom sales- en marketingteams gegevens uit Google Maps halen met Python
Laten we praktisch worden. Waarom zijn zoveel sales- en marketingteams in 2026 zo gefocust op Google Maps-data?
- Leadgeneratie: bouw hypergerichte lijsten van lokale bedrijven, compleet met contactgegevens en beoordelingen, voor outreach-campagnes.
- Territoriumplanning: breng salesgebieden, bezorgzones of servicegebieden in kaart op basis van echte bedrijfsdichtheid en -types.
- Concurrentiemonitoring: volg in de tijd de locaties, beoordelingen en reviews van concurrenten om trends en kansen te ontdekken.
- Marktonderzoek: analyseer bedrijfscategorieën, openingstijden en sentiment in reviews om go-to-market-strategieën te onderbouwen.
- Locatieselectie: voor vastgoed en retail kun je potentiële locaties beoordelen op basis van nabijgelegen voorzieningen, foot traffic en concurrentie.
Impact in de praktijk: Volgens de is 92% van de salesteams van plan te investeren in AI/data, en teams die gerichte, lokale data gebruiken zien conversieratio’s tot 8× hoger dan teams die op generieke cold lists vertrouwen (). Uit een onderzoek naar leadgeneratie voor franchises bleek zelfs $15 nieuwe omzet voor elke $1 die werd uitgegeven aan op Google Maps gebaseerde leadlijsten.
Bedrijfsdoelen koppelen aan Google Maps-velden:
| Bedrijfsdoel | Benodigde Google Maps-velden |
|---|---|
| Lokale leadlijst | naam, adres, telefoon, website, categorie |
| Territoriumplanning | naam, lat/lng, business_status, opening_hours |
| Concurrentiebenchmarking | naam, beoordeling, userRatingCount, priceLevel, reviews |
| Locatieselectie | categorie, lat/lng, reviewdichtheid, openingDate |
| Inzichten in sentiment/menu | reviews, editorialSummary, photos, types |
| Outreach via e-mail/telefoon | nationalPhoneNumber, websiteUri (daarna aanvullen waar nodig) |
Je Python Google Maps-scraper instellen: tools en vereisten
Voordat je begint met scrapen, moet je je Python-omgeving instellen en de juiste tools verzamelen. Dit heb je in 2026 nodig:
1. Installeer Python en vereiste libraries
Aanbevolen Python-versie: 3.10 of hoger.
Installeer de belangrijkste libraries:
1pip install \
2 requests==2.33.1 httpx==0.28.1 \
3 beautifulsoup4==4.14.3 lxml==6.0.3 \
4 pandas==2.3.3 \
5 selenium==4.43.0 playwright==1.58.0 \
6 googlemaps==4.10.0 google-maps-places==0.8.0 \
7 schedule==1.2.2 APScheduler==3.11.2 \
8 python-dotenv==1.2.2 tenacity==9.1.4
9playwright install chromiumWat deze doen:
requests,httpx: HTTP-verzoeken (API-aanroepen)beautifulsoup4,lxml: HTML-parsing (voor webscraping)pandas: data opschonen, analyseren en exporterenselenium,playwright: browserautomatisering (voor HTML-scraping)googlemaps,google-maps-places: Google Maps API-clientsschedule,APScheduler: taken plannenpython-dotenv: API-sleutels veilig laden uit.env-bestandentenacity: retry-logica voor foutafhandeling
2. Vraag een Google Maps API-sleutel aan (voor API-gebaseerde scraping)
- Ga naar .
- Maak een project aan of selecteer een bestaand project.
- Schakel billing in (vereist, ook voor free-tier gebruik).
- Schakel “Places API (New)” in onder APIs & Services > Library.
- Ga naar Credentials > Create Credentials > API Key.
- Beperk je sleutel tot specifieke API’s en IP’s voor extra veiligheid.
- Bewaar je API-sleutel in een
.env-bestand (nooit in je code committen):
1GOOGLE_MAPS_API_KEY=your_actual_api_key_hereLet op: Sinds maart 2025 biedt Google geen universeel gratis krediet van $200 per maand meer. In plaats daarvan krijg je per API-tier gratis maandelijkse drempels (zie ).
Hoe je gegevens uit Google Maps haalt met Python: stap-voor-stap gids
We splitsen de twee hoofdbenaderingen op — API-gebaseerd en HTML-scraping — zodat je kunt kiezen wat bij je past.
Aanpak 1: De Google Maps Places API gebruiken (aanbevolen)
Stap 1: Vereiste libraries installeren en importeren
1import os
2import httpx
3import pandas as pd
4from dotenv import load_dotenvStap 2: Je API-sleutel veilig laden
1load_dotenv()
2API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]Stap 3: Je zoekopdracht opbouwen
Je gebruikt het Text Search-endpoint om bedrijven te vinden die aan je criteria voldoen.
1URL = "https://places.googleapis.com/v1/places:searchText"
2FIELD_MASK = ",".join([
3 "places.id", "places.displayName", "places.formattedAddress",
4 "places.location", "places.rating", "places.userRatingCount",
5 "places.priceLevel", "places.types",
6 "places.nationalPhoneNumber", "places.websiteUri",
7 "nextPageToken",
8])Stap 4: De API-aanroep doen
1def text_search(query, lat, lng, radius=3000, min_rating=4.0):
2 body = {
3 "textQuery": query,
4 "minRating": min_rating, # server-side filter
5 "includedType": "restaurant",
6 "openNow": False,
7 "pageSize": 20,
8 "locationBias": {
9 "circle": {
10 "center": {"latitude": lat, "longitude": lng},
11 "radius": radius,
12 }
13 },
14 }
15 headers = {
16 "Content-Type": "application/json",
17 "X-Goog-Api-Key": API_KEY,
18 "X-Goog-FieldMask": FIELD_MASK, # Altijd instellen!
19 }
20 r = httpx.post(URL, json=body, headers=headers, timeout=30)
21 r.raise_for_status()
22 return r.json()Stap 5: Paginering afhandelen en resultaten verzamelen
1def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
2 results = []
3 next_page_token = None
4 while True:
5 data = text_search(query, lat, lng, radius, min_rating)
6 places = data.get('places', [])
7 results.extend(places)
8 next_page_token = data.get('nextPageToken')
9 if not next_page_token:
10 break
11 return resultsStap 6: Gegevens exporteren met Pandas
1df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
2df.to_csv("brooklyn_coffee_shops.csv", index=False)Pro-tips:
- Stel altijd de
X-Goog-FieldMask-header in om kosten te beheersen. Als je reviews of foto’s opvraagt, kan je prijs per 1.000 verzoeken van $5 naar $25 stijgen (). - Gebruik server-side filters (zoals
minRating,includedType,locationBias) om geen credits te verspillen aan irrelevante resultaten. - Cache
place_id-waarden voor deduplicatie en toekomstige updates.
Aanpak 2: Google Maps HTML scrapen (voor educatief of eenmalig gebruik)
Waarschuwing: Google Maps is een single-page app. Je moet browserautomatisering gebruiken (Playwright of Selenium), en HTML-scraping kan in strijd zijn met Google’s voorwaarden. Gebruik dit voor onderzoek, niet voor productie.
Stap 1: Playwright installeren en een browser starten
1from playwright.sync_api import sync_playwright
2import time, re
3def scrape_maps(query, max_results=100):
4 with sync_playwright() as pw:
5 browser = pw.chromium.launch(headless=True)
6 ctx = browser.new_context(
7 user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
8 locale="en-US",
9 )
10 page = ctx.new_page()
11 page.goto("https://www.google.com/maps", timeout=60_000)
12 page.fill("#searchboxinput", query)
13 page.click('button[aria-label="Search"]')
14 page.wait_for_selector('div[role="feed"]')
15 feed = page.locator('div[role="feed"]')
16 prev = 0
17 while True:
18 feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
19 time.sleep(2)
20 count = page.locator('div[role="feed"] > div > div[jsaction]').count()
21 if count == prev or count >= max_results:
22 break
23 prev = count
24 if page.locator("text=You've reached the end of the list").count():
25 break
26 rows = []
27 cards = page.locator('div[role="feed"] > div > div[jsaction]')
28 for i in range(cards.count()):
29 c = cards.nth(i)
30 name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
31 rating_el = c.locator('span[role="img"]').first
32 raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
33 m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
34 rating = float(m.group(1)) if m else None
35 reviews = int(m.group(2).replace(",", "")) if m else None
36 rows.append({"name": name, "rating": rating, "reviews": reviews})
37 browser.close()
38 return rowsTips:
- Google randomiseert CSS-klassen om de paar weken, dus deze code moet mogelijk regelmatig worden bijgewerkt.
- Gebruik vertragingen die menselijk gedrag nabootsen en scrape niet te snel om de kans op blokkering te verkleinen.
- Probeer nooit CAPTCHA’s of Google’s SearchGuard-systeem te omzeilen — dat kan juridische risico’s met zich meebrengen.
Vermijd blind scrapen: hoe je precies de data target die je nodig hebt
Alles scrapen is een recept voor tijdverlies en logge datasets. Zo target je alleen de data die ertoe doet:
- Genereer gerichte URL-lijsten: gebruik de eigen zoekfilters van Google Maps (categorie, locatie, beoordeling, nu open) om resultaten te verfijnen vóór het scrapen.
- Gebruik frase-matching: zoek op exacte bedrijfstypes of keywords (bijv. “vegan bakkerij in Austin”).
- Locatiefilters: geef stad, wijk of zelfs coördinaten en straal op voor nauwkeurige resultaten.
- Server-side filtering (API): gebruik
minRating,includedTypeenlocationBiasin de request body van je API. - Client-side filtering (Python): gebruik na het scrapen pandas om bedrijven te filteren met een beoordeling boven 4.0, meer dan 50 reviews of specifieke categorieën.
Voorbeeld: alleen restaurants in Manhattan filteren met een beoordeling boven 4.0
1df = pd.DataFrame(results)
2filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
3filtered.to_csv("manhattan_top_restaurants.csv", index=False)Python libraries gebruiken om Google Maps-data te organiseren en exporteren
Zodra je je data hebt gescrapt, is het tijd om die op te schonen, te analyseren en te exporteren voor je team.
Data opschonen en structureren met Pandas
1import pandas as pd
2df = pd.read_json("brooklyn_restaurants.json")
3df = (
4 df.dropna(subset=["name", "address"])
5 .drop_duplicates(subset=["place_id"])
6 .assign(
7 name=lambda d: d["name"].str.strip(),
8 phone=lambda d: d["phone"].astype(str)
9 .str.replace(r"\D", "", regex=True)
10 .str.replace(r"^1?(\d\{10\})$", r"+1\1", regex=True),
11 rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
12 user_ratings_total=lambda d: pd.to_numeric(
13 d["user_ratings_total"], errors="coerce"
14 ).fillna(0).astype("int32"),
15 )
16)Data analyseren en samenvatten
Voorbeeld: gemiddelde beoordeling per wijk
1by_neighborhood = (
2 df.groupby("neighborhood", as_index=False)
3 .agg(avg_rating=("rating", "mean"),
4 n_places=("place_id", "nunique"),
5 median_reviews=("user_ratings_total", "median"))
6 .sort_values("avg_rating", ascending=False)
7)Exporteren naar Excel of CSV
1df.to_csv("brooklyn_top.csv", index=False)
2df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")Grote datasets? Gebruik dan Parquet voor snelheid en ruimte-efficiëntie:
1df.to_parquet("brooklyn_top.parquet", compression="zstd")Thunderbit: AI-gedreven alternatief voor een Python Google Maps-scraper
Als je nu denkt: “Dit is best veel gedoe voor een simpele leadlijst,” dan ben je niet de enige. Precies daarom hebben we gebouwd — een AI-gedreven, no-code webscraper waarmee je Google Maps-data (en veel meer) in een paar klikken kunt ophalen.
Waarom Thunderbit?
- Geen code of API-sleutels nodig: open gewoon de , ga naar Google Maps en klik op “AI Suggest Fields”.
- AI-veldherkenning: Thunderbit’s AI leest de pagina en stelt de juiste kolommen voor — naam, adres, beoordeling, telefoon, website en meer.
- Subpagina-scraping: wil je je tabel verrijken met gegevens van de website van elk bedrijf? Thunderbit kan elke subpagina bezoeken en automatisch extra info ophalen.
- Export naar Excel, Google Sheets, Airtable of Notion: geen gedoe meer met pandas — klik op “Exporteren” en je data is klaar voor je team.
- Gepland scrapen: stel terugkerende taken in om concurrenten te volgen of je leadlijst automatisch te verversen.
- Geen onderhoud: Thunderbit’s AI past zich aan sitewijzigingen aan, zodat je niet voortdurend kapotte scripts hoeft te repareren.
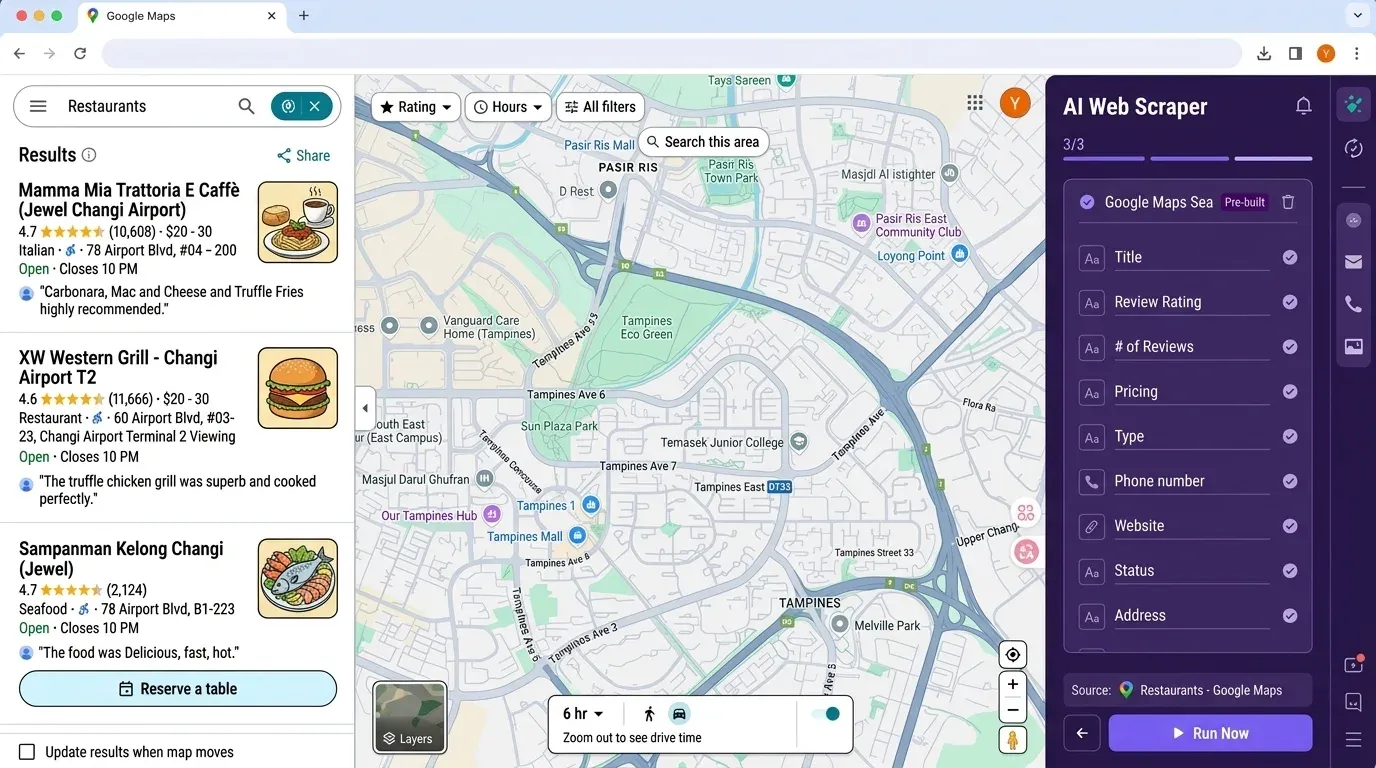
Thunderbit versus Python-workflow:
| Stap | Python-scraper | Thunderbit |
|---|---|---|
| Tools installeren | 30–60 min (Python, pip, libraries) | 2 min (Chrome-extensie) |
| API-sleutel instellen | 10–30 min (Cloud Console) | Niet nodig |
| Veldselectie | Handmatige code, field masks | AI Suggest Fields (1 klik) |
| Data-extractie | Scripts schrijven/uitvoeren, fouten afhandelen | Klik op “Scrape” |
| Exporteren | pandas naar CSV/Excel | Exporteren naar Excel/Sheets/Notion |
| Onderhoud | Handmatige updates bij sitewijzigingen | AI past zich automatisch aan |
Bonus: Thunderbit wordt vertrouwd door meer dan , en met de gratis versie kun je tot 6 pagina’s scrapen (of 10 met een proefboost) zonder kosten.
Compliant blijven: de gebruiksvoorwaarden van Google Maps en scraping-ethiek
Hier lopen veel Python-tutorials gevaarlijk achter. Dit moet je in 2026 weten:
- Google Maps Platform ToS §3.2.3 verbiedt expliciet het scrapen, cachen of exporteren van data buiten de officiële API’s (). De enige uitzondering: latitude/longitude-waarden mogen tot 30 dagen worden gecached; Place ID’s mogen onbeperkt worden opgeslagen.
- API-gebruikers zijn contractueel gebonden: gebruik je een API-sleutel, dan ga je akkoord met Google’s voorwaarden — ook als je alleen openbare data scrapt.
- Het omzeilen van technische barrières (CAPTCHA’s, SearchGuard) kan nu een mogelijke DMCA §1201-schending zijn, met zelfs strafrechtelijke gevolgen ().
- AVG/GDPR en privacywetgeving: als je persoonlijke gegevens verzamelt (e-mails, telefoonnummers, namen van reviewers) uit Google Maps, moet je een rechtsgeldige grondslag hebben en verwijderverzoeken respecteren. De Franse CNIL legde KASPR in 2024 een boete van €200.000 op voor het scrapen van LinkedIn-contacten ().
- Best practices:
- Kies waar mogelijk standaard voor de Places API.
- Beperk je requests (≤10 QPS voor de API, 1–2 req/s voor HTML-scraping).
- Omzeil nooit CAPTCHA’s of technische blokkades.
- Verspreid gescrapete persoonsgegevens niet opnieuw.
- Respecteer opt-out- en verwijderverzoeken.
- Controleer altijd de lokale wetgeving — GDPR, CCPA en andere regels worden actief gehandhaafd.
Kortom: als compliance een zorg is, houd je dan aan de API en minimaliseer de data die je verzamelt. Voor de meeste zakelijke gebruikers verkleint een no-code tool zoals Thunderbit je risico aanzienlijk (geen API-sleutel, geen herdistributie).
Je Google Maps-scraping plannen en automatiseren met Python
Als je je data actueel wilt houden — bijvoorbeeld voor wekelijkse concurrentiemonitoring of maandelijkse updates van leadlijsten — dan is automatisering je beste vriend.
Eenvoudig plannen met schedule
1import schedule, time
2from my_scraper import run_job
3schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
4schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
5while True:
6 schedule.run_pending()
7 time.sleep(30)Productieklare planning met APScheduler
1from apscheduler.schedulers.background import BackgroundScheduler
2from apscheduler.triggers.cron import CronTrigger
3sched = BackgroundScheduler(timezone="America/New_York")
4sched.add_job(
5 run_job,
6 CronTrigger(hour=3, minute=15, jitter=600), # 03:15 ± 10 min
7 kwargs={"query": "restaurants in Brooklyn"},
8 id="brooklyn_daily",
9 max_instances=1,
10 coalesce=True,
11 misfire_grace_time=3600,
12)
13sched.start()Tips voor veilige automatisering
- Voeg willekeurige jitter toe aan je planning om voorspelbare patronen te vermijden.
- Laat HTML-scraping nooit sneller lopen dan 1–2 requests per seconde.
- Monitor bij API-gebruik je quota en stel billing alerts in.
- Log fouten altijd en houd een “dead-letter”-bestand bij voor mislukte requests.
Thunderbit-bonus: met Thunderbit kun je terugkerende scraping-taken direct in de interface inplannen — geen code, geen cronjobs, geen serverinstelling.
Belangrijkste inzichten: efficiënte, gerichte en compliant Google Maps-data-extractie
Laten we de essentie samenvatten:
- Google Maps is dé nummer 1-bron voor locatiegegevens van bedrijven, en voedt alles van leadgeneratie tot marktonderzoek.
- Scrapen met Python biedt flexibiliteit en controle, maar brengt ook setup-, onderhouds- en compliancewerk met zich mee — zeker nu Google’s anti-botmaatregelen en handhaving strenger worden.
- API-gebaseerde extractie is voor de meeste teams de veiligste en schaalbaarste route. Gebruik altijd field masks en server-side filters om kosten te beheersen.
- HTML-scraping is fragiel en risicovol — gebruik het alleen voor eenmalig onderzoek en omzeil nooit technische barrières.
- Target je data: gebruik frase-matching, locatiefilters en pandas-workflows om alleen te halen wat je nodig hebt.
- Thunderbit is de snelste route voor niet-programmeurs: AI-gedreven, geen setup, directe export en ingebouwde planning.
- Compliance telt: respecteer Google’s voorwaarden, privacywetten en rate limits om juridische problemen te voorkomen.
Voor meer tutorials en tips, bekijk de en ons .
FAQ’s
1. Is het in 2026 legaal om Google Maps-data te scrapen met Python?
Google Maps scrapen via de officiële API is toegestaan binnen Google’s voorwaarden, zolang je quota respecteert en geen beperkte data herdistribueert. HTML-scraping van Google Maps is expliciet verboden door Google’s ToS en brengt juridische risico’s met zich mee, vooral als je technische barrières omzeilt of persoonlijke gegevens zonder toestemming verzamelt. Controleer altijd de lokale wetgeving (GDPR, CCPA, enz.) en houd je aan best practices voor compliance.
2. Wat is het verschil tussen de Google Maps API gebruiken en de HTML webscrapen?
De API is stabiel, gelicentieerd en ontworpen voor data-extractie, maar vereist een API-sleutel en is onderhevig aan quota en kosten. HTML-scraping gebruikt browserautomatisering om data uit de gerenderde pagina te halen, maar is fragiel (de site verandert vaak), kan voorwaarden schenden en is juridisch risicovoller. Voor de meeste zakelijke toepassingen is de API de aanbevolen route.
3. Hoeveel kost het om in 2026 Google Maps-data te extraheren met Python?
Google’s Places API-prijzen worden per 1.000 requests berekend en variëren van $5 (Essentials) tot $25 (Enterprise+Atmosphere), afhankelijk van de velden die je opvraagt. Er zijn gratis maandelijkse drempels (10.000 voor Essentials, 5.000 voor Pro, 1.000 voor Enterprise), maar grootschalig scrapen kan snel oplopen. Gebruik altijd field masks en server-side filters om kosten te beperken.
4. Hoe verhoudt Thunderbit zich tot Python-gebaseerde Google Maps-scrapers?
Thunderbit is een no-code, AI-gedreven webscraper waarmee je Google Maps-data (en veel meer) kunt extraheren zonder programmeren, API-sleutels of onderhoud. Het is ideaal voor sales- en marketingteams die snel en betrouwbaar willen exporteren naar Excel, Google Sheets, Airtable of Notion. Voor technische gebruikers die maatwerklogica nodig hebben, biedt Python meer flexibiliteit, maar het vraagt ook meer setup en compliancebeheer.
5. Hoe kan ik terugkerende Google Maps-data-extractie automatiseren?
Met Python kun je scheduling libraries zoals schedule of APScheduler gebruiken om je scraper op vaste intervallen te laten draaien (dagelijks, wekelijks, enz.). Voeg willekeurige jitter toe om detectie te vermijden en monitor je API-quota. Met Thunderbit kun je terugkerende scrapes direct in de interface inplannen — zonder code of serverinstelling.
Klaar om Google Maps om te zetten in jouw superkracht voor sales en marketing? Of je nu een Python-liefhebber bent of de snelste no-code-oplossing wilt, in 2026 staan de tools voor je klaar. Probeer voor directe, AI-gedreven scraping — of rol je mouwen op en duik in de API. Hoe dan ook: moge je leadlijsten vers zijn, je exports schoon en je campagnes vol hoogwaardige lokale prospects. Veel scrape-plezier!
Meer weten