Een crawl-gebaseerde studie van hoe websites met veel verkeer machineleesbare richtlijnen publiceren voor grote taalmodellen, hoe vroege implementaties eruitzien en waarom adoptie meten meer vraagt dan alleen HTTP 200-responses tellen.
- Dataset:
data/llms_probe_results_top_10000.csv - Tranco-lijst gedownload: 6 mei 2026
- Scope: root-level
/llms.txten/llms-full.txt
Belangrijke cijfers
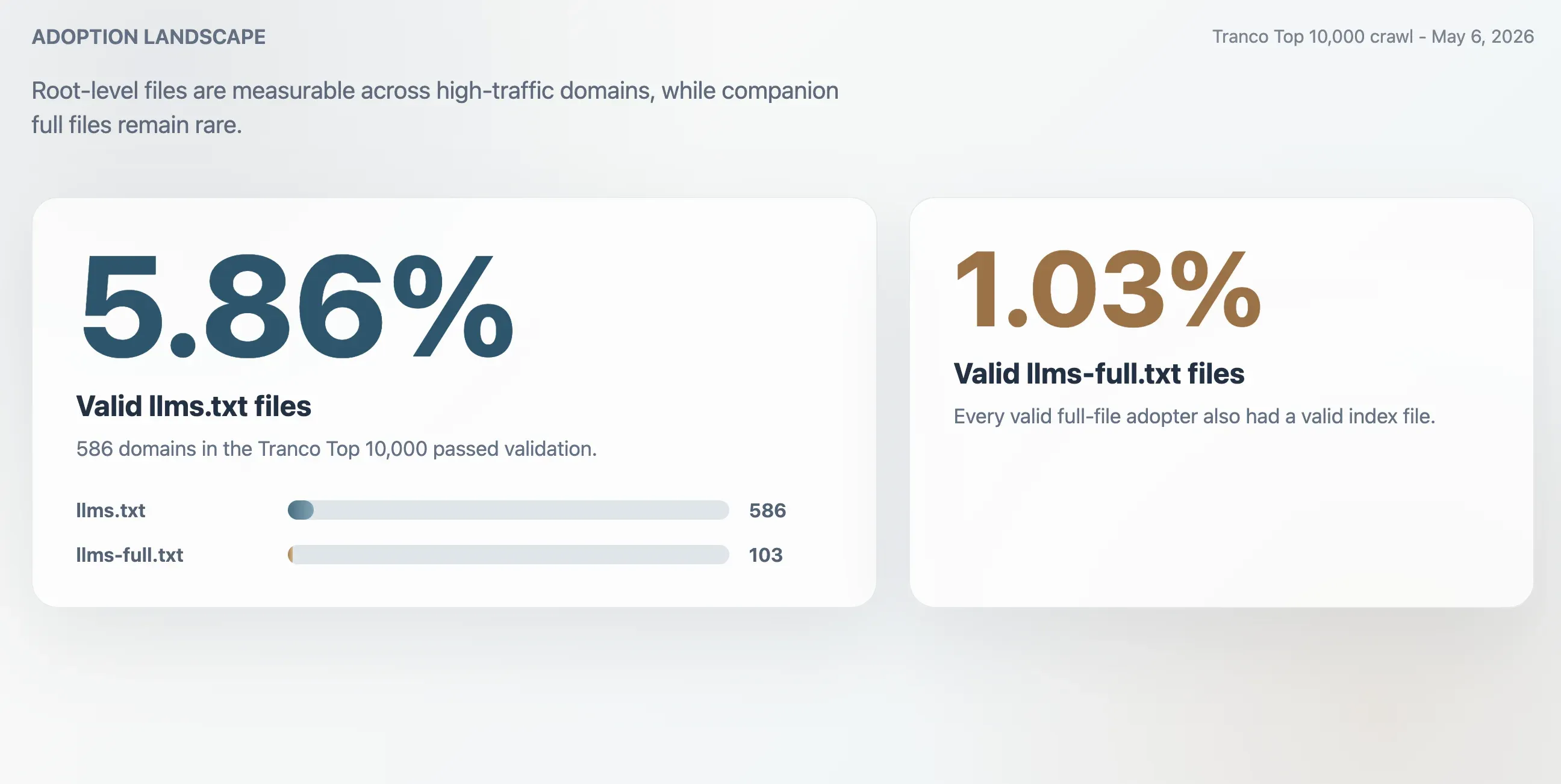
- 5,86%: Geldige adoptie van
llms.txtbinnen de Tranco Top 10.000, goed voor 586 domeinen. - 1,03%: Geldige adoptie van
llms-full.txt, goed voor 103 domeinen. Elk geldig volledig bestand had ook een geldig indexbestand. - 63,51%: Aandeel HTTP 200-responses voor
/llms.txtdat de validatie niet haalde. - 2,74x: Geschatte overschatting als adoptie alleen op ruwe HTTP 200-responses zou worden gemeten.
Samenvatting voor leidinggevenden
llms.txt is nog steeds een vroege webconventie, maar het is geen niche-experiment meer. In een crawl van 6 mei 2026 over de Tranco Top 10.000-domeinen vond dit onderzoek 586 geldige llms.txt-bestanden, goed voor een waargenomen adoptiegraad van 5,86%. Het bijbehorende bestand llms-full.txt kwam veel minder vaak voor: 103 domeinen hadden een geldig volledig bestand, goed voor een adoptiegraad van 1,03%.
De belangrijkste methodologische bevinding is dat statuscodes een slechte proxy zijn voor adoptie. De crawler zag 1.606 HTTP 200-responses voor /llms.txt, maar slechts 586 daarvan haalden de validatie. De overige 1.020 waren vooral omleidingen naar verkeerde bestemmingen, algemene HTML-pagina’s, lege bodies of andere ongeldige responses. Een naïeve crawler die elke 200-response als adoptie telt, zou de geldige adoptie met ongeveer 2,74 keer overschatten.
Onder geldige adopters is de implementatiekwaliteit hoger dan een puur placeholderverhaal doet vermoeden. Het mediane geldige bestand was ongeveer 7,1 KB, 61,77% van de geldige bestanden was groter dan 5 KB, 70,82% bevatte zes of meer Markdown-secties en 77,47% bevatte 11 of meer Markdown-links. Tot de vroege adopters behoren Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog en Cloudinary.
llms.txtkun je het best zien als een verklarend en navigerend signaal voor AI-systemen, niet als vervanging vanrobots.txt. De waarde zit niet alleen in het bestaan van een bestand, maar vooral in de vraag of het machines helpt om gezaghebbende, compacte en actuele informatie te vinden.
Context: het web voegt AI-signalen toe
Websites gebruiken al lang robots.txt om crawler-voorkeuren aan te geven, sitemap.xml om URL-ontdekking te verbeteren en gestructureerde data om zoek- en platformsystemen pagina’s beter te laten interpreteren. Generatieve AI introduceert een ander probleem. Content kan worden gebruikt voor training, retrieval, samenvattingen, agentic browsing, code-assistentie, klantenservice en het genereren van antwoorden. Dat creëert twee tegelijk lopende behoeften: uitgevers willen meer controle over geautomatiseerd gebruik, maar willen ook dat AI-systemen de juiste canonieke informatie vinden wanneer die systemen hun site daadwerkelijk bezoeken.
Het , geïntroduceerd door Jeremy Howard in 2024, beschrijft het bestand als een Markdown-document op de root van een website om tijdens inferentie LLM-vriendelijke informatie te bieden. Volgens het voorstel bevatten HTML-pagina’s vaak navigatie, advertenties, scripts en andere ruis die ze lastiger maken voor taalmodellen om te verwerken. Een compact Markdown-bestand kan modellen naar de belangrijkste pagina’s, docs, API’s, voorbeelden, beleid en productinformatie leiden.
Extern webonderzoek plaatst dit in een bredere context. beschrijft een snelle toename van AI-gerelateerde beperkingen in robots.txt en voorwaarden, en stelt dat bestaande webtoestemmingsmechanismen niet zijn ontworpen voor grootschalig hergebruik van AI-data. heeft daarnaast AI-crawler- en robots.txt-patronen zichtbaar gemaakt op het niveau van de Top 10.000-domeinen. In die omgeving staat llms.txt aan de constructieve kant van AI-signaling: niet “crawl dit niet”, maar “als je deze site wilt begrijpen, begin hier”.
Extern bewijs en het debat over adoptie
Het publieke debat rond llms.txt splitst zich in twee standpunten. Het optimistische standpunt is dat het bestand AI-systemen een schonere en efficiëntere route naar gezaghebbende content geeft. Het sceptische standpunt is dat geen grote LLM-provider publiekelijk heeft toegezegd het te gebruiken als ranking-, crawl- of citatiesignaal, waardoor uitgevers geen verkeerstoename op basis van alleen dit bestand moeten verwachten. De drie externe bronnen die voor deze update zijn bekeken, ondersteunen een genuanceerdere conclusie: llms.txt is nuttige infrastructuur, maar het bewijs voor directe verkeerseffecten blijft beperkt en contextafhankelijk.
Externe adoptiebenchmarks veranderen snel
rapporteerde op 22 juni 2025 een adoptiegraad van 0,3% over de top 1.000 websites, ofwel 3 van de 1.000 sites. Het beschrijft maandelijkse geautomatiseerde scans van domain.com/llms.txt, met validatie die redirects en HTML-responses uitsluit. Die methodiek lijkt in grote lijnen op de conservatieve validatie-aanpak van dit onderzoek.
Het verschil in uitkomsten is groot: dit onderzoek vond op 6 mei 2026 75 geldige llms.txt-bestanden in de Tranco Top 1.000, oftewel 7,50%. De twee cijfers moeten niet worden gezien als een strikte tijdreeks, omdat de rankingbron, implementatiedetails, validatielogica en crawltiming kunnen verschillen. Toch suggereert het contrast dat de adoptie tussen midden 2025 en mei 2026 substantieel is veranderd, vooral bij developer-, SaaS-, cloud-, security- en documentatiezware sites.
| Bron | Momentopname | Steekproef | Gerapporteerde geldige adoptie | Interpretatie |
|---|---|---|---|---|
| Rankability | 22 juni 2025 | Top 1.000 websites | 0,3% | Vroege publieke benchmark die een minimale adoptie midden 2025 laat zien. |
| Dit onderzoek | 6 mei 2026 | Tranco Top 1.000 | 7,50% | Latere crawl die zichtbare adoptie laat zien bij sites met veel verkeer. |
| Dit onderzoek | 6 mei 2026 | Tranco Top 10.000 | 5,86% | Breder sample dat laat zien dat adoptie meetbaar is, maar nog niet mainstream. |
Verkeersexperimenten blijven gemengd
publiceerde in januari 2026 een analyse van 10 sites die gedurende 90 dagen vóór en 90 dagen na implementatie werden gevolgd. Het artikel meldde dat twee sites een AI-verkeerstoename van 12,5% en 25% zagen, acht geen meetbare verbetering lieten zien en één site met 19,7% daalde. De kerninterpretatie was causale voorzichtigheid: de twee ogenschijnlijke succesverhalen lanceerden ook nieuwe templates, bouwden resourcecentra opnieuw op, voegden extractable comparison tables toe, verdienden persaandacht, herstelden technische problemen of publiceerden nieuwe FAQ-achtige content. In die lezing documenteerde llms.txt sterker content- en technisch werk; het leek de groei niet zelf te veroorzaken.
kwam op basis van een kleinere observatie op siteniveau tot een positievere conclusie. Het vergeleek twee periodes van vier maanden in Yandex.Metrica nadat zowel llms.txt als llms-full.txt waren toegevoegd. LLM-verwijzingssessies stegen van 75 naar 92, een toename van 23%, terwijl gebruikers stegen van 51 naar 64. Sessies vanuit Perplexity stegen van 29 naar 55, terwijl ChatGPT-sessies daalden van 31 naar 26. In dezelfde post wordt ook vermeld dat het totale verwijzingsverkeer harder groeide, van 160 naar 290 sessies, waardoor het aandeel van LLM-sessies daalde van 47% naar 32%.
This paragraph contains content that cannot be parsed and has been skipped.
Wat het debat verduidelijkt
Het externe bewijs scherpt de interpretatie van deze dataset aan. Een goed gestructureerd llms.txt-bestand kan de frictie voor machine parsing verlagen, vooral voor developer-documentatie, API-referenties en knowledge-basecontent. Maar de sterkste verkeersgevallen lijken nog steeds afhankelijk van content die bruikbaar, extractable, gezaghebbend en buiten het bestand om vindbaar is. De praktische vraag is daarom niet losstaand: “maakt llms.txt uit?” Het gaat erom of het bestand onderdeel is van een breder AI-leesbaar contentsysteem.
Geactualiseerde interpretatie: implementeer
llms.txtals goedkope AI-facing infrastructuur. Positioneer het niet als vervanging voor betere documentatie, gestructureerde content, technische toegankelijkheid, citaties, links of merkautoriteit.
Methode
Dit onderzoek gebruikte de Tranco Top 10.000-domeinen als steekproef. Tranco is een op onderzoek gerichte top-sites-ranking die stabieler is en beter bestand tegen manipulatie dan veel traditionele toplijsten. Het Tranco-bronbestand werd gedownload op 6 mei 2026, met een Last-Modified-tijdstempel van 5 mei 2026 om 22:17:59 GMT.
De crawler controleerde per domein twee root-level paden:
https://example.com/llms.txt, met HTTP-fallback indien nodig.https://example.com/llms-full.txt, met HTTP-fallback indien nodig.
Voor elke probe legde de crawler de statuscode, uiteindelijke URL, fetch-methode, responsbytes, contenttype, foutmelding, verstreken tijd en validatieresultaat vast. Succesvolle response bodies werden opgeslagen onder raw_llms_txt/ voor review en secundaire analyse.
Validatieregels
Een response werd alleen als geldig bestand geteld als die een succesvolle body teruggaf en niet op een generieke web-fallback leek. Het uiteindelijke URL-pad moest /llms.txt of /llms-full.txt blijven. Lege bodies werden afgewezen. Overduidelijke HTML-documenten en app shells werden afgewezen. Contenttype gold als ondersteunend bewijs en niet als enige regel, omdat een klein aantal geldige tekstachtige bestanden met ongebruikelijke contenttypes werd geserveerd.
Adoptielandschap
De crawl vond 586 geldige llms.txt-bestanden in de Tranco Top 10.000. Dat levert een geldige adoptiegraad op van 5,86%. Het kleinere begeleidende bestand llms-full.txt was aanwezig en geldig op 103 domeinen, oftewel 1,03% van de steekproef.
| Metriek | Aantal | Aandeel van Top 10.000 |
|---|---|---|
| Domeinen gecrawld | 10.000 | 100,00% |
| Geldige llms.txt-bestanden | 586 | 5,86% |
| Geldige llms-full.txt-bestanden | 103 | 1,03% |
| HTTP 200-responses voor /llms.txt | 1.606 | 16,06% |
| HTTP 200-responses afgewezen als ongeldig | 1.020 | 10,20% |
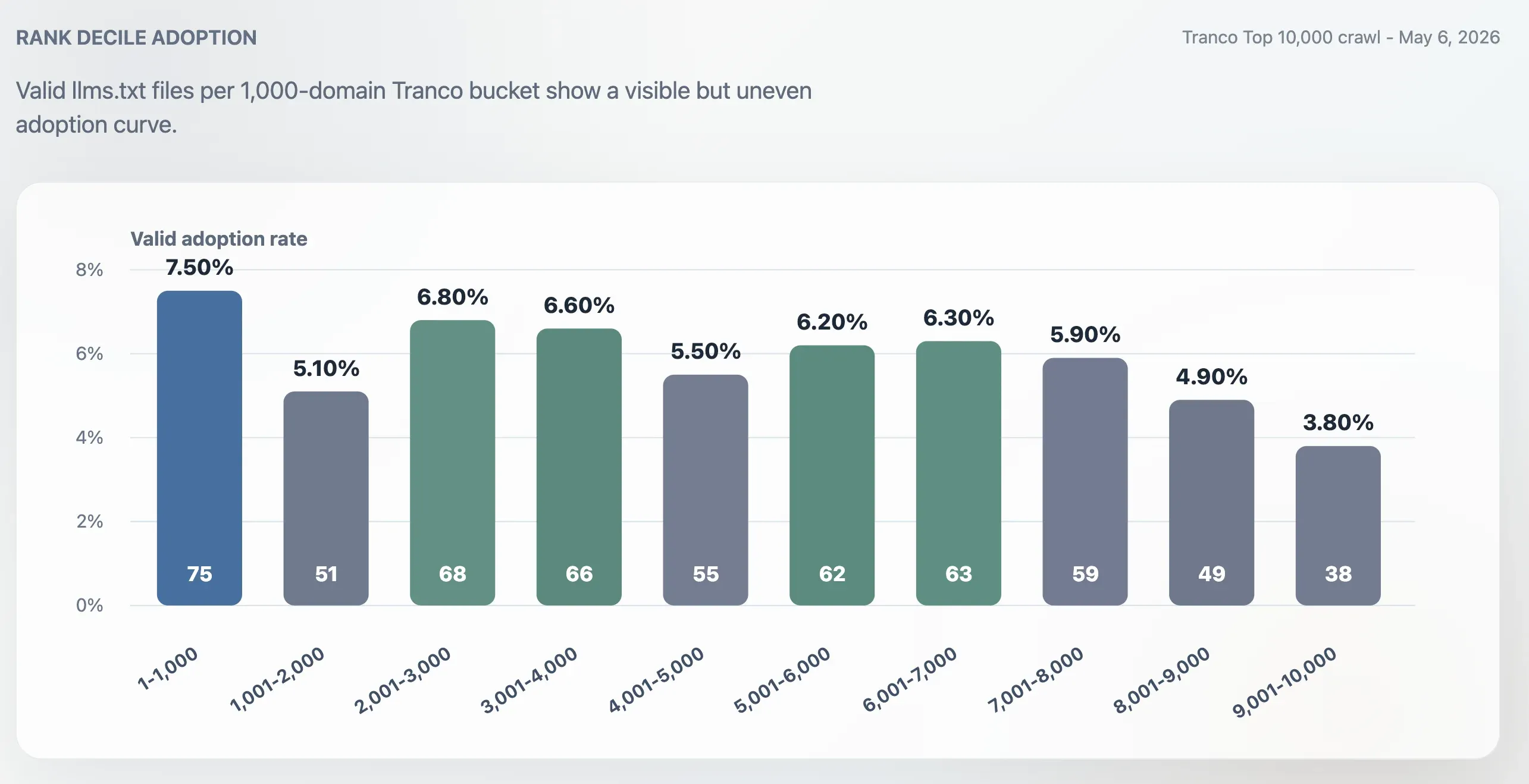
Adoptie is niet puur topzwaar
De adoptie was hoger in de Top 1.000 dan in de volledige Top 10.000, maar was niet beperkt tot de allergrootste sites. De adoptiegraad in de Top 1.000 was 7,50%. De laatste bucket van 1.000 domeinen, rang 9.001-10.000, zakte naar 3,80%. Het midden van de ranking bleef actief: de buckets 2.001-3.000, 3.001-4.000, 5.001-6.000 en 6.001-7.000 kwamen allemaal rond de 6% uit.
Vroege adopters
De hoogst gerangschikte geldige adopter was Cloudflare op Tranco-rang 4. Andere hoog gerangschikte adopters waren Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink en OneSignal.
Deze adopters zijn niet willekeurig. Ze hebben vaak grote documentatie-oppervlakken, productlijnen die uitleg vragen, API’s of developer-ecosystemen, supportcontent, prijspagina’s, security- en privacy-informatie en genoeg merkautoriteit om te geven om hoe AI-systemen hun sites interpreteren.
| Rang | Domein | Bestandsgrootte | Waargenomen patroon |
|---|---|---|---|
| 4 | cloudflare.com | 4.225 B | Compacte index voor product-, developer-, bedrijfs- en prijsinformatie. |
| 26 | azure.com | 47.037 B | Developer-tools, AI, compute, storage, security, monitoring en optionele resources. |
| 28 | github.com | 27.108 B | Programmatic access, Copilot, MCP, REST API, Actions, repositories en CLI-links. |
| 248 | stripe.com | 64.229 B | Betalingen, Connect, Checkout, Billing, Tax, Atlas, Radar en developer-docs. |
| 265 | salesforce.com | 1,02 MB | Massieve product- en Agentforce-linkcatalogus, zonder Markdown-sectiekoppen. |
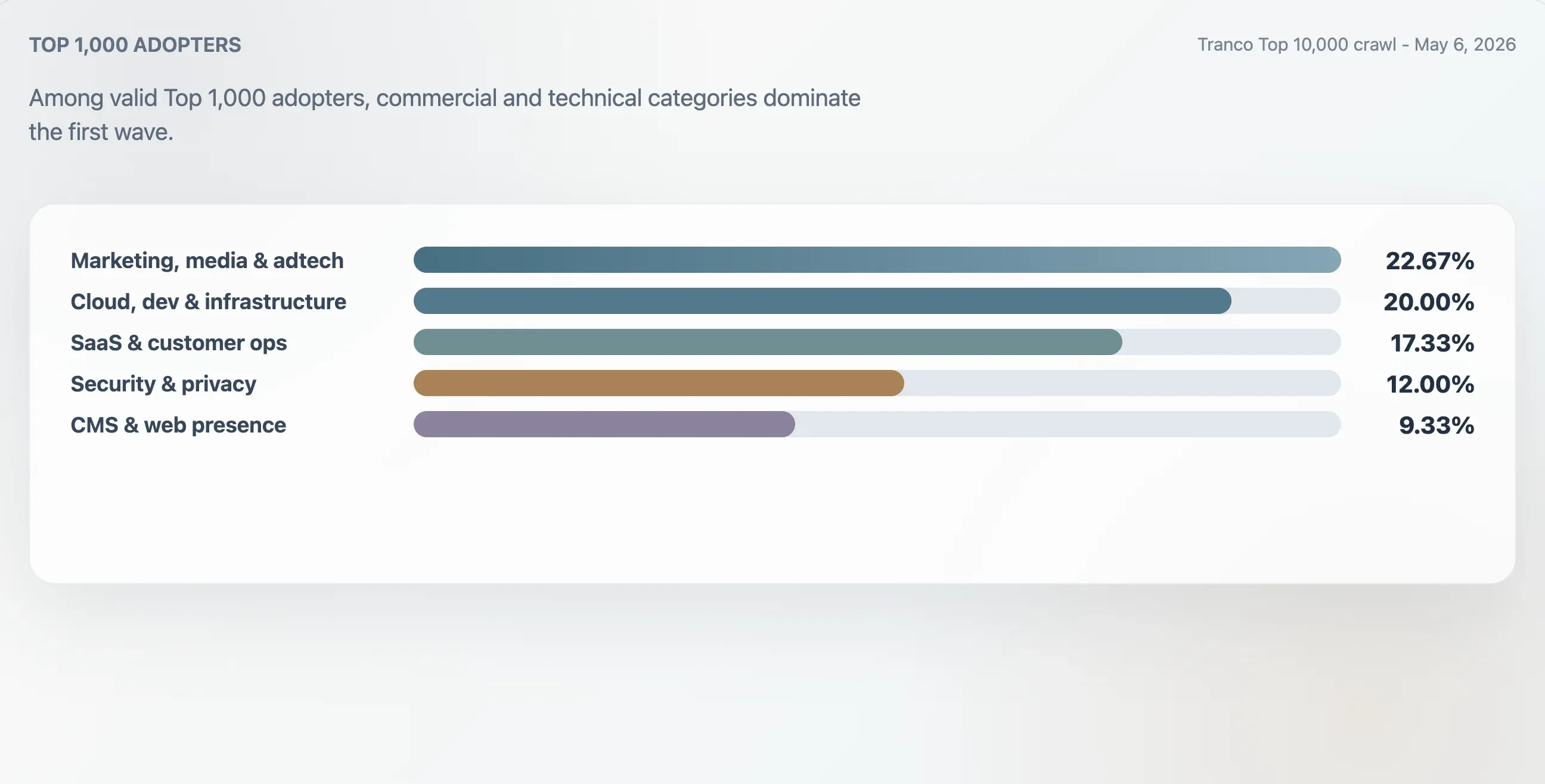
Categorisatie van Top 1.000-adopters
Dit onderzoek classificeerde de 75 geldige adopters in de Tranco Top 1.000 op basis van domeincontext, eerste koppen, ruwe bestandsstructuur en contentwoorden. De grootste groep was marketing, media en adtech met 22,67%. Cloud-, developer- en infrastructuursites waren goed voor 20,00%. SaaS-, productiviteits- en customer-operations-sites waren goed voor 17,33%. Security-, identity- en privacy-sites waren goed voor 12,00%.
| Categorie | Domeinen | Aandeel van Top 1.000 adopters | Mediane kwaliteitsscore | Mediaan aantal links |
|---|---|---|---|---|
| Marketing, media & adtech | 17 | 22,67% | 94 | 25 |
| Cloud, dev & infrastructuur | 15 | 20,00% | 94 | 62 |
| SaaS, productiviteit & customer ops | 13 | 17,33% | 94 | 46 |
| Security, identity & privacy | 9 | 12,00% | 98 | 78 |
| CMS, hosting & web presence | 7 | 9,33% | 100 | 24 |
TLD-patronen
Top-level domeinen zijn geen branchelabels, maar wel nuttige richtinggevende signalen. Onder TLD’s met minstens 50 domeinen in de steekproef had .io de hoogste geldige adoptiegraad met 14,44%. .com volgde met 8,19%. Lagere adoptie bij .gov, .edu en .net suggereert dat de vroege adopters vaker commercieel en technisch dan institutioneel zijn.
Implementatiekwaliteit
Geldige adoptie betekent niet dat de implementatiekwaliteit overal gelijk is. Sommige bestanden zijn compacte, goed gestructureerde indexen. Sommige bestaan vooral uit lopende tekst. Sommige zijn ruwe linkcatalogi. Sommige zijn bijna lege placeholders. Sommige zijn content dumps van meerdere megabytes die misschien compleet zijn maar duur zijn om op te halen en te parsen.
Van de geldige llms.txt-bestanden waren er 362 groter dan 5 KB, oftewel 61,77% van de geldige adopters. De mediane bestandsgrootte was ongeveer 7,1 KB. De P90-bestandsgrootte was 156 KB, P95 was 356 KB, P99 was 2,54 MB en het grootste waargenomen bestand was 7,97 MB.
Veelvoorkomende contentsignalen
Een scan op keywordniveau van geldige bestanden liet zien dat veel sites niet alleen een verklaring publiceren, maar modellen ook naar operationeel bruikbaar materiaal leiden. Termen voor support of help kwamen voor in 70,31% van de geldige bestanden. Blog-, gids- of tutorialtermen kwamen voor in 67,92%. Security-, privacy-, compliance- of terms-termen kwamen voor in 61,43%. Pricing kwam voor in 53,92%, documentatie in 52,22%, API-termen in 33,96% en changelog- of releasesignalen in 27,30%.
Kwaliteitsscore en archetypen
Om van aanwezigheid naar rijpheid te gaan, ontwikkelde dit onderzoek een lichte implementatiescore. De score houdt rekening met contenttype, bestandsgrootte, Markdown-structuur, linkaantal, onderwerpdekking en waarschuwingssignalen zoals ontbrekende koppen, geen Markdown-links, ongebruikelijke contenttypes, kleine bestanden, zeer grote bestanden en linkdump-gedrag. Dit is geen formele standaard, maar een research-scoremodel om waargenomen implementaties te vergelijken.
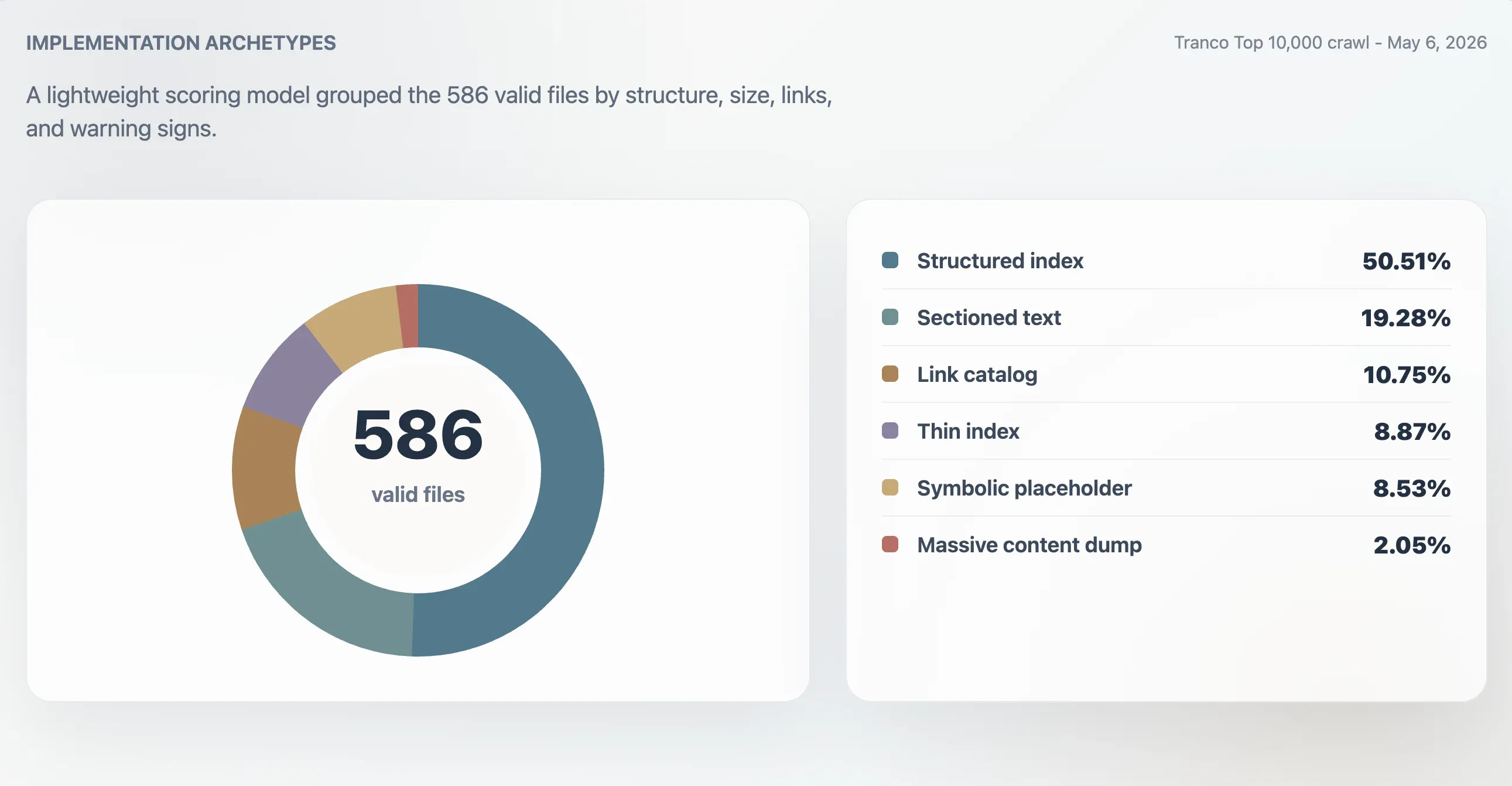
Met dit model werden 416 geldige bestanden geclassificeerd als sterke gestructureerde indexen, 107 als bruikbare indexen, 24 als dun of onregelmatig en 39 als symbolisch of van lage waarde. Een aparte archetype-analyse vond 296 gestructureerde indexen, 113 bestanden met secties en tekst, 63 linkcatalogi, 52 dunne indexen, 50 symbolische of placeholderbestanden en 12 enorme content dumps.
| Archetype | Domeinen | Aandeel van geldige bestanden | Mediane score | Mediaan bestandsgrootte | Mediaan aantal links |
|---|---|---|---|---|---|
| Gestructureerde index | 296 | 50,51% | 98 | 11.241 B | 61,5 |
| Tekst met secties | 113 | 19,28% | 78 | 4.718 B | 0 |
| Linkcatalogus | 63 | 10,75% | 86 | 4.160 B | 23 |
| Dunne index | 52 | 8,87% | 66 | 2.814 B | 0 |
| Symbolisch of placeholder | 50 | 8,53% | 27 | 15 B | 0 |
| Enorme content dump | 12 | 2,05% | 74 | 2,84 MB | 7.259,5 |
Topadopters hebben dichtere implementaties
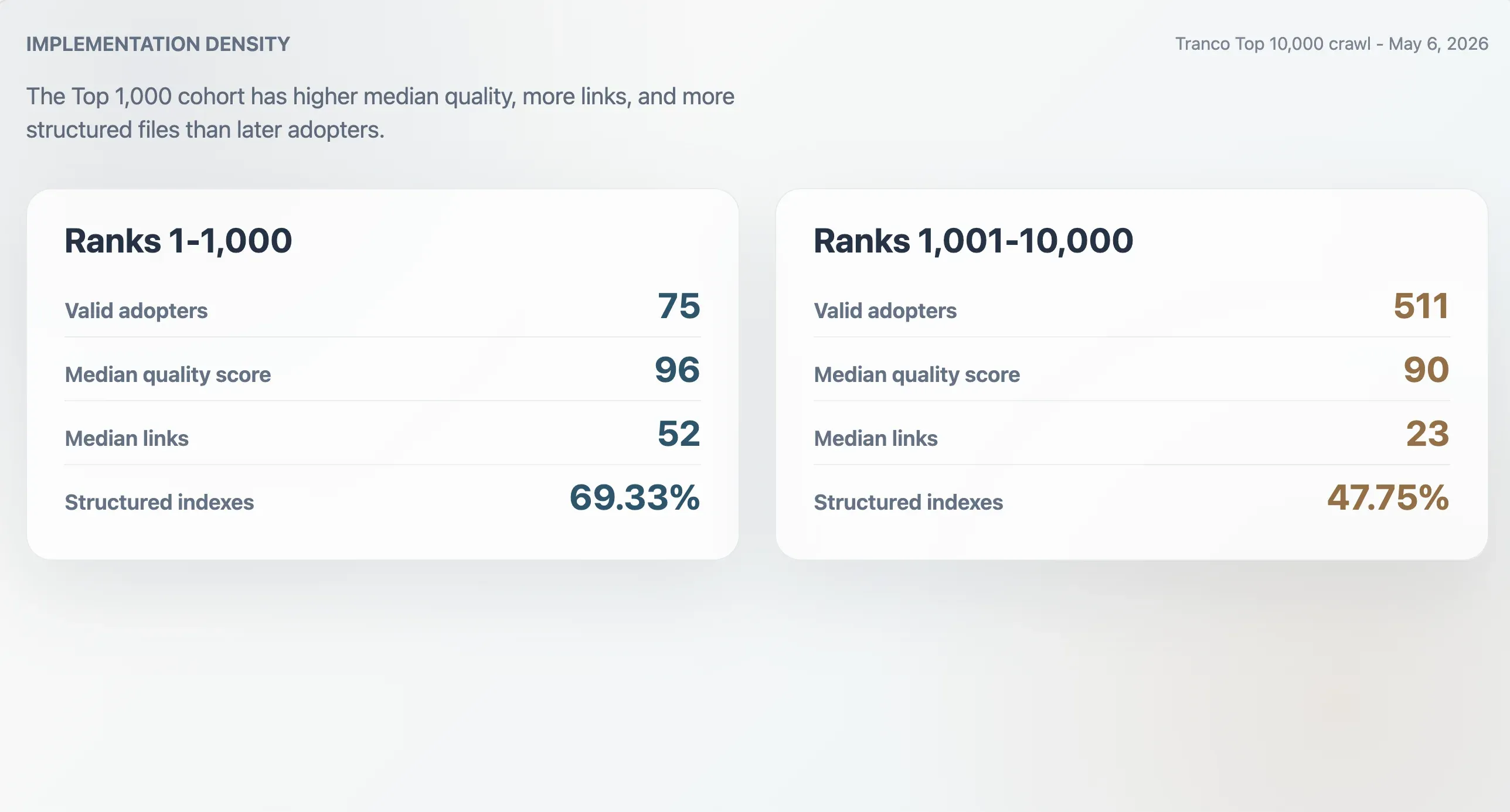
De 75 geldige adopters in de Tranco Top 1.000 hadden een mediane kwaliteitsscore van 96, een mediane bestandsgrootte van 9.068 bytes, een mediaan Markdown-linkaantal van 52 en een mediaan sectieaantal van 11. De 511 adopters op rang 1.001-10.000 hadden lagere medianen: score 90, bestandsgrootte 6.506 bytes, 23 Markdown-links en 9 secties. Adopters in de Top 1.000 waren ook vaker gestructureerde indexen: 69,33% tegenover 47,75% in de latere cohort.
Het probleem van fout-positieven

Het grootste meetrisico zijn fout-positieven. Van de 1.606 domeinen die HTTP 200 gaven voor /llms.txt, haalden er 1.020 de validatie niet. De meest voorkomende ongeldige reden was een omleiding naar een verkeerde bestemming, met 618 gevallen. Nog eens 367 responses waren generieke HTML-documenten. Negenentwintig gaven een lege body terug en zes waren andere of niet-gecategoriseerde ongeldige responses.
Dit is belangrijk omdat veel grote sites onbekende paden sturen naar inlogpagina’s, homepages, app shells, regionale pagina’s, toestemmingsschermen of marketing-fallbacks. Deze responses kunnen er gezond uitzien voor een statuscode-crawler, maar bevatten geen geldig llms.txt-signaal.
llms-full.txt: schaarser en grilliger
Het begeleidende bestand llms-full.txt kwam veel minder vaak voor dan llms.txt. De crawl vond 103 geldige volledige bestanden, goed voor 17,58% van de geldige llms.txt-adopters en 1,03% van de volledige Top 10.000-steekproef.
De implementaties van volledige bestanden waren grillig. Van de 103 dubbele adopters hadden er 57 een llms-full.txt-bestand dat groter was dan het indexbestand, maar 46 hadden óf een volledig bestand dat niet groter was dan het indexbestand óf een volledig bestand van minder dan 100 bytes. De mediane verhouding tussen full-file en indexgrootte was 1,43, maar extreme gevallen lagen veel hoger. Het volledige bestand van Supabase was ongeveer 7.139 keer zo groot als het indexbestand. Made-in-China.com had een volledig bestand van 89,89 MB.
| Domein | llms.txt | llms-full.txt | Verhouding |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7.139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Aanbeveling: publiceer
llms-full.txtalleen wanneer de site al een stabiele documentatiepijplijn, versiebeheerdiscipline en een duidelijke reden heeft om grote hoeveelheden content in één machineleesbaar bestand bloot te stellen.
llms.txt, robots.txt en sitemap.xml
llms.txt moet niet worden gezien als een nieuwe robots.txt. Het zijn allebei machineleesbare bestanden op rootniveau, maar ze communiceren iets anders. robots.txt is een signaal voor crawler-voorkeuren en toegangscontrole. sitemap.xml is een signaal voor URL-ontdekking. llms.txt is een verklarend en navigerend signaal.
| Signaal | Primaire rol | Typische lezer | Interpretatie in dit onderzoek |
|---|---|---|---|
robots.txt | Crawler-voorkeuren en beperkingen op padniveau vastleggen. | Zoekcrawlers, AI-crawlers, archiveringscrawlers, generieke bots. | Governance- en toegangssignaal. |
sitemap.xml | Ontdekkbare URL’s voor indexeringssystemen opsommen. | Zoekmachines en indexeringspijplijnen. | Ontdekkingssignaal. |
llms.txt | Compacte sitecontext, belangrijke links, docs, API’s, voorbeelden en beleidsverwijzingen bieden. | LLM-toepassingen, AI-agents, developer-tools, retrievalsystemen. | Verklarings- en navigatiesignaal. |
Aanbevelingen
Voor sites die llms.txt overwegen, wijzen de sterkste implementaties in deze dataset en het externe verkeersbewijs op een pragmatisch patroon:
- Publiceer
/llms.txtop de root en houd het toegankelijk zonder login, JavaScript-uitvoering, consent walls of omleidingen buiten het pad. - Serveer het waar mogelijk als
text/plainoftext/markdown. - Begin met een korte beschrijving van de site en groepeer daarna links per product, documentatie, API, pricing, changelog, voorbeelden, support, beleid en bedrijfsresources.
- Geef de voorkeur aan canonieke links boven uitputtende URL-lijsten.
- Vermijd lege symbolische bestanden; die gelden hooguit als een zwak signaal.
- Vermijd enorme, ongedeferentieerde dumps, tenzij er een sterke use case is voor machineconsumptie en een betrouwbare generatiepijplijn.
- Valideer na publicatie de uiteindelijke URL, responsebody, contenttype, Markdown-structuur, linkaantal en bestandsgrootte.
Teams moeten ook zorgvuldig verwachtingen managen. De beschikbare publieke experimenten bewijzen niet dat llms.txt zelfstandig AI-verwijzingsverkeer verhoogt. Als een team de zakelijke impact wil testen, moet het LLM-verwijzingen, geciteerde pagina’s, botrequests, versheid van indexen en contentwijzigingen samen volgen. Een nuttig experiment zou gematchte paginagroepen vergelijken, contentupdates waar mogelijk constant houden en platformspecifiek verkeer zoals Perplexity, ChatGPT, Gemini, Claude en Bing/Copilot scheiden.
Beperkingen
Dit is een crawl-gebaseerde momentopname, geen permanente waarheid. Websites kunnen op elk moment llms.txt-bestanden toevoegen, verwijderen of wijzigen. Sommige domeinen kunnen geautomatiseerde verzoeken blokkeren of zich anders gedragen per geografische regio, TLS-configuratie, redirectlogica, user agent of botmitigatie. Het onderzoek testte alleen root-level bestanden en doorzocht geen subdomeinen of niet-standaard paden.
De kwaliteitsscore en archetypen zijn onderzoekstools, geen officiële compliancelabels. De topicanalyse is gebaseerd op keywords en moet worden gelezen als richtinggevend. Het onderzoek bewijst niet dat een specifiek AI-platform momenteel llms.txt in productie leest, respecteert of gebruikt.
Het externe verkeersbewijs dat in deze versie is bekeken, heeft ook beperkingen. De analyse van Search Engine Land is sterker als een waarschuwende observatie over meerdere sites dan als een gerandomiseerd experiment. Het resultaat van Alimbekov is nuttig als transparante casestudy op siteniveau, maar het mist een controlegroep en omvat een periode waarin het totale verwijzingsverkeer fors steeg. Deze bronnen helpen het debat te kaderen, maar maken van deze crawl nog geen causale verkeerstudie.
Bestanden en reproduceerbaarheid
| Bestand | Doel |
|---|---|
crawl_llms_txt.py | Crawler voor /llms.txt en /llms-full.txt. |
analyze_llms_txt.py | Primaire adoptieanalyse en grafiekgeneratie. |
deep_analyze_llms_txt.py | Secundaire analyse voor rangdecielen, TLD’s, topicsignalen, kwaliteitsscores, archetypen en dubbelbestandsgedrag. |
deep_dive_early_quality.py | Classificatie van vroege adopters en deep dive in implementatiekwaliteit. |
data/llms_probe_results_top_10000.csv | Hoofddataset met crawlresultaten. |
data/deep_analysis_top_10000.json | Samenvatting van de secundaire analyse. |
data/deep_early_quality_analysis.json | Categorieën van vroege adopters, vergelijking van kwaliteitscohorten, archetypedetails en case studies. |
Bronnen
- , Jeremy Howard, 2024.
- .
- .
- .
- , Data Provenance Initiative.
- .
- , Search Engine Land, januari 2026.
- , Rankability, juni 2025.
- , Renat Alimbekov.
Correcties op de methodologie, datasetproblemen en vervolganalyses zijn welkom via support@thunderbit.com. Dit rapport is onafhankelijk gepubliceerd van elke commerciële positie die Thunderbit inneemt. De data in dit rapport spreekt voor zich. — Het Thunderbit-onderzoeksteam, mei 2026.