Het internet barst van de waardevolle data, en laten we eerlijk zijn—niemand heeft zin om urenlang handmatig duizenden producten of vacatures te kopiëren en plakken. Daarom is webscraping tegenwoordig onmisbaar voor iedereen die werkt in sales, operations, e-commerce en nog veel meer. Python is dankzij zijn toegankelijke stijl en krachtige libraries dé favoriete taal om een webscraper te bouwen. Wist je dat inmiddels meer dan Python gebruikt? Daarmee laat het alle andere programmeertalen ver achter zich.
Maar er zit ook een keerzijde aan: hoewel webscraping met Python superkrachtig is, kan het voor beginners best overweldigend zijn. Zelfs ervaren gebruikers lopen soms vast op dynamische websites, anti-botmaatregelen of rommelige data. Daarom heb ik deze praktische handleiding voor je gemaakt. We beginnen bij het begin, bouwen samen een python webscraper voorbeeld, en laten zien hoe je Python slim kunt combineren met AI-tools zoals om slimmer te scrapen, niet harder. Of je nu leads wilt automatiseren, concurrentieprijzen wilt volgen of webdata in een spreadsheet wilt krijgen—hier vind je direct bruikbare stappen en handige tips uit de praktijk.
Python Webscraping 101: Starten vanaf Nul
We beginnen bij de basis. Webscraping betekent simpelweg dat je het verzamelen van data van websites automatiseert. In plaats van handmatig informatie te kopiëren, bezoekt een webscraper de pagina, leest de HTML en haalt precies die gegevens op die jij nodig hebt—denk aan prijzen, contactgegevens of reviews. Voor bedrijven betekent dit: altijd actuele data voor sales, prijsmonitoring of marktonderzoek, direct beschikbaar ().
Stap 1: Installeer Python
Je hebt Python 3 nodig. De nieuwste versie kun je makkelijk downloaden via de . Op Windows start je de installer en vink je “Add Python to PATH” aan. Op Mac kun je gebruiken met brew install python, of direct downloaden. Na installatie open je de terminal (of Command Prompt) en typ je:
1python --versionof
1python3 --versionZie je iets als Python 3.11.0, dan zit je goed.
Stap 2: Maak een Virtuele Omgeving aan
Met een virtuele omgeving houd je de afhankelijkheden van je project netjes gescheiden van andere Python-projecten. In je projectmap voer je uit:
1# Op macOS/Linux
2python3 -m venv .venv
3# Op Windows
4py -m venv .venvActiveer de omgeving met:
- macOS/Linux:
source .venv/bin/activate - Windows:
.venv\Scripts\activate
Nu worden alle geïnstalleerde pakketten alleen binnen dit project gebruikt ().
Stap 3: Installeer de Belangrijkste Bibliotheken
Je hebt een paar essentiële pakketten nodig:
- Requests: Om webpagina’s op te halen.
- BeautifulSoup (bs4): Voor het parsen van HTML.
- Scrapy: Voor geavanceerde, grootschalige scraping.
Installeer ze met:
1pip install requests beautifulsoup4 scrapy- Requests maakt HTTP-verzoeken net zo makkelijk als het lezen van een bestand.
- BeautifulSoup helpt je om data uit HTML te filteren en te extraheren.
- Scrapy is een compleet framework voor het crawlen van veel pagina’s, foutafhandeling en data-export.
Voor beginners is starten met Requests + BeautifulSoup ideaal. Scrapy is handig als je wilt opschalen.
Stap 4: Maak je Projectmap aan
Houd je bestanden netjes! Maak een aparte map voor je project en bewaar daar je scripts, data en virtuele omgeving. Je toekomstige zelf zal je dankbaar zijn.
python webscraper voorbeeld: Basis Script en Structuur
Laten we samen een simpele webscraper bouwen. We halen een webpagina op, parsen deze en halen data eruit. Hier een kort voorbeeld voor :
1import requests
2from bs4 import BeautifulSoup
3URL = "https://example.com"
4response = requests.get(URL)
5response.raise_for_status() # Geeft een fout als het geen 200 OK is
6soup = BeautifulSoup(response.text, "html.parser")
7# Zoek alle paragraaf-tags
8paragraphs = soup.find_all('p')
9for idx, p in enumerate(paragraphs, start=1):
10 print(f"Paragraaf {idx}: {p.get_text()}")Wat gebeurt er hier?
- We importeren de benodigde libraries.
- Halen de pagina op met
requests.get. - Parsen de HTML met BeautifulSoup.
- Zoeken alle
<p>-tags en printen de tekst.
Veelvoorkomende valkuilen:
- Niet controleren van
response.status_code(altijd checken op 200 OK). - Proberen
.get_text()te gebruiken op eenNoneobject (als het element niet gevonden wordt). - Vergeten je virtuele omgeving te activeren (waardoor imports kunnen mislukken).
Deze structuur—importeren, ophalen, parsen, extraheren, outputten—is de basis van bijna elke Python-webscraper.
Webpagina’s Scrapen met Python: Stapsgewijs
Laten we het proces voor een echte scraping-taak doorlopen.
1. Inspecteer de Website
Open je browser, klik met rechts op de gewenste data en kies “Inspecteren.” Hiermee open je de ontwikkelaarstools en zie je de HTML-structuur. Zoek naar unieke tags, klassen of ID’s die jouw data aanduiden ().
2. Haal de Pagina op
Gebruik Requests om de HTML binnen te halen:
1headers = {"User-Agent": "Mozilla/5.0"}
2response = requests.get(URL, headers=headers)
3response.raise_for_status()Een User-Agent toevoegen helpt om simpele anti-botblokkades te omzeilen.
3. Parseer de HTML
1soup = BeautifulSoup(response.text, "html.parser")4. Vind en Extraheer Data
Stel, je wilt vacatures scrapen, elk in een <div class="job-card">:
1job_cards = soup.find_all('div', class_='job-card')
2for card in job_cards:
3 title = card.find('h2', class_='title').get_text(strip=True)
4 company = card.find('h3', class_='company').get_text(strip=True)
5 print(title, company)Je kunt .find(), .find_all() of .select() met CSS-selectors gebruiken voor complexere queries.
5. Meerdere Items (Lijsten) Afhandelen
Loop door de containers (zoals productlijsten, vacaturekaarten, etc.) en haal de gewenste velden op. Sla ze op in een lijst van dictionaries voor eenvoudige export.
6. Problemen Oplossen
- Krijg je lege resultaten? Controleer je selectors—misschien is de klassenaam gewijzigd of wordt de content via JavaScript geladen.
- Print
response.text[:500]om te checken of je de juiste HTML binnenkrijgt.
python webscraper voorbeeld: Data Opslaan en Exporteren
Als je de data hebt, wil je deze natuurlijk bewaren. Dit zijn de meest gebruikte opties:
Printen naar de Console
Handig voor snelle checks, maar niet voor echte projecten.
Schrijven naar CSV
1import csv
2data = [
3 {"Name": "Alice", "Age": 25},
4 {"Name": "Bob", "Age": 30},
5]
6with open("output.csv", "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=["Name", "Age"])
8 writer.writeheader()
9 writer.writerows(data)Exporteren naar Excel
Als je pandas en openpyxl hebt geïnstalleerd:
1import pandas as pd
2df = pd.DataFrame(data)
3df.to_excel("output.xlsx", index=False)Opslaan in een Database
Voor eenvoudige toepassingen is SQLite standaard in Python aanwezig:
1import sqlite3
2conn = sqlite3.connect("scraped_data.db")
3cursor = conn.cursor()
4cursor.execute("CREATE TABLE IF NOT EXISTS people (name TEXT, age INTEGER)")
5for row in data:
6 cursor.execute("INSERT INTO people VALUES (?, ?)", (row["Name"], row["Age"]))
7conn.commit()
8conn.close()Wanneer gebruik je wat?
- CSV: Ideaal voor spreadsheets en delen.
- Excel: Voor rapportages met opmaak of meerdere tabbladen.
- Database: Voor grote of doorlopende projecten.
Gebruik altijd encoding="utf-8" om rare tekens te voorkomen ().
Thunderbit en Python: Je Scraping Workflow Versnellen
 Laten we het hebben over , de AI-webscraper Chrome-extensie die het leven van zakelijke gebruikers een stuk makkelijker maakt.
Laten we het hebben over , de AI-webscraper Chrome-extensie die het leven van zakelijke gebruikers een stuk makkelijker maakt.
Wat Maakt Thunderbit Uniek?
- AI Veldsuggesties: Thunderbit’s AI scant de pagina en stelt automatisch voor welke datavelden je kunt extraheren—geen HTML-zoektochten of handmatig selectors schrijven.
- Klik-en-Klaar Werkwijze: Open de extensie, laat de AI velden voorstellen, klik op “Scrapen” en je bent klaar.
- Subpagina’s Scrapen: Thunderbit kan automatisch detailpagina’s (zoals product- of profielpagina’s) bezoeken en je dataset verrijken met extra informatie.
- Overal Exporteren: Download je data als CSV, Excel, of exporteer direct naar Google Sheets, Notion of Airtable ().
Hoe Werkt Thunderbit Samen met Python?
Stel, je wilt een complexe e-commercesite scrapen met veel JavaScript en inlogvereisten. Traditionele Python-scripts kunnen hier moeite mee hebben, maar Thunderbit—die in je browser draait—pakt dit moeiteloos op. Na het scrapen exporteer je de data en gebruik je Python voor verdere analyse, rapportages of automatisering.
Voorbeeldscenario:
- Gebruik Thunderbit om productlijsten (inclusief afbeeldingen, prijzen en reviews) van een dynamische site te scrapen.
- Exporteer naar CSV.
- Gebruik Python om trends te analyseren, te combineren met andere datasets of automatische meldingen te maken.
Deze combinatie maakt zelfs de lastigste scrapingklussen haalbaar—ongeacht je programmeerkennis.
Nauwkeurigheid en Stabiliteit van je Python Webscraper Waarborgen
Webscraping draait niet alleen om data verzamelen, maar vooral om het betrouwbaar binnenhalen van de juiste data. Zo houd je je webscraper stabiel:
1. Omgaan met Websitewijzigingen
Websites veranderen hun HTML regelmatig. Schrijf je selectors zo robuust mogelijk—gebruik bij voorkeur unieke ID’s of stabiele klassen in plaats van kwetsbare tagposities.
2. Foutafhandeling Gebruiken
Omring je requests en parsing-code met try/except-blokken:
1import time
2for attempt in range(3):
3 try:
4 response = requests.get(url, timeout=10)
5 response.raise_for_status()
6 break
7 except Exception as e:
8 if attempt < 2:
9 time.sleep(5)
10 else:
11 print(f"Mislukt na 3 pogingen: {e}")3. User-Agent Roulatie en Proxies Gebruiken
Veel sites blokkeren scripts die op bots lijken. Varieer je User-Agent en gebruik bij intensief scrapen proxies om IP-blokkades te voorkomen ().
4. Respecteer robots.txt en Wees Ethisch
Check altijd het robots.txt-bestand en de gebruiksvoorwaarden van een site. Scrape alleen openbare data, vermijd persoonlijke informatie en belast servers niet onnodig ().
5. Loggen en Monitoren
Gebruik Python’s logging-module om fouten en successen bij te houden. Draait je webscraper op een schema? Stel dan meldingen in voor fouten of dagen zonder resultaten.
Hoe Thunderbit’s AI-functies Python Webscraping Verbeteren
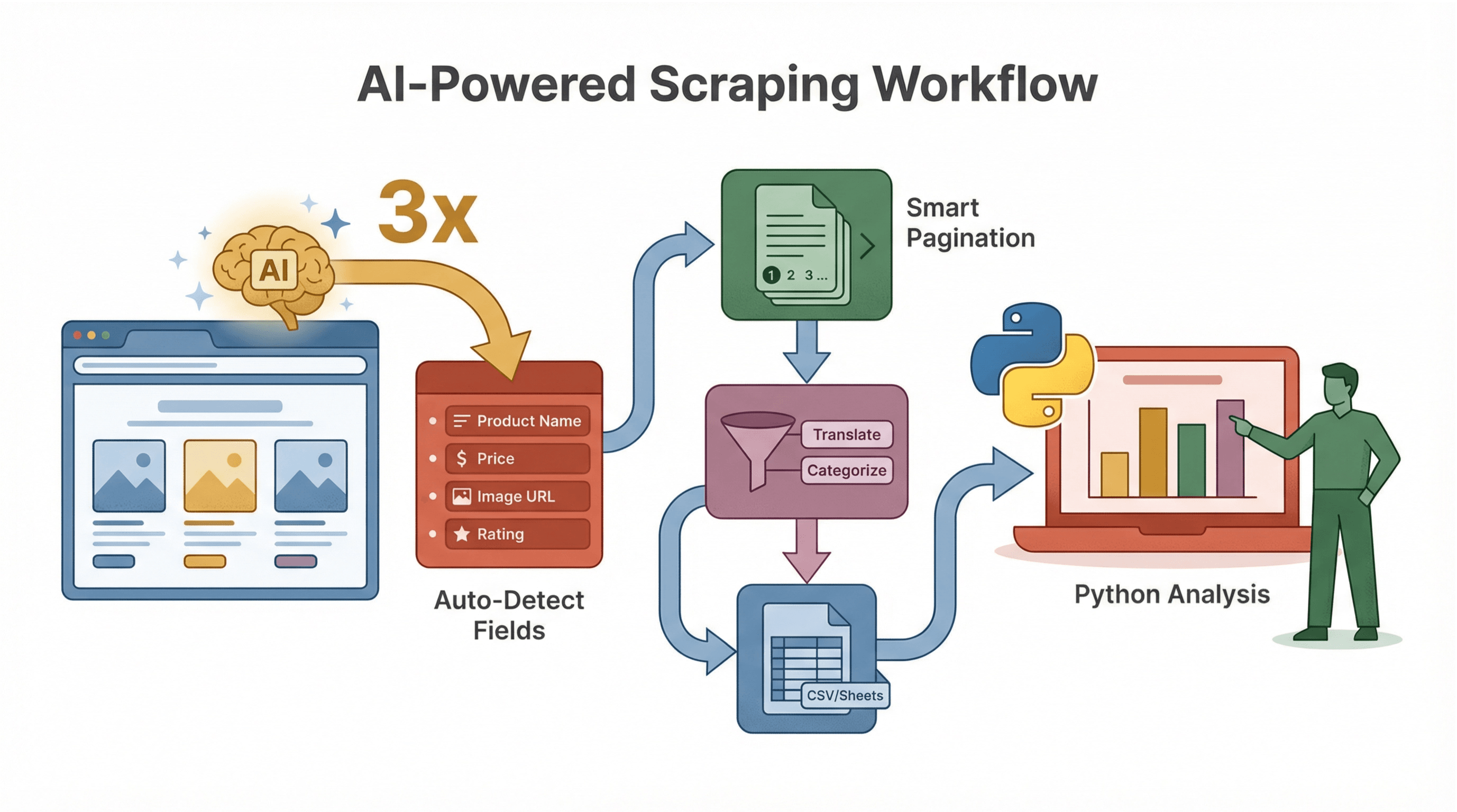 Thunderbit draait niet alleen om scrapen, maar vooral om het proces slimmer en sneller te maken.
Thunderbit draait niet alleen om scrapen, maar vooral om het proces slimmer en sneller te maken.
AI-voorgestelde Datastructuur
Thunderbit’s AI stelt direct voor welke velden je kunt extraheren, zodat je niet zelf in de HTML hoeft te duiken of selectors hoeft te schrijven. Op een productpagina detecteert het bijvoorbeeld automatisch “Productnaam”, “Prijs”, “Afbeeldings-URL” en meer.
Subpagina’s en Paginering Automatisch Herkennen
Thunderbit’s AI ziet wanneer er detailpagina’s of meerdere resultatenpagina’s zijn, en kan deze allemaal scrapen—zonder extra code. Ideaal voor e-commerce, vastgoed of leadgeneratie.
AI Datacleaning en Verrijking
Wil je data direct vertalen, samenvatten of categoriseren tijdens het scrapen? Thunderbit laat je AI-prompts toevoegen aan elk veld, zodat je bijvoorbeeld reviews als “Positief” of “Negatief” kunt labelen, of alleen het numerieke deel van een prijs kunt extraheren.
Voorbeeld Workflow
- Gebruik Thunderbit om je data te scrapen en structureren (met AI-veldvoorstellen).
- Exporteer naar CSV of Google Sheets.
- Gebruik Python voor analyse, visualisatie of verdere automatisering.
Deze workflow is ideaal voor teams waar niet iedereen programmeert—Thunderbit regelt het scrapen, Python doet de rest.
python webscraper voorbeeld: Geavanceerde Tips en Veelvoorkomende Problemen
Klaar voor de volgende stap? Hier wat tips van de pro’s:
Dynamische Content Scrapen
Veel moderne sites laden data via JavaScript. Geeft Requests + BeautifulSoup lege of incomplete data? Probeer dan:
- Selenium of Playwright: Automatiseer een echte browser om de pagina te renderen en daarna de HTML te extraheren.
- Zoek naar API’s: Soms wordt data via achtergrond-API’s (vaak in JSON-formaat) geladen. Gebruik het Netwerk-tabblad van je browser om deze endpoints te vinden—dat scrapen is vaak veel eenvoudiger!
Paginering Afhandelen
Loop door pagina’s door de URL-parameter aan te passen (bijv. ?page=2). Of gebruik BeautifulSoup om de “Volgende”-link te vinden en volg deze tot er geen pagina’s meer zijn.
Scrapes Inplannen
Gebruik Python’s schedule-bibliotheek of een cronjob om je webscraper automatisch te laten draaien. Of gebruik de ingebouwde planningsfunctie van Thunderbit voor een no-code oplossing.
Veelvoorkomende Problemen
- CAPTCHAs: Vertraag je verzoeken, gebruik proxies of overweeg een menselijke tussenkomst.
- Encoding Issues: Geef altijd
encoding="utf-8"op bij het schrijven van bestanden. - IP-blokkades: Gebruik proxies, randomiseer je User-Agent en respecteer de limieten.
Conclusie & Belangrijkste Leerpunten
Webscraping met Python hoeft niet ingewikkeld te zijn. Begin eenvoudig:
- Zet je omgeving en belangrijkste libraries op.
- Inspecteer de doelwebsite en bepaal je selectors.
- Schrijf een script om data op te halen, te parsen en te extraheren.
- Exporteer je resultaten in het formaat dat bij jouw bedrijf past.
Wil je verder groeien? Combineer Python met AI-tools zoals voor complexe, dynamische of grootschalige scraping. Thunderbit’s AI-functies—zoals veldsuggesties, subpagina-scraping en directe export—besparen je uren handwerk en maken webscraping toegankelijk voor iedereen.
Onthoud: de beste webscrapers zijn betrouwbaar, ethisch en gebouwd met het einddoel voor ogen. Of je nu in sales, e-commerce of data-analyse werkt, webscraping opent een wereld aan inzichten—begin klein, blijf leren en bouw verder.
Meer weten? Bekijk de voor meer handleidingen, of probeer de en ervaar AI-gestuurd scrapen zelf.
Veelgestelde Vragen
1. Wat is de makkelijkste manier om te starten met webscraping in Python?
Begin met het installeren van Python 3 en gebruik de Requests- en BeautifulSoup-bibliotheken om webpagina’s op te halen en te parsen. Start met eenvoudige sites en pak steeds complexere aan naarmate je ervaring groeit.
2. Hoe ga ik om met websites die data via JavaScript laden?
Gebruik voor sites die zwaar op JavaScript leunen browserautomatiseringstools zoals Selenium of Playwright, of zoek in het Netwerk-tabblad van je browser naar API-calls die gestructureerde data (zoals JSON) teruggeven.
3. Wat is de beste manier om gescrapete data te exporteren voor zakelijk gebruik?
CSV is het meest universele formaat (werkt in Excel, Google Sheets, enz.), maar je kunt ook exporteren naar Excel, JSON of databases zoals SQLite. Thunderbit ondersteunt ook directe export naar Google Sheets, Notion en Airtable.
4. Hoe voorkom ik dat ik geblokkeerd word tijdens het scrapen?
Varieer je User-Agent, gebruik proxies bij grootschalig scrapen, respecteer de limieten en check altijd het robots.txt-bestand van de site. Vermijd het scrapen van persoonlijke of gevoelige data.
5. Hoe maakt Thunderbit webscraping makkelijker voor niet-programmeurs?
Thunderbit gebruikt AI om datavelden voor te stellen, subpagina’s en paginering te verwerken en gestructureerde data te exporteren met slechts een paar klikken—zonder code. Ideaal voor zakelijke gebruikers die snel en betrouwbaar resultaat willen zonder technische rompslomp.
Klaar om je dataverzameling te automatiseren? Probeer gratis en laat AI je webscraping naar een hoger niveau tillen.
Meer weten