

“Is het legaal om data van websites te scrapen?” Die vraag krijg ik bijna elke week van sales-, operations- en marketingteams. Webscraping is tegenwoordig niet meer weg te denken voor alles van leadgeneratie tot concurrentieanalyse, dus het is logisch dat iedereen duidelijkheid wil. Maar eerlijk? De juridische situatie is allesbehalve zwart-wit. Kijk maar naar het nieuws: de ene rechter vindt het scrapen van openbare data prima, terwijl een andere waarschuwt voor ‘illegale dataverzameling’. Geen wonder dat veel teams twijfelen of ze niet te ver gaan.
Feit blijft: meer dan tweederde van de organisaties gebruikt webscraping voor analyses en AI-projecten, en maar liefst 78% van de e-commercebedrijven vertrouwt erop voor prijsinformatie. Maar met spraakmakende rechtszaken als LinkedIn vs. hiQ Labs is de druk hoger dan ooit. Hoe kun je de kracht van webdata benutten zonder juridische problemen? We zetten de belangrijkste regels, checks en best practices op een rij die elke zakelijke gebruiker moet kennen. En ja, ik laat zien hoe Thunderbit compliant scrapen een stuk makkelijker maakt.
De juridische context: is data scrapen van websites toegestaan?
Juridische gevolgen van webscraping Lees meer over de juridische kant van webscraping en hoe je compliant blijft. Get Started Free
Kort gezegd: of webscraping legaal is, hangt af van wat je scrapt, hoe je dat doet en waar je je bevindt. Er is geen wereldwijde wet die zegt “scrapen is legaal” of “scrapen is verboden”. In plaats daarvan heb je te maken met een wirwar van regels—denk aan anti-hackwetgeving, privacyregels, auteursrecht en zelfs de gebruiksvoorwaarden van websites (Thunderbit Blog).
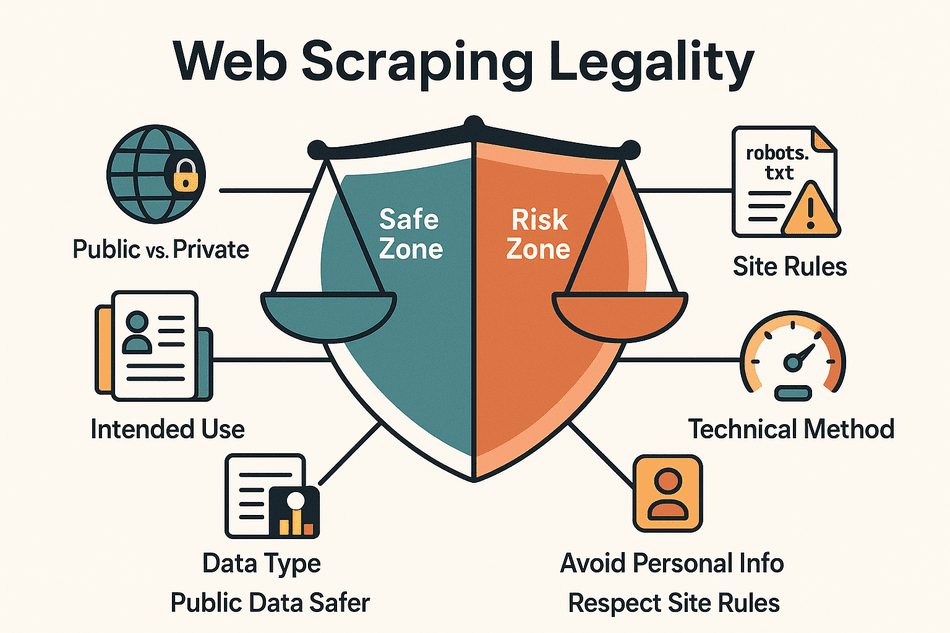
Dit zijn de belangrijkste factoren die bepalen of jouw scrapingproject binnen de lijntjes blijft:
- Openbare vs. afgeschermde data: Data die voor iedereen toegankelijk is (geen login, geen betaalmuur) is meestal veiliger. Probeer je achter een login te komen, dan begeef je je snel op glad ijs.
- Soort data: Persoonsgegevens (zoals namen, e-mails of social media-profielen) en auteursrechtelijk beschermd materiaal (artikelen, afbeeldingen) zijn veel risicovoller dan feitelijke informatie (prijzen, productspecificaties, bedrijfsgegevens).
- Doel van gebruik: Data intern gebruiken (voor analyse of onderzoek) is veel minder risicovol dan het opnieuw publiceren of verkopen ervan.
- Naleving van website-regels: Overtreed je de gebruiksvoorwaarden of negeer je het robots.txt-bestand, dan kun je in de problemen komen—zelfs als de data openbaar is.
- Technische aanpak: Scrapen op een tempo dat lijkt op menselijk gedrag en het niet omzeilen van beveiligingen (zoals CAPTCHAs of IP-blokkades) verkleint het risico.
 (https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
Kortom: Het scrapen van openbare, niet-persoonlijke data voor intern gebruik wordt in veel regio’s geaccepteerd, maar er zijn belangrijke kanttekeningen—vooral rond privacy, auteursrecht en de manier waarop je scrapt (Thunderbit Blog).
(https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
Kortom: Het scrapen van openbare, niet-persoonlijke data voor intern gebruik wordt in veel regio’s geaccepteerd, maar er zijn belangrijke kanttekeningen—vooral rond privacy, auteursrecht en de manier waarop je scrapt (Thunderbit Blog).
Juridisch kader: de belangrijkste internationale regels rond data scraping
 Hier een kort overzicht van de belangrijkste juridische kaders wereldwijd:
Hier een kort overzicht van de belangrijkste juridische kaders wereldwijd:
Verenigde Staten: CFAA, auteursrecht en contracten
- Computer Fraud and Abuse Act (CFAA): Deze anti-hackwet verbiedt ongeautoriseerde toegang tot computersystemen. Maar rechters hebben bepaald dat het scrapen van openbare websites niet onder de CFAA valt, omdat er geen ‘toestemming’ nodig is (California Lawyers Association).
- Belangrijke zaak: In hiQ Labs v. LinkedIn oordeelde het hof dat het scrapen van openbare LinkedIn-profielen geen CFAA-overtreding was. LinkedIn kan echter nog steeds procederen op basis van schending van de gebruiksvoorwaarden of auteursrecht.
- Andere risico’s: Als je extreem veel requests doet (zoals de bot in eBay v. Bidder’s Edge met 100.000 verzoeken per dag), kun je aansprakelijk zijn voor ‘trespass to chattels’—oftewel het verstoren van andermans servers (Wikipedia).
Europese Unie: AVG en databankrechten
- AVG (GDPR): De Algemene Verordening Gegevensbescherming geldt ook voor openbare persoonsgegevens. Als je data verzamelt waarmee iemand te identificeren is, heb je een wettelijke grondslag nodig (zoals toestemming of gerechtvaardigd belang) en moet je strikte privacyregels volgen.
- Databankenrichtlijn: De EU beschermt ook databanken als geheel. Het scrapen van een ‘substantieel deel’ van een gestructureerde databank (zoals alle advertenties van een vastgoedsite) kan databankrechten schenden—zelfs als de losse feiten niet auteursrechtelijk beschermd zijn (Thunderbit Blog).
Verenigd Koninkrijk: UK GDPR en Data Protection Act
- UK GDPR: Na Brexit zijn de regels vergelijkbaar met die van de EU. Openbare, niet-persoonlijke data scrapen is meestal toegestaan, maar persoonsgegevens zijn streng gereguleerd.
- Computer Misuse Act: Net als de CFAA kan deze wet ongeautoriseerde toegang strafbaar maken.
China: PIPL en Data Security Law
- Personal Information Protection Law (PIPL): Vereist toestemming voor het verzamelen van persoonsgegevens. Zonder toestemming persoonsgegevens van Chinese websites scrapen is uit den boze.
- Data Security Law: Wordt ingezet tegen scraping die de data-eigenaar schaadt of oneerlijke concurrentie veroorzaakt.
Overige regio’s
- Canada, Australië, APAC: De meeste landen hebben anti-hackwetgeving en privacyregels vergelijkbaar met de EU/UK. Controleer altijd de lokale wetgeving voordat je gaat scrapen.
Belangrijkste les: Het veiligst is om openbare, niet-persoonlijke data te scrapen voor intern gebruik, en altijd de regels in jouw regio te checken (Thunderbit Blog).
Compliance checklist: hoe zorg je dat jouw scraping legaal is?
Voordat je begint, loop deze compliance checklist door:
- Lees de gebruiksvoorwaarden van de website: Staat er ‘geen scraping toegestaan’, stop dan of vraag eerst toestemming (Thunderbit Blog).
- Blijf bij openbare data: Scrape niets achter een login of betaalmuur zonder expliciete toestemming.
- Check robots.txt: Kijk op
site.com/robots.txtof bots zijn uitgesloten van bepaalde delen. Het is niet wettelijk bindend, maar het is netjes om het te respecteren. - Vermijd persoonsgegevens: Verzamel geen namen, e-mails of andere PII zonder wettelijke basis en privacyplan.
- Kopieer geen creatieve content: Beperk je tot feitelijke data. Het herpubliceren van artikelen, afbeeldingen of grote stukken tekst kan tot auteursrechtclaims leiden.
- Gebruik officiële API’s als die er zijn: Als de site een API aanbiedt, gebruik die—dat is veiliger en stabieler.
- Scrape voorzichtig: Overbelast servers niet. Scrape op menselijk tempo en omzeil geen technische beveiligingen.
- Documenteer je proces: Houd bij wat je hebt gescrapet, wanneer en waarom. Dit helpt als er later vragen komen.
- Wees bereid te stoppen: Krijg je een ‘cease-and-desist’-brief, stop dan direct en heroverweeg je aanpak.
Thunderbit’s compliant scraping: veiliger en betrouwbaarder data extraheren
Bij het ontwikkelen van Thunderbit stond compliance centraal. Zo helpt Thunderbit je om binnen de regels te blijven:
- Scrapen via de browser: Thunderbit scrapt alleen wat zichtbaar is in je browser—geen verborgen API-calls, geen hacks om logins te omzeilen. Wat jij niet ziet, kan Thunderbit ook niet scrapen (Thunderbit Blog).
- Ingebouwde waarschuwingen: Probeer je te scrapen op een site met strenge anti-scrapingregels, dan krijg je een waarschuwing. Alsof er een compliance-expert meekijkt.
- AI-veld suggesties: Thunderbit’s AI scant de pagina en stelt alleen relevante velden voor—zo voorkom je dat je per ongeluk gevoelige of onnodige data verzamelt (Thunderbit Blog).
- Menselijk tempo: Of je nu lokaal of in de cloud scrapt, Thunderbit houdt het tempo netjes om servers niet te overbelasten.
- Geen data-opslag op onze servers: Je data gaat direct naar jou—Thunderbit bewaart geen kopie, wat goed is voor privacy.
- Compliance-vriendelijke export: Exporteer direct naar Google Sheets, Excel, Airtable of Notion—ideaal voor intern gebruik.
- Subpagina’s & paginering: Thunderbit navigeert als een echte gebruiker door pagina’s en subpagina’s, zonder endpoints te forceren.
- Geplande scraping met beleid: Stel geplande scrapes in op verantwoorde intervallen, zodat je een site niet overbelast.
- Meertalige ondersteuning: Thunderbit ondersteunt 34 talen, zodat compliance-advies wereldwijd toegankelijk is.
Kortom, Thunderbit “bouwt compliance in” zodat je verantwoord kunt scrapen—ook als je geen jurist bent (Thunderbit Blog).
Probeer Thunderbit voor compliant webscraping
Data scrapen vs. data hergebruiken: waar ligt de juridische grens?
 Data scrapen voor intern gebruik is echt iets anders dan het opnieuw publiceren, doorverkopen of anderszins hergebruiken van die data. Hier wordt de juridische lijn scherp:
Data scrapen voor intern gebruik is echt iets anders dan het opnieuw publiceren, doorverkopen of anderszins hergebruiken van die data. Hier wordt de juridische lijn scherp:
- Intern gebruik: Openbare data scrapen voor interne analyse (zoals sales leads of prijsmonitoring) is doorgaans veilig—mits je geen persoonsgegevens verzamelt of privacywetten schendt.
- Herpublicatie of verkoop: Het opnieuw publiceren van gescrapete data (op je eigen site, in een product of doorverkoop) kan leiden tot claims op basis van auteursrecht, databankrechten of contractbreuk.
- Auteursrecht & databankrechten: In de VS zijn feiten niet auteursrechtelijk beschermd, maar de selectie of ordening van data soms wel. In de EU/UK kan het scrapen van een ‘substantieel deel’ van een databank inbreuk maken op databankrechten.
- Fair use: In de VS is ‘fair use’ soms toegestaan (zoals bij commentaar of analyse), maar grote stukken tekst kopiëren valt daar zelden onder.
- Bronvermelding: Vermeld altijd je bron als je gescrapete data openbaar gebruikt—maar let op: bronvermelding maakt het niet legaal als je andere rechten schendt.
- Verkoop geen ruwe data: Het verkopen van onbewerkte gescrapete datasets is extra risicovol. Gebruik data om inzichten te genereren, niet als los product.
Tip: Gebruik gescrapete data voor interne inzichten en besluitvorming. Moet je het extern delen, aggregeer of bewerk het dan, en check altijd of je toestemming nodig hebt (Thunderbit Blog).
Praktijkvoorbeelden: zo beperk je juridische risico’s
Laten we kijken naar een paar praktijkvoorbeelden—want van andermans fouten kun je veel leren:
LinkedIn vs. hiQ Labs
- Wat gebeurde er: hiQ Labs scrapte openbare LinkedIn-profielen om analyses te maken over personeelsverloop. LinkedIn probeerde dit te blokkeren, maar de rechter oordeelde dat het scrapen van openbare data geen CFAA-overtreding was.
- Les: Openbare data scrapen is in de VS juridisch verdedigbaar, maar let op de gebruiksvoorwaarden en privacyclaims (California Lawyers Association).
eBay vs. Bidder’s Edge
- Wat gebeurde er: Bidder’s Edge scrapte eBay’s veilingaanbod extreem intensief (100.000 verzoeken per dag), in strijd met eBay’s voorwaarden en robots.txt. De rechter verbood dit wegens ‘trespass to chattels’.
- Les: Zelfs openbare data scrapen kan onrechtmatig zijn als je te agressief bent of expliciete regels overtreedt (Wikipedia).
Facebook (Meta) vs. Power Ventures
- Wat gebeurde er: Power Ventures scrapte Facebook-data met toestemming van gebruikers, maar nadat Facebook de toegang introk en IP’s blokkeerde, bleef Power Ventures doorgaan. De rechter oordeelde dat dit ‘ongeautoriseerde toegang’ was.
- Les: Als een site-eigenaar je vraagt te stoppen met scrapen, moet je dat doen—anders riskeer je schending van anti-hackwetgeving.
Succesvolle compliance-cases
Veel prijsvergelijkingssites in de EU werken legaal door alleen feitelijke data te scrapen, opt-outs te respecteren en geen volledige databases te kopiëren. Het uitblijven van rechtszaken tegen deze bedrijven laat zien dat je met openbare, niet-persoonlijke data en respect voor site-regels veilig zit.
Hoe Thunderbit helpt
Thunderbit’s ingebouwde waarschuwingen, snelheidslimieten en browser-gebaseerde aanpak hadden veel van deze juridische misstappen kunnen voorkomen—door gebruikers te waarschuwen voor risicovolle sites en standaard netjes te scrapen.
Zelfcheck voor compliance bij data scraping in zakelijke situaties
Hier is een praktische checklist voor je volgende scrapingproject:
- Is de data openbaar? (Geen login vereist)
- Wat zeggen de gebruiksvoorwaarden? (Zijn er anti-scrapingclausules?)
- Heb je robots.txt gecheckt? (Is jouw doelgebied uitgesloten?)
- Scrape je persoonsgegevens? (Zo ja, heb je een privacyplan?)
- Scrape je een groot deel van de site? (Vermijd het kopiëren van volledige databases)
- Wat is je doel? (Intern gebruik = veiliger; openbaar hergebruik = meer risico)
- Scrape je voorzichtig? (Menselijk tempo, geen technische omzeilingen)
- Is er een API? (Gebruik die als het kan)
- Ben je bereid te stoppen als daarom wordt gevraagd? (Heb je een plan voor een ‘cease-and-desist’)
- Hoe sla je de data op en beveilig je die? (Beperk toegang, bescherm privacy)
- Documenteer je proces? (Houd alles bij voor compliance)
Twijfel je bij een van deze punten, neem dan eerst de tijd om het uit te zoeken voordat je doorgaat (Thunderbit Blog).
Voorbeeldworkflow: compliant data scrapen met Thunderbit
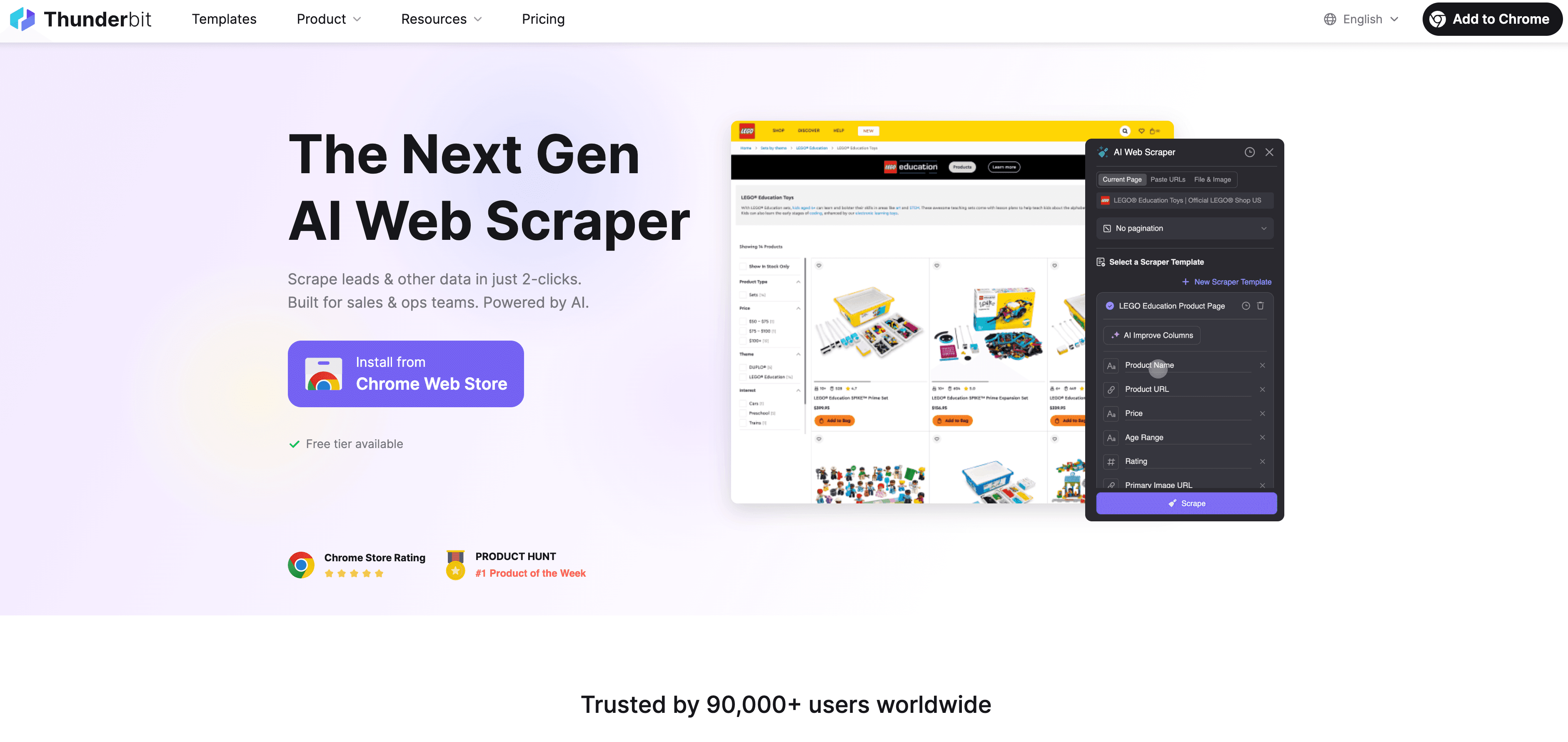 Zo ziet een typische, compliance-vriendelijke workflow met Thunderbit eruit:
Zo ziet een typische, compliance-vriendelijke workflow met Thunderbit eruit:
- Vooraf checken: Bekijk robots.txt en de gebruiksvoorwaarden van de site. Geen anti-scrapingtaal? Dan kun je door.
- Open Thunderbit: Ga naar de gewenste pagina en start de Thunderbit Chrome-extensie.
- AI-veld suggesties: Laat Thunderbit’s AI relevante, niet-gevoelige velden voorstellen. Controleer of er geen persoonsgegevens bij zitten, tenzij je een wettelijke basis hebt.
- Velden aanpassen: Pas kolommen en gegevenstypen aan—verzamel alleen wat je echt nodig hebt.
- Scrapen: Klik op “Scrapen”. Thunderbit haalt de data op menselijk tempo binnen en respecteert de sitestructuur.
- Subpagina’s scrapen: Gebruik indien nodig de subpagina-functie van Thunderbit om je data te verrijken—maar alleen met openbare info.
- Exporteren: Stuur je data direct naar Google Sheets, Excel, Airtable of Notion voor interne analyse.
- Inplannen (optioneel): Stel geplande scrapes in op redelijke intervallen—nooit te vaak.
- Documenteren: Houd bij wat je hebt gescrapet, wanneer en waarom.
Thunderbit’s interface geeft bij elke stap aan als er compliance-issues zijn—je staat er dus nooit alleen voor.
Meer weten over Thunderbit’s compliance-functies
Conclusie & belangrijkste adviezen: veilig en compliant waarde halen uit data
Webscraping is een krachtig hulpmiddel voor zakelijke groei—maar het is geen vrijbrief. De juridische context is complex, maar de kernprincipes zijn duidelijk:
- Scrape waar mogelijk alleen openbare, niet-persoonlijke data voor intern gebruik.
- Check altijd de gebruiksvoorwaarden, robots.txt en relevante wetgeving voordat je begint.
- Vermijd het scrapen van persoonsgegevens of creatieve content zonder wettelijke basis en privacyplan.
- Gebruik compliance-vriendelijke tools zoals Thunderbit om je workflow te sturen en risico’s te beperken.
- Documenteer je proces en wees bereid te stoppen als daarom wordt gevraagd.
Door compliance standaard onderdeel te maken van je aanpak, kun je de waarde van webdata benutten—zonder juridische kopzorgen. Wil je ervaren hoe eenvoudig compliant scrapen kan zijn, probeer Thunderbit dan zelf. Je juridische afdeling (en je toekomstige zelf) zullen je dankbaar zijn.
Meer weten over webscraping, compliance en automatisering? Bekijk de Thunderbit Blog.
Probeer AI-webscraper voor compliant data-extractie Get Started Free
Veelgestelde vragen
1. Mag je zomaar data van elke website scrapen?
Niet altijd. Het scrapen van openbare, niet-persoonlijke data voor intern gebruik is in veel regio’s toegestaan, maar het scrapen van persoonsgegevens, auteursrechtelijk beschermd materiaal of data achter een login kan riskant of zelfs verboden zijn. Controleer altijd de voorwaarden van de site en de lokale wetgeving voordat je begint (Thunderbit Blog).
2. Wat is het verschil tussen scrapen en hergebruiken van data?
Scrapen is het verzamelen van data; hergebruiken betekent publiceren, verkopen of op een andere manier verspreiden van die data. Intern gebruik is veel veiliger. Herpublicatie of verkoop van gescrapete data kan leiden tot claims op basis van auteursrecht, databankrechten of contractbreuk (Thunderbit Blog).
3. Hoe helpt Thunderbit bij compliance?
Thunderbit scrapt alleen wat zichtbaar is in je browser, waarschuwt bij risicovolle sites, stelt relevante (niet-gevoelige) velden voor en houdt het tempo netjes om servers niet te overbelasten. Je data wordt niet opgeslagen en de exportopties zijn bedoeld voor intern gebruik (Thunderbit Blog).
4. Wat moet ik doen als ik een 'cease-and-desist'-brief krijg?
Stop direct met scrapen en heroverweeg je project. Doorgaan na een direct verzoek om te stoppen kan een grijs juridisch gebied veranderen in een duidelijke overtreding van anti-hackwetgeving of contractvoorwaarden (Thunderbit Blog).
5. Mag ik openbare persoonsgegevens scrapen?
Niet zonder wettelijke basis. Privacywetten zoals de AVG en CCPA gelden ook voor openbare persoonsgegevens. Je hebt toestemming of een gerechtvaardigd belang nodig, en je moet zorgvuldig omgaan met de data (Thunderbit Blog).
Deze gids is uitsluitend bedoeld ter informatie en is geen juridisch advies. Voor complexe of risicovolle projecten, raadpleeg altijd een gespecialiseerde jurist op het gebied van data- en privacywetgeving in jouw regio.
Lees meer




