

Het web is in 2026 een wilde plek — inmiddels komt de helft van al het internetverkeer van bots, en open-source webcrawlers zijn de onzichtbare helden achter de schermen. Ze maken van alles mogelijk, van prijsbewaking tot AI-training. Ik werk al jaren in SaaS en automatisering, en als ik één ding heb geleerd, is het dit: de juiste zelfgehoste crawler kiezen kan je team maanden frustratie besparen, en misschien ook een paar late-night debug-sessies. Of je nu een handvol productpagina’s scraped of miljoenen URL’s crawlt voor onderzoek, de open-source Firecrawl-alternatieven in deze lijst dekken je behoeften af — ongeacht je schaal, tech stack of tolerantie voor complexiteit.
Maar hier zit de twist: er is geen one-size-fits-all-oplossing. Sommige teams hebben de brute kracht van Scrapy of de archiveringskracht van Heritrix nodig, terwijl anderen de onderhoudslast van open-source libraries gewoon te hoog vinden. Dus laten we de top 9 open-source Firecrawl-alternatieven voor 2026 doornemen, laten zien waar elk van hen in uitblinkt, en je helpen de juiste tool aan je zakelijke behoeften te koppelen — zonder de pijn van trial-and-error.
Hoe kies je het beste open-source Firecrawl-alternatief voor jouw bedrijf
Voordat je in de lijst duikt, eerst even over strategie. Het landschap van open-source webcrawling is diverser dan ooit, en je keuze zou moeten afhangen van een paar belangrijke factoren:
- Gebruiksgemak: Wil je een point-and-click-interface, of vind je het prima om Python, Go of JavaScript te schrijven?
- Schaalbaarheid: Scrape je één site, of moet je miljoenen pagina’s over honderden domeinen crawlen?
- Type content: Is je doelsite statische HTML, of leunt die zwaar op JavaScript en dynamische loading?
- Integratiebehoeften: Hoe wil je de data gebruiken — exporteren naar Excel, in een database zetten, of doorsturen naar een analytics-pijplijn?
- Onderhoud: Heb je de middelen om custom code te onderhouden, of wil je een tool die zich automatisch aan sitewijzigingen aanpast?
Hier is een snelle cheat sheet om je te helpen kiezen:
| Scenario | Beste tool(s) |
|---|---|
| No-code, offline browsen | HTTrack |
| Grootschalige crawl over meerdere domeinen | Scrapy, Apache Nutch, StormCrawler |
| Dynamische sites / zwaar op JS | Puppeteer |
| Formulierautomatisering / login vereist | MechanicalSoup |
| Statische site downloaden / archiveren | Wget, HTTrack, Heritrix |
| Go-ontwikkelaar, hoge prestaties | Colly |
Laten we nu in de top 9 open-source Firecrawl-alternatieven voor 2026 duiken.
1. Scrapy: het beste voor grootschalig crawlen met Python

Scrapy is de zwaargewichtkampioen onder de open-source webcrawlers. Gebouwd in Python is het hét framework voor ontwikkelaars die op schaal willen crawlen — denk aan miljoenen pagina’s, frequente updates en complexe sitelogica.
Waarom Scrapy?
- Enorme schaal: Scrapy kan duizenden requests per seconde verwerken en wordt gebruikt door bedrijven die miljarden pagina’s per maand scrapen (Zyte).
- Uitbreidbaar en modulair: Schrijf custom spiders, plug middleware in voor proxies, handel logins af en voer output naar JSON, CSV of databases.
- Actieve community: Tientallen plugins, documentatie en Stack Overflow-antwoorden.
- Beproefd in productie: Wereldwijd gebruikt door e-commerce-, nieuws- en onderzoeksteams.
Beperkingen: Een steile leercurve voor niet-ontwikkelaars, en je moet je spiders onderhouden wanneer websites veranderen. Maar als je totale controle en schaalbaarheid wilt, is Scrapy moeilijk te verslaan.
2. Apache Nutch: het beste voor enterprise search engines
Apache Nutch is de grootvader van de open-source crawlers, ontworpen voor enterprise-grade crawling op internetschaal. Als je ervan droomt je eigen zoekmachine te bouwen of miljoenen domeinen te crawlen, dan is Nutch jouw vriend.
Waarom Apache Nutch?
- Schaal dankzij Hadoop: Gebouwd op Hadoop kan Nutch miljarden pagina’s crawlen over clusters van servers (Common Crawl gebruikt het om het publieke web te crawlen).
- Batchcrawling: Geef een lijst met seed-URL’s en laat het draaien — ideaal voor geplande, grootschalige taken.
- Integratie: Werkt met Solr, Elasticsearch en big-data-pijplijnen.
Beperkingen: Complexe setup, met Hadoop-clusters en Java-configuratiebestanden, en het draait meer om ruw crawlen dan om het extraheren van gestructureerde data. Overkill voor kleine projecten, maar ongeëvenaard voor crawling op webschaal.
3. Heritrix: het beste voor webarchivering en compliance
Heritrix is de crawler van het Internet Archive zelf, speciaal gebouwd voor webarchivering en digitale preservatie.
Waarom Heritrix?
- Archiefwaardige volledigheid: Legt elke pagina, asset en link vast — perfect voor juridische compliance of historische snapshots.
- WARC-output: Slaat alles op in gestandaardiseerde Web ARChive-bestanden, klaar om opnieuw af te spelen of te analyseren.
- Webgebaseerd beheer: Configureer en monitor crawls via een browserinterface.
Beperkingen: Een zwaar systeem dat veel schijfruimte en geheugen nodig heeft, voert geen JavaScript uit en levert ruwe archieven in plaats van gestructureerde datatabellen. Het beste voor bibliotheken, archieven of gereguleerde sectoren.
4. Colly: het beste voor Go-ontwikkelaars met hoge prestaties
Colly is de favoriet van Go-ontwikkelaars — een snelle, lichtgewicht en sterk parallelle webscraper.
Waarom Colly?
- Razendsnel: Dankzij de concurrency van Go kan Colly duizenden pagina’s scrapen met minimaal CPU-/RAM-gebruik (Oxylabs).
- Eenvoudige API: Definieer callbacks voor HTML-elementen, en cookies en robots.txt worden automatisch afgehandeld.
- Geweldig voor statische sites: Perfect voor server-rendered pagina’s, API’s, of wanneer je scraping wilt integreren in een Go-backend.
Beperkingen: Geen ingebouwde JavaScript-rendering, dus voor dynamische sites moet je het combineren met iets als Chromedp, en je moet Go beheersen.
5. MechanicalSoup: het beste voor eenvoudige formulierautomatisering

MechanicalSoup is een Python-library die de kloof overbrugt tussen simpele HTTP-requests en volledige browserautomatisering.
Waarom MechanicalSoup?
- Formulierautomatisering: Log eenvoudig in, vul formulieren in en behoud sessies — ideaal voor scraping achter authenticatie.
- Lichtgewicht: Gebruikt Requests en BeautifulSoup onder de motorkap, dus het is snel en makkelijk op te zetten.
- Perfect voor interactieve sites: Als je zoekformulieren moet versturen of data na een login wilt scrapen, is MechanicalSoup een goede keuze (Apify Blog).
Beperkingen: Voert geen JavaScript uit, dus het werkt niet op sites die zwaar op JS leunen. Het beste voor statische of server-rendered pagina’s met simpele interacties.
6. Puppeteer: het beste voor dynamische sites en sites met veel JavaScript
Puppeteer is het Zwitsers zakmes voor het scrapen van moderne websites met veel JavaScript. Het is een Node.js-library die je volledige controle geeft over een headless Chrome-browser.
Waarom Puppeteer?
- Kan dynamische content aan: Scrape SPA’s, infinite scroll en pagina’s die data laden via AJAX (Browserless Guide).
- Simuleert gebruikersgedrag: Klik op knoppen, vul formulieren in, maak screenshots en los zelfs CAPTCHA’s op (met plugins).
- Krachtige automatisering: Geweldig voor testen, monitoring en het scrapen van alles wat een echte gebruiker kan zien.
Beperkingen: Resource-intensief, omdat het volledige Chrome-instanties draait, langzamer dan scrapers die alleen HTTP gebruiken, en schaalvergroting vereist stevige hardware of cloudorkestratie.
7. Wget: het beste voor snelle downloads via de command line

Wget is de klassieke commandline-tool voor het downloaden van statische websites en bestanden.
Waarom Wget?
- Eenvoud: Download complete sites of mappen met één commando — geen code nodig.
- Snelheid: Geschreven in C, dus snel en efficiënt.
- Geweldig voor statische content: Perfect voor documentatiesites, blogs of bulkdownloads van bestanden (HuggingFace Guide).
Beperkingen: Geen JavaScript-uitvoering of formulierverwerking, en het downloadt ruwe pagina’s in plaats van gestructureerde data. Zie het als een digitale stofzuiger voor statische sites.
8. HTTrack: het beste voor offline browsen (no-code)
HTTrack is de gebruiksvriendelijke neef van Wget en biedt een grafische interface om websites te spiegelen.
Waarom HTTrack?
- GUI-eenvoud: Een stap-voor-stap wizard maakt het toegankelijk voor niet-technische gebruikers.
- Offline browsen: Past links aan zodat je gespiegeld sites lokaal kunt bekijken.
- Geweldig voor archivering: Perfect voor onderzoekers, marketeers of iedereen die een snapshot van een site wil zonder te coderen (Reddit DataHoarder).
Beperkingen: Ondersteunt geen dynamische content, kan traag zijn op grote sites en is niet ontworpen voor gestructureerde data-extractie.
9. StormCrawler: het beste voor realtime gedistribueerd crawlen

StormCrawler is de moderne, gedistribueerde crawler voor teams die realtime en continu webdata op schaal nodig hebben.
Waarom StormCrawler?
- Realtime crawling: Gebouwd op Apache Storm en verwerkt data als streams — ideaal voor nieuwsmonitoring of zoekmachines (Wikipedia).
- Modulair en schaalbaar: Voeg parsering, indexering en custom processing bolts toe wanneer nodig.
- Gebruikt door Common Crawl: Draagt bij aan de nieuwsdataset van een van de grootste open webarchieven.
Beperkingen: Vereist Java-ontwikkeling en een Storm-cluster, dus het is het beste voor teams met ervaring in gedistribueerde systemen. Overkill voor kleine projecten.
Open-source Firecrawl-alternatieven vergelijken: welke gratis concurrent past bij jouw behoeften?
Hier is een overzicht van alle 9 tools naast elkaar:
| Tool | Beste use-case | Belangrijkste voordelen | Nadelen | Taal / setup |
|---|---|---|---|---|
| Scrapy | Grootschalig, frequent crawlen | Krachtig, schaalbaar, enorme community | Steile leercurve, Python vereist | Python-framework |
| Apache Nutch | Enterprise, crawlen op webschaal | Aangedreven door Hadoop, bewezen op schaal | Complexe setup, batchgericht | Java/Hadoop |
| Heritrix | Archivering, compliance-crawling | Volledige sitevastlegging, WARC-output | Zwaar, geen JS, ruwe archieven | Java-app, webinterface |
| Colly | Go-ontwikkelaars, high-performance scraping | Snel, eenvoudige API, concurrency | Geen JS, Go vereist | Go-library |
| MechanicalSoup | Formulierautomatisering, login-scraping | Lichtgewicht, sessieafhandeling | Geen JS, beperkte schaal | Python-library |
| Puppeteer | Dynamische sites / veel JS | Volledige browsercontrole, automatisering | Resource-intensief, Node.js vereist | Node.js-library |
| Wget | Statische site-download, offline toegang | Eenvoudig, snel, CLI | Geen JS, ruwe pagina’s | Commandline-tool |
| HTTrack | Niet-technische gebruikers, sitearchivering | GUI, eenvoudig offline browsen | Geen JS, traag op grote sites | Desktop-app (GUI) |
| StormCrawler | Realtime, gedistribueerd crawlen | Schaalbaar, modulair, realtime | Java/Storm-expertise nodig | Java/Storm-cluster |
Moet je je eigen crawler bouwen of een bestaande open-source Firecrawl-alternatief gebruiken?
Hier is de eerlijke waarheid: je eigen crawler bouwen klinkt leuk — tot je tot je knieën in onderhoud, proxies en anti-botproblemen zit. De open-source tools hierboven bundelen jaren aan harde ervaring en communitykennis. Volgens branche-rapporten is het gebruik van bestaande oplossingen de snelste en betrouwbaarste manier om resultaat te boeken en het wiel niet opnieuw uit te vinden (IveerData).
- Kies open source als: Je behoeften aansluiten op wat er al bestaat, je ontwikkelingstijd wilt verminderen en communitysupport belangrijk vindt.
- Bouw iets eigens als: Je écht unieke eisen hebt, diepgaande interne expertise en scraping een kernonderdeel van je business is.
Open source is echter niet echt “gratis” als je de kosten meerekent van engineeringtijd, serveronderhoud en constante updates om anti-scrapingmaatregelen te omzeilen. Wil je de voordelen van een krachtige crawler zonder code, dan is er nog een optie.
Bonus: als open source te complex wordt, probeer Thunderbit
Hoewel de tools hierboven fantastisch zijn voor ontwikkelaars, delen ze ook een aantal beperkingen: je hebt programmeerkennis nodig, ze hebben moeite met dynamische AI-gebaseerde anti-bots, en ze vragen constant onderhoud.
Thunderbit is mijn vaste aanbeveling voor iedereen die die beperkingen wil omzeilen. Het overbrugt de kloof tussen krachtige scraping en gebruiksgemak.
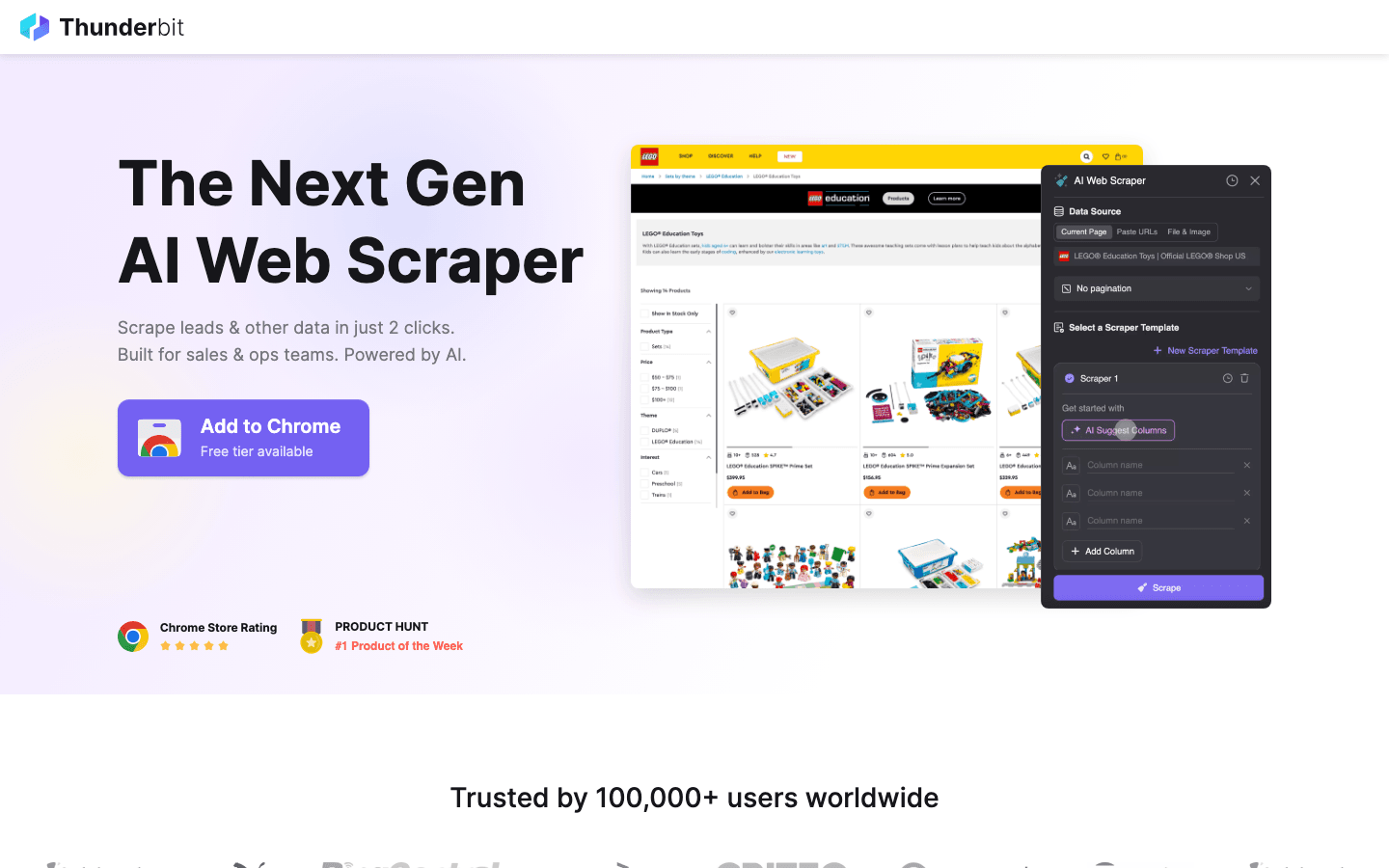
Waarom Thunderbit overwegen in plaats van open source?
- Geen code nodig: In tegenstelling tot Scrapy of Puppeteer is Thunderbit een AI-aangedreven Chrome-extensie. Je klikt op “AI Suggest Fields”, en het bouwt de scraper voor je.
- Kan de lastige dingen aan: Dynamische content, infinite scrolling en paginering worden automatisch door AI afgehandeld, zodat je uren aan custom scripts bespaart.
- Direct exporteren: Ga in twee klikken van website naar Excel, Google Sheets of Notion.
- Geen onderhoud: Je hoeft je code niet bij te werken wanneer een website zijn layout wijzigt — Thunderbit’s AI past zich voor je aan.
Als je een salesmedewerker, marketeer of onderzoeker bent die data nu wil zonder Python of Go te leren, dan is Thunderbit de perfecte aanvulling op de open-source tools in deze lijst.
Wil je zien hoe het werkt? Download de Chrome-extensie en probeer het zelf uit.
Probeer Thunderbit AI Web Scraper
Conclusie: de juiste zelfgehoste webcrawler kiezen voor 2026
Lees meer webscrapinggidsen Get Started Free
De wereld van open-source Firecrawl-alternatieven is rijker dan ooit. Of je nu de brute schaal van Scrapy of Nutch nodig hebt, of de archiefnauwkeurigheid van Heritrix, er is voor elk zakelijk scenario een oplossing. De sleutel is om je tool af te stemmen op je behoeften — ga niet over-engineeren als je alleen snel data wilt ophalen, en investeer niet te weinig als je op internetschaal crawlt.
En onthoud: als de open-source route te technisch of tijdrovend blijkt, staan AI-tools zoals Thunderbit klaar om het over te nemen.
Klaar om te beginnen? Zet Scrapy in voor je volgende grote dataproject, of Probeer Thunderbit voor eenvoudig, AI-aangedreven scrapen. Als je meer webscrapingtips wilt, bekijk dan de Thunderbit-blog voor diepgaande artikelen en tutorials.
Probeer Thunderbit voor AI-aangedreven webscraping
Veelgestelde vragen
1. Wat is het belangrijkste voordeel van open-source Firecrawl-alternatieven gebruiken?
Open-source alternatieven bieden flexibiliteit, kostenbesparing en de mogelijkheid om je crawler zelf te hosten en aan te passen. Je vermijdt vendor lock-in en profiteert van actieve communitysupport en updates.
2. Welke tool is het beste voor niet-technische gebruikers die snel resultaat willen?
HTTrack is een solide open-source keuze voor offline browsen. Maar voor gestructureerde data-extractie (zoals Excel-tabellen) raden we de bonustool Thunderbit aan vanwege de AI-mogelijkheden.
3. Hoe ga ik om met dynamische websites met veel JavaScript?
Puppeteer is je beste keuze — het bestuurt een echte browser, dus het kan alles scrapen wat een gebruiker kan zien, inclusief SPA’s en content die via AJAX wordt geladen.
4. Wanneer moet ik een zware crawler zoals Apache Nutch of StormCrawler gebruiken?
Als je miljoenen pagina’s over veel domeinen moet crawlen, of realtime, gedistribueerd crawlen nodig hebt (zoals voor zoekmachines of nieuwsmonitoring), dan zijn deze tools gebouwd voor schaal en betrouwbaarheid.
5. Is het beter om mijn eigen crawler te bouwen of een bestaande open-source oplossing te gebruiken?
Voor de meeste teams is het sneller, goedkoper en betrouwbaarder om een bestaande open-source tool te gebruiken en aan te passen. Bouw alleen iets eigens als je zeer gespecialiseerde behoeften hebt en de middelen om het op de lange termijn te onderhouden.
Veel succes met crawlen — en moge je data altijd vers, gestructureerd en klaar voor actie zijn.
Probeer Thunderbit AI Web Scraper gratis Get Started Free
Meer lezen




