

Het web van 2025 is een snel veranderend en soms onvoorspelbaar speelveld—de ene dag ben je druk bezig met het volgen van concurrentieprijzen, de volgende dag zit je te stoeien met ingewikkelde JavaScript en slimme anti-botbeveiliging. Na jaren ervaring met het bouwen van automatiseringstools voor sales- en operationele teams kan ik je verzekeren: webscraping is allang geen ‘leuke extra’ meer. Het is een absolute must-have skill voor elk bedrijf. Nu 90% van de bedrijven vertrouwt op data-analyse voor strategische keuzes en de hoeveelheid online data in vier jaar tijd met bijna 193% is gegroeid, is het kunnen omzetten van rommelige webinfo naar bruikbare inzichten hét verschil tussen vooroplopen of achterblijven.

Toch is webscraping niet meer wat het ooit was. De tijd dat je met een paar regels Python simpele HTML kon binnenhalen, is echt voorbij. Tegenwoordig krijg je te maken met dynamische content, eindeloos scrollen en anti-botmaatregelen waar zelfs een geheim agent van zou zweten. Of je nu net begint of je scraping-skills wilt aanscherpen, deze gids neemt je mee langs de beste tools, methodes en workflows voor Python scraping in 2025—en laat zien hoe je met AI-tools zoals Thunderbit je projecten naar een hoger niveau tilt.
Met AI data van elke website halen Get Started Free
Van Beginner tot Expert: De Basis van Python Webscraping
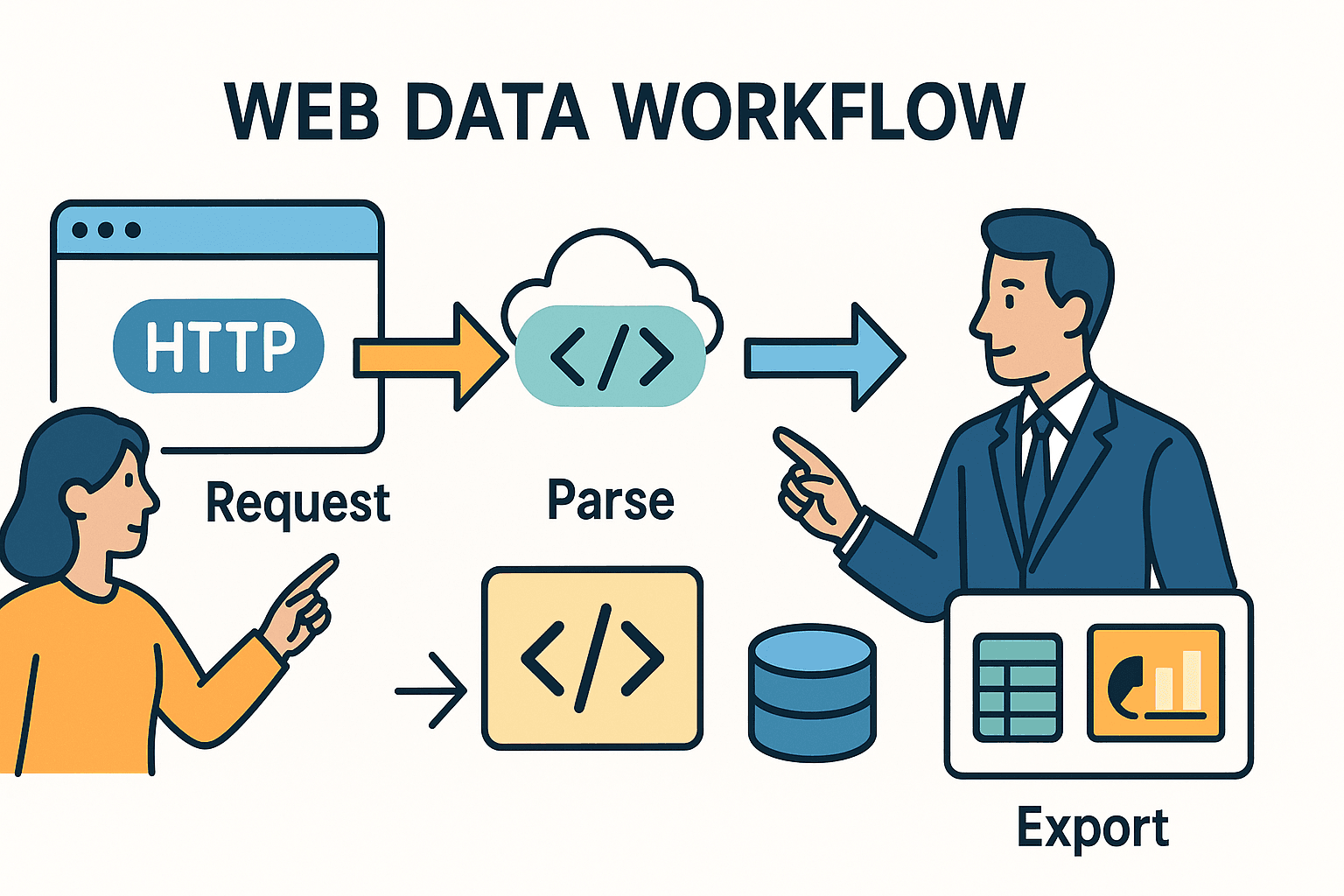
Laten we bij het begin beginnen. Webscraping draait in de kern om het automatiseren van wat je normaal in je browser doet: een pagina openen, de juiste data vinden en die opslaan. In Python bestaat dit meestal uit drie stappen:
- Een HTTP-verzoek sturen (zoals je browser doet als je een URL bezoekt).
- De HTML parseren om de data te vinden die je zoekt.
- De data exporteren of verwerken—bijvoorbeeld naar een spreadsheet, database of dashboard.
Let op: de tools die je gebruikt (en de uitdagingen die je tegenkomt) hangen af van hoe ingewikkeld de website is en wat je wilt bereiken.
Python Scraping 101: Zo Werkt Het
Zie scraping als een bibliothecaris die een krant voor je haalt, waarna jij met een schaar alleen de artikelen uitknipt die je nodig hebt. De requests-bibliotheek van Python is je bibliothecaris—die haalt de HTML op. BeautifulSoup is je schaar—daarmee knip en plak je precies de juiste stukjes uit de HTML.
Maar wat als de krant in onzichtbare inkt is geschreven (hallo JavaScript!) of de artikelen verspreid zijn over tientallen pagina’s? Dan heb je geavanceerdere tools nodig—of een beetje AI-magie.
Vergelijking van de Belangrijkste Tools
Hier een kort overzicht van de populairste Python scraping-tools en wanneer je ze gebruikt:
| Tool/Bibliotheek | Gebruik bij... | Voordelen | Nadelen |
|---|---|---|---|
| Requests + BeautifulSoup | Statische pagina’s of kleine klussen | Simpel, snel, ideaal voor beginners. Volledige controle. | Kan geen JavaScript of grootschalige crawling aan. |
| Scrapy | Grote projecten, veel pagina’s/sites | Hoge performance, ingebouwde crawler, async, pipelines, robuuste foutafhandeling. | Steilere leercurve, meer opzet vereist. |
| Selenium/Playwright | Pagina’s met JavaScript, logins of gebruikersacties | Kan alles scrapen wat een browser toont. Geschikt voor dynamische content, logins, infinite scroll. | Langzamer, vraagt meer resources, complexer te deployen. |
| Thunderbit (AI) | Ongestructureerde data, PDF’s, afbeeldingen, of no-code nodig | AI herkent velden automatisch, verwerkt subpagina’s, exporteert naar Excel/Sheets, geen code nodig. | Minder aanpasbaar voor uitzonderingen, werkt op credits. |
Voor de meeste zakelijke gebruikers is requests met BeautifulSoup ideaal voor eenvoudige, statische sites. Voor grotere of complexere klussen is Scrapy je beste vriend. En als je vastloopt—door dynamische content, anti-botmaatregelen of ongestructureerde data—dan zijn AI-tools zoals Thunderbit een uitkomst.
Probeer Thunderbit AI-webscraper gratis
Het Proces: Stapsgewijze Best Practices voor Complexe Scraping
Hoe ga je van “ik wil die data” naar een robuuste, onderhoudbare scraper? Dit is mijn beproefde workflow:
1. Analyseer en Begrijp de Doelwebsite
Voordat je begint te coderen, open je de Developer Tools van je browser (F12 of rechtsklik > Inspecteren). Zoek de gewenste data in de HTML. Staat het in een tabel? In een reeks <div>s? Is er een verborgen API die JSON terugstuurt? Soms ligt de makkelijkste oplossing voor het oprapen.
Pro tip: Zie je een netwerkverzoek dat JSON ophaalt als je op “volgende pagina” of “meer laden” klikt? Dan kun je vaak direct die API aanroepen met Python, zonder HTML te hoeven parseren.
2. Begin Klein: Prototype op Eén Pagina
Start eenvoudig. Gebruik requests om één pagina op te halen en BeautifulSoup om een paar velden te extraheren. Print de resultaten. Blokkeert de site of ontbreekt de data? Voeg dan headers toe (zoals een User-Agent van een echte browser), of check of de content via JavaScript wordt geladen (zie stap 3).
3. Omgaan met Dynamische Content en Paginering
Staat de data niet in de HTML? Dan wordt deze waarschijnlijk via JavaScript geladen. Wat kun je doen:
- Browserautomatisering: Gebruik Selenium of Playwright om de pagina te openen, te wachten tot de content geladen is, en de gerenderde HTML op te halen.
- API-aanroepen: Zoek in het Netwerk-tabblad naar XHR-verzoeken. Vind je een endpoint dat JSON terugstuurt, dan kun je die vaak direct met
requestsaanroepen. - Paginering: Voor data over meerdere pagina’s, loop je door de paginanummers of volg je “Volgende”-links. Bij infinite scroll gebruik je Selenium om naar beneden te scrollen of simuleer je de API-aanroepen die door scrollen worden getriggerd.
4. Foutafhandeling en Netjes Scrapen
Websites zijn niet altijd blij met scrapers. Voorkom blokkades door:
- Respecteer
robots.txt: Check altijdexample.com/robots.txtop verboden paden of crawl-delays. - Rate limiting: Voeg
time.sleep()toe tussen verzoeken. Staat erCrawl-delay: 5inrobots.txt, wacht dan minstens 5 seconden. - Custom User-Agent: Stel je scraper netjes voor (bijv.
"MyScraper/1.0 (jouw@email.com)"). - Retry-logica: Gebruik try/except-blokken. Probeer opnieuw bij fouten, wacht langer bij HTTP 429 (Too Many Requests).
5. Data Parseren en Opschonen
Gebruik BeautifulSoup of Scrapy-selectors om velden te extraheren. Verwijder overbodige spaties, zet prijzen om naar getallen, parseer datums en controleer op volledigheid. Voor grote datasets kun je pandas gebruiken voor opschonen en deduplicatie.
6. Subpagina’s Scrapen
Vaak staat de echte waarde op detailpagina’s. Scrape een lijst met links en bezoek elke link om meer info te verzamelen. In Python betekent dit: door de URLs loopen en elke pagina ophalen. In Thunderbit kun je de functie “Subpagina’s scrapen” gebruiken—AI bezoekt dan automatisch elke subpagina en verrijkt je dataset.
7. Exporteren en Automatiseren
Exporteer je opgeschoonde data naar CSV, Excel, Google Sheets of een database. Voor terugkerende taken plan je je script in met cron, Airflow, of (met Thunderbit) stel je een geplande cloud scrape in met natuurlijke taal (“elke maandag om 9:00”).
Websitegegevens naar Excel halen met AI Get Started Free
Thunderbit: Wanneer AI je Python Scraping Workflow Versterkt
Soms is zelfs de beste Python-code niet opgewassen tegen rommelige, ongestructureerde of beschermde data. Dan biedt Thunderbit uitkomst.
Hoe Thunderbit Python Aanvult
Thunderbit is een AI-gedreven Chrome-extensie die webpagina’s (of PDF’s, afbeeldingen, enz.) omzet naar gestructureerde data—zonder code. Zo gebruik ik het naast Python:
- Voor ongestructureerde data: Kom ik een PDF, afbeelding of onvoorspelbare HTML tegen, dan laat ik Thunderbit’s AI het werk doen. Het haalt tabellen uit PDF’s, tekst uit afbeeldingen en stelt zelfs automatisch velden voor.
- Voor subpagina’s en meerstaps scraping: De “Subpagina’s scrapen”-functie van Thunderbit bespaart enorm veel tijd. Scrape een overzichtspagina, laat AI elke detailpagina bezoeken en de resultaten samenvoegen—geen ingewikkelde loops of state management nodig.
- Voor export: Thunderbit exporteert direct naar Excel, Google Sheets, Notion of Airtable. Daarna kan ik de data in mijn Python-pipeline verder analyseren of rapporteren.
Praktijkvoorbeeld: Python + Thunderbit in Actie
Stel, ik volg vastgoedaanbiedingen. Met Python en Scrapy verzamel ik de listing-URLs van verschillende sites. Maar één site plaatst de details alleen in downloadbare PDF’s. In plaats van een eigen PDF-parser te schrijven, upload ik die bestanden naar Thunderbit, laat de AI de tabellen extraheren en exporteer naar CSV. Vervolgens voeg ik alle data samen in Python voor een compleet marktoverzicht.
Of ik bouw een leadlijst voor sales. Met Python scrape ik bedrijfs-URLs, daarna gebruik ik Thunderbit’s gratis e-mail- en telefoonextractors om contactgegevens van elke site te halen—zonder gedoe met regex.
Ongestructureerde data scrapen met Thunderbit AI
Een Duurzame Scraping Workflow Bouwen: Van Script tot Pipeline
Een eenmalig script is handig voor snelle resultaten, maar de meeste zakelijke scrapingbehoeften zijn structureel. Zo bouw ik een schaalbare, onderhoudbare scraping-stack:
Het CCCD-model: Crawl, Collect, Clean, Debug
- Crawl: Verzamel alle doel-URLs (uit sitemaps, zoekpagina’s of een lijst).
- Collect: Haal data op van elke URL (met Python, Thunderbit of beide).
- Clean: Normaliseer, dedupliceer en valideer de data.
- Debug/Monitor: Log elke run, handel fouten af en stel alerts in voor storingen of afwijkingen.
Zie dit als een pipeline:
URLs → [Crawler] → [Scraper] → [Cleaner] → [Exporter] → [Business Platform]
Plannen en Monitoren
- Voor Python: Gebruik cronjobs, Airflow of cloud schedulers om scripts periodiek te draaien. Log output, stuur e-mail of Slack-alerts bij fouten.
- Voor Thunderbit: Gebruik de ingebouwde planner—typ simpelweg “elke maandag om 9:00” en Thunderbit voert de scrape automatisch in de cloud uit en exporteert de data waar je wilt.
Documentatie en Overdracht
Zet je code in versiebeheer (Git), documenteer je workflow en zorg dat minstens één collega weet hoe de pipeline werkt of aangepast kan worden. Voor workflows met Python én Thunderbit: noteer welk tool welke site verwerkt en waar de output terechtkomt (bijv. “Thunderbit scraped Site C naar Google Sheets, Python voegt alle data wekelijks samen”).
Ethiek en Wetgeving: Verantwoord Scrapen in 2025
Met grote scrapingkracht komt grote verantwoordelijkheid. Zo blijf je binnen de regels en goede zakelijke praktijken:
Robots.txt en Rate Limiting
- Check robots.txt: Bekijk altijd het robots.txt-bestand van de site voor verboden paden en crawl-delays. Gebruik Python’s
robotparserom dit te automatiseren. - Netjes scrapen: Voeg vertragingen toe tussen verzoeken, zeker als er een
Crawl-delayis opgegeven. Overlaad een site nooit met te veel verzoeken tegelijk. - User-Agent: Stel je scraper eerlijk voor. Doe je niet voor als Googlebot of een andere browser.
Privacy en Wetgeving
- GDPR/CCPA: Verzamel je persoonsgegevens (namen, e-mails, telefoonnummers), dan ben je verantwoordelijk voor de verwerking volgens privacywetgeving. Verzamel alleen wat nodig is, beveilig de data en wees bereid om op verzoek te verwijderen.
- Gebruiksvoorwaarden: Scrape niet achter logins zonder toestemming. Veel ToS verbieden geautomatiseerde toegang—overtreding kan leiden tot een ban of erger.
- Alleen openbare data: Beperk je tot publiek toegankelijke informatie. Scrape geen privé, auteursrechtelijk beschermde of gevoelige data.
Compliance Checklist
- Robots.txt gecontroleerd op regels en vertragingen
- Netjes rate limiting en custom User-Agent toegevoegd
- Alleen openbare, niet-gevoelige data gescrapet
- Persoonsgegevens verwerkt volgens privacywetgeving
- Geen ToS of copyright geschonden
Veelvoorkomende Fouten en Debugging Tips: Maak je Scraper Robuust
Zelfs de beste scrapers lopen soms vast. Dit zijn de meest voorkomende problemen—en zo los ik ze op:
| Fouttype | Symptoom/Bericht | Debugging Tip |
|---|---|---|
| HTTP 403/429/500 | Geblokkeerd, rate-limited, of serverfout | Check headers, vertraag, roteer IP’s of gebruik proxies. Respecteer crawl-delays. |
| Ontbrekende data/NoneType | Data niet gevonden in HTML | Print en inspecteer de HTML. Misschien is de structuur veranderd of krijg je een blockpagina. |
| JavaScript-gerenderde data | Data ontbreekt in statische HTML | Gebruik Selenium/Playwright of zoek de onderliggende API-aanroep. |
| Parseer-/encodingproblemen | Unicodefouten, vreemde tekens | Stel de juiste encoding in, gebruik .text of html.unescape(). |
| Duplicaten/inconsistenties | Herhaalde of niet-kloppende data | Dedupliceer op unieke ID of URL. Controleer op volledigheid van velden. |
| Anti-bot/CAPTCHA | CAPTCHA-pagina of login vereist | Vertraag, gebruik browserautomatisering of schakel over op Thunderbit/AI voor lastige gevallen. |
Debugging Workflow:
- Print de ruwe HTML als het misgaat.
- Gebruik browser DevTools om te vergelijken wat je script ziet versus de browser.
- Log elke stap—URLs, statuscodes, aantal gescrapete items.
- Test eerst op een klein aantal pagina’s voordat je opschaalt.
Geavanceerde Projectideeën: Til je Python Scraping naar een Hoger Niveau
Klaar om best practices toe te passen? Probeer eens deze praktijkprojecten:
1. Prijsmonitoring Dashboard voor E-commerce
Scrape prijzen en voorraad van Amazon, eBay en Walmart. Omzeil anti-botmaatregelen, dynamische content en exporteer dagelijks naar Google Sheets voor trendanalyse. Gebruik Thunderbit’s kant-en-klare templates voor snelle resultaten.
2. Jobaanbiedingen Aggregator
Verzamel vacatures van Indeed en niche jobboards. Parseer titels, bedrijven, locaties en publicatiedata. Verwerk paginering en dedupliceer op vacature-ID. Plan dagelijkse runs en exporteer naar Airtable.
3. Contactgegevens Extractor voor Leadgeneratie
Geef een lijst met bedrijfs-URLs en haal e-mails en telefoonnummers van homepages en contactpagina’s. Gebruik regex in Python of Thunderbit’s gratis extractors voor snelle resultaten. Exporteer naar Excel voor je salesteam.
4. Vastgoedaanbiedingen Vergelijken
Scrape listings van Zillow en Realtor.com voor een specifieke regio. Normaliseer adressen en prijzen, vergelijk trends en visualiseer in Google Sheets.
5. Social Media Mentions Tracker
Volg merkvermeldingen op Reddit via hun JSON API. Tel posts, analyseer sentiment en exporteer tijdreeksen voor marketinginzichten.
Conclusie: Belangrijkste Lessen voor Python Scraping in 2025
Samengevat:
- Webscraping is belangrijker dan ooit voor business intelligence, sales en operations. Het web is een goudmijn—als je weet hoe je moet delven.
- Python is je Zwitsers zakmes: Begin eenvoudig met
requestsenBeautifulSoup, schaal op met Scrapy en gebruik browserautomatisering voor dynamische sites. - AI-tools zoals Thunderbit zijn je geheime wapen voor ongestructureerde, complexe of no-code scraping. Combineer Python en AI voor maximale efficiëntie.
- Best practices zijn essentieel: Inspecteer eerst, codeer modulair, vang fouten af, maak je data schoon en automatiseer je workflow.
- Compliance is geen keuze: Check altijd robots.txt, respecteer privacywetgeving en scrape ethisch.
- Blijf flexibel: Het web verandert—monitor je scrapers, debug regelmatig en wees klaar om je aanpak aan te passen.
De toekomst van webscraping is hybride, ethisch en gericht op zakelijk succes. Of je nu een beginner bent of een doorgewinterde pro: blijf leren, wees nieuwsgierig en laat data je volgende succes bepalen.
Bijlage: Python Scraping Tutorials & Tools
Mijn favoriete bronnen voor leren en troubleshooting:
- Requests Documentatie – HTTP voor mensen, met alle extra’s.
- BeautifulSoup Docs – Leer HTML parseren als een pro.
- Scrapy Documentatie – Voor grootschalige, professionele scraping.
- Selenium met Python / Playwright voor Python – Voor browserautomatisering en dynamische content.
- Thunderbit Chrome-extensie – De makkelijkste AI-webscraper voor zakelijke gebruikers.
- Thunderbit Blog – Tutorials, praktijkvoorbeelden en best practices voor AI-gedreven scraping.
- AIMultiple’s Legal Guide – Blijf op de hoogte van compliance en ethiek.
- Stack Overflow / Reddit r/webscraping** – Community Q&A en troubleshooting.
Wil je zien hoe Thunderbit je scraping makkelijker maakt? Bekijk onze YouTube Channel voor demo’s en deep dives.
Veelgestelde Vragen
1. Wat is de beste Python-bibliotheek voor webscraping in 2025?
Voor statische pagina’s en kleine klussen blijft requests + BeautifulSoup de standaard. Voor grootschalige of multi-page scraping is Scrapy het beste. Voor dynamische content gebruik je Selenium of Playwright. Voor ongestructureerde of lastige data zijn AI-tools zoals Thunderbit onmisbaar.
2. Hoe ga ik om met JavaScript-rijke of dynamische sites?
Gebruik browserautomatiseringstools zoals Selenium of Playwright om de pagina te renderen en data te extraheren. Of inspecteer het Netwerk-tabblad voor API-aanroepen die JSON teruggeven—vaak makkelijker en betrouwbaarder te scrapen.
3. Is webscraping legaal?
Het scrapen van openbare data is in de VS meestal toegestaan, maar check altijd robots.txt, respecteer de gebruiksvoorwaarden van de site en houd je aan privacywetgeving zoals GDPR/CCPA. Scrape nooit privé, auteursrechtelijk beschermde of gevoelige informatie.
4. Hoe kan ik mijn scraping-workflows automatiseren en plannen?
Voor Python-scripts gebruik je cronjobs, Airflow of cloud schedulers. Voor no-code automatisering biedt Thunderbit ingebouwde planning—beschrijf je schema in gewone taal en laat het in de cloud draaien.
5. Wat moet ik doen als mijn scraper niet meer werkt?
Controleer eerst of de website-structuur is veranderd of dat je geblokkeerd wordt (HTTP 403/429). Inspecteer de HTML, pas je selectors aan, vertraag je verzoeken en check op anti-botmaatregelen. Blijft het probleem, probeer dan de AI-functies van Thunderbit of schakel over op browserautomatisering.
Veel succes met scrapen—en moge je data altijd schoon, compliant en direct bruikbaar zijn. Wil je zien hoe Thunderbit in jouw workflow past? Download de Chrome-extensie en probeer het uit. Meer tips? De Thunderbit Blog staat altijd voor je klaar.
Probeer Thunderbit AI-webscraper gratis Get Started Free




