Het internet is tegenwoordig hongeriger naar data dan ooit, en in 2025 is dé tool voor teams die slimmer willen webscrapen in plaats van harder. Of je nu in sales, e-commerce werkt of gewoon een echte dataliefhebber bent zoals ik, je hebt vast gemerkt dat webscraping allang niet meer draait om simpelweg ‘data binnenhalen’—het gaat nu om snelheid, schaalbaarheid en zorgen dat je IP-adres niet op een zwarte lijst belandt. Met een verwachte groei van de webscrapingmarkt van $7,48 miljard in 2025 naar bijna $38,4 miljard in 2034 (), zijn de belangen (en de concurrentie) groter dan ooit.
Maar hier zit het venijn: moderne websites zijn een doolhof van dynamische content, anti-botmaatregelen en steeds veranderende layouts. Ik heb meer webscrapers zien crashen dan me lief is—meestal omdat ze de basisregels negeerden of de slimheid van anti-scraping technologie onderschatten. Daarom neem ik je mee langs de belangrijkste best practices voor efficiënte Node.js webscraping, met praktijkvoorbeelden, een vleugje humor en vooral veel handige tips.
Waarom kiezen voor Node.js bij webscraping?
Als je ooit honderden of zelfs duizenden pagina’s tegelijk hebt gescrapet, weet je dat snelheid en gelijktijdigheid allesbepalend zijn. Daar blinkt Node.js echt in uit. Dankzij het asynchrone, non-blocking I/O-model kan Node.js moeiteloos enorme aantallen netwerkverzoeken tegelijk aan—zie het als de ultieme multitasker voor het web (). Waar andere talen wachten tot elk verzoek is afgerond, blijft Node.js zijn event loop draaien en verwerkt verzoeken als een circusartiest op een dubbele espresso.
Ik heb Node.js Python en Java zien overtreffen in situaties waar real-time updates en grootschalige extractie nodig zijn, vooral bij websites die zwaar op JavaScript draaien. Inmiddels gebruikt Node.js voor backend- en automatiseringstaken, waarmee het wereldwijd de populairste webtechnologie is.
Node.js versus andere webscraping frameworks
Even technisch: zo steekt Node.js af tegen de concurrentie:
| Framework | Sterke punten | Zwakke punten | Beste toepassingen |
|---|---|---|---|
| Node.js | Asynchroon, top voor gelijktijdigheid, enorme npm-bibliotheek, native JS voor dynamische sites | Kan veel geheugen gebruiken, callback-hel (zonder async/await) | Real-time scraping, JS-rijke sites, schaalbare microservices |
| Python | Veel scraping libraries (BeautifulSoup, Scrapy), makkelijke syntax | Minder snel bij veel gelijktijdigheid, moeite met JS-sites | Statische HTML, onderzoek, prototyping |
| Java | Sterk getypeerd, robuust voor enterprise | Uitvoerig, minder flexibel voor snelle scripts | Grootschalige, enterprise scraping |
| Go | Snel, efficiënte gelijktijdigheid | Kleinere community, steilere leercurve | High-performance, lage latency scraping |
Voor de meeste bedrijven is Node.js de ideale keuze: snel, flexibel en perfect afgestemd op het moderne, JavaScript-gedreven web ().
Een solide Node.js webscraping omgeving opzetten
Een goede webscraper begint met een stevige basis. Dit is mijn standaard setup:
- Projectstructuur: Werk modulair. Gebruik mappen als
/src,/libsen/config. Bewaar gevoelige info (API keys, proxies) in omgevingsvariabelen metdotenv(). - HTTP-client: Gebruik , of voor je verzoeken.
- HTML-parsing: voor statische HTML, of Playwright voor dynamische content.
- Utilities: Gebruik voor dataverwerking, en of voor datavalidatie.
- Testen & linten: Mocha voor tests, ESLint voor codekwaliteit ().
Onmisbare Node.js webscraping libraries
- axios/got/node-fetch: Voor HTTP-verzoeken. Axios is mijn favoriet vanwege de promise-based API en ingebouwde JSON-ondersteuning.
- Cheerio: Supersnelle, jQuery-achtige HTML-parser. Ideaal voor statische pagina’s—parseert in ~0,5s ().
- Puppeteer/Playwright: Headless browser-automatisering voor dynamische, JS-rijke sites. Iets trager (~4s per pagina), maar onmisbaar voor content die na het laden verschijnt ().
- dotenv: Voor het beheren van omgevingsvariabelen.
- csv-writer/jsonfile: Voor het exporteren van data.
Veelgemaakte fouten bij Node.js webscraping voorkomen
Ik ben de tel kwijt van het aantal webscrapers dat is geblokkeerd, gecrasht of alleen maar rommelige data opleverde. Let hierop:
- robots.txt en gebruiksvoorwaarden negeren: Check altijd voor je gaat scrapen. Overtreding kan je IP blokkeren—of erger, juridische problemen opleveren ().
- Servers overbelasten: Stuur niet te veel verzoeken tegelijk. Gebruik willekeurige vertragingen (1–3 seconden), beperk gelijktijdigheid en gedraag je niet als een hyperactieve bot ().
- Fouten niet afhandelen: Gebruik altijd try/catch, verwerk HTTP-fouten en log mislukkingen. Probeer tijdelijke fouten opnieuw met exponential backoff ().
- Verzoekheaders vergeten: Gebruik realistische User-Agent strings en roteer ze. Voeg Accept-Language, Referer en andere headers toe om browsers na te bootsen ().
Anti-scraping maatregelen omzeilen
Moderne websites zijn uitgerust met slimme anti-bot technologie. Zo blijf ik ze voor:
- Proxies/IP’s roteren: Gebruik een proxy pool en roteer IP-adressen om blokkades te voorkomen ().
- Headers randomiseren: Roteer User-Agent, Accept-Language en andere headers per verzoek.
- Headless browser stealth: Gebruik plugins zoals
puppeteer-extra-plugin-stealthom automatiseringssporen te verbergen. - Menselijk gedrag simuleren: Voeg willekeurige vertragingen, muisbewegingen, scrollen en zelfs typfouten toe ().
Menselijk gedrag nabootsen in Node.js webscrapers
Hier wordt het leuk (en een beetje maf). In plaats van direct te klikken en scrollen, kun je je webscraper laten:
- Willekeurige pauzes tussen acties inlassen (
await page.waitForTimeout(randomDelay)) - De muis in kleine, onregelmatige stapjes bewegen (
page.mouse.move(x, y)) - Typen met variabele vertragingen en af en toe een typfoutje (
page.type(selector, text, {delay: random(100,200)})) - Onregelmatig scrollen, niet alleen naar beneden
Deze trucs verhogen je slagingskans op beschermde sites aanzienlijk ().
Complexe data-extractie vereenvoudigen met Thunderbit
Eerlijk is eerlijk: webscraping is vaak een gedoe. Maar het kan veel makkelijker. Daarom hebben we ontwikkeld.
Thunderbit is een AI-webscraper Chrome-extensie waarmee je data van elke website kunt halen met gewone taal. Klik op “AI Suggest Fields”, laat de AI de pagina analyseren en druk op “Scrape”. Het is alsof je een junior developer hebt die nooit slaapt en nooit om opslag vraagt.
Nog beter: Thunderbit biedt een API, zodat je het direct in je Node.js-workflows kunt integreren. In plaats van duizenden regels scrapingcode te schrijven, laat je Thunderbit het zware werk doen—dynamische content, subpagina’s, paginering, alles. Je haalt gewoon de gestructureerde data op (CSV, JSON of direct naar Google Sheets, Airtable, Notion) en kunt direct verder ().
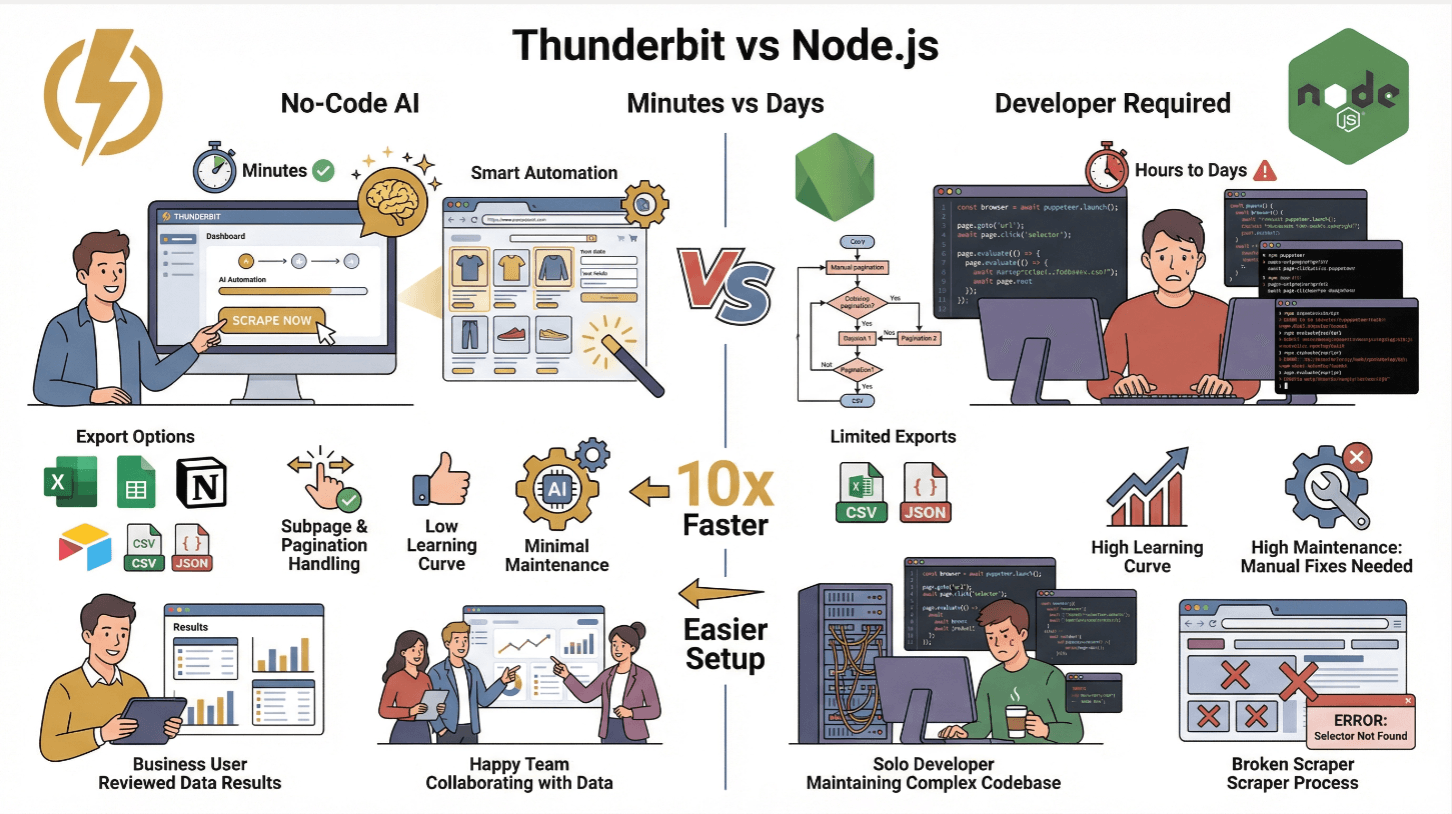
Thunderbit versus traditionele Node.js webscraping
| Functie | Thunderbit | Traditionele Node.js scraper |
|---|---|---|
| Installatietijd | Minuten (geen code) | Uren tot dagen (coderen, testen) |
| Dynamische content | Ja (AI + browser) | Ja (met Puppeteer/Playwright) |
| Subpagina’s & paginering | 1 klik | Handmatig coderen vereist |
| Data exporteren | Excel, Sheets, Notion, Airtable, CSV, JSON | CSV/JSON (eigen code) |
| Leercurve | Laag (zakelijke gebruikers) | Hoog (ontwikkelaars) |
| Onderhoud | Minimaal (AI past zich aan) | Hoog (handmatig aanpassen bij sitewijzigingen) |
Thunderbit is ideaal voor niet-technische teams of iedereen die snel inzichten wil zonder technisch gedoe. Voor gevorderden kun je de Thunderbit API gebruiken om scraping op grote schaal te automatiseren ().
Cheerio en Puppeteer combineren voor dynamische content
Dit is mijn favoriete Node.js webscraping-combo. Zo werkt het:
- Gebruik Puppeteer om de pagina te laden en JavaScript uit te voeren (wacht op
networkidlezodat alles geladen is). - Haal de HTML op met
await page.content(). - Parseer met Cheerio: Geef de HTML aan Cheerio voor razendsnelle, jQuery-achtige parsing en data-extractie.
Deze hybride aanpak geeft je het beste van twee werelden: de kracht van Puppeteer voor dynamische content en de snelheid van Cheerio voor parsing ().
Performance tip: Selecteer alleen de elementen die je nodig hebt. Cheerio laadt de hele DOM in het geheugen, dus vermijd brede selectors en cache resultaten als je dezelfde pagina’s vaker scrapt ().
HTML-parsing en data-extractie optimaliseren
- Gebruik specifieke selectors: Vermijd
$('body *')—target alleen wat je nodig hebt. - Stream grote pagina’s: Voor enorme HTML-bestanden kun je streamen of het werk opdelen.
- Cache gerenderde HTML: Als je URLs herhaald bezoekt, cache dan de HTML om dubbele verzoeken te voorkomen.
- Valideer en reinig data: Gebruik validator libraries om te voorkomen dat je database vervuild raakt ().
Schaalbare Node.js webscraper deployment in de cloud
Wil je grootschalig scrapen? Dan is cloud-native de way to go.
- Dockerize je scraper: Schrijf een
Dockerfile, kopieer je code, installeer dependencies en stel het entrypoint in. - Deploy naar de cloud: Gebruik AWS EC2, Google Cloud Compute of Azure VMs voor eenvoudige taken. Voor echte schaalbaarheid: Kubernetes of managed services zoals AWS ECS/EKS, Google Cloud Run of Azure Kubernetes Service ().
- Orchestreren met Kubernetes: Draai meerdere pods, schaal automatisch op basis van vraag en gebruik load balancers om URLs te verdelen.
- Taken plannen: Gebruik cloud schedulers (CloudWatch Events, Cloud Scheduler) of cronjobs om scrapes periodiek te starten.
In de praktijk: door van 5 naar 10 Kubernetes pods te schalen, werd een scrape van 400 pagina’s teruggebracht van enkele minuten naar minder dan een minuut ().
Monitoring en auto-scaling van je scraping infrastructuur
- Logging: Stream logs naar CloudWatch, Stackdriver of Datadog. Stel alerts in voor fouten of vertragingen.
- Health checks: Gebruik Prometheus en Grafana voor metrics zoals gescrapete pagina’s per minuut, foutpercentages en pod-status.
- Auto-scaling: Zet Kubernetes HPA (Horizontal Pod Autoscaler) in om pods te schalen op basis van CPU of aantal verzoeken.
Implementeer altijd retries met exponential backoff om te herstellen van netwerkproblemen of tijdelijke blokkades.
Dataopslag en post-processing best practices
Na het scrapen moet je de data opslaan en opschonen:
- Kleine jobs: Exporteer naar CSV, JSON of push naar Google Sheets, Airtable of Notion (Thunderbit regelt dit standaard).
- Grote jobs: Gebruik SQL (MySQL/PostgreSQL) voor gestructureerde data, of NoSQL (MongoDB, DynamoDB) voor semi-gestructureerde of veranderende schema’s ().
- Cloudopslag: Sla ruwe bestanden en back-ups op in S3 of Google Cloud Storage.
- Data opschonen: Valideer velden, normaliseer formaten (datums, getallen) en verwijder dubbele entries. Gebruik schema validators voor datakwaliteit ().
Bewaar zowel de ruwe als opgeschoonde data—je weet nooit wanneer je opnieuw moet verwerken of debuggen.
Conclusie: belangrijkste inzichten voor efficiënte Node.js webscraping
Kort samengevat:
- Maak gebruik van de asynchrone kracht van Node.js voor grootschalige, gelijktijdige webscraping—vooral op JS-rijke sites.
- Combineer de juiste tools: Gebruik axios/got voor verzoeken, Cheerio voor statische HTML, Puppeteer voor dynamische content en mix ze voor snelheid en flexibiliteit.
- Omzeil anti-botmaatregelen: Roteer proxies en headers, simuleer menselijk gedrag en respecteer robots.txt.
- Vereenvoudig met Thunderbit: Voor zakelijke gebruikers of snelle prototypes kun je met complexe data met AI extraheren en direct koppelen aan je Node.js stack via de API.
- Schaal je deployment: Dockerize, orkestreer met Kubernetes en monitor alles voor betrouwbaarheid.
- Sla data slim op en maak het schoon: Kies de juiste opslag en valideer altijd voor gebruik.
Het web wordt er niet eenvoudiger op, maar met deze best practices blijven je Node.js webscrapers snel, stabiel en altijd een stap voor op anti-botmaatregelen. En als je ooit moe wordt van selectors debuggen om 2 uur ‘s nachts: Thunderbit’s AI is altijd wakker.
Verder leren? Check de voor meer diepgaande artikelen, of probeer de en ontdek hoe makkelijk webscraping kan zijn.
Veelgestelde vragen
1. Waarom is Node.js zo geschikt voor webscraping in 2025?
Het asynchrone, event-driven model van Node.js maakt het mogelijk om duizenden verzoeken tegelijk te verwerken. Ideaal voor het scrapen van grote hoeveelheden data of real-time updates. De grote npm-community en native JavaScript-ondersteuning zijn perfect voor moderne, JS-rijke websites ().
2. Hoe voorkom ik blokkades bij Node.js webscraping?
Gebruik roterende proxies, randomiseer request headers, vertraag je verzoeken met willekeurige pauzes en simuleer menselijk gedrag (muisbewegingen, scrollen, typen) met tools als Puppeteer. Respecteer altijd robots.txt en de voorwaarden van de site ().
3. Wanneer gebruik ik Cheerio of Puppeteer in mijn Node.js webscraper?
Gebruik Cheerio voor snelle parsing van statische HTML (als de data direct in de HTML staat). Gebruik Puppeteer voor sites die content dynamisch met JavaScript laden. Voor het beste resultaat: render de pagina met Puppeteer en parse de HTML met Cheerio ().
4. Hoe maakt Thunderbit Node.js webscraping eenvoudiger?
Met Thunderbit kun je gestructureerde data van elke website halen via AI en natuurlijke taal—zonder te coderen. Het verwerkt dynamische content, subpagina’s en paginering, en biedt een API voor Node.js-integratie. Data kan direct worden geëxporteerd naar Excel, Google Sheets, Airtable of Notion ().
5. Wat is de beste manier om Node.js webscrapers te schalen en monitoren in de cloud?
Dockerize je webscraper, deploy op Kubernetes of managed cloud services en gebruik auto-scaling om pieken op te vangen. Monitor logs en metrics met tools als CloudWatch of Prometheus en stel alerts in voor fouten of vertragingen ().
Klaar om je webscraping naar een hoger niveau te tillen? Probeer Thunderbit en zorg dat je webscrapers snel, onzichtbaar en altijd een stap voor blijven.
Meer leren