
Elke Node.js fetch-tutorial leert je await fetch(url) en laat het daarbij. Daarna slikt je productieapp stilletjes een 500-fout in, blijft een request 90 seconden hangen zonder timeout, en zit jij op vrijdagavond te debuggen van iets dat eigenlijk meteen duidelijk had moeten zijn.
Ik bouw al een tijd interne tools en datapijplijnen bij , en ik kan je dit vertellen: de kloof tussen "fetch werkt in mijn tutorial" en "fetch werkt in productie" is precies waar de meeste ellende ontstaat. Een ontwikkelaar op Reddit zei het mooi: "when you go into production, you realise you need something more resilient than the native fetch."
Een ander gaf toe: "Worked for 3 years as a web developer, TIL the fetch API's catch block is NOT for HTTP errors." Deze gids behandelt de vijf dingen die de meeste tutorials overslaan — de error-valkuil, AbortController-timeouts, retrylogica, connection reuse en wanneer je verder moet gaan dan fetch voor gestructureerde data-extractie. Als een fetch-call ooit stilletjes is mislukt in productie, is dit voor jou.
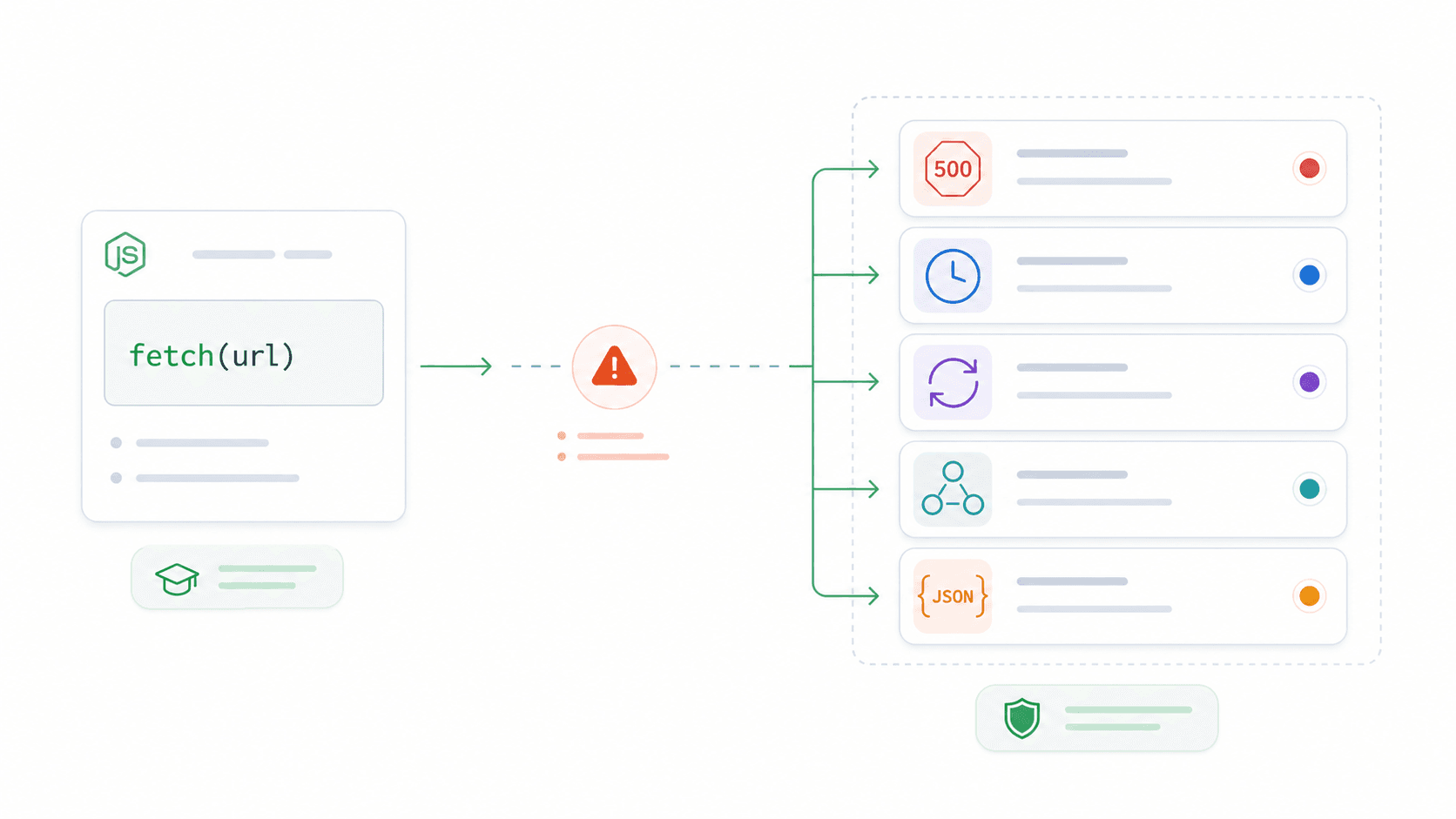
Wat is de Node.js Fetch API?
De Node.js Fetch API is de ingebouwde, browser-compatibele manier om HTTP-verzoeken te doen (GET, POST, PUT, DELETE, enz.) vanuit Node.js — zonder Axios, node-fetch of een ander pakket te installeren. Als je fetch() in de browser hebt gebruikt, ken je de syntax al. Nu werkt dezelfde API ook op de server.
Hier is de korte versie van de geschiedenis:
| Mijlpaal | Node-versie | Wat er gebeurde |
|---|---|---|
| Experimentele fetch-vlag | v17.5.0 / v16.15.0 | fetch toegevoegd achter --experimental-fetch |
| Standaard globale fetch | v18.0.0 | Experimentele fetch globaal beschikbaar, aangedreven door Undici |
| Stabiele fetch | v21.0.0 | Niet langer experimenteel |
| Productiebasislijn 2026 | v22 LTS / v24 LTS | Aanbevolen voor productie; v20 is nu EOL |
Onder de motorkap wordt Node's fetch aangedreven door Undici — een high-performance HTTP-client die speciaal is gebouwd voor Node.js. Het vertrouwt niet op de oudere ingebouwde http-module. Het praktische voordeel: je krijgt een moderne, Promise-gebaseerde HTTP API die hetzelfde werkt in je browsercode, je Express-backend, je serverless functie en je CLI-scripts.
Waarom de Node.js Fetch API belangrijk is voor je projecten
Voor Node 18 begon elk nieuw project met hetzelfde ritueel: npm install axios of npm install node-fetch. In 2026 heb je, als je project draait op een ondersteunde Node LTS, voor basis-HTTP-verzoeken nul afhankelijkheden nodig. Dat is echt winst voor bundlegrootte, supply-chain security en onboarding (front-end- en back-endontwikkelaars delen eindelijk dezelfde API).
Hier blinkt native fetch uit:
| Scenario | Waarom native fetch goed werkt | Productie-aandachtspunt |
|---|---|---|
| Express/Fastify-backend die REST API's aanroept | Bekende async/await, geen dependency | Voeg timeout en response.ok-checks toe |
| Serverless functies (Lambda, Vercel, enz.) | Kleine cold-start footprint, geen pakketinstallatie | Houd de timeout onder de maximale platformduur |
| CLI-scripts en automatiseringen | Simpele GET/POST zonder projectsetup | Voeg retry/backoff toe voor onstabiele API's |
| Webhook-aflevering of forwarding | Standaard HTTP-methoden en headers | Retry niet blind non-idempotente POST's |
| Rapporten en dashboards | Goed voor JSON uit API's halen | Gebruik paginering en connection pooling voor lussen |
| Microservicecommunicatie | Werkt voor eenvoudige interne HTTP-calls | Overweeg Got of Undici direct voor retry, hooks of HTTP/2 |
Voor nieuwe Node 22+-projecten is native fetch de logische standaard — tenzij je weet dat je functies nodig hebt die het niet biedt (interceptors, ingebouwde retry, HTTP/2, enz.). De npm-downloadcijfers laten zien dat de markt verschuift: , maar een groot deel daarvan is legacy en transitieve afhankelijkheden. , , en . De trend is duidelijk: native fetch is de nieuwe basis, en third-party clients zijn er voor specifieke behoeften.
Native Fetch vs node-fetch vs Axios vs Got vs Ky: de beslismatrix voor 2026
De vraag die ik het vaakst zie in developerforums: "Which HTTP client should I use in Node.js?" Een Reddit-gebruiker vatte het goed samen: "why import a library…when the language/framework has functionality built in?" Terechte vraag — maar het antwoord hangt af van wat je nodig hebt.
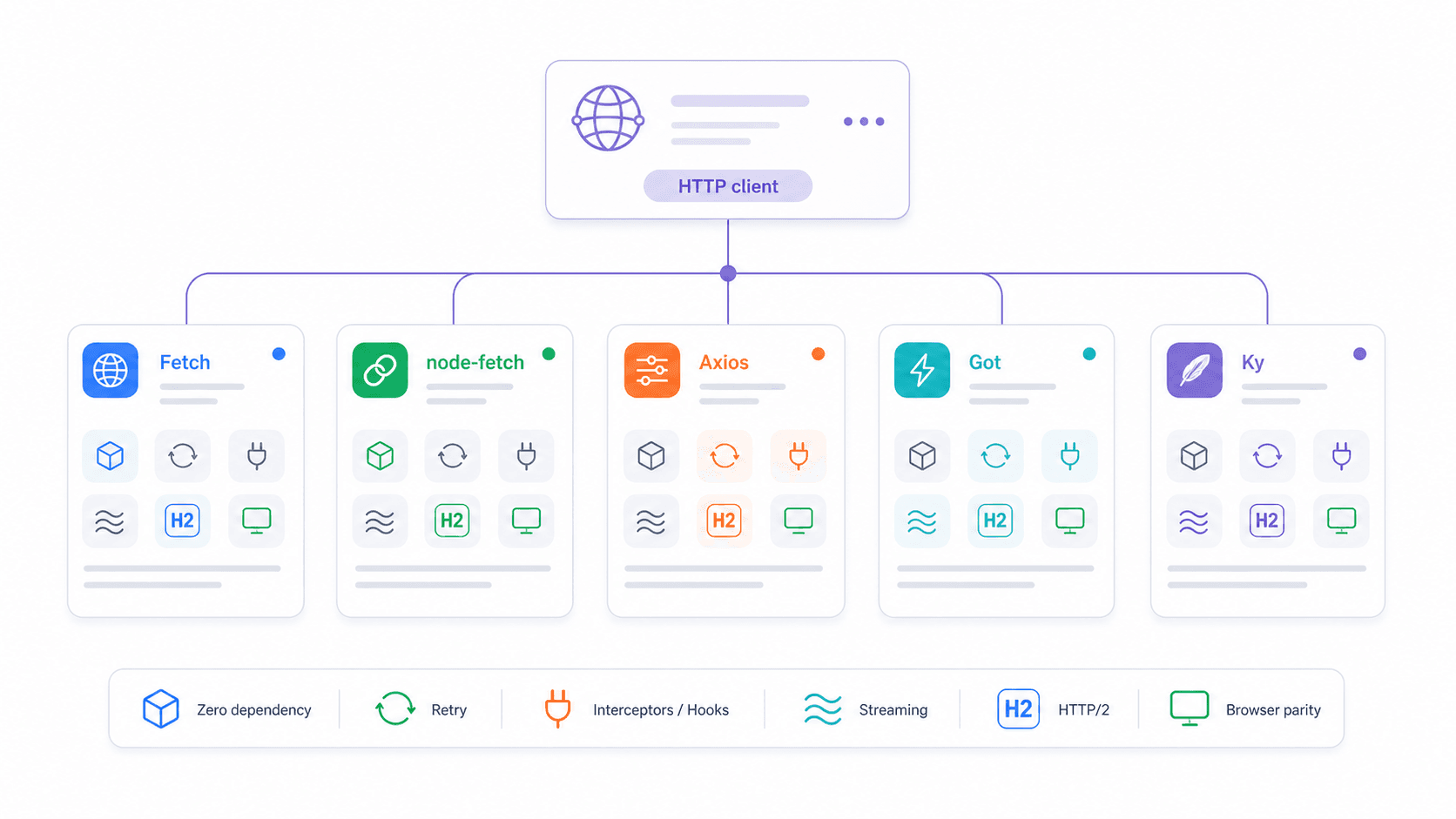
| Functie | Native fetch | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Node.js-versie | ≥18 (aanbevolen 22/24 LTS) | ≥12.20 | Breed | ≥22 | ≥22 |
| Installatie vereist | Nee | Ja | Ja | Ja | Ja |
| Ondersteuning voor ESM + CJS | Beide (globaal) | Alleen ESM (v3) | Beide | Alleen ESM | Alleen ESM |
| Automatisch afwijzen op 4xx/5xx | Nee | Nee | Ja | Ja | Ja |
| Ingebouwde retry | Nee | Nee | Nee | Ja | Ja |
| Request-interceptors | Nee | Nee | Ja | Ja (hooks) | Ja (hooks) |
| Streaming-ondersteuning | Web ReadableStream | Ja | Beperkt | Sterke Node-streams | Op fetch gebaseerd |
| Bundle/install-footprint | 0 KB | ~107 KB, 3 deps | ~2,8 MB, 4 deps | ~355 KB, 12 deps | ~405 KB, 0 deps |
| HTTP/2-ondersteuning | Via Undici dispatcher | Nee | Nee | Ja | Nee (fetch-wrapper) |
Een korte noot over de ESM/CJS-hoofdpijn: node-fetch v3 is alleen ESM, waardoor veel projecten stukgingen die require() gebruikten. Native fetch is globaal — het werkt in zowel CJS- als ESM-bestanden zonder import-gedoe. Als je vastzit op node-fetch v2 vanwege CommonJS, lost native fetch dat probleem volledig op.
En over vroege stabiliteitszorgen: ja, er zaten echte bugs in de eerste fetch-implementatie van Node 18. Een ontwikkelaar op Reddit merkte op: "Had a wild bug with native node 18 fetch recently so had to convert our app." Dat was in 2023. In 2026, met Node 22 en 24 LTS, zijn die problemen opgelost. Native fetch is productieklaar.
Wanneer je bij native fetch moet blijven
Kies native fetch wanneer:
- Je project draait op Node 22 LTS of Node 24 LTS.
- Verzoeken eenvoudige REST-calls zijn (GET, POST, PUT, DELETE).
- Je bereid bent een kleine wrapper toe te voegen voor
response.ok, JSON-parsing, timeouts en retry. - Je nul afhankelijkheden en minder supply-chain-zorgen wilt.
- Je browser/server-API-pariteit belangrijk vindt.
- Je in serverless- of edge-omgevingen zit waar ingebouwde API's de voorkeur hebben.
Wanneer Axios, Got of Ky logischer is
Axios is de juiste keuze wanneer je team vertrouwt op request/response-interceptors (bijv. automatische verversing van auth-tokens, tenant-headers, gecentraliseerde logging), wanneer je standaard afwijzing op HTTP-fouten wilt, of wanneer je backward compatibility nodig hebt met oudere Node-runtimes.
Got is gebouwd voor Node-services met hoge throughput die ingebouwde retries, hooks, geavanceerde timeout-fasen, streams, pagination helpers, Unix sockets, proxy/caching-workflows of HTTP/2-ondersteuning nodig hebben. Het is het Zwitsers zakmes voor HTTP-werk in Node.
Ky is de sweet spot als je de eenvoud van fetch fijn vindt maar minder boilerplate wilt — het voegt retry, timeout, hooks en HTTPError toe in een klein pakket zonder dependencies.
Hoe je GET-verzoeken doet met de Node.js Fetch API
Een GET-verzoek met async/await ziet er zo uit:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
2const post = await response.json();
3console.log(post.title);
4// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"En de .then()-keten, als je die liever gebruikt:
1fetch('https://jsonplaceholder.typicode.com/posts/1')
2 .then(response => response.json())
3 .then(post => console.log(post.title))
4 .catch(error => console.error(error));Beide werken. Maar geen van beide is al veilig genoeg voor productie (meer daarover zo meteen).
Response-readers die je moet kennen:
| Methode | Gebruik wanneer |
|---|---|
response.json() | De server JSON teruggeeft |
response.text() | De server HTML, platte tekst, CSV of Markdown teruggeeft |
response.arrayBuffer() | Je binaire data nodig hebt (afbeeldingen, bestanden) |
response.body | Je streaming/chunkverwerking nodig hebt |
Een beter patroon — eentje die echt op fouten controleert:
1async function getPost(id) {
2 const response = await fetch(`https://jsonplaceholder.typicode.com/posts/$\{id\}`);
3 if (!response.ok) {
4 throw new Error(`HTTP $\{response.status\} $\{response.statusText\}`);
5 }
6 return response.json();
7}
8const post = await getPost(1);
9console.log(post.title);Die if (!response.ok)-regel is het verschil tussen een tutorial en productiecode. En daarmee komen we bij de grootste valkuil.
Hoe je POST-verzoeken verstuurt met de Node.js Fetch API
POST-verzoeken volgen dezelfde vorm — je zet alleen de methode, headers en body:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
2 method: 'POST',
3 headers: {
4 'Content-Type': 'application/json',
5 },
6 body: JSON.stringify({
7 title: 'Node fetch-gids',
8 body: 'Productie-fetch heeft foutafhandeling nodig.',
9 userId: 1,
10 }),
11});
12if (!response.ok) {
13 throw new Error(`HTTP $\{response.status\}`);
14}
15const created = await response.json();
16console.log(created.id); // → 101Andere requesttypes versturen (PUT, DELETE, PATCH)
PUT, PATCH en DELETE gebruiken exact dezelfde structuur, met alleen een andere method-waarde:
1// PUT — volledige vervanging
2await fetch('https://jsonplaceholder.typicode.com/posts/1', {
3 method: 'PUT',
4 headers: { 'Content-Type': 'application/json' },
5 body: JSON.stringify({ id: 1, title: 'Vervangen', body: 'Volledige vervanging', userId: 1 }),
6});
7// PATCH — gedeeltelijke update
8await fetch('https://jsonplaceholder.typicode.com/posts/1', {
9 method: 'PATCH',
10 headers: { 'Content-Type': 'application/json' },
11 body: JSON.stringify({ title: 'Gedeeltelijke update' }),
12});
13// DELETE
14await fetch('https://jsonplaceholder.typicode.com/posts/1', {
15 method: 'DELETE',
16});De Express body-parser-valkuil: Als je JSON naar een Express-server POST en req.body komt terug als undefined, is de oplossing vrijwel altijd dit: gebruik express.json(), niet express.urlencoded(). De server heeft express.json()-middleware nodig vóór je route om bodies met Content-Type: application/json te parsen. Dit is een van de meest voorkomende over Express, en het pakt mensen telkens weer.
1import express from 'express';
2const app = express();
3app.use(express.json()); // ← Dit heb je nodig voor JSON POST-bodies
4app.post('/api/posts', (req, res) => {
5 res.json({ ontvangen: req.body });
6});De fetch()-errorvalkuil die productieapps breekt
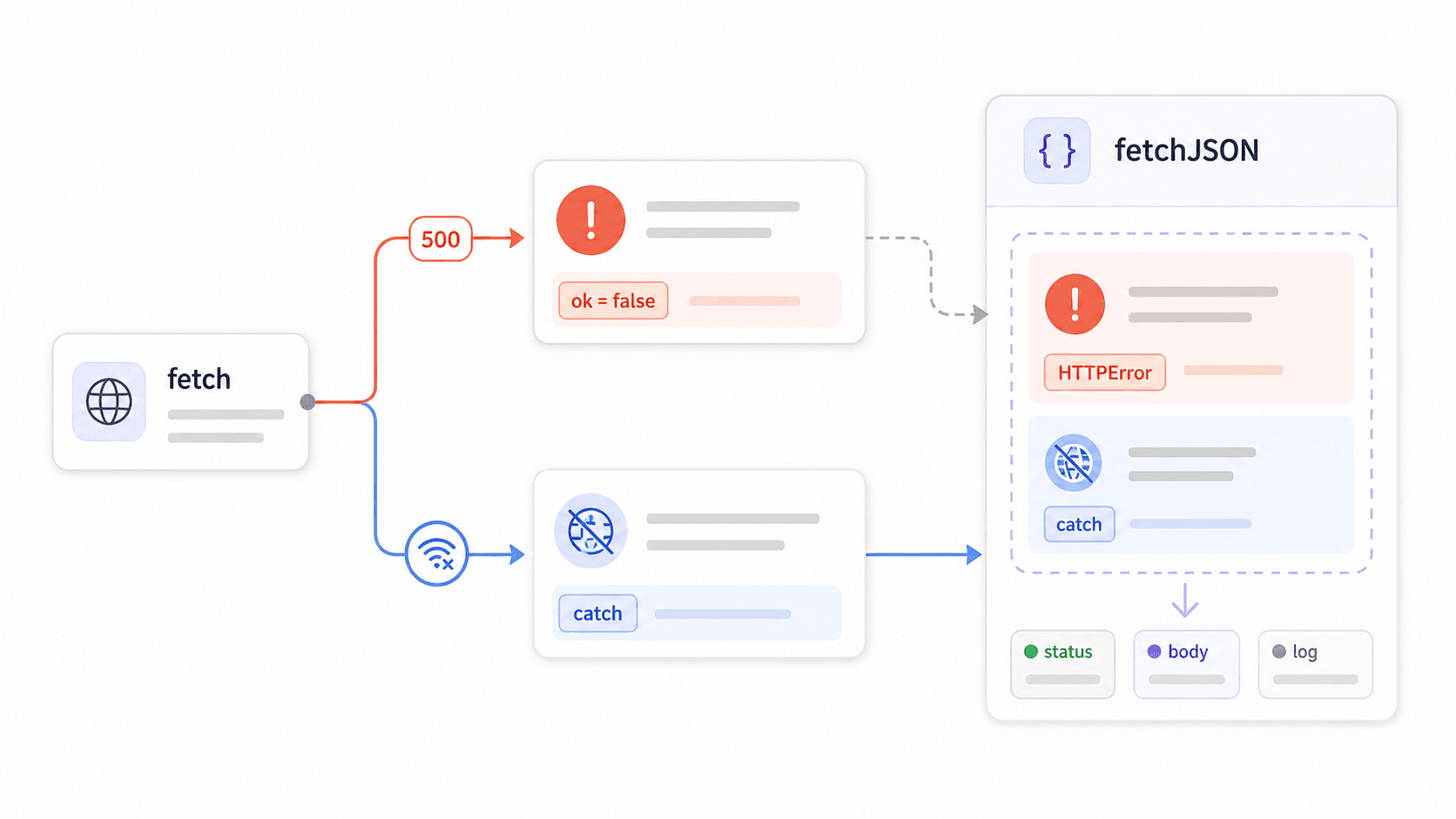
Hier ontstaan de meeste productiebugs met fetch.
fetch() wijst zijn promise niet af bij HTTP 4xx- of 5xx-fouten. Het wijst alleen af bij netwerkfouten — DNS-fouten, geen internetverbinding, geannuleerde verzoeken. Als de server een 403 Forbidden of een 500 Internal Server Error teruggeeft, ziet fetch dat als een succesvolle response. Je .catch()-block draait dan nooit. Je try/catch vangt het nooit af. Je code verwerkt vrolijk wat de server heeft teruggestuurd.
legt dit duidelijk uit, maar de meeste tutorials gaan er snel overheen. Het resultaat? Code als deze ziet er prima uit, maar slikt fouten stilletjes in:
1try {
2 const response = await fetch('https://api.example.com/private');
3 const data = await response.json(); // ← Dit draait zelfs bij een 403
4 console.log('Lijkt succesvol:', data);
5} catch (error) {
6 // Alleen netwerkfouten komen hier terecht
7 console.error('Opgevangen:', error);
8}Een snelle uitsplitsing van wat elk patroon echt vangt:
| Patroon | Vangt netwerkfouten | Vangt 4xx/5xx | Parseert JSON veilig | Hergebruikbaar |
|---|---|---|---|---|
Ruwe .then(res => res.json()) | Ja (via .catch()) | Nee | Geen content-type-guard | Nee |
try/catch met await fetch() | Ja | Nee | Geen content-type-guard | Nee |
Handmatige if (!res.ok) per call | Ja | Ja | Hangt af van elke call | Gedeeltelijk |
Aangepaste fetchJSON()-wrapper | Ja | Ja | Ja | Ja |
Bouw een herbruikbare fetchJSON()-wrapper
Bouw één wrapper. Importeer die overal. Stop met if (!response.ok) in elk bestand te copy-pasten:
1export class HTTPError extends Error {
2 constructor(message, { status, statusText, url, body }) {
3 super(message);
4 this.name = 'HTTPError';
5 this.status = status;
6 this.statusText = statusText;
7 this.url = url;
8 this.body = body;
9 }
10}
11export async function fetchJSON(url, options = {}) {
12 const response = await fetch(url, {
13 headers: {
14 Accept: 'application/json',
15 ...options.headers,
16 },
17 ...options,
18 });
19 const contentType = response.headers.get('content-type') || '';
20 const isJSON = contentType.includes('application/json');
21 const body = isJSON ? await response.json().catch(() => null) : await response.text();
22 if (!response.ok) {
23 throw new HTTPError(`HTTP $\{response.status\} $\{response.statusText\}`, {
24 status: response.status,
25 statusText: response.statusText,
26 url: response.url,
27 body,
28 });
29 }
30 return body;
31}Als de server nu een 403 teruggeeft:
1try {
2 const data = await fetchJSON('https://api.example.com/private');
3} catch (error) {
4 if (error instanceof HTTPError) {
5 console.error(`Server gaf $\{error.status\} terug:`, error.body);
6 } else {
7 console.error('Netwerk- of andere fout:', error);
8 }
9}De fout bevat de statuscode, de response-body en de URL — alles wat je nodig hebt voor logging, alerts of berichten aan gebruikers. Importeer dit één keer, gebruik het overal.
AbortController en timeouts: het productiepatroon voor de Node.js Fetch API
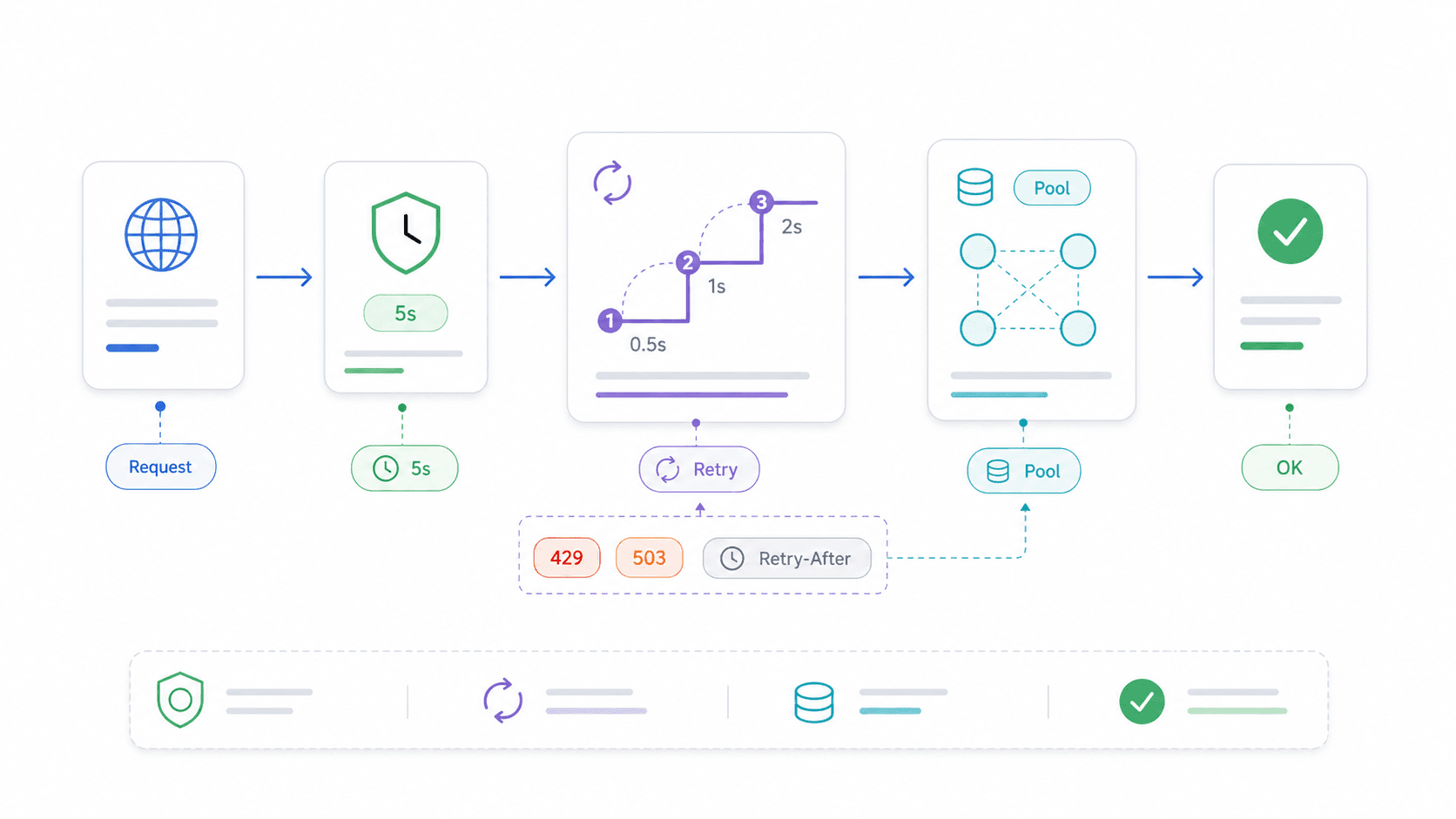
Zonder timeout blijft een fetch-call eindeloos hangen wanneer de externe server stilvalt. Je Express-route blokkeert. Je Lambda verbrandt zijn execution budget. Je script zit gewoon... te wachten.
Ik heb de bovenste zoekresultaten bekeken: geen enkele Node.js-specifieke fetch-tutorial behandelt request cancellation of timeouts. Toch zijn timeouts een van de belangrijkste redenen waarom ontwikkelaars bij Axios of Got blijven. Een Reddit-thread heet letterlijk "Node fetch does not timeout".
Gebruik AbortSignal.timeout() (Node 18.11+)
De simpelste aanpak — één extra optie:
1try {
2 const response = await fetch('https://api.example.com/data', {
3 signal: AbortSignal.timeout(5000), // 5 seconden
4 });
5 if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
6 const data = await response.json();
7 console.log(data);
8} catch (error) {
9 if (error.name === 'TimeoutError') {
10 console.error('De aanvraag time-outte na 5 seconden.');
11 } else {
12 throw error;
13 }
14}Let op: AbortSignal.timeout() gooit een TimeoutError, geen AbortError. Dat is een detail dat zelfs sommige ervaren ontwikkelaars verkeerd hebben.
Handmatige timeout met AbortController
Voor meer controle — of als je een request wilt annuleren op basis van gebruikersactie, niet alleen op een timer:
1const controller = new AbortController();
2const timeout = setTimeout(() => controller.abort(), 5000);
3try {
4 const response = await fetch('https://api.example.com/data', {
5 signal: controller.signal,
6 });
7 const data = await response.json();
8 console.log(data);
9} catch (error) {
10 if (error.name === 'AbortError') {
11 console.error('De aanvraag is handmatig geannuleerd.');
12 } else {
13 throw error;
14 }
15} finally {
16 clearTimeout(timeout);
17}AbortError vs TimeoutError afhandelen
Dit onderscheid is belangrijk voor logging en berichten aan gebruikers:
| Abort-pad | Foutnaam in catch-block |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| DNS-/netwerkfout | Typisch TypeError: fetch failed |
Hier is een praktisch scenario — een Express-route die een externe API aanroept en binnen 3 seconden moet reageren:
1app.get('/dashboard', async (req, res, next) => {
2 try {
3 const data = await fetchJSON('https://api.example.com/report', {
4 signal: AbortSignal.timeout(3000),
5 });
6 res.json(data);
7 } catch (error) {
8 if (error.name === 'TimeoutError') {
9 res.status(504).json({ error: 'Upstream API time-out' });
10 return;
11 }
12 next(error);
13 }
14});Zonder dit patroon zou een trage upstream API je hele route blokkeren totdat de client opgeeft.
Retrylogica en connection reuse: de Node.js Fetch API productieklaar maken
Native fetch heeft geen ingebouwde retry. Een korte netwerkstoring of een tijdelijke 503 betekent gewoon dat het verzoek mislukt. Voor de meeste read-operaties in productie is dat niet acceptabel.
Een composeerbare retry-wrapper met exponential backoff
Dit is bewust kort — ongeveer 10 regels echte logica:
1const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
2export async function fetchWithRetry(url, options = {}, retries = 2) {
3 for (let attempt = 0; ; attempt++) {
4 try {
5 const response = await fetch(url, options);
6 if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
7 return response;
8 }
9 if (attempt >= retries) return response;
10 } catch (error) {
11 if (attempt >= retries) throw error;
12 }
13 await wait(250 * 2 ** attempt); // 250ms, 500ms, 1000ms...
14 }
15}Wanneer je wel en niet moet retryen
- Wel retryen: Idempotente GET- en HEAD-verzoeken, tijdelijke statussen (408, 429, 500, 502, 503, 504), netwerkfluctuaties.
- Niet retryen: Niet-idempotente POST-verzoeken die records aanmaken, geld afschrijven of side effects veroorzaken — tenzij je idempotency keys gebruikt.
- Houd rekening met Retry-After: Controleer bij 429 (rate limit) en 503 (service unavailable) de
Retry-After-header vóór je backoff toepast.
Als je liever geen eigen retrylogica bouwt, is een lichte fetch-wrapper die retry, timeout, hooks en HTTPError standaard toevoegt — zonder dependencies.
Connection reuse met Undici's Agent en Pool
Voor loops met hoge throughput — honderden pagina's scrapen, een API in batches aanroepen, een service pollen — bespaart het hergebruiken van TCP-verbindingen veel tijd. Elke nieuwe verbinding betekent een verse DNS-lookup, TCP-handshake en (voor HTTPS) TLS-handshake.
Omdat Node's fetch wordt aangedreven door Undici, kun je een aangepaste dispatcher meegeven:
1import { Agent } from 'undici';
2const agent = new Agent({
3 keepAliveTimeout: 10_000,
4 keepAliveMaxTimeout: 60_000,
5});
6const response = await fetch('https://api.example.com/data', {
7 dispatcher: agent,
8});Voor nog meer controle met een specifieke origin:
1import { Pool } from 'undici';
2const pool = new Pool('https://api.example.com', { connections: 10 });
3const response = await fetch('https://api.example.com/data', {
4 dispatcher: pool,
5});
6// Wanneer klaar:
7await pool.close();De laten zien dat connection reuse en pooling de throughput drastisch kunnen verbeteren — undici - dispatch haalde in hun lokale benchmark ongeveer 22.234 req/sec versus ongeveer 5.904 req/sec voor undici - fetch. In de praktijk verschillen de cijfers, maar de richting is duidelijk: als je veel requests naar dezelfde origin doet, is pooling belangrijk.
Nog één ding: consumeer of annuleer response bodies altijd. Niet-geconsumeerde bodies kunnen resource leaks veroorzaken in Node's HTTP-internals.
Responses streamen met de Node.js Fetch API
Grote bestanddownloads, chunked JSON-feeds, server-sent events, LLM-output — dit zijn gevallen waarin wachten op de volledige response vóór verwerking tijd en geheugen verspilt. Streaming laat je data verwerken terwijl die binnenkomt.
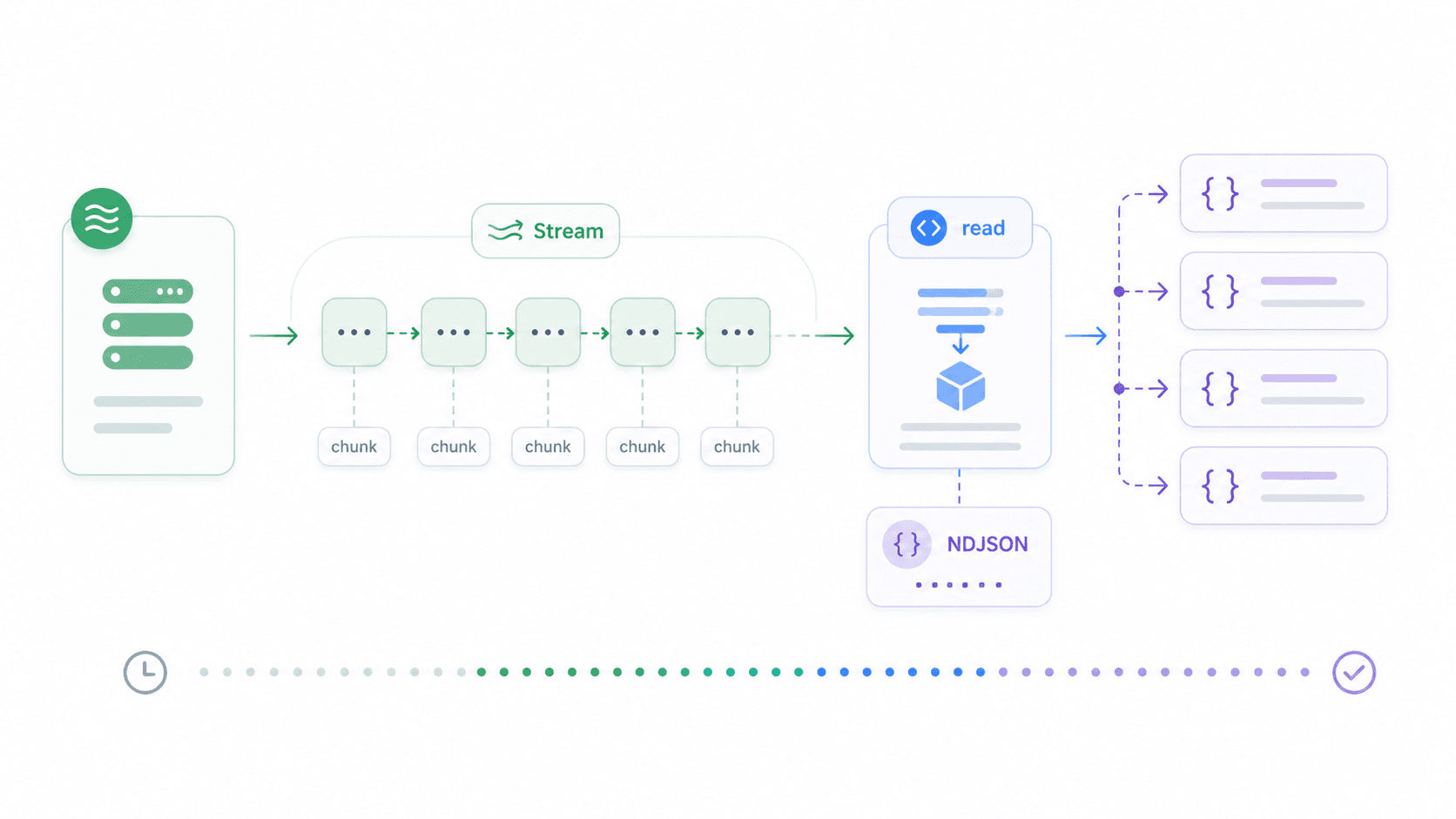
Node 18+ bevat browser-compatibele ReadableStream. Zo stream je een newline-delimited JSON-response en verwerk je elke regel zodra die binnenkomt:
1const response = await fetch('https://example.com/large-file.ndjson');
2if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
3const reader = response.body.getReader();
4const decoder = new TextDecoder();
5let buffer = '';
6while (true) {
7 const { value, done } = await reader.read();
8 if (done) break;
9 buffer += decoder.decode(value, { stream: true });
10 let newlineIndex;
11 while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
12 const line = buffer.slice(0, newlineIndex).trim();
13 buffer = buffer.slice(newlineIndex + 1);
14 if (line) {
15 const item = JSON.parse(line);
16 console.log('Verwerkt:', item.id);
17 }
18 }
19}Voor simpelere tekststreaming (bijv. LLM-output naar stdout pipen):
1const response = await fetch('https://example.com/stream');
2const reader = response.body.getReader();
3const decoder = new TextDecoder();
4for (;;) {
5 const { value, done } = await reader.read();
6 if (done) break;
7 process.stdout.write(decoder.decode(value, { stream: true }));
8}Streaming is een gebied waar native fetch en Got allebei sterk zijn. Axios' streaming-ondersteuning is beperkter.
Երբ fetch() tegen zijn grenzen aanloopt: gestructureerde webscraping met API's
Op een gegeven moment is fetch niet langer de bottleneck. Het echte probleem wordt: "Ik heb HTML, en nu?"
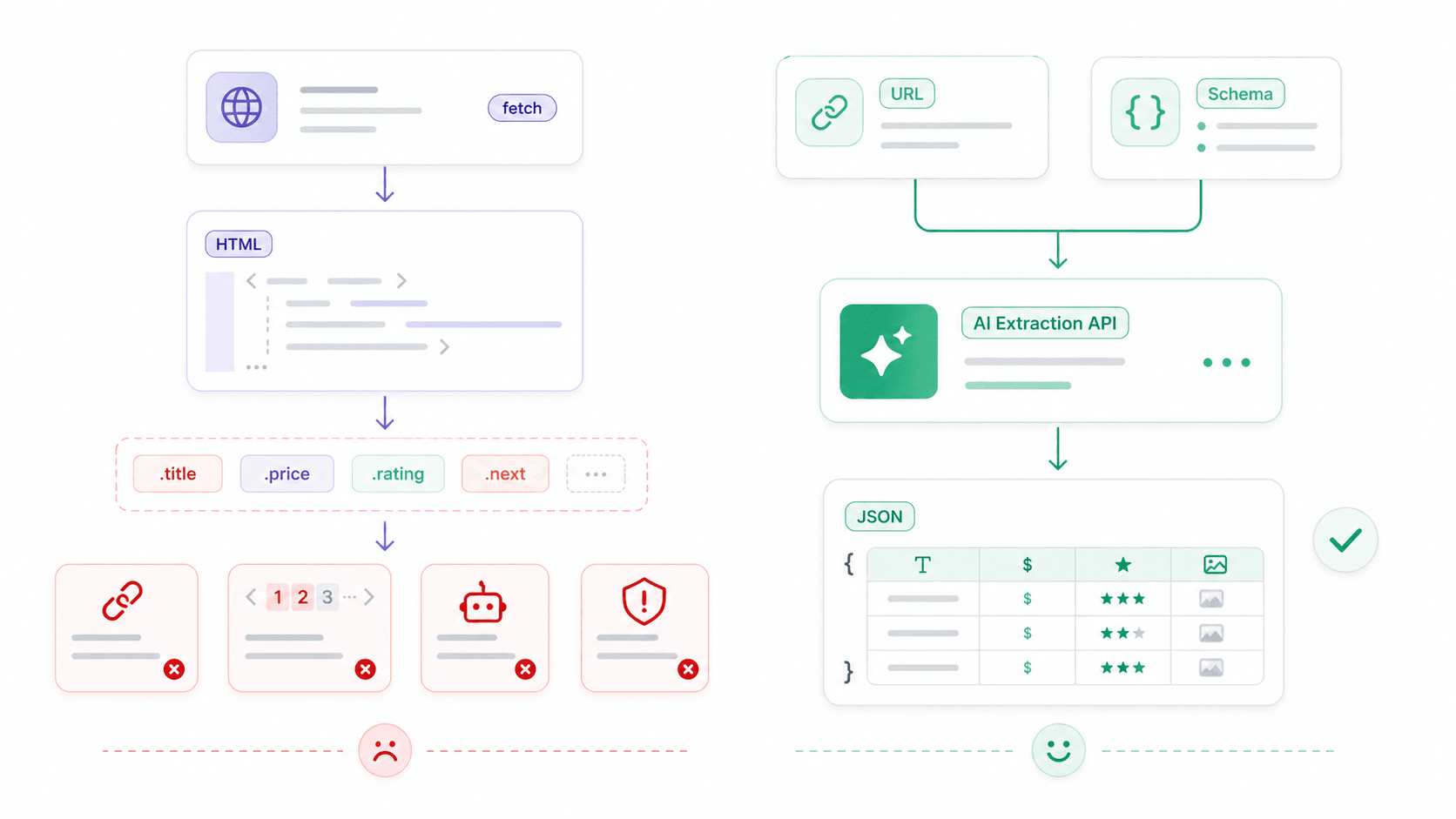
Fetch is een HTTP-client — het haalt bytes, tekst, JSON of HTML op. Het heeft geen concept van een productkaart, een prijs, een beoordeling of een contacttabel. Voor gestructureerde webscraping ziet de gebruikelijke ruwe stack er zo uit:
fetch()om HTML te downloaden- Cheerio (of iets vergelijkbaars) om elementen te selecteren met CSS-selectors
- Aangepaste pagineringslogica
- JavaScript-rendering wanneer pagina's client-side zijn
- Afhandeling van proxy/anti-bot/CAPTCHA
- Selector-onderhoud telkens wanneer de lay-out van de site verandert
Hier is een typisch fetch + Cheerio-voorbeeld — ongeveer 15 regels om producttitels te scrapen:
1import * as cheerio from 'cheerio';
2const response = await fetch('https://example-store.com/products');
3if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
4const html = await response.text();
5const $ = cheerio.load(html);
6const products = $('.product-card')
7 .map((_, el) => ({
8 name: $(el).find('.product-title').text().trim(),
9 price: $(el).find('.price').text().trim(),
10 url: new URL($(el).find('a').attr('href'), response.url).href,
11 }))
12 .get();
13console.log(products);Dit werkt voor stabiele pagina's met voorspelbare HTML. Het wordt snel kwetsbaar — JavaScript-gerenderde content, veranderende class-namen, anti-botmaatregelen en paginering voegen allemaal complexiteit toe.
Thunderbit's Open API: van ruwe HTML naar gestructureerde data in één call
Hier wordt een ander soort tool nuttig. Bij hebben we een API-laag gebouwd die de lastige onderdelen afhandelt — JavaScript-rendering, anti-botbescherming, layoutwijzigingen — zodat jij je kunt focussen op de data die je echt wilt.
Distill API (POST /distill): zet elke URL om naar schone Markdown. Handig voor LLM's, knowledge bases of contentanalyse — je hebt geen HTML-parser nodig.
Extract API (POST /extract): definieer een JSON Schema dat de gestructureerde data beschrijft die je wilt (productnaam, prijs, beoordeling), en AI extraheert die data. Geen CSS-selectors, geen breuken als de lay-out verandert.
Hier is dezelfde product-scrapingtaak met Thunderbit's Extract API — aangeroepen met native fetch:
1const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
2 method: 'POST',
3 headers: {
4 Authorization: `Bearer $\{process.env.THUNDERBIT_API_KEY\}`,
5 'Content-Type': 'application/json',
6 },
7 body: JSON.stringify({
8 url: 'https://example-store.com/products',
9 renderMode: 'basic',
10 schema: {
11 type: 'object',
12 properties: {
13 products: {
14 type: 'array',
15 items: {
16 type: 'object',
17 properties: {
18 name: { type: 'string', description: 'Productnaam' },
19 price: { type: 'string', description: 'Weergegeven productprijs' },
20 rating: { type: 'number', description: 'Gemiddelde klantbeoordeling' },
21 },
22 required: ['name', 'price'],
23 },
24 },
25 },
26 required: ['products'],
27 },
28 }),
29});
30if (!response.ok) throw new Error(`Thunderbit API: $\{response.status\}`);
31const result = await response.json();
32console.log(result.data);De vergelijking: ~15 regels fetch + Cheerio (plus kwetsbare selectors) versus één API-call die schone JSON teruggeeft. Voor batchtaken ondersteunt Thunderbit tot 50 URL's per batch-extractcall en tot 100 URL's per batch-distillcall.
Thunderbit is geen vervanging voor fetch — fetch is het transport. Thunderbit is de extractielaag die je gebruikt wanneer het parsen van ruwe HTML het echte probleem wordt. Als je nieuwsgierig bent naar de prijs, geeft het je 600 API-units om mee te experimenteren, en betaalde plannen beginnen bij $6/maand. Je kunt ook de bekijken voor no-code extractie direct in je browser.
Voor meer over gestructureerde scraping-aanpakken behandelen onze gidsen over , en specifieke workflows in detail.
Snelle referentie: Node.js Fetch API cheat sheet
Dit onderdeel is bedoeld om te bookmarken. Kom hier terug wanneer je een patroon nodig hebt om te copy-pasten.
| Patroon | Fragment |
|---|---|
| Basis GET | const res = await fetch(url); const data = await res.json(); |
| Basis POST | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| HTTP-foutcheck | if (!res.ok) throw new Error(\HTTP ${res.status}`);` |
| Timeout (simpel) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| Handmatige abort | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| Retry-statusen | Retry 408, 429, 500, 502, 503, 504. Retry POST niet blind. |
| JSON-wrapper | Gebruik fetchJSON() om ok te checken, content-type te parsen en HTTPError te gooien. |
| Connection pool | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| Stream-chunks | const reader = res.body.getReader(); loop over await reader.read() |
| Gestructureerde extractie | Gebruik Thunderbit Extract API wanneer het doel velden van een webpagina zijn, niet ruwe HTML. |
Conclusie en belangrijkste inzichten
Native fetch in Node.js is in 2026 productieklaar — voor nieuwe projecten is node-fetch niet nodig, en je hebt geen standaard Axios-afhankelijkheid nodig. Maar ruwe fetch() alleen is geen volwaardige HTTP-strategie voor productie.
De vijf dingen die de meeste tutorials overslaan — en die deze gids behandelt:
- De error-valkuil:
fetch()gooit niet op 4xx/5xx. Controleer altijdresponse.okof gebruik een wrapper zoalsfetchJSON(). - Timeouts: Gebruik
AbortSignal.timeout()voor simpele gevallen.AbortSignal.timeout()gooitTimeoutError; handmatigecontroller.abort()gooitAbortError. - Retrylogica: Niet ingebouwd. Voeg exponential backoff toe voor idempotente requests en tijdelijke fouten. Of gebruik Ky voor fetch-stijl retry uit de doos.
- Connection reuse: Gebruik voor loops met hoge throughput Undici's
AgentofPoolvia dedispatcher-optie. - Gestructureerde extractie: Wanneer je data van webpagina's nodig hebt (niet alleen ruwe HTML), overweeg een extractie-API zoals Thunderbit in plaats van kwetsbare CSS-selectors te onderhouden.
De beslismatrix in één zin: gebruik native fetch voor de meeste projecten, Axios voor interceptors, Got voor ingebouwde retry en HTTP/2, Ky voor fetch met betere defaults, en Thunderbit's API wanneer je fetch-gebaseerde scraping-scripts te complex worden om te onderhouden.
Probeer de patronen in deze gids. En als je wilt zien hoe Thunderbit gestructureerde extractie afhandelt, is het een goed startpunt — of bekijk een walkthrough op het .
FAQ's
1. Zit fetch ingebouwd in Node.js of moet ik het installeren?
Fetch zit ingebouwd in Node.js 18 en later — installatie is niet nodig. Het werd stabiel in Node 21 en wordt volledig ondersteund in Node 22 LTS en Node 24 LTS. Voor oudere Node-versies kun je het npm-pakket node-fetch gebruiken, maar nieuwe projecten zouden een ondersteunde LTS-release moeten targeten.
2. Gooit fetch een fout op 404- of 500-responses?
Nee. Fetch wijst zijn promise alleen af bij netwerkfouten (DNS-fouten, geen connectiviteit, geannuleerde verzoeken). HTTP-responses zoals 404, 403 en 500 worden normaal opgelost met response.ok === false. Je moet expliciet response.ok of response.status controleren — of een wrapper gebruiken zoals de fetchJSON()-functie uit deze gids.
3. Hoe voeg ik een timeout toe aan fetch in Node.js?
De simpelste aanpak is AbortSignal.timeout(ms), beschikbaar in Node 18.11+: await fetch(url, { signal: AbortSignal.timeout(5000) }). Dat gooit een TimeoutError als het verzoek langer dan 5 seconden duurt. Voor meer controle maak je handmatig een AbortController aan en roep je controller.abort() aan vanuit een setTimeout. Vang AbortError op voor het handmatige patroon en TimeoutError voor AbortSignal.timeout().
4. Kan ik fetch gebruiken voor webscraping in Node.js?
Ja, maar fetch geeft alleen ruwe HTML terug. Je hebt een parser zoals Cheerio nodig om specifieke elementen te extraheren, plus eigen logica voor paginering, JavaScript-gerenderde pagina's en anti-botmaatregelen. Voor gestructureerde data-extractie op schaal — waarbij je schone JSON wilt met productnamen, prijzen of contactgegevens — kun je overwegen, die AI gebruikt om gestructureerde data terug te geven zonder CSS-selectors of code die afhankelijk is van de lay-out.
5. Moet ik in 2026 overstappen van Axios naar native fetch?
Voor nieuwe projecten op Node 22+ is native fetch een sterke standaard. Het heeft geen dependencies, werkt met Promise's en deelt dezelfde API als browser-fetch. Houd Axios als je vertrouwt op request/response-interceptors, standaard afwijzing op HTTP-fouten of backward compatibility met oudere Node-versies nodig hebt. Beide zijn geldige keuzes — de beslissing hangt af van welke functies je project echt gebruikt.
Meer leren