
Het internet is tegenwoordig één grote beeldvijver—elke dag duiken er miljarden nieuwe plaatjes op, van productfoto’s tot de nieuwste memes. Werk je in sales, marketing of onderzoek? Dan heb je vast wel eens eindeloos plaatjes moeten verzamelen, stuk voor stuk. Geloof me, ik weet hoe frustrerend het is: urenlang ‘rechtsklik, opslaan als’ en je afvragen of het niet slimmer kan. Goed nieuws: dat kan zeker! Met een Python image scraper of no-code tools zoals kun je razendsnel afbeeldingen van websites binnenhalen.
In deze gids neem ik je stap voor stap mee in het scrapen van afbeeldingen met Python, hoe je omgaat met lastige dynamische sites, en waarom de combinatie van Python en Thunderbit je workflow een flinke boost geeft. Of je nu een productcatalogus bouwt, concurrenten in de gaten houdt of gewoon klaar bent met handmatig kopiëren en plakken—hier vind je praktische tips, codevoorbeelden en een vleugje nuchtere humor.
Wat is een Python Image Scraper?
Een Python image scraper is een script of tool die automatisch websites afstruint, plaatjes (zoals die in <img>-tags) opspoort en ze direct op je computer parkeert. In plaats van elke afbeelding handmatig te downloaden, doet Python het zware werk: pagina’s ophalen, HTML doorspitten en bestanden in bulk opslaan ().
Wie gebruikt Python image scrapers? Iedereen die snel veel plaatjes nodig heeft:
- E-commerce teams: Productfoto’s van leveranciers binnenhalen voor de webshop.
- Marketeers: Social media-afbeeldingen verzamelen voor campagnes of trendonderzoek.
- Onderzoekers: Datasets bouwen voor AI/ML-projecten of academisch werk.
- Makelaars: Vastgoedfoto’s verzamelen voor advertenties of marktanalyses.
Zie een Python image scraper als je digitale stagiair—maar dan eentje die nooit moe wordt of afgeleid raakt door kattenfilmpjes.
Waarom Python gebruiken voor het scrapen van afbeeldingen?
 Python is het Zwitsers zakmes onder de webscrapers. Dit maakt het zo geschikt voor het verzamelen van plaatjes:
Python is het Zwitsers zakmes onder de webscrapers. Dit maakt het zo geschikt voor het verzamelen van plaatjes:
- Uitgebreid aanbod aan libraries: Tools als Requests, BeautifulSoup en Selenium dekken alles van simpele HTML tot complexe, JavaScript-gedreven sites ().
- Makkelijk te leren: Python is lekker leesbaar en er zijn talloze tutorials en een grote community.
- Flexibel en schaalbaar: Je kunt één pagina scrapen of duizenden, downloads automatiseren en zelfs plaatjes direct verwerken.
- Scheelt bakken met tijd en geld: Uit een test bleek dat het scrapen van 100 afbeeldingen met Python maar 12 minuten kostte, tegenover 2 uur handmatig ().
Een overzicht van zakelijke toepassingen:
| Toepassing | Handmatig probleem | Voordeel Python scraper |
|---|---|---|
| Productcatalogus | Uren kopiëren en plakken | Duizenden afbeeldingen in minuten |
| Concurrentieanalyse | Details missen, traag | Snel afbeeldingen vergelijken |
| Trendonderzoek | Onvolledige datasets | Grote, diverse beeldverzamelingen |
| AI/ML dataset bouwen | Saai labelen | Automatisch verzamelen en voorbereiden |
| Vastgoedadvertenties | Verouderde, verspreide data | Foto’s eenvoudig centraliseren en updaten |
Onmisbare tools voor Python image scraping
Dit zijn de belangrijkste Python-libraries voor het scrapen van plaatjes:
| Bibliotheek | Functie | Ideaal voor | Voordelen | Nadelen |
|---|---|---|---|---|
| Requests | Webpagina’s en afbeeldingen ophalen via HTTP | Statische sites | Simpel, snel | Geen HTML-parsing, geen JS |
| BeautifulSoup | HTML parseren om <img>-tags te vinden | Afbeeldings-URL’s extraheren | Makkelijk, vergevingsgezind | Geen JS-ondersteuning |
| Scrapy | Volledig scraping/crawling framework | Grote projecten | Async, ingebouwde export | Steilere leercurve |
| Selenium | Browser automatiseren (JS, scrollen) | Dynamische/JS-sites | Kan JS renderen, simuleert gebruiker | Langzamer, meer setup |
| Pillow (PIL) | Afbeeldingen verwerken na download | Controleren/bewerken | Resizen, converteren, checken | Niet voor het scrapen zelf |
Wanneer gebruik je wat?
- Voor de meeste statische sites:
requests + BeautifulSoupis je go-to. - Voor dynamische sites (oneindig scrollen, JS-galerijen):
Seleniumis je redder in nood. - Voor grote, herhaalbare projecten:
Scrapybiedt structuur en snelheid. - Voor beeldbewerking:
Pillowis top na het downloaden.
Stapsgewijs: Afbeeldingen downloaden van een website met Python
Tijd om aan de slag te gaan! Zo download je plaatjes van een statische website met Python.
Je Python-omgeving opzetten
Zorg eerst dat je Python 3 op je laptop hebt staan. Maak daarna (optioneel) een virtuele omgeving aan:
1python3 -m venv venv
2source venv/bin/activate # Op Windows: venv\Scripts\activateInstalleer de benodigde libraries:
1pip install requests beautifulsoup4Afbeeldings-URL’s vinden en extraheren
Open de gewenste website in je browser. Klik met rechts en kies ‘Inspecteren’ om de <img>-tags te spotten—dat zijn je doelwitten.
Voorbeeldscript om de afbeeldings-URL’s te verzamelen:
1import requests
2from bs4 import BeautifulSoup
3from urllib.parse import urljoin
4import os
5url = "https://example.com"
6response = requests.get(url)
7soup = BeautifulSoup(response.text, "html.parser")
8img_tags = soup.find_all("img")
9img_urls = [urljoin(url, img.get("src")) for img in img_tags if img.get("src")]Tip: Sommige sites gebruiken data-src of srcset voor lazy-loaded plaatjes. Check ook die attributen.
Afbeeldingen downloaden en opslaan
Zo sla je de plaatjes op in een map:
1os.makedirs("images", exist_ok=True)
2for i, img_url in enumerate(img_urls):
3 try:
4 img_resp = requests.get(img_url, headers={"User-Agent": "Mozilla/5.0"})
5 if img_resp.status_code == 200:
6 file_ext = img_url.split('.')[-1].split('?')[0]
7 file_name = f"images/img_{i}.{file_ext}"
8 with open(file_name, "wb") as f:
9 f.write(img_resp.content)
10 print(f"Downloaded {file_name}")
11 except Exception as e:
12 print(f"Failed to download {img_url}: {e}")Tips voor organiseren:
- Geef bestanden namen op basis van product-ID’s of paginatitels.
- Gebruik submappen voor verschillende categorieën of bronnen.
- Check op dubbele bestanden (vergelijk URL’s of gebruik hashes).
Veelvoorkomende fouten en oplossingen
- Ontbrekende afbeeldingen? Misschien worden ze via JavaScript geladen—zie het volgende hoofdstuk.
- Geblokkeerde verzoeken? Stel een realistische User-Agent in en voeg
time.sleep()-pauzes toe tussen downloads. - Dubbele downloads? Houd een set van bezochte URL’s of bestandsnamen bij.
- Toegangsproblemen? Check of je script schrijfrechten heeft op de doelmap.
Afbeeldingen scrapen van dynamische en JavaScript-rijke pagina’s
Sommige websites verstoppen hun plaatjes achter JavaScript, oneindig scrollen of ‘meer laden’-knoppen. Met Selenium kun je deze toch binnenhalen.
Selenium gebruiken voor dynamische content
Installeer eerst Selenium en een browserdriver (bijvoorbeeld ChromeDriver):
1pip install seleniumDownload en voeg deze toe aan je PATH.
Voorbeeldscript met Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3import time
4import os
5driver = webdriver.Chrome()
6driver.get("https://example.com/gallery")
7# Scroll naar beneden om meer afbeeldingen te laden
8last_height = driver.execute_script("return document.body.scrollHeight")
9while True:
10 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
11 time.sleep(2) # Wacht tot afbeeldingen geladen zijn
12 new_height = driver.execute_script("return document.body.scrollHeight")
13 if new_height == last_height:
14 break
15 last_height = new_height
16img_elements = driver.find_elements(By.TAG_NAME, "img")
17img_urls = [img.get_attribute("src") for img in img_elements if img.get_attribute("src")]
18os.makedirs("dynamic_images", exist_ok=True)
19for i, img_url in enumerate(img_urls):
20 # (Downloadlogica zoals eerder)
21 pass
22driver.quit()Extra tips:
- Gebruik
WebDriverWaitom te wachten tot plaatjes zichtbaar zijn. - Moet je ergens op klikken om afbeeldingen te tonen? Gebruik
element.click().
Alternatieven: Tools als Playwright (met Python-ondersteuning) zijn soms sneller en stabieler voor complexe sites ().
No-code alternatief: Afbeeldingen scrapen met Thunderbit
Niet iedereen heeft zin om te stoeien met code of browserdrivers. Daar komt om de hoek kijken—een no-code, AI-webscraper Chrome-extensie waarmee je net zo makkelijk plaatjes verzamelt als een maaltijd bestelt.
Zo werkt afbeeldingen extraheren met Thunderbit
- Installeer Thunderbit: Haal de .
- Open de gewenste site: Ga naar de pagina met de plaatjes die je wilt verzamelen.
- Start Thunderbit: Klik op het extensie-icoon om de zijbalk te openen.
- AI Suggest Fields: Klik op “AI Suggest Fields”—de AI van Thunderbit scant de pagina en herkent automatisch afbeeldingen, en maakt een “Afbeelding”-kolom voor je aan ().
- Scrapen: Klik op “Scrape.” Thunderbit verzamelt alle plaatjes, ook van subpagina’s of oneindig scrollen.
- Exporteren: Download afbeeldings-URL’s of bestanden direct naar Excel, Google Sheets, Notion, Airtable of CSV—zonder extra kosten, zelfs met het gratis abonnement.
Extra: De gratis Afbeelding-extractor van Thunderbit haalt met één klik alle afbeeldings-URL’s van een pagina op ().
Waarom Thunderbit zo handig is:
- Geen programmeerkennis of HTML nodig.
- Werkt automatisch met dynamische content, subpagina’s en paginering.
- Exporteren is direct en onbeperkt (ook met het gratis plan).
- AI past zich aan bij site-wijzigingen—geen onderhoud nodig.
Python en Thunderbit combineren: het beste van beide werelden
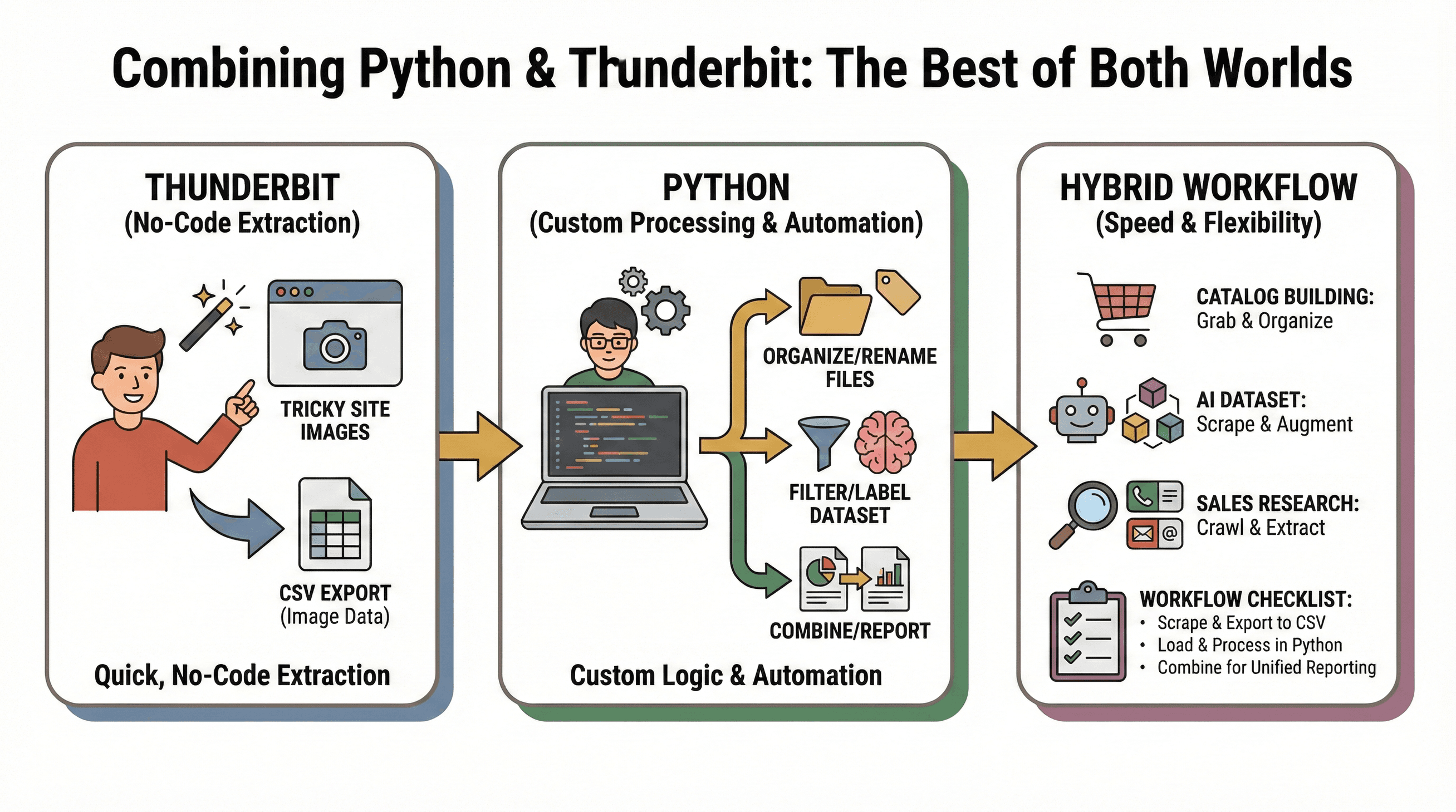 Mijn favoriete aanpak: gebruik Thunderbit voor snelle, no-code extractie en Python voor maatwerk of automatisering.
Mijn favoriete aanpak: gebruik Thunderbit voor snelle, no-code extractie en Python voor maatwerk of automatisering.
Voorbeelden:
- Catalogus bouwen: Gebruik Thunderbit om plaatjes van een lastige site te halen, en Python om ze te organiseren of te hernoemen.
- AI-dataset maken: Thunderbit verzamelt plaatjes uit verschillende bronnen; Python filtert, labelt of verrijkt de dataset.
- Salesonderzoek: Python crawlt een lijst met bedrijfswebsites; Thunderbit haalt per site plaatjes, e-mails of telefoonnummers op.
Stappenplan:
- Gebruik Thunderbit om afbeeldingen te scrapen en exporteer naar CSV.
- Laad de CSV in Python voor verdere analyse of automatisering.
- Combineer data uit meerdere bronnen voor een compleet overzicht.
Deze hybride aanpak geeft je snelheid, flexibiliteit en de mogelijkheid om praktisch elke webscraping-uitdaging aan te pakken.
Problemen oplossen & best practices voor Python image scraping
Veelvoorkomende issues:
- Geblokkeerde verzoeken: Stel een User-Agent in, voeg pauzes toe en respecteer
robots.txt. - Ontbrekende afbeeldingen: Check op JS-content—gebruik Selenium of Thunderbit.
- Dubbele downloads: Houd bezochte URL’s of hashes bij.
- Beschadigde bestanden: Gebruik Pillow om plaatjes na het downloaden te controleren.
Best practices:
- Organiseer afbeeldingen in duidelijke mappen (per site, categorie of datum).
- Gebruik beschrijvende bestandsnamen (product-ID’s, paginatitels).
- Filter irrelevante plaatjes (zoals advertenties of iconen) op bestandsgrootte of afmetingen.
- Check altijd de copyrightregels en gebruiksvoorwaarden voordat je afbeeldingen scrape ().
Python image scraper: code vs. no-code vergeleken
Hier een overzicht van de opties:
| Criteria | Python (Requests/BS) | Selenium (Python) | Thunderbit (No-Code) |
|---|---|---|---|
| Gebruiksgemak | Gemiddeld (coderen vereist) | Moeilijker (code + browser) | Zeer eenvoudig (point-and-click, AI) |
| Dynamische content | Nee | Ja | Ja |
| Installatietijd | Lang (installeren, coderen) | Lang (drivers, code) | Zeer kort (extensie installeren) |
| Schaalbaarheid | Handmatig (kan parallel) | Traag (browser overhead) | Hoog (cloud scraping, 50 pagina’s tegelijk) |
| Onderhoud | Hoog (scripts breken bij sitewijzigingen) | Hoog | Laag (AI past zich automatisch aan) |
| Exporteeropties | Maatwerk (CSV, DB) | Maatwerk | Eén klik naar Excel, Sheets, Notion, etc. |
| Kosten | Gratis (open source) | Gratis | Gratis tier, betaald bij veel gebruik |
Kortom: Ben je een coder en wil je volledige controle? Dan is Python ideaal. Wil je snelheid, gemak en ondersteuning voor dynamische sites? Dan is Thunderbit een uitkomst. De meeste teams halen het meeste uit een combinatie van beide.
Samenvatting & belangrijkste inzichten
De enorme groei van online beeldmateriaal maakt plaatjes waardevoller—maar ook lastiger te verzamelen. Met een Python image scraper kun je downloads automatiseren en maatwerk leveren, terwijl no-code tools als Thunderbit beeldscraping voor iedereen toegankelijk maken.
Belangrijkste punten:
- Gebruik Python (Requests + BeautifulSoup) voor statische sites en maatwerk.
- Gebruik Selenium voor dynamische, JavaScript-rijke pagina’s.
- Gebruik Thunderbit voor snelle, no-code extractie—vooral bij lastige sites of als je direct wilt exporteren naar Excel, Google Sheets of Notion.
- Combineer beide voor de ultieme workflow: Thunderbit voor het verzamelen, Python voor verwerking en automatisering.
Klaar om je image scraping skills te upgraden? Schrijf een simpel Python-script of en ontdek hoeveel tijd je bespaart. Meer tips en verdiepende artikelen vind je op de en in de .
Veel succes met scrapen—en moge je afbeeldingsmappen altijd overzichtelijk blijven!
Veelgestelde vragen
1. Wat is een Python image scraper?
Een Python image scraper is een script of tool die automatisch websites bezoekt, plaatjes (meestal in <img>-tags) vindt en deze op je computer opslaat. Zo hoef je niet meer handmatig elke afbeelding te bewaren.
2. Welke Python-bibliotheken zijn het beste voor het scrapen van afbeeldingen?
De populairste libraries zijn Requests (voor het ophalen van webpagina’s), BeautifulSoup (voor HTML-parsing), Selenium (voor dynamische content) en Pillow (voor beeldbewerking na het downloaden).
3. Hoe scrape ik afbeeldingen van JavaScript-rijke of oneindig scrollende sites?
Gebruik Selenium om een browser te automatiseren, de pagina te scrollen en afbeeldings-URL’s te verzamelen nadat alles geladen is. Thunderbit kan dit soort dynamische content ook automatisch aan met AI.
4. Kan ik zonder code afbeeldingen van websites scrapen?
Zeker! Thunderbit is een no-code Chrome-extensie die met AI plaatjes detecteert en verzamelt van elke website. Gewoon aanwijzen, klikken en exporteren naar Excel, Google Sheets, Notion of Airtable.
5. Kan ik Python en Thunderbit combineren voor het scrapen van afbeeldingen?
Absoluut. Gebruik Thunderbit voor snelle, no-code extractie en Python voor geavanceerde verwerking of automatisering. Exporteer data uit Thunderbit en verwerk deze verder met Python-scripts voor maximale flexibiliteit.
Meer weten?