

In de supersnelle wereld van e-commerce is het bijhouden van concurrentieprijzen, het spotten van nieuwe productlanceringen en het monitoren van klantreviews geen luxe meer, maar pure noodzaak. Waar je vroeger moest stoeien met lastige tools, onoverzichtelijke Excel-sheets of – nog erger – Python-scripts die vooral voor techneuten waren, is het speelveld nu flink veranderd. Browserautomatiseringstools zoals Playwright maken webscraping krachtiger dan ooit, maar voor veel zakelijke gebruikers blijft de technische drempel hoog. Gelukkig zijn er nu AI-gedreven oplossingen zoals Thunderbit, waarmee zelfs iemand zonder programmeerkennis in een paar minuten de juiste data kan verzamelen.
In deze gids neem ik je stap voor stap mee in de basis van webscraping met Playwright (met een praktisch voorbeeld op eBay), bespreek ik de uitdagingen voor beginners en laat ik zien hoe de AI-webscraper van Thunderbit het proces super eenvoudig maakt – ideaal voor sales, marketing of operations als je snel data wilt zonder je te verdiepen in Python.
Wat is Playwright? Een Introductie voor Starters
Laten we bij het begin beginnen: wat is Playwright nou eigenlijk?
Playwright is een browserautomatiseringsframework van Microsoft. Zie het als een afstandsbediening voor je browser, maar dan programmeerbaar en geschikt voor meerdere browsers (Chromium, Firefox, WebKit) én programmeertalen (Python, JavaScript/Node.js, Java, C#). Met Playwright kun je alles automatiseren: van klikken op knoppen en invullen van formulieren tot het scrapen van dynamische content die pas na het laden van JavaScript zichtbaar wordt.
Waarom is dit zo belangrijk voor webscraping? Klassieke scrapingtools zoals requests en BeautifulSoup zijn prima voor simpele, statische pagina’s, maar lopen vast bij moderne websites vol JavaScript. Playwright pakt juist die dynamische elementen aan en simuleert echte gebruikersacties. Het is alsof je een digitale stagiair hebt die nooit moe wordt (en nooit om opslag vraagt).
Hoe verhoudt Playwright zich tot Selenium en Puppeteer?
- Selenium: De oude rot in het vak. Ondersteunt veel talen, maar is vaak wat traag en log.
- Puppeteer: Google’s tool, vooral voor Chromium-browsers. Lekker snel, maar standaard alleen voor Chrome/Chromium.
- Playwright: Gemaakt voor meerdere browsers, sneller dan Selenium en met een moderne, gebruiksvriendelijke API. Het is razendsnel populair geworden voor scraping- en automatiseringsprojecten (bekijk de cijfers).
Waarom Playwright Gebruiken voor Webscraping?
Waarom zou je als sales-, operations- of e-commerceprofessional Playwright moeten overwegen?
Dit zijn de voordelen van Playwright:
- Perfect voor JavaScript-rijke sites: Ideaal voor het scrapen van grote e-commerceplatforms zoals eBay, waar productdata dynamisch wordt geladen.
- Automatiseert gebruikersacties: Klik op “volgende pagina”, scroll, filter of log zelfs in – net als een echte gebruiker.
- Draait in headless-modus: Je hoeft geen browservenster te zien knipperen; Playwright werkt onzichtbaar op de achtergrond.
- Slimme wachttijden ingebouwd: Wacht automatisch tot content geladen is, wat fouten en frustratie voorkomt (meer info).

Praktijkvoorbeeld:
Stel, je runt een webwinkel en wilt laptopprijzen op eBay volgen. Met Playwright kun je dit proces automatiseren: zoek op “laptop”, haal alle producttitels en prijzen op en loop automatisch door meerdere pagina’s. Dit soort data is goud waard voor dynamische prijsstrategieën – je hoeft nooit meer te gokken als de concurrentie ineens met een flash sale komt (81% van de shoppers doet online onderzoek voor aankoop).
Veelvoorkomende zakelijke toepassingen:
- Prijsmonitoring: Houd concurrenten in de gaten en pas je prijzen direct aan.
- Productcatalogus opbouwen: Maak of update je eigen productoverzicht.
- Concurrentieanalyse: Ontdek trends, voorraadstatus en marketingstrategieën van anderen.
- Leadgeneratie: Verzamel verkopersinformatie of contactgegevens uit directories en marktplaatsen.
De opbrengst is duidelijk – bedrijven die prijsmonitoring automatiseren, zien vaak 5–25% omzetgroei (bron).
Playwright Python Installeren: De Eerste Stappen
Tijd om zelf aan de slag te gaan met Playwright in Python. (Geen stress, ik houd het simpel.)
1. Wat heb je nodig?
- Python 3.7 of hoger (check met
python --version) - pip (de pakketbeheerder van Python)
2. Installeer Playwright en de browsers
Open je terminal of opdrachtprompt en voer uit:
pip install playwright
python -m playwright install
Hiermee installeer je Playwright en download je de benodigde browsers (Chromium, Firefox, WebKit). Je bent nu klaar om te automatiseren!
3. Een Simpel “Hello World”-Script
Start een browser en bezoek eBay:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True) # headless=True draait de browser op de achtergrond
page = browser.new_page()
page.goto("https://www.ebay.com/")
print(page.title())
browser.close()
Voer dit script uit en je ziet de titel van de eBay-homepage in je terminal verschijnen. Gefeliciteerd, je hebt je eerste browserautomatisering gedaan!
Veelvoorkomende Installatieproblemen Oplossen
Zelfs met de beste tools kan er iets misgaan. Dit zijn veelvoorkomende Playwright-installatieproblemen:
- Python of pip ontbreekt: Controleer of Python in je systeem-PATH staat.
- Machtigingen: Probeer je terminal als administrator uit te voeren of gebruik
sudoop Mac/Linux. - Browserbinaries niet gevonden: Controleer of je
python -m playwright installhebt uitgevoerd. - Firewall- of proxyproblemen: Sommige bedrijfsnetwerken blokkeren downloads; probeer het thuis als je vastloopt.
Kom je er niet uit? De officiële Playwright troubleshooting docs bieden uitkomst.
Stap-voor-stap: Productdata Scrapen van eBay met Playwright
Tijd voor de praktijk. Zo kun je producttitels en prijzen van eBay halen met Playwright Python.
1. Bepaal je Zoekopdracht
Stel, we willen “laptop”-aanbiedingen scrapen.
2. Het Script
from playwright.sync_api import sync_playwright
search_term = "laptop"
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(f"https://www.ebay.com/sch/i.html?_nkw={search_term}")
page.wait_for_selector("h3.s-item__title") # Wacht tot producten geladen zijn
page_num = 1
results = []
while page_num <= 2: # Scrape de eerste 2 pagina’s als voorbeeld
print(f"Scraping page {page_num}...")
titles = page.locator("h3.s-item__title").all_text_contents()
prices = page.locator("span.s-item__price").all_text_contents()
for title, price in zip(titles, prices):
results.append({"title": title, "price": price})
print(f"{title} --> {price}")
# Ga naar de volgende pagina
next_button = page.locator("a[aria-label='Go to next search page']")
if next_button.count() > 0:
next_button.click()
page.wait_for_selector("h3.s-item__title")
page_num += 1
page.wait_for_timeout(2000) # Beleefde pauze
else:
break
print(f"Found {len(results)} items in total.")
browser.close()
Wat gebeurt er hier?
- We starten een headless browser, zoeken op eBay naar “laptop” en wachten tot de producttitels zichtbaar zijn.
- We halen alle titels en prijzen van de pagina.
- We klikken op “Volgende pagina” om meer resultaten te verzamelen.
- We voegen een korte pauze toe om niet als bot op te vallen.
Dit is de basis van Playwright-scraping: navigeren, wachten, data ophalen, herhalen.
Omgaan met Paginering en Dynamische Content
Moderne webshops gebruiken vaak oneindig scrollen en dynamisch laden. Playwright’s slimme wachttijden (wait_for_selector) helpen, maar soms moet je:
- Op “Volgende” klikken: Zoals in het script hierboven.
- Wachten op AJAX-content: Gebruik
wait_for_selectorofwait_for_timeoutom zeker te zijn dat alles geladen is. - Oneindig scrollen afhandelen: Scroll de pagina automatisch en wacht tot nieuwe items verschijnen.
Dit vraagt soms wat experimenteren – en geduld.
Omgaan met Anti-Scraping Maatregelen
Websites als eBay zijn niet altijd blij met webscrapers. Veelvoorkomende obstakels zijn:
- CAPTCHAs
- User-agent-controles
- Rate limiting en IP-blokkades
Playwright helpt door echte browsers te simuleren, maar voor grootschalig scrapen kun je het volgende nodig hebben:
- User agents roteren: Laat je scraper als verschillende browsers lijken.
- Proxies gebruiken: Wissel van IP-adres om blokkades te voorkomen.
- Verzoeken vertragen: Voeg willekeurige pauzes toe.
Toch kun je soms alsnog tegen beperkingen aanlopen – zeker bij grote volumes (eBay gebruikt geavanceerde rate-limiting).
De Uitdagingen van Playwright voor Beginners
Hier wordt het spannend. Playwright is krachtig, maar niet direct geschikt voor niet-programmeurs. Dit zijn de struikelblokken voor beginners:
- Programmeervaardigheden vereist: Je moet Python (of een andere taal) kennen, HTML/CSS-selectors begrijpen en kunnen debuggen.
- Scripts onderhouden: Websites veranderen vaak hun opmaak. Als eBay een class-naam wijzigt, werkt je script ineens niet meer.
- Dynamische content afhandelen: Wachten op AJAX, omgaan met oneindig scrollen en time-outs kan lastig zijn.
- Hoge systeemeisen: Headless browsers vragen veel van je computer, zeker bij veel pagina’s.
- Anti-botmaatregelen: CAPTCHAs oplossen, proxies beheren en bans voorkomen is een vak apart.
Ik heb zelf talloze avonden besteed aan het repareren van kapotte selectors en het uitzoeken waarom mijn script ineens geen data meer vond. Het hoort erbij als je zelf webscrapers bouwt – maar niet iedereen heeft daar tijd of zin in.
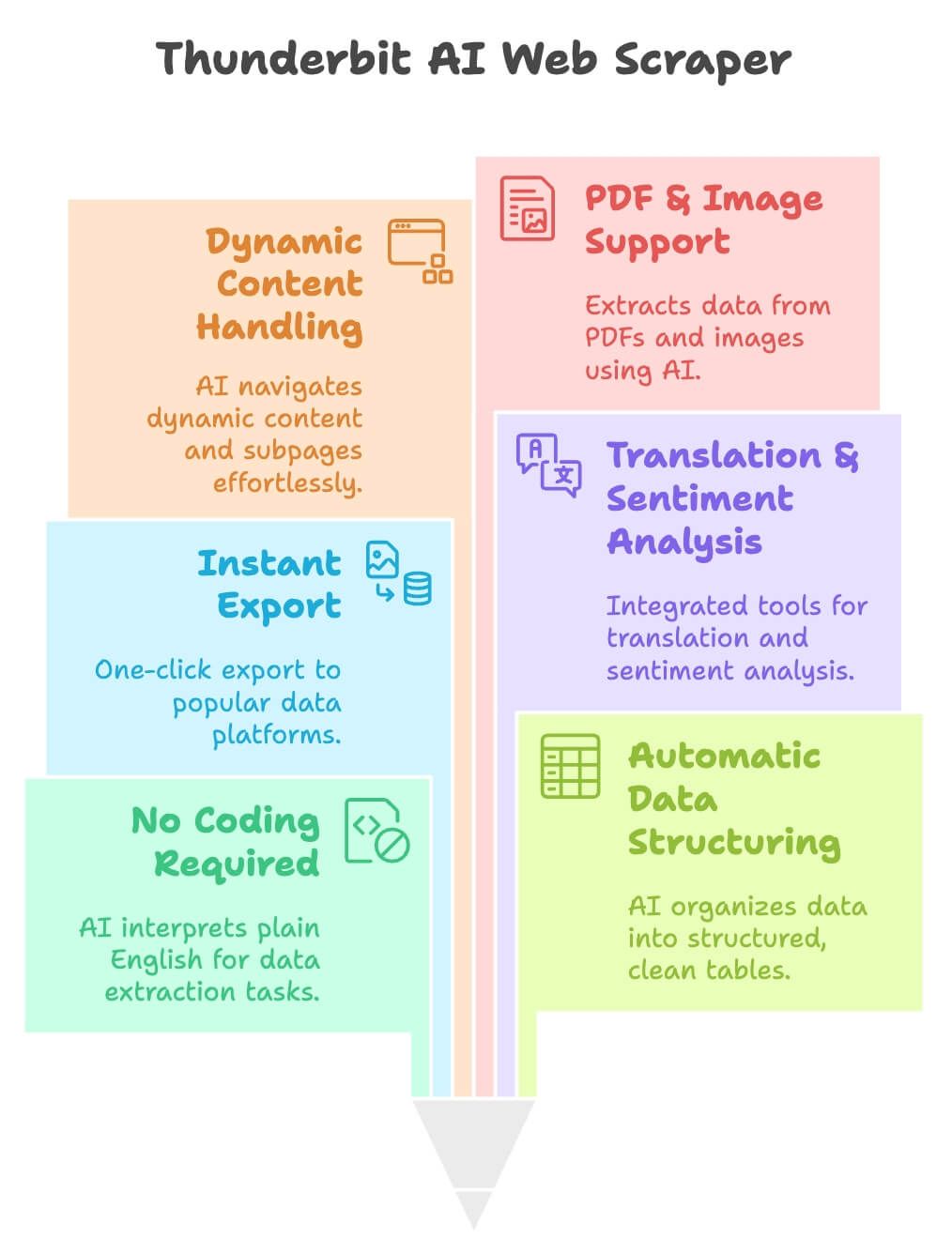
Thunderbit: AI-Webscraper Zonder Code of Gedoe
Tijd voor de nieuwe generatie: Thunderbit.
Thunderbit is een AI-webscraper Chrome-extensie, speciaal voor zakelijke gebruikers – denk aan sales, marketing en operations die snel data willen, zonder te programmeren. Dit maakt het zo aantrekkelijk:
- Geen code nodig: Beschrijf in gewone taal welke data je zoekt. Thunderbit’s AI regelt de rest.
- Automatische datastructurering: De AI stelt kolommen voor (zoals productnaam, prijs, beoordeling) en zet alles netjes in een tabel.
- Direct exporteren: Stuur je data met één klik naar Excel, Google Sheets, Airtable of Notion.
- Vertaling en sentimentanalyse ingebouwd: Wil je productomschrijvingen vertalen of klantbeoordelingen analyseren? Thunderbit doet het automatisch tijdens het scrapen – geen extra tools of scripts nodig.
- Omgaat met dynamische content, paginering en subpagina’s: De AI herkent en navigeert door “volgende”-knoppen, oneindig scrollen en klikt zelfs automatisch door naar subpagina’s.
- Werkt ook met PDF’s en afbeeldingen: Niet alleen webpagina’s – Thunderbit kan met OCR en AI ook data uit PDF’s en afbeeldingen halen.
Het is alsof je een data-assistent hebt die elke taal spreekt, nooit moe wordt en geen bezwaar heeft tegen repeterend werk.
Thunderbit vs. Playwright: Een Vergelijking
Laten we beide methodes naast elkaar leggen met het eBay-voorbeeld:
| Factor | Playwright (Code) | Thunderbit (AI, No-Code) |
|---|---|---|
| Installatietijd | 30+ minuten (installeren, coderen, debuggen) | Minder dan 5 minuten (extensie installeren, “AI Kolommen Voorspellen” aanklikken, dan “Scrapen”) |
| Benodigde kennis | Python, HTML/CSS-selectors, debugging | Geen – alleen basis webgebruik |
| Onderhoud | Handmatig (script aanpassen bij wijzigingen op eBay of anti-botmaatregelen) | Minimaal – AI past zich aan, sjablonen worden door Thunderbit bijgewerkt |
| Dynamische content & paginering | Zelf navigatie en wachttijden coderen | Automatisch geregeld door AI |
| Data verrijken | Zelf vertaling/sentimentanalyse coderen of externe API’s gebruiken | Ingebouwd – vertaling, categorisatie of sentimentanalyse direct in de interface |
| Exportmogelijkheden | Zelf CSV/JSON-export coderen of API’s gebruiken | Eén klik naar Excel, Google Sheets, Airtable, Notion |
| Schaalbaarheid | Kan met moeite (parallelle scripts, proxies), maar vraagt veel resources | Geschikt voor typische zakelijke volumes (honderden/duizenden records); zware taken in de cloud |
| Kosten | Gratis (open source), maar kost ontwikkeltijd en mogelijk proxyservices | Abonnement (vanaf ~$9–15/maand), gratis voor kleine taken |
Voor zakelijke gebruikers is het verschil enorm. Met Playwright ben je aan het programmeren, debuggen en onderhouden. Met Thunderbit klik je een paar keer en heb je direct gestructureerde data – inclusief vertaling en sentimentanalyse – zonder een regel code te schrijven.
Geavanceerde Data: Vertaling en Sentimentanalyse met Thunderbit
Hier blinkt Thunderbit echt uit voor zakelijke teams.
Stel, je wilt klantbeoordelingen van eBay-verkopers in verschillende talen analyseren. Met Playwright moet je:
- De reviews scrapen.
- Code schrijven om elke review naar een vertaal-API te sturen.
- Nog meer code schrijven voor sentimentanalyse (bijvoorbeeld via Google Cloud Natural Language).
- Alles samenvoegen in één spreadsheet.
Met Thunderbit hoef je alleen “Vertalen” en “Sentimentanalyse” aan te vinken. De AI doet de rest – vertaalt reviews, labelt ze als positief/negatief/neutraal en exporteert alles overzichtelijk.
Zakelijke voordelen:
- Wereldwijde marktinzichten: Vertaal direct productinformatie of reviews uit elke taal.
- Klantfeedback categoriseren: Zie trends en knelpunten in één oogopslag.
- Sneller beslissen: Direct bruikbare inzichten zonder gedoe met verschillende tools.
Wat vroeger een ontwikkelaar, data-analist en veel koffie kostte, is nu een kwestie van een paar klikken.
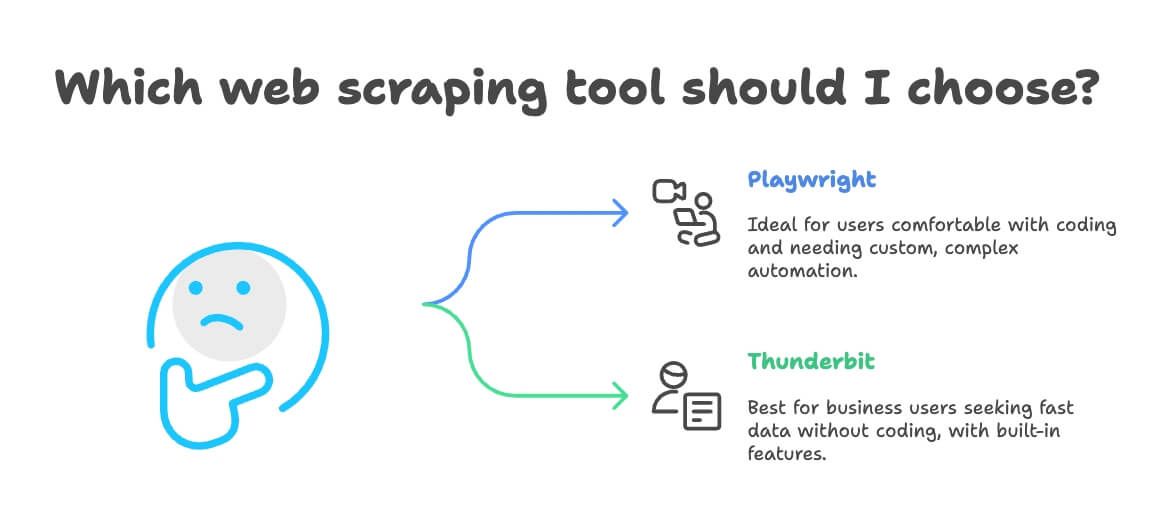
Wanneer Kies je voor Playwright of Thunderbit?
Eerlijk is eerlijk: er is geen universeel antwoord. Mijn advies:
Kies voor Playwright als:
- Jij (of je team) kunt programmeren.
- Je complexe, maatwerk automatisering nodig hebt (zoals inloggen, CAPTCHAs oplossen, koppelen aan interne systemen).
- Je maximale flexibiliteit en controle wilt.
- Je op grote schaal wilt scrapen of scraping wilt integreren in een groter softwareproject.
Kies voor Thunderbit als:
- Je als zakelijke gebruiker snel data wilt, zonder code.
- Je geen zin hebt in onderhoud of scriptproblemen.
- Je vertaling, sentimentanalyse of datastructurering direct nodig hebt.
- Je direct wilt exporteren naar Excel, Google Sheets, Airtable of Notion.
- Je use case typisch is voor sales, marketing, e-commerce of vastgoed (denk aan leadlijsten, prijsmonitoring, catalogusopbouw).
De meeste sales- en operationele teams die ik ken, willen gewoon data in een spreadsheet – geen programmeercertificaat. Thunderbit is voor hen gemaakt.
Samenvatting: Zo Maak je Webscraping Werkend voor Jouw Bedrijf
De Beste Webscraping Tools & Software van 2025 Get Started Free
Kort samengevat:
- Playwright is een krachtig, flexibel hulpmiddel voor webscraping en browserautomatisering. Ideaal voor technische gebruikers die volledige controle willen en kunnen programmeren.
- Thunderbit is een AI-gedreven, no-code webscraper voor zakelijke gebruikers. Snel, eenvoudig en regelt alles van data-extractie tot vertaling en sentimentanalyse in een paar klikken.
Ben je een ontwikkelaar die graag sleutelt? Dan is Playwright een geweldige tool. Maar zit je in sales, marketing of operations – en wil je vooral snel resultaat? Dan is Thunderbit de shortcut waar je op hebt gewacht.
Nieuwsgierig naar Thunderbit?
Je kunt gratis aan de slag met de Thunderbit Chrome-extensie, of meer lezen over de verschillen met andere tools op de Thunderbit Blog.
Probeer Thunderbit gratis op Chrome
Twijfel je nog? Onthoud: de beste tool is degene die je snel de juiste data oplevert, in het gewenste formaat, zonder dat het je hele middag (of je geduld) kost. Succes met webscrapen!
Meer tips over webscraping, AI en automatisering voor zakelijke gebruikers? Bekijk mijn andere gidsen op de Thunderbit Blog, zoals Wat is Data Scraping en Hoe Doe Je Het in 2025 en Amazon Producten en Reviews Scrapen in 2025 met AI.
Probeer AI-webscraper voor zakelijke gebruikers Get Started Free




