

In 2026 is webdata niet zomaar “handig om te hebben” — het is de levensader van bedrijfsstrategie. Van e-commercegiganten die de prijzen van concurrenten realtime volgen tot salesteams die hun pipeline vullen met verse leads: bedrijven behandelen openbare webdata als digitale olie. De cijfers liegen er niet om: bijna 65% van de ondernemingen gebruikt inmiddels webscraping- of data-extractietools, en meer dan 70% van de digitale bedrijven vertrouwt op openbare webdata voor marktinformatie. En terwijl Python alle aandacht krijgt, blijft Java nog altijd het werkpaard achter grootschalige, bedrijfskritische scrapingprojecten — vooral in enterprise-omgevingen waar betrouwbaarheid en integratie het belangrijkst zijn.
 Na jaren in SaaS en automatisering heb ik uit eerste hand gezien hoe Java-webscraping bedrijfsprocessen kan transformeren. Maar ik heb ook teams zien worstelen — vastgelopen in de krochten van laagwaardige code of overweldigd door dynamische websites en anti-botmaatregelen. Daarom deel ik met plezier een praktische, stapsgewijze gids om Java-webscraping in 2026 onder de knie te krijgen, met speciale aandacht voor de combinatie van code en moderne AI-tools zoals Thunderbit. Of je nu ontwikkelaar bent, operationeel leidinggevende of een zakelijke gebruiker die gewoon data wil zonder gedoe: deze gids is voor jou.
Na jaren in SaaS en automatisering heb ik uit eerste hand gezien hoe Java-webscraping bedrijfsprocessen kan transformeren. Maar ik heb ook teams zien worstelen — vastgelopen in de krochten van laagwaardige code of overweldigd door dynamische websites en anti-botmaatregelen. Daarom deel ik met plezier een praktische, stapsgewijze gids om Java-webscraping in 2026 onder de knie te krijgen, met speciale aandacht voor de combinatie van code en moderne AI-tools zoals Thunderbit. Of je nu ontwikkelaar bent, operationeel leidinggevende of een zakelijke gebruiker die gewoon data wil zonder gedoe: deze gids is voor jou.
Wat is Java-webscraping? Een niet-technische uitleg
Laten we de jargonstorm even ontwarren: Java-webscraping is simpelweg het proces waarbij je Java-code gebruikt om automatisch informatie van websites te halen. Stel je een super snelle virtuele stagiair voor die duizenden webpagina’s kan lezen en de data die je nodig hebt netjes in een spreadsheet zet — behalve dat deze stagiair nooit moe wordt, nooit spelfouten maakt en werkt op de snelheid van je internetverbinding.
Zo werkt het in gewoon Nederlands:
- Stuur een verzoek naar een website (alsof je een pagina bezoekt in je browser).
- Download de HTML-inhoud (de ruwe code waaruit de pagina bestaat).
- Parse die HTML naar een structuur die je programma begrijpt.
- Haal de specifieke data eruit die je nodig hebt (zoals productnamen, prijzen, e-mails).
- Sla het resultaat op in een bruikbaar formaat — CSV, Excel, een database of zelfs Google Sheets.
Je hoeft geen hardcore ontwikkelaar te zijn om de basis te begrijpen. Met de juiste tools en een beetje begeleiding kunnen zelfs zakelijke gebruikers dataverzameling automatiseren en rommelige webpagina’s omzetten in bruikbare inzichten.
Waarom Java-webscraping belangrijk is voor bedrijven in 2026
Webscraping is niet zomaar een hobbyproject voor techneuten — het is een zakelijke noodzaak. Laten we kijken hoe bedrijven Java-webscraping inzetten om voorsprong te nemen, en waarom het echte ROI oplevert.
| Use-case voor webscraping | Zakelijke voordelen (ROI) | Voorbeeldsectoren |
|---|---|---|
| Prijsmonitoring van concurrenten | Prijsinformatie realtime; omzetstijging van 20%+ door sneller te reageren op marktveranderingen | E-commerce, detailhandel |
| Leadgeneratie & sales intelligence | Geautomatiseerde, actuele prospectlijsten; 70% minder handmatig onderzoekstijd | B2B-sales, marketing, recruitment |
| Marktonderzoek & trendanalyse | Vroege signalering van trends; 5–15% omzetgroei en 10–20% hogere marketing-ROI | Consumentenproducten, marketingbureaus |
| Financiële & beleggingsdata | Alternatieve data voor trading; markt van $5 miljard+ voor webgescrapete “alt-data” | Finance, hedgefondsen, fintech |
| Workflowautomatisering & monitoring | Routinematige dataverzameling geautomatiseerd; 73% kostenbesparing en 85% snellere uitrol | Vastgoed, supply chain, overheid |
(Bron)
Waarom Java? Omdat het gebouwd is voor schaal, betrouwbaarheid en integratie. Veel enterprise-datapijplijnen draaien al op Java, dus een webscraper toevoegen is een logische stap. Bovendien maken Java’s multithreading en foutafhandeling het ideaal voor grote klussen — denk aan duizenden pagina’s per dag scrapen, niet slechts een handvol.
Hoe werkt Java-webscraping? Kernprincipes en unieke voordelen
Laten we de basis van een typische Java-webscraper ontleden:
- HTTP-verzoeken: Java gebruikt libraries zoals JSoup of Apache HttpClient om webpagina’s op te halen. Je kunt headers instellen, proxies gebruiken en echte browsers nabootsen om blokkades te vermijden.
- HTML-parsing: Libraries zoals JSoup zetten de ruwe HTML om in een “DOM” (een boomachtige structuur), waardoor het eenvoudig wordt om met CSS-selectors de gewenste data te vinden.
- Data-extractie: Je definieert regels (zoals “haal alle
<span class='price'>-elementen op”) om de info eruit te trekken die je nodig hebt. - Datopslag: Sla de resultaten op in CSV, Excel, JSON of een database.
Wat maakt Java bijzonder voor webscraping?
- Multithreading: Java kan veel pagina’s parallel ophalen en verwerken, waardoor grote crawls aanzienlijk sneller gaan. Python’s GIL kan hier een bottleneck zijn, maar Java’s threads draaien echt en snel.
- Prestaties: Dankzij het gecompileerde karakter kan Java grote taken en geheugenzware workloads moeiteloos aan.
- Enterprise-integratie: Java-scrapers kunnen direct aansluiten op bestaande systemen — CRM’s, ERP’s, databases — zonder omslachtige workarounds.
- Foutafhandeling: Java’s strikte typing en exception handling maken scrapers robuuster en beter onderhoudbaar voor langlopende projecten.
Als je een bedrijfskritische datapijplijn runt, zijn Java’s stabiliteit en schaalbaarheid moeilijk te verslaan.
Essentiële Java-bibliotheken en frameworks voor webscraping: wat kies je en waarom?
Er is geen gebrek aan Java-libraries voor webscraping, maar drie springen eruit voor de meeste zakelijke behoeften: JSoup, HtmlUnit en Selenium. Zo verhouden ze zich tot elkaar:
| Library | Ondersteunt JavaScript? | Gebruiksgemak | Prestaties | Beste voor |
|---|---|---|---|---|
| JSoup | ❌ (geen JS) | Zeer eenvoudig | Hoog | Statische pagina’s, snelle taken, lichte jobs |
| HtmlUnit | ⚠️ Gedeeltelijk | Gemiddeld | Gemiddeld | Eenvoudige JS, formulieren invullen, headless scraping |
| Selenium | ✅ Ja (volledig) | Gemiddeld/lastig | Lager (per pagina) | Sites met veel JS, interactieve/dynamische pagina’s |
JSoup: de eerste keuze voor eenvoudige HTML-parsing
JSoup is mijn eerste stop voor de meeste scrapingklussen. Het is lichtgewicht, makkelijk in gebruik en perfect voor statische pagina’s waar de data gewoon al in de HTML staat.
Voorbeeld:
Document doc = Jsoup.connect("https://www.scrapingcourse.com/ecommerce/").get();
String bannerTitle = doc.select("div.site-title").text();
System.out.println("Banner: " + bannerTitle);
Zo simpel is het. Als je blogposts, productoverzichten of directories scrapt die niet op JavaScript leunen, dan is JSoup je vriend.
HtmlUnit: browsers simuleren voor complexere taken
HtmlUnit is een headless browser geschreven in Java. Het kan een deel van JavaScript verwerken, formulieren invullen en op knoppen klikken — allemaal zonder een echt browservenster te openen.
Wanneer gebruiken? Als je moet inloggen op een site of te maken hebt met eenvoudige dynamische content, maar de overhead van Selenium wilt vermijden.
Voorbeeld:
WebClient webClient = new WebClient();
HtmlPage page = webClient.getPage("https://example.com/login");
// ... formulier invullen en verzenden ...
Selenium: voor JavaScript-zware en interactieve pagina’s
Selenium is de zwaargewicht. Het bestuurt een echte browser (zoals Chrome of Firefox), dus het kan elke site aan die een mens ook kan gebruiken — inclusief sites die volledig in JavaScript zijn gebouwd.
Wanneer gebruiken? Voor moderne webapps, sites met infinite scroll of alles waarbij klikken, wachten of interactie nodig is alsof je een gebruiker bent.
Voorbeeld:
WebDriver driver = new ChromeDriver();
driver.get("https://www.scrapingcourse.com/ecommerce/");
List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
// ... data extraheren ...
driver.quit();
Geef Java-webscraping extra kracht met Thunderbit: visuele automatisering ontmoet code
Haal data van elke website met AI Get Started Free
Nu wordt het echt interessant — vooral voor zakelijke gebruikers en teams die niet de hele dag in code willen leven. Thunderbit is een AI-gedreven, no-code webscraper waarmee je scrapingtaken visueel kunt definiëren (direct in je browser) en de data vervolgens rechtstreeks kunt exporteren naar Excel, Google Sheets, Airtable of Notion.
Waarom Thunderbit samen met Java gebruiken?
- Door AI voorgestelde velden: Thunderbit’s “AI Suggest Fields” leest de pagina en raadt precies aan wat je moet extraheren — je hoeft niet in HTML te duiken of selectors te schrijven.
- Subpagina’s scrapen: Meer details nodig? Thunderbit kan automatisch elke subpagina bezoeken (zoals productdetailpagina’s) en je dataset verrijken.
- Directe templates: Voor populaire sites (Amazon, Zillow, LinkedIn) heeft Thunderbit one-click templates — geen setup nodig.
- Eenvoudig exporteren: Zodra je gescrapet hebt, exporteer je data in enkele seconden — klaar voor je Java-code om te verwerken, analyseren of te integreren.
Thunderbit bespaart enorm veel tijd bij prototyping, het aanpakken van lastige sites of het in staat stellen van niet-ontwikkelaars om de data te krijgen die ze nodig hebben. En voor ontwikkelaars is het een uitstekende manier om repetitieve of kwetsbare onderdelen van scraping uit te besteden, zodat jij je kunt richten op de businesslogica.
Thunderbit en Java combineren voor complexe projecten
Dit is een workflow waar ik dol op ben:
- Prototype met Thunderbit: Gebruik de Chrome-extensie om je scrape visueel op te zetten. Laat AI velden voorstellen, paginering afhandelen en de data exporteren naar Google Sheets of CSV.
- Verwerk in Java: Schrijf Java-code om de geëxporteerde data te lezen (uit Sheets, CSV of Airtable) en voer daarna postprocessing, analyses of integratie met je enterprise-systemen uit.
- Automatiseer en plan in: Gebruik Thunderbit’s ingebouwde planner om je data actueel te houden, en laat je Java-pijplijn automatisch de nieuwste exports oppikken.
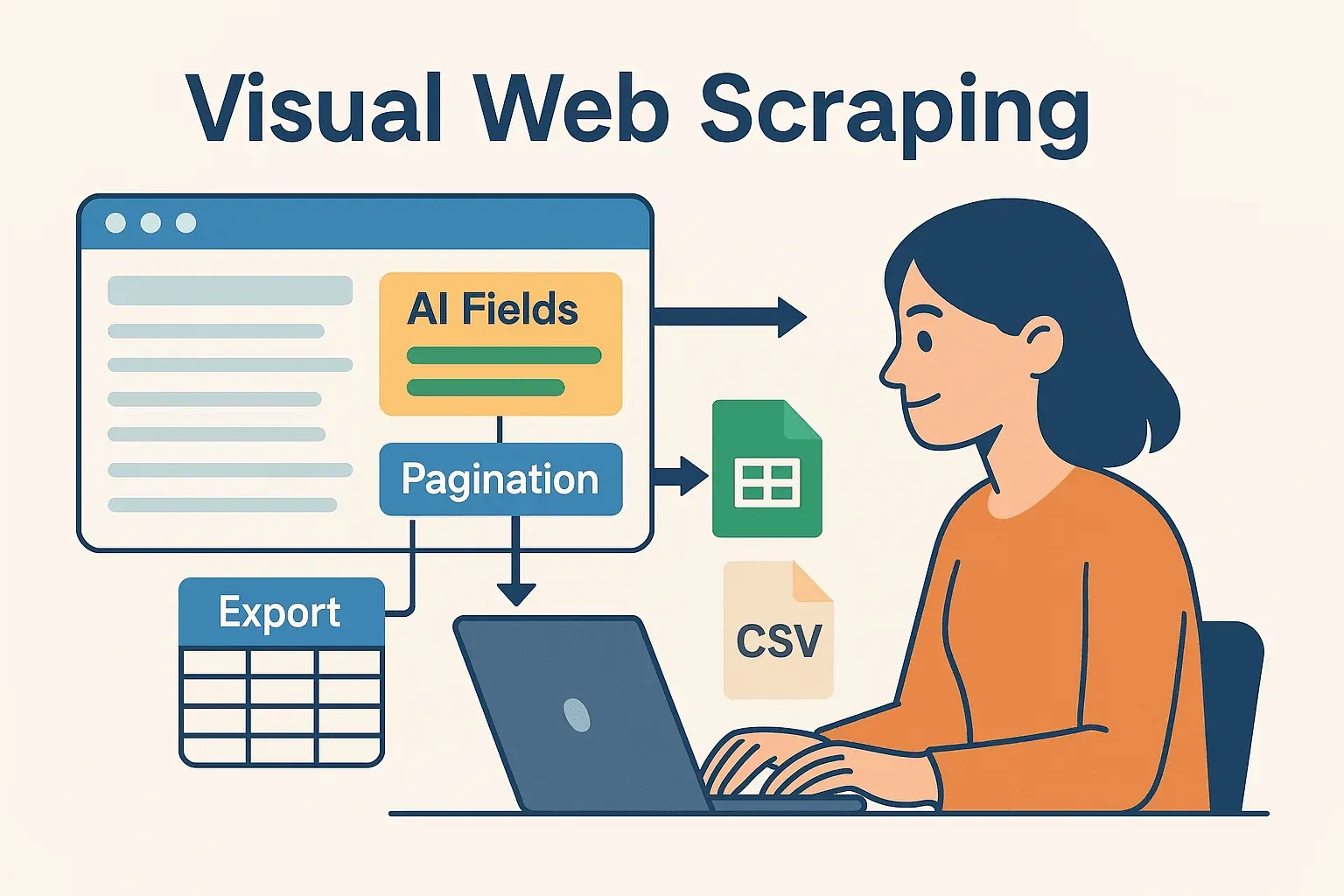 Deze hybride aanpak geeft je het beste van twee werelden: de snelheid en flexibiliteit van AI-gedreven no-code scraping, plus de kracht en betrouwbaarheid van Java voor verdere verwerking.
Deze hybride aanpak geeft je het beste van twee werelden: de snelheid en flexibiliteit van AI-gedreven no-code scraping, plus de kracht en betrouwbaarheid van Java voor verdere verwerking.
Probeer de Thunderbit Chrome-extensie gratis
Stapsgewijze gids: bouw je eerste Java-webscraper
Aan de slag. Hier lees je hoe je vanaf nul een eenvoudige Java-webscraper bouwt.
Je Java-omgeving instellen
- Installeer Java (JDK): Gebruik Java 21 of 25 voor de huidige LTS-ondersteuning. De gratis Oracle-updates voor Java 17 zijn in september 2024 beëindigd en de gratis updates voor Java 21 lopen naar verwachting af in september 2026, dus nieuwe projecten die in 2026 starten zouden Java 25 moeten kiezen (uitgebracht in september 2025, LTS tot 2033), tenzij je vastzit aan een bestaande Java 21-codebase.
- Stel Maven in: Dit regelt je dependencies.
- Kies een IDE: IntelliJ IDEA, Eclipse of VSCode werken allemaal prima.
- Voeg JSoup toe aan je
pom.xml:<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.22.2</version> </dependency>
Je scraper schrijven en uitvoeren
Laten we productnamen en prijzen scrapen van een demo e-commerce site.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
public class ProductScraper {
public static void main(String[] args) {
String url = "https://www.scrapingcourse.com/ecommerce/";
try {
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0")
.get();
Elements productElements = doc.select("li.product");
for (Element productEl : productElements) {
String name = productEl.selectFirst("h2").text();
String price = productEl.selectFirst("span.price").text();
System.out.println(name + " -> " + price);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Pro-tip: Stel altijd een user-agent in om een echte browser na te bootsen. Sommige sites blokkeren de standaard Java user-agent.
Je data exporteren en gebruiken
- CSV-export: Gebruik
FileWriterof een library zoals OpenCSV om resultaten naar een CSV-bestand te schrijven. - Excel-export: Gebruik Apache POI voor .xls/.xlsx-bestanden.
- Database-integratie: Gebruik JDBC om data direct in je database in te voegen.
- Google Sheets: Exporteer vanuit Thunderbit en lees in met de Google Sheets API van Java.
Veelvoorkomende uitdagingen bij Java-webscraping overwinnen
Webscraping is niet alleen maar rozengeur en maneschijn. Hier zijn de meest voorkomende pijnpunten — en hoe je ze oplost:
- IP-blokkering en rate limiting: Vertraag je verzoeken (
Thread.sleep()), roteer proxies en randomiseer vertragingen. Voor grote volumes kun je proxyservices gebruiken. - CAPTCHA’s en botdetectie: Gebruik Selenium om echt gebruikersgedrag na te bootsen, of besteed het uit aan anti-bot-API’s. Soms kun je met Thunderbit’s cloud scraping deze hindernissen omzeilen.
- Dynamische content: Als JSoup lege resultaten oplevert, wordt de data waarschijnlijk via JavaScript geladen. Schakel over naar Selenium of HtmlUnit, of spoor de onderliggende API van de site op.
- Wijzigingen in websitestructuur: Schrijf onderhoudbare code met flexibele selectors. Monitor je scrapers en wees klaar om ze bij te werken wanneer sites veranderen. Met Thunderbit betekent een lay-outwijziging meestal dat je “AI Suggest Fields” opnieuw draait in plaats van XPath handmatig te bewerken — nog steeds een handmatige stap, maar veel goedkoper dan selectors herschrijven.
- Sessiebeheer: Voor scraping achter login moet je cookies en sessies zorgvuldig beheren. Selenium en Thunderbit (wanneer je bent ingelogd in Chrome) kunnen geauthenticeerde pagina’s aan.
Geavanceerde tips om Java-webscraping efficiënter te maken
Meer leren over data scraping met AI Get Started Free
Klaar om een niveau hoger te gaan? Hier zijn een paar pro-tips:
- Multithreading: Gebruik Java’s
ExecutorServiceom meerdere pagina’s parallel te scrapen. Ga alleen niet te ver en zorg dat je niet geblokkeerd raakt! - Planning: Gebruik Quartz Scheduler in Java, of laat Thunderbit de planning in de cloud afhandelen met natuurlijke taal (“elke maandag om 9 uur”).
- Cloud-schaalbaarheid: Voor enorme klussen kun je headless browsers in de cloud draaien of taken over meerdere machines verdelen.
- Hybride workflows: Gebruik Thunderbit voor lastige, onderhoudsintensieve sites en Java-code voor de rest. Combineer de resultaten in je data warehouse.
- Monitoring & logging: Gebruik Java’s logging-frameworks om de gezondheid van je scraper te volgen, fouten vroeg op te vangen en alerts te triggeren als er iets misgaat.
Conclusie & belangrijkste inzichten
Webdata is het nieuwe goud, en Java is nog altijd een van de beste schop-en-zeef-combinaties in deze business — vooral voor teams die betrouwbaarheid, schaal en integratie nodig hebben. De kernworkflow is eenvoudig: ophalen, parsen, extraheren en uitvoeren. Met libraries zoals JSoup, HtmlUnit en Selenium kun je alles aan, van eenvoudige directories tot de wildste JavaScript-zware websites.
Maar je hoeft niet alles handmatig te doen. Tools zoals Thunderbit brengen AI en visuele automatisering samen, zodat je scrapingprojecten sneller dan ooit kunt prototypen, aanpassen en opschalen. Mijn advies? Wees niet bang om code en no-code te combineren. Gebruik Thunderbit voor snelle opzet en onderhoud, en laat je Java-pijplijn het zware werk doen.
Wil je zien hoe Thunderbit je workflow kan versnellen? Download de Chrome-extensie en probeer binnen enkele minuten je eerste site te scrapen. En als je meer wilt, bekijk dan de Thunderbit Blog voor diepgaande artikelen, tutorials en de nieuwste ontwikkelingen op het gebied van webscraping-automatisering.
Probeer Thunderbit AI-webscraper
Veel succes met scrapen — en moge je data altijd gestructureerd, actueel en klaar voor actie zijn.
FAQ’s
1. Is Java in 2026 nog relevant voor webscraping?
Ja. Hoewel Python populair is voor snelle scripts, blijft Java een veelgekozen optie voor scrapingpijplijnen op enterprise-schaal die lang draaien — vooral wanneer bestaande services al op de JVM draaien en profiteren van echte multithreading en het volwassen ecosysteem rond Maven, logging en JDBC.
2. Wanneer moet ik JSoup, HtmlUnit of Selenium gebruiken?
Gebruik JSoup voor statische pagina’s, HtmlUnit voor eenvoudige dynamische content of formulierinzendingen, en Selenium voor JavaScript-zware of interactieve sites. Kies de tool die past bij de complexiteit van de site.
3. Hoe voorkom ik dat ik word geblokkeerd tijdens het scrapen?
Tem je verzoeken, gebruik roterende proxies, stel realistische user-agents in en boots menselijk gedrag na. Voor lastige sites kun je Thunderbit’s cloud scraping of anti-bot-API’s overwegen.
4. Kunnen Thunderbit en Java samen werken?
Zeker weten. Gebruik Thunderbit om scrapes visueel te definiëren en in te plannen, exporteer de data en verwerk of integreer die vervolgens met je Java-code. Het is een krachtige combinatie voor zowel zakelijke gebruikers als ontwikkelaars.
5. Wat is de snelste manier om te starten met Java-webscraping?
Stel Java en Maven in, voeg JSoup toe en probeer een eenvoudige site te scrapen. Voor complexere klussen of snelle prototyping installeer je Thunderbit en laat je AI het zware werk doen — daarna koppel je de resultaten aan je Java-workflow.
Wil je meer tips, codevoorbeelden of automatiseringshacks? Duik in de Thunderbit Blog of abonneer je op ons YouTube-kanaal voor praktische tutorials en het laatste nieuws over webscraping-technologie. Meer leren
- De 15 beste webpagina-scrapers die je in 2025 moet kennen
- Hoe je webscraping doet: een uitgebreide beginnersgids
- Top 12 gratis data-scraper-tools in 2025
Probeer AI-webscraper voor Java-projecten Get Started Free




