Craigslist trekt nog steeds zo’n over ongeveer 700 lokale sites — en er is nog steeds geen publieke API. Wil je gestructureerde data uit appartementadvertenties, tweedehands auto’s, vacatures of gig-opdrachten halen, dan is scrapen eigenlijk je enige optie.
Craigslist heeft echter een eigen anti-botsysteem dat genadeloos is. Het gebruikt geen Cloudflare of DataDome, maar een zelfgebouwde nginx-based rate limiter die al meer dan tien jaar wordt aangescherpt. Doe je het verkeerd, dan krijg je nog voor je tweede kop koffie een harde 403. Ik heb veel tijd besteed aan het testen van verschillende aanpakken tegen de verdediging van Craigslist, en dit is het resultaat: een actuele Python-handleiding voor 2025, geschikt voor elke categorie, met de JSON-LD-extractiemethode (de grootste verbetering ten opzichte van verouderde handleidingen), eerlijke anti-ban-strategieën, de juridische context en een no-code alternatief voor iedereen die simpelweg data wil zonder ook maar één regel code te schrijven.
Wat betekent het om Craigslist te scrapen met Python?
Webscraping van Craigslist betekent dat je met Python-scripts geautomatiseerd Craigslist-pagina’s bezoekt, de gestructureerde data verzamelt die je nodig hebt — zoals titels, prijzen, beschrijvingen, afbeeldingen, locaties en plaatsingsdata — en die opslaat in een spreadsheet, database of JSON-bestand.
Python is hiervoor de standaardkeuze vanwege het rijke ecosysteem aan bibliotheken. Met requests, BeautifulSoup, lxml en curl_cffi kun je in minder dan 100 regels een werkende Craigslist scraper bouwen. De community is enorm, dus als Craigslist iets wijzigt (en dat gebeurt), heeft iemand anders de oplossing meestal al gevonden.
Belangrijk om te weten: Craigslist biedt . De enige officiële programmatic interface is de Bulk Posting Interface (BAPI), en die is alleen voor schrijven — goedgekeurde betaalde adverteerders kunnen er advertenties mee plaatsen, maar niet ophalen. Elk "Craigslist API"-product dat je op externe platforms ziet, is dus een onofficiële scraper en geen officieel endpoint. Wil je bulkdata, dan scrape je.
Waarom Craigslist scrapen? Praktische toepassingen in de echte wereld
Craigslist is niet alleen een plek om een tweedehands bank te vinden. Het is een enorme, continu bijgewerkte dataset over tientallen sectoren. Dit zijn de partijen die er echt profijt van hebben:
| Toepassing | Wie heeft hier voordeel van? | Wat haal je eruit? |
|---|---|---|
| Monitoring van huurprijzen voor appartementen | Makelaars, huurders, PropTech-bedrijven | Prijs, m², aantal slaapkamers, wijk, breedtegraad/lengtegraad |
| Analyse van de tweedehands automarkt | Autobedrijven, consumentenapps, onderzoekers | Prijs, merk, model, bouwjaar, kilometerstand, staat |
| Onderzoek naar de arbeidsmarkt | Recruiters, arbeidseconomen, arbeidsmarktanalisten | Titel, salaris, type dienstverband, datum geplaatst |
| Leadgeneratie | Sales teams, dienstverleners | Contactgegevens, bedrijfsnamen, servicegebied |
| Concurrentieanalyse van prijzen | Lokale dienstverleners, ecommerce-teams | Prijzen van diensten, beschrijvingen, werkgebieden |
Het meest aangehaalde academische voorbeeld is de — ongeveer 500.000 Amerikaanse tweedehands autoadvertenties met 26 variabelen. Deze dataset vormde de basis voor tientallen papers, waaronder een ResearchGate-studie uit 2024 over de dynamiek van de Amerikaanse tweedehands automarkt. Ook hedgefondsen kochten geaggregeerde Craigslist-huurdata voor onderzoek naar huurtrends. En salesteams scrapen regelmatig de categorieën services en gigs voor leadgeneratie.
De rekensom is simpel: 8 uur handmatig kopiëren en plakken tegenover ongeveer 10 minuten met een goed gebouwde scraper.
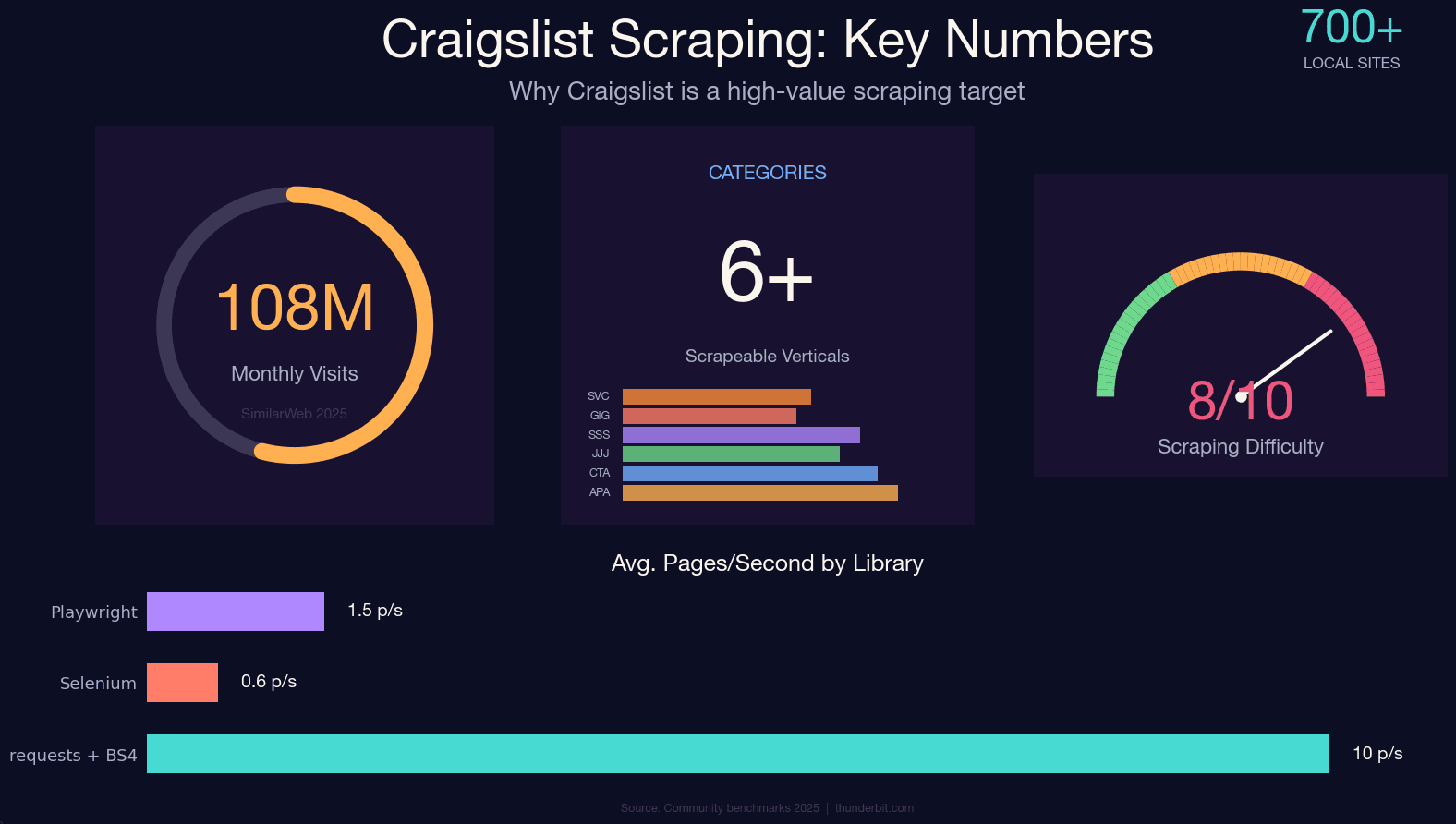
Craigslist scrapen met Python: alle categorieën, niet alleen auto’s
Bijna elke Craigslist-scrapinghandleiding die ik ben tegengekomen behandelt alleen cars-for-sale — alsof je een Google-tutorial schrijft die alleen image search bespreekt. Craigslist heeft tientallen categorieën, en de URL-structuur verschilt per categorie.
De opbouw is altijd: https://{city}.craigslist.org/search/{category_slug}
Vervang de city-subdomein en de slug, en je scrapt ineens een compleet andere sector. Hieronder staat een overzicht van de populairste categorieën (geverifieerd in april 2025):
| Categorie | URL-slug | Typische velden om uit te lezen |
|---|---|---|
| Appartementen / Woningaanbod | /search/apa | Prijs, m², slaapkamers, locatie, huisdierenbeleid |
| Auto’s & vrachtwagens | /search/cta | Prijs, merk, model, bouwjaar, kilometerstand |
| Vacatures | /search/jjj | Titel, bedrijf, salaris, type dienstverband |
| Diensten | /search/bbb | Titel, beschrijving, telefoonnummer, regio |
| Gigs | /search/ggg | Titel, vergoeding, datum, categorie |
| Te koop (algemeen) | /search/sss | Titel, prijs, staat, locatie |
Je kunt ook queryparameters stapelen om te filteren:
| Parameter | Doel | Voorbeeld |
|---|---|---|
query | Zoekterm op volledige tekst | ?query=studio |
min_price / max_price | Prijsklasse | &min_price=1500&max_price=3000 |
hasPic | Alleen advertenties met afbeeldingen | &hasPic=1 |
postedToday | Laatste 24 uur | &postedToday=1 |
sort | Sorteervolgorde | &sort=priceasc |
s | Offset voor paginering (120 per pagina) | ?s=120 |
Een URL als https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 geeft je dus appartementen in New York tussen $1.500 en $3.000 met foto’s. Elke Python scraper in deze gids werkt voor al deze categorieën — je hoeft alleen de slug te vervangen.
Craigslist HTML-selectors in 2025: oud versus nieuw (en de JSON-shortcut)
De belangrijkste reden dat Craigslist scrapers stuklopen, zijn wijzigingen in de HTML-structuur. Als je een tutorial uit 2022 volgt die je vertelt om .result-row of .result-info te gebruiken, dan is je scraper al afgeschreven.
Craigslist heeft de markup van de zoekresultaten in 2023–2024 herschreven. De oude classnamen zitten nog wel in nieuwe wrappers, maar als je ze bovenaan de DOM-boom target, krijg je gewoon een lege lijst terug. Dit is er veranderd:
| Element | Oude selector (voor 2024) | Huidige selector (2025) |
|---|---|---|
| Container van advertentie | .result-info | .cl-search-result |
| Link naar titel | .result-title | .posting-title a |
| Prijs | .result-price | .priceinfo |
| Metadata (wijk/regio) | .result-hood | .meta |
Maar hier zit de echte doorbraak — en die maakt een 2025-up-to-date scraper echt anders dan de rest: je hoeft zoekresultaten helemaal niet uit HTML te parseren.
Craigslist plaatst nu elke zichtbare listing in een <script id="ld_searchpage_results">-tag als gestructureerde JSON-LD-data. Eén requests.get()-call levert het volledige schema.org ItemList met alle advertenties op de pagina — titel, prijs, valuta, locatie, afbeeldings-URL en link naar de detailpagina. Geen JavaScript-rendering nodig. Geen kwetsbare CSS-selectors.
De JSON-LD-aanpak is sneller, stabieler en veel minder gevoelig voor UI-aanpassingen van Craigslist. Het is wat alle actief onderhouden GitHub-repos gebruiken, en ook wat we in de tutorial hieronder toepassen.
Eén kanttekening: het JSON-LD-blok is — appartementen (apa), te koop (sss), auto’s (cta), woningen (hhh). Voor vacatures (jjj), gigs (ggg), community (ccc) en diensten (bbb) ontbreekt het vaak of is het beperkt, omdat die advertenties geen schema.org/Offer-pricing hebben. Gebruik voor die categorieën de HTML-route met .cl-search-result.
Je Python-stack kiezen: Requests + BS4 versus Selenium versus Playwright
Dit is de vraag die in elk scrapingforum terugkomt: "Welke library moet ik gebruiken?" Voor Craigslist is het antwoord duidelijker dan voor de meeste sites.
| Factor | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| Snelheid | 5–15 pagina’s/sec (netwerkgebonden) | 0,3–1 pagina/sec | 0,5–2 pagina/sec |
| JS-gerenderde content | Nee | Ja | Ja |
| Geheugenverbruik | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| Complexiteit van setup | Laag | Gemiddeld | Gemiddeld |
| Bestendigheid tegen anti-bot | Laag (headers/proxy’s nodig) | Gemiddeld (echte browser) | Gemiddeld-hoog |
| Beste Craigslist-toepassing | Zoekresultaten (JSON-LD) | Detailpagina’s met dynamische content | Grootschalig async scrapen |
| Leercurve | Beginnersvriendelijk | Gemiddeld | Gemiddeld |
Craigslist-pagina’s worden server-side gerenderd. De JSON-LD-blok staat al in de initiële HTML. Er is geen JavaScript-uitdaging op leesroutes. Elke actief onderhouden gebruikt requests + BeautifulSoup of Scrapy. Geen Selenium of Playwright. Dat is geen toeval — een browserautomatiseringsframework voegt honderden MB geheugenverbruik toe, een 10–100× snelheidsverlies en een opvallender fingerprint, zonder voordeel.
Mijn advies:
- requests + BS4: begin hier. Het sluit perfect aan op de JSON-LD-extractiemethode en dekt 95% van de Craigslist-behoefte.
- Selenium: alleen als je moet interacteren met dynamische content op specifieke detailpagina’s (zeldzaam op Craigslist).
- Playwright: als je naar duizenden pagina’s schaalt met async concurrency — maar eerlijk gezegd is de rate limiter van Craigslist de bottleneck, niet de throughput van je library.
We hebben de -vergelijking en een overzicht van de apart besproken als je de volledige vergelijking wilt.
Het no-code alternatief: Craigslist scrapen zonder Python te schrijven
Even een korte omweg voor de code begint — dit deel is voor iedereen die geen developer is. Makelaars, sales teams, operations managers — als je alleen de data wilt en geen Python wilt schrijven, is er een snellere route.
is een AI webscraper als Chrome-extensie. Daarmee kun je Craigslist in ongeveer 2 klikken scrapen, zonder code. Zo werkt het:
- Ga naar een Craigslist-pagina met zoekresultaten (appartementen, auto’s, vacatures — elke categorie).
- Klik op "AI Suggest Fields" in de Thunderbit-zijbalk. De AI leest de pagina en herkent automatisch kolommen zoals advertentietitel, prijs, locatie en link.
- Klik op "Scrape" — de data wordt binnen enkele seconden opgehaald.
- Gebruik Subpage Scraping om elke detailpagina te bezoeken en je data te verrijken met volledige beschrijvingen, telefoonnummers, afbeeldingen en kenmerken.
- Exporteer direct naar Google Sheets, Excel, Airtable of Notion — helemaal gratis.
Voor terugkerende taken — zoals dagelijkse monitoring van huurprijzen of wekelijkse snapshots van vacatures — laat Thunderbit’s Scheduled Scraper je het schema in gewone taal beschrijven, waarna alles automatisch draait. Geen cronjobs, geen serverconfiguratie.
Thunderbit regelt ook anti-botmaatregelen via de Cloud Scraping-modus, dus je hoeft je geen zorgen te maken over roterende proxies of het handmatig samenstellen van headers. Wil je het proberen, pak dan de en zie het zelf.
Wil je volledige controle en maatwerk, lees dan verder voor de Python-stap-voor-stapgids.
Stap voor stap: hoe je Craigslist scrapt met Python (volledige handleiding)
- Moeilijkheidsgraad: gemiddeld
- Benodigde tijd: ~30 minuten (setup + eerste scrape)
- Wat je nodig hebt: Python 3.8+, Chrome-browser (om pagina’s te inspecteren), een terminal
Stap 1: zet je Python-omgeving op
Installeer de benodigde libraries:
1pip install requests beautifulsoup4 lxmllxml is optioneel, maar maakt het parsen met BeautifulSoup merkbaar sneller. Als je later TLS fingerprinting-problemen tegenkomt (meer daarover in het anti-ban-gedeelte), kun je ook curl_cffi installeren:
1pip install curl_cffiJe importblok:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomJe hebt nu een schone Python-omgeving met alle dependencies geïnstalleerd.
Stap 2: bouw de Craigslist-URL voor elke categorie
Stel de doellink dynamisch samen met city + category slug + optionele filters:
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# Voorbeeld: appartementen in New York, $1500-$3000, met foto’s
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1Vervang "apa" door "cta" (auto’s), "jjj" (vacatures), "bbb" (diensten) of een andere slug uit de categorietabel hierboven. Vervang "newyork" door "sfbay", "chicago", "losangeles", enzovoort.
Stap 3: haal de pagina op en extraheer ingebedde JSON
Stuur een GET-request met correcte headers en parse vervolgens het JSON-LD-blok:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}Als tag None is, dan is het JSON-LD-blok niet aanwezig voor die categorie — val dan terug op HTML-parsing (zie de selector-tabel hierboven). Voor appartementen, auto’s en te koop-categorieën is het JSON-LD-blok doorgaans beschikbaar.
Stap 4: parse listingdata naar gestructureerde records
Loop door de JSON-items en haal de velden op die je nodig hebt:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Found {len(listings)} listings")Je zou iets moeten zien als "Found 120 listings" (Craigslist toont 120 resultaten per pagina). Sommige advertenties kunnen None als prijs hebben als de plaatser geen prijs heeft ingevuld — ga daar in je verdere logica netjes mee om.
Stap 5: scrape detailpagina’s voor rijkere data
Zoekresultaten geven alleen samenvattende informatie. Voor volledige beschrijvingen, kenmerken (aantal slaapkamers, m², huisdierenbeleid), coördinaten en afbeeldingen moet je elke detail-URL bezoeken.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # cruciale anti-ban-jitterDe time.sleep(random.uniform(3, 6)) is niet optioneel. Sla je dit over, dan loop je binnen enkele tientallen verzoeken tegen een 403 aan. Detailpagina’s zijn server-rendered met stabiele selectors (#titletextonly, #postingbody, #map) die sinds ongeveer 2017 nauwelijks zijn veranderd — een van de weinige betrouwbare dingen aan Craigslist.
Stap 6: paginering afhandelen om alle resultaten te scrapen
Craigslist gebruikt een ?s=120 offset-parameter voor paginering. Elke pagina toont 120 resultaten, en de maximale offset is doorgaans 2999.
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))Probeer niet duizenden pagina’s razendsnel te scrapen. Craigslist’s rate limiter werkt per IP, en de duurzame throughput met één IP ligt ongeveer op 0,3–0,5 requests per seconde, ongeacht welke library je gebruikt. Die bovengrens wordt door Craigslist bepaald, niet door Python.
Stap 7: exporteer je Craigslist-data naar CSV, JSON of Google Sheets
Sla je resultaten op:
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)Wil je het exporteren liever helemaal overslaan, dan biedt Thunderbit gratis export naar Google Sheets, Excel, Airtable of Notion rechtstreeks vanuit de browser. Voor Python-pijplijnen zijn CSV en JSON echter de standaard. Je kunt de data ook direct in pandas verwerken voor analyse of in een database laden met sqlite3.
Hoe je voorkomt dat je geblokkeerd wordt bij het scrapen van Craigslist met Python
Veel handleidingen gaan hier te snel overheen. Craigslist heeft een eigen anti-botsysteem en dat heeft een paar specifieke eigenaardigheden.

Gebruik realistische request-headers
Craigslist valideert de volgorde en volledigheid van headers. Een request zonder Sec-Fetch-Dest of met een verouderde User-Agent wordt al afgevangen voordat het de content bereikt. De volledige Chrome 120+-header-set (zoals hierboven in stap 3) is het minimum. Wissel je User-Agent per sessie tussen 5–10 recente Chrome/Firefox desktop-strings — maar verander hem niet midden in een sessie, want dat oogt onnatuurlijk.
Ontbrekende Sec-Fetch-* headers zijn de meest voorkomende oorzaak van directe blokkades bij beginnende scrapers.
Voeg willekeurige vertragingen toe tussen requests
De consensus uit (ScrapingBee, Scraperly, Oxylabs, Multilogin) komt uit op willekeurig 2–5 seconden tussen zoekpagina’s en 3–6 seconden tussen detailpagina’s. Constante intervallen lijken op botgedrag. Gebruik time.sleep(random.uniform(2, 5)) — nooit time.sleep(2).
Roteer proxies als je op schaal scrapt
Craigslist blokkeert vooraf hele AWS-, GCP- en Azure-IP-bereiken. Datacenter-proxy’s zijn daardoor vaak meteen onbruikbaar. Voor alles boven een paar honderd pagina’s heb je residential rotating proxies nodig, die je elke 20–30 requests roteert. Mobile proxies hebben het laagste detectierisico, maar kosten $8–30/GB.
| Proxytype | Detectierisico op Craigslist | Kosten (2025) |
|---|---|---|
| Datacenter | Zeer hoog — vaak al geblokkeerd bij de eerste request | $0,50–2/GB |
| Residential rotating | Laag — aanbevolen | $5–15/GB |
| Mobile | Laagst | $8–30/GB |
Thunderbit’s Cloud Scraping-modus regelt proxy-rotatie automatisch als je dat liever niet zelf beheert.
Ga netjes om met CAPTCHA’s
CAPTCHA’s op Craigslist zijn zeldzaam op leesroutes — ze verschijnen vooral bij posten of reageren. Als je er toch een tegenkomt: wacht minstens 60 seconden, roteer het IP, wis cookies en vertraag je requests. Aanhoudende CAPTCHA’s betekenen dat je tempo te agressief is, niet dat je het met een solver moet forceren.
Respecteer rate limits en implementeer backoff
Craigslist geeft 403 (niet 429) terug wanneer je de rate limit raakt. Een 403 betekent dat het huidige IP op een denylist staat — probeer niet blind opnieuw. Roteer het IP, wijzig de UA en wacht.
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1,5, 3, 6, 12, 24s
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)Nog een tip: meldingen uit de community noemen consequent 2–6 uur ’s ochtends lokale tijd in de doelstad als het veiligste scrapingvenster, met ongeveer 30–40% minder blokkeringen dan overdag.
TLS fingerprinting — de verborgen valkuil
De botlaag van Craigslist bekijkt de TLS ClientHello. Python’s requests-bibliotheek (gebouwd op OpenSSL) heeft een JA3-fingerprint die niet overeenkomt met een echte browser. Een perfecte User-Agent-header met een niet-browser TLS-fingerprint is een detecteerbare mismatch. De workaround is met impersonate="chrome124", waarmee je de TLS-handshake van Chrome nabootst:
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")Krijg je onverklaarbare 403’s terwijl je schone residential IP’s en correcte headers gebruikt, dan is TLS fingerprinting waarschijnlijk de oorzaak.
Craigslist robots.txt, Terms of Service en ethisch scrapen
De meeste handleidingen slaan dit helemaal over of verstoppen één zin in de FAQ. Gezien Craigslist een vonnis van heeft gewonnen tegen een scraper (RadPad, 2017), verdient dit meer aandacht dan een voetnoot.
Wat staat er eigenlijk in Craigslist’s robots.txt?
Het is verrassend kort. Het bevat één User-agent: *-blok met slechts zeven verboden paden:
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafAlle zeven zijn interactieve of muterende endpoints: reply, flag, suggest, email-a-friend. Listingpagina’s (/search/..., individuele post-URL’s) zijn niet verboden. Er staat geen Crawl-delay-directive in, al handhaaft Craigslist er wel één via IP-blokkades.
City-subdomeinen publiceren ook sitemaps — bijvoorbeeld https://newyork.craigslist.org/sitemap/index.xml — en dat zijn officieel vindbare paden naar listings.
Juridisch precedent: de belangrijkste zaken
Craigslist v. 3Taps (2013, geschikt in 2015): 3Taps scrape-te Craigslist-advertenties en verkocht die door. Toen Craigslist een cease-and-desist stuurde en hun IP’s blokkeerde, omzeilde 3Taps dat met roterende proxies. De rechtbank oordeelde dat het omzeilen van IP-blokkades na expliciete intrekking "without authorization" vormde onder de CFAA. 3Taps .
Meta v. Bright Data (2024): een recentere uitspraak stelde dat Meta’s TOS het scrapen van publiek beschikbare data door uitgelogde bezoekers niet kan verbieden. De rechtbank oordeelde dat een uitgelogde scraper "in dezelfde schoenen stond als een bezoeker". Dit is de belangrijkste uitspraak voor scrapers in 2024–2025 — als je nooit een Craigslist-account aanmaakt, nooit inlogt en alleen publiek zichtbare pagina’s bezoekt, is de TOS mogelijk niet als contract tegen je afdwingbaar.
De praktische conclusie: het CFAA-risico is na Van Buren (2021) en hiQ v. LinkedIn (2022) aanzienlijk kleiner geworden voor publiek toegankelijke pagina’s. Maar civielrechtelijke claims onder staatsrecht, zoals trespass-to-chattels en misappropriation, blijven bestaan — dat was precies wat de schikking met 3Taps en het vonnis van $60,5 miljoen in de RadPad-zaak veroorzaakte.
Dit is informatief, geen juridisch advies. Als je Craigslist commercieel scrape’t, overleg dan met een jurist.
Praktische checklist voor ethisch scrapen
- ✅ Respecteer elke
Disallowin robots.txt — vooral de zeven actie-endpoints - ✅ Blijf ruim onder 1.000 pagina’s per 24 uur per IP (Craigslist’s TOS rekent boven die drempel als liquidated damages)
- ✅ Blijf uitgelogd — maak nooit een Craigslist-account aan om te scrapen
- ✅ Omzeil IP-blokkades niet met proxies nadat je expliciet bent geblokkeerd (dat was precies het probleem bij 3Taps)
- ✅ Voeg vertragingen toe tussen requests — minimaal 2–5 seconden
- ✅ Scrape geen persoonlijke contactgegevens voor spam
- ✅ Verspreid ruwe Craigslist-data niet opnieuw of presenteer het niet als je eigen platform
- ✅ Gebruik data voor legitiem onderzoek, analyse of persoonlijk gebruik
- ✅ Geef waar mogelijk de voorkeur aan gepubliceerde sitemaps boven brute-force crawling
- ✅ Verwijder PII (e-mails, telefoonnummers) bij het inlezen als je de data opslaat
We hebben een uitgebreidere gids geschreven over de als je het volledige plaatje wilt.
Python versus no-code: welke aanpak past bij jou?
| Factor | Python (requests + BS4) | Thunderbit (No-code) |
|---|---|---|
| Setup-tijd | 30–60 min (installeren, code schrijven) | 2 minuten (Chrome-extensie installeren) |
| Benodigde technische kennis | Gemiddelde Python-kennis | Geen |
| Maatwerk | Volledige controle over logica, velden en flow | AI detecteert velden automatisch; gebruiker kan bijsturen |
| Schaal | Onbeperkt (met proxies, planning) | Scheduled Scraper voor terugkerende taken |
| Afhandeling van bans | Handmatig (headers, vertragingen, proxies, TLS) | Ingebouwd (Cloud Scraping) |
| Exportopties | CSV, JSON (zelf coderen) | Google Sheets, Excel, Airtable, Notion — gratis |
| Beste voor | Developers, data scientists, custom pipelines | Sales teams, makelaars, operations managers |
Gebruik Python als je volledige maatwerk nodig hebt, dit wilt koppelen aan een grotere datapipe of precies wilt begrijpen wat er onder de motorkap gebeurt. Gebruik als je snel resultaat wilt zonder code te schrijven of te onderhouden. Beide zijn prima — het hangt af van je use case en van de vraag of je liever in een terminal of in een browser werkt.
Afronding
Craigslist is een rijke, continu bijgewerkte databron voor woningen, auto’s, vacatures, diensten, gigs en meer — en zonder publieke API is scrapen de enige manier om op schaal gestructureerde data te krijgen. De aanpak die in 2025 echt werkt: extraheer de ingebedde JSON-LD uit zoekresultaten (niet fragiele CSS-selectors), gebruik requests + BeautifulSoup (niet Selenium), voeg realistische headers met Sec-Fetch-*-velden toe, randomiseer vertragingen en gebruik residential proxies als je verder gaat dan een paar honderd pagina’s.
De JSON-LD-methode is de grootste verbetering ten opzichte van verouderde handleidingen. Het is sneller, robuuster tegen lay-outwijzigingen en vereist geen JavaScript-rendering. Combineer dit met de anti-ban-strategieën hierboven en je voorkomt de 403’s waar de meeste scrapers tegenaan lopen.
Als je de code liever helemaal overslaat, kan de elke Craigslist-categorie in een paar klikken scrapen en direct exporteren naar je favoriete spreadsheet of database. Wil je dieper gaan, dan behandelen onze gidsen over en de basis uitgebreider.
Veelgestelde vragen
Is het legaal om Craigslist te scrapen?
Craigslist’s Terms of Use verbieden geautomatiseerd scrapen en bevatten een liquidated-damages-clausule ($0,25/pagina boven 1.000/dag). Recente gerechtelijke uitspraken — vooral Meta v. Bright Data (2024) en hiQ v. LinkedIn (2022) — hebben de CFAA-aansprakelijkheid voor het scrapen van publiek beschikbare, uitgelogde data echter beperkt. Civielrechtelijke claims onder staatsrecht (trespass-to-chattels) blijven een risico, vooral bij commerciële herdistributie. Respecteer robots.txt, blijf uitgelogd, voeg vertragingen toe en verspreid ruwe data niet opnieuw. Dit is algemene informatie, geen juridisch advies.
Heeft Craigslist een publieke API?
Nee. Craigslist biedt alleen een write-only Bulk Posting Interface (BAPI) voor goedgekeurde betaalde adverteerders. Er is geen publieke read API, geen developer portal en geen rate-limited tier voor datatoegang. Elk "Craigslist API"-product op externe platforms is in feite een onofficiële scraper.
Waarom blijft mijn Craigslist scraper stuklopen?
Bijna altijd door wijzigingen in de HTML-structuur. Craigslist heeft de markup van de zoekresultaten in 2023–2024 herschreven, en handleidingen die nog werken met legacy-selectors zoals .result-row of .result-info functioneren niet meer. Stap over op de ingebedde JSON-LD-methode (parsen van script#ld_searchpage_results) voor een veel robuustere aanpak. Controleer ook of je headers Sec-Fetch-*-velden bevatten — ontbreken die, dan volgt vaak direct een blokkade.
Kan ik Craigslist scrapen zonder Python?
Ja. Thunderbit’s AI web scraper Chrome-extensie werkt op elke Craigslist-pagina — appartementen, auto’s, vacatures, diensten. Klik op "AI Suggest Fields" om kolommen automatisch te detecteren, klik op "Scrape" om data te verzamelen en exporteer gratis naar Google Sheets, Excel, Airtable of Notion. Geen code, geen setup, geen proxybeheer.
Hoe vaak kan ik Craigslist scrapen zonder geblokkeerd te worden?
Met één residential IP ligt de duurzame throughput rond 0,3–0,5 requests per seconde, met willekeurige vertragingen van 2–5 seconden tussen pagina’s. Blijf onder 1.000 pagina’s per 24 uur per IP om zowel blokkades als de liquidated-damages-drempel in Craigslist’s TOS te vermijden. Scrapen tijdens rustige uren (2–6 uur ’s ochtends lokale tijd in de doelstad) verlaagt de blokkaderatio met ongeveer 30–40%. Voor grotere volumes roteer je residential proxies elke 20–30 requests.
Meer lezen