Het internet zit bomvol data en elk bedrijf wil daar natuurlijk een graantje van meepikken. Maar laten we eerlijk zijn: handmatig info kopiëren van honderden webpagina’s is niet bepaald een feestje (en ook totaal niet efficiënt). Hier komt node webscraping om de hoek kijken. De laatste jaren zie ik steeds meer teams—van sales tot operations en marktonderzoek—automatisering inzetten om waardevolle inzichten op grote schaal van het web te halen. De wereldwijde webscraping-markt gaat zelfs naar verwachting boven de , en het zijn allang niet meer alleen de grote techspelers die hiervan profiteren. Of je nu prijzen wilt monitoren in e-commerce of leads wilt genereren, node webscraping is razendsnel een must-have skill geworden voor iedereen die voorop wil blijven lopen.
Benieuwd hoe je met Node.js data van websites kunt halen—of waarom Node.js zo krachtig is voor het scrapen van dynamische, JavaScript-rijke sites? Dan is deze gids echt iets voor jou. Ik leg uit wat node webscraping precies inhoudt, waarom het zo waardevol is voor bedrijven, en hoe je zelf een scraper opzet vanaf nul. En als je liever direct resultaat wilt, laat ik ook zien hoe tools als je uren werk (en frustratie) kunnen besparen door het proces te automatiseren. Klaar om het web om te toveren tot jouw persoonlijke databron? Laten we erin duiken.
Wat is Node Webscraping? Jouw ticket naar geautomatiseerde data-extractie
Heel simpel gezegd betekent node webscraping dat je met Node.js (de populaire JavaScript-runtime) automatisch info van websites haalt. Zie het als een supersnelle robot die webpagina’s bezoekt, de inhoud leest en precies die gegevens verzamelt die jij nodig hebt—of dat nu productprijzen, contactgegevens of het laatste nieuws is.
Zo werkt het in grote lijnen:
- Je Node.js-script stuurt een HTTP-verzoek naar een website (net als je browser).
- Het haalt de ruwe HTML van de pagina op.
- Met libraries als Cheerio kun je de HTML parsen en gericht data opvragen (vergelijkbaar met jQuery).
- Voor sites waar de inhoud via JavaScript wordt geladen (zoals moderne, interactieve webapps), kun je Puppeteer gebruiken om een echte browser aan te sturen, de pagina te renderen en de data te pakken zodra alles geladen is.
Waarom Node.js? JavaScript is dé taal van het web, en met Node.js kun je die ook buiten de browser gebruiken. Zo kun je zowel statische als dynamische sites scrapen, complexe interacties automatiseren (zoals inloggen of knoppen aanklikken) en razendsnel data verwerken. Dankzij de event-driven, non-blocking architectuur van Node kun je bovendien makkelijk veel pagina’s tegelijk verwerken—ideaal als je wilt opschalen.
Belangrijkste tools voor Node webscraping:
- Axios: Haalt webpagina’s op (regelt HTTP-verzoeken).
- Cheerio: Parseert en doorzoekt HTML van statische sites.
- Puppeteer: Automatiseert een echte browser voor JavaScript-rijke of interactieve sites.
Stel je een leger van onzichtbare browsers voor die data verzamelen terwijl jij rustig je koffie drinkt… zo ver zit je er niet naast.
Waarom Node Webscraping belangrijk is voor bedrijven
Eerlijk is eerlijk: webscraping is allang niet meer alleen voor hackers of dataspecialisten. Het is een echte business superkracht. Bedrijven in allerlei sectoren gebruiken node webscraping om:
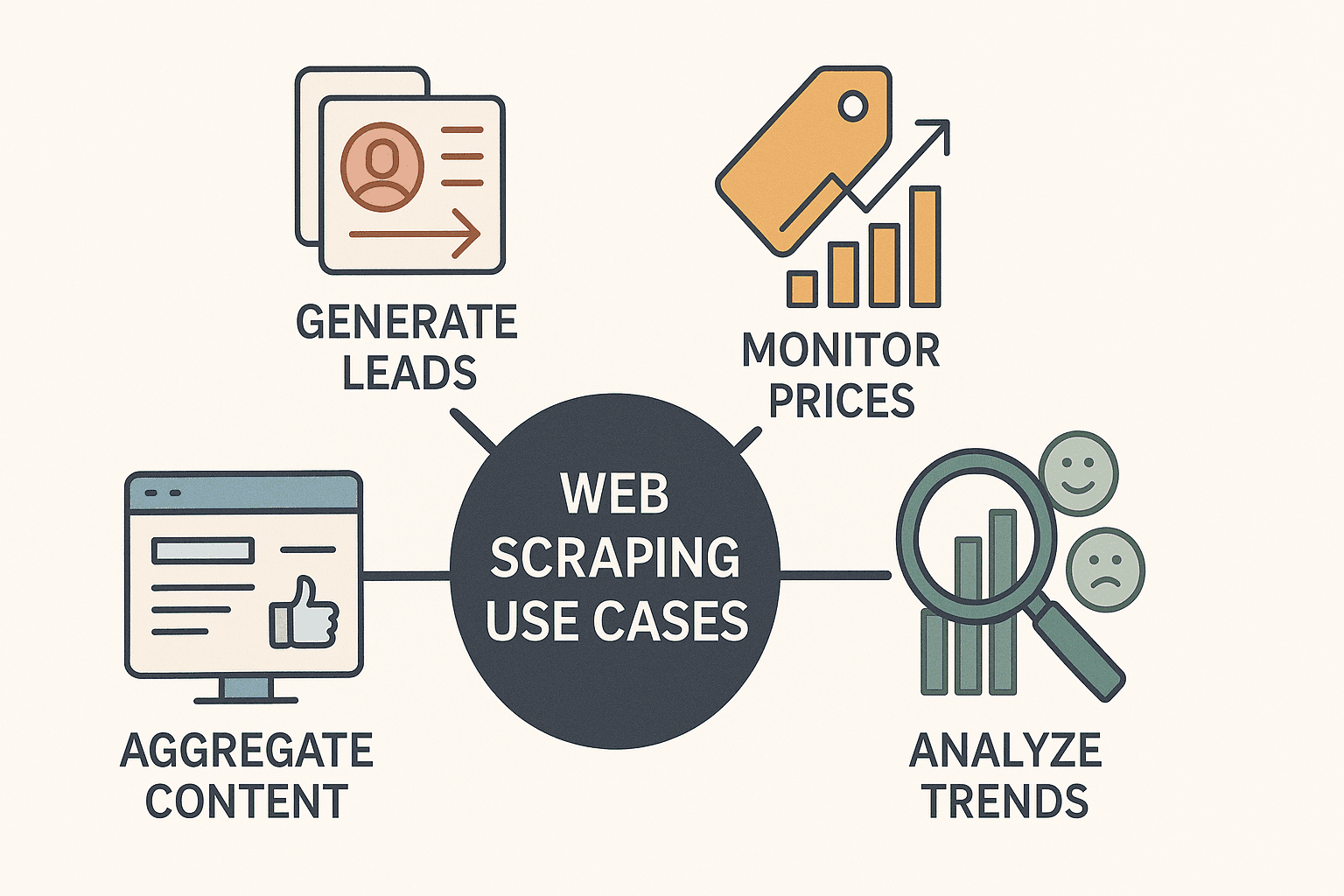
- Leads te genereren: Contactgegevens verzamelen uit bedrijvengidsen of LinkedIn voor sales.
- Concurrentieprijzen te monitoren: Productprijzen volgen en realtime je eigen prijzen aanpassen (meer dan doet dit dagelijks).
- Content te verzamelen: Dashboards bouwen met nieuws, reviews of social media mentions.
- Markttrends te analyseren: Reviews, fora of vacaturebanken scrapen voor sentiment en kansen.
En het mooiste? Met Node.js gaat dit sneller, flexibeler en makkelijker te automatiseren dan ooit. Dankzij de asynchrone opzet kun je tientallen of zelfs honderden pagina’s tegelijk verwerken, en door de JavaScript-basis is het dé keuze voor moderne websites.
Hier een overzicht van praktijkvoorbeelden:
| Use Case | Beschrijving & Voorbeeld | Voordeel van Node.js |
|---|---|---|
| Leadgeneratie | Bedrijvengidsen scrapen voor e-mails, namen en telefoonnummers. | Snel, parallel scrapen; makkelijke koppeling met CRM’s en API’s. |
| Prijsmonitoring | Concurrentieprijzen volgen op e-commerce sites. | Asynchrone verzoeken voor bulkpagina’s; eenvoudig plannen voor dagelijkse/uurcontroles. |
| Marktonderzoek | Reviews, fora of social posts verzamelen voor sentimentanalyse. | Flexibele datahandling; rijk ecosysteem voor tekstverwerking en opschoning. |
| Contentaggregatie | Nieuwsartikelen of blogs samenbrengen in één dashboard. | Realtime updates; naadloze integratie met notificatietools (Slack, e-mail, etc.). |
| Concurrentieanalyse | Productcatalogi, beschrijvingen en gebruikersbeoordelingen van concurrenten scrapen. | JavaScript-parsing voor complexe sites; modulaire code voor multi-pagina crawls. |
Node.js is vooral handig als je sites wilt scrapen die veel JavaScript gebruiken—iets waar Python en andere talen vaak moeite mee hebben. Met de juiste aanpak heb je in een paar minuten je spreadsheet met data klaar.
Node Webscraping Essentials: Tools en libraries die je nodig hebt
Voordat we in de code duiken, eerst de belangrijkste tools voor webscraping met Node.js:
1. Axios (HTTP-client)

- Wat het doet: Haalt webpagina’s op via HTTP-verzoeken.
- Wanneer gebruiken: Altijd als je de ruwe HTML van een pagina wilt ophalen.
- Waarom handig: Simpele, promise-based API; regelt redirects en headers moeiteloos.
- Installeren met:
npm install axios
2. Cheerio (HTML-parser)

- Wat het doet: Parseert HTML en laat je met jQuery-achtige selectors data vinden.
- Wanneer gebruiken: Voor statische sites waar de data direct in de HTML staat.
- Waarom handig: Snel, lichtgewicht en vertrouwd als je jQuery kent.
- Installeren met:
npm install cheerio
3. Puppeteer (Headless browser-automatisering)

- Wat het doet: Stuurt een echte Chrome-browser aan op de achtergrond, zodat je pagina’s kunt bedienen als een gebruiker.
- Wanneer gebruiken: Voor JavaScript-rijke of interactieve sites (zoals infinite scroll, inloggen, pop-ups).
- Waarom handig: Kan knoppen aanklikken, formulieren invullen, scrollen en data pakken nadat scripts zijn uitgevoerd.
- Installeren met:
npm install puppeteer
Extra tip: Er zijn ook tools als Playwright (voor meerdere browsers) en frameworks als Apify’s Crawlee voor geavanceerde workflows, maar voor beginners zijn Axios, Cheerio en Puppeteer de belangrijkste.
Voorwaarden: Zorg dat je Node.js hebt geïnstalleerd. Start een nieuw project met npm init -y en installeer de bovenstaande libraries.
Stapsgewijs: Bouw je eerste Node Webscraper vanaf nul
Tijd om aan de slag te gaan! We bouwen een eenvoudige scraper met Axios en Cheerio om boekgegevens te verzamelen van de demo-site .
Stap 1: Haal de HTML van de pagina op
1import axios from 'axios';
2import { load } from 'cheerio';
3const startUrl = 'http://books.toscrape.com/';
4async function scrapePage(url) {
5 const resp = await axios.get(url);
6 const html = resp.data;
7 const $ = load(html);
8 // ...data extraheren volgt
9}Stap 2: Parse en extraheer de data
1$('.product_pod').each((i, element) => {
2 const title = $(element).find('h3').text().trim();
3 const price = $(element).find('.price_color').text().replace('£', '');
4 const stock = $(element).find('.instock').text().trim();
5 const ratingClass = $(element).find('p.star-rating').attr('class') || '';
6 const rating = ratingClass.split(' ')[1];
7 const relativeUrl = $(element).find('h3 a').attr('href');
8 const bookUrl = new URL(relativeUrl, startUrl).href;
9 console.log({ title, price, rating, stock, url: bookUrl });
10});Stap 3: Omgaan met paginering
1const nextHref = $('.next > a').attr('href');
2if (nextHref) {
3 const nextUrl = new URL(nextHref, url).href;
4 await scrapePage(nextUrl);
5}Stap 4: Data opslaan
Na het verzamelen van de data kun je deze opslaan als JSON- of CSV-bestand met Node’s fs-module.
1import fs from 'fs';
2// Na het scrapen:
3fs.writeFileSync('books_output.json', JSON.stringify(booksList, null, 2));
4console.log(`Scraped ${booksList.length} books.`);En voilà—je hebt een werkende Node.js webscraper! Deze aanpak werkt perfect voor statische sites, maar wat als je te maken hebt met JavaScript-gedreven pagina’s?
JavaScript-rijke pagina’s scrapen: Puppeteer gebruiken met Node Webscraping
Sommige websites verstoppen hun data achter lagen JavaScript. Als je die probeert te scrapen met Axios en Cheerio, krijg je vaak een lege pagina of ontbrekende info. Hier biedt Puppeteer uitkomst.
Waarom Puppeteer? Het start een echte (headless) browser, laadt de pagina, wacht tot alle scripts zijn uitgevoerd en laat je dan de gerenderde inhoud pakken—net als een echte gebruiker.
Voorbeeldscript met Puppeteer
1import puppeteer from 'puppeteer';
2async function scrapeWithPuppeteer(url) {
3 const browser = await puppeteer.launch({ headless: true });
4 const page = await browser.newPage();
5 await page.goto(url, { waitUntil: 'networkidle2' });
6 await page.waitForSelector('.product_pod'); // Wacht tot data geladen is
7 const data = await page.evaluate(() => {
8 let items = [];
9 document.querySelectorAll('.product_pod').forEach(elem => {
10 items.push({
11 title: elem.querySelector('h3').innerText,
12 price: elem.querySelector('.price_color').innerText,
13 });
14 });
15 return items;
16 });
17 console.log(data);
18 await browser.close();
19}Wanneer Cheerio/Axios gebruiken en wanneer Puppeteer:
- Cheerio/Axios: Snel, lichtgewicht, ideaal voor statische content.
- Puppeteer: Iets trager, maar onmisbaar voor dynamische of interactieve pagina’s (inloggen, infinite scroll, enz.).
Tip: Probeer altijd eerst Cheerio/Axios voor de snelheid. Mis je data? Schakel dan over op Puppeteer.
Geavanceerd scrapen met Node: paginering, inloggen en data opschonen
Als je de basis onder de knie hebt, kun je aan de slag met complexere scenario’s.
Paginering verwerken
Loop door pagina’s door “volgende” links te detecteren of door URL’s te genereren als ze een patroon volgen.
1let pageNum = 1;
2while (true) {
3 const resp = await axios.get(`https://example.com/products?page=${pageNum}`);
4 // ...data extraheren
5 if (!hasNextPage) break;
6 pageNum++;
7}Automatisch inloggen
Met Puppeteer kun je inlogformulieren invullen zoals een echte gebruiker:
1await page.type('#username', 'myUser');
2await page.type('#password', 'myPass');
3await page.click('#loginButton');
4await page.waitForNavigation();Data opschonen
Na het scrapen kun je je data opschonen door:
- Duplicaten te verwijderen (gebruik een Set of filter op unieke sleutels).
- Nummers, datums en tekst te formatteren.
- Ontbrekende waarden op te vullen (met null) of onvolledige records over te slaan.
Reguliere expressies en de string-methodes van JavaScript zijn hierbij je beste vrienden.
Best practices voor Node Webscraping: valkuilen vermijden en efficiënt blijven
Webscraping is krachtig, maar kent ook uitdagingen. Zo voorkom je de meest voorkomende problemen:
- Respecteer robots.txt en sitevoorwaarden: Controleer altijd of een site scraping toestaat en blijf uit verboden delen.
- Vertraag je verzoeken: Stuur niet honderden verzoeken per seconde. Voeg vertragingen toe en randomiseer ze om menselijk gedrag na te bootsen ().
- Wissel user agents en IP’s af: Gebruik realistische headers en roteer IP-adressen bij grootschalig scrapen om blokkades te voorkomen.
- Foutafhandeling: Vang uitzonderingen op, probeer mislukte verzoeken opnieuw en log fouten voor debugging.
- Valideer je data: Controleer op ontbrekende of foutieve velden om veranderingen in de site snel te signaleren.
- Schrijf modulaire, onderhoudbare code: Splits ophalen, parsen en opslaan. Gebruik configuratiebestanden voor selectors en URL’s.
En het allerbelangrijkste: scrape ethisch. Het web is van iedereen, niemand zit te wachten op een onbeleefde bot.
Thunderbit vs. zelf bouwen: wanneer kies je voor een tool, wanneer voor eigen code?
Tijd voor de hamvraag: zelf een scraper bouwen of een tool als gebruiken?
Zelf een Node.js scraper bouwen:
- Voordelen: Volledige controle, volledig aanpasbaar, integreert met elke workflow.
- Nadelen: Programmeerkennis vereist, kost tijd om op te zetten en te onderhouden, breekt als sites veranderen.
Thunderbit AI-webscraper:
- Voordelen: Geen code nodig, AI herkent velden automatisch, ondersteunt subpagina’s en paginering, direct exporteren naar Excel, Google Sheets, Notion en meer (). Onderhoudsvrij—de AI past zich automatisch aan sitewijzigingen aan.
- Nadelen: Minder flexibel voor zeer specifieke of complexe workflows (maar dekt 99% van de zakelijke toepassingen).
Hier een snelle vergelijking:
| Aspect | Zelf Node.js Scraper | Thunderbit AI-webscraper |
|---|---|---|
| Technische kennis | Programmeren vereist | Geen code, point-and-click |
| Opzetduur | Uren tot dagen | Minuten (AI stelt velden voor) |
| Onderhoud | Doorlopend (sitewijzigingen) | Minimaal (AI past zich aan) |
| Dynamische content | Handmatig Puppeteer instellen | Ingebouwd |
| Paginering/subpagina’s | Handmatig coderen | 1-klik subpagina/paginering |
| Data exporteren | Handmatig code schrijven | 1-klik naar Excel, Sheets, Notion |
| Kosten | Gratis (dev-tijd, proxies) | Gratis tier, betalen per gebruik |
| Beste keuze voor | Developers, maatwerk | Zakelijke gebruikers, snel resultaat |
Thunderbit is een uitkomst voor sales-, marketing- en operationele teams die direct data nodig hebben—niet pas na een week coderen en debuggen. En voor developers is het ideaal om snel te prototypen of routinematige scraping-taken te automatiseren.
Conclusie & belangrijkste inzichten: begin vandaag nog met Node Webscraping
Node webscraping opent de deur naar verborgen webdata—of je nu leads verzamelt, prijzen monitort of je volgende grote idee voedt. Onthoud vooral:
- Node.js + Cheerio/Axios is ideaal voor statische sites; Puppeteer is onmisbaar voor dynamische, JavaScript-gedreven pagina’s.
- Zakelijke impact is groot: Bedrijven die webscraping inzetten voor datagedreven beslissingen boeken aantoonbare resultaten, van tot het verdubbelen van internationale verkopen.
- Begin eenvoudig: Bouw eerst een basis-scraper en voeg daarna functies toe zoals paginering, login-automatisering en data cleaning.
- Kies het juiste gereedschap: Voor snelle, no-code scraping en direct resultaat is onovertroffen. Voor maatwerk en integratie biedt zelf bouwen met Node.js maximale controle.
- Scrape verantwoord: Respecteer sitebeleid, doseer je bots en houd je code overzichtelijk en onderhoudbaar.
Klaar om te beginnen? Zet je eigen Node.js scraper op, of en ontdek hoe eenvoudig webdata verzamelen kan zijn. Meer tips? Bekijk de voor diepgaande artikelen, tutorials en het laatste nieuws over AI-gedreven scraping.
Veel succes met scrapen—en moge je data altijd actueel, gestructureerd en een stap voor zijn op de concurrentie.
Veelgestelde vragen
1. Wat is node webscraping en waarom is Node.js hiervoor geschikt?
Node webscraping is het automatisch verzamelen van data van websites met Node.js. Node.js is hiervoor ideaal omdat het efficiënt omgaat met asynchrone verzoeken en uitblinkt in het scrapen van JavaScript-rijke sites dankzij tools als Puppeteer.
2. Wanneer gebruik ik Cheerio/Axios en wanneer Puppeteer?
Gebruik Cheerio en Axios voor statische sites waar de data direct in de HTML staat. Gebruik Puppeteer als je content moet scrapen die door JavaScript wordt geladen, moet inloggen of te maken hebt met infinite scroll.
3. Wat zijn de meest voorkomende zakelijke toepassingen van node webscraping?
Belangrijke toepassingen zijn leadgeneratie, prijsmonitoring bij concurrenten, contentaggregatie, marktanalyse en het scrapen van productcatalogi. Node.js maakt deze taken snel en schaalbaar.
4. Wat zijn de grootste valkuilen bij node webscraping en hoe voorkom ik die?
Veelvoorkomende valkuilen zijn blokkades door anti-botmaatregelen, veranderingen in sitestructuur en datakwaliteit. Voorkom dit door verzoeken te vertragen, user agents/IP’s te roteren, je data te valideren en modulaire code te schrijven.
5. Hoe verhoudt Thunderbit zich tot zelf een Node.js scraper bouwen?
Thunderbit biedt een no-code, AI-gedreven oplossing die automatisch velden, subpagina’s en paginering herkent. Ideaal voor zakelijke gebruikers die snel resultaat willen, terwijl zelf bouwen met Node.js het beste is voor developers die volledige controle of integratie wensen.
Meer inspiratie? Bezoek de en abonneer je op ons voor praktische tutorials.
Meer weten