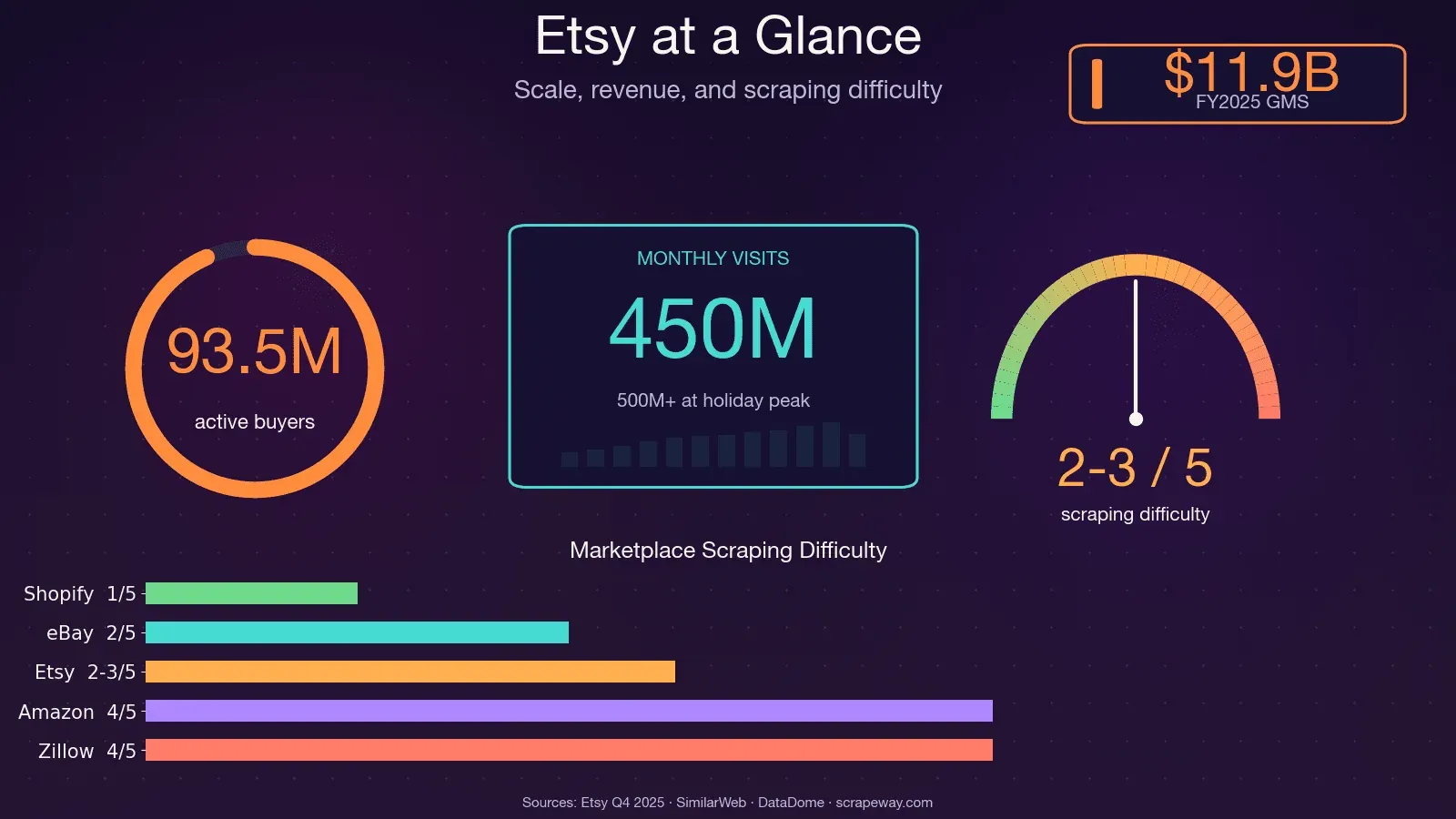
Etsy heeft meer dan 100 miljoen actieve vermeldingen, 5,6 miljoen verkopers en ongeveer 450 miljoen maandelijkse bezoeken. Dat is een enorme berg publiek beschikbare data over prijzen, trends, reviews en concurrenten — en als je het ooit handmatig hebt geprobeerd te verzamelen, weet je hoe vermoeiend dat is.
Ik heb ooit een weekend besteed aan het handmatig catalogiseren van concurrerende producten voor marktonderzoek. Bij product nummer 30 begon ik vraagtekens te zetten bij elke levenskeuze die tot die spreadsheet had geleid. Etsy-data is overigens ontzettend waardevol voor prijsanalyse, productontwikkeling, niche-ontdekking en benchmarking van verkopers — maar alleen als je het ook echt op schaal kunt ophalen. Daar gaat deze gids over: één complete tutorial waarin wordt uitgelegd hoe je Etsy kunt scrapen met Python over alle vier de belangrijkste paginatypen heen (zoekresultaten, productpagina’s, shop-pagina’s en reviews), plus een eerlijke uitleg over Etsy’s anti-botbeveiliging en een no-code alternatief voor wie liever helemaal geen scripts schrijft.
Wat betekent Etsy scrapen met Python?
Webscraping betekent heel simpel: code schrijven die webpagina’s bezoekt en automatisch de data ophaalt die je nodig hebt — productnamen, prijzen, beschrijvingen, afbeeldingen, beoordelingen, reviews, shopgegevens — en die vervolgens ordent in een gestructureerd formaat zoals een spreadsheet of database.
Python is hiervoor de meest gebruikte taal. Het is vriendelijk voor beginners, heeft een enorme community en biedt een uitgebreid ecosysteem aan bibliotheken voor scraping: Requests (voor het ophalen van pagina’s), BeautifulSoup (voor het parsen van HTML), Selenium en Playwright (voor browserautomatisering) en pandas (voor het structureren en exporteren van data). Python staat in Stack Overflow’s jaarlijkse ontwikkelaarsenquête steevast in de top 3 van populairste talen, en de scrapingbibliotheken behoren tot de meest gedownloade op PyPI.
Als je Etsy scrapt, haal je data uit de HTML (en soms verborgen JSON) die Etsy aan je browser levert. De soorten data die je kunt extraheren zijn onder andere:
- Productnamen, prijzen, beschrijvingen, afbeeldingen en varianten
- Verkopers- en shopinfo (naam, verkoopcijfer, locatie, beoordeling)
- Beoordelingen en volledige reviewtekst
- Zoekresultaatvermeldingen, categorieën en trendsignalen
Waarom Etsy scrapen? Praktische use-cases die direct rendement opleveren
Etsy scrapen is niet alleen een technische oefening — het geeft je ook een concurrentievoordeel. Of je nu verkoper, productmanager of data-analist bent, gestructureerde Etsy-data binnen handbereik kan direct invloed hebben op je omzet.
| Use-case | Wat je scrapt | Wie profiteert | Zakelijke impact |
|---|---|---|---|
| Analyse van concurrerende prijzen | Zoekresultaten + productprijzen | E-commerce operations, verkopers | Dynamische prijsstelling kan de omzet gemiddeld met 5–22% verhogen |
| Ontdekking van niches en trends | Zoekresultaten, trending vermeldingen | Oprichters, analisten | Ontdek trending niches vroeg (bijv. "preppy pajamas" groeide in zoekvolume met +1.112%) |
| Productontwikkeling en verbetering | Reviews, productdetails | Productteams | Een merk in keukenwaren pakte binnen 60 dagen de #1 Best Seller-positie terug met review-sentimentdata |
| SEO- en keywordonderzoek | Zoekresultaten, producttitels/tags | Marketingteams | Identificeer zoekwoorden met hoge vraag en lage concurrentie |
| Benchmarking van verkopers | Shop-pagina’s, verkoopcijfers | Salesteams, analisten | Bouw gekwalificeerde leadlijsten voor $0,01–0,10 per record, versus ingekochte lijsten |
| Voorraad- en stockmonitoring | Productbeschikbaarheid | E-commerce operations | Reageer sneller op voorraadwijzigingen van concurrenten |
Voor elk van deze use-cases heb je data nodig van verschillende Etsy-paginatypen — en daarom behandelt deze tutorial ze alle vier.
Tijdbesparing: handmatig vs. geautomatiseerd
- Handmatig Etsy-onderzoek: 30–45 minuten per product (50–75 uur voor 100 producten)
- Geautomatiseerd scrapen: 100 vermeldingen in 2–5 minuten
- AI-gedreven scraping is met een nauwkeurigheid tot 99,5%
Etsy API vs. webscraping: wat kies je?
Voordat je ook maar één regel code schrijft, is het goed om jezelf af te vragen: moet ik Etsy’s officiële API gebruiken of de site rechtstreeks scrapen? Die vraag zie ik constant terugkomen op forums, en het antwoord hangt af van de data die je nodig hebt.
Wat de Etsy API wel en niet kan
Etsy biedt een API v3 met OAuth 2.0-authenticatie. Die werkt voor toegang tot de data van je eigen shop — vermeldingen, bestellingen, bonnetjes. Maar er zitten duidelijke beperkingen aan:
- Data van concurrenten: De API is vooral beperkt tot je eigen shop. Je kunt niet zomaar prijzen, verkoopcijfers of vermeldingen van een andere verkoper ophalen.
- Reviews: Er is geen robuuste endpoint voor volledige reviewtekst in bulk.
- Rate limits: Standaard 10 verzoeken/seconde, 10.000 verzoeken/dag. De offsetgrens ligt op 12.000 records.
- AI/ML-gebruik: Expliciet afgewezen in de app review.
- Documentatie: Er is veel klachten uit de community — slechte voorbeelden, verouderde endpoints, trage ondersteuning.
Wanneer webscraping de betere keuze is
Als je concurrentie-informatie, review-sentiment, cross-shop-analyse of data nodig hebt die de API niet blootlegt, dan is scrapen de juiste route. De keerzijde: je krijgt te maken met Etsy’s anti-botverdediging (daarover hieronder meer) en je moet tijd investeren in de setup.
Vergelijkingstabel: API vs. scraping vs. no-code
| Criteria | Etsy officiële API | Python-webscraping | Thunderbit (no-code) |
|---|---|---|---|
| Toegang tot productprijzen | ✅ (beperkte velden) | ✅ Volledige HTML/JSON-LD | ✅ AI extraheert elk zichtbaar veld |
| Reviewdata | ❌ Niet in bulk beschikbaar | ✅ Via reviews-endpoint/HTML | ✅ Subpage scraping |
| Shopdata van concurrenten | ❌ Alleen eigen shop | ✅ Elke publieke shop | ✅ Elke publieke shop |
| Authenticatie vereist | ✅ OAuth 2.0 | ⚠️ Cookies voor ingelogde data | ⚠️ Browser scraping voor login |
| Anti-botrisico | Geen | HOOG (DataDome) | Afgevangen (browser-native) |
| Setup-tijd | Gemiddeld (API-sleutels, OAuth) | Hoog (code + proxies) | ~2 minuten |
Als je concurrentiedata, reviews of cross-shop-analyse nodig hebt, dekt de API dat simpelweg niet af. Dat is de eerlijke realiteit.
Kies je Python-aanpak voordat je één regel code schrijft
Een vraag die ik op Reddit en Stack Overflow steeds zie: "Moet ik Requests + BeautifulSoup gebruiken, Selenium, een proxy-API of iets heel anders?" Het juiste antwoord hangt af van je vaardigheidsniveau, budget en use-case.
| Aanpak | Het beste voor | Leercurve | Ondersteunt JS? | Anti-botafhandeling | Kosten |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | Developers die volledige controle willen | Gemiddeld | ❌ | Handmatig (headers, proxies) | Gratis + proxykosten |
| Selenium / Playwright | Pagina’s met veel JS, loginflows | Hoog | ✅ | Gedeeltelijk (browser fingerprint) | Gratis + proxykosten |
| Proxy-API-diensten | Schaal + anti-botomzeiling | Gemiddeld | ✅ (via API) | ✅ Ingebouwd | vanaf $49/maand |
| Thunderbit (no-code) | Niet-developers, snelle extractie | Zeer laag | ✅ (browser-native) | ✅ (browser-sessie) | Gratis tier beschikbaar |
Wil je volledige controle en ben je comfortabel met Python, kies dan voor Requests + BeautifulSoup. Heb je JS-rendering of loginflows nodig, gebruik dan Selenium. Wil je anti-botomzeiling op schaal, overweeg dan een proxyservice. En wil je Etsy-data zonder code te schrijven of te onderhouden, dan is Thunderbit zeker het bekijken waard — daar kom ik later op terug.
Hoe Etsy terugvecht: DataDome anti-botbeveiliging begrijpen
De meeste scrapinggidsen zeggen simpelweg: "gebruik een proxy" en klaar. Voor Etsy is dat niet genoeg. Etsy gebruikt DataDome, een van de agressiefste anti-botsystemen op het web. noemt Etsy als succesverhaal en vermeldt dat scrapers ooit goed waren voor ongeveer 1% van Etsy’s computerkosten.
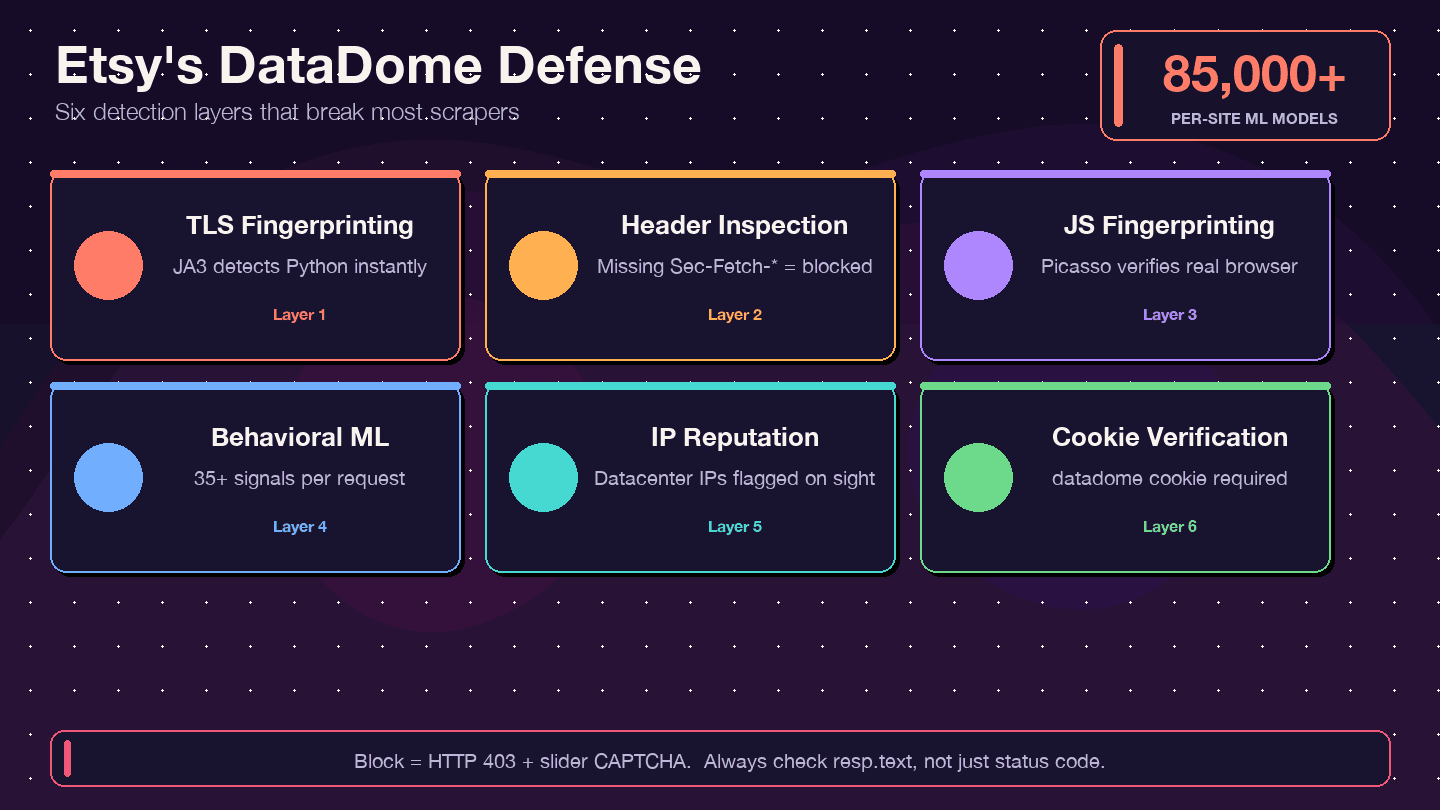
Wat is DataDome en hoe werkt het?
DataDome controleert niet alleen je IP-adres. Het draait een detectiestack met meerdere lagen:
- TLS-fingerprinting (JA3): Python’s
requests-bibliotheek heeft een herkenbare TLS-handtekening die DataDome direct kan spotten. - Inspectie van HTTP-headers/protocol: Controleert op volledige, consistente browserheaders — ontbrekende of verkeerd geordende headers zijn verdacht.
- JavaScript-fingerprinting (Picasso-protocol): Draait JS-challenges in de browser om te verifiëren dat je een echte gebruiker bent.
- Gedragsmatige ML: Analyseert meer dan 35 signalen per verzoek, met meer dan 85.000 modelspecifieke modellen per site.
- IP-reputatiescoring: Datacenter-IP’s worden direct gemarkeerd.
- Cookieverificatie: De
datadome-cookie moet aanwezig en geldig zijn.
Tekenen dat je geblokkeerd bent geraakt (en hoe je het controleert)
Een van de meest voorkomende valkuilen: je krijgt een 200 OK-response, maar de HTML blijkt een CAPTCHA-pagina te zijn in plaats van de data die je wilde. Andere signalen:
- 403 Forbidden-fouten
- Redirectlussen
- De response body bevat een
ddJavaScript-object of HTML van een slider-CAPTCHA
Controleer altijd de response body, niet alleen de statuscode. Een snelle check:
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("Geblokkeerd! CAPTCHA-pagina gekregen in plaats van data.")Headers en cookies die detectie verminderen
Je kunt nooit garanderen dat je niet geblokkeerd wordt, maar realistische headers en cookiebeheer helpen enorm:
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})Ook belangrijk:
- Behoud cookies tussen verzoeken met een
requests.Session(). - Voeg willekeurige vertragingen toe (2–7 seconden) tussen verzoeken.
- Simuleer een referrer-keten: bezoek eerst de homepage, dan de zoekresultaten, daarna de productpagina’s.
- Op schaal is rotatie van residential proxies essentieel. Datacenter-IP’s worden vrijwel direct gemarkeerd.
Deze technieken verminderen detectie, maar halen die niet volledig weg. Voor scraping met hoge volumes heb je waarschijnlijk een proxyservice of een browsergebaseerde aanpak nodig.
Je Python-omgeving instellen om Etsy te scrapen
Voordat je begint:
- Moeilijkheid: Gemiddeld
- Benodigde tijd: ~30–60 minuten (setup + eerste scrape)
- Wat je nodig hebt: Python 3.8+, pip, een code-editor, Chrome-browser (voor inspectie via DevTools)
Afhankelijkheden installeren
Maak een projectmap aan, zet een virtuele omgeving op en installeer de bibliotheken die je nodig hebt:
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # Op Windows: venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — haalt webpagina’s op
- beautifulsoup4 — parseert HTML
- lxml — snellere HTML-parser (optioneel, maar aanbevolen)
- pandas — structureert data en exporteert naar CSV/Excel
Als je later browserautomatisering nodig hebt (voor login of pagina’s met veel JS), installeer dan ook:
1pip install seleniumBegrijp de paginastuctuur van Etsy voordat je code schrijft
Hier is een tip die je enorm veel tijd bespaart: Etsy sluit op de meeste pagina’s gestructureerde productdata in binnen <script type="application/ld+json">-tags. Die JSON-LD-data is al netjes georganiseerd — productnaam, prijs, beoordeling, afbeeldingen — dus je hoeft niet voor elk veld te vechten met fragiele CSS-selectors.
Open een willekeurige Etsy-productpagina, klik met rechts, kies "Paginabron weergeven" en zoek op application/ld+json. Je vindt een blok met @type: Product dat het grootste deel van de data bevat die je nodig hebt. Zoekresultaatpagina’s hebben @type: ItemList.
CSS-selectors zijn nog steeds nuttig als fallback (voor data die niet in JSON-LD staat, zoals verzendinformatie of reviewtekst), maar JSON-LD zou je eerste stop moeten zijn.
Stap 1: Etsy-zoekresultaten scrapen met Python
Zoekresultaten zijn het startpunt van de meeste Etsy-scrapingprojecten — of je nu een niche monitort, concurrerende prijzen volgt of een productdatabase opbouwt.
Bouw de zoek-URL
Etsy-zoek-URL’s volgen dit patroon:
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}Voor zoekopdrachten met meerdere woorden moet je de spaties URL-encoderen (bijv. handmade+jewelry of handmade%20jewelry). De parameter ref=pagination laat het verzoek meer lijken op echte browsernavigatie.
Andere nuttige parameters: order (most_relevant, price_asc, price_desc, date_desc), min_price, max_price, ship_to, free_shipping=true. Elke pagina levert 48 items op.
Verstuur het verzoek en parse de HTML
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"Geblokkeerd op pagina \{page\}. Probeer vertragingen of proxies toe te voegen.")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsHaal listingdata uit JSON-LD
De itemListElement-array geeft je van elke listing de naam, URL, afbeelding, prijs en valuta. Als je ook sterrenbeoordelingen of resultaat-aantallen nodig hebt (die niet altijd in JSON-LD staan), gebruik dan CSS-selectors als fallback:
- Listingkaart:
.v2-listing-card - Titel:
h3.v2-listing-card__title - Prijs:
span.currency-value - Link:
a.listing-link(href)
Omgaan met paginering
Loop door de pagina’s en voeg tussen elk verzoek een willekeurige vertraging toe. Etsy geeft meestal tot 20–250 pagina’s terug, afhankelijk van de zoekopdracht.
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"{len(results)} producten gescrapt.")Voor een scrape van 5 pagina’s kostte dit in mijn test ongeveer 20 seconden — vergeleken met meer dan 30 minuten handmatig kopiëren en plakken.
Stap 2: Etsy-productpagina’s scrapen met Python
Zodra je een lijst met product-URL’s uit de zoekresultaten hebt, is de volgende stap het ophalen van gedetailleerde data van elke productpagina.
Haal de productpagina op
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return NoneOmgaan met prijsvarianten
Sommige producten hebben één offers.price. Andere, met varianten zoals maat of kleur, gebruiken offers.lowPrice en offers.highPrice. De code hierboven vangt beide af door van price terug te vallen op lowPrice.
Extra velden parsen via CSS-selectors
Voor data die niet in JSON-LD staat — verzendinformatie, variatie-opties, volledige sellerdetails — heb je CSS-selectors nodig:
- Titel:
h1[data-buy-box-listing-title] - Variaties:
select[data-selector-id]ofdiv[data-option-set] - Verzending:
div.wt-text-captionin de buurt van de verzendsectie
De afweging: JSON-LD is schoner en stabieler bij layoutwijzigingen. CSS-selectors zijn fragieler, maar dekken meer velden af.
Stap 3: Etsy-shop-pagina’s scrapen met Python
Dit is het deel dat de meeste concurrentiegidsen volledig overslaan — en het is misschien wel het waardevolste voor salesteams en concurrentieanalisten.
Bouw de shop-URL en haal de pagina op
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # Shopmetadata uit HTML (niet in JSON-LD)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # Vermeldingen uit JSON-LD
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_dataWat je uit shop-pagina’s kunt halen
JSON-LD op shop-pagina’s is @type: ItemList — dat dekt de productvermeldingen, maar niet shopniveau-metadata zoals verkoopcijfers, locatie of beoordeling. Daarvoor heb je CSS-selectors nodig:
| Datapunt | Selector | Opmerking |
|---|---|---|
| Shopnaam | h1 of meta title | Meestal in de paginatitel |
| Totaal aantal verkopen | div.shop-sales-reviews a | Tekst zoals "12.345 sales" |
| Sterbeoordeling | waarde van input[name="initial-rating"] | Numeriek 1–5 |
| Locatie | div.shop-location | Stad, land |
| Lid sinds | div.shop-info | Datumtekst |
Shopdata is uniek waardevol voor het opbouwen van leadlijsten, het benchmarken van concurrenten of het identificeren van toppers in een niche.
Stap 4: Etsy-reviews scrapen met Python
Reviews behoren tot de meest waardevolle — en lastigste — datapunten op Etsy. De volledige reviewtekst, scores en datums staan niet in de initiële HTML van de pagina; ze laden via een intern API-endpoint.
Aanpak 1: Etsy’s interne reviews-API-endpoint ontdekken
Open een productpagina in Chrome, open DevTools (F12), ga naar het tabblad Network en scroll naar de reviewsectie. Je ziet een POST-verzoek naar iets als:
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviewsDit endpoint geeft HTML-fragmenten terug met de reviewkaarten. Om het te gebruiken, heb je nodig:
- listing_id — de numerieke ID uit de product-URL
- shop_id — haal deze uit de HTML van de productpagina met regex
- csrf_nonce — haal deze uit een
<meta>-tag op de pagina
IDs en CSRF-token extraheren
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrfReviews scrapen met paginering
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviewsAanpak 2: Reviews uit HTML parsen (fallback)
Als de API-aanpak mislukt (bijvoorbeeld door problemen met het CSRF-token), kun je de eerste reviewpagina rechtstreeks uit de HTML van de productpagina parsen. De beperking: alleen de eerste batch reviews staat in de statische HTML. Voor meer heb je de API of een browserautomatiseringstool zoals Selenium nodig.
Omgaan met login-vereiste data: je eigen Etsy-shop scrapen
Dit is een gat dat geen enkele andere tutorial echt afdekt, maar het is een echte behoefte — vooral voor Etsy-verkopers die hun eigen bestellingen, omzet en statistieken willen extraheren.
Het probleem: requests alleen heeft geen toegang tot je Etsy-dashboard, omdat het geen cookies van je ingelogde sessie meeneemt.
Optie 1: Selenium met handmatige login en cookie-opvang
Gebruik Selenium om een browser te openen, log handmatig in (of automatiseer de login) en ga daarna verder met scrapen terwijl je geauthenticeerd bent:
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# Log handmatig in in het browservenster, en daarna:
5input("Druk op Enter nadat je bent ingelogd...")
6cookies = driver.get_cookies()
7# Gebruik nu driver.get() om naar je dashboardpagina's te gaan en daar te scrapenJe kunt cookies uit de Selenium-sessie ook opslaan en hergebruiken met requests.Session() voor sneller en lichter scrapen na de eerste login.
Optie 2: Browsercookies exporteren en gebruiken met Requests
Gebruik een browserextensie (zoals "EditThisCookie") om je actieve Etsy-sessiecookies te exporteren en laad ze vervolgens in een Requests-sessie:
1import requests
2session = requests.Session()
3# Voeg cookies toe die je uit je browser hebt geëxporteerd
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... voeg indien nodig andere sessiecookies toe
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)De makkelijke route: Thunderbit’s browser scraping-modus
Omdat in je Chrome-browser draait, neemt het je actieve Etsy-sessie automatisch over. Geen authenticatiecode, geen cookie-export — open gewoon je Etsy-dashboard en scrape. Dat is echt handig voor het extraheren van bestellingen, omzet, statistieken en andere seller-only data zonder ook maar iets te hoeven scripten.
Je gescrapete Etsy-data exporteren en gebruiken
Opslaan naar CSV of JSON
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)Best practices: neem tijdstempels op in je bestandsnamen, gebruik UTF-8-codering en houd rekening met speciale tekens in productnamen (Etsy-verkopers houden van emoji’s en geaccentueerde karakters).
Exporteren naar Google Sheets, Airtable of Notion
Voor Python-gebruikers laten bibliotheken zoals gspread (Google Sheets) of de Airtable API je data programmatisch wegschrijven. Maar als je gebruikt, zijn alle exports — naar Google Sheets, Excel, Airtable en Notion — gratis en met één klik beschikbaar. Geen API-sleutels, geen OAuth-setup.
Sla de code over: hoe je Etsy scrapt met Thunderbit (no-code alternatief)
Niet iedereen wil Python-scripts schrijven, proxyconfiguraties onderhouden of om 2 uur ’s nachts CSS-selectors debuggen. Als dat op jou van toepassing is, zo haal je Etsy-data binnen met .
Installeer de Thunderbit Chrome-extensie
Ga naar de en installeer Thunderbit. Maak een gratis account aan — het gratis plan geeft je en alle exports zijn gratis.
Gebruik AI Suggest Fields op elke Etsy-pagina
Ga naar een Etsy-zoekresultaat-, product- of shop-pagina. Klik op "AI Suggest Fields" in de zijbalk van Thunderbit. De AI scant de pagina en stelt kolommen voor — productnaam, prijs, beoordeling, afbeeldingen, shopnaam, tags, verzendinformatie. Pas kolommen aan of voeg ze toe zoals nodig.
Klik op Scrape en exporteer
Klik op "Scrape" om data van de huidige pagina te extraheren. Voor resultaten over meerdere pagina’s gebruik je Thunderbit’s scraping voor paginering. Wil je een lijst met product-URL’s verrijken met details van elke productpagina (beschrijvingen, reviews, verzending), gebruik dan subpage scraping — Thunderbit bezoekt elke link en haalt automatisch de extra data op.
Exporteer gratis naar Excel, Google Sheets, Airtable of Notion.
Wanneer Thunderbit beter is dan Python voor Etsy-scraping
- Geen proxysetup of anti-botcode nodig. Thunderbit draait in je echte Chrome-browser, dus het erft je sessie en ziet er voor DataDome uit als een normale gebruiker.
- AI past zich automatisch aan lay-outwijzigingen aan. Geen kapotte selectors die je hoeft te repareren wanneer Etsy zijn frontend bijwerkt.
- Geweldig voor eenmalig onderzoek, concurrentieanalyse of niet-technische teamleden. Als je gewoon snel een dataset nodig hebt, heb je geen Python-omgeving nodig.
- Subpage scraping laat je een lijst product-URL’s verrijken met gedetailleerde data zonder geneste loops te schrijven.
Voor een walkthrough kun je het bekijken.
Python vs. Thunderbit: kostenvergelijking over 6 maanden
| Factor | Python zelf bouwen | Thunderbit |
|---|---|---|
| Setup-tijd | 8–20 uur | Minder dan 5 minuten |
| Kosten over 6 maanden (incl. arbeid, proxies) | $2.720–9.450 | $90–228 |
| Maandelijkse onderhoudstijd | 4–10+ uur (selector-updates = 80%+ overhead) | 0–1 uur |
| Anti-botafhandeling | Residential proxies tegen 85x normale creditkosten | Browsergebaseerd, omzeilt DataDome native |
| Datakwaliteit | Hoog (met moeite) | Hoog (AI-gedreven) |
Ik zeg niet dat Python de verkeerde keuze is — als je volledige controle, aangepaste logica of integratie in een grotere pipeline nodig hebt, dan is code nog steeds koning. Maar voor de meeste zakelijke gebruikers die gewoon Etsy-data nodig hebben, wijst de ROI-berekening in de richting van een no-code tool.
Juridische en ethische tips voor het scrapen van Etsy
Ik krijg bij elk scrapingartikel vragen over de legaliteit, dus hier is de korte versie:
- Etsy’s Gebruiksvoorwaarden verbieden expliciet geautomatiseerde toegang. Etsy vertrouwt echter vooral op technische handhaving (DataDome) in plaats van rechtszaken — er zijn geen bekende Etsy-specifieke rechtszaken tegen scrapers.
- Scrape alleen publiek beschikbare data. Omzeil geen authenticatie en probeer geen privé dashboards van verkopers te benaderen die niet van jou zijn.
- Hanteer redelijke request-snelheden. 2–7 seconden vertraging tussen verzoeken, en belast Etsy’s servers niet onnodig.
- Respecteer
robots.txt. Etsy staat zoekpagina’s toe, maar beperkt sommige paden. - Ga zorgvuldig om met persoonsgegevens onder privacywetgeving zoals de AVG/GDPR.
- Raadpleeg juridisch advies voor scrapingprojecten op commerciële schaal.
Voor meer achtergrond kun je onze post lezen over — inclusief Meta v. Bright Data (2024), waarin het scrapen van publieke data werd toegestaan.
Afronding: belangrijkste inzichten
We hebben hier veel behandeld. Dit zijn de belangrijkste punten om mee te nemen:
- Etsy’s gestructureerde JSON-LD-data maakt extractie voor de meeste velden schoner dan ruwe HTML-parsing.
- DataDome is een echte hindernis — gebruik goede headers, vertragingen, cookiebeheer en residential proxies voor Python-scraping op schaal.
- De Etsy API is beperkt. Als je reviews, shops van concurrenten of cross-seller-analyse nodig hebt, is scrapen de praktische route.
- Thunderbit biedt een no-code alternatief dat anti-bot en authenticatie native afhandelt — de moeite waard als je Etsy-data wilt zonder scripts te onderhouden.
- Scrape altijd verantwoord en respecteer Etsy’s voorwaarden.
Wil je aan de slag zonder code te schrijven, . Of gebruik de Python-code uit deze tutorial om je eigen scraper te bouwen — en moge je selectors nooit op een vrijdagmiddag breken.
Voor meer scrapinggidsen, bekijk onze en het overzicht van .
FAQ’s
1. Is het legaal om Etsy te scrapen met Python?
Het scrapen van publiek beschikbare data is volgens recente juridische precedenten over het algemeen toegestaan (bijv. Meta v. Bright Data, hiQ v. LinkedIn). Etsy’s Gebruiksvoorwaarden verbieden echter geautomatiseerde toegang, dus bekijk altijd hun ToS en robots.txt voordat je gaat scrapen. Voor grootschalig of commercieel gebruik is juridisch advies verstandig.
2. Kan ik Etsy scrapen zonder geblokkeerd te worden?
Etsy gebruikt DataDome, een van de zwaarste anti-botsystemen die er zijn. Realistische headers, verzoekvertragingen, het behouden van cookies en rotatie van residential proxies helpen allemaal om blokkades te verminderen. Thunderbit’s browser-native aanpak ontwijkt de meeste detectie, omdat het binnen je echte Chrome-sessie werkt.
3. Heeft Etsy een API die ik kan gebruiken in plaats van scraping?
Ja — Etsy biedt een API v3, maar die is grotendeels beperkt tot de data van je eigen shop en biedt geen robuuste toegang tot reviews. Voor de meeste use-cases op het gebied van concurrentie-informatie en cross-shop-analyse is scraping nodig.
4. Welke Python-bibliotheken heb ik nodig om Etsy te scrapen?
Minimaal: requests, beautifulsoup4, pandas (voor export) en json (ingebouwd). Voor pagina’s met veel JS of pagina’s waarvoor login vereist is, voeg selenium toe. Voor snellere HTML-parsing gebruik je lxml.
5. Hoe scrape ik specifiek Etsy-reviews?
Etsy-reviews laden via een intern API-endpoint (/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews). Je moet de listing-ID, shop-ID en CSRF-token uit de productpagina halen en vervolgens met paginering naar het endpoint posten. Als fallback kun je de eerste batch reviews uit de HTML van de productpagina parsen — beide methoden worden stap voor stap behandeld in deze tutorial.
Meer lezen