

Laat me je meenemen naar mijn eerste stappen in SaaS en automatisering, toen 'webcrawlen' nog iets leek wat een spin op een regenachtige middag deed. Tegenwoordig is webcrawlen de basis van alles, van Google Search tot je favoriete prijsvergelijker. Het web is een levendig ecosysteem en iedereen—van techneuten tot sales—wil bij die waardevolle data kunnen. Maar hier zit de crux: dankzij Python is het bouwen van webcrawlers veel toegankelijker geworden, maar de meeste mensen willen gewoon de data, niet een spoedcursus HTTP-headers of JavaScript-trucs.
Haal data van elke website met AI Get Started Free
En daar wordt het pas echt interessant. Als medeoprichter van Thunderbit heb ik van dichtbij gezien hoe de vraag naar webdata in allerlei sectoren is geëxplodeerd. Sales wil verse leads, e-commerce managers willen concurrentieprijzen, en marketeers zoeken content-inzichten. Maar niet iedereen heeft tijd (of zin) om een Python-expert te worden. Dus: wat is een webcrawler in Python nu precies, waarom is het belangrijk, en hoe veranderen AI-tools zoals Thunderbit het speelveld voor zowel bedrijven als ontwikkelaars?
Webcrawler Python: Wat is het en waarom is het relevant?
Laten we meteen een veelgemaakte verwarring uit de wereld helpen: webcrawlers en webscrapers zijn niet hetzelfde. Ik weet het—de termen worden vaak door elkaar gehaald, maar het verschil is net zo groot als tussen een Roomba en een Dyson (beide maken schoon, maar op een heel andere manier).
- Webcrawlers zijn de verkenners van het internet. Ze ontdekken en indexeren systematisch webpagina's door links te volgen—denk aan Googlebot die het hele web in kaart brengt.
- Webscrapers zijn meer als slimme verzamelaars. Zij halen specifieke data van webpagina's, zoals prijzen, contactgegevens of artikelen.

Als mensen het hebben over 'webcrawler Python', bedoelen ze meestal het bouwen van geautomatiseerde bots in Python die het web doorkruisen en soms data verzamelen. Python is hiervoor favoriet omdat het makkelijk te leren is, een enorme bibliotheek aan tools heeft, en—laten we eerlijk zijn—niemand wil een webcrawler in Assembly schrijven.
Zakelijke waarde van webcrawlen en webscraping
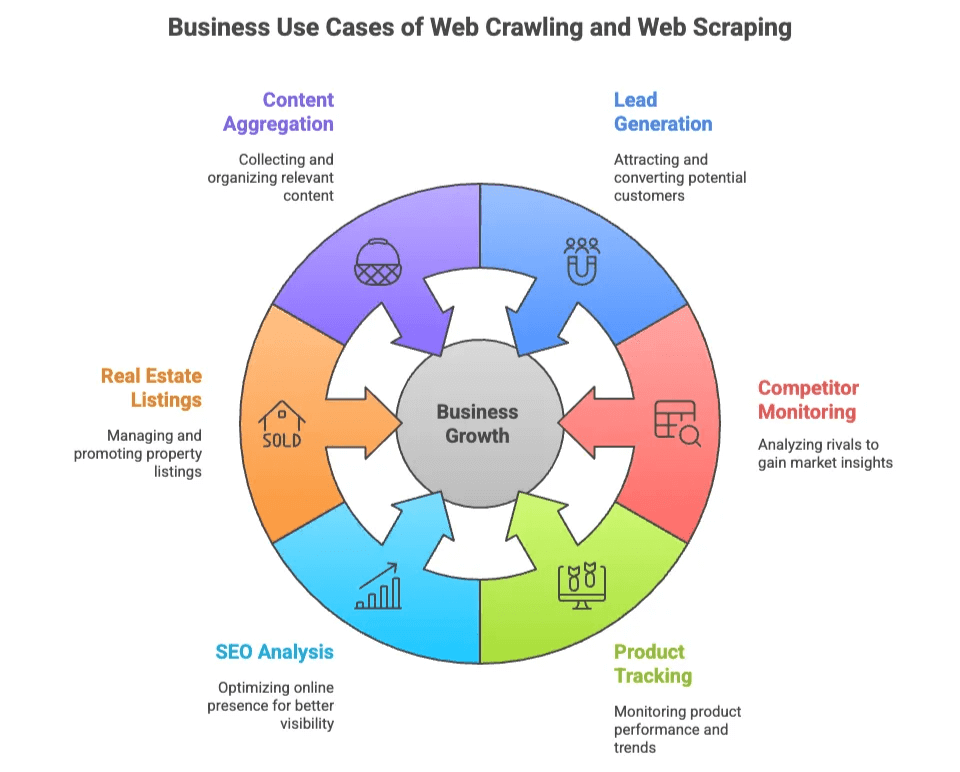
Waarom zijn zoveel teams bezig met webcrawlen en -scrapen? Omdat webdata het nieuwe goud is—maar dan zonder te hoeven graven, alleen wat code (of, zoals je straks ziet, een paar klikken).
Hier zijn de meest voorkomende zakelijke toepassingen:
| Toepassing | Voor wie | Waarde |
|---|---|---|
| Leadgeneratie | Sales, Marketing | Gericht lijsten bouwen van prospects uit directories, sociale netwerken |
| Concurrentiemonitoring | E-commerce, Operations | Prijzen, voorraad en nieuwe producten volgen bij concurrenten |
| Producttracking | E-commerce, Retail | Cataloguswijzigingen, reviews en ratings monitoren |
| SEO-analyse | Marketing, Content | Analyse van zoekwoorden, meta tags en backlinks voor optimalisatie |
| Vastgoedaanbod | Makelaars, Investeerders | Gegevens en contactinfo van panden verzamelen uit meerdere bronnen |
| Contentaggregatie | Onderzoek, Media | Artikelen, nieuws of forumberichten verzamelen voor inzichten |
Het mooie is: zowel technische als niet-technische teams profiteren hiervan. Ontwikkelaars bouwen maatwerkcrawlers voor grote projecten, terwijl business users gewoon snel en accuraat data willen—liefst zonder ooit van CSS-selectors gehoord te hebben.
Populaire Python Webcrawler-bibliotheken: Scrapy, BeautifulSoup en Selenium
De populariteit van Python voor webcrawlen is niet zomaar een hype—het is te danken aan een paar krachtige libraries, elk met hun eigen voor- en nadelen.
| Library | Gebruiksgemak | Snelheid | Ondersteuning dynamische content | Schaalbaarheid | Ideaal voor |
|---|---|---|---|---|---|
| Scrapy | Gemiddeld | Snel | Beperkt | Hoog | Grote, geautomatiseerde crawls |
| BeautifulSoup | Makkelijk | Gemiddeld | Geen | Laag | Simpele parsing, kleine projecten |
| Selenium | Moeilijker | Traag | Uitstekend | Laag-middel | JavaScript-rijke, interactieve sites |
Laten we kort bekijken wat elke library uniek maakt.
Scrapy: De alles-in-één Python webcrawler
Scrapy is het Zwitsers zakmes onder de Python webcrawlers. Het is een compleet framework voor grootschalige, geautomatiseerde crawls—denk aan duizenden pagina's tegelijk, met ondersteuning voor gelijktijdige verzoeken en data-export.
Waarom ontwikkelaars fan zijn:
- Crawlen, parsen en data-export in één omgeving.
- Ingebouwde ondersteuning voor gelijktijdigheid, planning en pipelines.
- Ideaal voor projecten waar je op grote schaal wilt crawlen en scrapen.
Maar… Scrapy heeft wel een leercurve. Zoals een developer het zei: 'over-engineered als je maar een paar pagina's wilt scrapen' (Reddit). Je moet selectors, asynchrone processen en soms zelfs proxies en anti-botmaatregelen begrijpen.
Basis Scrapy workflow:
- Definieer een Spider (de crawlerlogica).
- Stel Item pipelines in (voor dataverwerking).
- Start de crawl en exporteer de data.
Wil je het web doorzoeken als Google? Dan is Scrapy je vriend. Wil je alleen een emaillijstje? Dan is het waarschijnlijk te veel van het goede.
BeautifulSoup: Simpel en lichtgewicht webcrawlen
BeautifulSoup is de 'hello world' van webparsing. Het is een lichte library die zich richt op het parsen van HTML en XML, ideaal voor beginners of kleine projecten.
Waarom mensen het fijn vinden:
- Super eenvoudig te leren en te gebruiken.
- Perfect voor het extraheren van data uit statische pagina's.
- Flexibel voor snelle, simpele scripts.
Maar… BeautifulSoup crawlt niet zelf—het parseert alleen. Je moet het combineren met bijvoorbeeld requests om pagina's op te halen, en je eigen logica schrijven om links te volgen of meerdere pagina's te verwerken (ZenRows).
Wil je voorzichtig beginnen met webcrawlen? Dan is BeautifulSoup een fijne start. Maar verwacht geen ondersteuning voor JavaScript of grote projecten.
Selenium: Voor dynamische en JavaScript-rijke pagina's
Selenium is de koning van browserautomatisering. Het kan Chrome, Firefox of Edge aansturen, knoppen aanklikken, formulieren invullen en—belangrijk—JavaScript-gedreven pagina's renderen.

Waarom het krachtig is:
- Kan pagina's 'zien' en bedienen als een echte gebruiker.
- Geschikt voor dynamische content en AJAX-data.
- Onmisbaar voor sites met login of complexe interacties.
Maar… Selenium is traag en vraagt veel van je systeem. Voor elke pagina wordt een volledige browser gestart, wat je computer flink kan belasten bij grote crawls (WebScraping.AI). Ook het onderhoud is pittig—denk aan browserdrivers beheren en wachten tot dynamische content geladen is.
Selenium is je redder als je sites wilt crawlen die voor gewone scrapers ondoordringbaar zijn.
Uitdagingen bij het bouwen en draaien van een Python webcrawler
Nu het minder glamoureuze deel van webcrawlen met Python. Ik heb meer uren dan me lief is besteed aan het debuggen van selectors en het omzeilen van anti-botmaatregelen. Dit zijn de grootste struikelblokken:
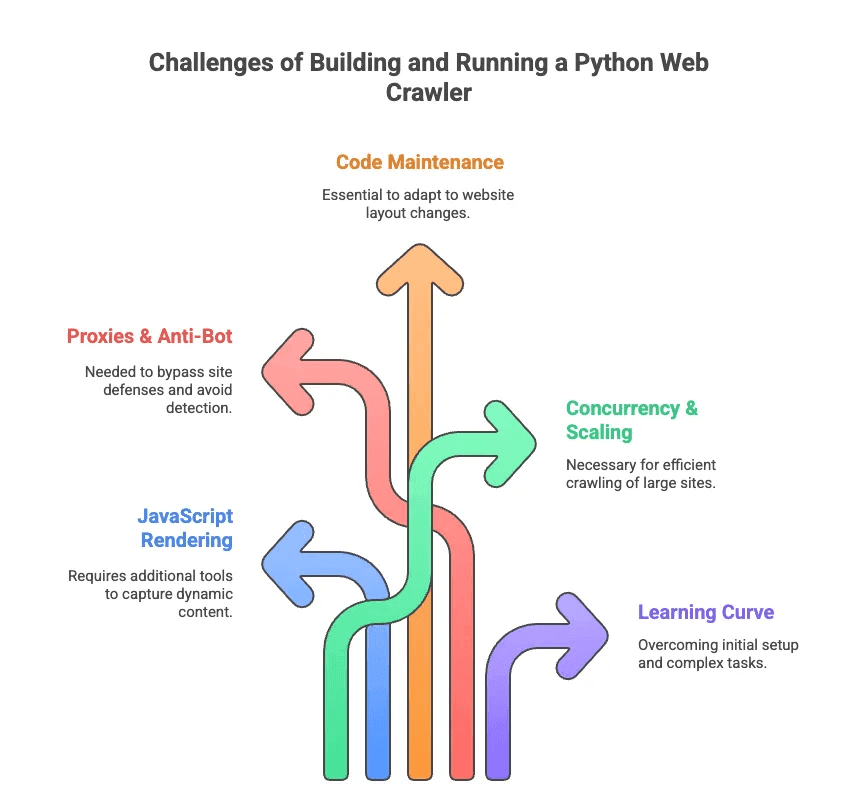
- JavaScript-rendering: De meeste moderne sites laden content dynamisch. Scrapy en BeautifulSoup zien deze data niet zonder extra tools.
- Proxies & anti-bot: Veel sites houden niet van crawlers. Je moet proxies roteren, user agents faken en soms zelfs CAPTCHAs oplossen.
- Code-onderhoud: Websites veranderen vaak van structuur. Je scraper kan van de ene op de andere dag stuk gaan, waarna je selectors of logica moet aanpassen.
- Schaalbaarheid & gelijktijdigheid: Duizenden pagina's crawlen? Dan moet je asynchrone verzoeken, foutafhandeling en datastromen beheren.
- Leercurve: Voor niet-ontwikkelaars is zelfs het opzetten van Python en dependencies al lastig. Laat staan paginering of loginflows automatiseren.
Zoals een engineer het verwoordde: custom scrapers schrijven voelt soms als 'een PhD in selectorconfiguratie nodig hebben'—niet bepaald waar de gemiddelde sales- of marketingprofessional op zit te wachten (Thunderbit Blog).
AI-webscraper vs. Python webcrawler: Nieuwe mogelijkheden voor bedrijven
Dus, wat als je alleen de data wilt, zonder de kopzorgen? Dan is er de AI-webscraper. Tools als Thunderbit zijn gemaakt voor zakelijke gebruikers, niet voor programmeurs. Ze gebruiken AI om webpagina's te lezen, stellen automatisch voor welke data je moet extraheren, en regelen alles achter de schermen (paginering, subpagina's, anti-bot).
Hier een snelle vergelijking:
| Functie | Python webcrawler | AI-webscraper (Thunderbit) |
|---|---|---|
| Installatie | Code, libraries, configuratie | 2-kliks Chrome-extensie |
| Onderhoud | Handmatig updaten, debuggen | AI past zich aan sitewijzigingen aan |
| Dynamische content | Selenium of plugins nodig | Ingebouwde browser/cloud rendering |
| Anti-bot | Proxies, user agents | AI & cloud-omzeiling |
| Schaalbaarheid | Hoog (met moeite) | Hoog (cloud, parallel scraping) |
| Gebruiksgemak | Voor ontwikkelaars | Voor iedereen |
| Data-export | Code of scripts | 1-klik naar Sheets, Airtable, Notion |
Met Thunderbit hoef je je niet druk te maken over HTTP-verzoeken, JavaScript of proxies. Klik gewoon op 'AI Suggest Fields', laat de AI bepalen wat belangrijk is, en druk op 'Scrape'. Het is alsof je een persoonlijke databutler hebt—zonder smoking.
Probeer Thunderbit AI-webscraper gratis
Thunderbit: De nieuwe generatie AI-webscraper voor iedereen
Even concreet: Thunderbit is een AI-gedreven webscraper Chrome-extensie die webdata extraheren net zo makkelijk maakt als eten bestellen. Dit maakt Thunderbit uniek:
- AI-veldherkenning: Thunderbit's AI leest de pagina en stelt automatisch voor welke velden (kolommen) je moet extraheren—geen gedoe meer met CSS-selectors (Thunderbit Blog).
- Dynamische pagina's: Zowel statische als JavaScript-rijke pagina's worden ondersteund, dankzij browser- en cloudmodi.
- Subpagina's & paginering: Heb je details nodig van elk product of profiel? Thunderbit klikt automatisch door naar subpagina's en verzamelt alles (Thunderbit Blog).
- Sjabloonflexibiliteit: Eén scraper-sjabloon past zich aan verschillende paginavormen aan—je hoeft niet steeds opnieuw te bouwen als een site verandert.
- Anti-bot omzeiling: AI en cloudinfrastructuur helpen om anti-scrapingmaatregelen te omzeilen.
- Data-export: Stuur je data direct naar Google Sheets, Airtable, Notion of download als CSV/Excel—zelfs in de gratis versie (Thunderbit Blog).
- AI-dataschoonmaak: Vat data samen, categoriseer of vertaal direct—geen rommelige spreadsheets meer.
Praktijkvoorbeelden:
- Salesteams halen in enkele minuten prospectlijsten uit directories of LinkedIn.
- E-commerce managers volgen concurrentieprijzen en productwijzigingen zonder handmatig werk.
- Makelaars verzamelen vastgoedaanbod en contactgegevens van meerdere sites.
- Marketingteams analyseren content, zoekwoorden en backlinks voor SEO—zonder ook maar één regel code te schrijven.
Thunderbit werkt zo eenvoudig dat zelfs mijn niet-technische vrienden ermee aan de slag kunnen—en dat doen ze ook. Installeer de extensie, open je doelwebsite, klik op 'AI Suggest Fields' en je bent vertrokken. Voor populaire sites als Amazon of LinkedIn zijn er zelfs kant-en-klare sjablonen—één klik en klaar (Thunderbit Blog).
Wat is Data Scraping en hoe doe je het in 2025 Get Started Free
Wanneer kies je voor een Python webcrawler of een AI-webscraper?
Dus, moet je zelf een Python webcrawler bouwen of gewoon Thunderbit gebruiken? Mijn eerlijke advies:
| Situatie | Python webcrawler | AI-webscraper (Thunderbit) |
|---|---|---|
| Maatwerklogica of enorme schaal nodig | ✔️ | Misschien (cloudmodus) |
| Diepe integratie met andere systemen | ✔️ (met code) | Beperkt (via export) |
| Niet-technische gebruiker, snel resultaat | ❌ | ✔️ |
| Regelmatig veranderende sites | ❌ (handmatig bijwerken) | ✔️ (AI past zich aan) |
| Dynamische/JS-rijke sites | ✔️ (met Selenium) | ✔️ (ingebouwd) |
| Klein budget, kleine projecten | Misschien (gratis, maar tijd) | ✔️ (gratis, geen paywall) |
Kies voor Python webcrawlers als:
- Je ontwikkelaar bent en volledige controle wilt.
- Je miljoenen pagina's crawlt of aangepaste datastromen nodig hebt.
- Je het niet erg vindt om onderhoud en debugging te doen.
Kies voor Thunderbit als:
- Je direct data wilt, zonder wekenlang te coderen.
- Je in sales, e-commerce, marketing of vastgoed werkt en gewoon resultaat wilt.
- Je geen zin hebt in proxies, selectors of anti-botproblemen.
Twijfel je nog? Hier een korte checklist:
- Ben je handig met Python en webtechnologie? Probeer Scrapy of Selenium.
- Wil je gewoon snel en netjes de data? Dan is Thunderbit je beste keuze.
Start met Thunderbit AI-webscraper
Conclusie: Webdata ontsluiten—het juiste gereedschap voor de juiste gebruiker
Webcrawlen en webscraping zijn onmisbare vaardigheden in een datagedreven wereld. Maar laten we eerlijk zijn: niet iedereen wil een webcrawl-expert worden. Python webcrawlers zoals Scrapy, BeautifulSoup en Selenium zijn krachtig, maar vragen veel kennis en onderhoud.
Daarom ben ik zo enthousiast over de opkomst van AI-webscrapers zoals Thunderbit. We hebben Thunderbit gebouwd om webdata voor iedereen toegankelijk te maken—niet alleen voor developers. Dankzij AI-veldherkenning, ondersteuning voor dynamische pagina's en no-code workflows kan iedereen binnen enkele minuten de gewenste data extraheren.
Of je nu een developer bent die graag sleutelt aan code, of een zakelijke gebruiker die gewoon snel data wil: er is altijd een passende tool. Kijk naar je behoeften, je technische kennis en je deadline. En wil je ervaren hoe eenvoudig webdata extraheren kan zijn? Probeer Thunderbit eens—je toekomstige zelf (en je spreadsheet) zullen je dankbaar zijn.
Meer weten? Bekijk meer handleidingen op de Thunderbit Blog, zoals Wat is Data Scraping en hoe doe je het in 2025 of Hoe je website-data naar Excel haalt met AI. Veel succes met crawlen—en scrapen!
Probeer AI-webscraper Get Started Free
Veelgestelde vragen
1. Wat is het verschil tussen een Python webcrawler en een webscraper?
Een Python webcrawler is bedoeld om systematisch webpagina's te ontdekken en te indexeren door links te volgen—ideaal om de structuur van een site in kaart te brengen. Een webscraper haalt juist specifieke data van die pagina's, zoals prijzen of e-mails. Crawlers brengen het web in kaart; scrapers verzamelen de data die jij nodig hebt. Vaak worden ze samen gebruikt in Python voor complete dataworkflows.
2. Welke Python-bibliotheken zijn het beste voor het bouwen van een webcrawler?
Populaire libraries zijn Scrapy, BeautifulSoup en Selenium. Scrapy is snel en schaalbaar voor grote projecten; BeautifulSoup is ideaal voor beginners en statische pagina's; Selenium blinkt uit bij JavaScript-rijke sites, maar is trager. De beste keuze hangt af van je technische kennis, het soort content en de omvang van je project.
3. Is er een makkelijkere manier om webdata te krijgen zonder een Python webcrawler te coderen?
Ja—Thunderbit is een AI-gedreven Chrome-extensie waarmee iedereen in twee klikken webdata kan extraheren. Geen code, geen installatie. Het herkent automatisch velden, regelt paginering en subpagina's, en exporteert data naar Sheets, Airtable of Notion. Ideaal voor sales, marketing, e-commerce of vastgoedteams die snel schone data willen.
Meer weten:




