Laat ik het zo zeggen: als ik een euro kreeg voor elke keer dat iemand me een PDF stuurde vol “belangrijke data” en verwachtte dat ik die op magische wijze in een spreadsheet veranderde, dan had ik waarschijnlijk genoeg voor een leven lang koffie — en misschien nog een paar extra Chrome-extensies. PDF’s zijn overal: verkoopcontracten, productcatalogi, onderzoeksrapporten, facturen, noem maar op. Maar zodra je die data écht wilt gebruiken? Dan begint het pas leuk te worden (lees: hoofdpijn).
Ik heb het allemaal meegemaakt — kopiëren, plakken, opnieuw opmaken, en soms gewoon opgeven als de opmaak compleet ontspoorde of afbeeldingen en links spoorloos verdwenen. Maar er is goed nieuws: de wereld van PDF-scraping is enorm veranderd, vooral door de opkomst van AI-tools. Ben je het zat om urenlang cijfers over te typen of gek te worden van kapotte tabellen? Dan zit je hier goed. Duiken we in de wereld van PDF scraping, waarom het ertoe doet, en hoe tools zoals het eindelijk pijnloos maken.
Wat is PDF scraping? De basis van gegevens extraheren uit PDF’s begrijpen
Laten we simpel beginnen: PDF scraping is eigenlijk een nette manier om te zeggen: “gestructureerde data automatisch uit PDF-bestanden halen.” Een PDF-scraper is een tool (software, extensie of dienst) die de informatie eruit trekt waar jij om geeft — tekst, tabellen, afbeeldingen, links, noem maar op — en die omzet naar een formaat dat je echt kunt gebruiken, zoals Excel, Google Spreadsheets of een database.
Maar hier zit het addertje onder het gras: PDF’s lijken niet op webpagina’s of Excel-bestanden. Ze zijn meer als digitale afdrukken, ontworpen om er overal hetzelfde uit te zien, niet om makkelijk door een computer uit elkaar gehaald te worden. Sommige PDF’s bevatten selecteerbare tekst, andere zijn gewoon gescande afbeeldingen (waar OCR — optische tekenherkenning — voor nodig is), en de opmaak kan alle kanten op gaan. Een PDF scrapen draait dus niet alleen om tekst kopiëren — het gaat om het ontcijferen van een puzzel van lay-outs, lettertypes en soms zelfs verborgen metadata.
Wat kun je uit een PDF halen?
- Gewone tekst (alinea’s, koppen, enz.)
- Tabellen (denk aan: financiële cijfers, productspecificaties, enquêtegegevens)
- Afbeeldingen en grafische elementen (grafieken, logo’s, gescande handtekeningen)
- Hyperlinks en verwijzingen (ingesloten URL’s, citaties)
- Formuliergegevens (velden uit invulformulieren)
- Metadata (auteur, titel, aanmaakdatum, tags)
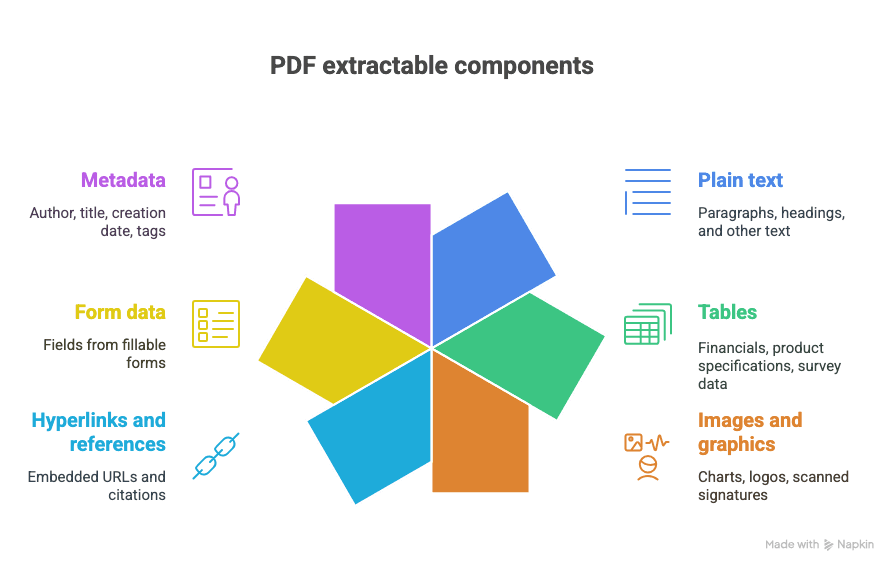
En ja, soms zit dat allemaal vrolijk door elkaar in één heerlijk chaotisch document.
Waarom PDF scraping belangrijk is: praktische use cases en zakelijke voordelen
Waarom zou je überhaupt PDF’s scrapen? Omdat iedereen ze gebruikt, en de data erin vaak cruciaal is voor bedrijven. Hier komt PDF scraping echt tot zijn recht:
| Use case | Handmatig werk | Met een PDF-scraper | Tijds- en foutbesparing |
|---|---|---|---|
| Sales leads extraheren | Urenlang contactgegevens kopiëren uit offertes of event-PDF’s, risico op gemiste leads | Haalt meteen alle leads in een spreadsheet | 80–90% sneller, minder fouten |
| Productdata voor e-commerce | Dagenlang productspecificaties invoeren uit leveranciers-PDF’s, opmaakdrama’s | Bulk-extractie naar CSV of Sheets | 95%+ tijd bespaard, consistente data |
| Analyseren van onderzoeksgegevens | Wekenlang tabellen overtikken uit academische papers, groot risico op typefouten | Extraheert tabellen, referenties en zelfs gescande tekst | 80% tijd bespaard, hogere nauwkeurigheid |
Laten we er wat cijfers aan hangen:
- worden elk jaar gemaakt.
- gebruikt PDF als primair formaat om informatie te delen.
- Handmatige digitale administratie (zoals data-invoer uit PDF’s) slokt op.
- Geautomatiseerde tools kunnen foutpercentages verlagen van .
Werk je in sales, e-commerce of research? Dan is het automatiseren van PDF-data-extractie niet zomaar een leuke extra — het is een concurrentievoordeel.
Traditionele methoden voor PDF-scraping: uitdagingen en beperkingen
Laten we eerlijk zijn: de oude manieren om data uit PDF’s te halen zijn… niet geweldig. Dit is wat de meesten van ons hebben geprobeerd (en waarom het zo frustrerend is):

1. Handmatig kopiëren en plakken
- Pijnpunten: Opmaak raakt verknald, tabellen worden een puinhoop, afbeeldingen en links verdwijnen, en jij zit met een migraine.
- Arbeidskosten: Hoog. Heb je 5.000 PDF’s, en doe je er zelfs maar 1 minuut per stuk over? Dan ben je 80+ uur van je leven kwijt die je nooit meer terugziet.
- Foutpercentage: 5–10%. Typefouten, gemiste rijen, per ongeluk verwijderen — been there, done that.
2. Omzetten naar Word/Excel en daarna opschonen
- Pijnpunten: Soms werkt het voor eenvoudige documenten, maar complexe lay-outs of tabellen raken in de war. Je moet de rommel daarna nog steeds opschonen.
- Afbeeldingen/links: Meestal gaan die onderweg verloren.
- Gerichte extractie: Vergeet het maar — je krijgt het hele document, niet alleen wat je nodig hebt.
3. Aangepaste scripts (Python, enz.)
- Pijnpunten: Je moet kunnen coderen (of iemand paraat hebben die dat kan). Elk nieuw PDF-formaat betekent dat je het script moet aanpassen. Gescande PDF’s? Succes ermee.
- Onderhoud: Hoog. Zodra een leverancier zijn factuursjabloon wijzigt, breekt je script.
- Schaalbaarheid: Niet voor watjes — of niet-technische teams.
4. Online converters
- Pijnpunten: Handig voor een losse klus, maar je moet gevoelige documenten uploaden naar een server van een derde partij (hallo, compliance-problemen). Beperkte controle over wat er precies wordt geëxtraheerd.
- Opmaak: Wisselend. Soms besteed je meer tijd aan opschonen dan je hebt gewonnen.
Kort gezegd: traditionele methoden zijn traag, foutgevoelig en schalen slecht. Daarom leven zoveel teams er maar gewoon mee — tegen een enorme prijs in productiviteit.
Moderne oplossingen voor PDF-scraping: van code tot no-code tools
Gelukkig zitten we niet meer vast in de donkere middeleeuwen. Het aanbod is flink uitgebreid met slimmere, snellere en gebruiksvriendelijkere PDF-scrapingopties.
1. Coding libraries (voor ontwikkelaars)
- Voorbeelden: , , .
- Sterktes: Superflexibel, kan worden geautomatiseerd voor grote batches, gratis (open source).
- Zwaktes: Veel insteltijd, programmeerkennis nodig, fragiel (breekt bij nieuwe formaten), beperkte OCR-/afbeeldingsondersteuning.
2. Online PDF-converters
- Voorbeelden: , , .
- Sterktes: Geen installatie nodig, makkelijk voor niet-techneuten, snel voor kleine klussen.
- Zwaktes: Beperkte aanpasbaarheid, privacyzorgen, opmaakfouten, bestands- en paginalimieten.
3. AI-aangedreven PDF-scrapers
- Voorbeelden: , Nanonets, Docparser.
- Sterktes: Geen code nodig, verwerkt tekst/tabellen/afbeeldingen/links, AI stelt voor wat je kunt extraheren, ondersteunt batchtaken, integreert met Sheets/Notion/Airtable.
- Zwaktes: Sommige hebben limieten op credits/pagina’s, internetverbinding kan nodig zijn, soms een kleine leercurve voor complexe documenten.
PDF-scrapingtools vergelijken: welke aanpak past bij jou?
| Tool/methode | Instelling | Het beste voor | Extraheert | Aanpasbaar? | Kosten |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Gemiddeld (UI/coding) | Tabellen in PDF’s | Tabellen | Enigszins | Gratis |
| PDFMiner | Codering vereist | Tekstrijke PDF’s | Tekst | Ja (code) | Gratis |
| PyPDF2 | Codering vereist | Eenvoudige tekst/metadata | Tekst, metadata | Ja (code) | Gratis |
| Smallpdf/online conv. | Geen (webgebaseerd) | Snelle conversies | Hele document (Word/Excel) | Nee | Freemium |
| Thunderbit | Installatie in 2 klikken | Zakelijke gebruikers, teams | Tekst, tabellen, afbeeldingen, links | Ja (AI-prompts) | Freemium ($16,5/maand voor Pro) |
Maak kennis met Thunderbit: de AI PDF-scraper Chrome-extensie
Laten we het nu hebben over de tool die mijn leven — en dat van heel wat zakelijke gebruikers — een stuk makkelijker heeft gemaakt: .
Wat maakt Thunderbit anders?
- Extractie in 2 klikken: Open een PDF in Chrome, klik op de Thunderbit-extensie en laat AI de rest doen.
- AI-gestuurde veldsuggesties: Thunderbit’s “AI Suggest Fields” leest je PDF en stelt de kolommen voor die je waarschijnlijk wilt (zoals “Naam,” “E-mail,” “Prijs,” enz.).
- Verwerkt afbeeldingen, links en tabellen: Niet alleen gewone tekst — Thunderbit kan afbeeldingen en hyperlinks eruit halen en zelfs OCR draaien op gescande documenten.
- Aangepaste prompts: Alleen telefoonnummers of productspecificaties nodig? Voeg een aangepaste instructie toe en Thunderbit richt zich precies daarop.
- Exporteert overal naartoe: Stuur je data direct naar Excel, Google Spreadsheets, Airtable of Notion. Geen CSV-gedoe meer.
- Batch- en subpage scraping: Een lijst met PDF’s of links? Thunderbit kan ze allemaal in één keer verwerken.
- Betrouwbaarheid op bedrijfsniveau: Ontworpen voor nauwkeurigheid, privacy en echte workflows.
Kortom: het is alsof je een digitale stagiair hebt die data-invoer daadwerkelijk leuk vindt (en nooit moe wordt).
Hoe je met Thunderbit data uit een PDF haalt: stap-voor-stap handleiding
Klaar om te zien hoe makkelijk het kan zijn? Zo gebruik ik Thunderbit om PDF’s om te zetten in gestructureerde, bruikbare data:
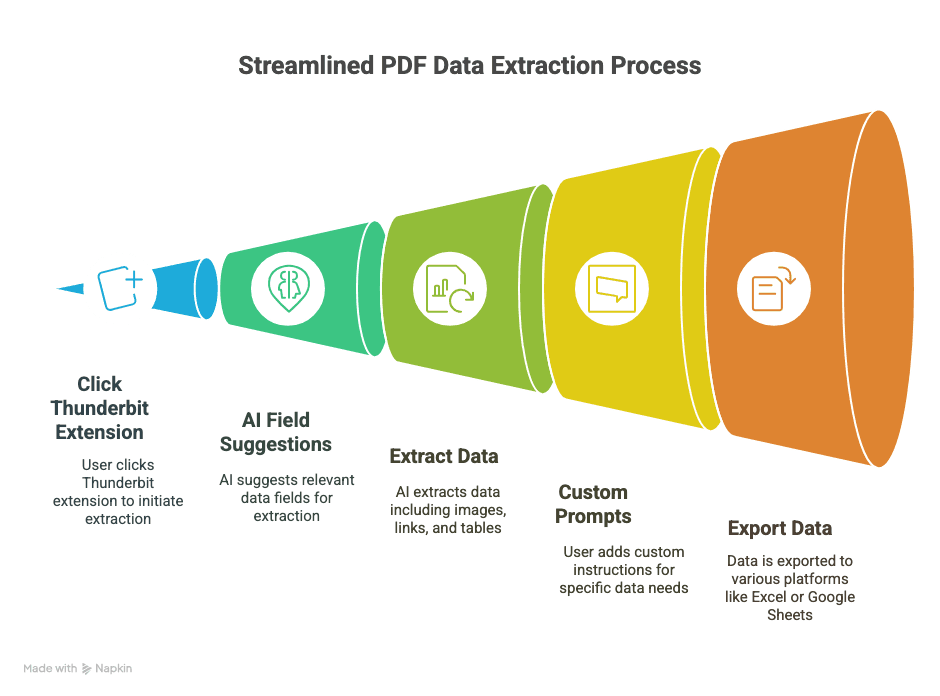
1. Installeer Thunderbit
- Download de .
- Meld je aan (met Google of e-mail — kost maar een paar seconden).
2. Open je PDF in Chrome
- Open een PDF via een web链接 of sleep een lokale PDF naar een Chrome-tab.
3. Start Thunderbit op de PDF
- Klik op het Thunderbit-pictogram in je browserwerkbalk.
- Selecteer “AI Web Scraper” — Thunderbit herkent de PDF en maakt zich klaar om aan de slag te gaan.
4. Laat AI velden voorstellen
- Klik op “AI Suggest Columns.”
- Thunderbit’s AI scant de PDF en beveelt kolommen aan (zoals “Datum,” “Bedrag,” “Contactnaam,” enz.).
- Bekijk de geëxtraheerde data direct in een tabel in de extensie.
5. Pas aan als dat nodig is
- Hernoem kolommen, verwijder extra velden of voeg je eigen toe (bijv. “Garantietermijn” of “Product-URL”).
- Voor lastige data kun je tekst in de PDF selecteren om de AI te trainen op wat je precies wilt.
6. Kies je exportformaat
- Kies uit CSV, Google Sheets, Airtable of Notion.
- Geef Thunderbit toestemming om verbinding te maken (eenmalige installatie).
7. Scrapen en exporteren
- Klik op “Scrape” of “Export.”
- Thunderbit verwerkt de PDF en stuurt de data naar waar jij wilt — meestal binnen enkele seconden.
Dat is alles. Geen code, geen kopieer-plakwerk, geen drama.
Tips voor nauwkeurige PDF-data-extractie met Thunderbit
- Controleer AI-voorgestelde velden: De AI is slim, maar een snelle check zorgt ervoor dat je precies krijgt wat je nodig hebt.
- Pak complexe tabellen aan: Gebruik bij tabellen over meerdere pagina’s of vreemd opgemaakte tabellen de preview om problemen te zien en kolommen waar nodig aan te passen.
- Extraheer afbeeldingen/links: Zorg dat je deze velden opneemt als je PDF ze bevat — Thunderbit kan ze ook ophalen.
- Gescande PDF’s: Thunderbit’s ingebouwde OCR is sterk, maar hoe schoner de scan, hoe beter het resultaat.
- Aangepaste prompts: Wil je alleen e-mails of telefoonnummers? Voeg een prompt toe zoals “Extraheer alle e-mailadressen” en Thunderbit focust daarop.
Geavanceerd PDF-scraping: afbeeldingen, links en aangepaste data extraheren
Thunderbit draait niet alleen om gewone tekst. Zo haal je nog meer uit je PDF’s:
- Afbeeldingen: Extraheer logo’s, grafieken of andere ingesloten visuals. Thunderbit kan zelfs de tekst in afbeeldingen OCR’en.
- Hyperlinks: Haal alle URL’s of verwijzingen eruit — ideaal voor onderzoeksrapporten of cv’s.
- Aangepaste gegevenstypen: Gebruik AI-prompts om precies te extraheren wat je nodig hebt (bijv. “Vind alle product-SKU’s en hun prijzen”).
- Samenvattingen en categorisering: Voeg een kolom toe en laat Thunderbit een sectie samenvatten of data direct categoriseren.
Data uit PDF analyseren voor specifieke zakelijke behoeften
- Sales: Extraheer alleen contactgegevens uit een batch offertes.
- E-commerce: Haal productspecificaties, prijzen en afbeeldingen uit leverancierscatalogi.
- Research: Pak tabellen en referenties, en genereer zelfs samenvattingen uit academische papers.
En zodra je de data hebt, kun je die structureren voor makkelijke analyse in Excel, Google Sheets of Notion — Thunderbit doet het zware werk, jij hoeft alleen nog maar de resultaten te gebruiken.
Je PDF-data exporteren en gebruiken: van extractie naar actie
De data eruit krijgen is nog maar het begin. Zo maak je er iets nuttigs van:
- Exportopties: CSV, Excel, Google Sheets, Airtable, Notion — kies wat je prettig vindt.
- Opmaak tips: Gebruik Thunderbit’s kolomtype-instellingen (getal, datum, tekst) voor schone, analyseklare data.
- Workflow-integratie: Koppel je geëxporteerde data aan CRM’s, voorraadsystemen of analytics-dashboards.
- Samenwerken: Deel Google Sheets of Airtable-bases met je team — iedereen werkt vanuit dezelfde, actuele data.
Het mooiste? Geen spreadsheets meer heen en weer mailen of je afvragen of je een rij hebt gemist.
Veelvoorkomende valkuilen bij PDF-scraping en hoe je ze vermijdt
Zelfs met de beste tools kunnen er haken en ogen opduiken. Dit heb ik geleerd — soms op de harde manier:
- OCR-fouten: Wazige scans of rare lettertypes kunnen zelfs de beste OCR in de war brengen. Gebruik waar mogelijk de schoonste PDF’s en controleer belangrijke velden dubbel.
- Complexe lay-outs: Tabellen met meerdere kolommen of geneste tabellen hebben soms wat handmatige sturing nodig — gebruik Thunderbit’s handmatige selectie of prompts.
- Gegevenstypen: Getallen met komma’s of data in vreemde notaties? Stel het kolomtype in vóór het exporteren, of maak het schoon in Excel/Sheets.
- Bestands- en paginalimieten: Enorme PDF’s? Splits ze op in kleinere stukken, of gebruik Thunderbit’s cloudmodus voor batchtaken.
- AI-“hallucinatie”: Zeldzaam, maar soms raadt AI een kolomnaam of vult ontbrekende data aan. Controleer de output altijd even steekproefsgewijs, vooral bij belangrijke cijfers.
- Handmatige review: Voor mission-critical data is een snelle validatie altijd slim — geautomatiseerde tools zijn accuraat, maar een menselijk oog doet nooit kwaad.
En als je vastloopt, staan Thunderbit’s support en community klaar om te helpen.
Conclusie en belangrijkste inzichten: PDF scraping laten werken voor je bedrijf
Laten we afronden. Data uit PDF’s halen was vroeger een nachtmerrie — traag, foutgevoelig en gewoon tijdrovend. Maar met moderne tools zoals is het nu snel, nauwkeurig en — durf ik het te zeggen — bijna leuk.
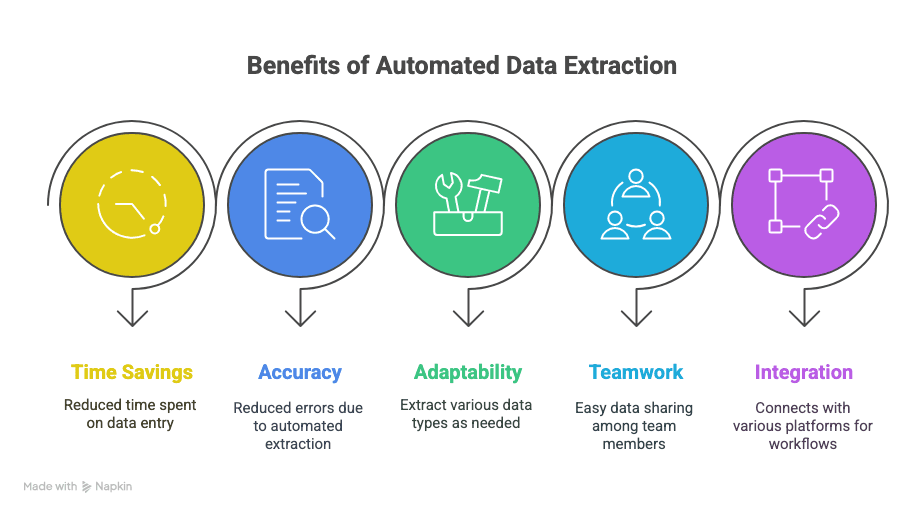
Dit krijg je ervoor terug:
- Tijd terug: Uren (of zelfs weken) bespaard op handmatige data-invoer.
- Minder fouten: Geautomatiseerde extractie betekent minder typefouten en gemiste rijen.
- Flexibiliteit: Extraheer precies wat je nodig hebt — tekst, tabellen, afbeeldingen, links, noem maar op.
- Samenwerking: Deel data direct met je team, waar ze ook zijn.
- Slimmere workflows: Integreer met Sheets, Notion, Airtable en meer.
Klaar om het zelf te proberen? Download de , laat hem los op je volgende PDF en ervaar hoe veel makkelijker het leven kan zijn. Je toekomstige zelf (en je carpaal tunnelsyndroom) zullen je dankbaar zijn.
Voor meer tips en handleidingen, bekijk de of ga dieper met .
Laten we die PDF-hoofdpijnen omzetten in productiviteitswinst — klik voor klik.
Shuai Guan, medeoprichter & CEO, Thunderbit