

Voor veel developers begint het avontuur met webscraping vaak uit pure nieuwsgierigheid en een simpel doel—bijvoorbeeld het binnenhalen van productdata van een concurrent. BeautifulSoup is meestal de eerste tool waar je tegenaan loopt, maar de start kan best overweldigend zijn. Na wat stoeien en proberen voelt het moment waarop pip install beautifulsoup4 eindelijk werkt en je een HTML-element—zoals een kopje—weet te pakken, als een echte mijlpaal. Voor veel beginnende Python-gebruikers is dit het moment waarop het kwartje valt en het zelfvertrouwen groeit.
Als je net begint met webscraping, is BeautifulSoup waarschijnlijk het eerste hulpmiddel waar je over hoort. En dat is niet voor niets: het is simpel, krachtig en al jarenlang dé standaardbibliotheek voor webscraping in Python. In deze gids laat ik je stap voor stap zien hoe je BeautifulSoup installeert met pip, geef ik je praktische codevoorbeelden en leg ik uit waarom deze tool nog steeds zo geliefd is bij developers en data-analisten. Maar ik ben ook eerlijk over de beperkingen van BeautifulSoup—en waarom steeds meer teams (vooral niet-programmeurs) overstappen op AI-gedreven tools zoals Thunderbit.
Wat is BeautifulSoup en Waarom Gebruiken Developers Het Nog Steeds?
BeautifulSoup vs. AI Web Scraper: Volledige Vergelijking Get Started Free
Laten we bij het begin beginnen: wat is BeautifulSoup nou eigenlijk? Zie het als een supertoegankelijke “HTML-parser” voor Python. Je voert er een stuk HTML of XML in, en het bouwt daar een overzichtelijke boomstructuur van die je makkelijk kunt doorzoeken, aanpassen en analyseren met Python-code. Het is alsof je röntgenogen krijgt voor webpagina’s—ineens zijn al die chaotische tags en attributen gestructureerde data.
Waarom is BeautifulSoup nog steeds zo populair?
Ondanks de opkomst van nieuwere scraping-frameworks, blijft BeautifulSoup de eerste keuze voor veel Python-beginners. Het wordt zelfs meer dan 150 miljoen keer per maand gedownload via PyPI. Dat is niet alleen hype—op Stack Overflow zijn er meer dan 32.000 vragen met het label “beautifulsoup”, wat betekent dat er een grote community en veel hulp is voor beginners.
Typische toepassingen:
- Productinformatie verzamelen van webshops (denk aan: namen, prijzen, reviews)
- Nieuws- of blogkoppen ophalen voor analyse of aggregatie
- Tabellen of overzichten parsen voor gestructureerde data (zoals bedrijvengidsen)
- Leads genereren door e-mails of telefoonnummers uit directories te halen
- Updates monitoren (zoals prijswijzigingen of nieuwe vacatures)
BeautifulSoup is vooral handig voor statische webpagina’s—sites waarbij de data direct in de HTML staat. Het is flexibel, vergeeft veel (ook bij rommelige HTML) en dwingt je niet in een strak keurslijf. Daarom is het, zelfs in 2025, nog steeds de “eerste liefde” van veel Python-scrapers (lees meer over de populariteit).
Pip Install BeautifulSoup: Zo Begin Je Snel
Wat is pip, en waarom zou je het gebruiken?
Als je nieuw bent met Python: pip is de pakketmanager waarmee je makkelijk bibliotheken installeert vanuit de Python Package Index (PyPI). Zie het als de App Store, maar dan voor Python-code. BeautifulSoup installeren met pip is de snelste en meest betrouwbare manier om te starten.
Tip: De juiste pakketnaam is beautifulsoup4 (dus niet alleen beautifulsoup). Voeg altijd de “4” toe voor de nieuwste versie.
Stap-voor-stap: BeautifulSoup Installeren
1. Check je Python-versie
BeautifulSoup vereist Python 3.7 of hoger. Check je versie in de terminal:
python --version
of
python3 --version
2. Installeer BeautifulSoup4 met pip
Open je terminal of opdrachtprompt en voer uit:
pip install beautifulsoup4
Heb je meerdere Python-versies? Gebruik dan:
pip3 install beautifulsoup4
Op Windows kun je ook gebruiken:
py -m pip install beautifulsoup4
3. (Optioneel, maar slim) Installeer een parser
BeautifulSoup werkt standaard met Python’s ingebouwde "html.parser", maar voor betere prestaties en nauwkeurigheid kun je lxml en html5lib installeren:
pip install lxml html5lib
4. (Optioneel) Installeer Requests
BeautifulSoup haalt zelf geen webpagina’s op—het verwerkt alleen HTML. De meeste mensen gebruiken de Requests bibliotheek om pagina’s te downloaden:
pip install requests
5. Check je installatie
Probeer het in Python:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Zie je <title>Example Domain</title>, dan zit je goed.
BeautifulSoup installeren in een virtuele omgeving
Ik raad altijd aan om een virtuele omgeving te gebruiken voor Python-projecten. Zo houd je je afhankelijkheden netjes gescheiden en voorkom je gedoe.
Zo maak je er een aan:
python -m venv venv
# Op Windows:
venv\Scripts\activate
# Op macOS/Linux:
source venv/bin/activate
pip install beautifulsoup4 requests lxml html5lib
Alles wat je nu installeert, blijft binnen deze projectmap. Geen gezeur meer met ontbrekende pakketten.
Alternatieve installatiemethoden (Conda, etc.)
Gebruik je Anaconda? Installeer BeautifulSoup dan met:
conda install beautifulsoup4
En voor de parser:
conda install lxml
Zorg dat je conda-omgeving actief is voordat je installeert.
BeautifulSoup Python: Eerste Stappen met Codevoorbeelden
Tijd om aan de slag te gaan. Zo gebruik je BeautifulSoup in een echt Python-script.
Voorbeeld 1: Een webpagina ophalen en de titel pakken
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Haal de paginatitel op
title_text = soup.title.string
print("Page title:", title_text)
Dit script haalt de Wikipedia-pagina voor Python op, verwerkt de HTML en print de titel. Lekker simpel toch?
Voorbeeld 2: Alle hyperlinks pakken
links = soup.find_all('a')
for link in links[:10]: # Toon de eerste 10 links
href = link.get('href')
text = link.get_text()
print(f"{text}: {href}")
Hiermee print je de tekst en URL van de eerste 10 links op de pagina.
Voorbeeld 3: Koppen extraheren
headings = soup.find_all('h2')
for h in headings:
print(h.get_text().strip())
Wil je alle <h2>-koppen? Dit is alles wat je nodig hebt.
Voorbeeld 4: CSS-selectors gebruiken
items = soup.select("ul.menu > li")
for item in items:
print(item.get_text())
Met de select()-methode kun je gewoon CSS-selectors gebruiken zoals je gewend bent.
Voorbeeld 5: Attributen en geneste tags ophalen
first_link = soup.find('a')
print(first_link['href']) # Directe toegang (geeft error als ontbreekt)
print(first_link.get('href')) # Veilige toegang (geeft None als ontbreekt)
Voorbeeld 6: Alle tekst extraheren
text_content = soup.get_text()
print(text_content)
Hiermee haal je alle tekst van de pagina op—handig voor snelle analyses.
Veelvoorkomende BeautifulSoup-taken voor beginners
Dit zijn de meest gebruikte handelingen met BeautifulSoup:
-
Eén element vinden:
soup.find('div', class_='price') -
Alle elementen vinden:
soup.find_all('p', class_='description') -
Tekstinhoud ophalen:
element.get_text() -
Een attribuutwaarde ophalen:
element.get('href') -
CSS-selectors gebruiken:
soup.select('table.data > tr') -
Omgaan met ontbrekende elementen:
price = soup.find('span', class_='price') if price: print(price.get_text())
De syntax is lekker leesbaar, vriendelijk voor beginners en vergeeft veel—zelfs als de HTML een rommeltje is (zie de documentatie).
De Beperkingen van BeautifulSoup voor Moderne Webscraping
Laten we ook eerlijk zijn over de nadelen. BeautifulSoup is top voor statische pagina’s en kleine projecten, maar het heeft zijn grenzen.
Dit zijn de grootste struikelblokken:
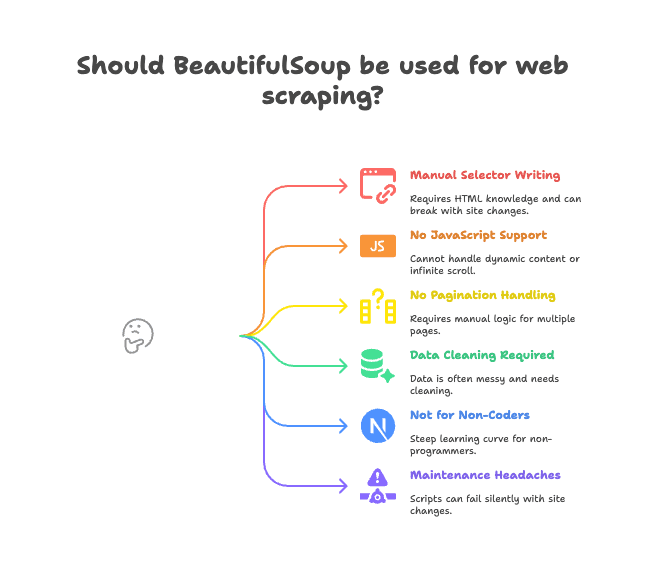
- Handmatig selectors schrijven: Je moet zelf de juiste HTML-tags en klassen vinden. Als de site verandert, werkt je script niet meer.
- Geen JavaScript-ondersteuning: BeautifulSoup ziet alleen de HTML die de server stuurt. Wordt data via JavaScript geladen (zoals bij oneindig scrollen of dynamische content), dan zie je die niet (meer info).
- Geen ingebouwde paginering of subpagina’s: Wil je meerdere pagina’s scrapen of doorklikken naar details? Dan moet je zelf alle logica schrijven.
- Data opschonen vereist: De data die je krijgt is vaak rommelig—extra spaties, vreemde tekens, inconsistente formaten.
- Niet geschikt voor niet-programmeurs: Werk je in sales, marketing of operations en kun je niet coderen? Dan is BeautifulSoup een flinke uitdaging.
- Onderhoudsproblemen: Als de website zijn structuur aanpast, kan je script stilletjes falen of data missen.
Voor veel teams zorgen deze “kleine” issues voor flinke vertragingen. Ik heb projecten zien vastlopen omdat de scraping-scripts steeds aangepast moesten worden.
Waarom Steeds Meer Teams Kiezen voor Thunderbit bij Webdata Extractie
Probeer Thunderbit AI Webscraper Scrape elke website met AI. Geen code nodig. Get Started Free
Wat is het alternatief? Hier komt Thunderbit om de hoek kijken. Thunderbit is geen Python-bibliotheek, maar een Chrome-extensie die fungeert als een AI-gedreven webdata-assistent.
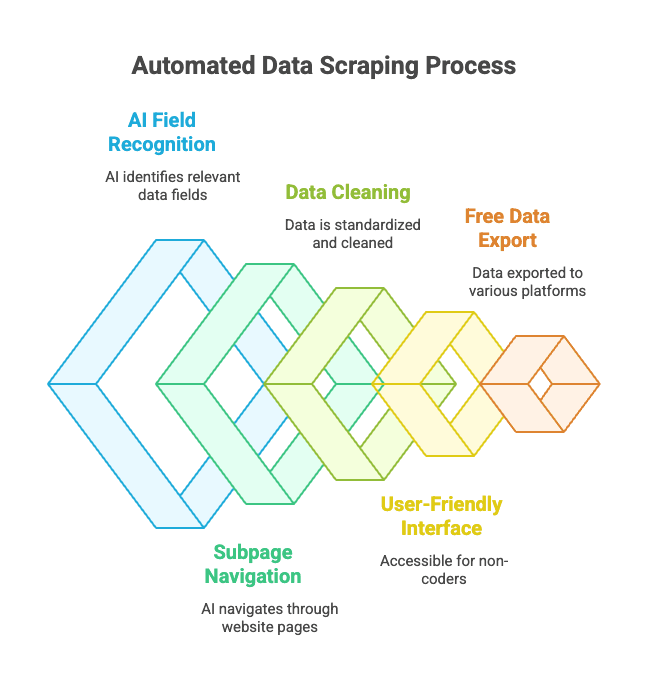
Hoe werkt het?
- Je opent de website die je wilt scrapen.
- Klik op “AI Velden Voorspellen”—Thunderbit’s AI leest de pagina en stelt automatisch de juiste kolommen voor (zoals “Productnaam”, “Prijs”, “Locatie”).
- Je kunt de kolomnamen en types aanpassen als je wilt.
- Klik op “Scrapen” en Thunderbit verzamelt, schoont en structureert de data voor je.
- Exporteer met één klik naar Excel, Google Sheets, Notion, Airtable of je favoriete tool.
Geen code. Geen selectors. Geen onderhoudsproblemen.
De sterke punten van Thunderbit:
- AI-gedreven veldherkenning: De AI herkent automatisch de relevante data, zelfs bij rommelige HTML.
- Subpagina’s en paginering: Thunderbit kan automatisch doorklikken naar productpagina’s of “volgende pagina” links volgen.
- Data opschonen en formatteren: Telefoonnummers, e-mails, afbeeldingen en meer worden direct gestandaardiseerd.
- Gebruiksvriendelijk voor niet-programmeurs: Iedereen die een browser kan gebruiken, kan met Thunderbit aan de slag.
- Gratis data-export: Exporteer naar Excel, Google Sheets, Airtable, Notion—zonder betaalmuur voor basisexports.
- Geplande scraping: Stel scraping-taken in op schema en laat Thunderbit het werk doen.
Voor zakelijke gebruikers verandert dit de manier waarop webdata wordt verzameld compleet. In plaats van te worstelen met Python-scripts, wijs je gewoon aan wat je wilt en krijg je direct je data.
Probeer Thunderbit AI Webscraper Gratis
Thunderbit vs. BeautifulSoup: Welke Past bij Jou?
Hier een overzicht:
| Functie | BeautifulSoup (Python Code) | Thunderbit (No-Code AI) |
|---|---|---|
| Installatie | Vereist Python, pip, code | Chrome-extensie, 2 klikken |
| Snelheid naar data | Uren voor eerste script | Minuten per site |
| JavaScript-ondersteuning | Nee (extra tools nodig) | Ja (werkt in browser) |
| Paginering/Subpagina’s | Handmatig coderen | Ingebouwd, aan/uit te zetten |
| Data opschonen | Handmatig coderen | AI-gestuurd, automatisch |
| Exportopties | Zelf CSV/Excel schrijven | Eén klik naar Sheets, Notion, etc. |
| Ideaal voor | Ontwikkelaars, hobbyisten | Zakelijke gebruikers, niet-programmeurs |
| Kosten | Gratis (maar kost tijd) | Freemium (gratis voor kleine taken) |
Wanneer kies je voor BeautifulSoup:
- Je bent vertrouwd met Python en wilt volledige controle.
- Je werkt met statische sites of hebt maatwerk nodig.
- Je wilt scraping integreren in een groter Python-project.
Wanneer kies je voor Thunderbit:
- Je wilt snel resultaat, zonder code.
- Je moet dynamische (JavaScript) sites scrapen.
- Je werkt in sales, marketing, operations of wilt gewoon geen code schrijven.
- Je wilt data direct exporteren naar je favoriete tools.
Zelfs als developer gebruik ik Thunderbit soms als ik snel wat data nodig heb zonder een heel Python-project op te tuigen. Het voelt als een superkracht in je browser.
Best Practices voor het Installeren en Gebruiken van BeautifulSoup
Blijf je bij BeautifulSoup? Hier mijn beste tips voor een soepele ervaring:
- Gebruik altijd een virtuele omgeving: Houd je afhankelijkheden schoon en voorkom “het werkt alleen op mijn computer”-problemen.
- Houd pip en je pakketten up-to-date: Voer regelmatig
pip install --upgrade pipenpip list --outdateduit. - Installeer aanbevolen parsers:
pip install lxml html5libvoor betere prestaties en stabiliteit. - Schrijf modulaire code: Scheid het ophalen en parsen van data voor makkelijker debuggen.
- Respecteer robots.txt en limieten: Belast websites niet te zwaar—gebruik
time.sleep()tussen verzoeken. - Gebruik duidelijke, maar stabiele selectors: Vermijd te specifieke paden die snel breken.
- Test parsing op opgeslagen HTML: Download een pagina en test je code offline om herhaalde verzoeken te voorkomen.
- Maak gebruik van de community: Stack Overflow is je beste vriend bij problemen.
Problemen met BeautifulSoup Installatie Oplossen
Loop je vast? Hier een snelle checklist:
- “ModuleNotFoundError: No module named bs4”
- Heb je
beautifulsoup4in de juiste omgeving geïnstalleerd? Probeerpython -m pip install beautifulsoup4.
- Heb je
- Verkeerd pakket geïnstalleerd (
beautifulsoupin plaats vanbeautifulsoup4)- Verwijder de oude:
pip uninstall beautifulsoup - Installeer de juiste:
pip install beautifulsoup4
- Verwijder de oude:
- Parser-waarschuwingen of Unicode-fouten
- Installeer
lxmlenhtml5lib, en geef de parser op:BeautifulSoup(html, "lxml")
- Installeer
- Elementen niet gevonden
- Wordt de data via JavaScript geladen? BeautifulSoup ziet die niet. Check de broncode van de pagina, niet de weergegeven DOM in de browser.
- Pip-fouten of rechtenproblemen
- Gebruik een virtuele omgeving, of probeer
pip install --user beautifulsoup4 - Update pip:
pip install --upgrade pip
- Gebruik een virtuele omgeving, of probeer
- Conda-problemen
- Probeer
conda install beautifulsoup4of gebruik pip binnen je conda-omgeving.
- Probeer
Nog steeds problemen? De documentatie van BeautifulSoup en Stack Overflow behandelen vrijwel elk scenario.
Samenvatting: Belangrijkste Punten voor BeautifulSoup Installeren en Gebruiken
-
BeautifulSoup is de populairste Python-bibliotheek voor webscraping—eenvoudig, flexibel en ideaal voor beginners.
-
Installeer met pip:
pip install beautifulsoup4 lxml html5lib requests -
Gebruik een virtuele omgeving voor een schone setup.
-
BeautifulSoup is perfect voor statische pagina’s en kleine projecten, maar minder geschikt voor JavaScript, paginering en onderhoud.
-
Thunderbit is het moderne, AI-gedreven alternatief voor zakelijke gebruikers en niet-programmeurs—geen code, geen gedoe, gewoon data.
-
Kies het juiste gereedschap voor jouw situatie:
- Developers en hobbyisten: BeautifulSoup geeft je controle.
- Zakelijke gebruikers en teams: Thunderbit levert snel resultaat.
Probeer beide methodes—soms is de beste oplossing degene die het snelst werkt.
Probeer Thunderbit AI Webscraper Gratis Get Started Free
Veelgestelde Vragen: Pip Install BeautifulSoup en Meer
Vraag: Wat is het verschil tussen beautifulsoup en beautifulsoup4?
Antwoord: Installeer altijd beautifulsoup4—dat is de nieuwste, ondersteunde versie. Het oude beautifulsoup-pakket is verouderd en werkt niet met Python 3. Je importeert het als from bs4 import BeautifulSoup (meer info).
Vraag: Moet ik lxml of html5lib installeren bij BeautifulSoup?
Antwoord: Niet verplicht, maar sterk aanbevolen. Ze maken het parsen sneller en robuuster. Installeer met pip install lxml html5lib (waarom het belangrijk is).
Vraag: Kan BeautifulSoup omgaan met websites die veel JavaScript gebruiken?
Antwoord: Nee—BeautifulSoup ziet alleen de statische HTML. Voor JavaScript-content kun je browserautomatiseringstools zoals Selenium gebruiken, of een AI-gedreven browsertool zoals Thunderbit (meer info).
Vraag: Hoe verwijder ik BeautifulSoup?
Antwoord: Voer pip uninstall beautifulsoup4 uit in je terminal (stap-voor-stap).
Vraag: Is Thunderbit gratis te gebruiken?
Antwoord: Thunderbit werkt met een freemium-model—gratis voor kleine taken, betaalde abonnementen voor grotere volumes of geavanceerde functies. Je kunt het direct gratis proberen in je browser (prijzen).
Benieuwd hoe Thunderbit zich in de praktijk verhoudt tot BeautifulSoup? Bekijk onze uitgebreide vergelijking. Wil je meer leren over webscraping? Lees dan ook onze gidsen over wat is data scraping en hoe je Amazon-producten en -reviews kunt scrapen.
Veel succes met scrapen—en onthoud: of je nu een Python-expert bent of gewoon snel data in een spreadsheet wilt, er is altijd een tool (en community) die je verder helpt.




