

Webscraping is van een nichevaardigheid uitgegroeid tot een onmisbare superkracht voor iedereen die werkt in sales, operations of marktonderzoek. Met de enorme explosie aan webdata — de wereldwijde datacreatie groeide van 2019 tot 2023 met bijna 193% — is het geen wonder dat 81% van de bedrijven data inmiddels ziet als het ‘hart’ van hun besluitvorming. Maar hier zit de adder onder het gras: 95% van de organisaties zegt dat het verwerken van ongestructureerde data (zoals rommelige HTML) een grote uitdaging is. Ik heb genoeg teams gezien die verzuipen in eindeloze copy-paste-marathons, terwijl ze website-informatie proberen om te zetten naar spreadsheets — geloof me, dat ziet er niet fraai uit.
Haal met AI data van elke website Get Started Free
Daar komt Python’s BeautifulSoup om de hoek kijken. In deze praktische tutorial laat ik je stap voor stap zien hoe je BeautifulSoup inzet voor webscraping, met een concreet Python Beautiful Soup-voorbeeld dat je kunt aanpassen aan je eigen zakelijke behoeften. En omdat ik altijd slimmer wil werken in plaats van harder, laat ik je ook zien hoe je BeautifulSoup combineert met Thunderbit, onze AI-aangedreven webscraper, om je workflow te versnellen en schonere, beter gestructureerde data te krijgen — ongeacht je programmeerniveau.
Wat is BeautifulSoup en waarom gebruik je het voor webscraping?
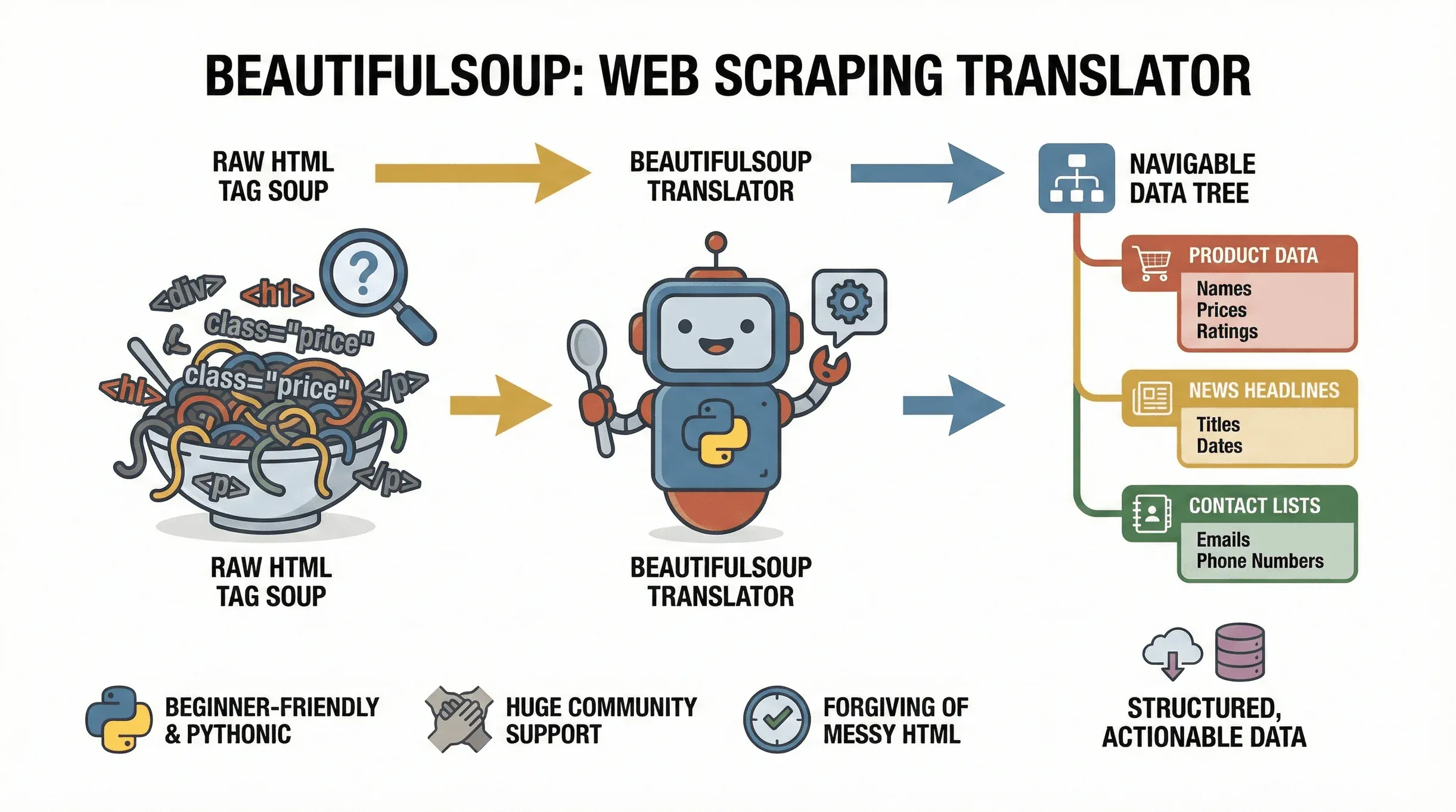 Laten we bij de basis beginnen. BeautifulSoup is een Python-library waarmee je HTML- en XML-documenten eenvoudig kunt parsen. Zie het als een vertaler: het neemt de ‘tagsoep’ van een webpagina en zet die om in een doorzoekbare boomstructuur, zodat je de data die je nodig hebt makkelijk kunt vinden, extraheren en aanpassen. Het project wordt nog steeds actief onderhouden —
Laten we bij de basis beginnen. BeautifulSoup is een Python-library waarmee je HTML- en XML-documenten eenvoudig kunt parsen. Zie het als een vertaler: het neemt de ‘tagsoep’ van een webpagina en zet die om in een doorzoekbare boomstructuur, zodat je de data die je nodig hebt makkelijk kunt vinden, extraheren en aanpassen. Het project wordt nog steeds actief onderhouden — beautifulsoup4 4.14.3 verscheen eind 2025 op PyPI — dus alles wat je hier leert is actueel. Of je nu productprijzen van een e-commercesite haalt, nieuwsheadlines verzamelt of bedrijvengidsen afspeurt op leads, BeautifulSoup is hét hulpmiddel om webpagina’s om te zetten in gestructureerde, bruikbare data.
Waarom is het zo populair? Om te beginnen is het enorm vriendelijk voor beginners. BeautifulSoup kan prima omgaan met rommelige HTML (en laten we eerlijk zijn: het web zit er vol mee), en dankzij de Python-achtige syntax kun je in slechts een paar regels code al beginnen met scrapen. Het wordt bovendien breed ondersteund, met miljoenen downloads en een enorme community — dus als je vastloopt, is hulp nooit ver weg via een snelle Google-zoekopdracht.
Typische toepassingen van BeautifulSoup zijn onder andere:
- Productnamen, prijzen en beoordelingen extraheren van e-commercepagina’s
- Nieuwsheadlines, auteurs en publicatiedatums ophalen van nieuwssites
- Tabellen of gidsen parsen (zoals lijsten met bedrijven of contactpersonen)
- E-mailadressen of telefoonnummers verzamelen van listing-sites
- Updates monitoren (prijswijzigingen, nieuwe vacatures, enzovoort)
Als je data in statische HTML staat, is BeautifulSoup je beste vriend voor webscraping.
De unieke voordelen van BeautifulSoup voor webscraping
Er zijn genoeg Python-bibliotheken voor webscraping — waarom zou je dan voor BeautifulSoup kiezen? Zo verhoudt het zich tot de concurrentie:
- Simpel: BeautifulSoup is lichtgewicht en gemakkelijk te leren. Je hoeft geen compleet framework op te zetten of een hoop boilerplate-code te schrijven. Het is perfect voor snelle, eenmalige scrapingklussen of voor beginners die net beginnen.
- Vergevingsgezind: Het kan kapotte of onjuist opgemaakte HTML verwerken, en dat komt vaker voor dan je denkt.
- Flexibel: Je zit niet vast aan een starre crawling-architectuur. Geef het simpelweg HTML en haal eruit wat je nodig hebt.
- Integratie: BeautifulSoup werkt goed samen met andere Python-bibliotheken zoals
requests(om webpagina’s op te halen),csv(om data op te slaan) enpandas(voor data-analyse).
Hoe verhoudt het zich tot andere tools?
| Tool | Beste voor | Voordelen | Nadelen |
|---|---|---|---|
| BeautifulSoup | Statische HTML-parsing, beginners | Simpel, snel op te zetten, vergevingsgezind, flexibel | Niet voor sites met veel JavaScript |
| Scrapy | Grootschalige, asynchrone taken | Krachtig, schaalbaar, ingebouwde crawling | Steilere leercurve, meer setup |
| Selenium | JavaScript/dynamische content | Kan met JS werken, formulieren invullen, knoppen klikken | Langzamer, zwaarder, meer resource-intensief |
Als je net begint of snel statische pagina’s wilt parsen, is BeautifulSoup het ‘Zwitserse zakmes’ van webscraping (medium.com). Voor complexere of dynamische sites kun je het combineren met Selenium of Scrapy — maar BeautifulSoup is de beste manier om de basis onder de knie te krijgen.
Je Python-omgeving instellen voor BeautifulSoup
Klaar om te starten? Zo stel je je omgeving in:
-
Installeer Python: Download de nieuwste versie via python.org.
-
Stel een virtuele omgeving in (optioneel, maar aanbevolen):
python -m venv venv source venv/bin/activate # Op Windows: venv\Scripts\activate -
Installeer BeautifulSoup en afhankelijkheden:
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4: De hoofd-libraryrequests: Voor het ophalen van webpagina’slxmlofhtml5lib: Snellere/betrouwbaardere HTML-parsers
-
Tips bij problemen:
- Krijg je de fout ‘pip not found’, probeer dan
pip3ofpy -m pip. - Op Mac/Linux heb je mogelijk
sudonodig voor rechten. - Gebruik je Windows, zorg dan dat Python aan je PATH is toegevoegd.
- Krijg je de fout ‘pip not found’, probeer dan
Om je installatie te controleren, kun je deze snelle test uitvoeren:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Als je <title>Example Domain</title> ziet, ben je klaar om aan de slag te gaan (Thunderbit Blog).
Een stapsgewijs Python Beautiful Soup-voorbeeld
Laten we duiken in een realistisch Python Beautiful Soup-voorbeeld. Stel dat je de nieuwste nieuwsheadlines van een openbare nieuwssite wilt extraheren. Zo pak je dat aan:
1. Haal de webpagina op
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. Parse de HTML
soup = BeautifulSoup(html, "html.parser")
3. Bekijk de HTML-structuur
Open de Developer Tools van je browser (rechtsklik → Inspecteren) en kijk welke tags de headlines bevatten. Op veel nieuwssites staan headlines in <h3>-tags met specifieke classes.
Je kunt bijvoorbeeld dit zien:
<h3 class="gs-c-promo-heading__title">Headline Title</h3>
4. Extraheer de data
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
Dit print alle nieuwsheadlines op de pagina.
5. Sla de data op in CSV
Laten we die headlines bewaren voor latere analyse:
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["headline"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
Nu heb je een CSV-bestand dat klaar is voor Excel of Google Sheets.
HTML-structuur begrijpen voor effectieve data-extractie
Voordat je code schrijft, moet je altijd de HTML van de pagina inspecteren. Zo doe je dat:
- Open Developer Tools: Klik met de rechtermuisknop op de pagina en kies ‘Inspecteren’.
- Vind de data: Beweeg over elementen om te zien welke tags de informatie bevatten die je zoekt (bijv. headlines, prijzen, auteurs).
- Let op tags en classes: Zoek naar unieke identificaties zoals
class="product-title"ofid="main-content". - Test je selectors: Gebruik de methoden
.find(),.find_all()of.select()van BeautifulSoup om die elementen te targeten.
Pro-tip: gebruik soup.prettify() om een leesbare versie van de HTML in je Python-console af te drukken.
Data extraheren en structureren met BeautifulSoup
Stel dat je zowel titels als auteurs van een blogpagina wilt extraheren:
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
Nu heb je een lijst met dictionaries — ideaal om te exporteren naar CSV of voor verdere analyse.
Je kunt links, afbeeldingen of elk ander attribuut zo extraheren:
for link in soup.find_all("a"):
print(link.get("href"))
Of afbeeldingen:
for img in soup.find_all("img"):
print(img.get("src"))
Geëxtraheerde data opslaan: van Python naar Excel of CSV
Zodra je data gestructureerd is, is exporteren eenvoudig. Zo doe je dat met de csv-module:
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Of, als je fan bent van pandas:
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
Gebruik altijd UTF-8-codering om vreemde tekens te voorkomen, vooral bij internationale data.
Case study: nieuwswebsite-data scrapen met BeautifulSoup
Laten we een praktisch Python Beautiful Soup-voorbeeld doornemen: het scrapen van titels, auteurs en publicatiedatums van een nieuwssite.
Stel dat je CNN wilt scrapen voor artikeldata:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Dit script haalt de nieuwste artikelen op, extraheert de titel, datum en auteur, en slaat ze op als CSV — ervan uitgaande dat de huidige markup van CNN nog steeds overeenkomt met de bovenstaande tags. Grote nieuwssites wijzigen class-namen en DOM-structuur vaak, dus inspecteer de pagina opnieuw voordat je dit op productiedata loslaat. De structuur (<article>-containers, daarna find op child-tags) is het duurzame patroon; de specifieke class-namen zoals "date" en "author" zijn placeholders die je moet aanpassen aan wat de livepagina vandaag levert.
Je workflow verbeteren: BeautifulSoup combineren met Thunderbit
Laten we het nu hebben over hoe je je scraping-workflow nog soepeler maakt. Thunderbit is een AI-aangedreven webscraper Chrome-extensie die het giswerk uit data-extractie haalt. Met Thunderbit kun je:
- ‘AI Suggest Fields’ gebruiken: Thunderbit leest de pagina en stelt automatisch voor welke datavelden je moet extraheren — geen gezoek meer in HTML of gedoe met selectors.
- Subpagina’s scrapen: Thunderbit kan links naar subpagina’s volgen (zoals individuele product- of artikelpagina’s) en je dataset verrijken met extra details.
- Direct exporteren: Stuur je data met één klik rechtstreeks naar Excel, Google Sheets, Airtable of Notion.
- Paginering verwerken: Thunderbit kan data over meerdere pagina’s heen scrapen (inclusief infinite scroll).
- Scrapes plannen: Stel terugkerende taken in om je data actueel te houden.
Dit is een hybride workflow die ik geweldig vind:
- Begin met Thunderbit: Open je doelwebsite, klik op het Thunderbit-icoon en laat ‘AI Suggest Fields’ de juiste kolommen identificeren (zoals titel, auteur, datum).
- Exporteer de data: Download de resultaten als CSV of stuur ze naar Google Sheets.
- Gebruik BeautifulSoup voor maatwerkverwerking: Als je dieper wilt analyseren (zoals tekst opschonen, dedupliceren of combineren met andere bronnen), laad je de geëxporteerde CSV in Python en gebruik je BeautifulSoup of pandas voor nabewerking.
Deze combinatie geeft je het beste van twee werelden: de snelheid en AI-gedreven veldherkenning van Thunderbit, plus de flexibiliteit van BeautifulSoup voor maatwerklogica.
Probeer Thunderbit AI-webscraper gratis
Snelheid en datakwaliteit: waarom Thunderbit en BeautifulSoup samen gebruiken?
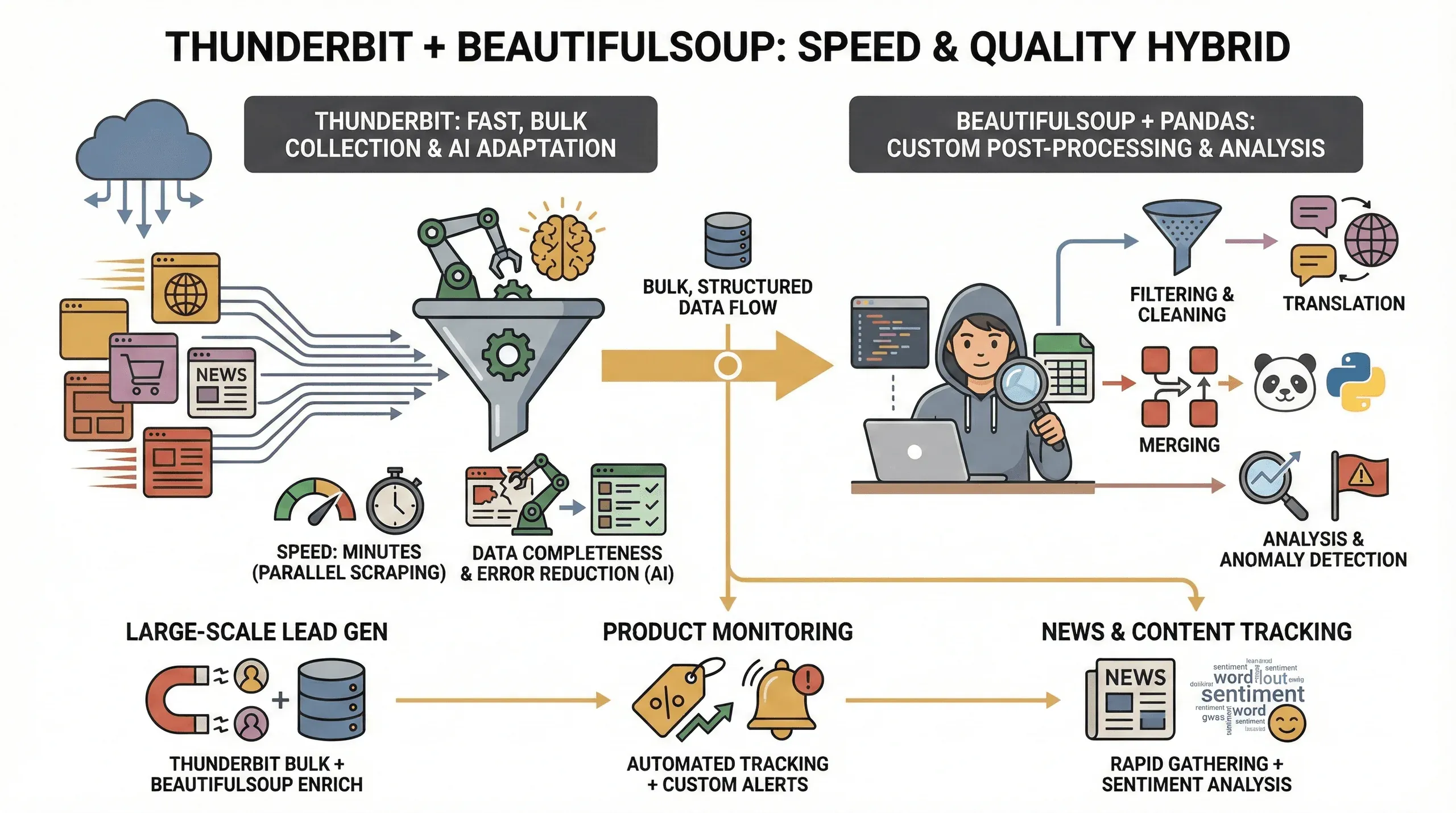 Waarom zou je beide tools gebruiken? Dit heb ik gemerkt:
Waarom zou je beide tools gebruiken? Dit heb ik gemerkt:
- Snelheid: Thunderbit kan tientallen pagina’s tegelijk scrapen (tot 50 tegelijk in cloudmodus), dus je hebt je data binnen minuten in plaats van uren.
- Volledigheid van data: Thunderbit’s AI past zich aan aan lay-outwijzigingen en kan zelfs op lastige sites gestructureerde data extraheren, waardoor de kans kleiner wordt dat velden ontbreken.
- Minder fouten: Geen kapotte scripts meer wanneer een class-naam verandert — Thunderbit’s AI beoordeelt de pagina elke keer opnieuw.
- Maatwerk nabewerking: Voor geavanceerde behoeften (zoals filteren, vertalen of datasets samenvoegen) geven BeautifulSoup en pandas je volledige controle.
Deze hybride aanpak is vooral waardevol voor:
- Leadgeneratie op grote schaal: Gebruik Thunderbit om de bulkdata te verzamelen en BeautifulSoup om die op te schonen en te verrijken.
- Productmonitoring: Thunderbit doet het repetitieve scrape-werk, terwijl BeautifulSoup je helpt trends te analyseren of afwijkingen te signaleren.
- Nieuws- en contenttracking: Verzamel snel artikelen met Thunderbit en gebruik daarna Python voor sentimentanalyse of keyword-extractie.
Veelvoorkomende problemen oplossen bij BeautifulSoup-webscraping
Probeer de Thunderbit Chrome-extensie Scrape elke website met AI in 2 klikken. Get Started Free
Webscraping verloopt niet altijd vlekkeloos — hier zijn een paar veelvoorkomende valkuilen en hoe je ze oplost:
- Dynamische content: Als een site data laadt met JavaScript (infinite scroll, AJAX), dan ziet BeautifulSoup die niet alleen. Gebruik in zulke gevallen Selenium of de browsermodus van Thunderbit.
- Anti-botmaatregelen: Sommige sites blokkeren geautomatiseerde verzoeken. Probeer een aangepaste User-Agent-header, voeg vertragingen tussen verzoeken toe of gebruik Thunderbit’s cloud scraping om eenvoudige blokkades te omzeilen.
- Wijzigingen in HTML-structuur: Als je script plots breekt, is de HTML van de site waarschijnlijk veranderd. Inspecteer de pagina opnieuw en werk je selectors bij. Thunderbit’s AI kan hierbij helpen door zich automatisch aan te passen.
- Ontbrekende data: Controleer altijd of elementen bestaan voordat je
.get_text()aanroept. Gebruik.get()in plaats van[]voor attributen om KeyErrors te vermijden. - Coderingproblemen: Sla bestanden op met UTF-8-codering om speciale tekens goed te verwerken.
En respecteer altijd robots.txt en de gebruiksvoorwaarden van de site. Scrape verantwoord — niemand houdt van een onbeleefde robot.
Conclusie en belangrijkste punten
Webscraping met BeautifulSoup is een van de meest praktische vaardigheden die je kunt leren in de huidige datagedreven wereld. Dit hebben we behandeld in deze BeautifulSoup-webscrapingtutorial:
- BeautifulSoup is het ideale startpunt voor het parsen van statische HTML en het extraheren van gestructureerde data met Python.
- Instellen is eenvoudig — installeer gewoon Python, pip en een paar libraries.
- HTML inspecteren is essentieel om de juiste data te targeten.
- Exporteren naar CSV/Excel maakt je data direct bruikbaar voor zakelijke analyses.
- Combineren met Thunderbit geeft je AI-gedreven veldherkenning, sneller scrapen en eenvoudiger exporteren — perfect voor zakelijke gebruikers en niet-programmeurs.
- Hybride workflows (Thunderbit voor bulk-extractie, BeautifulSoup voor maatwerkverwerking) leveren de beste snelheid, datakwaliteit en flexibiliteit op.
Ben je klaar om je webscraping naar een hoger niveau te tillen? Probeer dan beide tools uit: experimenteer met een eenvoudig BeautifulSoup-script en ontdek vervolgens hoe veel sneller je kunt werken met Thunderbit’s AI-webscraper. En voor meer praktische handleidingen kun je de Thunderbit Blog bekijken.
Veel scrapeplezier — en moge je data altijd schoon, gestructureerd en klaar voor actie zijn.
Probeer Thunderbit AI Web Scraper Get Started Free
Veelgestelde vragen
1. Wat is BeautifulSoup en waarvoor wordt het gebruikt?
BeautifulSoup is een Python-library voor het parsen van HTML- en XML-documenten. Het helpt je data van webpagina’s te extraheren en om te zetten naar gestructureerde formaten zoals lijsten of tabellen, waardoor het ideaal is voor webscraping-projecten.
2. Hoe verhoudt BeautifulSoup zich tot Selenium en Scrapy?
BeautifulSoup is lichtgewicht en eenvoudig te gebruiken voor statische HTML-pagina’s. Selenium is beter voor dynamische sites met veel JavaScript, terwijl Scrapy een volwaardig framework is voor grootschalige, asynchrone scraping. Voor beginners en snelle taken is BeautifulSoup de beste keuze.
3. Kan ik BeautifulSoup en Thunderbit samen gebruiken?
Absoluut. Thunderbit kan snel velden op webpagina’s identificeren en extraheren met AI, en je kunt BeautifulSoup gebruiken voor maatwerk-nabewerking of diepere analyse van de geëxporteerde data.
4. Wat zijn veelvoorkomende uitdagingen bij webscraping met BeautifulSoup?
Veelvoorkomende problemen zijn het omgaan met dynamische content, anti-botmaatregelen en veranderingen in de HTML-structuur. De AI-functies of browsermodus van Thunderbit kunnen helpen veel van deze uitdagingen te overwinnen.
5. Hoe exporteer ik data die ik met BeautifulSoup heb gescrapet naar Excel of CSV?
Je kunt de ingebouwde csv-module van Python of de pandas-library gebruiken om je geëxtraheerde data naar CSV- of Excel-bestanden te schrijven. Gebruik altijd UTF-8-codering om speciale tekens goed te verwerken en compatibiliteit met spreadsheettools te garanderen.
Klaar om het zelf te proberen? Download de Chrome-extensie van Thunderbit en begin vandaag nog slimmer te scrapen. Voor meer tutorials en tips kun je de Thunderbit Blog bezoeken.
Meer weten




