De meeste tutorials over eBay scrapen met Python zijn na een paar maanden al achterhaald. Dat weet ik, omdat ons team bij Thunderbit ontwikkelaars keer op keer ziet vastlopen op kapotte codefragmenten, verouderde CSS-selectors en “werkende” GitHub-repos die al stilletjes kapot waren sinds twee eBay-redesigns geleden.
eBay heeft — na Amazon de grootste long-tail pricing-dataset op het open web. Die data voedt alles van reseller-prijzen tot competitive intelligence. Maar er programmatic bij komen is een bewegend doel: eBay’s React-gebaseerde frontend verandert CSS-klassen voortdurend, A/B-tests serveren verschillende DOM-structuren aan verschillende gebruikers, en Akamai Bot Manager staat tussen jou en de HTML. In deze gids krijg je Python-code die vandaag werkt, leer je waarom scrapers stukgaan zodat je robuustere versies kunt bouwen, zetten we de eBay API eerlijk af tegen scraping, en laten we een no-code uitweg zien voor momenten waarop Python de setup niet waard is.
Wat betekent eBay scrapen met Python?
eBay scrapen met Python betekent dat je scripts schrijft die eBay-pagina’s programmatic ophalen, de HTML (of verborgen JSON) analyseren en gestructureerde data eruit halen — zoals titels, prijzen, verkopersinformatie, verkoopdatums en variantdetails — in een formaat dat je echt kunt gebruiken, zoals CSV, een spreadsheet of een database.
Je kunt verschillende soorten eBay-pagina’s scrapen:
- Zoekresultaten (bijv. alle aanbiedingen voor “AirPods Pro”)
- Individuele productdetailpagina’s (volledige specificaties, afbeeldingen, verkopersinfo)
- Verkochte/afgeronde aanbiedingen (daadwerkelijke transactieprijzen en datums)
- Verkopersprofielen en reviews
Python is hiervoor de standaardkeuze. Het ecosysteem — Requests, BeautifulSoup, lxml, pandas — maakt het eenvoudig om pagina’s op te halen, HTML te parsen en data te verwerken. Er is wel een belangrijk verschil tussen het scrapen van de website-HTML en het gebruiken van de officiële eBay API — dat licht ik zo toe.
Waarom eBay scrapen? Praktische use cases voor zakelijke teams
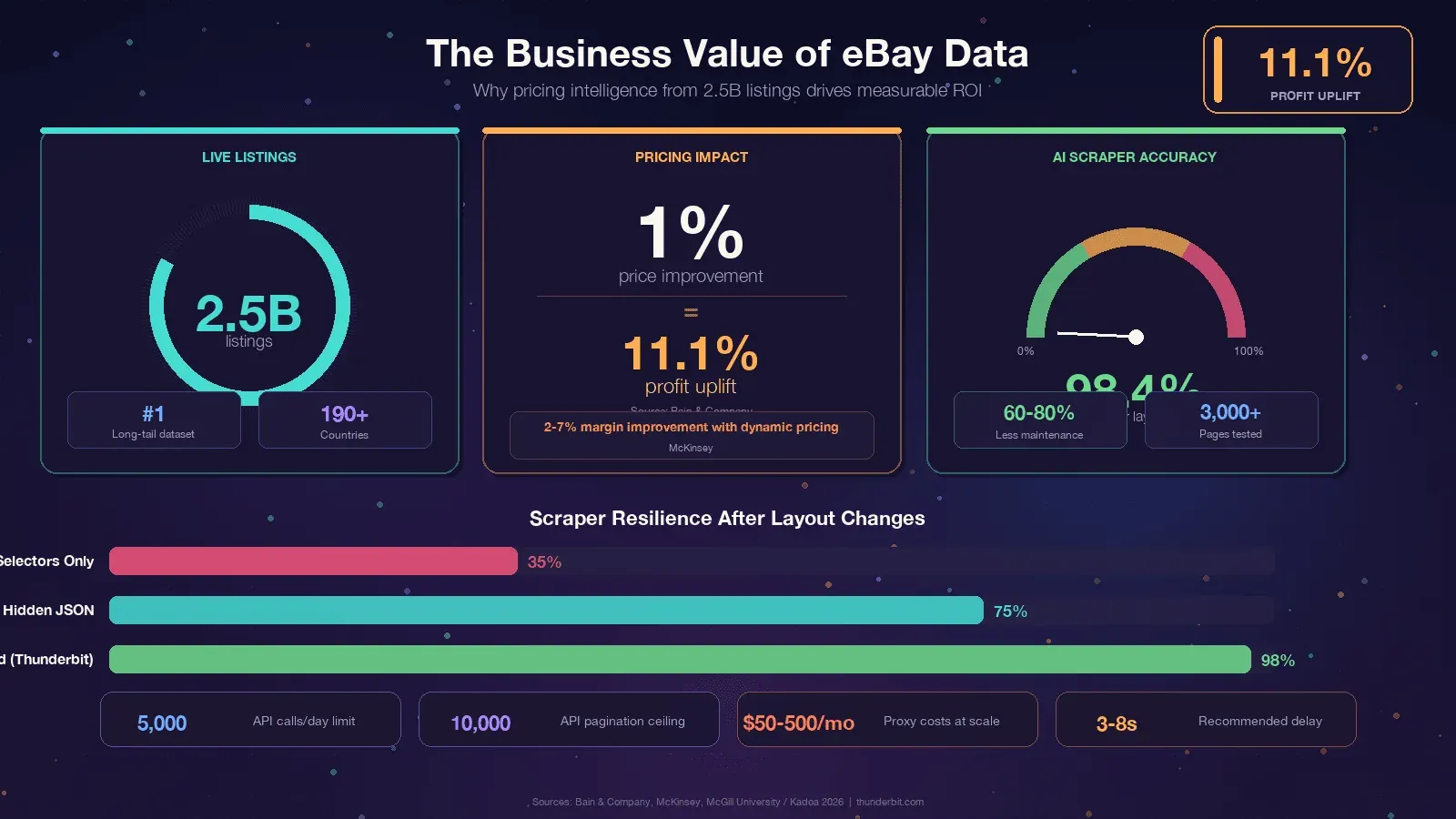
Als je dit leest, heb je waarschijnlijk al een reden. Toch is het goed om het gesprek te verankeren in concrete businesswaarde, want de ROI van eBay-data is echt indrukwekkend. Bain ontdekte dat een bij duizenden bedrijven. McKinsey schrijft toe aan dynamische pricing in retail.
De use cases die ik het vaakst zie:
| Use case | Benodigde data | Zakelijk resultaat |
|---|---|---|
| Prijsmonitoring & repricing | Actieve prijzen, verzending, conditie | Scherpere prijzen, bescherming van marges |
| Concurrentieanalyse | Assortiment, promoties, verzendvoorwaarden | Strategische positionering, zicht op assortimentsgaten |
| Marktonderzoek & trendanalyse | Aanbodtempo, categorietrends, vraagpatronen | Nieuwe productkansen, vraagvoorspelling |
| Reseller pricing / taxaties | Verkoopprijzen, verkoopdatums, conditie | Eerlijke marktwaarde, buy-box-beslissingen |
| Sentimentanalyse | Reviews, ratings, retourbeleid | Inzicht in productkwaliteit en klanttevredenheid |
| Leadgeneratie | Verkopersprofielen, store-informatie, contactgegevens | B2B-outreach naar verkopers met hoge GMV |
De rode draad: eBay heeft de data, maar die zit vast in webpagina’s.
Scraping is hoe je dat omzet in concurrentievoordeel.
Officiële eBay API versus Python webscraping: wat kies je?
Dit is de vraag waar ik meer tutorials eerlijk over had willen zien zijn. eBay biedt officiële API’s — vooral de — en veel gebruikers vragen zich af of ze die moeten gebruiken of direct moeten scrapen. Het antwoord hangt volledig af van welke data je nodig hebt.
| Criteria | eBay Browse/Finding API | Python webscraping |
|---|---|---|
| Verkochte/afgeronde aanbiedingen | Beperkt — Marketplace Insights API bestaat, maar toegang wordt vaak geweigerd | Volledige toegang via LH_Sold=1&LH_Complete=1 URL-parameters |
| Rate limits | 5.000 calls/dag op basisniveau | Zelf beheren (afhankelijk van proxies) |
| Data-velden | Vooraf gedefinieerd (titel, prijs, categorie, basisinfo verkoper) | Alles wat zichtbaar is op de pagina (reviews, volledige specs, variantmatrix) |
| Setup-complexiteit | OAuth 2.0, app-registratie, API-keys | pip install + code |
| Stabiliteit | Stabiele endpoints | Breekt zodra HTML wijzigt |
| Kosten | Gratis tier beschikbaar, betaald bij volume | Gratis code, maar op schaal proxykosten |
| Variant/MSKU-data | Gedeeltelijk — in veel gevallen alleen parent SKU | Volledig (via parsing van verborgen JSON) |
| Paginadiepte | Harde limiet van 10.000 items | In theorie onbeperkt |
Kleine maar belangrijke noot: de oude Finding API (met findCompletedItems) is in . Als je ebaysdk-python gebruikt of een library die de Finding-module aanspreekt, werkt die in productie nu niet meer.
Mijn advies: gebruik de Browse API voor stabiele, middelgrote gestructureerde catalogusqueries op actieve aanbiedingen. Gebruik Python scraping wanneer je verkoopprijzen, reviews, variantdata of velden nodig hebt die de API niet blootgeeft. Veel teams gebruiken beide.
Tools en libraries die je nodig hebt om eBay met Python te scrapen
Voordat we code schrijven, eerst de toolkit. Voor de meeste eBay-pagina’s heb je geen headless browser nodig — de data zit al in de server-rendered HTML.
| Library | Doel |
|---|---|
requests of httpx | HTTP-client om eBay-pagina’s te downloaden |
curl_cffi | HTTP-client met echte browser-TLS-fingerprints (cruciaal om Akamai te omzeilen) |
beautifulsoup4 | HTML-parser voor extractie met CSS-selectors |
lxml | Snelle parser-backend voor BeautifulSoup |
jmespath | Querytaal voor het parsen van geneste JSON-blobs |
pandas | Dataverwerking en export naar CSV/Excel |
gspread | Integratie met Google Sheets |
Installeer alles in één keer:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadGebruik Python 3.11+ — pandas 3.0 vereist 3.10+, en 3.11 geeft je 10–60% snelheidswinst bij I/O-bound werk.
Eén library verdient extra aandacht: curl_cffi is de upgrade met de grootste impact die een eBay-scraper in 2026 kan maken. eBay gebruikt , en Akamai detecteert vooral via TLS-fingerprinting. Gewone requests stuurt een Python-achtige JA3-fingerprint die direct wordt gemarkeerd. curl_cffi bootst de TLS-handshake van een echte Chrome-browser na, en vangt daarmee ongeveer 90% van de door Akamai beschermde targets af zonder headless browser.
Stap voor stap: hoe je eBay-zoekresultaten scrapt met Python
Dit is de kern van de tutorial. We gaan eBay-zoekresultaten scrapen voor productaanbiedingen.
- Moeilijkheid: Beginner–Intermediate
- Benodigde tijd: ongeveer 30 minuten voor de eerste werkende scrape
- Wat je nodig hebt: Python 3.11+, de libraries hierboven, een terminal en een eBay-zoek-URL
Stap 1: Zet je Python-project op
Maak een projectmap aan en installeer de dependencies:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasMaak een bestand aan met de naam scrape_ebay.py. Dat is je werkplek.
Stap 2: Bouw de eBay-zoek-URL
de zoek-URL van eBay is vrij simpel. De belangrijkste parameter is _nkw (keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # items per pagina: 60, 120 of 240 (240 kan botflags triggeren)
7 "_pgn": "1", # paginanummer
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Andere handige parameters:
LH_BIN=1— alleen Buy It Now_sacat=175673— specifieke categorie_sop=12— sorteren op best match (10 = laagste prijs + verzending, 13 = nieuw geplaatst)LH_Complete=1&LH_Sold=1— verkochte/afgeronde aanbiedingen (later in een aparte sectie)
Stap 3: Verstuur een request en verwerk het antwoord
Hier verdient curl_cffi zijn geld. Een gewone requests.get() levert vaak een 403 van Akamai op. Met curl_cffi doen we alsof we een echte Chrome-browser zijn:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status {r.status_code}, opnieuw proberen over {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Requestfout: {e}, opnieuw proberen...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Mislukt na {max_retries} retries: {url}")De exponentiële backoff met jitter is belangrijk — vaste slaapintervallen zijn zelf ook een botfingerprint.
Stap 4: Parse productvermeldingen uit de zoekpagina
eBay zit momenteel midden in een migratie tussen twee zoekresultaat-layouts. Een robuuste scraper moet beide aankunnen:
| Veld | Legacy layout | Nieuwe layout |
|---|---|---|
| Card-container | li.s-item | li.s-card of div.su-card-container |
| Titel | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Prijs | span.s-item__price | .s-card__price |
De parsingcode die beide layouts ondersteunt:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Titel — probeer beide layouts
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Sla de spookkaart “Shop on eBay” over
11 if not title or "Shop on eBay" in title:
12 continue
13 # Prijs
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Afbeelding
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Verzending
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsDie eerste spookkaart is een klassieker. De eerste li.s-item op veel eBay-zoekpagina’s is een verborgen placeholder met de titel “Shop on eBay” en zonder echte prijs. Filter die er altijd uit.
Stap 5: Verwerk paginering om meerdere pagina’s te scrapen
eBay gebruikt de _pgn-parameter voor paginering. De link naar de volgende pagina gebruikt a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Pagina {page_num aan het scrapen: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" Geen resultaten op pagina {page_num}, stoppen.")
12 break
13 all_results.extend(results)
14 print(f" {len(results)} aanbiedingen gevonden (totaal: {len(all_results)})")
15 # Netjes wachten — 3 tot 8 seconden met jitter
16 time.sleep(random.uniform(3, 8))
17 return all_resultsDie willekeurige vertraging van 3–8 seconden is niet optioneel.
eBay’s Akamai-laag detecteert aanhoudend >1 request/s vanaf één IP.
Stap 6: Exporteer je gescrapete data naar CSV of JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"{len(df)} aanbiedingen geëxporteerd naar CSV en JSON.")Nu heb je een nette spreadsheet met eBay-aanbiedingen. Op mijn machine duurde het scrapen van 3 pagina’s (360 aanbiedingen) ongeveer 45 seconden, inclusief wachttijden.
Hoe je eBay-productdetailpagina’s scrapt met Python
Zoekresultaten geven je een samenvatting. Productdetailpagina’s bevatten het interessante deel: volledige beschrijvingen, verkopersfeedback, item-specificaties, afbeeldingscarrousels en variantdata.
Eén productpagina parsen
eBay-itempagina’s leven op /itm/<ITEM_ID>. Het meest stabiele extractiepad is JSON-LD — eBay embedt een Product schema-block dat bijna alle CSS-wijzigingen overleeft:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — meest stabiele extractieroute
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. CSS-fallbacks voor velden die niet in JSON-LD zitten
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Item-specificaties
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemHet patroon hier — eerst JSON-LD, daarna CSS-fallbacks — is de sleutel tot scrapers die niet elk kwartaal kapot gaan. Daarover straks meer.
eBay-varianten scrapen (MSKU-data)
Sommige eBay-aanbiedingen hebben meerdere varianten — verschillende kleuren, maten of opslagcapaciteiten. De zichtbare DOM toont dan alleen een prijsvork zoals “$899 tot $1.099” totdat de gebruiker een optie klikt. De daadwerkelijke prijs per variant zit in een verborgen JavaScript-object genaamd MSKU.
Dit is een van de weinige gebieden waar de eBay API slechts gedeeltelijke data biedt (parent SKU), waardoor scraping hier de betere aanpak is.
1import re, json
2def extract_variants(html):
3 # Niet-gulzige match is cruciaal — gulzige .+ slokt de hele pagina op
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusDie niet-gulzige (.+?) in de regex is precies waar elke eBay-scraper over struikelt. Gulzige .+ slokt alles op tot de laatste "QUANTITY" op de pagina, waardoor de JSON beschadigd raakt. Ik heb deze bug minstens drie keer gezien in “werkende” tutorials.
Hoe je eBay verkochte en afgeronde aanbiedingen scrapt met Python
Dit is de use case die scraping boven de API rechtvaardigt. Verkochte-itemdata — wat er echt is verkocht, tegen welke prijs en op welke datum — is de gouden standaard voor marktonderzoek, reseller-pricing en taxaties. De eBay Browse API biedt dit expliciet niet. De doet dat technisch wel, maar toegang is een “Limited Release” die .
De URL-parameters die je nodig hebt zijn LH_Complete=1 (afgeronde aanbiedingen) en LH_Sold=1 (beperken tot echt verkochte items). Je moet beide meegeven. Alleen LH_Sold=1 leidt in sommige categorieën stilletjes terug naar actieve aanbiedingen — dat is de grootste valkuil in de community.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Verkochte pagina {page_num aan het scrapen...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Alleen daadwerkelijk verkochte items opnemen (groene POSITIVE-prijs)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Niet-verkochte afgeronde aanbieding — overslaan
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Verkoopdatum parsen
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldHet belangrijkste verschil in de HTML: verkochte items tonen de prijs in groen (binnen een .POSITIVE wrapper), terwijl niet-verkochte afgeronde listings de prijs rood en doorgestreept tonen. Filter dus altijd op die .POSITIVE-klasse.
Waarom eBay-scrapers stukgaan (en hoe je ze robuust maakt)
Als je eBay-scraper is gestopt met werken, ben je zeker niet de enige. Dit is het nummer 1-probleem in elk eBay-scrapingforum dat ik heb gelezen. De vraag is niet of je scraper stukgaat — maar wanneer.
Waarom dat gebeurt:
- eBay gebruikt React-gebaseerde rendering met dynamisch gegenereerde klassenamen die veranderen bij deploys
- A/B-tests serveren verschillende DOM-structuren aan verschillende gebruikers (de dubbele
s-item/s-card-layout is nu een live voorbeeld) - Periodieke redesigns veranderen de HTML-nesting, ook als de data hetzelfde blijft
- Oude selectors zoals
#itemTitleen#prcIsumzijn jaren geleden verwijderd, maar duiken nog steeds op in tutorials
Zoals het zegt: “De echte uitdaging bij eBay web scraping is het omgaan met veranderingen in eBay’s CSS-selectors. eBay past de frontend regelmatig aan, waardoor scrapers die vertrouwen op specifieke class-namen kapotgaan.”

Beschermingsstrategieën voor eBay-scrapers die lang meegaan
Vier strategieën die de kwartaalwissels van eBay overleven:
1. Geef prioriteit aan JSON-LD boven CSS-selectors. eBay embedt gestructureerde Product-schema-data op elke itempagina. De datalaag verandert veel minder dan de presentatielaag — designers refactoren CSS-klassen elk kwartaal, maar backend-veldnamen zoals price, name en seller hangen aan interne API’s en krijgen zelden een nieuwe naam.
2. Gebruik fallback-selectors in lagen. Vertrouw nooit op één enkele CSS-selector. Geef altijd alternatieven op:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Parse verborgen JSON-blobs. Het MSKU-variantobject en inline JavaScript-data overleven CSS-wijzigingen omdat ze server-side worden gegenereerd. Regex-extractie uit <script>-tags vraagt vooraf meer werk, maar scheelt enorm in onderhoud.
4. Log selector-fouten. Voeg monitoring toe zodat je weet wanneer een selector niet meer matcht, niet alleen dat je data leeg is:
1if title is None:
2 print(f"WAARSCHUWING: title-selector faalde voor {url}")5. Gebruik curl_cffi met browser-impersonatie. Daarmee omzeil je Akamai’s TLS-fingerprinting zonder headless browser.
Het AI-alternatief: geen selector-onderhoud meer
Als je het beu bent om elke paar maanden selectors te repareren, is er een fundamenteel andere aanpak. Tools zoals gebruiken AI om de pagina elke keer opnieuw te lezen en de extractielogica dynamisch af te leiden. Een studie van McGill University testte AI versus selector-gebaseerde scrapers op 3.000 pagina’s en vond dat , terwijl branchebenchmarks wijzen op .
| Aanpak | Breekt het als eBay HTML wijzigt? | Onderhoudsinspanning |
|---|---|---|
| Hardcoded CSS-selectors | Ja, elk kwartaal | Hoog — voortdurende patches |
| Verborgen JSON / JSON-LD extractie | Zelden | Laag |
| AI-gebaseerd scrapen (Thunderbit) | Nee — AI herleidt selectors per run opnieuw | Geen |
Later leg ik de Thunderbit-workflow uitgebreider uit. Voor nu is de kern: als je een scraper bouwt die maandenlang moet draaien, investeer dan in JSON-first extractie en fallback-selectors. Wil je helemaal geen selectors onderhouden, dan is de AI-aanpak het bekijken waard.
Terugkerende eBay-scrapes automatiseren voor prijsmonitoring
Een eenmalige scrape is handig. Maar prijsmonitoring, voorraadtracking en concurrentieanalyse vragen om terugkerende dataverzameling. Elk concurrentieartikel noemt prijsmonitoring als use case, maar bijna geen enkel artikel laat zien hoe je dat daadwerkelijk automatiseert.
Optie 1: Cron jobs (Linux/macOS) of Taakplanner (Windows)
De eenvoudigste aanpak. Verpak je Python-script in een cron job. Gebruik altijd het absolute pad naar Python in je venv — cron draait met een minimale omgeving:
1crontab -e
2# Dagelijks om 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Op Windows gebruik je PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TDit vereist een machine die altijd aan staat, en je beheert proxies en anti-botmaatregelen zelf.
Optie 2: Cloud functions (serverless)
Met AWS Lambda of Google Cloud Functions kun je scrapers draaien zonder een dedicated server. Meer setupwerk — je moet dependencies bundelen, time-outs afhandelen (Lambda stopt na 15 minuten) en nog steeds proxies beheren. Maar geen serveronderhoud.
Optie 3: No-code scheduling met Thunderbit
Met de van Thunderbit kun je het interval in gewone taal beschrijven (bijv. “elke dag om 8 uur”), eBay-URL’s invoeren en op Plannen klikken. Het draait in de cloud met ingebouwde anti-bot-afhandeling.
| Aanpak | Setup-inspanning | Server nodig? | Anti-bot handling? |
|---|---|---|---|
| Cron + Python-script | Gemiddeld | Ja (machine moet altijd aan staan) | Proxies zelf beheren |
| Cloud function (Lambda) | Hoog | Nee (serverless) | Proxies zelf beheren |
| Thunderbit Scheduled Scraper | Laag (in gewone taal beschrijven) | Nee (cloud-based) | Ingebouwd |
Voor het opslaan van data uit terugkerende scrapes is een lokale SQLite-database de juiste keuze voor prijshistorie. Gebruik ON CONFLICT ... DO UPDATE (niet INSERT OR REPLACE, want dat ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Geen code willen schrijven? Zo scrape je eBay in 2 minuten met Thunderbit
Ik heb nu 2.000 woorden besteed aan Python-code. Nu wil ik eerlijk zijn over wanneer je dat niet nodig hebt.
Als je een zakelijke gebruiker bent die een eenmalig marktonderzoek doet, een reseller die vergelijkbare verkopen controleert, of een ecommerce-team dat vandaag data nodig heeft zonder dev-sprint, dan is Python vaak overkill. De setup, het onderhouden van selectors, het beheren van proxies — het is veel overhead voor “ik heb gewoon deze 200 aanbiedingen in een spreadsheet nodig.”
Hoe Thunderbit eBay scrapt (stap voor stap)
- Installeer de — geen creditcard nodig.
- Ga in Chrome naar een eBay-zoekresultaat of productpagina.
- Klik op “AI Suggest Fields” in de Thunderbit-zijbalk. De AI leest de pagina en stelt kolommen voor: Title, Price, Condition, Shipping, Seller, Rating.
- Klik op “Scrape.” De extensie loopt door de paginering heen en vult de datatabel. Specifiek voor eBay heeft Thunderbit die met één klik werken.
- Exporteer gratis naar Google Sheets, Airtable, Notion, CSV, JSON of Excel.
Het hele proces duurt minder dan 2 minuten.
Ik heb het getimed.
Subpagina-verrijking: detailpagina-data ophalen zonder extra code
Na het scrapen van een zoekresultatenpagina kan Thunderbit elke listing-detailpagina bezoeken en extra velden toevoegen — volledige specificaties, verkopersinfo, beschrijving, alle afbeeldingen. Daarmee vervangt het de 20+ regels Python-code voor subpage scraping die we eerder schreven, met één klik.
Wanneer je toch Python moet gebruiken
Python is de beste keuze wanneer je nodig hebt:
- Scraping op grote schaal (tienduizenden pagina’s per run)
- Diep aangepaste parsingslogica of datatransformaties
- Integratie in bestaande datapipelines (Airflow, dbt, Kafka)
- Fijne controle over TLS/sessiegedrag voor geavanceerde anti-botmaatregelen
- Unit economics — op miljoenen rijen is een beheerde stack goedkoper dan credits in SaaS
Voor de meeste eenmalige of middelgrote projecten is Thunderbit sneller en eenvoudiger. Voor productiepipelines op schaal geeft Python je volledige controle.
Tips om blokkades te vermijden wanneer je eBay met Python scrapt
eBay’s Akamai-laag is serieus. Wat in de praktijk echt werkt:
- Gebruik
curl_cffimetimpersonate="chrome124"— dit is de grootste verbetering ten opzichte van gewonerequests - Roteer User-Agent-strings uit een lijst met actuele browserversies (Chrome 143, Firefox 124, Safari 26)
- Voeg willekeurige vertragingen toe van — vaste intervallen zijn een fingerprint
- Gebruik residential of roterende proxies zodra je meer dan een paar dozijn pagina’s verwerkt. Datacenter-IP’s (AWS, GCP, DigitalOcean) worden snel door Akamai gemarkeerd.
- Respecteer
robots.txt— de meeste gefilterde browse-URL’s zijn expliciet verboden; itemdetailpagina’s (/itm/<id>) meestal niet - Ga netjes om met CAPTCHA’s — detecteer ze en probeer het opnieuw met een ander IP, of gebruik een CAPTCHA-oplossingsdienst
- Overbelast de server niet. Het precedent laat zien dat trespass to chattels kan gelden wanneer scraping servers daadwerkelijk vertraagt. Met 1 request/s per IP blijf je daar ruim onder.
Voor commerciële toepassingen op hoge volumes is het verstandig om de Browse API te gebruiken voor actieve aanbiedingen en alleen gericht te scrapen voor verkochte vergelijkbare items en data die de API niet blootgeeft. Die hybride aanpak is technisch én juridisch netter.
Is het legaal om eBay met Python te scrapen?
Ik ben geen advocaat, en deze blogpost is geen juridisch advies. Dus ik hou het kort.
De juridische context is verschoven in het voordeel van het scrapen van publiek beschikbare data. De belangrijkste precedenten:
- (9th Cir., 2022): scrapen van publiek toegankelijke data schendt de CFAA niet
- Van Buren v. United States (SCOTUS, 2021): beperkte de “exceeds authorized access”-bepaling van de CFAA
- (N.D. Cal., 2024): scraping zonder inloggen schendt platform-TOS niet omdat de scraper geen “user” is
Dat gezegd hebbende: eBay’s verbiedt expliciet “buy-for-me agents, LLM-gestuurde bots, of elke end-to-end flow die probeert bestellingen te plaatsen zonder menselijke review.” De lijn is duidelijk: read-only scraping van publieke pagina’s is juridisch veel sterker; checkout automatiseren niet.
Best practices: scrape alleen publiek zichtbare data. Maak geen nepaccounts aan en omzeil geen login-muren. Verkoop auteursrechtelijk beschermde listing-afbeeldingen niet in bulk door. En raadpleeg juridisch advies voor projecten op commerciële schaal.
Conclusie en belangrijkste lessen
Python is de meest flexibele manier om eBay te scrapen, maar het vraagt om doorlopend onderhoud zodra de HTML van de site verandert. Het besliskader:
- Gebruik de eBay Browse API voor stabiele, middelgrote, gestructureerde queries op actieve aanbiedingen
- Gebruik Python scraping voor verkochte aanbiedingen, reviews, variantdata en alles wat de API niet blootgeeft
- Gebruik als je eBay-data wilt zonder code te schrijven of te onderhouden
De code in deze gids is gebouwd op veerkracht: eerst JSON-LD-extractie, daarna fallback CSS-selectors, en voor varianten verborgen JSON-parsing. Die gelaagde aanpak zorgt ervoor dat je scraper niet omvalt bij de volgende frontend-redesign van eBay.
Als je de no-code route wilt proberen, kun je met de direct op eBay-pagina’s testen. En als je wilt zien hoe de werkt, ben je één klik verwijderd.
Voor meer over webscraping-tools, bekijk onze gidsen over de , , en . Je kunt ook tutorials bekijken op het .
Veelgestelde vragen
1. Kan ik eBay gratis scrapen met Python?
Ja. Alle libraries (Requests, BeautifulSoup, curl_cffi, pandas) zijn gratis en open source. De kosten ontstaan op schaal — residential proxies voor high-volume scraping kosten doorgaans $50–500 per maand, afhankelijk van bandbreedte. Voor kleine projecten (een paar honderd pagina’s) kun je vanaf je eigen IP scrapen met zorgvuldige rate limiting.
2. Hoe scrape ik eBay verkochte items en afgeronde aanbiedingen met Python?
Voeg LH_Complete=1&LH_Sold=1 toe aan je zoek-URL-parameters. Je moet beide meegeven — alleen LH_Sold=1 valt in sommige categorieën stilletjes terug op actieve aanbiedingen. Filter resultaten door te controleren op de .POSITIVE CSS-klasse op het prijselement; dat wijst op een daadwerkelijke verkoop en niet op een onverkochte verlopen listing.
3. Blokkeert eBay webscraping?
eBay gebruikt Akamai Bot Manager, die scrapers vooral detecteert via TLS-fingerprinting en gedragsanalyse. Gewone requests-calls leveren vaak 403-responses op. Met curl_cffi plus browser-impersonatie, roterende User-Agents en 3–8 seconden willekeurige vertraging tussen requests kom je al een heel eind. Residential proxies helpen op schaal.
4. Moet ik de eBay API gebruiken of webscraping?
Gebruik de Browse API voor stabiele queries op actieve aanbiedingen met middelgroot volume (tot 5.000 calls per dag). Gebruik scraping wanneer je verkoopprijshistorie, volledige variant/MSKU-data, reviews of andere velden nodig hebt die de API niet blootgeeft. De Marketplace Insights API levert technisch verkocht data, maar toegang is beperkt en wordt .
5. Wat is de makkelijkste manier om eBay te scrapen zonder te coderen?
De gebruikt AI om eBay-pagina’s te lezen, datavelden voor te stellen en aanbiedingen met één klik te extraheren. Het verwerkt paginering, detailpagina-verrijking en export naar Google Sheets, Excel, Airtable of Notion. Vooraf gebouwde maken het nog sneller voor veelvoorkomende use cases.
Meer weten