De snelheid waarmee digitaal nieuws zich tegenwoordig ontwikkelt, is ronduit duizelingwekkend. Elke minuut worden duizenden koppen gepubliceerd, bijgewerkt of stilletjes aangepast — bij grote nieuwssites, nicheblogs en op sociale feeds.
Om dat in perspectief te plaatsen: verwerkt elke dag meer dan 4 miljoen nieuwsartikelen, terwijl het nieuws in 100+ talen volgt en zijn wereldwijde feed elke 15 minuten bijwerkt.
Voor iedereen in media, onderzoek of business intelligence voelt proberen bij te blijven met die stroom alsof je een zinkend schip leegschept met een koffiebekertje.
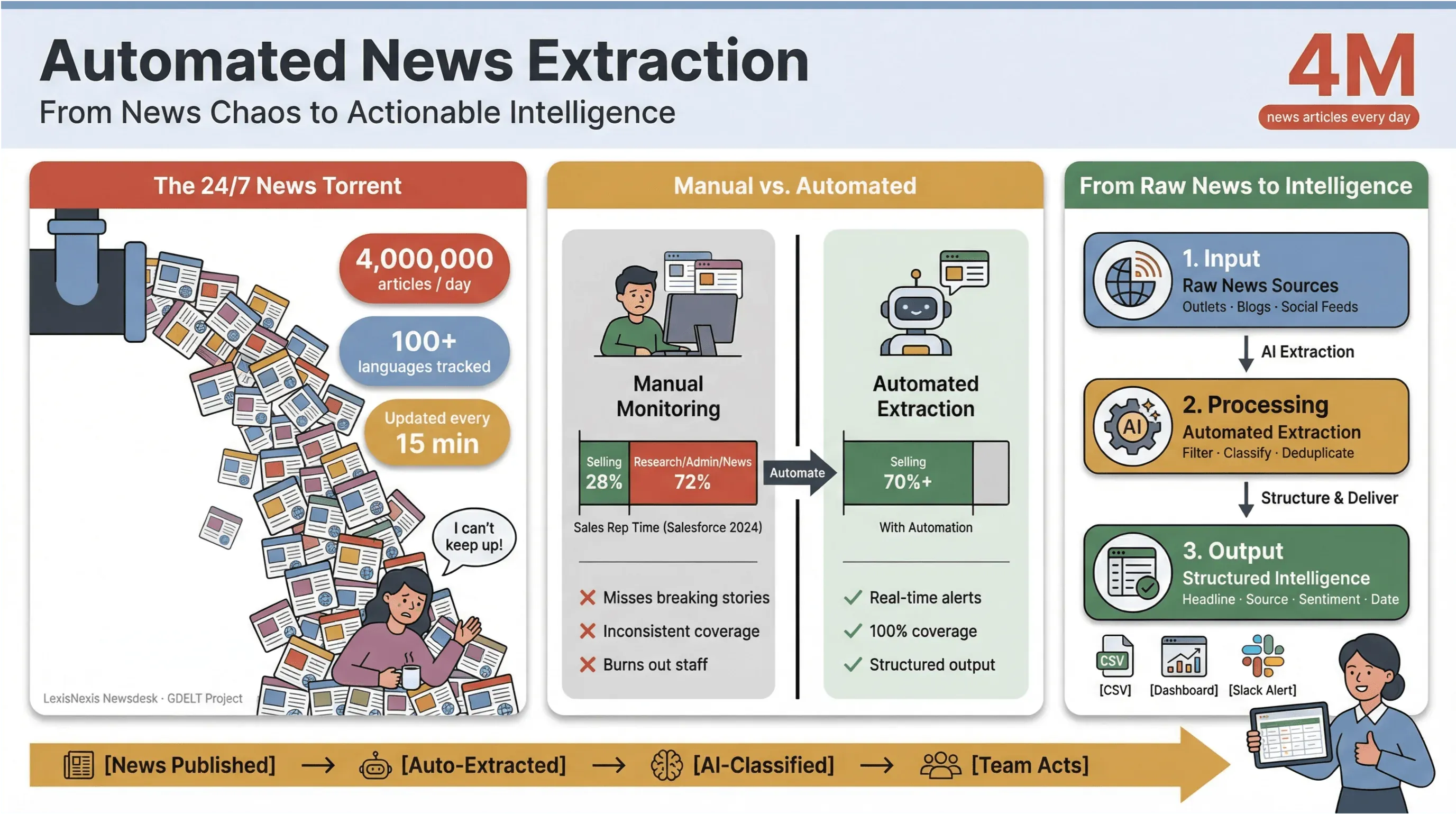
Ik heb uit eerste hand gezien hoeveel tijd handmatige nieuwsmonitoring opslokt en hoeveel middelen het verbruikt. Salesteams besteden minder dan een derde van hun week daadwerkelijk aan verkopen — — en de rest gaat op aan onderzoek, administratie en ja, eindeloos schakelen tussen nieuwstabbladen.
Daarom is geautomatiseerd nieuws extraheren hét geheime wapen van moderne teams geworden: het is de enige manier om de chaos van de 24/7-nieuwscyclus om te zetten in gestructureerde, bruikbare inzichten — zonder je team op te branden of de belangrijkste verhalen te missen.
Laten we eens kijken wat geautomatiseerd nieuws extraheren nu echt inhoudt, waarom het onmisbaar is voor iedereen die om realtime nieuwsdata geeft, en hoe je een robuuste, conforme workflow opzet met de beste tools (inclusief hoe het hele proces schokkend eenvoudig maakt — zelfs voor niet-techneuten zoals mijn moeder).
Geautomatiseerde nieuws-extractie: waarom het onmisbaar is voor moderne redacties
Geautomatiseerde nieuws-extractie is precies wat het klinkt als: software gebruiken om nieuwsinhoud automatisch te verzamelen en om te zetten in gestructureerde, doorzoekbare data — denk aan rijen en kolommen in plaats van rommelige webpagina’s of pdf’s. In de praktijk betekent dit dat je honderden (of duizenden) bronnen kunt volgen, sleutelvelden zoals kop, tijdstempel, auteur en hoofdtekst kunt extraheren, en die data naar dashboards, alerts of downstream analytics kunt sturen — zonder ooit Ctrl+C/Ctrl+V aan te raken.
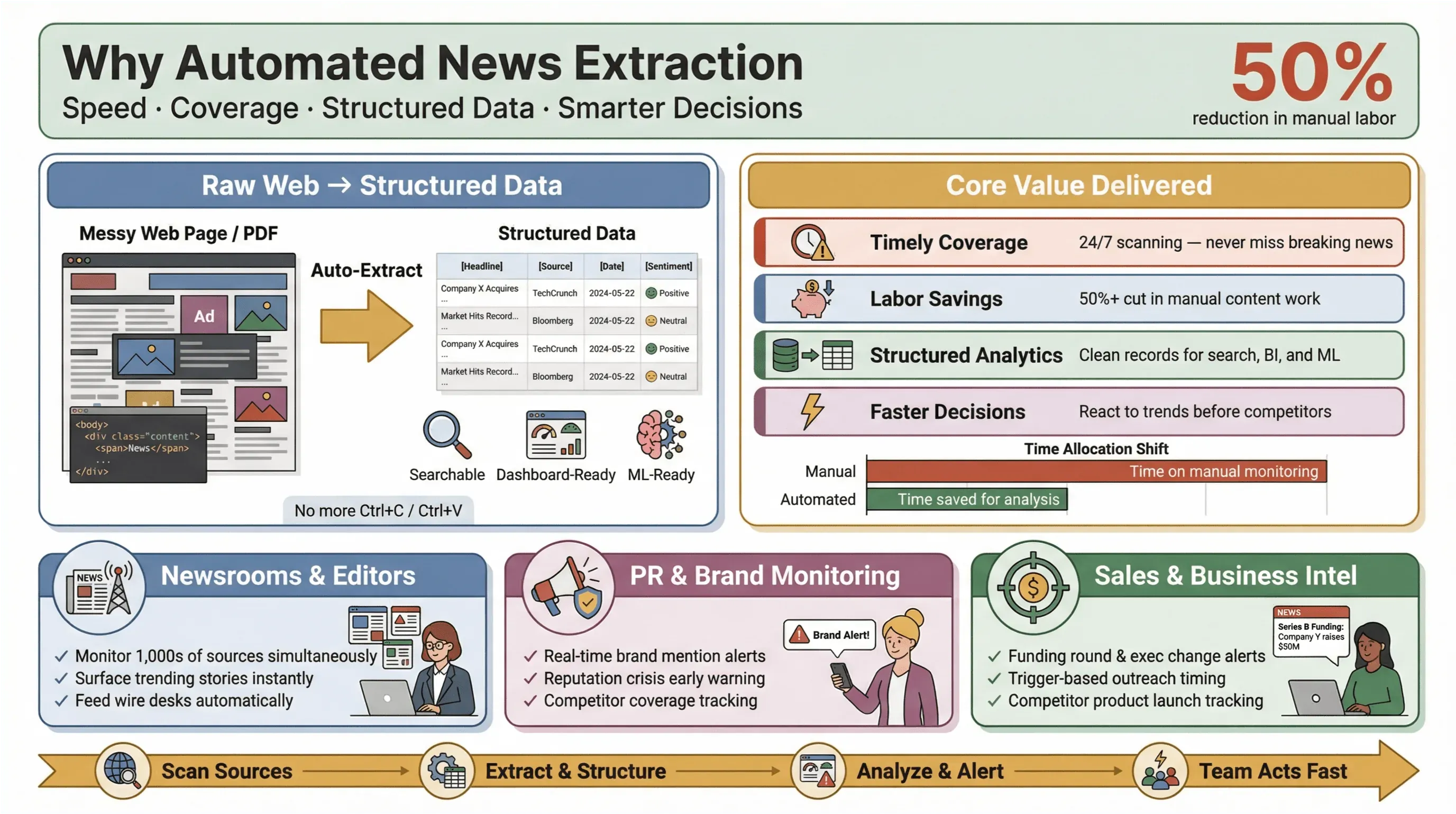 Waarom is dit belangrijk? Omdat in het huidige nieuwslandschap snelheid alles is. Of je nu een redacteur bent, een PR-manager die merkvermeldingen volgt, of een businessanalist die bewegingen van concurrenten monitort: als je als eerste weet wat er speelt, kan dat het verschil maken tussen een kans pakken en achter de feiten aanlopen. Geautomatiseerde extractietools stellen zelfs kleine teams in staat om boven hun gewicht te presteren — door realtime nieuwsdata van het hele web te verzamelen, handmatig werk te verminderen en de verhalen naar voren te halen die er het meest toe doen.
Waarom is dit belangrijk? Omdat in het huidige nieuwslandschap snelheid alles is. Of je nu een redacteur bent, een PR-manager die merkvermeldingen volgt, of een businessanalist die bewegingen van concurrenten monitort: als je als eerste weet wat er speelt, kan dat het verschil maken tussen een kans pakken en achter de feiten aanlopen. Geautomatiseerde extractietools stellen zelfs kleine teams in staat om boven hun gewicht te presteren — door realtime nieuwsdata van het hele web te verzamelen, handmatig werk te verminderen en de verhalen naar voren te halen die er het meest toe doen.
En de impact is echt: onderzoeken laten zien dat automatisering het handmatige werk voor content-updates met minstens 50% kan verminderen, waardoor er meer tijd vrijkomt voor echte analyse en besluitvorming.
De kernwaarde van geautomatiseerde nieuws-extractie in de nieuwssector
Laten we praktisch worden. Wat levert geautomatiseerde nieuws-extractie nu eigenlijk op voor redacties en zakelijke teams?
- Tijdige, volledige dekking: Geen breaking stories meer missen omdat iemand een feed niet heeft gecontroleerd. Geautomatiseerde tools scannen bronnen 24/7, zodat je niets mist.
- Besparing op arbeid en kosten: Kleine en middelgrote teams kunnen net zoveel bronnen volgen als de grote spelers — zonder een leger stagiairs aan te nemen.
- Gestructureerde data voor analytics: In plaats van ongestructureerde artikelen door te spitten, krijg je nette, gestructureerde records die klaar zijn voor search, dashboards en machine learning.
- Snellere, slimmere beslissingen: Realtime nieuwsdata betekent dat je kunt reageren op marktverschuivingen, PR-crises of opkomende trends voordat je concurrenten dat doen.
Neem PR en communicatie: platforms zoals en positioneren realtime media monitoring als essentieel om reputaties te beschermen en snel te reageren op schadelijke berichtgeving. In sales worden realtime nieuwsalerts “contextcards” voor prospecting — denk aan investeringsrondes, wisselingen in het management of productlanceringen die precies op het juiste moment een outreach triggeren.
De juiste nieuws-scrapingtools kiezen voor verschillende scenario’s
Niet alle nieuws-scrapingtools zijn gelijk. De juiste keuze hangt af van je doelen, je technische comfort en het type nieuws dat je wilt volgen. Hier is een kader om je te helpen de beste match te kiezen:
Gebruiksgemak en toegankelijkheid beoordelen
Voor de meeste zakelijke gebruikers en journalisten is gebruiksgemak niet-onderhandelbaar. Je wilt een tool die direct werkt, zonder coderen of ingewikkelde installatie. No-code- en low-codeplatforms zoals , en laten je scrapers visueel bouwen — gewoon aanwijzen, klikken en extraheren.
Thunderbit valt in het bijzonder op door zijn tweestapsproces: beschrijf wat je wilt, laat de AI velden voorstellen, en klik op “Scrape”. Zelfs niet-technische gebruikers kunnen binnen enkele minuten een nieuwsdatapijplijn opzetten, niet pas na uren.
Overwegingen rond beveiliging en gegevensprivacy
Met veel data komt veel verantwoordelijkheid. Nieuws-scrapingtools hebben vaak toegang tot gevoelige inhoud, dus beveiliging en compliance moeten bovenaan je lijst staan. Let op:
- Gegevensversleuteling (tijdens transport en in rust)
- Heldere privacybeleid (Thunderbit geeft bijvoorbeeld aan dat het geen gebruikersdata verkoopt en alleen toegang heeft tot content die je zelf kiest om te scrapen)
- Fijnmazige permissies (zeker voor browserextensies — controleer altijd tot welke data de tool toegang heeft)
- Naleving van lokale wetgeving (AVG/GDPR, CCPA en, voor EU-gebruikers, de )
Kies voor extra gemoedsrust betrouwbare leveranciers, controleer extensierechten en beperk de toegang tot alleen wat echt nodig is.
Tools afstemmen op nieuwstypen en branchebehoeften
Sommige tools blinken uit in specifieke nieuwsdomeinen:
- Finance: API’s zoals en bieden clustering, sentimentanalyse en eventdetectie voor financieel nieuws.
- Tech & startups: Aangepaste scraping met Thunderbit of Octoparse maakt het mogelijk om nicheblogs, persberichten of evenementoverzichten te targeten.
- Politiek & beleid: Gelicentieerde databases zoals en bieden toegang tot premiumbronnen en archieven.
Als je een mix van grote, niche- en internationale bronnen wilt volgen — inclusief bronnen zonder API’s — dan zijn flexibele, AI-gedreven scrapers zoals Thunderbit je beste keuze.
Thunderbit’s unieke voordelen voor realtime nieuwsdata-extractie
Laten we het nu hebben over wat Thunderbit een opvallende keuze maakt voor geautomatiseerde nieuws-extractie — vooral als je realtime nieuwsdata wilt zonder technische hoofdpijn.
Thunderbit is een AI-aangedreven webscraper Chrome-extensie die is ontworpen voor zakelijke gebruikers, journalisten en analisten die actuele, gestructureerde nieuwsinhoud van elke website nodig hebben. Daarom is het mijn vaste favoriet geworden:
- AI Suggest Fields: Thunderbit leest de nieuwspagina en stelt automatisch de beste kolommen voor om te extraheren — kop, tijdstempel, auteur, samenvatting en meer. Geen gedoe met selectors of templates.
- Subpage Scraping: Heb je het volledige artikel nodig, niet alleen de kop? Thunderbit kan elk nieuwslinkje bezoeken, de hoofdtekst, entiteiten en tags extraheren, en alles samenvoegen in één gestructureerde tabel.
- Bulkexport en directe updates: Exporteer je nieuwsdata met één klik rechtstreeks naar Excel, Google Sheets, Airtable of Notion. Geen eindeloze copy-paste-sessies of gedoe met CSV’s meer.
- Gepland scrapen: Stel terugkerende jobs in (elk uur, dagelijks of met een aangepaste interval) om je nieuws-pijplijn vers te houden — ideaal voor breaking news, marktmonitoring of lopend onderzoek.
- Aanpasbaarheid: Thunderbit’s AI past zich aan lay-outwijzigingen en long-tail-nieuwssites aan, zodat je minder tijd kwijt bent aan het repareren van kapotte scrapers en meer tijd hebt om data te analyseren.
Met meer dan en een beoordeling van 4,8 sterren wordt het wereldwijd vertrouwd voor alles van PR-monitoring tot competitieve intelligence.
AI-gedreven veldherkenning en subpage scraping
Een van Thunderbit’s sterkste functies is de AI-gedreven veldherkenning. Klik gewoon op “AI Suggest Fields” en de tool scant de nieuwspagina — waarna belangrijke velden zoals titel, datum, auteur en samenvatting worden geïdentificeerd. Je kunt aangepaste velden verfijnen of toevoegen (bijvoorbeeld: “label dit artikel als ‘earnings’ als het kwartaalcijfers noemt”), en de AI van Thunderbit doet de rest.
Subpage scraping is een gamechanger voor nieuws: scrape een homepage of sectielijst voor koppen, en laat Thunderbit vervolgens elke artikel-URL bezoeken om het volledige verhaal, entiteiten en zelfs afbeeldingen te extraheren. Zo krijg je complete, verrijkte nieuwsrecords — klaar voor search, dashboards of downstream AI-analyse.
Bulkexport en directe updates
Thunderbit maakt het exporteren van nieuwsdata pijnloos. Met één klik stuur je je gestructureerde nieuwsfeed naar Google Sheets, Airtable of Notion, of download je deze als CSV/Excel. Voor teams die leven in spreadsheets of BI-tools is dat een enorme tijdsbesparing.
En omdat Thunderbit gepland scrapen ondersteunt, kun je het elk uur, elke dag of volgens je eigen schema laten draaien — zodat je nieuwsdata altijd actueel is. Geen wachten meer tot Google Alerts verhalen dagen later oppikt.
Operationele uitdagingen bij realtime nieuwsdata-oplossingen overwinnen
Zelfs met de beste tools brengt realtime nieuws-extractie zijn eigen uitdagingen met zich mee. Zo pak je de meest voorkomende aan:
Latentie en versheid van data beheren
- Plan scrapes op basis van nieuws-snelheid: Voor breaking news stel je scrapers in op elke 15–30 minuten (in lijn met de ). Voor langzamere onderwerpen kunnen dagelijks of elk uur voldoende zijn.
- Monitor de vertraging tussen publiceren en ophalen: Houd het verschil bij tussen het moment waarop een artikel wordt gepubliceerd en wanneer je systeem het ophaalt. Als de vertraging oploopt, controleer dan op blokkades of vertragingen.
- Her-scrape voor “stille bewerkingen”: Nieuwsartikelen worden vaak na publicatie aangepast. Plan 24 uur later een tweede scrape om correcties of stilzwijgende wijzigingen mee te pakken ().
API-limieten en variatie tussen bronnen aanpakken
- Respecteer API-quotas: Als je nieuws-API’s gebruikt, let dan op rate limits — spreid verzoeken over de tijd en cache resultaten waar mogelijk ().
- Dedupliceer en canonicaliseer: Nieuwsverhalen verschijnen vaak op meerdere URL’s of worden bijgewerkt. Leg canonical URL’s vast en gebruik hashes (bijv. titel + datum) om duplicaten te vermijden ().
- Ga om met dynamische content: Voor sites met infinite scroll of lazy loading gebruik je tools die dynamische rendering ondersteunen en let je op lay-outwijzigingen ().
Slimme analyse van nieuwsdata: de rol van AI en machine learning
Nieuws extraheren is slechts de eerste stap. De echte waarde ontstaat door de data te analyseren en erop te handelen — en daar blinken AI en machine learning in uit.
- Entiteitsextractie: Gebruik NLP om personen, organisaties en plaatsen uit elk artikel te halen ().
- Onderwerpsclassificatie: Label artikelen automatisch op onderwerp, sentiment of urgentie — zodat je slimmere dashboards en alerts kunt bouwen ().
- Eventclustering: Groepeer dubbele of gerelateerde verhalen uit verschillende media, zodat je het grotere plaatje ziet (en niet alleen een vloedgolf van bijna identieke koppen).
- Personalisatie en targeting: Gebruik realtime nieuwsdata om doelgroepen te segmenteren, advertentietargeting te verbeteren of content aan te bevelen — wat engagement en ROI verhoogt.
PR-teams gebruiken realtime nieuwsanalytics bijvoorbeeld om opkomende crises te signaleren voordat ze viraal gaan, terwijl salesteams prospectlijsten verrijken met “trigger events” zoals financieringsrondes of nieuwe executives.
Checklist met best practices voor geautomatiseerde nieuws-extractie
Hier is een snelle checklist om je nieuws-extractiepijplijn soepel te laten draaien:
| Best practice | Waarom het belangrijk is | Hoe je het implementeert |
|---|---|---|
| Regelmatig scrapen plannen | Minimaliseer datavertraging, vang breaking news | Stem de updatefrequentie af op de nieuws-snelheid (bijv. elke 15 min voor snelle beats) |
| AI-gedreven extractie gebruiken | Past zich aan lay-outwijzigingen aan, vermindert insteltijd | Tools zoals Thunderbit, Diffbot, Zyte API |
| Dedupliceren en canonicaliseren | Voorkom dubbele alerts, zorg voor schone data | Leg canonical URL’s vast, gebruik hashes voor deduplicatie |
| Extractiekwaliteit monitoren | Mis je geen velden, drift of fouten | Volg % complete records, vertraging en foutpercentages |
| Juridische/compliancegrenzen respecteren | Vermijd juridisch risico, behoud vertrouwen | Geef voorkeur aan officiële API’s/feeds, review voorwaarden, minimaliseer persoonsgegevens |
| Exporteren naar gestructureerde formaten | Maak downstream analytics mogelijk | CSV, Excel, Sheets, Notion, Airtable |
| Her-scrapes voor bewerkingen inplannen | Pak wijzigingen na publicatie mee | Bezoek artikelen opnieuw na 24 uur/1 week (GDELT-model) |
| Beveilig je pijplijn | Bescherm gevoelige data | Versleuteling, toegangscontrole, betrouwbare tools |
Een robuuste workflow voor geautomatiseerde nieuws-extractie bouwen
Klaar om je eigen black box voor nieuwsdata te bouwen? Zo ziet een stapsgewijze workflow eruit:
- Identificeer je bronnen: Maak een lijst van nieuwswebsites, blogs of API’s die je wilt volgen.
- Stel de extractie in: Gebruik Thunderbit of je favoriete tool om velden te definiëren (AI Suggest Fields maakt dit heel eenvoudig).
- Plan scrapes: Stel de frequentie in op basis van de nieuws-snelheid — elk uur voor breaking news, dagelijks voor langzamere onderwerpen.
- Verrijk subpagina’s: Scrape bij elke kop het volledige artikel voor hoofdtekst, entiteiten en tags.
- Dedupliceer en normaliseer: Leg canonical URL’s vast, hash records en standaardiseer velden.
- Exporteer en integreer: Stuur gestructureerde data naar Excel, Google Sheets, Airtable of Notion voor analyse.
- Monitor en pas aan: Volg de kwaliteit van de extractie, let op lay-outwijzigingen en stel bij waar nodig.
- Blijf compliant: Controleer voorwaarden, respecteer robots.txt en minimaliseer persoonsgegevens.
Voor een visuele workflow, denk aan:
Bronnen → Extractie (AI-velden) → Subpage-verrijking → Deduplicatie → Export → Analyse/alerts → Monitoring
Conclusie & belangrijkste inzichten
Geautomatiseerde nieuws-extractie is niet langer iets “leuks om te hebben” — het is een must voor iedereen die voorop wil blijven lopen in een wereld waarin nieuws per minuut breekt (en verandert). Door best practices te volgen en de juiste tools te gebruiken, kun je de brandkraan van digitaal nieuws omzetten in een gestage stroom van bruikbare, gestructureerde inzichten.
Belangrijkste inzichten:
- De schaal en snelheid van online nieuws vragen om automatisering — handmatige monitoring kan simpelweg niet bijbenen.
- Tools voor geautomatiseerde nieuws-extractie besparen tijd, verlagen kosten en geven kleine teams de mogelijkheid om te concurreren met veel grotere organisaties op het gebied van dekking.
- De juiste tool kiezen betekent balanceren tussen gebruiksgemak, beveiliging en aanpasbaarheid — Thunderbit springt eruit door zijn AI-gedreven eenvoud en realtime exportopties.
- Bouw je workflow rond versheid, deduplicatie, compliance en kwaliteitsmonitoring om betrouwbare, bruikbare nieuwsdata te waarborgen.
- AI en machine learning ontsluiten nog meer waarde — voor slimmere targeting, personalisatie en besluitvorming.
Als je nog steeds koppen zit te kopiëren en plakken of wacht tot Google Alerts bij is, is het tijd om een stap hoger te gaan. en ontdek hoe eenvoudig geautomatiseerde nieuws-extractie kan zijn. Voor meer tips, workflows en diepgaande uitleg kun je de bekijken.
FAQ’s
1. Wat is geautomatiseerde nieuws-extractie en hoe werkt het?
Geautomatiseerde nieuws-extractie is het proces waarbij software nieuwsartikelen verzamelt en omzet in gestructureerde data (zoals tabellen of JSON) voor analyse, search of alerts. Tools zoals Thunderbit gebruiken AI om sleutelvelden (kop, tijdstempel, auteur, hoofdtekst) te identificeren en deze automatisch uit webpagina’s of API’s te extraheren.
2. Waarom zijn realtime nieuwsdata zo belangrijk voor bedrijven?
Realtime nieuwsdata stelt bedrijven in staat snel te reageren op marktgebeurtenissen, PR-crises of acties van concurrenten. Of je nu in sales, PR of onderzoek werkt: actuele nieuwsdata helpt je slimmer en sneller beslissingen te nemen en de concurrentie voor te blijven.
3. Hoe maakt Thunderbit nieuws scrapen makkelijker voor niet-technische gebruikers?
Thunderbit biedt een eenvoudig tweestapsproces: beschrijf welke data je wilt en laat de AI velden voorstellen. Met functies zoals subpage scraping en directe export naar Excel of Google Sheets kunnen zelfs niet-technische gebruikers binnen enkele minuten robuuste nieuwsdatapijplijnen opzetten.
4. Wat zijn de juridische en compliance-overwegingen bij nieuws scrapen?
Controleer altijd de gebruiksvoorwaarden van je doelwebsites, kies waar mogelijk voor officiële API’s of feeds, en respecteer robots.txt-richtlijnen. Scrape geen content achter login of betaalmuur zonder toestemming, en beperk het verzamelen van persoonsgegevens om aan privacywetgeving te voldoen.
5. Hoe zorg ik dat mijn workflow voor nieuws-extractie op lange termijn betrouwbaar blijft?
Plan regelmatige scrapes, monitor de kwaliteit van de extractie en gebruik tools die zich aanpassen aan lay-outwijzigingen (zoals Thunderbit’s AI-gedreven extractie). Dedupliceer records, volg de vertraging tussen publicatie en extractie, en stel alerts in voor fouten of ontbrekende velden om je pijplijn gezond en actueel te houden.
Meer weten