Google zette zijn Flights API in 2018 stop, maar vluchtprijzen blijven schommelen — voor één binnenlandse route. Als je die data programmatisch wilt gebruiken, is scrapen eigenlijk de enige realistische optie.
Ik heb flink wat tijd besteed aan het testen van verschillende manieren om vluchtgegevens uit Google te halen, en het speelveld is flink veranderd — vooral nadat Google in januari 2025 SearchGuard uitrolde. In deze gids laat ik je stap voor stap zien hoe je met Playwright een werkende Python-scraper voor Google Flights bouwt, hoe je de anti-botmaatregelen omzeilt waar de meeste mensen op vastlopen, en hoe je dit vervolgens uitbreidt tot een geautomatiseerde prijsmonitor met meldingen. Wil je liever helemaal geen code schrijven? Dan laat ik je ook een no-code route zien met waarmee je in ongeveer twee minuten hetzelfde bereikt.
Waarom Google Flights scrapen met Python?
Google Flights is oppermachtig in vliegtickets zoeken. De zichtbaarheid op Amerikaanse mobiel en laat daarmee alle grote OTA’s achter zich. De reismeta-zoekmarkt daarachter was in 2024 en groeit met 30,2% per jaar. Toch bestaat er sinds het definitief sluiten van de QPX Express API op geen officiële manier meer om deze data programmatisch op te vragen.
Ondertussen kan de prijs voor dezelfde reisroute verschillen, met gemiddeld zo’n $20 tussen de laagste en hoogste prijs. Luchtvaartmaatschappijen zoals Delta werken met 77 tariefbuckets voor dynamische prijsstelling. De gemiddelde retourvlucht in de VS lag begin 2026 op $408, waarbij de ticketprijzen .
Dominant platform, geen API, grillige prijzen. Daarom is Google Flights scrapen met Python uitgegroeid tot een van de populairste projecten op GitHub en in reisforums.
Dit is wie er baat bij heeft en waarom:
| Type gebruiker | Toepassing | Belangrijkste voordeel |
|---|---|---|
| Individuele reizigers | Prijzen voor specifieke routes in de gaten houden | Gemiddeld $50 besparen per vlucht |
| Reisbureaus | Inzicht in concurrerende prijzen | Realtime bewaking van tariefpariteit |
| Corporate travel teams | Kosten optimaliseren over routes heen | 10–30% besparing op zakelijke reizen |
| Ontwikkelaars | Apps bouwen voor tariefvergelijking | Programmatische toegang tot prijsdata |
| Onderzoekers | Volatiliteit van luchtvaartprijzen analyseren | Academisch en marktonderzoek |
Gebruikers op forums zijn daar duidelijk over: "Google Flights API was discontinued and I should use web scraping instead" hoor je vaak terug. En de ROI is echt — op basis van meer dan 5 miljard prijsquotes per dag, terwijl Expedia-data uit 2026 laat zien dat 8–15 dagen van tevoren boeken ongeveer .
Welke data kun je uit Google Flights scrapen?
Een resultatenpagina van Google Flights bevat verrassend veel velden. Dit is meestal beschikbaar:
- Naam van de luchtvaartmaatschappij (en logo)
- Vertrektijd en luchthavencode
- Aankomsttijd en luchthavencode
- Totale vluchtdduur
- Aantal tussenstops en details van overstappen (luchthaven, duur, wel/niet ’s nachts)
- Ticketprijs (per valuta)
- CO2-uitstoot (kg CO2e, met procentuele afwijking t.o.v. typische vluchten)
- Reisklasse, vluchtnummer, vliegtuigtype
- Beenruimte
- Extra’s (wifi, stopcontacten, mediastreaming)
- Prijsindicatie (laag/typisch/hoog)
- Waarschuwing voor vertraging ("Vaak meer dan 30 min vertraging")
De beschikbare data verschilt per route, datum en type ticket (enkele reis vs. retour). Zo ziet één gescrapt vluchtrecord eruit in JSON:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Je Python-omgeving voorbereiden
Voordat we code gaan schrijven, moet je een paar dingen op orde hebben.
Benodigdheden:
- Moeilijkheidsgraad: gemiddeld
- Tijd nodig: ongeveer 1–2 uur voor de volledige tutorial
- Wat je nodig hebt: Python 3.7+, basiskennis van Python, een browser op basis van Chrome
Installeer de vereiste libraries
We gebruiken Playwright voor browserautomatisering (Google Flights is 100% JavaScript-gerenderd — simpele HTTP-verzoeken leveren niets bruikbaars op), plus een paar hulppakketten:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — automatisering van de headless browser, ondersteunt JavaScript-rendering en ingebouwde wachtmechanismen
- playwright-stealth — maskeert veelvoorkomende signalen voor botdetectie
- pandas — voor data-analyse en later CSV-export
Waarom Playwright in plaats van Selenium of requests
Google Flights werkt niet met alleen requests + BeautifulSoup — de paginainhoud wordt volledig via JavaScript opgebouwd. Je hebt een echte browser nodig.
| Eigenschap | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| JS-rendering | Volledige ondersteuning | Volledige ondersteuning | Geen |
| Snelheid | 42% sneller in totaal | Basisniveau | N.v.t. voor deze toepassing |
| Async-ondersteuning | Native | Alleen sequentieel | N.v.t. |
| Geheugenverbruik | 30% minder | Hoger | Minimaal |
| Omzeilen van botdetectie | Goed (met stealth) | Eerder detecteerbaar | N.v.t. |
Playwright is sneller, moderner en ondersteunt async veel beter. Voor Google Flights is het simpelweg de beste keuze.
Stap voor stap: Google Flights scrapen met Python
Dit is de kern van de tutorial. We bouwen de scraper stap voor stap op.
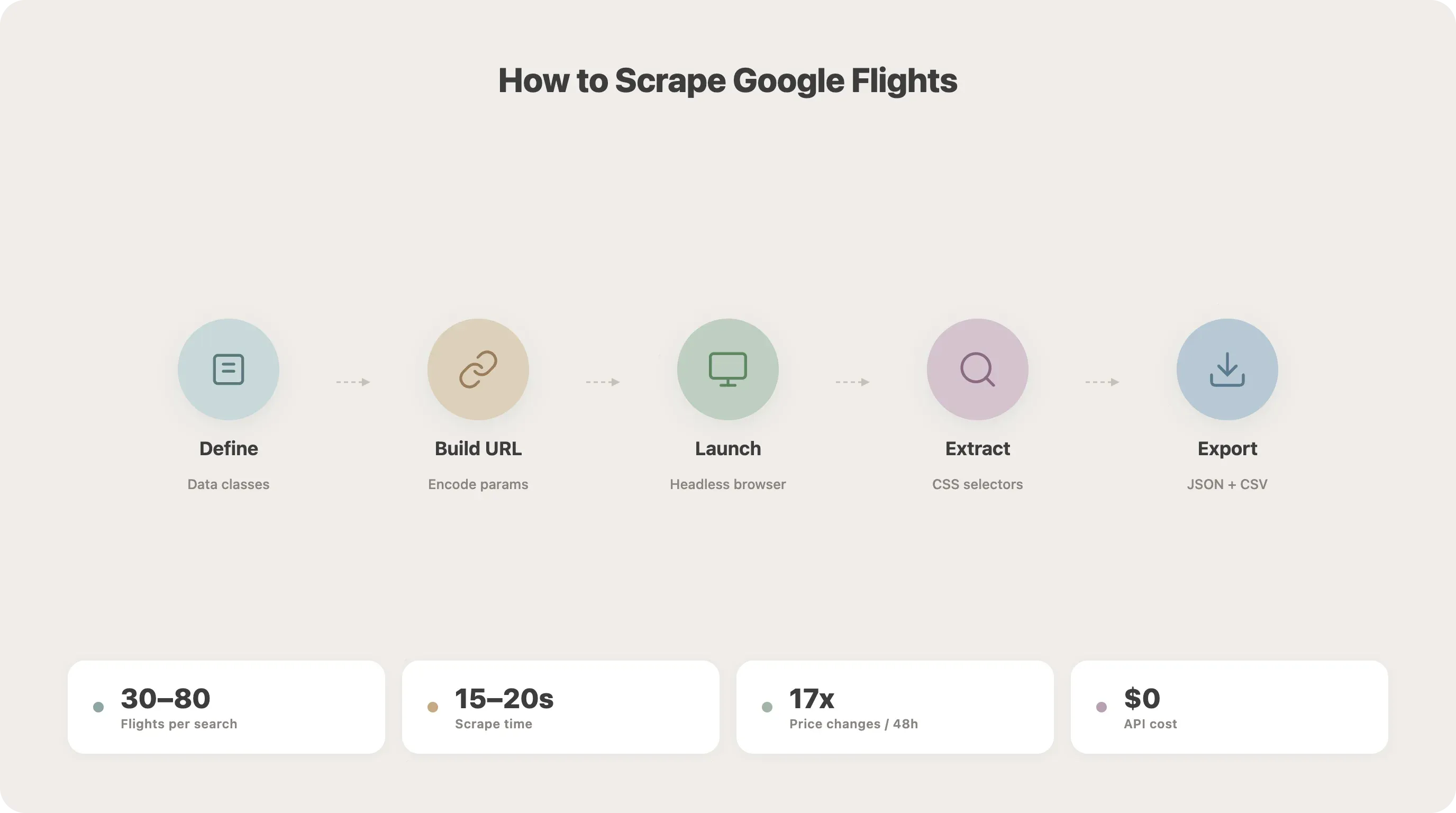
Stap 1: Definieer je dataclasses
Begin met het structureren van je zoekparameters en vluchtgegevens met Python dataclasses. Dat houdt alles netjes en maakt het later makkelijker om uit te breiden.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # bijvoorbeeld "SFO"
6 destination: str # bijvoorbeeld "JFK"
7 departure_date: str # bijvoorbeeld "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" of "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""Elk veld sluit direct aan op wat we van de pagina gaan halen. Door deze structuur vooraf vast te leggen, hoef je later niet met rommelige dictionaries te werken.
Stap 2: Begrijp de URL-structuur van Google Flights
Google Flights encodeert zoekparameters via Base64-gecodeerde Protobuf in de tfs-URLparameter. Je kunt die encoding zelf reverse-engineeren, maar de eenvoudigere route is een zoek-URL in natuurlijke taal samenstellen.
De simpelste methode is de zoekopdracht in deze vorm:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDVoor meer controle kun je URL’s programmatisch opbouwen:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"De alternatieve aanpak — het Protobuf-formaat reverse-engineeren — geeft je preciezere controle, maar breekt zodra Google het interne formaat wijzigt. Libraries zoals op GitHub gebruiken Protobuf-decoding om HTML-parsing helemaal te omzeilen, maar dat is wel een geavanceerdere route.
Stap 3: Start de browser en ga naar Google Flights
Hier komt de Playwright-opzet. We gebruiken playwright-stealth om de detectiekans vanaf het begin te verkleinen.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Zet de cookie vooraf om de toestemmingspop-up over te slaan
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()We draaien headless voor productie (zet headless=False als je wilt debuggen), gebruiken een realistische viewport en user-agent, en zetten de SOCS-cookie vooraf klaar om de consent-pop-up over te slaan — daar komen we in het anti-botgedeelte op terug.
Stap 4: Navigeer naar de zoekresultaten
Laad de samengestelde URL en wacht tot de vluchtresultaten verschijnen:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Wacht tot de vluchtresultaten geladen zijn
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )Als je hier een timeout ziet, betekent dat meestal dat de consent-pop-up de pagina blokkeerde (zie de cookie-fix in stap 3) of dat Google een CAPTCHA toont. Beide gevallen behandelen we in het anti-botgedeelte.
Stap 5: Laad alle vluchtresultaten
Google Flights verstopt extra resultaten achter de knop "Show more flights". Je moet die steeds aanklikken tot alle vluchten zichtbaar zijn:
1 # Klik op "Show more flights" totdat alle resultaten geladen zijn
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakDeze lus klikt op de knop, wacht 2 seconden tot nieuwe resultaten zijn gerenderd en stopt zodra de knop niet meer zichtbaar is. In mijn tests hebben de meeste routes 1–3 resultaatpagina’s.
Stap 6: Extraheer vluchtgegevens met CSS-selectors
Nu parseren we de daadwerkelijke vluchtgegevens van de geladen pagina. Dit zijn de selectors (geverifieerd in april 2026 — zie het onderhoudsgedeelte hieronder voor waarom die datum belangrijk is):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Naam van de luchtvaartmaatschappij
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Vertrektijd
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Aankomsttijd
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Duur
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Tussenstops
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Prijs
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2-uitstoot
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flightsWaarschuwing: classnamen zoals pIav2d, sSHqwe en FpEdX worden gegenereerd door Google’s Closure Compiler en kunnen bij elke build veranderen. De aria-label-selectors zijn stabieler. Hieronder leg ik een onderhoudsstrategie uit.
Stap 7: Sla de resultaten op als JSON of CSV
Sla de gescrapete data tenslotte op met een tijdstempel (cruciaal voor prijsmonitoring later):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Ook opslaan als CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())Voer dit uit en je zou een flights.json en flights.csv met je resultaten moeten zien. In mijn tests levert een SFO-JFK-zoekopdracht doorgaans 30–80 vluchtopties op en duurt het ongeveer 15–20 seconden.
De anti-bot survival guide voor Google Flights scrapen
De meeste tutorials stoppen hier. De meeste scrapers falen hier. Google rolde uit, waardoor bijna elke SERP-scraper van de ene op de andere dag stukging. Google omschrijft het als "the product of tens of thousands of person hours and millions of dollars of investment." Google Flights krijgt een voor scraping.
Geen enkel concurrerend artikel gaat hier diep op in, terwijl dit precies de belangrijkste reden is waarom scrapers stoppen met werken. Dit is waar je tegenaan loopt en hoe je ermee omgaat.

Willekeurige vertragingen tussen verzoeken
De simpelste verdediging tegen rate limiting. Twee regels code, middelmatige effectiviteit:
1import time
2import random
3time.sleep(random.uniform(3, 7))Plaats dit tussen paginanavigaties. Vaste intervallen (zoals exact elke keer 5 seconden) vallen op — randomiseer dus.
User-agent rotatie
Elke keer dezelfde user-agent meesturen is een makkelijk herkenningspunt. Wissel af uit een lijst:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)Omzeilen van headless-detectie
Google controleert de navigator.webdriver-flag en andere automatiseringssignalen. De playwright-stealth-bibliotheek vangt het meeste hiervan af, maar je moet ook de launch-argumenten uit stap 3 gebruiken. De belangrijkste flags:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]Daarmee omzeil je de basisdetectie. SearchGuard gaat verder — het monitort muissnelheid, toetsinterval en scrollpatronen — maar voor scrapes met beperkt volume is stealth-modus plus realistische vertragingen meestal voldoende.
Proxyrotatie: datacenter versus residential
Voor meer dan een handvol zoekopdrachten heb je proxies nodig. Het verschil maakt echt uit:
Residential proxies zijn ongeveer bij het scrapen van beveiligde websites. Prijzen in 2026: Smartproxy vanaf $7/GB, Bright Data $8,40/GB, Oxylabs $8/GB.
Zo voeg je een proxy toe aan Playwright:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Omgaan met cookie-consent pop-ups
Gebruikers noemen de "I agree to terms"-pop-up steevast als blokkade: "first google will show you the 'I agree to terms and conditions' popup." De netste oplossing is de SOCS-cookie vooraf instellen (zoals in stap 3). Als dat niet werkt, klik je erdoorheen:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # Geen pop-up aanwezigLet op: de knoptekst verschilt per taal — "Alle akzeptieren" in het Duits, "Tout accepter" in het Frans.
Snelle anti-bot referentie
| Techniek | Moeilijkheid | Effectiviteit | Code nodig? |
|---|---|---|---|
| Willekeurige vertragingen (2–7s) | Laag | Middelmatig | 2 regels |
| User-agent rotatie | Laag | Middelmatig | 5 regels |
| Omzeilen van headless-detectie | Gemiddeld | Hoog | Playwright launch-args |
| playwright-stealth plugin | Gemiddeld | 60–80% op simpele sites | pip install |
| Proxyrotatie (datacenter) | Gemiddeld | Middelmatig | Config |
| Proxyrotatie (residential) | Gemiddeld | 85–95% succes | Config |
| Cookie-consent vooraf instellen (SOCS) | Laag | Vereist | 1 regel |
Voor aanbevolen veilige snelheden: houd 10–20 seconden vertraging tussen verzoeken aan met IP-rotatie. Google’s drempels liggen grofweg rond 100 verzoeken per minuut per IP voordat je een 429 krijgt, en aanhoudend meer dan 1.000 verzoeken per dag per IP kan tijdelijke bans uitlokken.
Waarom je Google Flights-selectors blijven breken (en hoe je dat oplost)
Veruit het grootste pijnpunt. Forumtopics zitten vol varianten op "all I get back is 14 empty lists." Elke tutorial geeft je selectors. Geen enkele legt uit waarom ze breken.
Waarom Google Flights-selectors veranderen
Dat komt door drie dingen:
-
Obfuscatie door Closure Compiler. Google gebruikt om via
goog.setCssNameMapping()classnamen zoalsBVAVmfenYMlIzte genereren. Die veranderen bij elke build — soms zelfs wekelijks. -
A/B-testen. Verschillende gebruikers zien tegelijk verschillende HTML-structuren. Jouw scraper kan op jouw machine werken, maar falen voor iemand in een andere regio.
-
Lokale verschillen. Gebruikers in de EU zien andere termen, lay-outs en zelfs andere databronnen dan gebruikers in de VS.
Schrijf robuuste selectors
Geef de voorkeur aan selectors die op betekenis zijn gebaseerd in plaats van op uiterlijk:
1# Breekbaar — valt bij elke build om
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# Robuuster — gekoppeld aan toegankelijkheidslabels
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Ook robuust — tekstgebaseerde match
6more_btn = page.locator('button:has-text("Show more flights")')Volgorde van selector-stabiliteit (van meest naar minst stabiel):
aria-label-attributen — gekoppeld aan toegankelijkheid, zelden gewijzigddata-*-attributen — expliciet toegevoegd voor functionaliteitrole-attributen — ARIA-rollen zijn semantisch- Tekstgebaseerde selectors — matchen zichtbare content
- Substring class matching — bijvoorbeeld
[class*="price"] - Volledige geobfusceerde classnamen — vermijd deze waar mogelijk
Voeg een validatiefunctie toe
Laat kapotte selectors niet stilletjes lege output opleveren. Vang dat vroegtijdig op:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Missing '{field_name}' — selectors may need updating"
11 )
12 valid = False
13 return validVoer dit uit voor elke gescrapete vlucht. Als je waarschuwingen ziet verschijnen, is het tijd om de pagina te inspecteren en je selectors bij te werken.
Strategie voor selector-onderhoud
- Controleer selectors maandelijks, of direct zodra de outputkwaliteit daalt
- Houd selectors in een aparte configuratie-dictionary zodat updates makkelijk zijn
- Selectors in dit artikel zijn voor het laatst যাচificeerd: april 2026
- Overweeg de als alternatief — die gebruikt Protobuf-decoding in plaats van CSS-selectors en omzeilt dit probleem volledig (al blijft er fragiliteit bestaan wanneer Google het interne datamodel wijzigt)
Van eenmalige scrape naar een geautomatiseerde Google Flights-prijsmonitor
De meeste tutorials eindigen bij "sla op als JSON." De titel van dit artikel noemt echter "Price Alerts." Tijd om dat waar te maken.
![]()
Plan je scraper om automatisch te draaien
Optie 1: Python schedule-bibliotheek (simpelst, platformonafhankelijk):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)Optie 2: cron-job (Linux/Mac):
1# Draai dagelijks om 6:00 en 18:00
20 6,18 * * * cd /path/to/scraper && python scraper.pyOptie 3: Windows Taakplanner — maak een basis-taak aan die python scraper.py uitvoert volgens je gewenste schema.
Nadeel: dit vereist allemaal een machine die altijd aan staat. Als je dit op een laptop draait die in slaapstand gaat, mis je scrapes.
Sla historische prijsdata op
Stap over van een JSON-bestand overschrijven naar het bijhouden van een SQLite-database:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()Na een week met twee scrapes per dag heb je genoeg data om trends te herkennen.
Analyseer prijsontwikkelingen en stel alerts in
Vind de goedkoopste optie in je historische data:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Cheapest: ${cheapest['price_usd']:.0f} on "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)Stuur een e-mailwaarschuwing zodra een prijs onder je drempel zakt:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Price drop alert! {route}: ${price:.0f} "
6 f"(below your ${threshold:.0f} threshold)"
7 )
8 msg["Subject"] = f"Flight Deal: {route} at ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# Controleer na elke scrape op deals
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")Aanbevolen scrape-frequentie: twee keer per dag is voldoende voor persoonlijk prijsvolgen (willekeurige tijdstippen verlagen de detectiekans). Voor zakelijk gebruik kun je elke 4–6 uur monitoren. Elk uur alleen tijdens tijdelijke uitverkoopacties, en alleen tijdelijk.
De makkelijke route: Thunderbit’s Scheduled Scraper
Als cronjobs, een altijd draaiende server en proxyconfiguraties je meer infrastructuur lijken dan je wilt onderhouden, dan pakt Scheduled Scraper hetzelfde use case aan zonder die extra last. Je beschrijft het scrape-interval in gewone taal, voert je Google Flights-URL’s in, en de scraper draait automatisch op Thunderbit’s cloudinfrastructuur — met ingebouwde anti-botafhandeling en export rechtstreeks naar . Het is geen vervanging voor de volledige Python-aanpak (je levert aan flexibiliteit in), maar voor het specifieke doel "ik wil een spreadsheet met prijsmonitoring" is dit de snelste route. Je kunt het proberen via de .
Wanneer Python te zwaar is: no-code manieren om Google Flights te scrapen
Na alles wat hierboven staat, zeg ik eerlijk: het is best wat om te beheren. Niet iedereen heeft dit niveau van controle nodig. Selectors breken, proxies moeten roteren, cronjobs moeten bewaakt worden. Als je doel gewoon is: "vluchtprijzen regelmatig in een spreadsheet krijgen," dan zijn er snellere opties.
Vergelijking: zelf bouwen in Python vs. API-diensten vs. Thunderbit
| Aanpak | Insteltijd | Code nodig | Anti-bot afhandeling | Planning | Kosten |
|---|---|---|---|---|---|
| Zelfbouw met Playwright (deze tutorial) | 1–2 uur | Python (gemiddeld) | Handmatige configuratie | Handmatig (cron) | Gratis + proxykosten |
| SerpApi Google Flights endpoint | 15 min | Alleen API-calls | Afgehandeld | Via API | ~$50+/maand |
| Thunderbit Chrome-extensie | 2 min | Geen | Cloud scraping | Ingebouwde planner | Gratis plan beschikbaar |
Een kanttekening bij SerpApi: Google , met de beschuldiging dat hun verzoeken in twee jaar tijd met 25.000% waren gestegen. Die juridische onzekerheid is het overwegen waard als je API-providers vergelijkt.
Hoe Thunderbit Google Flights scrapt
Open je Google Flights-resultaten in Chrome, klik op Thunderbit’s knop "AI Suggest Fields" — de AI leest de pagina en stelt kolommen voor zoals airline, price, departure time en stops — controleer de voorgestelde velden en klik op "Scrape." De resultaten verschijnen in een tabel die je kunt exporteren naar Excel, Google Sheets, Airtable of Notion — allemaal binnen het .
Voor prijsmonitoring vervangt Thunderbit’s Scheduled Scraper en (dat 50 pagina’s gelijktijdig aankan) de volledige cron-, proxy- en serverinfrastructuur.
Python geeft je volledige controle en oneindige maatwerkopties. Thunderbit geeft je snelheid en geen onderhoud. Kies op basis van je echte doel. Als je meer wilt weten over no-code scraping, bekijk dan onze gids over de .

Is Google Flights scrapen legaal? Dit moet je weten
Forumgebruikers vragen dit vaak: "scraping Google Flights directly violates the TOS that Google has." Begrijpelijke zorg — zeker omdat de API is stopgezet en er geen officieel alternatief is.
Schending van de gebruiksvoorwaarden vs. juridische aansprakelijkheid
Google’s Terms of Service (bijgewerkt op 22 mei 2024) zeggen dat gebruikers de Services of content niet mogen "access or use ... through the use of any automated means (such as robots, spiders or scrapers)." Het schenden van de ToS is een contractbreuk (civiele kwestie) — dat is niet hetzelfde als de wet overtreden.
Het belangrijkste juridische precedent: hiQ v. LinkedIn (Ninth Circuit, 2022) stelde dat het scrapen van publiek beschikbare data de Computer Fraud and Abuse Act (CFAA) niet schendt. De zaak eindigde echter in een schikking, en Google’s rechtszaak tegen SerpApi uit december 2025 gebruikt een andere juridische redenering — DMCA Section 1201 (het omzeilen van technische beschermingsmaatregelen) — en die kan ernstiger uitpakken.
Best practices voor verantwoord scrapen
- Beperk je request-rate — 10–20 seconden vertraging met IP-rotatie
- Scrape geen persoonlijke data — vluchtprijzen zijn publiek zichtbare geaggregeerde data
- Omzeil CAPTCHA’s niet programmatisch (hier zit het DMCA-risico)
- Gebruik de data voor eigen onderzoek, niet om zonder licentie een concurrerend commercieel product te bouwen
- Overweeg officiële API’s waar beschikbaar
Alternatieve databronnen
Als scrapen voor jouw use case te riskant voelt, zijn er legitieme API-opties:
| Provider | Kosten | Gratis plan | Opmerkingen |
|---|---|---|---|
| SerpApi | $75–$3.750+/maand | 250 zoekopdrachten/maand | Directe Google Flights JSON (onder juridische aandacht) |
| Kiwi Tequila | Gratis (affiliate-model) | Onbeperkt | Goed voor startups en tests |
| Amadeus | Pay-as-you-go | 2.000 req/maand | 400+ luchtvaartmaatschappijen, boekingsmogelijkheden |
| Skyscanner | Maatwerk | Toestemming vereist | 52 markten, 30 talen |
We schreven ook een diepere uitleg over als je het volledige plaatje wilt.
Conclusie en belangrijkste inzichten
Dat was veel. Dit zijn de kernpunten:
- Python + Playwright is de meest flexibele aanpak voor Google Flights scrapen, maar vereist doorlopend onderhoud
- Anti-botmaatregelen (vertragingen, user-agent rotatie, residential proxies) zijn niet optioneel — ze zijn essentieel voor betrouwbaarheid, zeker na SearchGuard
- Selectors breken vaak — gebruik waar mogelijk
aria-labelen tekstgebaseerde selectors, valideer je output en plan onderhoud in - Automatiseer met
scheduleof cron om van een eenmalige scrape een echte prijsmonitor met historische data en e-mailalerts te maken - biedt een no-code alternatief met ingebouwde planning, cloud scraping en anti-botafhandeling — ideaal als je doel een prijsmonitor-spreadsheet is in plaats van een codeproject
- Respecteer de juridische grenzen — beperk je request-rate, scrape alleen openbare data en overweeg API-alternatieven voor commercieel gebruik
Pak de code uit deze tutorial, of installeer de als je snel aan de slag wilt. Hoe dan ook, je houdt straks vluchtprijzen bij in plaats van Google Flights handmatig te verversen.
Voor meer Python-scrapingtechnieken, bekijk onze gidsen over en de .
Veelgestelde vragen
1. Kan ik Google Flights scrapen zonder Python?
Ja. API-diensten zoals SerpApi en Kiwi Tequila leveren gestructureerde vluchtdata via API-calls (dus zonder browserautomatisering). Voor een volledig no-code aanpak kan de Google Flights-resultaten direct uit je browser scrapen met door AI voorgestelde velden en export met één klik.
2. Blokkeert Google vlucht-scraping?
Google gebruikt botdetectie (SearchGuard), CAPTCHA’s en rate limiting. Met goede anti-botmaatregelen — willekeurige vertragingen, user-agent rotatie, residential proxies en stealth browser-instellingen — kun je op middelgrote schaal betrouwbaar scrapen. Zie het anti-botgedeelte hierboven voor concrete technieken en drempels.
3. Hoe vaak moet ik Google Flights scrapen voor prijsmonitoring?
Twee keer per dag (op willekeurige tijdstippen) is voldoende voor persoonlijk prijsvolgen en houdt het detectierisico laag. Voor zakelijke monitoring kun je elke 4–6 uur scrapen met proxyrotatie. Vermijd uurlijkse scrapes, behalve bij kortlopende prijsacties — de kans op blokkades neemt dan sterk toe.
4. Is er een gratis Google Flights API?
De officiële Google QPX Express API is . Er is geen gratis officiële vervanger. De dichtstbijzijnde gratis optie is de (affiliate-model, onbeperkt zoeken). SerpApi biedt 250 gratis zoekopdrachten per maand. Voor de meeste gebruikers is scrapen of een no-code tool zoals Thunderbit de praktische route.
5. Waarom leveren mijn Google Flights CSS-selectors steeds lege data op?
Google gebruikt Closure Compiler om geobfusceerde classnamen te genereren die bij elke build veranderen. Ook A/B-testen en localeverschillen zorgen ervoor dat de HTML-structuur per gebruiker kan verschillen. De oplossing: gebruik aria-label-attributen en tekstgebaseerde selectors in plaats van classnamen, voeg een validatiefunctie toe om breuken vroeg te detecteren, en controleer je selectors maandelijks. Zie het onderhoudsgedeelte voor een gedetailleerde strategie.
Meer lezen