Een GitHub-zoekopdracht naar "linkedin scraper" levert per april 2026 ongeveer op. De meeste kosten je vooral tijd. Hard? Misschien. Maar dat is wat ik ontdekte nadat ik acht van de meest zichtbare repos had beoordeeld, tientallen GitHub-issues had doorgespit en communityrapporten van Reddit en scrapingforums had vergeleken. Het patroon komt telkens terug: repos met veel sterren trekken aandacht, het anti-botteam van LinkedIn kijkt mee, detectie wordt gepatcht, en gebruikers blijven achter met kapotte selectors, CAPTCHA-lussen of zelfs accountblokkades. Een Reddit-gebruiker vatte de situatie kernachtig samen: LinkedIn heeft "strengere rate limits, betere botdetectie, sessietracking en frequente wijzigingen" toegevoegd, en oude tools "breken nu snel of markeren accounts/IP's". Als je een salesmedewerker, recruiter of operationsmanager bent die LinkedIn-data in een spreadsheet wil zetten, kan de repo die je vorige maand hebt gekloond nu al waardeloos zijn. Deze gids helpt je bepalen welke GitHub-projecten je tijd echt waard zijn, hoe je voorkomt dat je account wordt gesloopt, en wanneer het slimmer is om de code gewoon over te slaan.
Wat is een LinkedIn Scraper op GitHub?
Een LinkedIn-scraper GitHub-project is een open-source script — meestal in Python, soms in Node.js — dat automatisch gestructureerde data van LinkedIn-pagina's haalt. De gebruikelijke doelen zijn:
- Persoonsprofielen: naam, headline, bedrijf, locatie, vaardigheden, ervaring
- Vacatures: titel, bedrijf, locatie, publicatiedatum, vacature-URL
- Bedrijfspagina's: overzicht, aantal medewerkers, sector, aantal volgers
- Berichten en interactie: inhoud, likes, reacties, shares
Onder de motorkap gebruiken de meeste repos één van twee aanpakken. Browsergestuurde scrapers leunen op Selenium, Playwright of Puppeteer om pagina's te renderen, door flows te klikken en data uit te lezen via CSS-selectors of XPath. Een kleinere groep probeert rechtstreeks LinkedIn's interne (ongedocumenteerde) API-endpoints aan te roepen. En een nieuwere golf — nog zeldzaam op GitHub, maar wel in opkomst — combineert browserautomatisering met een LLM zoals GPT-4o mini om paginataal om te zetten in gestructureerde velden zonder fragiele selectors.
Er zit een fundamentele mismatch tussen vraag en aanbod. Deze tools worden gebouwd door developers die thuis zijn in virtual environments, browserafhankelijkheden en proxyconfiguratie. Maar een groot deel van de mensen die zoeken op "linkedin scraper github" zijn recruiters, SDR's, RevOps-managers en oprichters die gewoon rijen in een spreadsheet willen.
Die kloof verklaart de meeste frustratie in de issue-threads.
Waarom mensen GitHub gebruiken voor LinkedIn-scraping
De aantrekkingskracht is duidelijk. Gratis. Aanpasbaar. Geen vendor lock-in. Volledige controle over je datapijplijn. Als een SaaS-tool de prijs wijzigt of ermee stopt, blijft je code bestaan.
| Use case | Wie heeft dit nodig? | Typische data die wordt gehaald |
|---|---|---|
| Leadgeneratie | Salesteams | Namen, titels, bedrijven, profiel-URL's, aanwijzingen voor e-mailadressen |
| Kandidaatwerving | Recruiters | Profielen, vaardigheden, ervaring, locaties |
| Marktonderzoek | Operations- en strategieteams | Bedrijfsgegevens, aantal medewerkers, vacatures |
| Concurrentieanalyse | Marketingteams | Berichten, engagement, bedrijfsupdates, signalen rond werving |
Maar "gratis" is een licentielabel, geen operationele kostenpost. De echte kosten zijn:
- Insteltijd: zelfs vriendelijke repos vereisen meestal 30 minuten tot ruim 2 uur om de omgeving, browserafhankelijkheden, cookie-extractie en proxyconfiguratie op te zetten
- Onderhoud: LinkedIn past zijn DOM en anti-botverdediging regelmatig aan — een scraper die vandaag werkt, kan volgende week al stuk zijn
- Proxies: residential proxy-bandbreedte kost ongeveer , afhankelijk van aanbieder en abonnement
- Accountrisico: je LinkedIn-account is het duurste wat op het spel staat, en dat vervang je niet even zoals een proxy-IP
De repo-gezondheidsscorekaart: hoe je elk LinkedIn Scraper GitHub-project beoordeelt
De meeste lijsten met de "beste LinkedIn scrapers" rangschikken repos op aantal sterren. Sterren meten historische interesse, niet of iets nu nog werkt. Een repo met 3.000 sterren en geen commits sinds 2022 is een museumstuk, geen productietool.
Voordat je iets git clonet, gebruik dit kader:
| Criteria | Waarom het telt | Rode vlag |
|---|---|---|
| Datum van laatste commit | LinkedIn wijzigt de DOM vaak | > 6 maanden geleden voor browsergestuurde repos |
| Verhouding open/gesloten issues | Responsiviteit van de maintainer | > 3:1 open tegenover gesloten, vooral met recente meldingen over "blocked" of "CAPTCHA" |
| Anti-detectiefuncties | LinkedIn bant agressief | Geen vermelding van cookies, sessies, pacing of proxies in de README |
| Authenticatiemethode | 2FA en CAPTCHA breken inlogflows | Alleen wachtwoordgebaseerde headless login |
| Licentietype | Juridische blootstelling bij commercieel gebruik | Geen licentie of vage voorwaarden |
| Ondersteunde datatypes | Verschillende use-cases hebben verschillende repos nodig | Slechts één datatype terwijl je er meerdere nodig hebt |
De ene truc die de meeste tijd bespaart: zoek vóór je je vastlegt op een repo in het Issues-tabblad op "blocked", "banned", "CAPTCHA" of "not working". Als recente issues vol staan met die termen en de maintainer reageert niet, loop dan door. Die repo heeft de strijd al verloren.
Wat de audit van 2026 echt liet zien
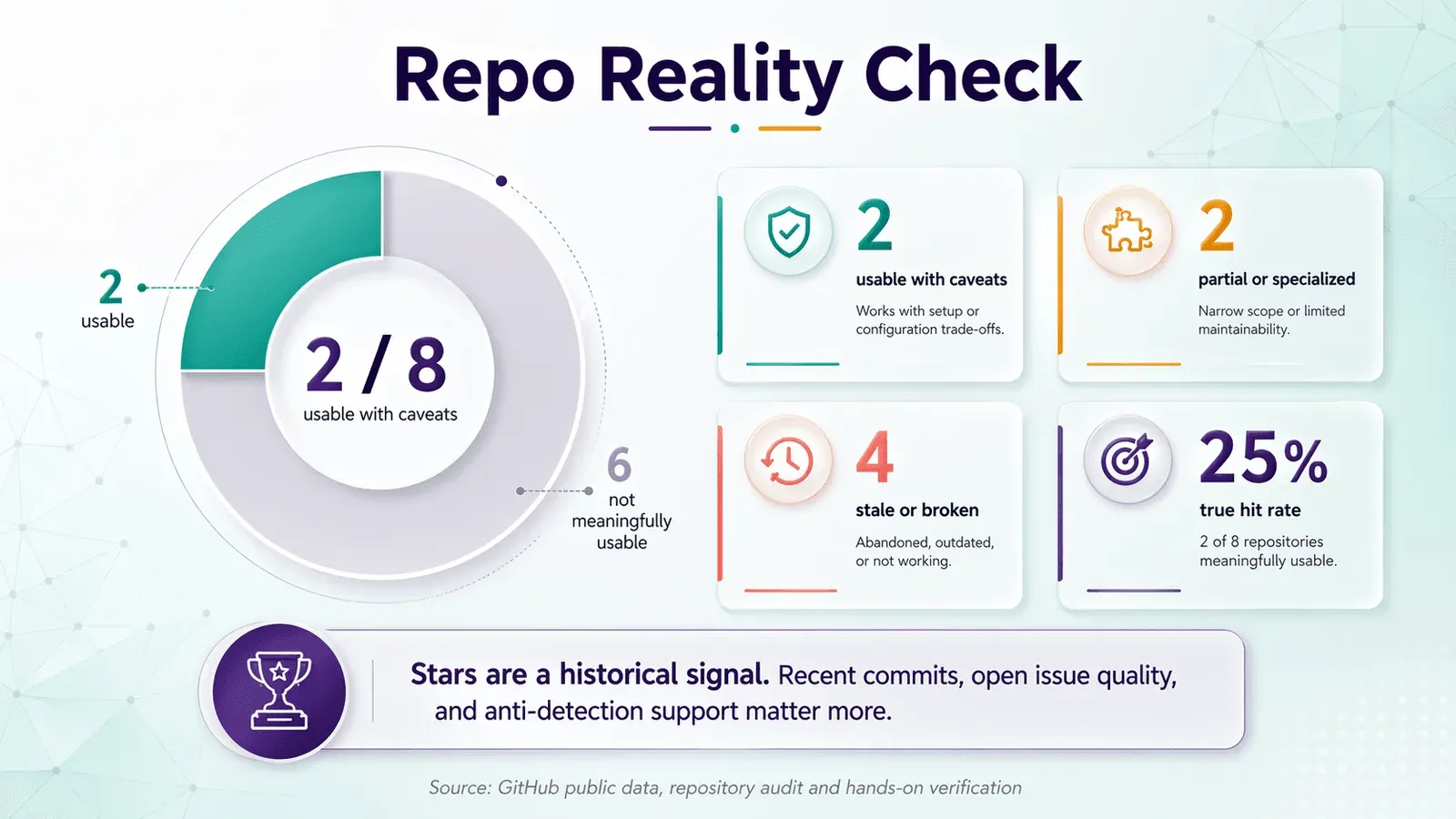
Ik heb deze scorekaart toegepast op acht van de meest zichtbare LinkedIn-scraper repos op GitHub. De resultaten waren niet bemoedigend.
| Repo | Sterren | Laatste commit | Werkt in 2026? | Hoofdfocus | Belangrijkste opmerkingen |
|---|---|---|---|---|---|
| joeyism/linkedin_scraper | ~3.983 | apr 2026 | ✅ Met kanttekeningen | Profielen, bedrijven, berichten, vacatures | Playwright-herschrijving, hergebruik van sessies — maar recente issues tonen beveiligingsblokkades en kapotte vacaturezoekopdrachten |
| python-scrapy-playbook/linkedin-python-scrapy-scraper | ~111 | jan 2026 | ✅ Voor tutorials/openbare data | Personen, bedrijven, vacatures | ScrapeOps-proxyintegratie; gratis plan staat 1.000 verzoeken/maand toe met 1 thread |
| spinlud/py-linkedin-jobs-scraper | ~472 | mrt 2025 | ⚠️ Alleen vacatures | Vacatures | Cookie-ondersteuning, experimentele proxymodus — handig als je alleen openbare vacatures nodig hebt |
| madingess/EasyApplyBot | ~170 | mrt 2025 | ⚠️ Verkeerde tool | Easy Apply-automatisering | Geen datascraper — automatiseert sollicitaties |
| linkedtales/scrapedin | ~611 | mei 2021 | ❌ | Profielen | README zegt nog steeds "working in 2020"; issues tonen pincodeverificatie en HTML-wijzigingen |
| austinoboyle/scrape-linkedin-selenium | ~526 | okt 2022 | ❌ | Profielen, bedrijven | Ooit nuttig, nu te verouderd voor 2026 |
| eilonmore/linkedin-private-api | ~291 | jul 2022 | ❌ | Profielen, vacatures, bedrijven, berichten | Wrapper voor private API; ongedocumenteerde endpoints verschuiven onvoorspelbaar |
| nsandman/linkedin-api | ~154 | jul 2019 | ❌ | Profielen, berichten, zoeken | Historisch interessant; gedocumenteerde rate limiting na ongeveer 900 verzoeken/uur |
Slechts 2 van de 8 repos leken in 2026 echt bruikbaar zonder zware kanttekeningen. Dat is niet uitzonderlijk — het is de norm voor LinkedIn-scraping op GitHub.
Het banpreventie-handboek: proxies, rate limits en accountveiligheid
Accountbans vormen het grootste operationele risico. Zelfs technisch capabele scrapers lopen hier vast. De code werkt; het account niet. Gebruikers melden dat ze al na 40 tot 80 profielen worden gemarkeerd, zelfs met proxies en lange pauzes.
Rate limiting: wat de community meldt

Er bestaat geen gegarandeerd veilig aantal. LinkedIn beoordeelt sessieleeftijd, kliktempo, burstpatronen, IP-reputatie en accountgedrag — niet alleen de ruwe aantallen. Communitydata clustert rond deze bandbreedtes:
- Een gebruiker meldde detectie na 40–80 profielen met proxies en een tempo van 33 seconden
- Een ander adviseerde om rond de 30 profielen/dag/account te blijven
- Een agressievere operator claimde verspreid over de dag
- documenteerde een interne rate-limit-waarschuwing na ongeveer 900 verzoeken in één uur
De praktische samenvatting: onder 50 profielweergaven/dag/account zit je in de lagerisicogroep. 50–100/dag is middelmatig risico, waarbij sessiekwaliteit erg belangrijk wordt. Boven 100/dag/account kom je steeds duidelijker in agressief terrein.
Proxystrategie: residential vs. datacenter
Residential proxies blijven de standaard voor LinkedIn omdat ze eruitzien als normaal eindgebruikersverkeer. Datacenter-IP's zijn goedkoper, maar worden op geavanceerde sites sneller gemarkeerd — en LinkedIn is precies zo'n site waar goedkoop verkeer opvalt.
Huidige prijscontext:
- : $3,00–$4,00/GB, afhankelijk van plan
- : $4,00–$6,00/GB, afhankelijk van plan
Wissel per sessie, niet per verzoek. Rotatie per request creëert een fingerprint die harder "proxy-infrastructuur" schreeuwt dan welk afzonderlijk IP dan ook.
Protocol voor een burner-account
De community is hier duidelijk over: behandel je hoofd-LinkedIn-account niet als wegwerpbare scraping-infrastructuur.
Als je toch met account-gebonden scraping werkt:
- Gebruik een apart account van je primaire professionele identiteit
- Vul het profiel volledig in en laat het dagenlang menselijk gedrag vertonen voordat je begint met scrapen
- Koppel nooit je echte telefoonnummer aan scraping-accounts
- Houd scraping-sessies volledig gescheiden van echte outreach en berichtenverkeer
Let op: LinkedIn's (van kracht sinds 3 november 2025) verbiedt expliciet valse identiteiten en het delen van accounts. De burner-accounttactiek komt operationeel vaak voor, maar zit contractueel lastig in elkaar.
Omgaan met CAPTCHA's
Een CAPTCHA is niet alleen hinderlijk. Het is een signaal dat je sessie al onder de loep ligt. Opties zijn onder meer:
- Handmatig oplossen om de sessie voort te zetten
- Cookies hergebruiken in plaats van inlogflows opnieuw uitvoeren
- Solverdiensten zoals (~$0,50–$1,00 per 1.000 image-CAPTCHA's, ~$1,00–$2,99 per 1.000 reCAPTCHA v2-oplossingen)
Maar als je workflow regelmatig CAPTCHA's triggert, zijn de kosten van solverdiensten nog het kleinste probleem. Je stack verliest de stealthstrijd.
Het risicospectrum
| Volume | Risiconiveau | Aanbevolen aanpak |
|---|---|---|
| < 50 profielen/dag | Laag | Browser-sessie of cookiehergebruik, langzaam tempo, geen agressieve automatisering |
| 50–500 profielen/dag | Middel tot hoog | Residential proxies, opgewarmde accounts, sessiehergebruik, willekeurige vertragingen |
| 500+/dag | Zeer hoog | Commerciële API's of onderhouden tooling met ingebouwde anti-detectie; alleen publieke GitHub-repos zijn meestal niet genoeg |
De open-sourceparadox: waarom populaire LinkedIn Scraper GitHub-repos sneller stukgaan
Gebruikers brengen een terechte zorg naar voren: "Als je een open-source versie maakt, kan LinkedIn gewoon zien wat je doet en het blokkeren." Die zorg is niet paranoïde. Ze klopt structureel.
Het zichtbaarheidprobleem
Veel sterren creëren tegelijk twee signalen: vertrouwen voor gebruikers en een doelwit voor LinkedIn's securityteam. Hoe populairder een repo wordt, hoe waarschijnlijker het is dat LinkedIn specifiek de gebruikte methodes gaat tegenwerken.
Je ziet die levenscyclus terug in de auditdata. linkedtales/scrapedin was ooit populair genoeg om te vermelden dat het werkte met de "nieuwe website" van LinkedIn in 2020. Maar de repo bleef niet bij met latere verificatie- en layoutwijzigingen. nsandman/linkedin-api documenteerde ooit nuttige trucs, maar de laatste commit lag jaren vóór de huidige anti-botomgeving.
Het voordeel van community-patches
Open source heeft nog steeds één echte troef: actieve maintainers en bijdragers kunnen snel patchen wanneer LinkedIn zijn verdediging aanpast. joeyism/linkedin_scraper is het belangrijkste voorbeeld uit deze audit — het geeft nog steeds issues rond geblokkeerde authenticatie en kapotte zoekopdrachten, maar het beweegt tenminste nog. Forks implementeren vaak sneller nieuwere ontwijktechnieken dan de oorspronkelijke repo.
Wat je eraan kunt doen
- Vertrouw niet op één openbare repo als permanente infrastructuur
- Let op actieve forks die bijgewerkte ontwijktechnieken implementeren
- Overweeg een private fork voor productiegebruik te onderhouden (zodat je specifieke aanpassingen niet openbaar zijn)
- Verwacht van methode te moeten veranderen zodra LinkedIn detectie of UI-gedrag aanpast
- Diversifieer je aanpak in plaats van alles op één tool te zetten
AI-gestuurde extractie versus CSS-selectors: een praktische vergelijking

De interessantere technische splitsing in 2026 is niet GitHub versus no-code. Het is selectorgebaseerde extractie versus semantische extractie — en dat verschil is belangrijker dan de meeste overzichten toegeven.
Hoe CSS-selectors werken (en breken)
Traditionele scrapers inspecteren LinkedIn's DOM en koppelen elk veld aan een CSS-selector of XPath-expressie. Als de paginastuctuur stabiel is, is dat een uitstekende aanpak: hoge precisie, lage marginale kosten, heel snel parsen.
Het faalmechanisme is even duidelijk. LinkedIn verandert class-namen, nesting, lazy-loading-gedrag of zet content achter andere auth-walls — en de scraper breekt meteen. De issue-titels in de repo-audit vertellen het verhaal: "changed HTML", "broken job search", "missing values", "authwall blocks."
Hoe AI/LLM-extractie werkt
Het nieuwere patroon is conceptueel eenvoudiger: render de pagina, verzamel de zichtbare tekst, en laat een model gestructureerde velden uitspugen. Dat is de logica achter veel no-code AI-scrapers en sommige nieuwere maatwerkflows.
Met de huidige ($0,15/1M inputtokens, $0,60/1M outputtokens) kost een tekst-only extractieronde voor één profiel doorgaans $0,0006–$0,0018 per profiel. Dat is klein genoeg om bij workflows met middelgroot volume nauwelijks mee te wegen.
Vergelijking naast elkaar
| Dimensie | CSS-selector / XPath | AI/LLM-extractie |
|---|---|---|
| Instelwerk | Hoog — DOM inspecteren, selectors per veld schrijven | Laag — gewenste output in natuurlijke taal beschrijven |
| Breuk bij layoutwijzigingen | Breekt meteen | Past zich automatisch aan (leest semantisch) |
| Nauwkeurigheid op gestructureerde velden | ~99% wanneer selectors kloppen | ~95–98% (af en toe interpretatiefouten van het LLM) |
| Omgaan met ongestructureerde/variabele data | Zwak zonder aangepaste logica | Sterk — AI interpreteert context |
| Kosten per profiel | Bijna nul (alleen compute) | ~$0,001–$0,002 (API-tokencost) |
| Labelen/categoriseren | Vereist aparte nabewerking | Kan in één keer categoriseren, vertalen en labelen |
| Onderhoudslast | Doorlopend selectorfixes | Bijna nul |
Welke moet je kiezen?
Voor pijplijnen met heel hoog volume, stabiel en in handen van engineers, kan selectorgebaseerde parsing qua kosten nog steeds winnen. Voor de meeste kleine en middelgrote gebruikers die honderden — en niet miljoenen — profielen scrapen, is AI-extractie de betere langetermijninvestering, omdat wijzigingen in LinkedIn's lay-out meer kosten in ontwikkeltijd dan de modeltokens die je bespaart.
Wanneer GitHub-repos overkill zijn: de no-code route
De meeste mensen die zoeken op "linkedin scraper github" willen geen onderhoudsbeheerders van browserautomatisering worden.
Ze willen rijen in een tabel.
Gebruikers klagen in issue-threads expliciet over de bruikbaarheid van GitHub-scrapers: "It does not handle 2FA and it is not easy to use since there is no UI." Het publiek bestaat uit recruiters, SDR's en operationsmanagers — niet alleen Python-developers.
De beslissing build versus buy
| Factor | GitHub-repo | No-code tool (bijv. Thunderbit) |
|---|---|---|
| Insteltijd | 30 min–2+ uur (Python, afhankelijkheden, proxies) | Minder dan 2 minuten (extensie installeren, klikken) |
| Onderhoud | Jij fixt het wanneer LinkedIn verandert | De toolprovider verzorgt updates |
| Anti-detectie | Jij configureert proxies, vertragingen, sessies | Ingebouwd in de tool |
| Datastructurering | Jij schrijft parsinglogica | AI stelt velden automatisch voor |
| Exportopties | Jij bouwt de exportpijplijn | Eén klik naar Excel, Google Sheets, Airtable, Notion |
| Kosten | Gratis repo + proxykosten + jouw tijd | Gratis tier beschikbaar; op credits gebaseerd bij volume |
Hoe Thunderbit LinkedIn-scraping zonder code aanpakt
pakt dit anders aan dan GitHub-repos. In plaats van selectors te schrijven of browserautomatisering te configureren, doe je het volgende:
- Installeer de
- Ga naar een LinkedIn-pagina (zoekresultaten, profiel, bedrijfspagina)
- Klik op "AI Suggest Fields" — Thunderbit's AI leest de pagina en stelt gestructureerde kolommen voor (naam, titel, bedrijf, locatie, enz.)
- Pas indien nodig kolommen aan en klik vervolgens om te extraheren
- Exporteer direct naar Excel, Google Sheets, of Notion
Omdat Thunderbit AI gebruikt om de pagina elke keer semantisch te lezen, breekt het niet wanneer LinkedIn zijn DOM wijzigt. Dat is hetzelfde voordeel als de GPT-geïntegreerde aanpak in maatwerk Python-scripts, maar dan verpakt in een no-code extensie in plaats van een codebase die je zelf onderhoudt.
Voor — doorklikken naar individuele profielen vanuit een lijst met zoekresultaten om je datatabel te verrijken — regelt Thunderbit dat automatisch. De browsertmodus werkt ook op pagina's waarvoor je moet inloggen, zonder aparte proxyconfiguratie.
Wie zou nog steeds een GitHub-repo moeten gebruiken?
GitHub-repos blijven logisch voor:
- Developers die diepe maatwerkopties of ongebruikelijke datatypes nodig hebben
- Teams die op zeer hoog volume scrapen, waar kosten per credit ertoe doen
- Gebruikers die scraping in CI/CD-pijplijnen of op servers willen draaien
- Mensen die LinkedIn-data in grotere geautomatiseerde workflows inbouwen
Voor alle anderen — vooral sales-, recruitment- en operations-teams — haalt de de hele opzet- en onderhoudscyclus weg.
Stap voor stap: hoe je een LinkedIn Scraper van GitHub evalueert en gebruikt
Als je hebt besloten dat GitHub de juiste route is, volgt hier een gefaseerde workflow die verspilde tijd en accountrisico minimaliseert.
Stap 1: Zoek en maak een shortlist van repos
Zoek op GitHub naar "linkedin scraper" en filter op:
- Recent bijgewerkt (laatste 6 maanden)
- Taal die overeenkomt met jouw stack (Python komt het vaakst voor)
- Scope die past bij je echte behoefte (profielen vs. vacatures vs. bedrijven)
Maak een shortlist van 3–5 repos die levend lijken.
Stap 2: Pas de repo-gezondheidsscorekaart toe
Haal elke repo door de scorekaart van eerder. Schrap alles met:
- Geen commits in het afgelopen jaar
- Onopgeloste issues over "blocked" of "CAPTCHA"
- Alleen wachtwoordauthenticatie
- Geen vermelding van sessies, cookies of proxies
Stap 3: Richt je omgeving in
Veelvoorkomende setup-commando's uit de repos in deze audit:
1pip install linkedin-scraper
2playwright install chromium
3pip install linkedin-jobs-scraper
4LI_AT_COOKIE=<cookie> python your_app.py
5scrapy crawl linkedin_people_profileTerugkerende pijnpunten:
- Ontbrekende
session.json-bestanden - Versiemismatches van browserdrivers (Chromium/Playwright)
- Cookies extraheren uit browser-DevTools
- Time-outs bij proxy-authenticatie
Stap 4: Doe een kleine testscrape
Begin met 10–20 profielen. Controleer:
- Worden velden correct geparseerd?
- Is de data compleet?
- Ben je op beveiligingscontroles gestuit?
- Is het outputformaat bruikbaar of vooral ruwe JSON-ruis?
Stap 5: Schaal voorzichtig op
Voeg willekeurige vertragingen toe (5–15 seconden tussen verzoeken), verlaag de concurrency, hergebruik sessies en gebruik residential proxies. Ga niet meteen naar honderden profielen per dag met een nieuw account.
Stap 6: Exporteer en structureer je data
De meeste GitHub-repos leveren ruwe JSON of CSV op. Je moet dan nog steeds:
- Records dedupliceren
- Titels en bedrijfsnamen normaliseren
- Velden mappen naar je CRM of ATS
- De herkomst van data documenteren voor compliance
(Thunderbit regelt structurering en export automatisch als je deze stap liever overslaat.)
LinkedIn Scraper GitHub versus no-code tools: de volledige vergelijking
| Dimensie | GitHub-repo (CSS-selectors) | GitHub-repo (AI/LLM) | No-code tool (Thunderbit) |
|---|---|---|---|
| Insteltijd | 1–2+ uur | 1–3+ uur (+ API-sleutel) | Minder dan 2 minuten |
| Technische vaardigheid | Hoog (Python, CLI) | Hoog (Python + LLM-API's) | Geen |
| Onderhoud | Hoog (selectors breken) | Middel (LLM past zich aan, code heeft nog steeds updates nodig) | Geen (provider onderhoudt) |
| Anti-detectie | DIY (proxies, vertragingen) | DIY | Ingebouwd |
| Nauwkeurigheid | Hoog als het werkt | Hoog met af en toe LLM-fouten | Hoog (AI-gestuurd) |
| Kosten | Gratis + proxykosten + jouw tijd | Gratis + LLM-API-kosten + proxykosten | Gratis tier; op credits gebaseerd bij volume |
| Export | DIY (JSON, CSV) | DIY | Excel, Sheets, Airtable, Notion |
| Beste voor | Developers, maatwerkpijplijnen | Developers die minder onderhoud willen | Sales-, recruitment- en operations-teams |
Juridische en ethische overwegingen
Ik houd dit kort, maar je kunt het niet overslaan.
LinkedIn's (van kracht sinds 3 november 2025) verbiedt expliciet het gebruik van software, scripts, robots, crawlers of browserplugins om de dienst te scrapen. LinkedIn heeft dit ook afgedwongen:
- : LinkedIn kondigde juridische stappen aan tegen Proxycurl
- : LinkedIn meldde dat die zaak was afgerond
- : Law360 meldde dat LinkedIn extra gedaagden aanklaagde wegens scraping op industriële schaal
De hiQ v. LinkedIn-reeks van zaken bracht enige nuance aan rond toegang tot openbare data, maar vielen in het voordeel van LinkedIn uit op basis van contractbreuk. "Publiek zichtbaar" betekent niet "duidelijk veilig om op schaal te scrapen voor commercieel hergebruik".
Voor workflows met een EU-link geldt de . De handhavingsactie tegen door de Franse datawaakhond is een concreet voorbeeld van toezichthouders die gescrapete LinkedIn-data als persoonsgegevens behandelen die onder privacyregels vallen.
Het gebruik van een onderhouden tool zoals Thunderbit verandert je wettelijke verplichtingen niet. Wel verkleint het de kans dat je per ongeluk beveiligingsreacties triggert of rate limits overschrijdt op een manier die LinkedIn's aandacht trekt.
Wat in 2026 wel en niet werkt
Wat wel werkt
- De repo-gezondheidsscorekaart toepassen vóór je je vastlegt op een repo
- Cookies/sessies hergebruiken in plaats van herhaaldelijk automatisch inloggen
- Residential proxies wanneer je account-gebonden scraping moet draaien
- Kleinere, langzamere, menselijk ogende scrapingworkflows
- AI-ondersteunde extractie wanneer aanpasbaarheid belangrijker is dan marginale tokenkosten
- wanneer de echte behoefte spreadsheetoutput is, niet eigenaarschap van de scraper
- Aanpakken diversifiëren in plaats van op één openbare repo te gokken
Wat niet werkt
- Hoge-starrepos klonen zonder onderhoudsstatus of recente issues te controleren
- Datacenterproxies of gratis proxy-lijsten voor LinkedIn gebruiken
- Opschalen naar honderden profielen per dag zonder rate limits of anti-detectie
- Op de lange termijn op CSS-selectors vertrouwen zonder onderhoudsplan
- Je echte LinkedIn-account behandelen als wegwerp-infrastructuur
- "Publiek toegankelijk" verwarren met "contractueel of juridisch probleemloos"
FAQ's
Werken LinkedIn-scraper GitHub-repos in 2026 nog steeds?
Sommige wel, maar slechts een kleine subset. In deze audit van acht zichtbare repos leken er maar twee echt bruikbaar voor een lezer in 2026 zonder zware kanttekeningen. De sleutel is repos beoordelen op onderhoudsactiviteit en issuegezondheid, niet op het aantal sterren. Gebruik de repo-gezondheidsscorekaart voordat je tijd steekt in de setup van welk project dan ook.
Hoeveel LinkedIn-profielen kan ik per dag scrapen zonder geblokkeerd te worden?
Er is geen gegarandeerd veilig aantal, omdat LinkedIn sessiegedrag beoordeelt en niet alleen volume. Communityrapporten suggereren dat onder 50 profielen/dag/account het laagste risicogebied is, 50–100/dag middelmatig risico is waarbij de kwaliteit van de infrastructuur belangrijk wordt, en boven 100/dag steeds agressiever wordt. Willekeurige vertragingen van 5–15 seconden en residential proxies helpen, maar nemen het risico nooit helemaal weg.
Is er een no-code alternatief voor LinkedIn-scraper GitHub-projecten?
Ja. laat je LinkedIn-pagina's in een paar klikken scrapen met AI-gestuurde veldherkenning, browsergebaseerde authenticatie (geen proxyconfiguratie nodig) en export met één klik naar Excel, Google Sheets, Airtable of Notion. Het is ontworpen voor sales-, recruitment- en operations-teams die data willen zonder code te onderhouden. Je kunt het proberen via de .
Is het scrapen van LinkedIn-data legaal?
Het zit in een grijs gebied met steeds scherpere randen. LinkedIn's User Agreement verbiedt scraping expliciet, en LinkedIn heeft in juridische stappen tegen scrapers ondernomen. Het hiQ v. LinkedIn-precedent over toegang tot openbare data is door recentere uitspraken ingeperkt. De AVG/GDPR geldt voor persoonsgegevens van EU-inwoners, ongeacht hoe die zijn verzameld. Zoek voor elk commercieel gebruik juridisch advies dat op jouw situatie is toegesneden.
AI-extractie of CSS-selectors — wat moet ik gebruiken voor LinkedIn-scraping?
CSS-selectors zijn sneller en goedkoper per record wanneer ze werken, maar ze creëren een onderhoudstredmolen omdat LinkedIn zijn DOM regelmatig aanpast. AI/LLM-extractie kost per profiel iets meer (~$0,001–$0,002 bij de huidige ), maar past zich automatisch aan lay-outwijzigingen aan. Voor de meeste niet-enterprise gebruikers die honderden in plaats van miljoenen profielen scrapen, is AI-extractie de betere langetermijninvestering. Thunderbit's ingebouwde AI-engine biedt dit voordeel zonder dat je code hoeft te schrijven of te onderhouden.
Meer weten