Executive summary
stelde een beleidsvraag: hoeveel van de meest bezochte websites ter wereld vertellen AI-crawlers wat ze wel en niet mogen doen?
Deze vervolgstudie stelt de operationele vraag daarachter: hoe betrouwbaar is robots.txt als infrastructuur die dat beleid nu moet dragen?
Het antwoord is ongemakkelijk. robots.txt werkt nog steeds omdat het openbaar, goedkoop, machineleesbaar en al bekend is bij crawlers. Maar inmiddels moet het veel meer doen dan waarvoor het ooit bedoeld was. In 2026 kan hetzelfde platte tekstbestand SEO-crawlregels, sitemap-indexen, verouderde extensies voor zoekmachines, opt-outs voor AI-training, beleidsvocabulaire van Cloudflare, auteursrechtelijke voorbehouden en juridische taal voor toekomstige geschillen bevatten.
Dat is configuratieschuld.
De dataset achter dit rapport is dezelfde Tranco Top 10.000-crawl als in de oorspronkelijke studie naar AI-crawlers. Van de 10.000 domeinen gaven 6.638 een leesbare robots.txt terug; nog eens 610 gaven 404 terug, wat volgens het protocol geldt als impliciete toestemming. Dat levert 7.248 analyseerbare sites op voor beslissingen over bot-toegang en 6.638 concrete bestanden voor analyse van configuratiecomplexiteit.
Zes bevindingen springen eruit:
-
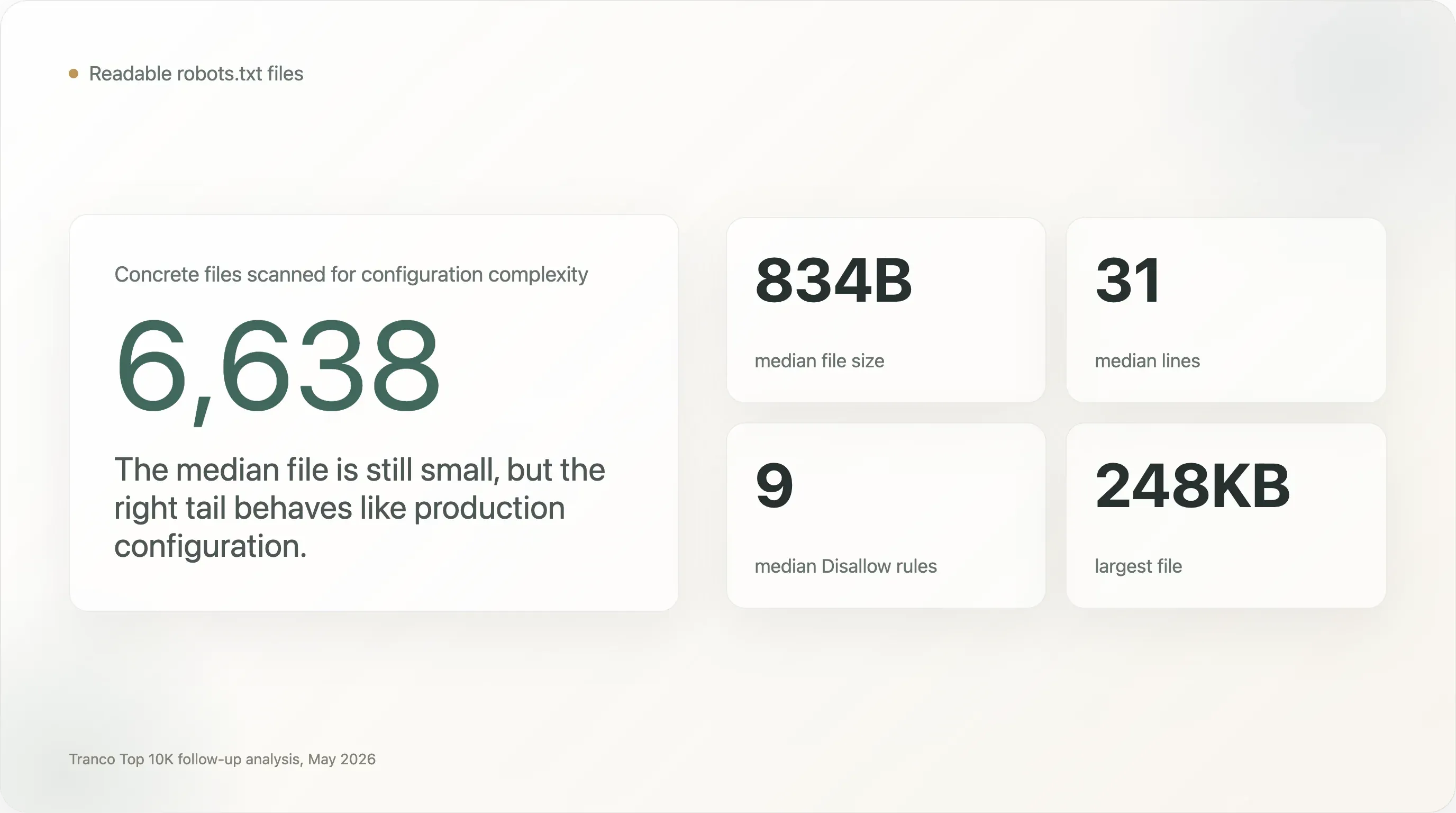
De meeste
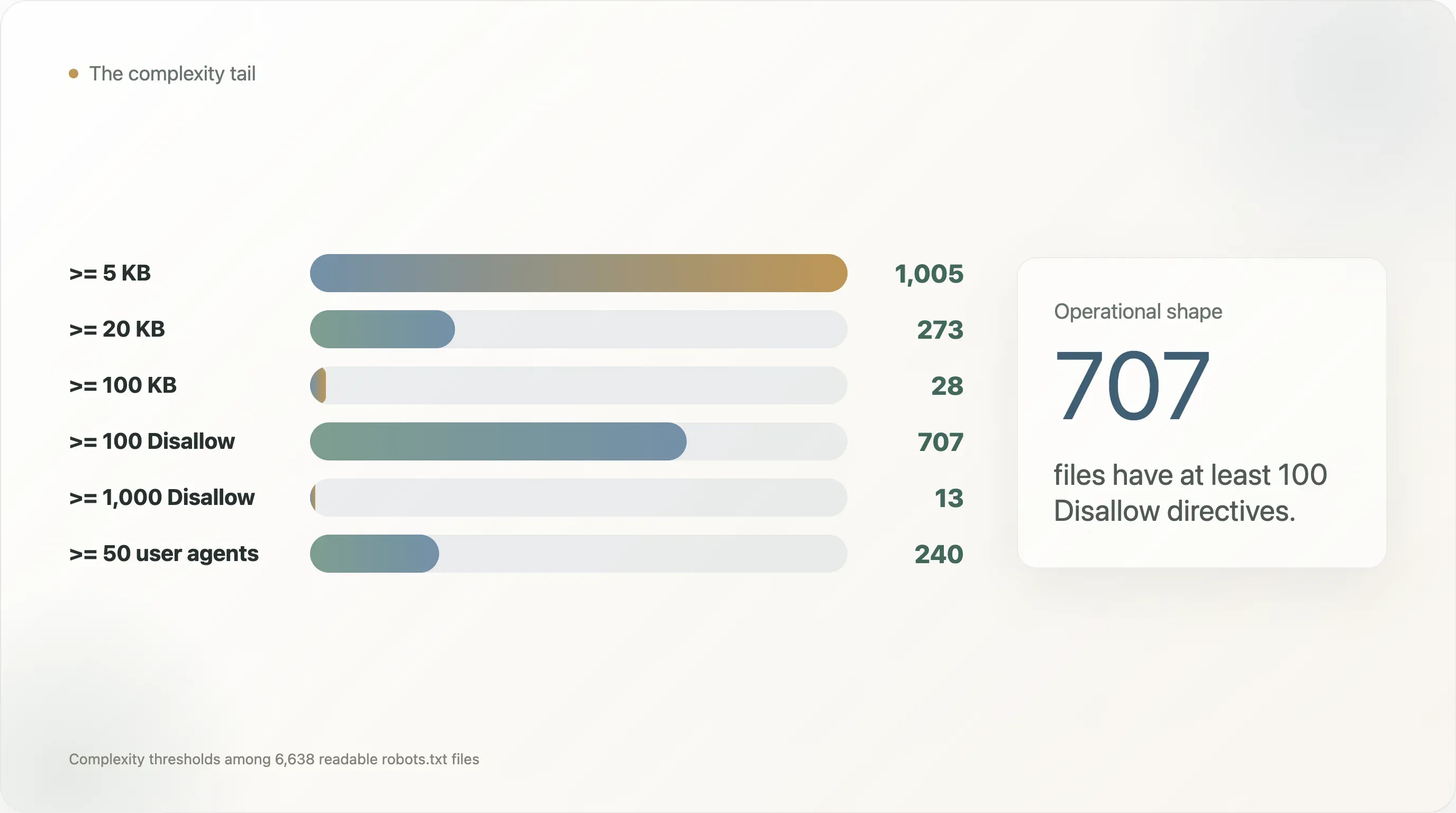
robots.txt-bestanden zijn klein, maar de rechterstaart is extreem complex. Het mediane bestand is slechts 834 bytes en 31 regels. Maar 1.005 bestanden zijn minstens 5 KB, 273 zijn minstens 20 KB en 28 zijn minstens 100 KB. Het grootste bestand in de steekproef is 248 KB. -
Honderden toonaangevende websites draaien bestanden die meer weg hebben van productieconfiguratie dan van beleidsnotities. Het mediane bestand heeft 9
Disallow-regels. Maar 707 sites hebben minstens 100Disallow-regels, 13 hebben er minstens 1.000, 240 noemen minstens 50 user agents en 110 noemen minstens 100 user agents. -
Protocoldrift is niet theoretisch. Onder de 6.638 leesbare bestanden bevatten er 685
Crawl-delay, 303Host, 200Clean-param, 9Request-rate, 5Visit-timeen 271 Cloudflare-achtigeContent-Signal-taal. Niet al deze onderdelen horen bij dezelfde zuivere standaard. Het is opgestapelde crawlerfolklore. -
Googlebot wordt als een speciale burger behandeld. 562 analyseerbare domeinen blokkeren ten minste één traditionele zoekcrawler. In 404 van die gevallen is Googlebot toegestaan terwijl ten minste één andere zoekcrawler wordt geblokkeerd. Discriminatie tussen AI-crawlers ontstond dus niet in een neutraal ecosysteem;
robots.txthad al een hiërarchie tussen zoekmachines ingebouwd. -
AI-beleid maakt de schuld zichtbaarder. 1.377 leesbare bestanden bevatten AI-beleids-taal; 719 bevatten auteursrecht-, voorwaarden-, licentie- of toestemmings-taal; en 501 bevatten beide. Het bestand is daarmee tegelijk machine-interface en juridisch artefact geworden. Dat is nuttig, maar kwetsbaar.
-
De risicovolste bestanden zijn niet altijd de meest anti-AI-bestanden. Ecommerce, reizen, sociale media, financiën, academische sites en nieuws maken allemaal complexe bestanden om verschillende redenen: controle van crawlbudget, verouderde paden, door gebruikers gemaakte content, voorbehouden van rechten en botspecifieke uitzonderingen. AI-regels worden boven op een al rommelige basis gelegd.
De belangrijkste conclusie: robots.txt blijft het belangrijkste openbare oppervlak voor crawlerbeleid op het web, maar is een zwakke basis voor AI-governance met hoge inzet, tenzij het ecosysteem crawleridentiteit, vocabulaire voor AI-gebruik en controleerbaarheid van beleid standaardiseert.
Methode
Dit rapport hergebruikt de dataset uit de oorspronkelijke Thunderbit-analyse van AI-crawlerbeleid op de Tranco Top 10.000-domeinen.
De gebruikte bronbestanden waren:
tranco_top10k.csv— de oorspronkelijke Tranco Top 10K-domeinlijst.out/fetch_meta.csv— fetchstatus, byte-aantal, schema, redirectresultaat en foutmetadata.out/sites.csv— domein, rang, categorie, taal enrobots.txt-status.out/site_meta.csv— één analytische rij per site, met onder meer sjabloonklasse, AI-blokkeerflags, bestandsgrootte en samenvattende velden voor botbeleid.out/bot_status.csv— één rij per domein en crawler, inclusief of die bot wordt geblokkeerd en of een specifieke regel bestaat.raw_robots/— gecachterobots.txt-inhouden voor de 6.638 sites die status200teruggaven.
Voor deze vervolgstudie is elk leesbaar robots.txt-bestand gescand op:
- bestandsgrootte en aantal regels;
- actieve niet-opmerkingsregels;
- aantallen
User-agent-,Disallow-,Allow- enSitemap-regels; - verouderde of niet-kernregels zoals
Crawl-delay,Host,Clean-param,Request-rateenVisit-time; - AI-tijdperk-vocabulaire zoals
Content-Signal,llms.txt, AI, LLM, machine learning, TDM en2019/790; - juridische vocabulaire zoals auteursrecht, voorwaarden, licenties, toestemming en taal over rechtenvoorbehoud;
- behandeling van zoekcrawlers voor Googlebot, Bingbot, DuckDuckBot, Slurp, Baiduspider en YandexBot.
Het rapport definieert ook een eenvoudige configuratieschuldscore voor triage. Die combineert bestandsgrootte, aantal user agents, aantal Disallow-regels, aantal Allow-regels, aantal niet-standaardregels en de mix van AI-beleids- en juridische taal. De score is niet bedoeld als universele maat voor juistheid. Het is een manier om bestanden te identificeren die waarschijnlijk lastig te onderhouden, te beoordelen of te interpreteren zijn.
Alle afgeleide tabellen en grafieken zitten in de leveringsmap.
Bevinding 1: Het mediane bestand is eenvoudig; de staart is dat niet
Het typische robots.txt-bestand op het topweb is nog steeds klein.
Over de 6.638 leesbare bestanden heen:
| Metriek | Mediaan | P90 | P95 | P99 | Max |
|---|---|---|---|---|---|
| Bestandsgrootte | 834 bytes | 6,7 KB | 15,8 KB | 76,0 KB | 248,3 KB |
| Regels | 31 | 238 | 332 | 1.008 | 4.998 |
| Actieve regels | 23 | 198 | 282 | 837 | 4.998 |
User-agent-regels | 1 | 21 | 39 | 137 | 823 |
Disallow-regels | 9 | 103 | 176 | 422 | 4.997 |
Allow-regels | 1 | 17 | 33 | 69 | 890 |
Deze verdeling doet ertoe, omdat robots.txt vaak wordt besproken alsof het om een korte verklaring gaat:
1User-agent: *
2Disallow: /private/Dat mentale model klopt niet voor een betekenisvolle minderheid van het web met veel verkeer.
In deze dataset:
This paragraph contains content that cannot be parsed and has been skipped.
De grootste en meest complexe bestanden zijn geen academische curiositeiten. Ze horen bij echte, drukbezochte properties:
| Domein | Rang | Categorie | Bytes | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114.341 | 76 | 4.184 | 281 |
runescape.com | 5.226 | unknown | 113.393 | 1 | 4.997 | 0 |
academia.edu | 832 | academia | 57.384 | 63 | 2.044 | 227 |
etsy.com | 286 | ecommerce | 51.320 | 3 | 1.621 | 120 |
thepaper.cn | 9.395 | news | 56.867 | 1 | 1.496 | 0 |
opentable.com | 4.137 | unknown | 70.494 | 32 | 1.683 | 176 |
alfabank.ru | 2.625 | finance | 73.158 | 2 | 1.566 | 133 |
Deze bestanden lijken meer op productie-routingtabellen dan op beleidsleuzen. Ze coderen jaren aan productlanceringen, verouderde paden, geblokkeerde parameterpatronen, crawleruitzonderingen, SEO-experimenten, CDN-beslissingen en nu ook AI-crawlerregels.
De staart gaat niet alleen over AI. Van de 273 bestanden van 20 KB of groter bevatten er 131 AI-beleids-taal en 142 niet. Van de 707 bestanden met minstens 100 Disallow-regels bevatten er slechts 207 AI-beleids-taal. Met andere woorden: AI heeft het grote-bestandsprobleem niet veroorzaakt. Het kwam later, nadat jaren van gewone weboperaties het bestand al hadden gevuld met padregels, sitemapverwijzingen en crawleruitzonderingen.
Dat is belangrijk, omdat onderhoudbaarheid afhangt van vorm, niet alleen van intentie. Een klein bestand met een directe AI-blokkering kan eenvoudig te auditen zijn. Een ecommerce- of reisbestand van 70 KB kan lastig te auditen zijn, zelfs als het niets over AI zegt. Het risico is niet dat elk groot bestand fout is. Het risico is dat het werkelijke beleid te moeilijk wordt voor de verantwoordelijken om te verifiëren.
Het operationele risico is eenvoudig: naarmate robots.txt groeit, wordt het moeilijker voor een uitgever, platformengineer, jurist of SEO-lead om de basisvraag te beantwoorden: wat staat dit bestand eigenlijk toe?
Die vraag is niet langer triviaal. Volgens RFC-achtige parsing kan een crawler een specifieker user-agentblok matchen in plaats van User-agent: *; langere padmatches kunnen kortere overschrijven; Allow- en Disallow-regels werken via voorrang samen; en algemene weiger-alles-regels kunnen per ongeluk nieuwe crawlers meenemen die nog niet bestonden toen het bestand werd geschreven.
Voor een bestand van 30 regels kan een mens dat nog overzien. Voor een bestand van 4.000 regels met tientallen benoemde bots zou niemand dat moeten proberen.
Bevinding 2: robots.txt draagt meer dan alleen crawlregels
Het debat over AI-crawlers maakte robots.txt politiek zichtbaar, maar het onderliggende bestand had al eerder taken op zich genomen die er niets mee te maken hebben.
Een modern robots.txt-bestand van een topwebsite kan bevatten:
- padcontrole voor crawlers;
- ontdekking van sitemaps;
- extensies specifiek voor zoekmachines;
- hints over crawlsnelheid;
- hints voor canonicalisatie van hosts;
- hints voor opschoning van URL-parameters;
- beleidsvocabulaire ingevoegd door een CDN;
- tekst over auteursrechtvoorbehoud;
- opt-outs voor AI-training;
- juridisch leesbare commentaarregels.
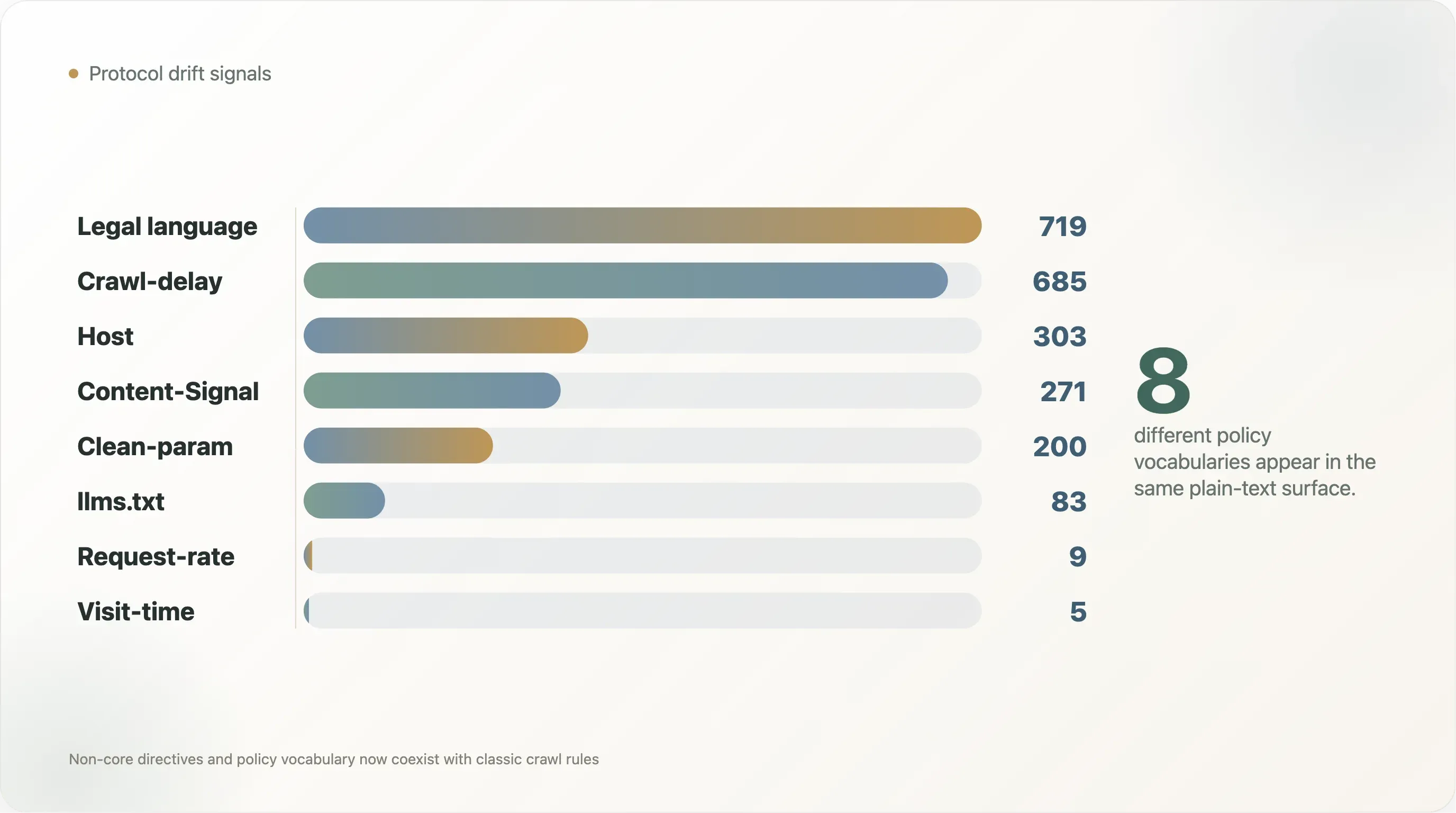
De dataset laat deze gelaagdheid duidelijk zien.
| Signaal | Bestanden | Aandeel van leesbare bestanden |
|---|---|---|
Crawl-delay | 685 | 10,3% |
Host | 303 | 4,6% |
Clean-param | 200 | 3,0% |
Content-Signal | 271 | 4,1% |
Request-rate | 9 | 0,1% |
Visit-time | 5 | 0,1% |
Vermelding van llms.txt | 83 | 1,3% |
| Auteursrecht-, voorwaarden-, licentie- of toestemmings-taal | 719 | 10,8% |
| AI-beleids-taal | 1.377 | 20,7% |
Sommige van deze regels worden breed herkend door specifieke crawlers. Sommige zijn verouderde conventies. Sommige zijn leverancier-specifiek. Sommige zijn helemaal geen crawlerregels, maar juridische of producttaal ingebed in opmerkingen.
Zo ziet protocoldrift eruit.
Crawl-delay is een goed voorbeeld. Veel sitebeheerders kennen het, maar de ondersteuning is ongelijk verdeeld over grote crawlers. Host en Clean-param werden historisch met Yandex-gedrag geassocieerd. Content-Signal maakt deel uit van Cloudflare’s beleidsvocabulaire uit het AI-tijdperk. llms.txt is een voorgesteld aanvullend ontdekkingsformaat, geen universeel erkende standaard. Toch komen ze allemaal voor in hetzelfde soort bestand, vaak naast klassieke User-agent- en Disallow-regels.
De cijfers laten ook zien hoe oude en nieuwe conventies nu naast elkaar bestaan. Crawl-delay komt voor in 685 bestanden, meer dan twee keer zoveel als de 271 bestanden met Content-Signal. Host komt voor in 303 bestanden en Clean-param in 200, vooral als weerspiegeling van zoekmachineconventies uit het verleden. llms.txt wordt, ondanks veel discussie in AI-searchkringen, slechts in 83 leesbare bestanden genoemd. Het live web convergeert niet op één vocabulaire. Het stapelt vocabularia op.
Het probleem is niet dat een enkele extensie fout is. Het probleem is dat het bestand een onverversioneerde container is geworden voor meerdere overlappende governance-systemen.
Dat creëert drie soorten schuld:
- Semantische schuld. Verschillende crawlers kunnen hetzelfde bestand anders interpreteren.
- Eigenaarschuld. SEO-, juridische, infrastructuur-, security- en productteams kunnen allemaal redenen hebben om het bestand te bewerken, maar geen enkel team bezit misschien het volledige beleid.
- Auditschuld. Een site kan een beleid publiceren dat intentioneel oogt, terwijl alleen een parser het werkelijke gedrag kan bepalen.
AI maakt dit belangrijker omdat de inzet veranderd is. Wanneer een verouderde hint over crawlsnelheid wordt genegeerd, kan het resultaat extra verkeer zijn. Wanneer een opt-out voor AI-training dubbelzinnig is, kan het resultaat bewijs worden in een auteursrecht- of licentiekwestie.
Bevinding 3: Het bestand is zowel machine-interface als juridisch artefact geworden
Het oorspronkelijke rapport over AI-crawlers liet zien dat 17,0% van de analyseerbare sites expliciete AI-specifieke regels had geschreven. Deze vervolgstudie kijkt naar de tekstuele last die dat beleid toevoegt.
Onder de 6.638 leesbare robots.txt-bestanden:
- 1.377 bevatten AI-beleids-taal;
- 719 bevatten auteursrecht-, voorwaarden-, licentie-, rechten- of toestemmings-taal;
- 271 bevatten
Content-Signal; - 83 vermelden
llms.txt.
De overlap is waar het verhaal interessanter wordt:
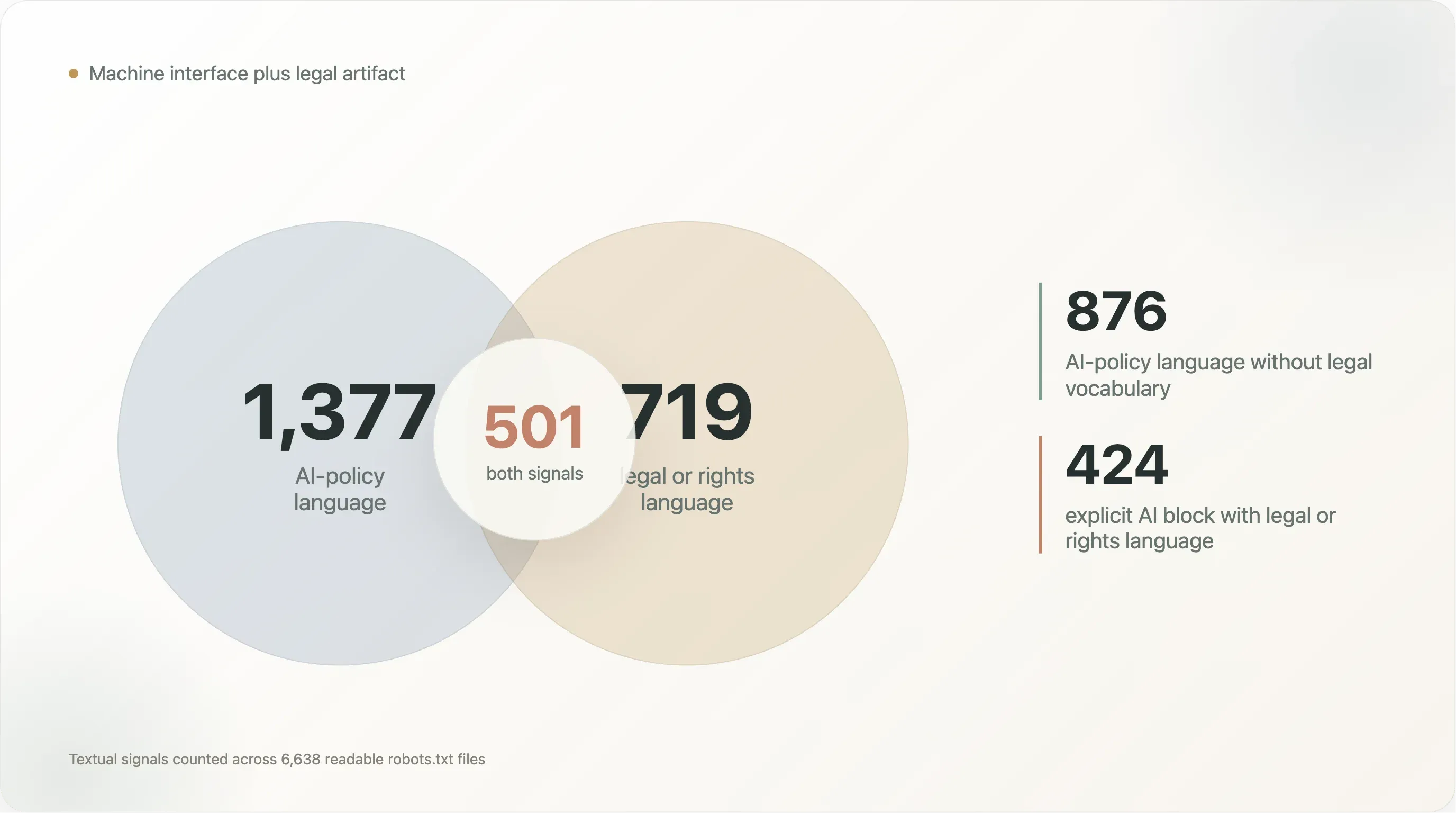
| Tekstpatroon | Bestanden |
|---|---|
| AI-beleids-taal en juridische/rechten-taal | 501 |
| AI-beleids-taal zonder juridische/rechten-taal | 876 |
| Juridische/rechten-taal zonder AI-beleids-taal | 218 |
Content-Signal met juridische/rechten-taal | 242 |
| Expliciete AI-blokkering met juridische/rechten-taal | 424 |
Dit is een nieuw soort bestand.
Een traditioneel robots.txt-bestand is gericht aan crawlers. Een robots.txt-bestand met een juridische preambule is gericht aan minstens vier doelgroepen tegelijk:
- crawleroperators, die machineleesbare regels nodig hebben;
- zoek- en AI-leveranciers, die beleidsignalen nodig hebben;
- juristen, die expliciet rechtenvoorbehoud willen;
- toekomstige auditors, rechters of journalisten, die de opmerkingen kunnen lezen als bewijs van intentie.
Die ontwerpkeuze voor meerdere doelgroepen verklaart waarom sommige bestanden nu als beleidsdocumenten lezen. Maar ze verzwakt ook de strakke scheiding tussen wat een crawler kan parseren en wat een menselijke jurist wil verklaren.
De 876 bestanden met AI-beleids-taal maar zonder juridische woordenschat zijn vooral machinebeleidsbestanden: botnamen, Disallow-blokken en sjabloontaal. De 501 bestanden met zowel AI- als juridische taal zijn anders. Die proberen tegelijk crawlerinstructies en rechtenvoorbehouden te zijn. De 218 bestanden met juridische taal maar zonder AI-vocabulaire laten zien dat dit patroon niet met LLM’s begon; robots.txt werd al gebruikt om voorwaarden, grenzen aan toestemming en claims op rechten te formuleren.
Een opmerking kan bijvoorbeeld zeggen dat machine learning verboden is, terwijl de daadwerkelijke regel alleen een subset van bekende user agents blokkeert. Een site kan wereldwijd rechten voorbehouden, maar slechts een paar crawlers noemen. Een CDN-sjabloon kan AI-gerelateerde woordenschat in een bestand injecteren waarvan de beheerder de juridische taal nooit handmatig heeft geschreven. Een site kan een brede User-agent: *-regel schrijven die toekomstige crawlers onbedoeld blokkeert.
Vanuit governance-oogpunt is robots.txt juist aantrekkelijk omdat het openbaar en machineleesbaar is. Maar hoe meer beleid het draagt, hoe meer de beperkingen tellen:
- Er is geen authenticatielaag die bewijst dat een specifiek beleid is beoordeeld door de rechthebbende in plaats van geërfd uit infrastructuur.
- Er is geen native versiegeschiedenis.
- Er is geen gestructureerd veld voor beoogd gebruik, zoals training, retrieval, zoeken, samenvatten, cachen of modelevaluatie.
- Er is geen universeel register van AI-crawleridentiteiten.
- Er is geen handhavingsmechanisme.
Dat maakt het bestand niet nutteloos. Het maakt het kwetsbaar.
De betere interpretatie is dat robots.txt een meldingslaag aan het worden is: een openbare, inspecteerbare verklaring van voorkeur en intentie. Het is op zichzelf geen compleet systeem voor rechtenbeheer.
Bevinding 4: Zoekmachines waren al ongelijk behandeld vóór AI arriveerde
Een van de sterkste bevindingen in het oorspronkelijke rapport was dat veel uitgevers onderscheid maken tussen AI-trainingscrawlers en zoekcrawlers. Ze blokkeren CCBot, GPTBot of Google-Extended en laten Google-zoekzichtbaarheid intact.
Deze vervolgstudie voegt een ander punt toe: traditionele zoekcrawlers worden ook niet gelijk behandeld.
We controleerden zes zoekcrawlers:
- Googlebot;
- Bingbot;
- DuckDuckBot;
- Slurp;
- Baiduspider;
- YandexBot.
Over de 7.248 analyseerbare sites heen:
| Behandeling van zoekcrawlers | Sites |
|---|---|
| Blokkeert minstens één zoekcrawler | 562 |
| Staat Googlebot toe maar blokkeert minstens één andere zoekcrawler | 404 |
| Blokkeert alle zes gecontroleerde zoekcrawlers | 152 |
De aantallen geblokkeerde bots zijn niet gelijk verdeeld:
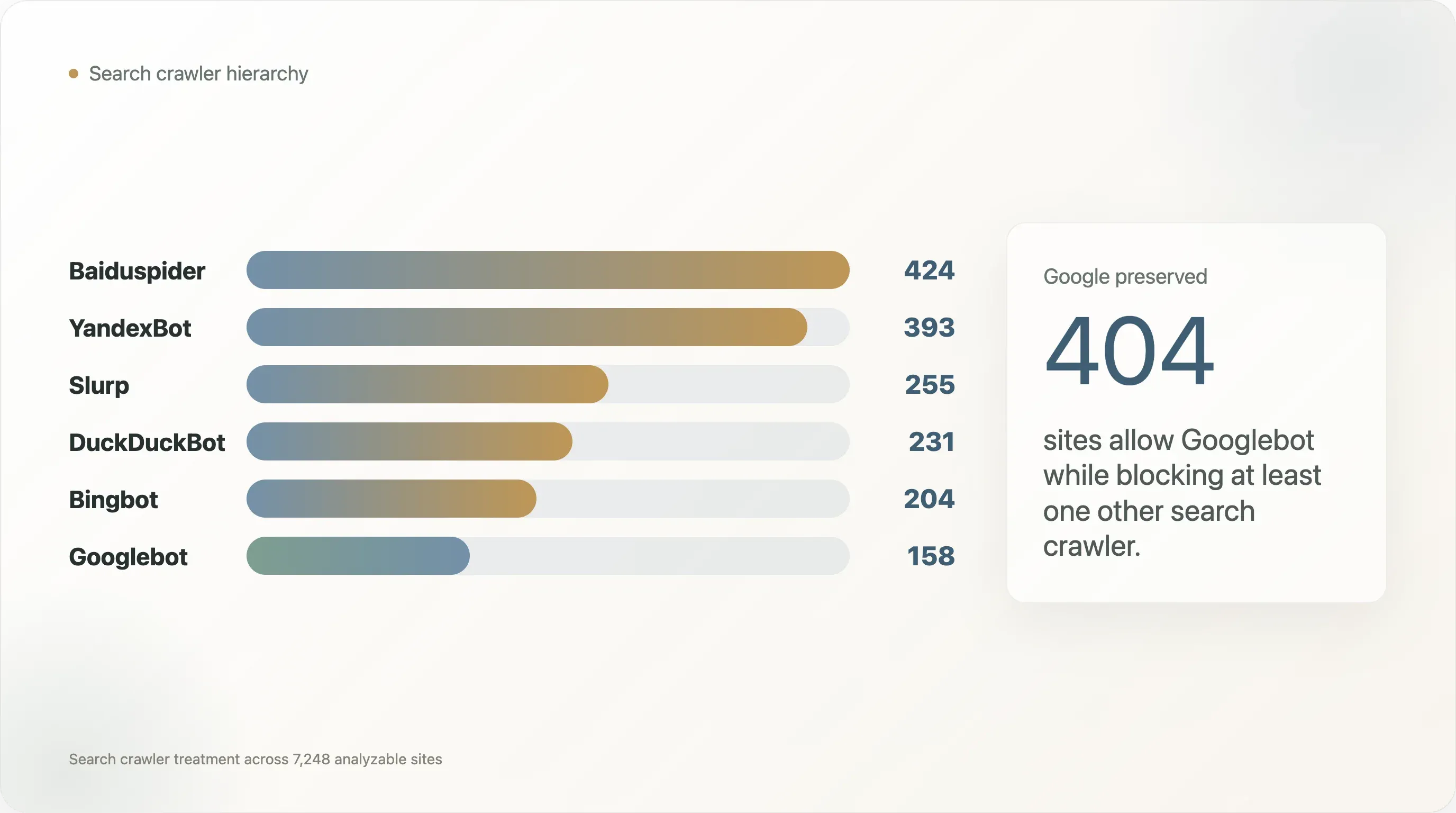
| Zoekcrawler | Sites die hem blokkeren |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
Googlebot is de minst geblokkeerde crawler in deze set. Baiduspider en YandexBot worden veel vaker geblokkeerd, en in de meeste van die gevallen blijft Googlebot toegestaan. Van de 404 sites die Googlebot toestaan terwijl ze een andere zoekcrawler blokkeren, blokkeren er 269 Baiduspider en 240 YandexBot.
De voorbeelden zijn bekend:
| Domein | Geblokkeerde zoekcrawlers terwijl Googlebot is toegestaan |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
Dit is relevant voor het AI-debat, omdat het laat zien dat robots.txt al vóór LLM-crawlers geen neutraal, universeel toegangsprotocol was. Het openbare web had al een hiërarchie:
- Googlebot blijft vaak behouden omdat Google-zoekverkeer te waardevol is om te riskeren.
- Regionale of concurrerende crawlers zijn makkelijker te blokkeren.
- Sommige sites behandelen toegang door zoekcrawlers als een beslissing per markt of per leverancier.
AI-crawlers kwamen binnen in een ecosysteem waarin gedifferentieerde toegang al normaal was.
Dat maakt de beleidsverschuiving beter te begrijpen. Een uitgever die schrijft "blokkeer Google-Extended, laat Googlebot toe" verzint geen nieuwe vorm van discriminatie. Er wordt een oud patroon toegepast op een nieuwe klasse crawler: distributie behouden, extractie beperken.
De open vraag is of dit oude patroon schaalbaar is. Bij zoeken waren er maar een handvol economisch belangrijke crawlers. Bij AI is crawleridentiteit versnipperd over modelleveranciers, retrieval-bots, datamakelaars, academische crawlers, synthetische browseragents en fetchers op infrastructuurniveau. Het aantal benoemde user agents zal blijven groeien, tenzij het ecosysteem zich consolideert rond een kleinere set op doel gebaseerde signalen.
Zo groeit configuratieschuld.
Bevinding 5: Complexiteit verschilt per sector, maar niet op dezelfde manier als AI-blokkeerpercentages
Het oorspronkelijke rapport liet een grote sectorvariatie in AI-blokkering zien: nieuws blokkeert vaak; telecom, overheid en SaaS blokkeren weinig.
Configuratiecomplexiteit snijdt het web anders in.
Onder geselecteerde categorieën met genoeg leesbare robots.txt-bestanden voor een zinvolle vergelijking:
| Categorie | n | Mediaan bytes | P90 bytes | Mediaan Disallow | P90 Disallow | Mediaan User-agent | P90 User-agent |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1.738 | 10.388 | 37 | 164 | 3 | 49 |
| travel | 63 | 2.074 | 27.368 | 41 | 779 | 5 | 34 |
| news | 647 | 1.534 | 7.039 | 19 | 114 | 6 | 68 |
| finance | 121 | 1.002 | 8.337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3.959 | 14 | 75 | 1 | 11 |
| government | 151 | 1.227 | 3.263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12.606 | 4 | 56 | 1 | 10 |
| dev tools | 119 | 273 | 9.255 | 3 | 58 | 1 | 10 |
This paragraph contains content that cannot be parsed and has been skipped.
Nieuws is politiek complex omdat het expliciete AI-regels en juridische tekst schrijft. Maar ecommerce en reizen zijn operationeel complex omdat ze grote catalogi, gefacetteerde navigatie, pagina’s met zoekresultaten, filters, gebruikerspaden en geparametriseerde URL’s hebben.
Dat onderscheid is belangrijk.
Reizen is het duidelijkste voorbeeld. Er zijn hier slechts 63 leesbare bestanden in deze categorische uitsnede, maar de P90 robots.txt is 27,4 KB en de P90 Disallow-telling is 779, ruim boven nieuws. Dat betekent niet dat reiswebsites een verder ontwikkeld AI-beleid hebben. Het betekent dat reiswebsites meer oppervlakken hebben waar crawleroperators hun budget per ongeluk aan kunnen verspillen: datumzoekopdrachten, beschikbaarheidspagina’s, recensie-paginering, boekingsstromen, filtercombinaties en gelokaliseerde voorraadpaden.
SaaS is het tegenovergestelde soort verrassing. Het mediane bestand is slechts 485 bytes, maar het P90-bestand springt naar 12,6 KB. De meeste SaaS-sites zijn open en licht; een kleinere groep draagt lange bestandsregels voor padcontrole, vaak omdat documentatie, inlogoppervlakken, app-routes en marketingpagina’s onder hetzelfde domein leven.
Nieuws zit operationeel in het midden, maar politiek bijna bovenaan. Het P90-aantal User-agent-regels is 68, hoger dan ecommerce, travel, finance, academia, government, SaaS en dev tools in deze tabel. Dat wijst op botspecifiek beleid, niet alleen op hygiëne van paden.
De robots.txt van een uitgever kan complex zijn door rechtenbeleid. Een marktplaatsbestand kan complex zijn door crawlbudgetbeheer. Een universiteitsbestand kan complex zijn doordat duizenden oude paden zich onder één domein hebben opgehoopt. Een sociale platformsite kan complex zijn omdat sommige oppervlakken zichtbaar moeten blijven en andere op enorme schaal moeten worden onderdrukt.
AI-beleid komt daar bovenop. Het vervangt de bestaande redenen voor complexiteit niet.
Dat helpt verklaren waarom AI-tijdperk-robots.txt-governance niet kan worden opgelost met een universele blokkeerlijst. De onderliggende bestanden hebben verschillende taken:
- ecommerce-sites beheren dubbele paden en inventarisoppervlakken;
- reiswebsites beheren lijsten, kalenders, recensies en dynamische zoekpagina’s;
- nieuwswebsites beheren auteursrecht, archieven en licentieposities;
- SaaS- en dev-tool-sites willen vaak AI-zichtbaarheid;
- overheden hebben vaak openbare toegang nodig, maar kunnen nog steeds gevoelige systemen willen uitsluiten;
- sociale platforms beheren door gebruikers gemaakte content, profieloppervlakken en zorgen rond misbruik.
Dezelfde AI-crawlerregel betekent in elke omgeving iets anders.
Bevinding 6: Een index voor configuratieschuld identificeert beoordelingsrisico, geen morele fout
Deze analyse maakte een eenvoudige configuratieschuldscore om robots.txt-bestanden te identificeren die waarschijnlijk moeilijk te beoordelen zijn.
De score weegt:
- bestandsgrootte;
- aantal
User-agent-regels; - aantal
Disallow-regels; - aantal
Allow-regels; - aantal niet-kernregels;
- aanwezigheid van AI-beleids-taal;
- combinatie van expliciete AI-blokkering en juridische of auteursrechtelijke taal.
Dit is geen juistheidsscore. Een bestand met hoge complexiteit kan volledig intentioneel zijn. Een eenvoudig bestand kan nog steeds fout zijn. Het doel is triage: als een bestand groot, beleidszwaar, botspecifiek en vol uitzonderingen is, verdient het strengere beoordelingsdiscipline.
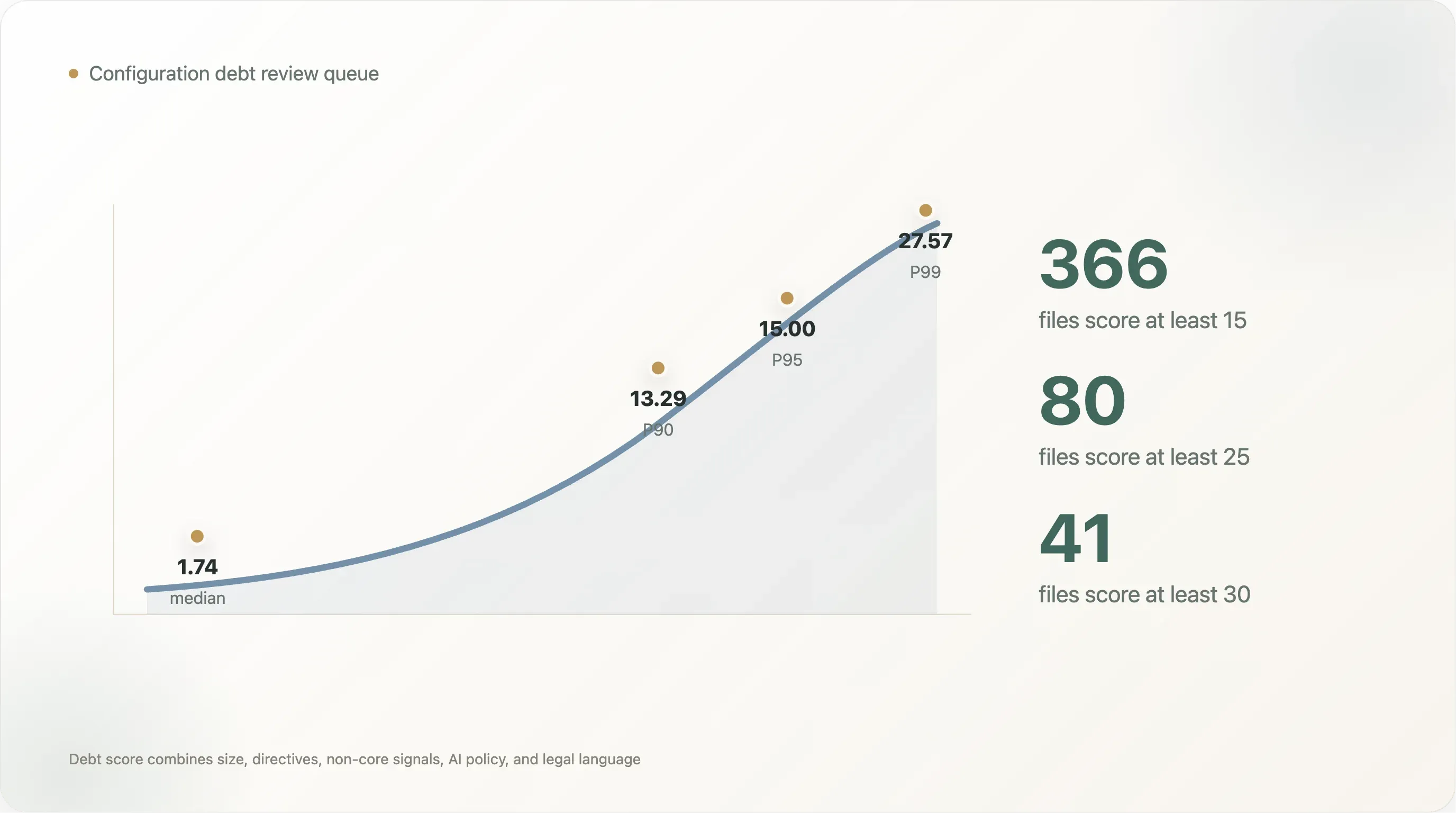
De verdeling van de score is steil. Het mediane leesbare bestand scoort 1,74. De P90-score is 13,29, de P95 is 15,00 en de P99 is 27,57. Slechts 366 bestanden scoren minstens 15, 80 scoren minstens 25 en 41 scoren minstens 30. Dat is de praktische beoordelingsrij: niet elke site heeft een governanceproject nodig, maar de bovenste staart wel.
Ook het categorische beeld laat zien waarom één label als "AI-blocker" te vlak is:
| Categorie | Mediane score | P90 score |
|---|---|---|
| travel | 4,92 | 28,94 |
| search | 2,97 | 24,23 |
| social | 2,25 | 15,00 |
| news | 4,91 | 14,92 |
| finance | 1,67 | 12,61 |
| SaaS | 0,98 | 11,85 |
| ecommerce | 3,88 | 10,87 |
| government | 1,57 | 6,38 |
Travel en search hebben de hoogste P90-scores omdat een minderheid van de bestanden heel groot en regelzwaar wordt. News heeft een van de hoogste mediane scores omdat beleids-taal en botspecifieke behandeling in de hele categorie vaker voorkomen. Ecommerce heeft een hoog mediaan aantal Disallow-regels, maar een lagere P90-schuldscore dan travel omdat de complexiteit sterker geconcentreerd zit in padregels dan in gemengde beleids- en juridische signalen.
De hoogst scorende bestanden in deze dataset zijn onder meer:
| Domein | Waarom het hoog scoort |
|---|---|
linkedin.com | Zeer groot bestand, duizenden padregels, veel benoemde user agents, expliciete AI-beleids-taal |
lnkd.in | Zelfde beleidsoppervlak als de shortlink-infrastructuur van LinkedIn |
fragrantica.com | Honderden benoemde user-agentblokken plus AI-beleids-taal |
sovcombank.ru | Honderden user-agentblokken en juridische/beleids-taal |
academia.edu | Grote matrix van allow/disallow en expliciet AI-blokkeringsbeleid |
opentable.com | Grote set padregels, veel sitemapregels, AI-gerelateerd beleidsoppervlak |
etsy.com | Groot ecommerce-bestand voor padcontrole met meer dan 1.600 Disallow-regels |
runescape.com | Bijna 5.000 Disallow-regels onder één user-agentgroep |
Deze bestanden moeten niet bespot worden omdat ze complex zijn. Complexiteit weerspiegelt vaak echte zakelijke behoeften. Maar ze laten wel zien waarom robots.txt-beleid dezelfde technische discipline verdient als andere productieconfiguratie:
- eigenaarschap moet expliciet zijn;
- wijzigingen moeten worden beoordeeld;
- gegenereerde secties moeten gelabeld zijn;
- juridische opmerkingen moeten waar mogelijk worden gescheiden van machinerichtlijnen;
- tests moeten verwachte bottoegang voor kritieke crawlers bevestigen;
- versiegeschiedenis moet bewaard blijven;
- oude botnamen moeten worden uitgefaseerd of gedocumenteerd;
- AI-training, AI-retrieval, zoekindexering en archivering moeten als afzonderlijke doeleinden worden behandeld.
Dat laatste punt is het belangrijkst. De huidige grammatica is user-agent-eerst: ze vraagt sitebeheerders bots te noemen. De behoefte in het AI-tijdperk is purpose-first: ze vraagt sitebeheerders aan te geven welke toepassingen zijn toegestaan.
Dat is niet hetzelfde.
Die mismatch is waarom langere blokkeerlijsten slecht zullen verouderen. Een uitgever kan vandaag GPTBot, ClaudeBot, CCBot, Google-Extended, Bytespider, Applebot-Extended en PerplexityBot toevoegen, maar morgen kan de volgende crawlernaam, retrieval-agent of datasetbroker opduiken. Een op doeleinden gebaseerd beleid zou een site laten zeggen "zoekindexering ja, AI-training nee, door de gebruiker geactiveerde retrieval misschien" zonder robots.txt in een adresboek van bots te veranderen.
Wat dit betekent voor AI-governance
Het publieke debat presenteert robots.txt vaak als óf betekenisvol óf achterhaald. De data suggereert een praktischer antwoord:
robots.txt is betekenisvol, maar overbelast.
Het is betekenisvol omdat grote sites het gebruiken, crawlers het kunnen parseren en beleidskeuzes zichtbaar zijn voor onderzoekers, journalisten, leveranciers en rechters. Het oorspronkelijke rapport vond dat 17,0% van de analyseerbare topsites bewuste AI-specifieke regels had. Dat is geen symbolische ruis.
Het is overbelast omdat het bestand nu meer moet uitdrukken dan bottoegang:
- "Train hier niet op."
- "Je mag deze content gebruiken voor zoekindexering."
- "Je mag deze content gebruiken voor live retrieval."
- "Je mag geen gecachte datasets maken."
- "Dit juridische voorbehoud geldt onder de EU-regels voor tekst- en datamining."
- "Deze door een CDN beheerde site stuurt
Content-Signal: ai-train=no." - "Deze site wil Googlebot wel, maar YandexBot niet."
- "Deze site heeft 1.000 verouderde URL-paden die niet gecrawld mogen worden."
De grammatica was niet ontworpen voor zoveel taken.
Drie veranderingen zouden de schuld verlagen:
-
Crawleridentiteit heeft een register nodig. Sitebeheerders zouden niet zelf een steeds langer wordende lijst moeten bijhouden van
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Applebot-Extended,Bytespider,OAI-SearchBot,ChatGPT-Useren nog tientallen meer. Zonder register loopt beleid altijd achter op crawlergedrag. -
AI-gebruik heeft gestructureerde woordenschat nodig. Training, retrieval, indexing, samenvatten, doorverkoop van datasets, modelevaluatie en door de gebruiker geactiveerd browsen zijn verschillende gebruiksvormen. Die uitdrukken via leveranciersspecifieke user-agentnamen is kwetsbaar.
-
Beleid heeft controleerbaarheid nodig. Het web heeft een manier nodig om handgeschreven rechtenvoorbehouden te onderscheiden van geërfde CDN-standaarden, gegenereerde CMS-sjablonen, oude verouderde regels en per ongeluk brede blokkeringsregels. Dat onderscheid is belangrijk voor vertrouwen en voor rechtszaken.
Dit betekent niet dat robots.txt van de ene op de andere dag vervangen moet worden. De betere route is gelaagdheid: houd robots.txt als ontdek- en compatibiliteitslaag, maar standaardiseer daarnaast machineleesbaar beleid voor AI-specifieke toepassingen.
llms.txt is één poging, maar de adoptie in deze dataset is nog klein: slechts 83 leesbare bestanden noemen het. Content-Signal is zichtbaarder omdat Cloudflare het via infrastructuur kan verspreiden, en alle 271 Content-Signal-bestanden in deze scan kwamen ook overeen met AI-beleids-taal. Toch is distributie niet hetzelfde als consensus. Een duurzame oplossing heeft waarschijnlijk de saaie machine van standaardisatie nodig: duidelijke velden, duidelijke semantiek, crawlerverplichtingen en openbare testsuites.
Conclusie
De strijd rond AI-crawlers heeft robots.txt veranderd in een governance-artefact. Dat is zowel nuttig als riskant.
Nuttig, omdat het bestand openbaar is. Onderzoekers kunnen het auditen. Uitgevers kunnen het aanpassen. Crawlers kunnen het respecteren. Rechters kunnen het lezen. Infrastructuurproviders kunnen het op grote schaal uitrollen.
Riskant, omdat het te veel draagt.
Het mediane robots.txt-bestand in de Tranco Top 10K is nog steeds klein genoeg om te begrijpen. Maar de lange staart van het web met veel verkeer zit vol grote, oude, gelaagde, leverancier-specifieke en juridisch geladen bestanden. Honderden sites onderhouden nu robots.txt-configuraties die beter te begrijpen zijn als productiebeleidsystemen dan als simpele crawlerhints.
De kernles is niet dat robots.txt heeft gefaald. Het is dat het web het heeft gepromoveerd zonder het te refactoren.
Als AI-toegangbeleid zal afhangen van openbare, machineleesbare verklaringen, dan is de volgende stap niet nog een langere blokkeerlijst. Het is een betere beleidsinfrastructuur: toestemmingen op basis van doel, stabiele crawleridentiteit, reviewbare sjablonen en auditsporen.
Tot die tijd blijft de AI-governancelayer van het openbare web rusten op een tekstbestand dat nooit bedoeld was om zoveel gewicht te dragen.
Opmerkingen over reproduceerbaarheid
De leveringsmap bevat:
source_data/analysis.json— oorspronkelijke geaggregeerde metrics.source_data/site_meta.csv— oorspronkelijke analytische tabel per site.source_data/bot_status.csv— oorspronkelijke beleids-tabel per domein en bot.source_data/fetch_meta.csv— oorspronkelijke fetchmetadata.source_data/sites.csv— oorspronkelijke domein-/categorie-/status-tabel.derived_data/robots_complexity_by_site.csv— per-site complexiteitsmetrics gegenereerd voor dit rapport.derived_data/search_bot_treatment.csv— matrix voor behandeling van zoekcrawlers.derived_data/category_complexity_summary.csv— samenvatting van complexiteit per categorie.derived_data/top_config_debt_sites.csv— top-sites op basis van de hierboven beschreven triagescore.derived_data/summary_metrics.json— alle headline-metrics geciteerd in dit rapport.
Correcties op de methode, dataproblemen en vervolganalyses zijn welkom via support@thunderbit.com. Dit rapport is onafhankelijk gepubliceerd van elke commerciële positie die Thunderbit inneemt; wij bouwen een AI-aangedreven webscraper, en we hebben een structureel belang bij het feit dat robots.txt een betekenisvol, machineleesbaar contract op het openbare web blijft. De data in dit rapport staat op zichzelf. — Het onderzoeksteam van Thunderbit, mei 2026.