Als je ooit online data hebt geprobeerd te kopen voor je bedrijf, ken je waarschijnlijk dat gevoel: je bent op jacht naar de perfecte dataset, maar het lijkt een beetje op het kopen van avocado’s—soms vind je een pareltje, soms krijg je een zompige rommel, en soms vraag je je af of je wel in het juiste gangpad staat. In de huidige datagedreven wereld vormen openbare datasets de motor achter alles, van slimmere marketing tot scherpere concurrentieanalyses. Maar nu steeds meer bedrijven de belofte van datagedreven groei najagen, zit de echte uitdaging niet alleen in het vinden van openbare data—maar vooral in ervoor zorgen dat wat je koopt ook echt bruikbaar, betrouwbaar en direct inzetbaar is in je workflow.
Ik heb veel tijd doorgebracht met teams die openbare data willen inzetten voor groei, en ik heb uit eerste hand gezien hoe snel je kunt struikelen over verborgen kosten, schimmige leveranciers of data die op papier geweldig lijkt maar in de praktijk tegenvalt. In deze gids neem ik je mee door de praktische stappen (en een paar hard bevochten lessen) voor het vinden, beoordelen en benutten van openbare datasets—zodat je al die ruwe informatie kunt omzetten in echte bedrijfsresultaten.
De waarde van het kopen van openbare datasets voor bedrijfsgroei
Laten we beginnen met de “waarom”. Waarom willen zoveel bedrijven online data kopen, en wat maakt betaalde openbare data anders dan gratis data?
Het korte antwoord: openbare datasets zijn inmiddels een kernmotor van bedrijfsstrategie en ROI. Volgens recent onderzoek beschouwt , en maakt ongeveer een kwart van de organisaties bijna alle strategische beslissingen datagedreven. De opbrengst is concreet— op dan strategieën die geen data gebruiken.
Openbare datasets kunnen groei op allerlei manieren aanjagen:
- Leadgeneratie: Verrijk je CRM met nieuwe contacten of bedrijfsprofielen.
- Marktonderzoek: Volg concurrentieprijzen, productlanceringen of klantgevoelens.
- Operationele efficiëntie: Automatiseer handmatig onderzoek, bewaak trends of benchmark salarissen.
Maar hier zit de crux: gratis openbare data (denk aan overheidsportalen of open datasets) is vaak “as is”—onvolledig, rommelig of verouderd. Het is een beetje alsof je een gratis puppy krijgt: schattig, maar je bent veel tijd kwijt aan de rommel. Betaalde datasets daarentegen zijn samengesteld met oog op betrouwbaarheid, volledigheid en gebruiksgemak. Leveranciers investeren in het opschonen, updaten en structureren van de data, zodat jij dat niet hoeft te doen. Voor veel bedrijven is betalen voor kwalitatieve data veel kostenefficiënter dan gratis data zelf bij elkaar puzzelen—zeker als het alternatief is dat je uren (en loonkosten) verliest aan opschonen en samenvoegen.
Belangrijke uitdagingen bij het online kopen van data
Was data kopen maar net zo makkelijk als eten bestellen. In werkelijkheid zijn er een paar obstakels waar zelfs de slimste teams tegenaan lopen:
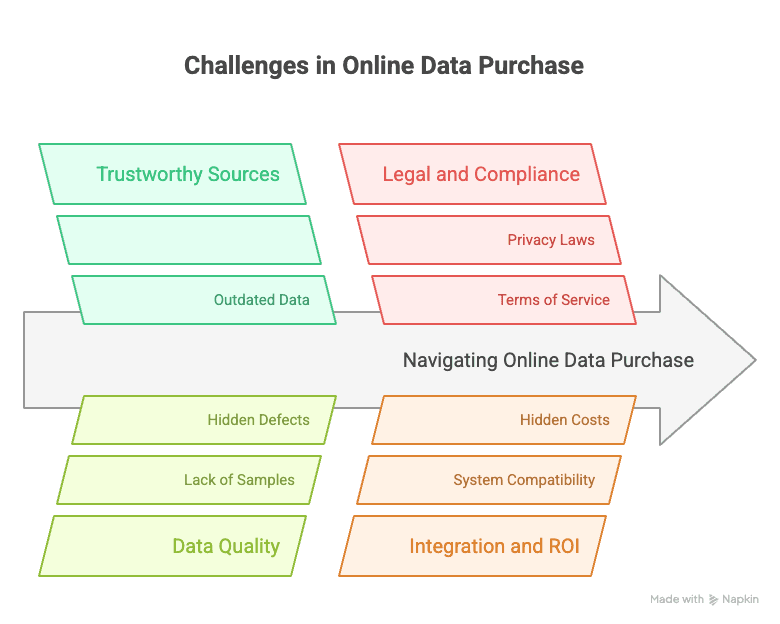
- Betrouwbare bronnen vinden: Het internet staat vol datamarktplaatsen en leveranciers, maar ze zijn lang niet allemaal even goed. Sommigen verkopen verouderde of slecht verkregen data, en anderen zijn ronduit dubieus. .
- Datakwaliteit verifiëren: Veel datasets zien er in de beschrijving geweldig uit, maar de echte inhoud zie je vaak pas nadat je hebt betaald. Sommige marktplaatsen bieden geen voorbeeld, waardoor je het risico loopt een kat in de zak te kopen.
- Juridische en compliance-risico’s: Alleen omdat data “openbaar” is, betekent dat nog niet dat je het overal voor mag gebruiken. Privacywetten zoals de AVG of CCPA, of de gebruiksvoorwaarden van een website, kunnen beperken wat je mag doen. Niet alle leveranciers garanderen compliance ().
- Integratieproblemen: Zelfs als de data goed is, past die misschien niet in je systemen of workflows. Je moet de data mogelijk omzetten, opschonen of samenvoegen—wat tijd en geld kost.
- Onzeker ROI: De prijs op het etiket is nog maar het begin. Er zijn verborgen kosten voor integratie, opschoning en doorlopend onderhoud. En de waarde van de data wordt niet altijd duidelijk voordat je ermee aan de slag gaat.
Uit mijn ervaring is de kernuitdaging niet alleen data vinden—het is ervoor zorgen dat je die data ook echt kunt gebruiken om bedrijfsresultaten te behalen. Daarom raad ik altijd een checklist voor databeoordeling aan: actualiteit, dekking, volledigheid, compliance en integratie.
Waar vind je betrouwbare openbare datasets?
Waar ga je dan precies heen om online data te kopen? Dit zijn de belangrijkste opties, elk met hun eigen kenmerken:
Datamarktplaatsen
Zie deze als de Amazon voor datasets. Platformen zoals , AWS Data Exchange en Oracle Data Marketplace laten je duizenden datasets van verschillende aanbieders doorzoeken. Je vindt er alles van consumentendemografie tot B2B-firmographics en geospatiale data.
Voordelen: Enorme variatie, makkelijk te vergelijken, soms directe integratie met je cloudtools.
Nadelen: De kwaliteit varieert, niet alle data is gecontroleerd en je moet nog steeds zelf zorgen voor integratie en opschoning. Let dus goed op de kleine lettertjes.
Overheids- en open dataportalen
Sites zoals of het bieden gratis, gezaghebbende data over alles van economie tot gezondheidszorg. Ideaal voor marktonderzoek of benchmarking.
Voordelen: Gratis, vaak betrouwbaar en geen gedoe met licenties.
Nadelen: De data kan verouderd, slecht gestructureerd of niet afgestemd op zakelijke behoeften zijn. Je zult waarschijnlijk veel moeten opschonen.
Gespecialiseerde dataleveranciers
Bedrijven zoals ZoomInfo, Dun & Bradstreet, Experian of S&P Global Market Intelligence verdienen hun geld met het verkopen van samengestelde datasets—denk aan B2B-contacten, kredietdata of financiële gegevens.
Voordelen: Hoge kwaliteit, diepe dekking en vaak inclusief support of analysetools.
Nadelen: Duur, en je kunt vastzitten aan een abonnement. Zorg dat je niet betaalt voor meer dan je nodig hebt.
Webscrapingdiensten of zelf scrapen
Als je de data die je nodig hebt niet kunt vinden, kun je die altijd zelf verzamelen—met traditionele webscrapingtools of door een dienst in te huren. Hier wordt het interessant (en soms wat ingewikkeld).
Voordelen: Volledige maatwerkcontrole, je krijgt precies wat je wilt.
Nadelen: Technische obstakels, juridische risico’s en onderhoudsproblemen. Daarover straks meer.
Pro tip: Vraag altijd om een sample of preview voordat je koopt. Als een leverancier die niet wil geven, is dat een waarschuwingssignaal.
Openbare datasets beoordelen vóór aankoop
Hier komt het op de praktijk aan. Voordat je ook maar een euro uitgeeft, loop je deze checklist door:
| Beoordelingscriterium | Waarop letten |
|---|---|
| Actualiteit | Hoe recent is de data bijgewerkt? Wordt ze regelmatig vernieuwd? |
| Dekking & volledigheid | Dekt de data de volledige scope die je nodig hebt? Zijn belangrijke velden (zoals e-mail, prijs, locatie) meestal ingevuld? |
| Nauwkeurigheid & geloofwaardigheid | Licht de leverancier zijn bronnen toe? Kun je een paar records controleren? |
| Formaat & integratievermogen | Is de data in een formaat dat je team kan gebruiken (CSV, JSON, API)? Zijn kolommen duidelijk gelabeld en zijn datatypes consistent? |
| Juridische compliance | Zijn er gebruiksbeperkingen? Is de data AVG-/CCPA-conform? |
| Support van leverancier & SLA | Wat gebeurt er als er een fout is? Is er een supportcontact of restitutiebeleid? |
Test indien mogelijk een sample in je eigen workflow. Laad het in je CRM of analysetool en kijk of het soepel werkt. Ik heb bedrijven enorme datasets zien kopen, om er vervolgens achter te komen dat 90% van de records troep is of cruciale velden mist. Een beetje zorgvuldigheid vooraf bespaart later veel ellende.
Traditionele dataverzamelingsmethoden: waarom ze tekortschieten
Laten we het nu hebben over de olifant in de kamer: traditionele webscraping. Ik heb zóveel teams hun eigen scrapers zien bouwen, om uiteindelijk vast te lopen in een eindeloos spelletje whack-a-mole.
Waarom hebben de oude methoden het moeilijk?
- Moderne websites zijn complex: Dynamische content, JavaScript, oneindig scrollen en geneste reacties maken het lastig voor simpele scrapers om bij te blijven ().
- Sites veranderen voortdurend: Een kleine aanpassing in de HTML kan je scraper al breken. Onderhoud wordt dan een voltijdbaan.
- Anti-scrapingmaatregelen: CAPTCHA’s, IP-blokkades en inlogvereisten kunnen je volledig blokkeren.
- Handmatige setup: Je moet elk selectorelement vinden, paginering scripten en subpagina’s afhandelen. Het is tijdrovend en foutgevoelig.
- Onvolledige data: Verborgen of geneste content (zoals reviews of afbeeldingen) wordt vaak gemist.
Het resultaat? Zelfs als het werkt, is het fragiel en onderhoudsintensief. Voor de meeste zakelijke gebruikers is die moeite simpelweg niet de moeite waard.
Thunderbit: een slimmere manier om openbare data te kopen en te verzamelen
Hier word ik enthousiast van—want bij hebben we een andere aanpak gekozen. In plaats van te vertrouwen op kwetsbare code en CSS-selectors, gebruikt Thunderbit AI om webpagina’s semantisch te ‘lezen’.
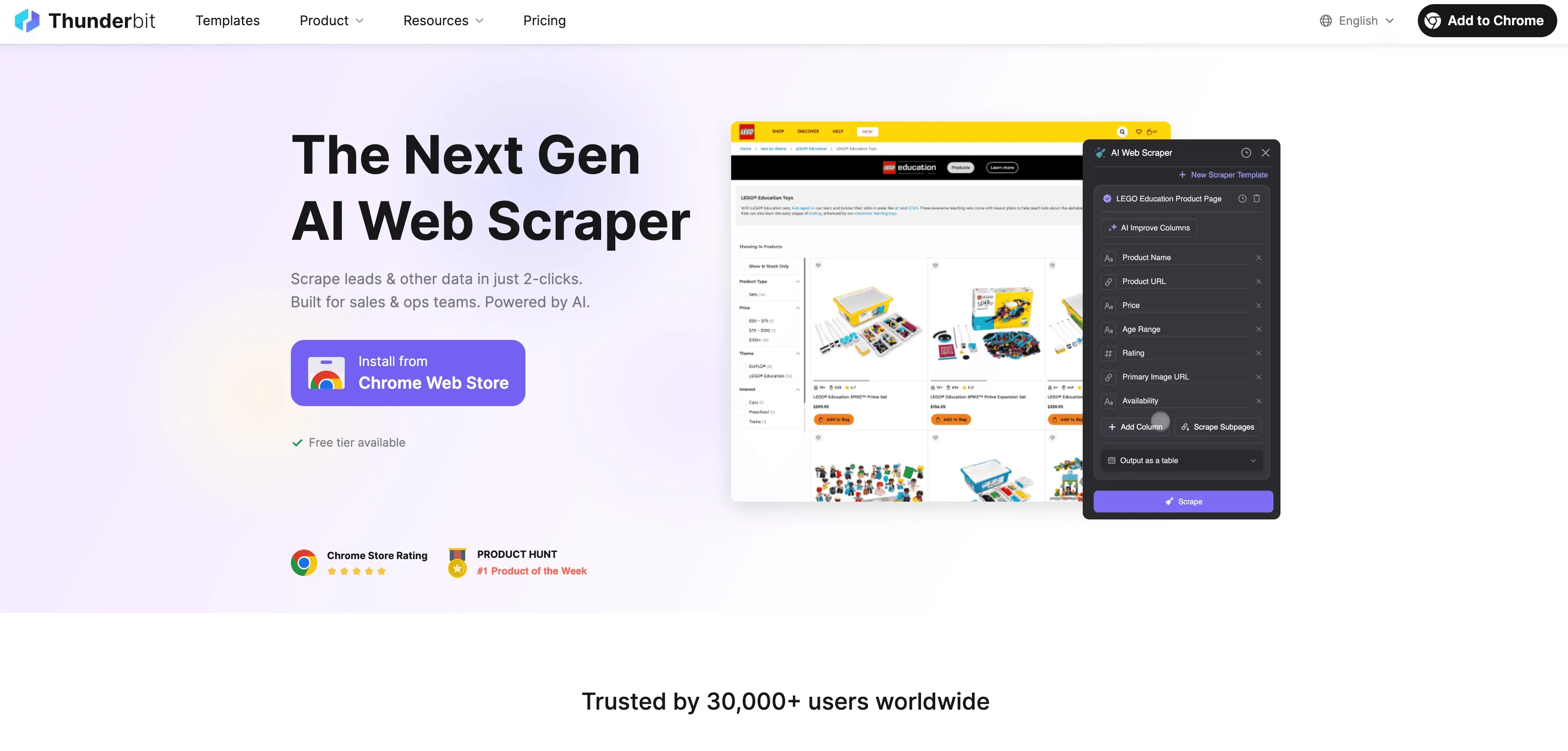
Zo werkt het:
- Semantisch begrip: Thunderbit zet de webpagina om naar een Markdown-achtige structuur, waarbij de opbouw en betekenis behouden blijven (koppen, lijsten, tabellen, enz.). De AI analyseert daarna die structuur en herkent wat belangrijk is—net zoals een mens dat zou doen ().
- Bestendig tegen lay-outwijzigingen: Als een site zijn ontwerp aanpast, kan Thunderbit’s AI nog steeds de juiste data vinden, zolang de betekenis hetzelfde blijft.
- Omgaan met dynamische content: Oneindig scrollen, knoppen “Meer laden” en JavaScript-elementen? Thunderbit detecteert en bedient ze automatisch.
- Scrapen van subpagina’s: Thunderbit kan links naar detailpagina’s volgen en je dataset verrijken met extra velden—zonder extra scriptwerk.
- Geen code nodig: Zakelijke gebruikers klikken gewoon op “AI Suggest Fields”, bekijken de voorgestelde kolommen en klikken op “Scrape”. Zo simpel is het.
Het resultaat? Je krijgt gestructureerde, betrouwbare data—zelfs van complexe of voortdurend veranderende sites—zonder de gebruikelijke hoofdpijn.
Je openbare dataverzamelingsproces standaardiseren met Thunderbit
Een van de grootste pijnpunten die ik zie, is inconsistentie. Elke nieuwe databron betekent het wiel opnieuw uitvinden—nieuwe velden, nieuwe formaten, nieuwe opschoningsstappen. Thunderbit helpt je het hele proces te standaardiseren en automatiseren:
- AI Suggest Fields: Thunderbit scant de pagina en stelt de juiste kolommen en datatypes voor, zodat je niet hoeft te gokken wat je moet extraheren ().
- Subpage Scraping: Meer details nodig? Thunderbit bezoekt automatisch elke gelinkte subpagina en haalt extra info binnen—denk aan bedrijfsprofielen, productspecificaties of contactgegevens.
- Paginering en oneindig scrollen: Thunderbit herkent en verwerkt deze patronen, zodat je altijd de volledige dataset krijgt.
- Ingebouwde data-opruiming: Voeg aangepaste prompts toe om data te normaliseren, categoriseren of formatteren terwijl je scrape’t.
- Eenvoudig exporteren: Stuur je data met één klik rechtstreeks naar Excel, Google Sheets, Airtable of Notion. Geen eindeloos kopiëren en plakken meer ().
- Gepland scrapen: Automatiseer terugkerende datataken—dagelijks, wekelijks, wat je ook nodig hebt.
Deze combinatie betekent dat je data op schaal kunt verzamelen, verrijken en standaardiseren, zonder een team van engineers of een PhD in webscraping nodig te hebben.
De ROI van het kopen van openbare datasets berekenen
Laten we het over geld hebben. Hoe weet je of online data kopen de investering waard is?
De werkelijke kosten
- Aanschaf: De prijs van de dataset of het abonnement.
- Integratie: Tijd en arbeid om de data op te schonen, te formatteren en te laden.
- Onderhoud: Doorlopende updates, abonnementen of kosten voor scrapingtools.
Onthoud dat . Koop je een rommelige dataset, dan betaal je daar in uren (en frustratie) voor.
De opbrengst
- Omzetgroei: Meer leads, betere targeting, slimmere prijsstelling.
- Kostenbesparing: Handmatig onderzoek automatiseren, minder arbeidsuren.
- Betere beslissingen: Fouten vermijden, sneller kansen signaleren.
- Snellere time-to-market: Producten of campagnes eerder lanceren.
Een eenvoudige ROI-formule:
(Totale opbrengst – Totale kosten) / Totale kosten x 100%
Als je bijvoorbeeld $10.000 uitgeeft aan data (inclusief alle kosten) en je helpt daarmee $50.000 aan nieuwe business te sluiten, dan is je ROI 400%. Niet slecht.
Pro tip: Doe eerst een pilot. Gebruik Thunderbit’s gratis export om een kleine sample te scrapen, test die in je workflow en kijk of het waarde oplevert voordat je een grote aankoop doet.
Stapsgewijze handleiding: openbare datasets kopen en gebruiken met Thunderbit
Klaar om dit in de praktijk te brengen? Hier is mijn praktische, in het veld geteste routekaart:
Stap 1: Bepaal je databehoefte
Begin met je bedrijfsdoel. Wil je leads genereren? Concurrenten volgen? Salarissen benchmarken? Wees specifiek over:
- De velden die je nodig hebt (bijv. bedrijfsnaam, e-mail, prijs, locatie)
- Het volume (hoeveel records?)
- De frequentie (eenmalig of doorlopend?)
- Het formaat (CSV, Excel, Google Sheets, enz.)
Schrijf het op. Hoe duidelijker je behoefte, hoe makkelijker het is om opties te beoordelen en onnodige kosten te vermijden.
Stap 2: Vind en beoordeel datasets
- Doorzoek datamarktplaatsen, leveranciercatalogi en open dataportalen.
- Stel een shortlist op: Kijk naar datasets die aan je criteria voldoen.
- Vraag samples of previews op: Als die niet beschikbaar zijn, gebruik Thunderbit om een kleine sample van openbare sites te scrapen.
- Doorloop de evaluatiechecklist: Actualiteit, dekking, volledigheid, nauwkeurigheid, formaat, compliance en support.
- Test in je workflow: Laad de sample in je CRM of analysetool. Past het? Zijn belangrijke velden ingevuld?
Als een dataset door de test komt, kun je verder. Zo niet, blijf zoeken—of overweeg de data zelf te scrapen met Thunderbit.
Stap 3: Gebruik Thunderbit om data te verzamelen en structureren
Zo gebruik ik (en jij kunt dat ook):
- Installeer de .
- Ga naar je doelwebsite (gids, lijsten, zoekresultaten).
- Klik op “AI Suggest Fields”. Thunderbit stelt kolommen en datatypes voor.
- Controleer en pas velden aan waar nodig. Voeg aangepaste prompts toe voor speciale opmaak of verrijking.
- Schakel Subpage Scraping in als je details van gelinkte pagina’s nodig hebt.
- Verwerk paginering of oneindig scrollen—Thunderbit detecteert dit meestal automatisch.
- Klik op “Scrape”. Kijk hoe Thunderbit je datatabel vult.
- Exporteer naar Excel, Google Sheets, Airtable of Notion—alles met één klik.
- Controleer je data. Als je aanpassingen nodig hebt, pas die dan toe en voer het opnieuw uit.
Thunderbit’s gratis versie laat je dit op een paar pagina’s uitproberen, zodat je de resultaten kunt zien voordat je opschaalt.
Stap 4: Test, integreer en schaal op
- Test datakwaliteit en ROI: Voer een kleine campagne of analyse uit met je nieuwe data. Zijn de leads geldig? Zijn de inzichten bruikbaar?
- Integreer met je bedrijfstools: Importeer in je CRM, BI-dashboard of marketingautomationplatform.
- Automatiseer op schaal: Gebruik Thunderbit’s geplande scraping om je data actueel te houden.
- Monitor en verfijn: Houd de datakwaliteit in de gaten en pas je proces aan waar nodig.
Conclusie en belangrijkste inzichten
Online openbare datasets kopen kan een krachtige hefboom zijn voor bedrijfsgroei—maar alleen als je het aanpakt met een helder plan en de juiste tools. Dit heb ik geleerd (soms op de harde manier):
- Begin met een duidelijk doel. Weet wat je nodig hebt en waarom.
- Controleer je bronnen. Gebruik een checklist om datasets te beoordelen vóór aankoop.
- Wees alert op verborgen kosten. Houd rekening met opschoning, integratie en onderhoud.
- Benut geavanceerde tools. Thunderbit’s AI-gedreven aanpak maakt dataverzameling sneller, betrouwbaarder en toegankelijker—zelfs voor niet-programmeurs.
- Standaardiseer en automatiseer. Bouw een herhaalbare workflow, zodat je niet elke keer opnieuw het wiel uitvindt.
- Meet de ROI. Test op kleine schaal en schaal op wat werkt.
Met de juiste aanpak kun je openbare data omzetten in een echt concurrentievoordeel—zonder de gebruikelijke hoofdpijn. Als je wilt zien hoe makkelijk het kan zijn, probeer dan eens uit (de gratis versie is een mooie manier om rustig kennis te maken).
Veel succes met het vinden van data—en moge je avocado’s altijd perfect rijp zijn.
Veelgestelde vragen
1. Wat is het verschil tussen gratis en betaalde openbare datasets?
Gratis datasets (zoals die van overheidsportalen) zijn vaak onvolledig, verouderd of slecht gestructureerd en vereisen veel opschoning. Betaalde datasets zijn samengesteld met focus op betrouwbaarheid, volledigheid en eenvoudige integratie, waardoor je tijd en moeite bespaart.
2. Hoe weet ik of een dataset van hoge kwaliteit is voordat ik koop?
Vraag altijd om een sample of preview. Gebruik een checklist: controleer actualiteit, volledigheid, nauwkeurigheid, formaat en compliance. Test de sample in je workflow om te zien of die aan je behoeften voldoet.
3. Wat zijn de juridische risico’s bij het online kopen van openbare data?
Niet alle “openbare” data is vrij van beperkingen. Zorg ervoor dat de leverancier voldoet aan privacywetten (zoals de AVG of CCPA) en dat je het recht hebt om de data te gebruiken voor je beoogde doel.
4. Hoe maakt Thunderbit dataverzameling makkelijker dan traditionele scrapers?
Thunderbit gebruikt AI om webpagina’s semantisch te begrijpen, verwerkt dynamische content en lay-outwijzigingen, automatiseert veldselectie en ondersteunt het scrapen van subpagina’s—alles via een no-code interface en directe export naar je favoriete tools.
5. Hoe bereken ik de ROI van het kopen van een openbare dataset?
Tel alle kosten op (aanschaf, integratie, onderhoud) en schat de opbrengsten in (omzetgroei, kostenbesparing, betere beslissingen). Doe een pilot met een kleine sample om de praktijkimpact te testen voordat je opschaalt. Gebruik de formule: (Totale opbrengst – Totale kosten) / Totale kosten x 100%.
Meer weten: