Als jouw Glassdoor-scraper in 2022 nog prima werkte en nu alleen nog maar 403-fouten teruggeeft, ben je echt niet de enige. Op fora verschijnt steeds weer dezelfde vraag: "Weet iemand waarom deze scraper niet meer werkt?"
Het korte antwoord: Glassdoor heeft alles volledig omgegooid. Recruit Holdings nam Glassdoor in juli 2025 op in Indeed, ontsloeg en zette de anti-botbeveiliging zo strak aan dat gewone Selenium- en requests-scrapers al worden geblokkeerd voordat de eerste byte HTML geladen is. Sinds februari 2026 lopen Glassdoor-logins helemaal via Indeed Login — dus elke handleiding die nog uitgaat van een Glassdoor-specifiek inlogformulier is vanaf de basis al achterhaald. Tegelijkertijd bevat het platform nog altijd van . Die data is enorm waardevol voor HR-benchmarking, concurrentieanalyse en sales prospecting — als je er tenminste bij kunt. Deze gids is de versie die werkt ná al die veranderingen, en behandelt alle drie Glassdoor-datatypeen (vacatures, reviews én salarissen) op één plek. Ik laat je de Python-aanpak zien met werkende code voor 2025, leg precies uit wat je blokkeert en hoe je daar omheen komt, en toon een no-code alternatief voor iedereen die liever helemaal geen engineering doet.
Waarom Glassdoor scrapen met Python in 2025?
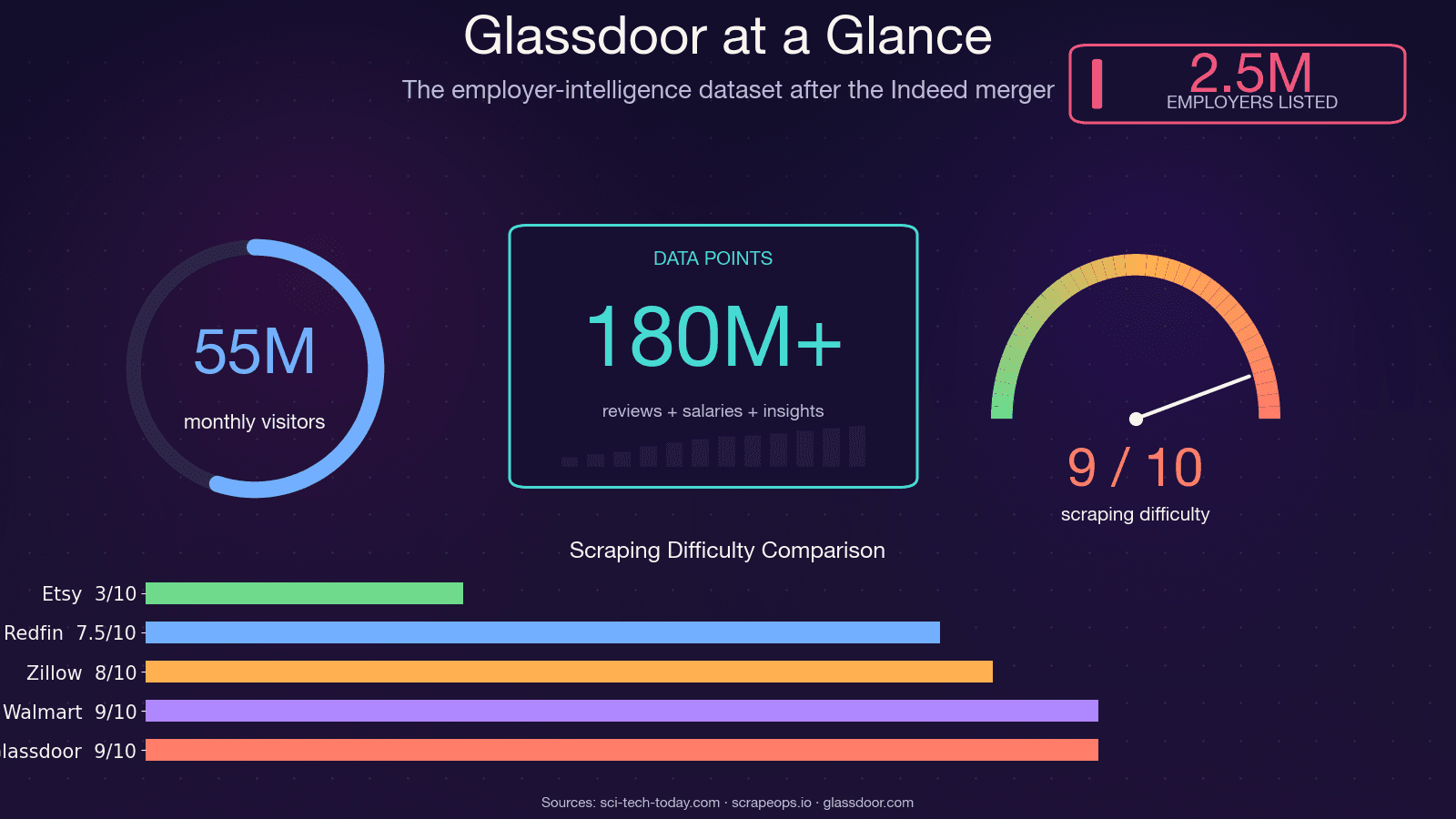
Glassdoor is niet zomaar een vacaturebank. Het is een van de rijkste datasets voor werkgeversinzichten op het web — gebruikt door ongeveer en goed voor zo’n 55 miljoen unieke bezoekers per maand. De data achter die pagina’s stuurt echte zakelijke beslissingen binnen meerdere teams.
Zo gebruiken verschillende teams Glassdoor-data in de praktijk:
| Use case | Benodigde data | Wie profiteert |
|---|---|---|
| Salarisbenchmarking | Salarisverdelingen, steekproefgroottes | HR, Total Rewards, Operations |
| Concurrentieanalyse van werving | Vacatures, plaatsingsfrequentie | Sales, Strategy, VC/Corp Dev |
| Monitoring van employer branding | Reviewtekst, ratingtrends, CEO-goedkeuring | HR, Marketing, Communicatie |
| Leadgeneratie (groeiende bedrijven) | Vacatures + bedrijfsinformatie | Sales teams, SDR's |
| Markt- en academisch onderzoek | Alle drie | Analisten, consultants, onderzoekers |
Toen het BLS tijdens de Amerikaanse overheidsshutdown van oktober 2025 geen arbeidsmarktcijfers kon publiceren, bracht Glassdoors eigen Economic Research-team op basis van hun dataset. Zó serieus nemen institutionele analisten deze data inmiddels.
Python blijft de standaardkeuze omdat het ecosysteem simpelweg ongeëvenaard is — Playwright voor browserautomatisering, parsel/lxml voor parsing, curl_cffi voor het omzeilen van TLS-fingerprints en een enorme community die werkende patronen deelt. Het probleem is niet Python. Het probleem is dat Glassdoor een stuk lastiger te scrapen is geworden.
Als je een no-code alternatief zoekt voor het extraheren van Glassdoor-data, kan Thunderbit je helpen vacatures, reviews en salaris-pagina’s te scrapen zonder een eigen Python-stack op te zetten en te onderhouden.
Welke Glassdoor-data kun je eigenlijk scrapen?
De meeste handleidingen behandelen alleen vacatures. Maar op basis van forumthreads, GitHub-issues en Reddit-vragen die ik heb gevolgd, is de vraag het grootst voor de twee datatypes die bijna niemand uitlegt: reviews en salarissen. Hieronder zie je wat je uit alle drie de categorieën kunt halen.
Vacatures
Het meest toegankelijk. Je kunt ophalen: functietitel, bedrijfsnaam, locatie, salarisschatting, bedrijfsbeoordeling, plaatsingsdatum, easy-apply-badge en de vacaturelink. Vacatures zijn gedeeltelijk beschikbaar zonder in te loggen, al kan Glassdoor na een aantal pagina’s een login-popup tonen.
Bedrijfsreviews
Hier wordt employer-brandanalyse echt interessant. Velden die je kunt extraheren zijn onder andere: overall rating, sub-ratings (work-life balance, cultuur & waarden, diversiteit & inclusie, doorgroeimogelijkheden, beloning & voordelen, senior management), pros-tekst, cons-tekst, functietitel van de reviewer, reviewedatum en dienstverbandstatus. De volledige reviewtekst zit achter een login — je ziet wel een samenvatting, maar voor de volledige pros/cons is authenticatie nodig.
Salarisgegevens
Het meest gevraagde én het meest frustrerende datatype. Je kunt ophalen: functietitel, basissalarisrange, totale compensatierange, aantal salarisrapporten en locatie. Maar salarispagina’s zijn volledig afgeschermd achter login, en Glassdoor gebruikt soms ook nog een "bijdragen om te ontgrendelen"-flow waarbij je eerst je eigen salaris moet invoeren voordat je anderen ziet. Geen enkele concurrerende handleiding geeft hier werkende code voor — dat lossen we hier op.
Wat vereist inloggen en wat niet?
Deze tabel voorkomt dat je op de harde manier ontdekt welke pagina’s leeg terugkomen:
| Datatype | Beschikbaar zonder login? | Opmerking |
|---|---|---|
| Vacaturtitels & basisinformatie | Meestal wel | Na enkele pagina’s kan een popup verschijnen |
| Volledige vacaturebeschrijvingen | Gedeeltelijk | Vaak afgeschermd na 2–3 weergaven |
| Bedrijfsreviews (volledige tekst) | Nee — login vereist | Samenvatting zichtbaar, volledige tekst afgeschermd |
| Salarisgegevens | Nee — login vereist | Mogelijk ook "contribute to unlock" vereist |
Waarom je oude Glassdoor-scraper waarschijnlijk kapot is
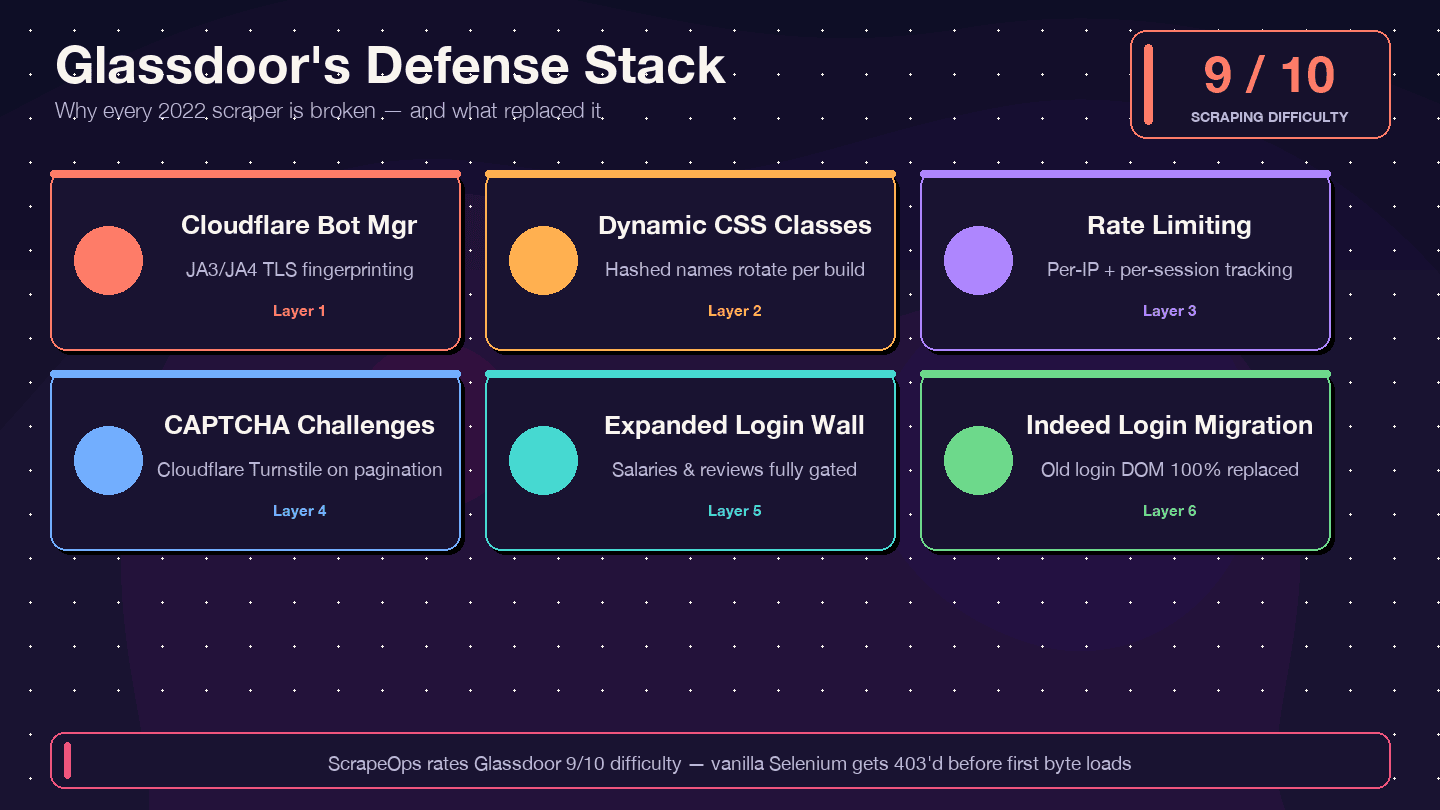
Ik wil hier duidelijk over zijn: als je code uit een handleiding van 2021–2023 kopieert, gaat die niet werken. De legacy Glassdoor Selenium-scraper met de meeste sterren op GitHub (, ongeveer 1,4k sterren) heeft 12+ open, onopgeloste issues — waaronder "Glassdoor new UI design," "Cloudflare anti-bot protection" en "NoSuchElementException." De repo is in de praktijk verlaten. . en 8/10 voor het omzeilen van de beveiliging.
Dit is er veranderd en waarom oude code stukloopt:
| Verdedigingslaag | Wat er veranderde | Impact op oude scrapers |
|---|---|---|
| Cloudflare Bot Management | Strengere JA3/JA4-fingerprinting sinds 2024 | Basis requests/Selenium-scripts krijgen direct 403 |
| Dynamische CSS-klassennamen | Klassennamen worden bij elke build gerandomiseerd | Oude CSS-selectors uit tutorials werken stilletjes niet meer |
| Rate limiting + sessietracking | Strengere limieten per IP en per sessie | Scrapers raken sneller geblokkeerd |
| CAPTCHA-uitdagingen (waarschijnlijk Cloudflare Turnstile) | Vaker, vooral tijdens paginering | Headless browsers triggeren uitdagingen |
| Uitgebreidere login wall | Meer paginatypes vereisen authenticatie | Salaris- en reviewpagina’s geven lege data terug |
| Migratie naar Indeed Login (feb 2026) | Glassdoor-loginformulier volledig vervangen | Code die het oude login-DOM target is dood |
bevat een expliciete waarschuwing: "Glassdoor is known for its high blocking rate, so if you get None values while running the Python code, it's likely you're getting blocked." En een zegt het nog directer: "Simple HTTP requests with requests or httpx get blocked instantly."
De tegenmaatregelen die ik hier laat zien — Patchright (een stealth-fork van Playwright), selectors op basis van data-test-attributen, roterende residential proxies en geauthenticeerde persistente sessies — zijn specifiek ontworpen om met al deze lagen om te gaan.
Glassdoor API versus Python-scraping: kies eerst de juiste aanpak
In meerdere forumthreads wordt gevraagd: "Moet ik dan gewoon de Glassdoor API gebruiken?" — en het antwoord is: dat kan niet.
De . Het developerportal bestaat technisch gezien nog wel, maar . Er is nooit een publieke reviews-endpoint geweest — de scraper van MatthewChatham is juist gebouwd "omdat Glassdoor geen API voor reviews heeft." En onder Indeed’s Publisher API bestaat geen migratiepad voor reviews of salarissen.
Hier is de eerlijke vergelijking:
| Factor | Glassdoor Partner API v1 | Python-scraping | Thunderbit (no-code) |
|---|---|---|---|
| Toegang | Gesloten voor nieuwe aanmeldingen | Open (zelf implementeren) | Chrome-extensie |
| Vacatures | Beperkt/afgebouwd | Beschikbaar met moeite | Beschikbaar |
| Bedrijfsreviews | Nooit publiek beschikbaar geweest | Ja (login nodig) | Ja (via Browser Mode) |
| Salarisgegevens | Nooit publiek beschikbaar geweest | Ja (login nodig) | Ja |
| Rate limits | Niet gedocumenteerd | Jij bepaalt het tempo | Op credits gebaseerd |
| Setup-inspanning | Geen nieuwe apps te registreren | Uren tot dagen | ~2 minuten |
| Onderhoudslast | N.v.t. | Hoog (HTML-wijzigingen breken code) | Laag (AI stelt velden opnieuw voor) |
Als je reviews of salarisgegevens nodig hebt — en de meeste lezers hebben dat — dan is Python-scraping of een no-code tool je enige realistische optie.
Voordat je begint
- Moeilijkheidsgraad: Gemiddeld (je moet comfortabel zijn met Python en de terminal)
- Benodigde tijd: ~30–60 minuten voor de volledige setup; daarna ~10 minuten per datatype
- Wat je nodig hebt:
- Python 3.10+ (3.11 of 3.12 aanbevolen)
- Chrome-browser geïnstalleerd
- Een Glassdoor-account (gratis — nodig voor salaris- en reviewdata)
- Roterende residential proxies (voor meer dan een handvol pagina’s)
- Optioneel: als je de no-code route wilt
Tools en libraries voor Glassdoor scrapen met Python in 2025
Het toolinglandschap is flink veranderd. Dit is wat tegenwoordig echt werkt tegen Glassdoor’s huidige beveiliging.
Waarom Patchright de beste keuze is voor Glassdoor
is een stealth-fork van Playwright die de Runtime.Enable CDP-leak patcht — precies de technische reden waarom vanilla Playwright faalt op sites die door Cloudflare worden beschermd. Het gebruikt exact dezelfde API als Playwright, dus als je Playwright kent, kun je ook met Patchright uit de voeten. Versie 1.58.2 (maart 2026) is actueel en wordt actief onderhouden.
Vergeleken met alternatieven:
- Vanilla Playwright: Wordt op Glassdoor’s loginpagina gedetecteerd door de Runtime.Enable-leak
- Selenium + undetected-chromedriver: De laatste release van undetected-chromedriver was in februari 2024 — feitelijk legacy. vond dat het "failed on every domain in our test"
- requests + BeautifulSoup: Kan geen JavaScript renderen en wordt meteen geblokkeerd door Cloudflare’s TLS-fingerprinting
- : Uitstekend voor de snelle route (10–20x sneller dan een browser) wanneer pagina’s
__NEXT_DATA__in de initiële HTML meesturen, maar niet geschikt voor login of tussenliggende uitdagingen
Ondersteunende libraries
- parsel (1.11.0) of lxml (6.0.4): snelle HTML/XPath-parsing
- csv of pandas: export van data
- asyncio: async scraping voor snellere paginering
Proxies: alleen residential
Glassdoor’s Cloudflare-laag daagt datacenter-ASN’s agressief uit. . Instapprijzen liggen rond (promotie) of $3,00/GB bij . Voor productie-scraping moet je rekenen op $3–8/GB, afhankelijk van volume.
Willekeurige vertragingen tussen requests (minimaal 3–8 seconden, 5–15 seconden bij langere runs) zijn essentieel, ongeacht de proxykwaliteit.
Stap 1: zet je Python-omgeving op
Maak je projectmap aan en installeer de aanbevolen stack:
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# Core stack
6pip install patchright==1.58.2 parsel==1.11.0
7# Browserbinaries installeren
8patchright install chromium
9# Optioneel: snelle route voor __NEXT_DATA__-extractie
10pip install "curl_cffi==0.15.0"Je zou Patchright een Chromium-binary moeten zien downloaden. Als patchright install chromium faalt, controleer dan of je genoeg schijfruimte hebt (~300MB) en of je Python-versie 3.10+ is.
Stap 2: start Patchright en ga naar Glassdoor
Hier is het basispatroon dat werkt tegen Glassdoor’s Cloudflare-laag:
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # headless is nog steeds makkelijker te detecteren
6 channel="chrome", # gebruik echte Chrome, niet de meegeleverde Chromium
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # Sluit de login-overlay — de content staat nog steeds in de DOM
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("Pagina geladen — vacatures zichtbaar.")Een paar dingen om op te merken. De channel="chrome"-vlag vertelt Patchright om jouw geïnstalleerde Chrome-binary te gebruiken in plaats van de meegeleverde Chromium — dat levert een authentiekere browserfingerprint op. De add_style_tag-truc verbergt Glassdoor’s loginmodal (genaamd #HardsellOverlay) zonder iets aan te klikken. dat "all of the content is still there, it's just covered up by the overlay" — de HTML bevat de data dus gewoon, ook als de modal zichtbaar is.
Je zou nu een Chrome-venster moeten zien dat naar de Glassdoor-jobzoekpagina navigeert en vacaturekaarten toont zonder dat de login-popup in de weg zit.
Stap 3: Glassdoor-vacatures scrapen
Vind stabiele selectors
Glassdoor randomiseert CSS-klassennamen bij elke build — dus de .jobCard_xyz123-selector uit een tutorial van 2023 levert tegenwoordig stilletjes niets op. Gebruik daarom data-test-attributen; dat is Glassdoor’s interne QA-conventie en die blijven meestal stabiel tussen deploys.
Hier is de selectorreferentie voor vacaturevelden:
| Veld | Selector |
|---|---|
| Vacaturekaart-container | [data-test="jobListing"] |
| Functietitel | [data-test="job-title"] |
| Vacaturelink | a[data-test="job-link"] |
| Bedrijfsnaam | [data-test="employer-name"] |
| Locatie | [data-test="emp-location"] |
| Salarisrange | [data-test="detailSalary"] |
| Bedrijfsrating | [data-test="rating"] |
| Plaatsingsdatum | [data-test="job-age"] |
| Volgende pagina | [data-test="pagination-next"] |
Extraheer vacaturedata
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"Pagina {page_num}: geen kaarten gevonden — mogelijk een blokkade of gewijzigde selector.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"Pagina {page_num}: {len(cards)} vacatures gescrapet")
26 # Paginering
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsOpslaan naar CSV
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("Geen vacatures om op te slaan.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"{len(jobs)} vacatures opgeslagen in {filename}")Een opmerking over paginering: Glassdoor beperkt zoekresultaten tot ongeveer 30 pagina’s, ongeacht de totale aantallen. Als je meer dekking nodig hebt, gebruik dan filters (locatie, functietype, salarisrange) om elke zoekopdracht te verfijnen in plaats van door de limiet heen te proberen te bladeren.
In mijn tests kostte het scrapen van 5 pagina’s vacatureoverzichten (ongeveer 75 vacatures) met willekeurige vertragingen zo’n 45 seconden. Handmatig zou hetzelfde minimaal 20 minuten copy-pasten kosten.
Stap 4: Glassdoor-bedrijfsreviews scrapen
Dit is het gedeelte waarvoor geen enkele andere handleiding werkende code geeft. Reviews zijn waar de échte employer intelligence zit — sentimentanalyse, cultuursignalen, management-waarschuwingen.
Ga naar de reviewpagina
Review-URL’s volgen dit patroon: /Reviews/{Company}-Reviews-E{id}.htm. Je kunt het employer-ID vinden door op Glassdoor naar een bedrijf te zoeken en de URL te bekijken.
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)De verborgen BFF-endpoint (de schoonste route)
Dit is de belangrijkste ontdekking uit mijn onderzoek: Glassdoor-reviews hebben een werkende interne JSON API die HTML-parsing volledig omzeilt. De documenteert dit endpoint, en het is veel betrouwbaarder dan DOM-scraping.
1import json, re, requests
2def get_review_ids(page):
3 """Extraheer employerId en dynamicProfileId uit de HTML van de reviewpagina."""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Roep Glassdoor's interne BFF-endpoint aan voor gestructureerde reviewdata."""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF gaf {resp.status_code} terug op pagina {pg}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"Reviews-pagina {pg}/{total_pages}: {len(reviews)} reviews opgehaald")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsDe BFF-endpoint levert schone JSON met alle reviewvelden — geen HTML-parsing, geen brekende CSS-selectors. Je hebt wel sessiecookies nodig uit een geauthenticeerde Playwright-context (hieronder in Stap 6), en je moet eerst de employerId en dynamicProfileId uit de HTML van de reviewpagina halen.
HTML-fallback selectors voor reviews
Als de BFF-endpoint verandert of als je liever DOM-parsing gebruikt, dan zijn dit de stabiele data-test-selectors:
| Veld | Selector |
|---|---|
| Review-container | [data-test="review"] |
| Kopregel | [data-test="review-title"] |
| Overall rating | [data-test="overall-rating"] |
| Pros | [data-test="pros"] |
| Cons | [data-test="cons"] |
| Datum | [data-test="review-date"] |
| Functie van auteur | [data-test="author-jobTitle"] |
Stap 5: Glassdoor-salarisdata scrapen
Salarispagina’s zijn volledig afgeschermd achter login. Je moet dus eerst een geauthenticeerde sessie hebben (Stap 6) voordat deze code echte data teruggeeft.
Ga naar de salarispagina
Salaris-URL’s volgen dit patroon: /Salary/{Company}-Salaries-E{id}.htm, met paginering als _P{n}.htm.
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"Salarispagina {pg}: geen items — mogelijk loginblok of blokkade.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"Salarispagina {pg}: {len(items)} items gescrapet")
25 return all_salariesLet op het patroon [class*="SalaryItem_jobTitle__"]. Glassdoor gebruikt op de salarispagina CSS-module-hashes (bijv. SalaryItem_jobTitle__XWGpT) waarbij het hash-achtervoegsel bij elke deploy verandert. Het voorvoegsel blijft stabiel — de hash niet. Hardcode dus nooit de volledige classname.
Stap 6: kom voorbij Glassdoor’s login wall
Dit is het cruciale onderdeel waarmee je salarisdata en volledige reviewtekst ontsluit. De aanpak: log één keer handmatig in via een zichtbaar browservenster, sla de geauthenticeerde sessie op en hergebruik die daarna voor al je scraping-runs.
Sla je geauthenticeerde sessie op
Voer dit script één keer uit. Het opent een Chrome-venster, gaat naar Glassdoor’s loginpagina (die nu doorstuurt naar Indeed Login), en wacht tot jij handmatig inlogt:
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("Log in in het browservenster en druk daarna hier op Enter...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"Sessie opgeslagen in {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())Nadat je bent ingelogd en op Enter hebt gedrukt, slaat Patchright alle cookies en local storage op in glassdoor_state.json. Dit bestand bevat je gdId, GSESSIONID, cf_clearance en auth-tokens.
Hergebruik de sessie voor scraping
Bij elke volgende scraping-run laad je de opgeslagen state opnieuw — handmatig inloggen is dan niet meer nodig:
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return htmlDe opgeslagen sessie blijft doorgaans 20–30 minuten actief voordat Glassdoor opnieuw een challenge toont. Bouw voor langere runs daarom een controle in: als een pagina die data zou moeten hebben nul resultaten oplevert, log dan opnieuw in om je statebestand te verversen.
De login-popup detecteren en wegwerken
Voor gedeeltelijk afgeschermde pagina’s (vacatures met data achter een modal) werkt de CSS-injectie uit eerdere stappen prima:
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")Dat werkt alleen als de HTML onder de overlay de data al bevat. Voor volledig server-side afgeschermde pagina’s (salarissen, diepere reviewpagina’s) is de geauthenticeerde sessie uit Stap 6 de enige route.
Tips om je Glassdoor-scraper werkend te houden
Glassdoor wijzigt zijn frontend regelmatig. Zo bouw je veerkracht in je scraper.
Geef voorkeur aan data-test-attributen boven klassennamen
Glassdoor randomiseert CSS-klassennamen, maar laat data-test-attributen vaak stabiel. Gebruik altijd liever [data-test="jobListing"] dan .jobCard_abc123. Als data-test niet beschikbaar is (zoals bij salarisvelden), gebruik dan het prefix-match-patroon: [class*="SalaryItem_jobTitle__"].
Roteer proxies en randomiseer vertragingen
Gebruik roterende residential proxies — datacenter-IP’s worden vrijwel direct uitgedaagd. Voeg willekeurige vertragingen van 3–8 seconden toe tussen pagina’s (5–15 seconden bij langere runs). Scrapen buiten Amerikaanse kantooruren kan helpen, omdat Cloudflare’s gedragsdetectie dan vaak minder agressief is.
Houd breuken in de gaten
Bouw een eenvoudige controle in je scraper: als een pagina die data zou moeten bevatten nul records oplevert, behandel dat dan als een selectorfout (niet als een lege dataset) en stuur jezelf een melding. Draai wekelijks een kleine testscrape om problemen vroeg te ontdekken — Glassdoor rolt frontendwijzigingen uit zonder aankondiging.
Gebruik de __NEXT_DATA__-snelle route waar mogelijk
Glassdoor is een Next.js + Apollo GraphQL-app. Veel pagina’s leveren een <script id="__NEXT_DATA__">-tag mee met de volledige GraphQL-cache als JSON. Dat parseren is veel robuuster dan DOM-scraping en :
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return NoneDit geeft je de gestructureerde Apollo-cache met alle vacature-, review- en salarisvelden — zonder CSS-selectors. Het is de meest robuuste extractiestrategie die er is, omdat het exact dezelfde data is die Glassdoor’s React-frontend aandrijft.
Sla de code over: Glassdoor scrapen met Thunderbit (geen Python nodig)
Niet iedereen die dit leest is developer. HR-teams, recruiters, sales ops-analisten en marktonderzoekers hebben ook Glassdoor-data nodig — en die zouden geen Playwright-contexten en proxyrotatie hoeven beheren om die data te krijgen.
is een AI Web Scraper Chrome Extension die dezelfde vacatures-, review- en salarisdata kan extraheren zonder één regel code te schrijven. Ik werk zelf aan het Thunderbit-team, dus daar ben ik transparant over — maar de reden dat ik het hier noem is dat het werkelijk de twee lastigste problemen in Glassdoor-scraping oplost.
Hoe Thunderbit werkt op Glassdoor
De workflow bestaat uit twee klikken:
- Open een willekeurige Glassdoor-pagina in Chrome (job search, company reviews, salary page)
- Klik op AI Suggest Fields in de Thunderbit-sidebar — de AI leest de DOM van de pagina en stelt kolommen voor (functietitel, bedrijf, rating, salarisrange, pros, cons, enz.)
- Klik op Scrape — de data wordt naar een tabel gehaald zonder CSS-selectors of browserautomatisering code
Thunderbit heeft een die in één run meer dan 23 velden per bedrijf ophaalt. Voor vacatures, reviews of salarissen werkt de generieke AI Suggest Fields-flow met elke Glassdoor-URL.
De login wall zonder code verwerken
Dit is Thunderbit’s structurele voordeel specifiek voor Glassdoor. Browser Mode draait in je eigen Chrome-sessie — als je al bent ingelogd bij Glassdoor in Chrome, neemt Thunderbit die cookies automatisch over. De login wall voor salarissen en reviews die server-side scrapers blokkeert, speelt dan gewoon niet meer mee. Geen cookiebeheer, geen persistente contexten, geen sessiecode.
Subpage-scraping voor verrijking
Begin vanaf een lijstpagina (bijv. 30 bedrijven uit een zoekopdracht), laat Thunderbit de rijen uitlezen en zet daarna aan om per bedrijf de review- of salaris-pagina te bezoeken en de tabel te verrijken met volledige beschrijvingen, reviewtekst of salarisdetails.
Export naar business tools
In tegenstelling tot Python-scripts die CSV of JSON opleveren, exporteert Thunderbit direct naar Google Sheets, Airtable, Notion of Excel — gratis op elk plan. Vooral handig voor teams die data samen moeten delen en analyseren.
Python versus Thunderbit: wanneer gebruik je wat?
| Scenario | Aanbevolen aanpak |
|---|---|
| Een terugkerende datapijplijn bouwen | Python + Patchright |
| Eenmalig onderzoek of klein teamproject | Thunderbit |
| Programmatic controle over elk veld nodig | Python |
| Niet-developer die vandaag Glassdoor-data nodig heeft | Thunderbit |
| 1.000+ pagina’s in één run scrapen | Python + proxies |
| 30 bedrijven scrapen met verrijking | Beide werken — Thunderbit is sneller op te zetten |
Thunderbit begint gratis (6 pagina’s per maand), met het voor 3.000 credits. Met 1 credit per outputrij (2 credits voor subpage scraping) is dat genoeg voor ongeveer 33 runs van 30 verrijkte bedrijven per maand.
Is Glassdoor scrapen legaal?
Ik houd dit kort en feitelijk. Glassdoor’s verbieden geautomatiseerd scrapen expliciet: "You may not use any robot, spider, scraper... to access the Services for any purpose without our express written permission."
Het juridische landschap is echter genuanceerder dan één ToS-clausule:
- (N.D. Cal., jan 2024): de rechtbank oordeelde dat als je nooit inlogt, je de ToS ook nooit hebt geaccepteerd, en scrapen van publiek toegankelijke uitgelogde data die voorwaarden niet schendt
- hiQ Labs v. LinkedIn (9th Cir.): de CFAA is niet van toepassing op geautomatiseerde verzameling van publiek toegankelijke data — maar nepaccounts en scraping na login zijn een ander verhaal
- Van Buren v. United States (Supreme Court, 2021): beperkte de betekenis van "exceeds authorized access" onder de CFAA
De praktische conclusie: publieke vacaturelijsten scrapen zonder in te loggen zit juridisch in een relatief veiliger gebied. Scrapen met een ingelogde sessie betekent dat je bij aanmelding akkoord bent gegaan met de ToS, en daarin staat expliciet dat het niet mag. Dat geldt zowel voor Python-scripts als voor Thunderbit’s Browser Mode.
Een paar ethische richtlijnen die je hoe dan ook zou moeten volgen:
- Rate-limit ruim onder menselijke browsesnelheid
- Scrape of verkoop geen persoonlijk identificeerbare informatie van reviewers
- Respecteer robots.txt-richtlijnen
- Haal alleen de velden op die je echt nodig hebt
Conclusie: welke methode past bij jou?
Deze gids behandelde alle drie de Glassdoor-datatypes — vacatures, reviews en salarissen — met werkende code voor 2025 die rekening houdt met de migratie naar Indeed Login, Cloudflare Bot Management en de rotatie van CSS-moduleklassennamen die oudere tutorials stuk maakten.
Dit is het besliskader:
| Jouw situatie | Beste route |
|---|---|
| Developer die een datapijplijn bouwt | Python + Patchright (volg de stap-voor-stap hierboven) |
| Eenmalig onderzoek of terugkerende kleine pulls | Thunderbit (no-code, browsergebaseerd) |
| Alleen basis-vacatures op kleine schaal nodig | Check eerst of Glassdoor API-toegang nog bestaat (waarschijnlijk niet) |
| Specifiek salaris- of reviewdata nodig | Moet via Python-scraping of Thunderbit — de API dekte dit nooit |
| Team van niet-developers dat gedeelde data nodig heeft | Thunderbit → export naar Google Sheets |
Glassdoor’s beveiliging blijft zich ontwikkelen. Selectors breken. Nieuwe uitdagingen verschijnen. Bookmark deze gids — en als je dieper wilt duiken in webscraping-tools en technieken, bekijk dan onze artikelen over , , en . Je kunt ook walkthroughs bekijken op het .
FAQ’s
1. Kun je Glassdoor scrapen zonder in te loggen?
Ja, voor de meeste vacaturedata en de bovenste bedrijfsratings. Nee, voor volledige salarisuitsplitsingen of de complete reviewtekst voorbij de eerste paar pagina’s. De #HardsellOverlay is een CSS-only modal — de onderliggende HTML bevat nog steeds de data van de eerste pagina — maar diepere content zit server-side achter Glassdoor’s "give-to-get"-muur.
2. Welke Python-library werkt in 2025 het best voor Glassdoor scrapen?
Patchright (een stealth Playwright-fork) is de standaardaanbeveling. Het patcht de Runtime.Enable CDP-leak die vanilla Playwright heeft en waar Cloudflare expliciet op controleert. Voor lijstpagina’s die __NEXT_DATA__ in de initiële HTML meesturen, is curl_cffi met impersonate="chrome124" 10–20x sneller, maar het kan geen login-afgeschermde pagina’s verwerken.
3. Hoe voorkom ik blokkades bij het scrapen van Glassdoor?
Gebruik Patchright of rebrowser-playwright (niet vanilla Playwright of Selenium). Roteer residential proxies — datacenter-IP’s worden vrijwel meteen uitgedaagd. Voeg willekeurige vertragingen van 3–8 seconden toe tussen pagina’s. Bewaar cookies (gdId, cf_clearance, GSESSIONID) tussen requests. Reken op een sessievenster van 20–30 minuten voordat opnieuw een challenge verschijnt.
4. Is er een Glassdoor API die ik kan gebruiken in plaats van scrapen?
In de praktijk niet. De legacy Partner API staat , er heeft nooit een publieke reviews-endpoint bestaan, en via Indeed’s Publisher API is er geen migratiepad. Scraping of een no-code tool zoals Thunderbit is de enige praktische optie voor reviews en salarisdata.
5. Hoe vaak breken Glassdoor-scrapers?
Vaak. Glassdoor rolt frontendwijzigingen uit zonder aankondiging, en CSS-module hash-namen veranderen bij elke build. De meest stabiele extractiestrategieën zijn: (1) data-test-attribute selectors, (2) de __NEXT_DATA__-JSON blob, en (3) de interne BFF-reviews-endpoint. Bouw een zero-results-check in en draai wekelijks een kleine testscrape om problemen vroeg te signaleren.
Meer lezen