

Sommige mensen verzamelen postzegels. Anderen verzamelen sneakers. Maar als je in 2026 in sales, marketing, e-commerce of operations werkt, is de kans groot dat je iets verzamelt dat net wat… digitaler is: webdata. En niet een beetje ook—bedrijven geven inmiddels gemiddeld $5 miljoen per jaar uit aan het verzamelen van webdata, terwijl webscraping inmiddels een standaardtool is binnen afdelingen van strategie tot klantenservice (bron).
Door die explosieve groei in vraag duiken twee namen steeds weer op in elke Python-scrapingtutorial en elk project rond bedrijfsdata: Playwright en Selenium. Beide begonnen als browserautomatiseringstools voor testen, maar zijn inmiddels de standaardframeworks voor iedereen die het web wil omzetten in gestructureerde, bruikbare data. Maar hier zit de clou: kiezen tussen deze twee is niet alleen een technische beslissing—het gaat om het kiezen van de juiste tool voor jouw praktische scrapingbehoeften. En als je geen developer bent, of gewoon snel resultaat wilt, is er zelfs een nog eenvoudigere route (tip: daar komt geen enkele regel Python aan te pas). Laten we erin duiken.
Van testtools tot webscraping-krachtpatsers: Playwright en Selenium uitgelegd
Laten we de context schetsen. Selenium bestaat al sinds 2004 en is de betrouwbare klassieker onder de browserautomatiseringstools. Oorspronkelijk gebouwd voor QA-testers, waarmee je browsers als Chrome, Firefox en zelfs Internet Explorer kunt aansturen (voor wie graag met gevaar speelt). Playwright, daarentegen, maakte zijn entree in 2020, gesteund door Microsoft, met een moderne kijk op browserautomatisering—zie het als Seleniums jongere, snellere broer of zus.
Met beide tools kun je scripts schrijven (vaak in Python) die een browser openen, naar een website navigeren, op knoppen klikken, formulieren invullen en—het allerbelangrijkste voor ons—data extraheren. Hoewel hun oorsprong ligt in geautomatiseerd testen, vormen ze nu de ruggengraat van webscraping voor alles van prijsmonitoring tot leadgeneratie (bron). Hun populariteit is niet alleen onder developers groot: steeds meer zakelijke gebruikers steken zelf de handen uit de mouwen om hun eigen scrapers te bouwen, of proberen het in elk geval.
Maar hier wordt het interessant: wanneer je data aan het scrapen bent, verschuiven je prioriteiten. Je geeft minder om testdekking en meer om betrouwbaar data ophalen, blokkades vermijden en niet je hele weekend besteden aan het debuggen van Python-fouten. Dáár zitten de echte verschillen tussen Playwright en Selenium.
Belangrijkste verschillen: Playwright vs. Selenium voor webscraping

Laten we meteen ter zake komen: Playwright en Selenium kunnen allebei websites scrapen, maar ze blinken uit in verschillende scenario’s.
- Selenium is de veteraan. Het werkt met bijna elke browser en programmeertaal, heeft een enorme community en is een uitstekende keuze voor het scrapen van oudere, statische websites met voorspelbare lay-outs.
- Playwright is de nieuwkomer met moderne functies. Het is ontworpen voor de dynamische, JavaScript-zware sites van vandaag, met ingebouwde tools voor logins, pop-ups, oneindig scrollen en meer. Bovendien is het sneller en eenvoudiger op te zetten, vooral voor Python-gebruikers.
Maar neem mijn woord hier niet zomaar voor aan—laten we het functie voor functie uit elkaar halen.
Vergelijkingstabel van functies: Playwright vs. Selenium
| Functie | Selenium | Playwright |
|---|---|---|
| Taalondersteuning | Python, Java, C#, JS, Ruby en meer | Python, JS/TS, Java, C# |
| Browserondersteuning | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Complexiteit van installatie | Vereist browserdriver, handmatige configuratie | Installeert alles met één commando |
| Snelheid/prestaties | Langzamer, meer resource-intensief | Over het algemeen sneller op JS-zware pagina’s; async/concurrent van ontwerp uit |
| Omgaan met dynamische content | Handmatige waits, meer code nodig | Auto-waits, verwerkt JS-zware sites moeiteloos |
| Anti-bot omzeiling | Gevoelig voor detectie, add-ons nodig | Ingebouwde stealth, beter in het nabootsen van gebruikers |
| Debugtools | Basis (Selenium IDE, screenshots) | Inspector, video-opname, codegen |
| Communitysupport | Groot, volwassen, veel tutorials | Snel groeiend, moderne documentatie, actieve developers |
| Workflow voor Python-scraping | Meer installatie, meer boilerplate | Soepeler, minder code, eenvoudiger voor beginners |
De juiste tool kiezen: wanneer gebruik je Playwright of Selenium voor webscraping
Welke moet je nu kiezen voor je volgende scrapingproject? Dit is mijn kijk erop, na jaren bouwen aan automatiseringstools en teams helpen om data uit de wilde wereld van het web te halen.
- Selenium is je vriend als:
- De site die je wilt scrapen ouderwets is—denk aan statische HTML, minimale JavaScript en geen fancy pop-ups.
- Je ondersteuning nodig hebt voor vreemde browsers (hallo, Internet Explorer) of wilt integreren met legacy-systemen.
- Je het comfort wilt van een enorme community en eindeloze StackOverflow-antwoorden.
- Je Selenium al kent van testprojecten.
- Playwright is de juiste keuze als:
- De site modern, dynamisch en vol JavaScript zit (denk aan e-commerce, social media of alles waarvan je laptopventilator harder gaat draaien).
- Je moet inloggen, door tabbladen klikken, oneindig scrollen of omgaan met pop-ups.
- Je snel aan de slag wilt, met minder installatie en minder code.
- Je genoeg hebt van overal
time.sleep(5)schrijven en wilt dat de tool de timing voor je regelt.
Een simpele vuistregel: Als je eerste poging om een site met Selenium te scrapen eindigt in veel “waarom laadt dit niet?”-momenten, is het waarschijnlijk tijd om Playwright te proberen.
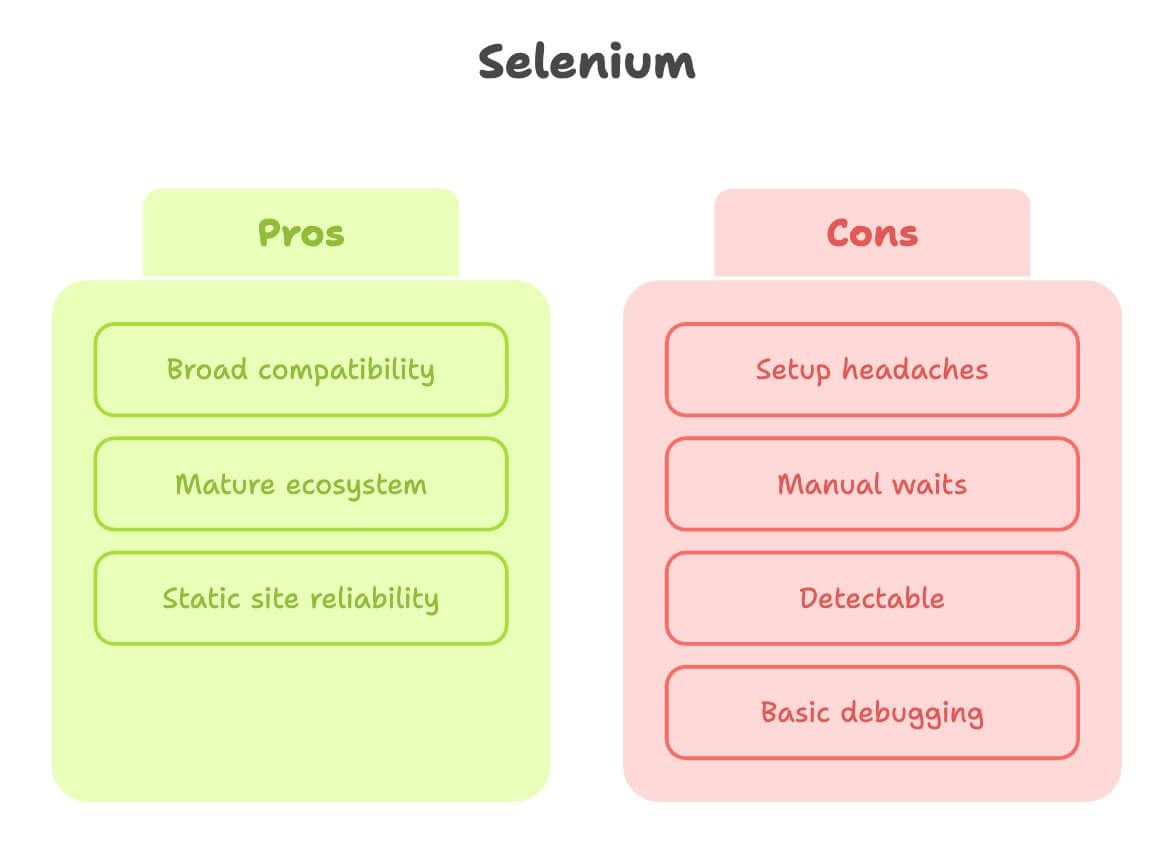
Selenium voor webscraping: sterke punten en beperkingen
Laten we Selenium zijn eer geven. Het is de grootvader van browserautomatisering, en voor veel scrapingklussen werkt het gewoon.
Sterke punten:
- Brede compatibiliteit: Werkt met bijna elke browser en taal.
- Volwassen ecosysteem: Tientallen tutorials, Q&A’s en plugins.
- Geweldig voor statische sites: Als de pagina weinig verandert, is Selenium oersterk.
Beperkingen:
- Gedoe bij de installatie: Je moet een browserdriver downloaden en configureren (zoals ChromeDriver), en die up-to-date houden. Beginners lopen hier vaak vast (bron).
- Handmatige waits: Dynamische content? Dan schrijf je veel expliciete waits of, erger nog, willekeurige sleep-statements.
- Makkelijker te detecteren: Veel sites kunnen Selenium-aangestuurde browsers herkennen en blokkeren, vooral als je op een cloudserver draait.
- Debuggen is basis: Geen ingebouwde video-opname of interactieve inspector.
Kortom, Selenium is perfect voor eenvoudige, stabiele sites—maar kan voelen alsof je een rots bergop duwt op moderne, interactieve pagina’s.
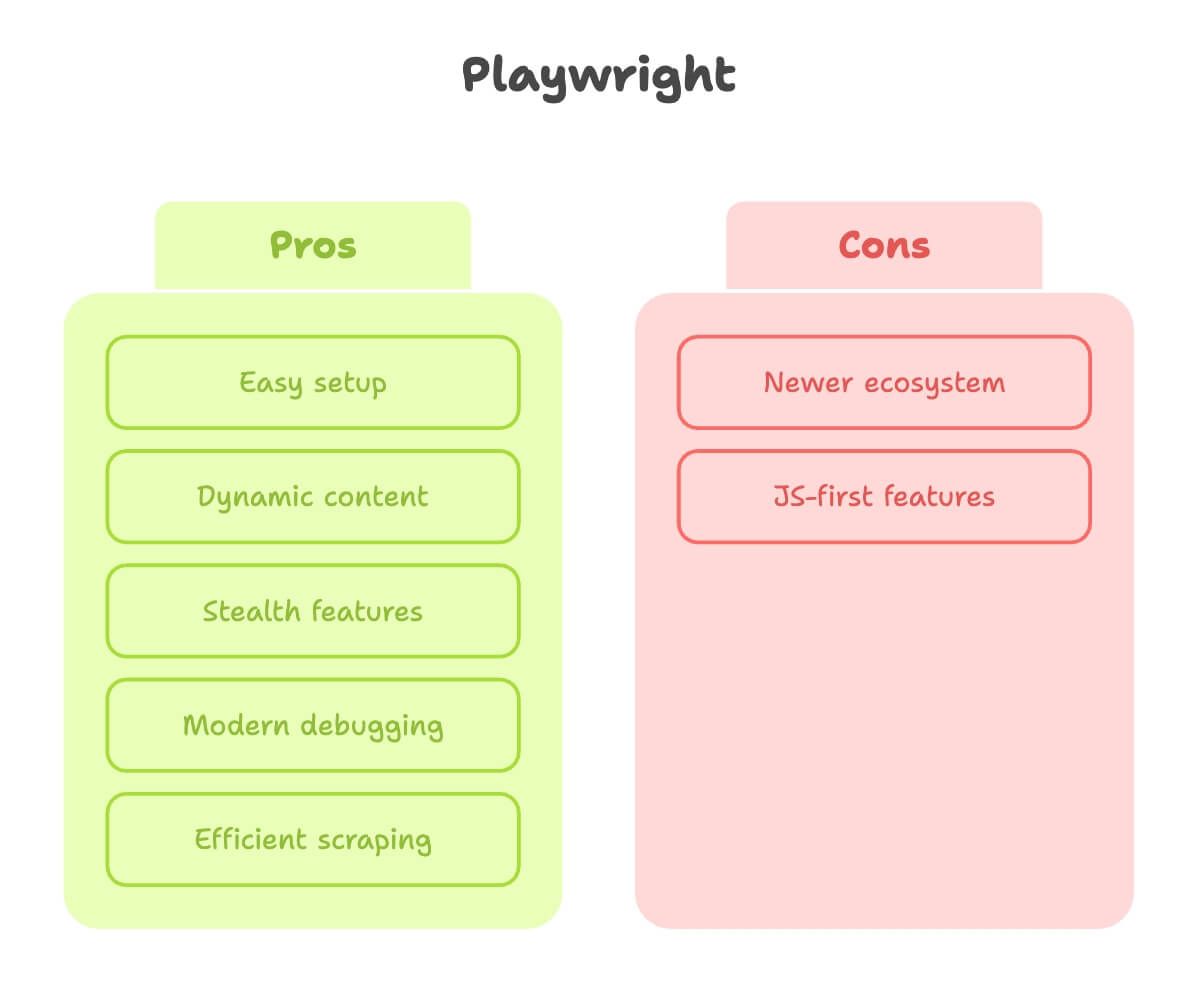
Playwright voor webscraping: sterke punten en beperkingen
Nu over Playwright. Als iemand die veel tijd heeft besteed aan het hanteren van beide tools, kan ik zeggen dat Playwright voelt alsof het is gebouwd door mensen die zelf echt hebben geleden onder webscraping.
Sterke punten:
- Eenvoudige installatie: Eén pip-installatie, één commando, en je kunt aan de slag. Geen gedoe met drivers.
- Verwerkt dynamische content: Wacht automatisch op elementen, zodat je niet hoeft te gokken wanneer de pagina klaar is (bron).
- Stealth-functies: Bootst echte gebruikers beter na, met ingebouwde stealth-modus en ondersteuning voor meerdere contexten (handig om als meerdere “gebruikers” tegelijk te scrapen).
- Moderne debugging: Inspector, video-opname en zelfs codegeneratie op basis van je handmatige klikken.
- Sneller en efficiënter: Vooral bij het scrapen van veel pagina’s of parallel draaien.
Beperkingen:
- Jonger ecosysteem: Iets minder tutorials, al wordt dat gat snel kleiner.
- Sommige functies zijn meer JavaScript-first: Het meeste werkt in Python, maar af en toe stuit je op een functie die in JS beter gedocumenteerd is.
De conclusie: Playwright is mijn vaste keuze voor elke site die ook maar een beetje dynamisch is, of wanneer ik snel resultaat wil zonder te worstelen met de installatie.
Anti-bot omzeilen: welke Python scraper gaat beter om met moderne websites?
Laten we de olifant in de kamer benoemen: geblokkeerd worden. Bij webscraping is het moeilijkste niet de code schrijven—het is ervoor zorgen dat de site de deur niet in je gezicht dichtgooit.
- Selenium: Standaard is het makkelijker te detecteren. Websites kunnen de
webdriver-vlag, headless user agents en andere herkenbare signalen spotten. Er zijn workarounds (zoals undetected-chromedriver), maar die vragen extra installatie en lopen voortdurend achter op anti-bottechnologie (bron). - Playwright: Heeft ingebouwde stealth-functies, zoals het automatisch verbergen van automatiseringsvingerafdrukken, ondersteuning voor meerdere browsercontexten en wachten op interacties die meer lijken op echt gebruikersgedrag. Het is geen magie, maar je wordt er minder snel bij de eerste poging door geblokkeerd.
Maar hier is de waarheid: Geen van beide tools is volledig immuun voor anti-botmaatregelen. Voor scraping met hoge inzet (denk aan sneakerdrops of ticketsites) heb je nog steeds proxies, IP-rotatie en misschien zelfs CAPTCHA-oplossing nodig. Playwright maakt het alleen net iets minder pijnlijk.
Developer experience: installatie, leercurve en debuggen
Laten we praten over de echte ervaring van starten—vooral als je beginner bent of gewoon de klus geklaard wilt hebben zonder een PhD in Python.
- Selenium:
- Installatie: Installeer Python, installeer Selenium, download de juiste browserdriver, zet die in je PATH, en hoop dat de versies kloppen. (Ik heb meer mensen vast zien lopen op de driverstap dan op het echte scrapen.)
- Leercurve: Veel bronnen, maar ook veel legacycode en verouderde tutorials.
- Debuggen: Vooral print-statements en screenshots. Selenium IDE bestaat, maar is vrij basic.
- Playwright:
- Installatie:
pip install playwright, daarnaplaywright install. Klaar. - Leercurve: Moderne documentatie, veel voorbeelden en de API voelt menselijker aan—je kunt elementen selecteren op tekst, rol of zelfs placeholder.
- Debuggen: De Inspector laat je door je script stappen, de browser bekijken en zelfs video’s opnemen van je scraping-runs (bron).
- Installatie:
Als je snel resultaat wilt zien en minder tijd wilt besteden aan installatie en troubleshooting, is Playwright de duidelijke winnaar. Selenium is geweldig als je al vertrouwd bent met de eigenaardigheden ervan of de brede compatibiliteit nodig hebt.
Stap voor stap: je eerste Python-webscraper bouwen met Playwright of Selenium
Laten we bekijken hoe het er in de praktijk uitziet om met elk van deze tools een scraper te bouwen—geen code, alleen de stappen.
Playwright (Python):
- Installeer Playwright en browsers:
pip install playwright+playwright install - Start de browser: Open een Chromium-, Firefox- of WebKit-browser (headless of zichtbaar).
- Navigeer naar de pagina: Gebruik
page.goto("<https://example.com>") - Wacht op content: Playwright wacht automatisch tot elementen geladen zijn.
- Extraheer data: Gebruik gebruiksvriendelijke selectors (zoals
get_by_text,locator("span.price")). - Verwerk paginatie of subpagina’s: Loop door pagina’s of klik door links—Playwright maakt het eenvoudig om meerdere pagina’s parallel uit te voeren.
- Exporteer data: Sla op naar CSV, Excel of een database.
- Debug: Gebruik de Inspector of video-opname als het misgaat.
Selenium (Python):
- Installeer Selenium:
pip install selenium - Download de browserdriver: (bijv. ChromeDriver voor Chrome), en zet die in je PATH.
- Start de browser: Open Chrome, Firefox of een andere browser.
- Navigeer naar de pagina:
driver.get("<https://example.com>") - Wacht op content: Voeg handmatig expliciete waits toe (
WebDriverWait) of, als je geluk wilt afvuren,time.sleep. - Extraheer data: Gebruik
find_elementoffind_elements(CSS/XPath-selectors). - Verwerk paginatie of subpagina’s: Loop door URL’s of klik op knoppen, maar timing en navigatie moet je zelf beheren.
- Exporteer data: Sla op naar CSV, Excel of een database.
- Debug: Vooral handmatig—kijk naar de browser, print HTML of maak screenshots.
Zie je het verschil? Playwright is gewoon net iets meer “plug-and-play” voor moderne sites.
Verder dan code: no-code webscraping met Thunderbit AI Web Scraper
Gegevens van elke website scrapen met AI Get Started Free
Laten we eerlijk zijn. Niet iedereen wil een Python-goeroe worden alleen maar om een tabel met productprijzen of een lijst met leads te krijgen. Misschien werk je in sales, marketing, vastgoed of operations, en wil je gewoon de data—nu. Daar komt Thunderbit om de hoek kijken.
Als medeoprichter van Thunderbit heb ik uit de eerste hand gezien hoeveel zakelijke gebruikers gewoon de code willen overslaan en meteen bij de goede dingen willen uitkomen. Daarom hebben we een AI-gestuurde Chrome-extensie gebouwd waarmee je elke website in twee klikken kunt scrapen—geen Python, geen drivers, geen debuggen.
Hoe Thunderbit werkt
- Ga naar de website die je wilt scrapen.
- Klik op “AI Suggest Fields”. Thunderbit’s AI scant de pagina en stelt de datavelden voor (zoals productnaam, prijs, afbeelding, beoordeling).
- Klik op “Scrape”. Meteen krijg je een gestructureerde tabel met data.
- Exporteer naar Excel, Google Sheets, Airtable, Notion, CSV of JSON. Klaar.
Geen gedoe met selectors, geen trial-and-error, geen code. Het is net zo makkelijk als eten bestellen (en eerlijk is eerlijk, waarschijnlijk sneller dan wachten tot je eten bezorgd wordt).
Probeer Thunderbit AI Web Scraper gratis
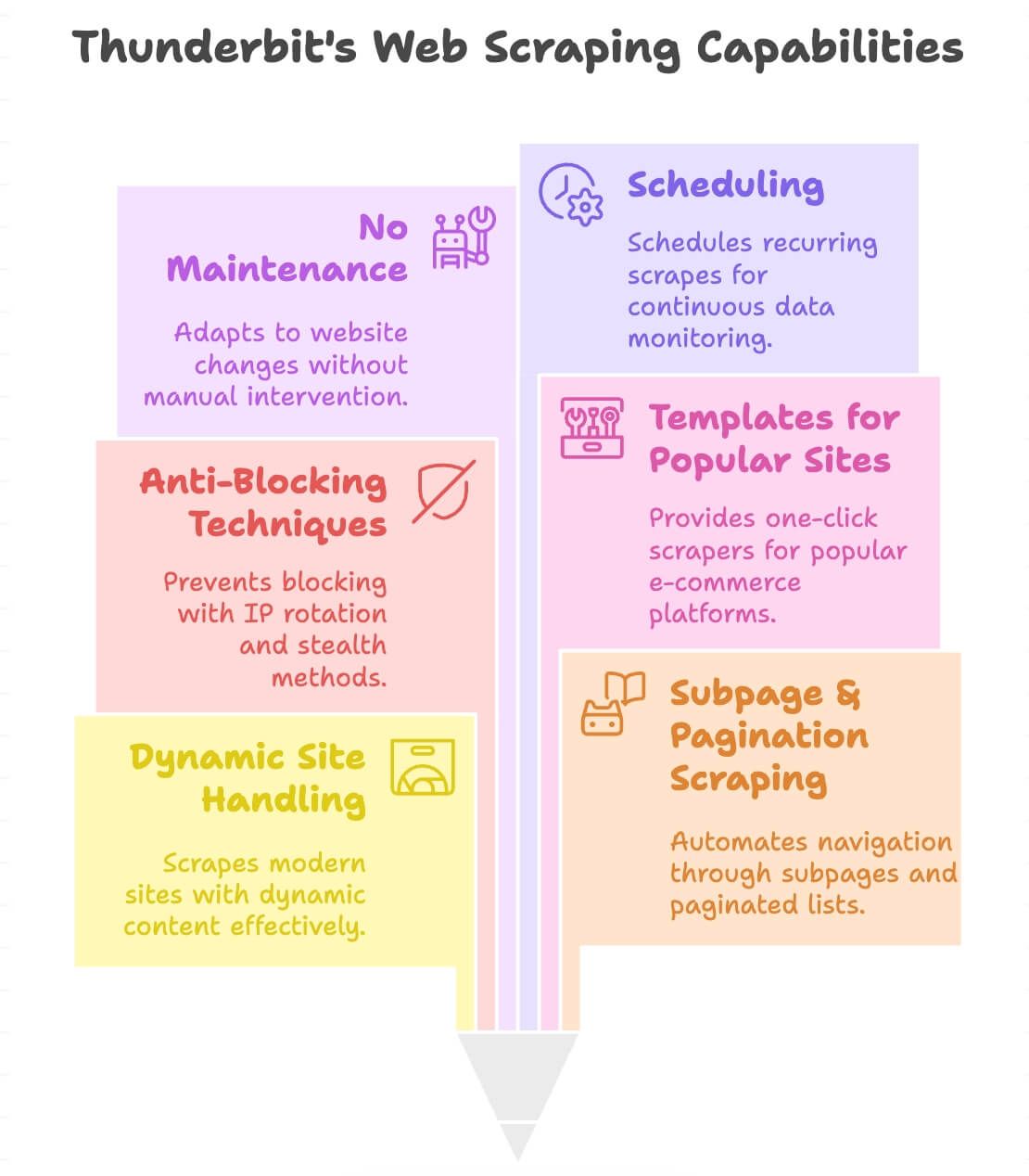
Wat maakt Thunderbit anders?
- Verwerkt dynamische sites: Scrapt moderne e-commerce, directories en zelfs sites met oneindig scrollen of pop-ups.
- Scraping van subpagina’s en paginatie: Klikt automatisch door productpagina’s of gepagineerde lijsten om alle data te verzamelen die je nodig hebt.
- Ingebouwde anti-blokkering: Gebruikt backend-IP-rotatie en stealth-technieken, zodat je minder snel wordt geblokkeerd.
- Sjablonen voor populaire sites: One-click scrapers voor Amazon, eBay, Shopify, Zillow en meer (zie onze blog voor details).
- Minder onderhoud: Als de lay-out van een site verschuift, kan de “AI Suggest Fields”-ronde meestal de velden opnieuw detecteren, zodat je vaak alleen de suggestiestap opnieuw uitvoert in plaats van een selectorscript helemaal opnieuw op te bouwen.
- Planning: Stel terugkerende scrapes in voor doorlopende monitoring (bijv. dagelijkse prijschecks).
- Ondersteunt 55 talen: Scrape en vertaal data van bijna overal.
En het mooiste? Je hoeft niets te weten van HTML, CSS of Python. Als je een browser kunt gebruiken, kun je Thunderbit gebruiken.
Welke webscraping-oplossing past bij jou?
Laten we afsluiten met een korte keuzegids:
| Jouw situatie | Beste tool |
|---|---|
| Een statische, eenvoudige website scrapen; installatie is geen probleem | Selenium |
| Een moderne, dynamische site scrapen; snel resultaat willen | Playwright |
| Ondersteuning nodig voor legacy-browsers of -talen | Selenium |
| Eenvoudige installatie, moderne debugging en minder code willen | Playwright |
| Geen developer; nu data willen, geen code, geen installatie | Thunderbit |
| Meerdere pagina’s, subpagina’s of geplande taken willen scrapen | Thunderbit |
| Direct exporteren naar Excel, Sheets, Notion, Airtable | Thunderbit |
| Een hekel hebben aan het debuggen van Python-fouten | Thunderbit |
Als je developer bent, of graag met code speelt, zijn Playwright en Selenium allebei krachtige opties. Maar als je doel is om zo snel mogelijk data in een spreadsheet te krijgen, dan bespaart Thunderbit je uren—misschien zelfs dagen—werk.
Aan de slag met Thunderbit AI Web Scraper
Conclusie: snel, betrouwbaar webscraping—op jouw manier
Webscraping is mainstream geworden, en dat is niet voor niets: bedrijven hebben data nodig om te concurreren, en ze hebben het nu nodig. Playwright en Selenium zijn allebei geëvolueerd van bescheiden testtools naar essentiële scrapingframeworks, elk met hun eigen sterke punten. Selenium is de oude betrouwbare keuze voor statische sites en legacy-opstellingen; Playwright is de moderne, snelle optie voor dynamische, interactieve pagina’s.
Maar hier is mijn eerlijke advies, na jaren in SaaS, automatisering en AI: Als je hier niet voor de code in zit, verspil dan geen tijd met worstelen met drivers, selectors en anti-bottrucs. Met Thunderbit’s AI Web Scraper ga je in minuten van “ik heb deze data nodig” naar “hier is mijn Excel-bestand”—niet in dagen.
Dus of je nu een Python-pro bent of een zakelijke gebruiker die gewoon resultaat wil, er is een scrapingoplossing die past bij jouw behoeften—en jouw geduld. Probeer ze uit, kijk wat werkt voor jouw workflow, en onthoud: de beste scraper is degene die je de data geeft die je nodig hebt, met zo min mogelijk gedoe.
En als je ooit om 2 uur ’s nachts een Selenium-driverfout aan het debuggen bent, weet dan dat Thunderbit er nog steeds is, klaar om in twee klikken te scrapen. Veel scrapeplezier.
Wil je meer leren over no-code scraping, AI-gestuurde data-extractie en hoe Thunderbit je team kan helpen? Bekijk onze blog, of ga vandaag nog aan de slag met de Thunderbit Chrome-extensie.
P.S. Als je nog steeds niet zeker weet welke tool je moet gebruiken, of als je Thunderbit in actie wilt zien, kom dan langs op ons YouTube-kanaal voor demo’s, tips en af en toe een grap over webscraping. (Ja, die hebben we.)
Verder lezen:
- Wat is data scraping en hoe doe je het in 2025
- Hoe je Amazon-producten en -reviews in 2025 scrapt met AI
- De beste webscrapingtools en software in 2025
Probeer AI Web Scraper Get Started Free




