

De meeste artikelen over "Playwright vs Puppeteer" doen alsof één van de twee per se de betere scraper moet zijn. Die insteek houdt al meteen geen stand. Ik heb beide libraries langs exact dezelfde set pagina’s gehaald — een statische catalogus, een JavaScript-gerenderde catalogus, een artikel, een kapotte 500-pagina, een kleine crawl-grafiek en twee openbare oefensites — en de resultaten waren bijna niet van elkaar te onderscheiden. Zelfde recall, dezelfde rendering, dezelfde screenshots, dezelfde hiaten.
Dit is dus geen kroning. Bij de taken die er echt toe doen bij het scrapen van webpagina’s, kwam geen van beide duidelijk als winnaar uit de bus. Hieronder lees je wat dan wél het echte verschil is dat je keuze zou moeten sturen, wat beide tools stilletjes bij jou neerleggen om zelf te bouwen, en een noot over het versieverschil dat ik heb getest (stand van zaken op 2026-07-09).
Waarom deze vergelijking überhaupt eerlijk is
Vergelijkingsartikelen hebben vaak de vervelende gewoonte om elk hulpmiddel op andere pagina’s te testen en daarna een winnaar aan te wijzen — dan leer je meer over de pagina’s dan over de tools. Ik heb dat vermeden door Playwright en Puppeteer tegen dezelfde lokale testserver en dezelfde openbare demo’s te laten lopen, Books to Scrape en Quotes to Scrape, zodat elke uitkomst netjes één-op-één te vergelijken is.
Alleen dan heeft een uitspraak als “gelijkspel” echt betekenis. Als de testcases verschillen, is een gelijkspel gewoon ruis. Als ze byte voor byte hetzelfde zijn, zeggen gelijke resultaten echt iets over de tools zelf.
Wat elk hulpmiddel eigenlijk is
Puppeteer is een JavaScript-API om Chrome te besturen via het Chrome DevTools Protocol. De officiële omschrijving zegt het ook gewoon zo: "a JavaScript API to control Chrome (and experimentally Firefox)." Het is volwassen, sterk gericht op Chrome en gebouwd op Node.
Playwright positioneert zichzelf anders: als "a framework for Web Testing and Automation" dat via één API Chromium, Firefox en WebKit aanstuurt, met officiële clients in JavaScript, Python, Java en .NET. De twee delen DNA (Playwright komt voort uit het team achter Puppeteer bij Google voordat het naar Microsoft verhuisde), en daarom voelen ze eerder als familie dan als rivalen.
Voor scraping gedragen ze zich echter vrijwel hetzelfde. Je start een echte browser, opent een pagina, laat de scripts draaien en leest daarna de gerenderde DOM uit. Juist daarom grijp je naar een van deze twee in plaats van naar een HTTP-parser: je wilt de pagina nadat JavaScript is uitgevoerd, niet de lege huls ervoor. Alles hieronder vloeit voort uit datzelfde mechanisme — en precies daarom blijkt zoveel tussen de twee uiteindelijk nauwelijks uit te maken.
De resultaten, naast elkaar
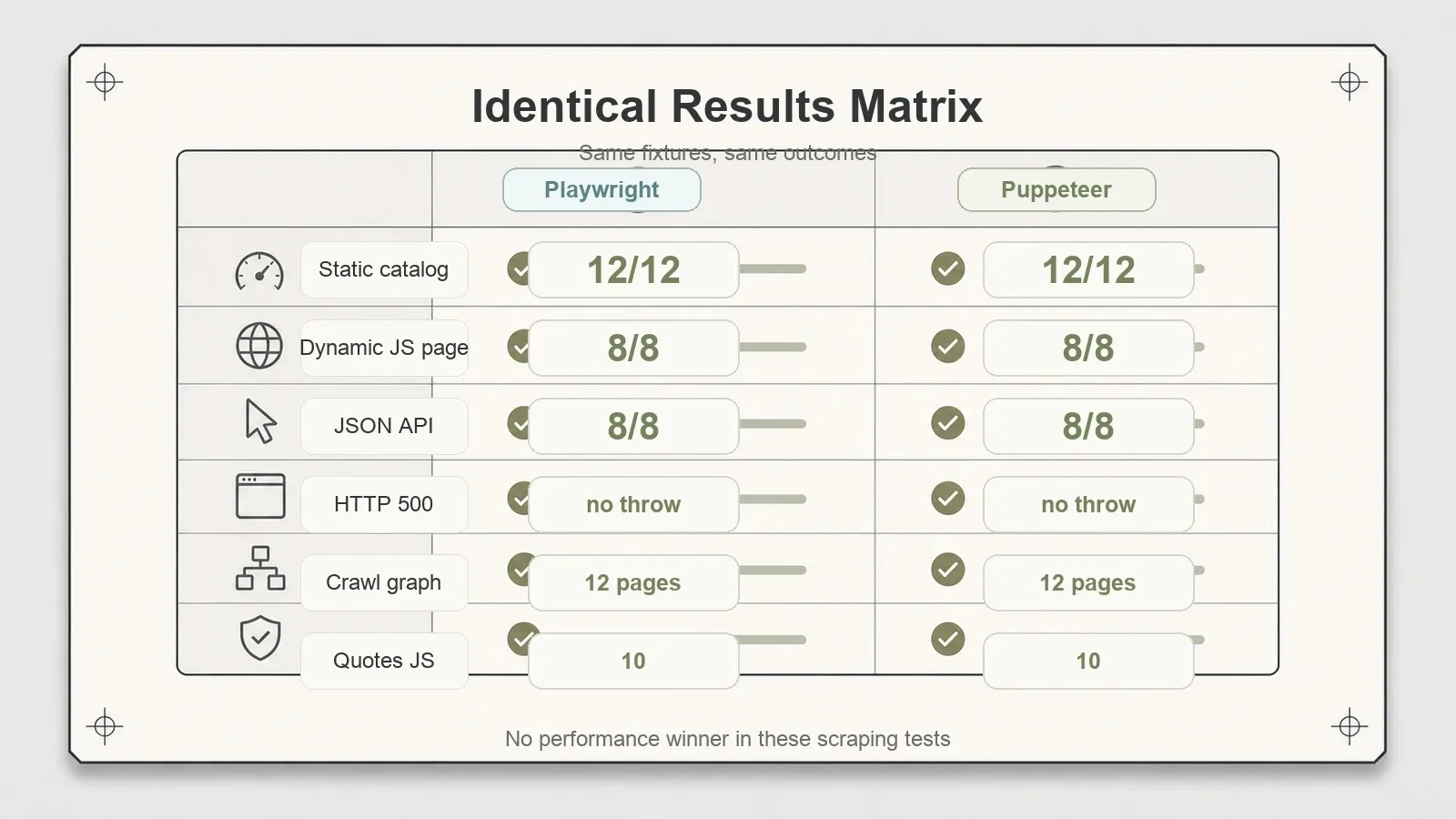
Hier stort het verhaal van “de ene is duidelijk beter” stilletjes in elkaar. Dezelfde testcases, dezelfde cijfers, overal.
| Test | Playwright | Puppeteer |
|---|---|---|
| Statische catalogus (12 producten) | 12/12, recall 1.0 | 12/12, recall 1.0 |
| Artikel (titel + 3 alinea’s) | 3/3, boilerplate gescheiden | 3/3, boilerplate gescheiden |
| Dynamische JS-pagina (native rendering) | 8/8 + screenshot | 8/8 + screenshot |
| Dynamische JSON-API | 8/8, recall 1.0 | 8/8, recall 1.0 |
| Afhandeling HTTP 500 | inspecteerbaar, geen throw | inspecteerbaar, geen throw |
| Crawl-grafiek (handgeschreven BFS) | 12 pagina’s, dieptes {0,1,2} | 12 pagina’s, dieptes {0,1,2} |
| Books to Scrape | 20 producten | 20 producten |
| Quotes JS (publiek) | 10 quotes | 10 quotes |
Beide renderden JavaScript native, zonder speciale configuratie. Beide maakten volledige screenshots van de pagina. Beide vingen een 500 af door een inspecteerbaar response-object terug te geven in plaats van een exception te gooien — klein, maar belangrijk als je op schaal scrapt en liever een foutstatus logt dan dat een hele run crasht.

Nog een nuance die ik bewust blijf herhalen, omdat die makkelijk misbruikt wordt: dit waren observaties op één machine, één keer uitgevoerd, geen benchmarks. Ik beweer dus niet dat de ene milliseconden sneller is dan de andere, want een stopwatch per pagina op één laptop is geen echte snelheidsmeting. Wat ik wél claim, en wat goed onderbouwd is: qua extractierecall en renderinggedrag, over acht verschillende paginatypen, deden ze exact wat ze moesten doen en sprong geen van beide eruit. Als je hoopte dat één van de twee op een echte pagina afstand zou nemen, dan gebeurde dat niet.
Het ene verschil dat wél de doorslag zou moeten geven
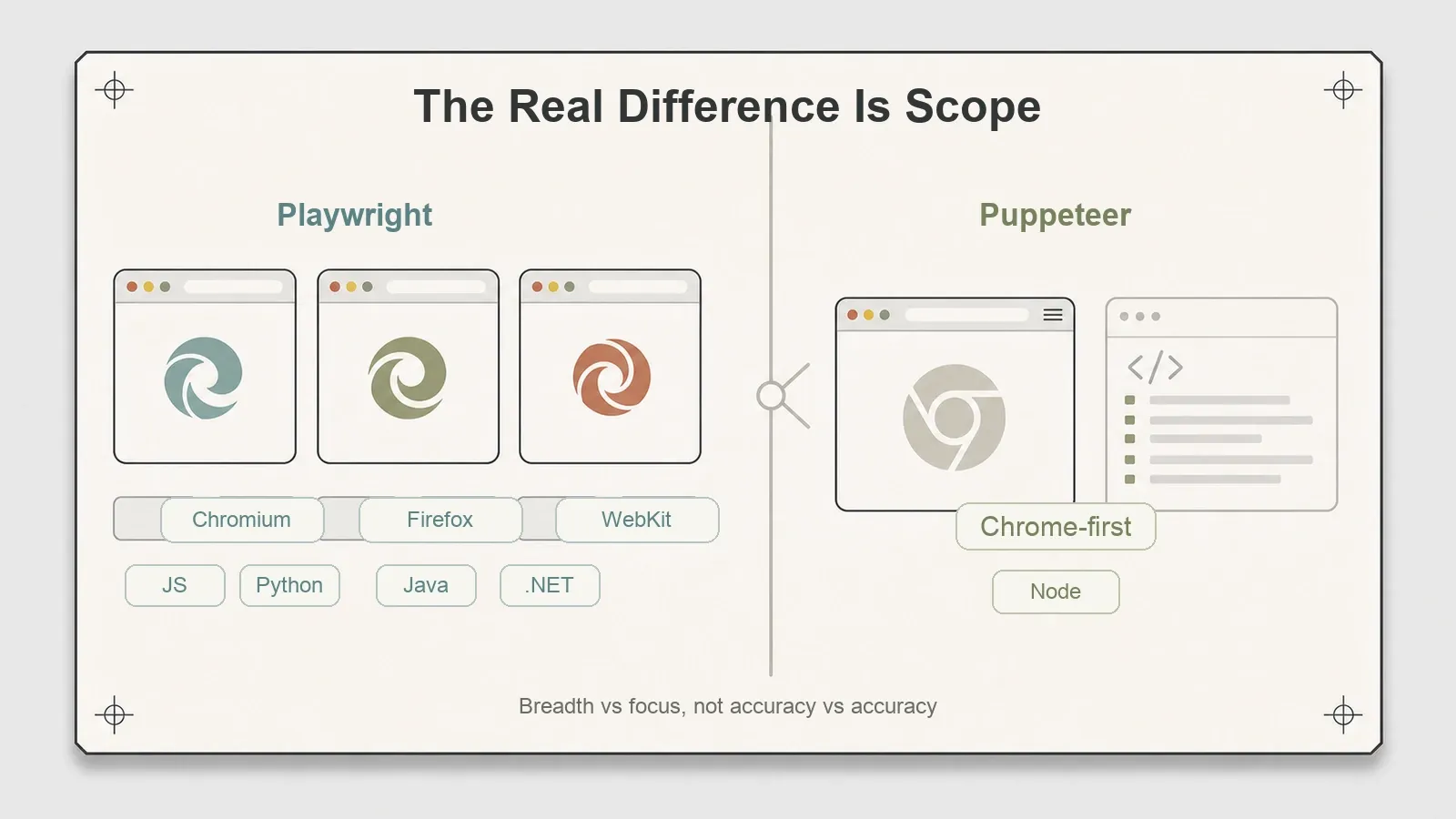
De echte scheidslijn zit niet in de cijfers. Die zit in de scope.
Playwright stuurt drie engines aan — Chromium, Firefox en WebKit — via één API, en levert daarnaast volwaardige clients in Python, Java en .NET bovenop JavaScript. Dat is een gedocumenteerde kracht, en ik wil hier precies zijn over het woord "gedocumenteerd": in deze test heb ik alleen Chromium gebruikt, dus ik rapporteer Playwrights ondersteuning voor drie engines als een beschreven mogelijkheid die ik niet zelf heb geverifieerd, niet als iets dat ik uitgebreid heb getest. Als je een site moet scrapen die er anders uitziet onder Safari’s WebKit, of als je team in Python werkt, dan is die breedte precies het argument vóór Playwright.
Puppeteer is Chrome-first, en de populaire samenvatting klopt inmiddels niet meer helemaal. "Alleen Chrome" is niet langer juist. Sinds Puppeteer v23 heeft het productieklaar Firefox-ondersteuning via WebDriver BiDi, terwijl het voor Chrome standaard CDP gebruikt om bestaande automatiseringen intact te houden — een verschuiving die zowel Chrome for Developers als Mozilla heeft gedocumenteerd. De versie die ik testte (24.16.0) ligt ver voorbij v23, dus het echte contrast is niet meer "Chrome versus drie engines". Het is: Puppeteer dekt Chrome (CDP) plus Firefox (BiDi), maar niet WebKit, en de cross-engine-ondersteuning is jonger dan die van Playwright. De engine die Playwright wel heeft en Puppeteer niet is WebKit.
Dat is de beslissing, in een notendop. Niet snelheid, niet nauwkeurigheid, niet rendering fidelity — op die punten is het gelijk. Het is een scopevraag: heb je WebKit-dekking nodig of niet-JavaScript clients, of is Chrome-en-Firefox vanuit Node genoeg voor jouw doelen? Voor een groot deel van de scrapingklussen voldoen beide, en kies je dus op stack-fit in plaats van op pure functionaliteit.
Wat geen van beide doet
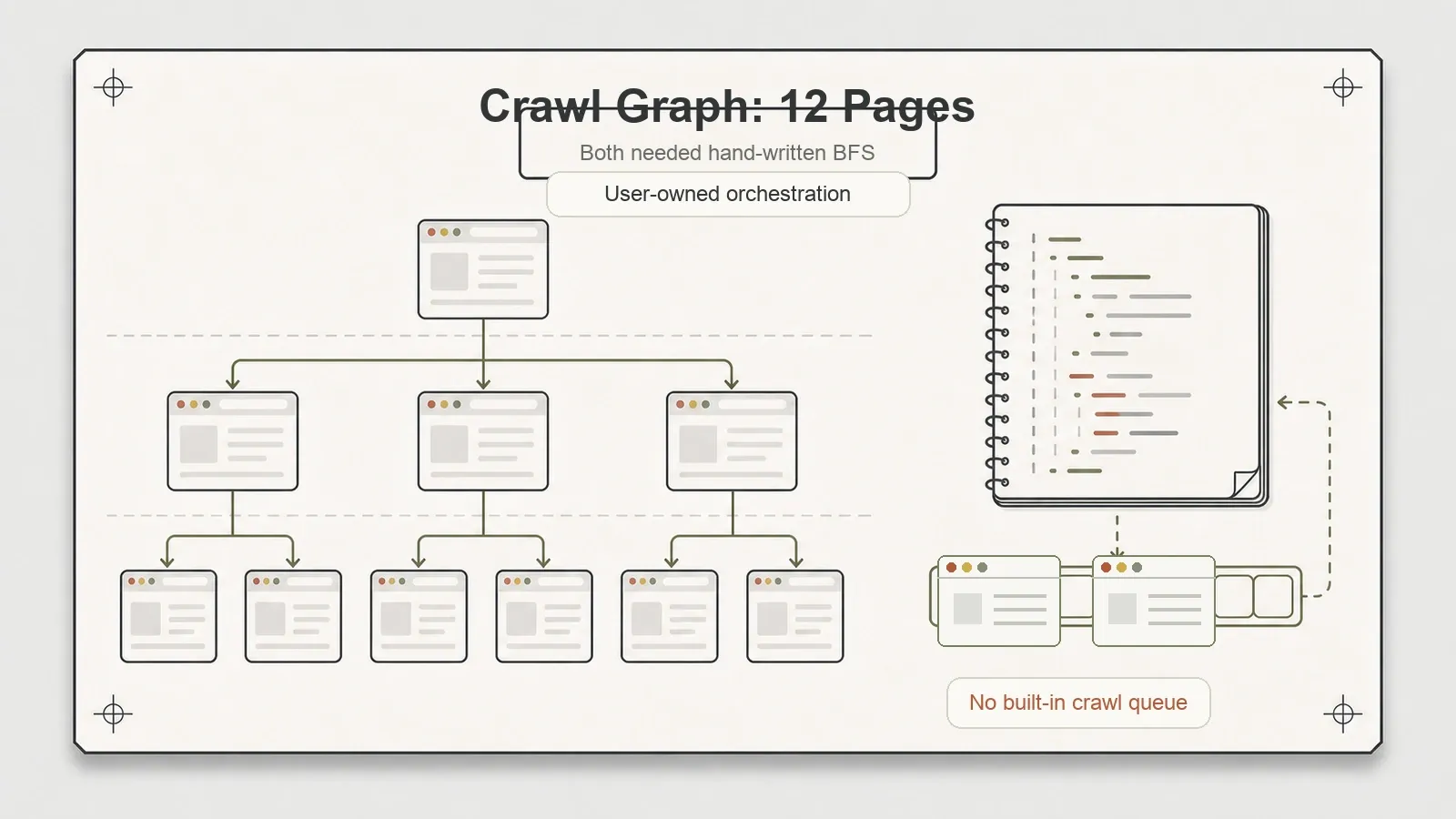
Beide tools laten hetzelfde werk op jouw bureau liggen: crawl-orchestratie. Geen van beide levert een ingebouwde request queue, dataset-writer of automatische throttling. Mijn test met de crawl-grafiek — interne links volgen, diepte bijhouden, geen URL opnieuw bezoeken — vereiste in beide gevallen handgeschreven breadth-first search. Twaalf pagina’s, dieptes {0,1,2}, mijn eigen BFS, twee keer.
Voor een handjevol pagina’s is dat prima; een kleine BFS is een paar regels code. Maar voor crawlen op schaal — honderden of duizenden URL’s met deduplicatie, retries en beleefde wachttijden — moet je die machine zelf bouwen of kiezen voor iets dat deze engines omhult. Crawlee doet precies dat en biedt een echte crawlinglaag bovenop zowel Playwright als Puppeteer.
Dit is geen gebrek, en ik wil het ook correct benoemen: Playwright en Puppeteer zijn browser-automation frameworks, geen crawler frameworks. De ontbrekende queue is een scopegrens, geen bug. Het juiste mentale model is dat deze tools het deel zijn waarmee je de pagina “ziet”. Het deel waarmee je de site “afloopt” moet je er nog altijd zelf bij leveren — of inpluggen via een wrapper die dat al doet.
Installatie en het versievoorbehoud
De installatie is bijna identiek. npm install haalt de library én een browserbinary op, en die binary is het zware gedeelte — Puppeteer bundelt automatisch een Chrome-download (in mijn run een schone installatie, zonder gemelde kwetsbaarheden), terwijl Playwright een aparte npx playwright install gebruikt voor zijn browserbuilds. Geen van beide installaties is lastig, maar reken in beide gevallen op de download; het browsergewicht en de kosten per pagina zijn de echte prijs die je betaalt voor rendering, vergeleken met een HTTP-only tool.
Dan de openheid die ik je verschuldigd ben. Ik testte Playwright 1.56.0 tegenover de nieuwste release 1.61.1, en Puppeteer 24.16.0 tegenover npm-latest 25.3.0 — dus Puppeteer liep een volledige major versie achter, allemaal op 2026-07-09. De API’s die ik gebruikte zijn stabiel over die verschillen heen, dus de resultaten blijven geldig. Maar als je dit lang na publicatie leest, test het dan opnieuw met de huidige versies voordat je er exacte getallen op gaat baseren. En nogmaals: ik heb bij Playwright alleen Chromium gebruikt, dus ik doe geen uitspraak over de gelijkwaardigheid van Firefox of WebKit buiten het feit dat het gedocumenteerd is.
Playwright en Puppeteer: voor- en nadelen
Dat het gelijkspel eindigt, maakt de lijst met voor- en nadelen minder een strijd en meer een kwestie van wat je precies kiest.
Playwright
- Voordelen: gedocumenteerde ondersteuning voor drie engines (Chromium, Firefox, WebKit) via één API; officiële clients voor Python, Java en .NET; native JavaScript-rendering met volledige recall; actief verbreed.
- Nadelen: geen ingebouwde crawl queue; browsergewicht en kosten per pagina; in deze test alleen Chromium gebruikt; de versie die ik draaide liep achter op de nieuwste release.
Puppeteer
- Voordelen: volwassen, stabiele Chrome-automatisering via CDP; native JavaScript-rendering met volledige recall; nette afhandeling van 500’s (response-object, geen throw); diep, veelgebruikt ecosysteem; gedocumenteerde Firefox-ondersteuning via WebDriver BiDi sinds v23.
- Nadelen: Chrome-first en Node-based, zonder WebKit-engine; geen ingebouwde crawl queue; browsergewicht; de versie die ik draaide lag een volledige major achter op de nieuwste npm-versie.
Wie kiest wat?
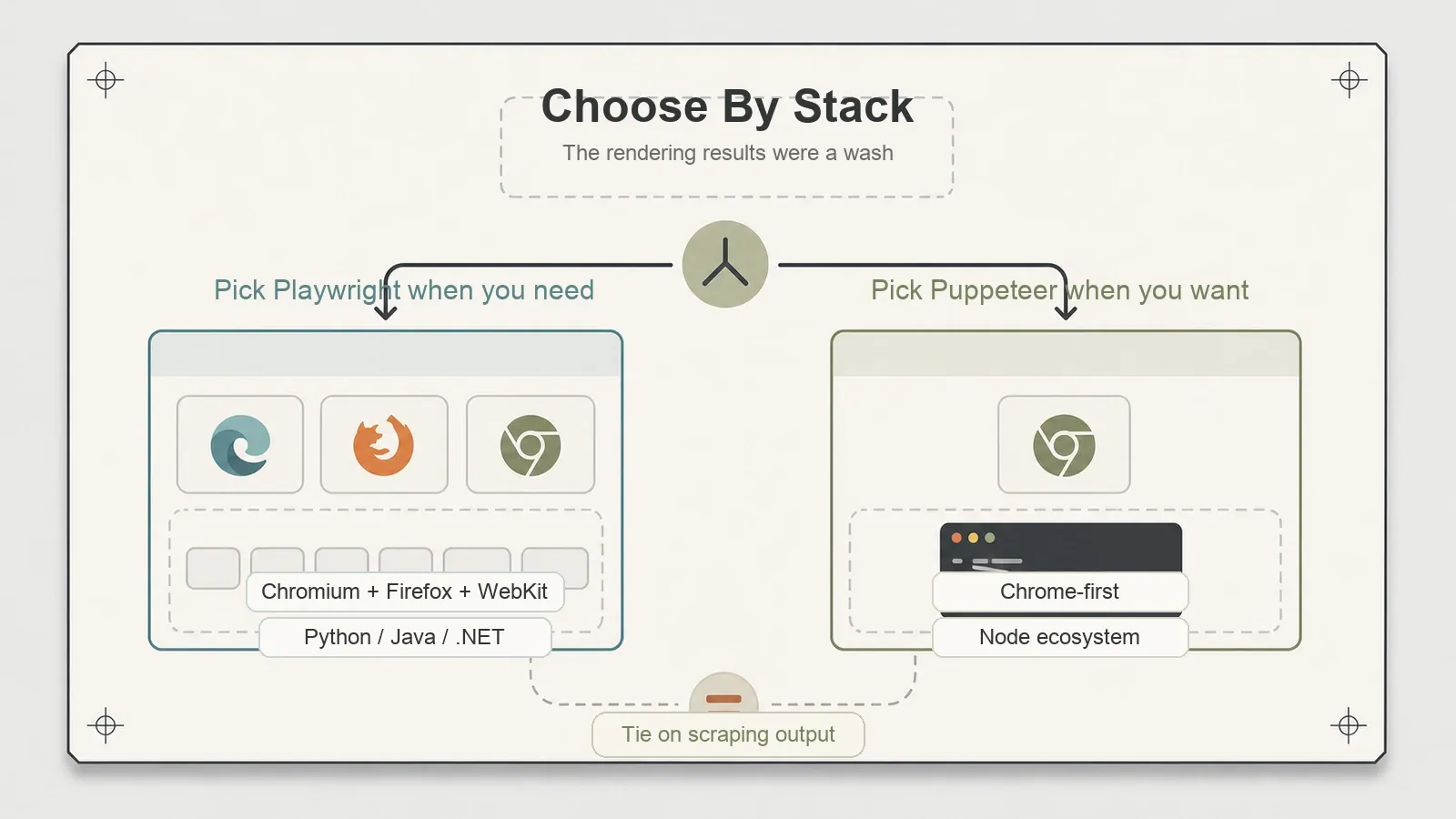
Kies Puppeteer als je in Node leeft, je doelen prima renderen in Chrome — en dat is meestal zo — en je een volwassen, gefocuste library wilt met een diep ecosysteem en één complexiteitslaag minder om rekening mee te houden. De optie via Firefox-BiDi is er als je daar later op wilt doorgroeien.
Kies Playwright als je WebKit-dekking nodig hebt, je je scraper in Python of .NET wilt schrijven, of liever inzet op het project met de bredere engine- en taalscope. Alleen al die taalkoppeling is voor veel Python-teams de duidelijkste reden om voor Playwright te kiezen.
En er is nog een derde antwoord dat vergelijkingsartikelen vaak overslaan: kies geen van beide als je pagina’s hun data helemaal niet via JavaScript nodig hebben. Als een HTTP-request en een parser je al de inhoud geven, dan is een headless browser dure overkill — dat is een andere toolcategorie, en daar een echte browser voor inzetten kost alleen maar geheugen en opstarttijd zonder voordeel.
Waar een managed API past, inclusief Thunderbit
Probeer Thunderbit voor webdata-extractie
Zowel Playwright als Puppeteer zijn gratis, open source libraries die je zelf draait en onderhoudt. Jij bent verantwoordelijk voor de browseromgeving, updates, de crawlcode die je erbovenop bouwt en de anti-bot-wapenwedloop. Voor heel veel projecten is dat precies de juiste keuze, en niets hier is een argument tegen die aanpak.
Maar kijk eens hoeveel van het echte scrape-werk eigenlijk buiten deze tools valt. Ze renderen een pagina prima; ze plannen geen URL’s in, ze rouleren niet automatisch rond blokkades, ze leveren je geen gestructureerde JSON en jij houdt de browservloot draaiend. Dat is een andere laag in de stack dan een managed extraction service, en het is goed om dat hardop te benoemen als je als developer een build-versus-buy-afweging maakt. Onze eigen Thunderbit developer stack zit in die andere laag: POST /distill zet een pagina om in schone, LLM-klare Markdown en POST /extract geeft gestructureerde JSON terug op basis van een schema dat je zelf definieert, met JavaScript-rendering, anti-bot-afhandeling en CAPTCHA’s server-side geregeld in plaats van op je laptop. Er is een Thunderbit MCP-server voor AI-agents en coding assistants (waar thunderbit_suggest_fields gratis draait vóórdat je iets uitgeeft), en een CLI via npx @thunderbit/thunderbit-cli voor CI en cron.
Ik ga niet doen alsof dat per se beter is — het is een andere vorm van afweging. Met Playwright of Puppeteer beheer je zelf de rendering en alles wat je eromheen bouwt, zonder kosten per call. Met een managed API besteed je rendering, anti-bot en crawling-plumbing uit, en betaal je per request (in Thunderbit’s geval op basis van gebruik per call — één credit voor een distill, twintig voor een extract — niet per rij). Klein, zelf gehost en graag zelf de browser in de hand? Dan zijn deze libraries de juiste tools. Schaal je op, en wil je liever niet ook nog een headless browser-vloot, crawler én block-rotationlaag beheren? Dan haalt een managed route dat hele soort werk weg.
Voor het bredere landschap heeft ons team ook Crawlee’s twee-engine-aanpak en een reeks HTTP-first frameworks op dezelfde testcases gezet, wat een logische volgende stap is als je inmiddels hebt besloten dat een volledige browser meer is dan jouw pagina’s nodig hebben.
Conclusie
Moet je Playwright of Puppeteer gebruiken? Voor het renderen van JavaScript-pagina’s maakt het in deze test niet uit — ze eindigden gelijk op alles wat hier relevant was, dus je levert geen capaciteit in als je op andere gronden kiest. Kies Puppeteer als Chrome-en-Firefox vanuit Node past en je waarde hecht aan volwassenheid en focus. Kies Playwright als je WebKit-bereik of niet-JavaScript clients nodig hebt.
Twee dingen die vergelijkingsartikelen vaak overslaan, zijn het waard om mee te nemen. Ten eerste: in echte scrapingtaken is dit duo een oprecht gelijkspel, dus maak je niet druk om een prestatieverschil dat in acht verschillende tests niet opdook. Ten tweede: geen van beide is een crawler — ze renderen, en het crawlen moet jij zelf regelen of uitbesteden aan een wrapper zoals Crawlee. Als je dat scherp hebt, de scope laat aansluiten op je stack en de keuze blijft klein. De engine-keuze is veel minder belangrijk dan de helft van het werk die geen van beide voor je doet.
Meer lezen
Probeer Thunderbit voor webdata-extractie Get Started Free
Veelgestelde vragen
Is Playwright of Puppeteer sneller voor webscraping? Op identieke testcases was het praktisch gelijkspel — dezelfde recall op statische pagina’s (12/12), dynamische pagina’s (8/8) en JSON-API-extractie, dezelfde native rendering en dezelfde afhandeling van 500-fouten. Dit waren eenmalige observaties op één machine, geen benchmarks, dus timingverschillen per pagina zijn geen echte snelheidsmeting. Kies op scope en taal, niet op een snelheidsverschil dat niet zichtbaar werd.
Wat is het echte verschil tussen Playwright en Puppeteer? De engine- en taalscope. Playwright stuurt Chromium, Firefox en WebKit aan via één API, met clients voor Python, Java en .NET. Puppeteer is Chrome-first via CDP, met gedocumenteerde Firefox-ondersteuning via WebDriver BiDi sinds v23, maar zonder WebKit, en het is Node-based. Beide renderen JavaScript native, en geen van beide bevat ingebouwde crawl-orchestratie.
Kan ik met Playwright of Puppeteer een hele site crawlen? Niet out of the box. Geen van beide heeft een request queue, dataset-writer of automatische throttling — mijn crawl-grafiektest vereiste in beide gevallen handgeschreven BFS, twaalf pagina’s op dieptes {0,1,2}. Voor schaal gebruik je een crawlaag zoals Crawlee, die beide engines omhult met echte crawl-machinerie.
Heb ik überhaupt een browsertool nodig voor scraping? Alleen als de pagina JavaScript nodig heeft om de data zichtbaar te maken. Als een HTTP-request plus parser al de inhoud oplevert die je wilt, dan is een headless browser dure overkill — gebruik dan liever een HTTP-first tool en sla de browserlast helemaal over.
Welke moet een Python-team kiezen? Playwright, omdat het een eersteklas Python-client heeft. Puppeteer is Node-based, dus gebruik ervan vanuit Python betekent een brug bouwen die je ook nog moet onderhouden. Die taalfit is een van de duidelijkste redenen om voor Playwright in plaats van Puppeteer te kiezen.




