

Laten we eerlijk zijn: niemand wordt ’s ochtends wakker met het idee: “Yes, vandaag ga ik 500 rijen productprijzen kopiëren en plakken in een spreadsheet.” (Als jij dat wél doet, petje af voor je uithoudingsvermogen — en misschien is een goede polsbrace geen overbodige luxe.) Of je nu in sales werkt, operations doet, of gewoon probeert je bedrijf een stap voor te houden op de concurrentie: je hebt waarschijnlijk al eens geworsteld met data van websites. De wereld draait inmiddels op webdata, en de vraag naar geautomatiseerde extractie schiet omhoog — de markt voor webscrapingsoftware gaat naar verwachting in 2032 de $11 miljard overstijgen.
Ik werk al jaren in de SaaS- en automationwereld en heb het allemaal voorbij zien komen: van heroïsche Excel-macro’s tot Python-scripts die met ducttape om 2 uur ’s nachts in elkaar zijn gezet. In deze gids laat ik je zien hoe je met een Python HTML-parser echte data kunt scrapen (ja, we gaan samen IMDb-filmratings ophalen), en ook waarom er in 2026 een betere manier is: AI-aangedreven tools zoals Thunderbit waarmee je de code overslaat en meteen bij de inzichten uitkomt.
Wat is een HTML-parser en waarom zou je die in Python gebruiken?
Laten we bij het begin beginnen: wat doet een HTML-parser eigenlijk? Zie het als je persoonlijke bibliothecaris voor het web. Hij leest de rommelige HTML-code achter een webpagina en zet die om in een nette, boomachtige structuur. Daardoor kun je precies de data eruit halen die je nodig hebt — titels, prijzen, links — zonder verdwaald te raken in een zee van punthaken en divs.
Python is dé taal voor dit soort werk, en daar zijn goede redenen voor. De taal is leesbaar, beginnervriendelijk en heeft een enorm ecosysteem aan libraries voor webscraping en parsing. Sterker nog: Python is veruit de populairste taal voor webscraping, dankzij de lage leercurve en sterke community.
De belangrijkste Python HTML-parsers op een rij
Dit zijn de hoofdrolspelers die je tegenkomt bij het parsen van HTML in Python:
- BeautifulSoup: de klassieke, beginnervriendelijke keuze. Nog steeds actief onderhouden —
beautifulsoup44.14.3 verscheen eind 2025 op PyPI — dus de uitleg hier verwijst niet naar een verouderde library. - lxml: snel en krachtig, met geavanceerde querymogelijkheden.
- html5lib: heel tolerant voor rommelige HTML, net als je browser.
- PyQuery: laat je jQuery-achtige selectors gebruiken in Python.
- HTMLParser: Python’s ingebouwde parser — altijd beschikbaar, maar wat basaal.
Elke optie heeft zijn eigenaardigheden, maar ze helpen je allemaal om ruwe HTML om te zetten in gestructureerde data.
Belangrijkste use cases: hoe bedrijven profiteren van Python HTML-parsers
Webdata-extractie is niet alleen iets voor techneuten of data scientists. Het is een kernactiviteit geworden, vooral in sales en operations. Dit is waarom:
| Use case (branche) | Typische gescrapede data | Bedrijfsresultaat |
|---|---|---|
| Prijsmonitoring (retail) | Prijzen van concurrenten, voorraadniveaus | Dynamische prijsstelling, betere marges (bron) |
| Productinformatie van concurrenten | Aanbiedingen, reviews, beschikbaarheid | Kansen identificeren, leads genereren (bron) |
| Leadgeneratie (B2B sales) | Bedrijfsnamen, e-mails, contactpersonen | Geautomatiseerde prospecting, groei van de pipeline (bron) |
| Marktsentiment (marketing) | Social posts, reviews, ratings | Real-time feedback, trends signaleren (bron) |
| Vastgoedaggregatie | Aanbiedingen, prijzen, informatie over makelaars | Marktanalyse, prijsstrategie (bron) |
| Recruitment intelligence | Kandidatenprofielen, salarissen | Talent sourcing, salarismarketing (bron) |
Kort gezegd: als je data nog handmatig kopieert, laat je tijd en geld liggen.
Maak kennis met de Python HTML-parser-toolkit: populaire libraries vergeleken
Laten we praktisch worden. Hier is een snelle vergelijking van de populairste Python HTML-parser libraries, zodat je de juiste tool voor je klus kunt kiezen:
| Library | Gebruiksgemak | Snelheid | Flexibiliteit | Onderhoudsbehoefte | Beste voor |
|---|---|---|---|---|---|
| BeautifulSoup | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | Gemiddeld | Beginners, rommelige HTML |
| lxml | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Gemiddeld | Snelheid, XPath, grote documenten |
| html5lib | ⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | Laag | Browser-achtige parsing, kapotte HTML |
| PyQuery | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | Gemiddeld | Fans van jQuery, CSS-selectors |
| HTMLParser | ⭐⭐⭐ | ⭐⭐⭐ | ⭐ | Laag | Simpele, ingebouwde taken |
BeautifulSoup: de beginnervriendelijke keuze
BeautifulSoup is de “hello world” van HTML-parsing. De syntax is intuïtief, de documentatie is sterk en de library is vergevingsgezind bij lelijke, foutieve HTML (lees meer). Het nadeel? Het is niet de snelste optie, vooral niet op grote of complexe pagina’s, en ondersteunt geavanceerde selectors zoals XPath niet standaard.
lxml: snel en krachtig
Als je snelheid nodig hebt of XPath-queries wilt gebruiken, is lxml je vriend (details). Het is gebouwd op C-libraries en daardoor razendsnel, maar de installatie kan wat lastiger zijn en de leercurve is steiler.
Andere opties: html5lib, PyQuery en HTMLParser
- html5lib: parseert HTML net als je browser — ideaal voor kapotte of vreemde markup, maar langzaam (vergelijking).
- PyQuery: laat je jQuery-stijl selectors gebruiken in Python, handig als je uit de front-endwereld komt (zie docs).
- HTMLParser: Python’s ingebouwde optie — snel en altijd beschikbaar, maar minder uitgebreid.
Stap 1: je Python HTML-parseromgeving instellen
Voordat je iets kunt parsen, moet je je Python-omgeving klaarzetten. Zo doe je dat:
-
Installeer Python: download het via python.org als je het nog niet hebt.
-
Installeer pip: meestal meegeleverd met Python 3.4+, maar je kunt het controleren met
pip --versionin je terminal. -
Installeer de libraries (we gebruiken voor deze tutorial BeautifulSoup en requests):
pip install beautifulsoup4 requests lxmlbeautifulsoup4is de parser.requestslaat je webpagina’s ophalen.lxmlis een snelle parser die BeautifulSoup onder de motorkap kan gebruiken.
-
Controleer je installatie:
python -c "import bs4, requests, lxml; print('Alles in orde!')"
Tips voor probleemoplossing:
- Krijg je permissiefouten? Probeer
pip install --user ... - Op Mac/Linux heb je mogelijk
python3enpip3nodig. - Zie je “ModuleNotFoundError”? Controleer dan je spelling en je Python-omgeving.
Stap 2: je eerste webpagina parseren met Python
Laten we de handen uit de mouwen steken en IMDb’s Top 250-films scrapen. We halen de filmtitels, jaren en ratings op.
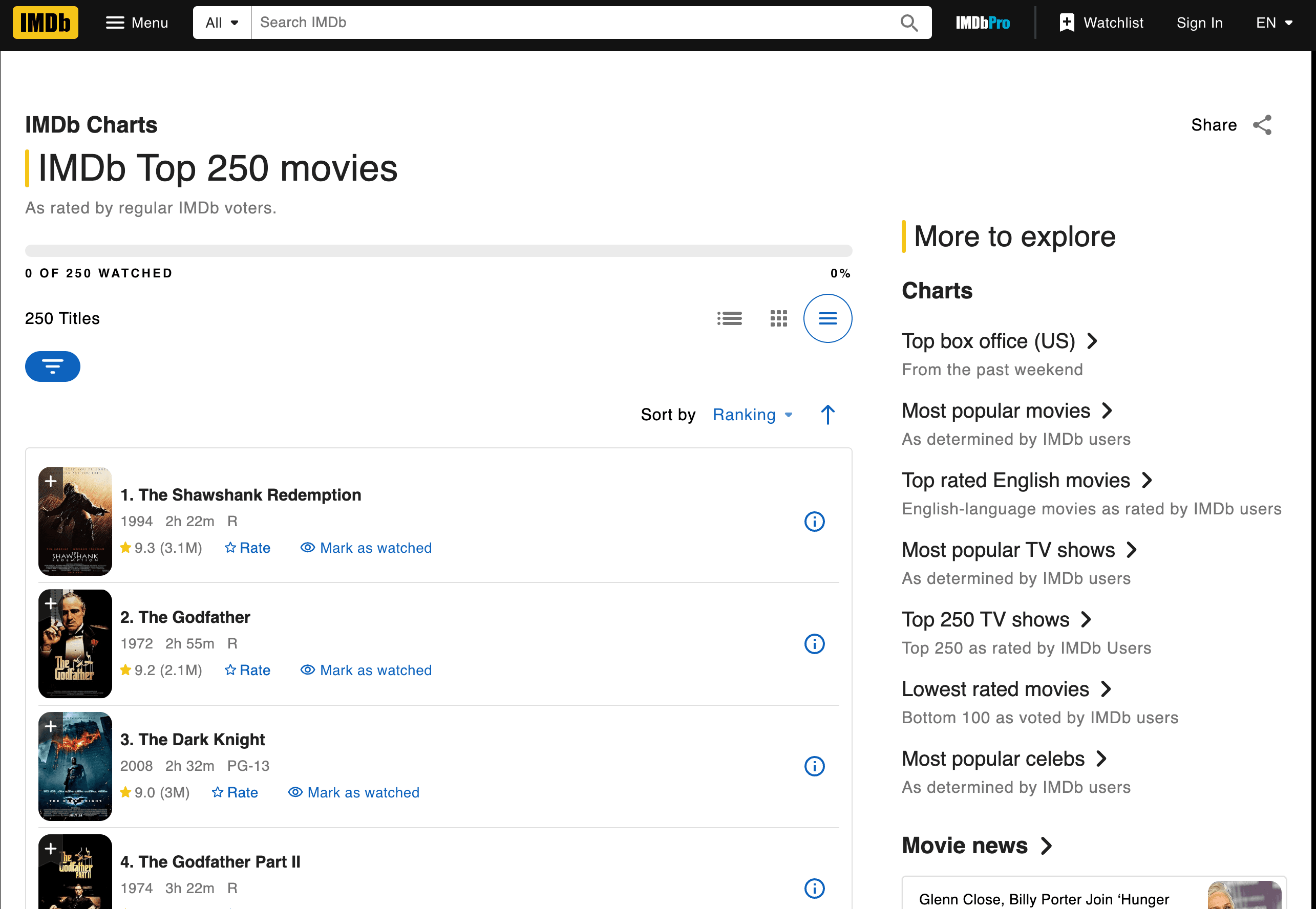
De pagina ophalen en parsen
Hier is een script stap voor stap. Kleine waarschuwing voordat je het kopieert: IMDb heeft de Top 250-pagina in juni 2023 opnieuw ontworpen, dus de oude td.titleColumn- en td.ratingColumn-selectors die je nog in oudere tutorials ziet, matchen inmiddels niets meer. De huidige markup gebruikt ipc--klassen die door hun componentensysteem worden gegenereerd, en IMDb heeft de pagina sindsdien nog een paar keer aangepast (ook midden 2025), dus inspecteer de pagina telkens opnieuw met DevTools als je terugkomt naar dit voorbeeld.
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/top/"
headers = {"User-Agent": "Mozilla/5.0"} # IMDb geeft zonder echte UA vaak een uitgeklede markup terug
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
# Elke rij is een list item onder de chart-container
rows = soup.select("li.ipc-metadata-list-summary-item")
for i, row in enumerate(rows[:3], start=1):
title_el = row.select_one("h3.ipc-title__text")
year_el = row.select_one("span.cli-title-metadata-item")
rating_el = row.select_one("span.ipc-rating-star--rating")
title = title_el.get_text(strip=True) if title_el else None
# h3-tekst komt terug als "1. The Shawshank Redemption" — verwijder het rangnummer
if title and ". " in title:
title = title.split(". ", 1)[1]
year = year_el.get_text(strip=True) if year_el else None
rating = rating_el.get_text(strip=True) if rating_el else None
print(f"{i}. {title} ({year}) -- Rating: {rating}")
Wat gebeurt hier?
- We gebruiken
requests.get()om de pagina op te halen (met een realistischeUser-Agent— IMDb serveert soms een uitgeklede versie aan kalepython-requests-clients). BeautifulSoupparseert de HTML.- We halen elke filmrij op via
li.ipc-metadata-list-summary-itemen lezen vervolgens titel (h3.ipc-title__text), jaar (span.cli-title-metadata-item) en rating (span.ipc-rating-star--rating) eruit metselect_one(). - We halen de tekst op voor titel, jaar en rating, en verwijderen het leidende rangnummer (
"1. ") dat IMDb in de titeltekst verwerkt.
Als je iets duurzamers wilt dan elke paar maanden achter veranderende class-namen aanjagen, dan levert IMDb op dezelfde pagina ook een <script type="application/ld+json">-blok met dezelfde data in gestructureerde vorm — je kunt het parsen met json.loads(soup.find("script", type="application/ld+json").string) en de itemListElement-array doorlopen. Dat is de aanpak die ik in productie zou kiezen; de CSS-selector-versie hierboven is makkelijker uit te leggen maar ook fragieler.
Output:
1. The Shawshank Redemption (1994) -- Rating: 9.3
2. The Godfather (1972) -- Rating: 9.2
3. The Dark Knight (2008) -- Rating: 9.0
Data extraheren: titels, ratings en meer vinden
Hoe wist ik welke tags en classes ik moest gebruiken? Ik heb de HTML van IMDb geïnspecteerd (rechtsklik > Inspecteren in je browser). Zoek naar patronen — hier staat elke filmrij in een <li class="ipc-metadata-list-summary-item">, met de titel onder <h3 class="ipc-title__text"> en de rating onder <span class="ipc-rating-star--rating">. Eén belangrijk voorbehoud: IMDb heeft deze markup meer dan eens aangepast (de td.titleColumn-layout die je in oudere walkthroughs nog ziet werkt sinds hun redesign in juni 2023 niet meer), dus beschouw de exacte class-strings altijd als illustratief en inspecteer de pagina opnieuw voordat je het script draait.
Pro tip: als je een andere site scraped, begin dan altijd met het inspecteren van de HTML-structuur en het identificeren van unieke class-namen of tags.
Je resultaten opslaan en exporteren
Laten we onze data opslaan in een CSV-bestand:
import csv
movies = []
for i in range(len(title_cells)):
title_cell = title_cells[i]
rating_cell = rating_cells[i]
title = title_cell.a.text
year = title_cell.span.text.strip("()")
rating = rating_cell.strong.text if rating_cell.strong else rating_cell.text
movies.append([title, year, rating])
with open('imdb_top250.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Titel', 'Jaar', 'Rating'])
writer.writerows(movies)
Opschoontips:
- Gebruik
.strip()om witruimte te verwijderen. - Vang ontbrekende data af met
if-checks. - Voor export naar Excel kun je de CSV in Excel openen of
pandasgebruiken om.xlsx-bestanden te schrijven.
Stap 3: omgaan met HTML-wijzigingen en onderhoudsuitdagingen
Hier wordt het serieus. Websites veranderen graag hun layout — soms lijkt het wel alsof ze dat doen om scrapers dwars te zitten. Als IMDb class="titleColumn" wijzigt naar class="movieTitle", geeft je script ineens lege resultaten terug. Been there, gedebugd.
Wanneer scripts breken: problemen uit de praktijk
Veelvoorkomende issues:
- Selectors niet gevonden: je code kan de opgegeven tag/class niet vinden.
- Lege resultaten: de paginastuctuur is gewijzigd, of content laadt nu via JavaScript.
- HTTP-fouten: de site heeft anti-botmaatregelen toegevoegd.
Stappen voor troubleshooting:
- Controleer of de HTML die je parseert overeenkomt met wat je in je browser ziet.
- Werk je selectors bij zodat ze passen bij de nieuwe structuur.
- Als content dynamisch wordt geladen, moet je misschien overschakelen naar een browser-automationtool (zoals Selenium) of een API-endpoint zoeken.
De echte hoofdpijn? Als je 10, 50 of 500 verschillende sites scraped, ben je soms meer tijd kwijt aan het repareren van scripts dan aan het analyseren van de data (zie dev-verhalen).
Stap 4: opschalen — de verborgen kosten van handmatige Python HTML-parsing
Stel dat je niet alleen IMDb wilt scrapen, maar ook Amazon, Zillow, LinkedIn en nog een dozijn andere sites. Voor elke site heb je een eigen script nodig. En elke keer dat een site verandert, zit je weer terug in de code-editor.
De verborgen kosten:
- Onderhoudswerk: sommigen schatten dat onderhoud 10x zo duur is als de initiële bouw.
- Infrastructuur: je hebt proxies, foutafhandeling en monitoring nodig.
- Prestaties: opschalen betekent omgaan met concurrency, rate limits en meer.
- Kwaliteitscontrole: meer scripts = meer plekken waar iets kan breken.
Voor niet-technische teams wordt dit al snel onhoudbaar. Het is alsof je een team stagiairs inhuurt om de hele dag data te kopiëren en plakken — alleen zijn die stagiairs Python-scripts, en melden ze zich ziek zodra een website verandert.
Een korte noot over AI-coding agents
Voordat we naar no-code tools gaan, is het de moeite waard om een middenweg te noemen die vroeger eigenlijk nauwelijks bestond toen de meeste “leer BeautifulSoup”-tutorials werden geschreven: AI-coding agents. Tools zoals Claude Code of Cursor nemen gerust een Engelstalige beschrijving (“haal IMDb’s Top 250 op, zet titel / jaar / rating in een CSV”) en maken in één keer een werkend requests + BeautifulSoup-script voor je, inclusief het soort selector-opruiming dat we hierboven handmatig deden. Voor browserflows in natuurlijke taal — inloggen, pagineren, cookie-banners afhandelen — kan een library zoals Browser Use een headless browser rechtstreeks vanuit een prompt aansturen.
Maar ze nemen de moeilijke delen niet weg. Rate limits, robots.txt, inlogschermen en anti-botverdediging blijven jouw probleem, en als een selector stilletjes breekt (zoals bij IMDb) moet je nog steeds herkennen wat de agent heeft gegenereerd en het repareren. Dus zelfs met een agent in de loop is begrip van de HTML-parser-workflow uit deze tutorial precies wat je nodig hebt om de output te debuggen in plaats van naar lege lijsten te staren.
Verder dan Python HTML-parsers: maak kennis met Thunderbit, het AI-aangedreven alternatief
Nu wordt het interessant. Wat als je de code kunt overslaan, het onderhoud kunt overslaan, en gewoon de data krijgt die je nodig hebt — ongeacht hoe de website verandert?
Precies dat hebben we gebouwd met Thunderbit. Het is een AI-webscraper Chrome-extensie waarmee je gestructureerde data van elke website in twee klikken kunt extraheren. Geen Python, geen scripts, geen hoofdpijn.
Python HTML-parsers versus Thunderbit: naast elkaar vergeleken
| Aspect | Python HTML-parsers | Thunderbit (bekijk prijzen) |
|---|---|---|
| Insteltijd | Hoog (installeren, coderen, debuggen) | Laag (extensie installeren, klikken) |
| Gebruiksgemak | Vereist coderen | Geen code — aanwijzen en klikken |
| Onderhoud | Hoog (scripts breken vaak) | Laag (AI past zich automatisch aan) |
| Schaalbaarheid | Complex (scripts, proxies, infrastructuur) | Ingebouwd (cloud scraping, batchjobs) |
| Data-enrichment | Handmatig (meer code schrijven) | Ingebouwd (labelen, opschonen, vertalen, subpagina’s) |
Waarom bouwen als je het probleem met AI kunt oplossen?
Waarom AI kiezen voor webdata-extractie?
Thunderbit’s AI-agent leest de pagina, doorziet de structuur en past zich aan wanneer dingen veranderen. Het is alsof je een superstagiair hebt die nooit slaapt en nooit moppert over veranderende class-namen.
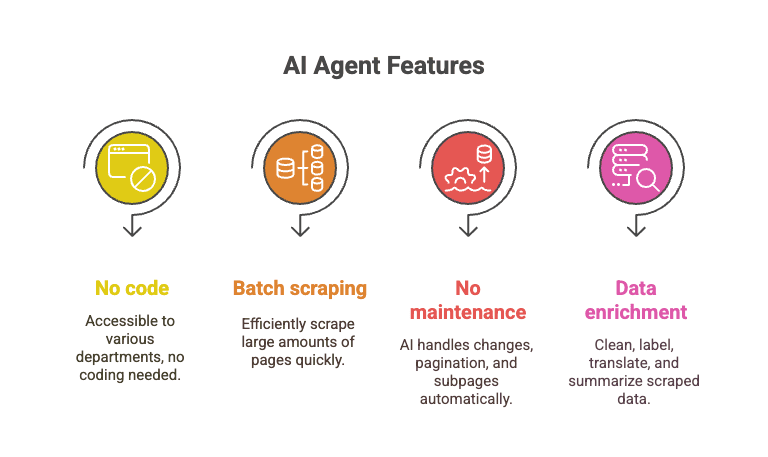
- Geen code nodig: iedereen kan het gebruiken — sales, ops, marketing, noem maar op.
- Batchscraping: scrape 10.000+ pagina’s in de tijd die je anders kwijt bent aan het debuggen van één Python-script.
- Geen onderhoud: de AI handelt layoutwijzigingen, paginering, subpagina’s en meer af.
- Data-enrichment: schoon, label, vertaal en vat data samen terwijl je scraped.
De keerzijde van de BeautifulSoup-workflow die we net hebben doorlopen, is precies de kwetsbaarheid die we hierboven bij de IMDb-selectors zagen — zodra de pagina verschuift, geeft het script stilletjes lege resultaten terug, en breng je de middag door in DevTools in plaats van naar data te kijken. Een no-code AI-scraper verbergt die stap achter zijn eigen inferentielaag; dat is een echte afweging (je vertrouwt erop dat de extractie van een ander klopt), geen wondermiddel.
Stap voor stap: IMDb-filmratings scrapen met Thunderbit
Laten we zien hoe Thunderbit dezelfde IMDb-taak afhandelt:
- Installeer de Thunderbit Chrome-extensie.
- Ga naar IMDb’s Top 250-pagina.
- Klik op het Thunderbit-icoon.
- Klik op “AI Suggest Fields.” Thunderbit leest de pagina en stelt kolommen voor (Titel, Jaar, Rating).
- Controleer of pas de kolommen aan indien nodig.
- Klik op “Scrape.” Thunderbit haalt alle 250 rijen direct op.
- Exporteer naar Excel, Google Sheets, Notion of CSV — jij kiest.
Dat is alles. Geen code, geen debugging, geen momenten van “waarom is deze lijst leeg?”
Wil je het in actie zien? Bekijk dan het Thunderbit YouTube-kanaal voor walkthroughs, of lees onze stap-voor-stapgids voor het scrapen van Amazon-producten voor nog een praktijkvoorbeeld.
Conclusie: de juiste tool kiezen voor je webdata-behoeften
Python HTML-parsers zoals BeautifulSoup en lxml zijn krachtig, flexibel en gratis. Ze zijn ideaal voor ontwikkelaars die volledige controle willen en het niet erg vinden om zelf de handen uit de mouwen te steken. Maar ze brengen een steile leercurve, doorlopend onderhoud en verborgen kosten met zich mee — vooral als je scrapingbehoefte groeit.
Voor zakelijke gebruikers, salesteams en iedereen die gewoon de data wil hebben (en niet de code), zijn AI-aangedreven tools zoals Thunderbit een verademing. Ze laten je webdata op schaal extraheren, opschonen en verrijken, zonder code en zonder onderhoud.
Mijn advies? Gebruik Python als je van scripten houdt en totale aanpasbaarheid nodig hebt. Maar als je je tijd én je gemoedsrust waardeert, probeer Thunderbit dan eens. Waarom scripts bouwen en babysitten als je AI het zware werk kunt laten doen?
Wil je meer leren over webscraping, data-extractie en AI-automatisering? Duik dan in meer tutorials op de Thunderbit Blog, zoals Hoe je websitegegevens naar Excel scrape met AI of De beste webscrapingtools en software in 2025.




