
Laten we eerlijk zijn: als je werkt in sales, marketing, e-commerce of operations, heb je vast wel eens gehoord van webscraping—of gebruik je het misschien al om leads te verzamelen, concurrenten in de gaten te houden of saaie data-invoer te automatiseren. Na jaren in SaaS en automatisering kan ik je vertellen: webscraping is overal. Sterker nog, bijna kwam van bots—waaronder webscrapers. Maar de grote vraag die ik altijd krijg: Is webscraping legaal?
Het eerlijke antwoord: dat hangt ervan af. (Klinkt als een jurist, toch?) Maar blijf nog even hangen, want het ligt wat genuanceerder. Of webscraping legaal is, hangt af van waar je woont, wat je precies verzamelt, hoe je dat doet en wat je met de data van plan bent. We zetten alles voor je op een rijtje, zodat je slimmer kunt scrapen—en met een gerust hart kunt slapen.
Wat is webscraping? In gewone mensentaal voor bedrijven
Webscraping is eigenlijk gewoon “automatisch data verzamelen van websites”. Stel je een super-intern voor die razendsnel duizenden webpagina’s afstruint, precies de info kopieert die je nodig hebt—contacten, prijzen, productinformatie, noem maar op—en alles netjes in een spreadsheet zet. Dat is webscraping in een notendop.
Webscrapingtools zoals (ja, een kleine shout-out, maar we hebben het speciaal voor ondernemers gebouwd) maken dit voor iedereen toegankelijk. Je hoeft niet te kunnen programmeren of te stoeien met ingewikkelde instellingen. Met Thunderbit wijs je gewoon aan wat je wilt, klikt, en de AI doet de rest. Het is alsof je een persoonlijke databutler hebt—maar dan zonder vlinderdas.
Welke data kun je allemaal scrapen?
- Contactgegevens (e-mails, telefoonnummers)
- Productinformatie en prijzen
- Reviews en beoordelingen
- Nieuwsartikelen, vacatures, vastgoeddata
- Afbeeldingen, PDF’s en meer
En ja, je kunt alles exporteren naar Excel, Google Sheets, Airtable of Notion. Wil je meer weten? Check dan onze .
Waarom bedrijven webscrapingtools inzetten
Laten we eerlijk zijn: niemand wordt blij van handmatig data invoeren. (En als jij dat wel leuk vindt, heb ik nog wat spreadsheets voor je liggen.) Maar webscraping levert meer op dan alleen tijdwinst. Zo gebruiken bedrijven webscrapingtools nu:
| Zakelijk Doel | Toepassing van Webscraping |
|---|---|
| Sales pipeline opbouwen | Verzamel leads uit bedrijvengidsen of LinkedIn—namen, e-mails, telefoonnummers—voor gerichte outreach. |
| Concurrentieprijzen monitoren | Houd prijzen en voorraad van concurrenten bij om je eigen strategie direct aan te passen. |
| Markttrends analyseren | Verzamel reviews, social posts of forumdata om trends te spotten en productbeslissingen te onderbouwen. |
| Compliance & Due Diligence | Haal openbare registers of watchlists op voor KYC, risicobeheer of regelgeving. |
| Content aggregatie | Verzamel lijsten of nieuws uit verschillende bronnen in één dashboard (denk aan vastgoed, reizen of vacatures). |
En het mooiste? Met tools als Thunderbit kunnen zelfs niet-technische teams binnen een paar minuten een scraper instellen. Je hoeft niet meer te wachten op IT of een developer om een lijstje met leads te regelen.
Is webscraping legaal? Het korte antwoord: het hangt ervan af
Eerlijk is eerlijk: Webscraping is niet per definitie illegaal, maar ook niet altijd toegestaan. Het is een hulpmiddel—zoals een hamer. Je kunt er iets moois mee bouwen, of schade aanrichten. De legaliteit hangt af van:
- Jurisdictie: Waar zitten jij en de website?
- Doel: Gebruik je het zakelijk, voor onderzoek of privé?
- Websitevoorwaarden: Wat staat er in de Terms of Service (ToS)?
- Type data: Is het openbaar, afgeschermd, auteursrechtelijk beschermd of persoonlijk?
Hier een handig overzicht:
| Scraping-situatie | Legaliteit (algemene richtlijn) |
|---|---|
| Openbare data (geen login nodig) | Meestal toegestaan in de VS—let wel op auteursrecht en privacywetgeving. |
| Data achter login of betaalmuur (zonder toestemming) | Hoog risico—vaak illegaal (kan anti-hackwetgeving schenden). |
| Websitevoorwaarden negeren die scraping verbieden | Risicovol—kan contractbreuk zijn (civiel, geen strafrecht, maar wel gedoe). |
| Auteursrechtelijk beschermde content scrapen en herpubliceren | Waarschijnlijk illegaal—tenzij je toestemming hebt of het onder fair use valt (bijv. onderzoek). |
| Persoonsgegevens scrapen voor commercieel gebruik | Sterk gereguleerd—vooral in de EU (GDPR). |
| Data gebruiken voor spam of discriminatie | Illegaal en onethisch—niet doen. |
Dus, het antwoord op “Is data scraping legaal?” is: het hangt af van de details. Laten we dieper ingaan op de belangrijkste punten.
Belangrijke juridische factoren bij webscraping
1. Openbare data versus afgeschermde data
Dit is de belangrijkste. Data die openbaar toegankelijk is—dus iedereen kan het zien zonder in te loggen of extra stappen—is meestal veilig, zeker in de VS. Zo oordeelden rechters dat het scrapen van openbare LinkedIn-profielen geen “hacken” is ().
Maar als je data achter een login, betaalmuur of technische barrière (zoals een CAPTCHA) probeert te scrapen, is dat een ander verhaal. Dat kan worden gezien als ongeoorloofde toegang—vergelijk het met backstage gaan op een concert terwijl je alleen een kaartje voor het balkon hebt.
2. Websitevoorwaarden (ToS)
Websites hebben vaak voorwaarden waarin staat dat scraping niet is toegestaan. Als je die negeert—vooral als je op “akkoord” hebt geklikt—kun je aansprakelijk zijn voor contractbreuk. Ook als je je niet hebt aangemeld, kunnen sommige rechters deze voorwaarden handhaven als ze duidelijk vermeld staan.
3. Doel en intentie (commercieel vs. persoonlijk gebruik)
Scrape je voor eigen onderzoek, of om een concurrerend bedrijf op te zetten? Commercieel scrapen wordt strenger bekeken. Niet-commercieel, academisch of journalistiek scrapen wordt vaak soepeler beoordeeld, zeker als het vernieuwend is of in het publieke belang.
4. Type data (auteursrecht, privacy, gevoeligheid)
Niet alle data is gelijk. Feiten scrapen (zoals prijzen of productnamen) is meestal prima. Auteursrechtelijk beschermde artikelen, afbeeldingen of persoonsgegevens (namen, e-mails, foto’s) kunnen onder copyright of privacywetgeving vallen—vooral in de EU.
5. Hoe je scrape (technische aanpak)
Als je rustig scrape, net als een gewone gebruiker, is de kans op problemen kleiner. Maar als je een site bestookt met duizenden verzoeken per seconde, of beveiliging omzeilt, kun je worden beschuldigd van “computervredebreuk” of het schenden van anti-omzeilingswetten.
Openbare data versus afgeschermde data: wat is het verschil?
Kort samengevat:
- Openbare data: Alles wat je kunt zien op een website zonder in te loggen, betalen of geheime trucs. Denk aan openbare vacatures, productpagina’s of overheidsdatabases.
- Afgeschermde data: Alles achter een login, betaalmuur of technische barrière. Heb je een wachtwoord nodig? Dan is het afgeschermd.
Voorbeeld:
- Openbare vastgoedadvertenties scrapen? Meestal prima.
- Ledenlijsten of besloten Facebookgroepen scrapen? Risicovol.
Rechters maken dit onderscheid duidelijk. In de hiQ v. LinkedIn-zaak werd scrapen van openbare profielen toegestaan, maar scrapen van privédata (achter login) niet ().
Websitevoorwaarden: waarom je altijd eerst moet lezen
Niemand leest graag de kleine lettertjes, maar de ToS kunnen je webscrapingproject maken of breken. Veel sites verbieden scraping of geautomatiseerde toegang expliciet. Overtreed je die regels, dan kun je te maken krijgen met:
- Geblokkeerde accounts of IP-adressen
- Sommatiebrieven
- Rechtszaken wegens contractbreuk
Tip:
- Zoek naar clausules als “no scraping” of “no automated access”.
- Biedt de site een API aan? Gebruik die—dat is meestal toegestaan.
- Twijfel je? Vraag toestemming. Soms opent een vriendelijk mailtje deuren.
Commercieel vs. persoonlijk gebruik: maakt het doel uit?
Zeker. Als je scrape voor persoonlijk onderzoek of academisch werk, heb je meestal meer speelruimte (en minder kans op juridische problemen). Rechters en toezichthouders zijn soepeler als het in het publieke belang is of niet-commercieel.
Maar scrape je voor winst—bijvoorbeeld om een concurrerend product te bouwen of data door te verkopen—dan loop je meer risico. Bedrijven zien hun data liever niet bij de concurrent terug en zullen alles inzetten (juridisch of technisch) om je te stoppen.
Kortom:
- Commercieel scrapen = meer risico
- Persoonlijk/academisch scrapen = minder risico, maar geen vrijbrief
Internationaal: hoe webscraping-wetgeving per land verschilt
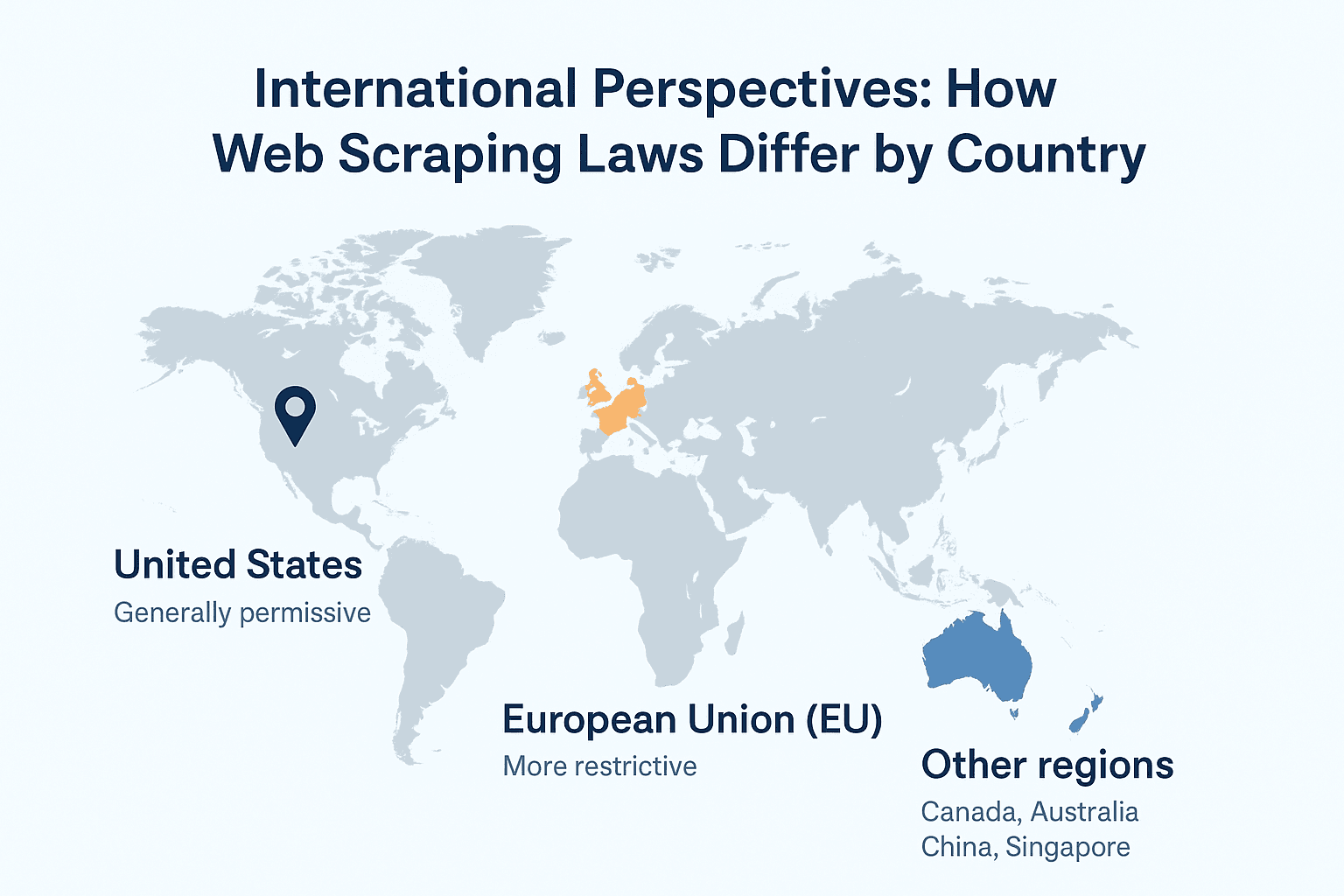
Hier wordt het interessant. De regels rond webscraping verschillen sterk per land.
Verenigde Staten
- Over het algemeen toegestaan voor openbare data.
- Anti-hackwetgeving (CFAA) geldt als je logins of technische barrières omzeilt.
- Privacywetgeving is versnipperd—let op lokale regels (zoals de biometriewet in Illinois).
Europese Unie
- Veel strenger, vooral bij persoonsgegevens.
- ziet het scrapen van persoonsgegevens (zelfs als ze openbaar zijn) als “verwerking”—je hebt een wettelijke grondslag nodig, vaak toestemming.
- Databankrechten kunnen het scrapen van grote hoeveelheden gestructureerde data beperken.
Andere regio’s
- Canada en Australië: Privacywetgeving geldt voor persoonsgegevens.
- Azië: Grote verschillen—Japan is soepeler, China erg streng, Singapore strafbaar bij grootschalig ongeoorloofd scrapen.
Scrape je data uit het buitenland? Vraag altijd lokaal juridisch advies. De boetes kunnen fors zijn—vooral in de EU.
Best practices: zo gebruik je webscrapingtools legaal en ethisch
Problemen voorkomen? Dit is mijn checklist voor verantwoord scrapen:
- Lees de ToS: Check altijd de regels van de website.
- Scrape alleen openbare data: Moet je inloggen? Denk dan goed na.
- Beperk je verzoeken: Overbelast websites niet—scrape op menselijk tempo.
- Vermijd persoonsgegevens: Zeker zonder toestemming. Moet je ze toch verzamelen? Anonimiseer en aggregeer.
- Publiceer of verkoop geen ruwe data: Voeg waarde toe, transformeer, of vraag toestemming.
- Gebruik officiële API’s als die er zijn: Daar zijn ze voor bedoeld.
- Houd logboeken bij: Documenteer je scrapingactiviteiten voor het geval er vragen komen.
- Blijf op de hoogte: Wetgeving verandert—volg nieuwe regels en uitspraken.
- Vraag juridisch advies bij grote of gevoelige projecten: Zeker bij grootschalig of gereguleerd scrapen.
En vooral: scrape met gezond verstand. Dat het kan, betekent niet dat het altijd moet.
Thunderbit en legaal webscrapen: zo helpt onze tool bij compliance

Bij hebben we onze ontwikkeld met oog voor wet- en regelgeving. Zo helpen we je compliant te blijven:
- Focus op openbare data: Thunderbit is ontworpen om alleen te scrapen wat je in je browser ziet—geen hacks, geen logins omzeilen.
- Gebruikersadvies: We herinneren je eraan om de ToS te checken en geen afgeschermde of persoonlijke data te scrapen. Probeer je een site met strenge regels te scrapen, dan krijg je een waarschuwing.
- Menselijk tempo: Omdat Thunderbit in je browser draait, scrape je op een natuurlijk tempo—minder kans op blokkades of serverproblemen.
- Instellingen op maat: Jij bepaalt welke data je verzamelt, hoe vaak en waar je het naartoe exporteert. Dat ondersteunt dataminimalisatie en transparantie.
- Privacy en veiligheid: Je gescrapete data blijft bij jou. Wij slaan niets op of hergebruiken het—het is en blijft jouw data.
- Compliance-functies: Onze sjablonen voor populaire sites zijn afgestemd op de regels en best practices van die sites.
- Educatieve content: We publiceren regelmatig over legaal en ethisch scrapen, zodat je altijd op de hoogte bent.
We zijn geen juristen, maar we doen ons best om je goed te informeren. Twijfel je? Vraag altijd professioneel juridisch advies—zeker bij grote of gevoelige projecten.
Conclusie: belangrijkste punten voor bedrijven
Samengevat:
- Webscraping is niet per definitie illegaal—maar ook niet altijd toegestaan. Het hangt af van waar je bent, wat je scrapt, hoe en waarom.
- Openbare data scrapen mag meestal, zeker in de VS, maar respecteer auteursrecht, privacy en websitevoorwaarden.
- Commercieel scrapen brengt meer risico met zich mee dan persoonlijk of academisch gebruik.
- Internationale regels verschillen— vooral de EU is streng met persoonsgegevens.
- Best practices zijn belangrijk: Lees de ToS, scrape alleen openbare data, beperk je verzoeken en vermijd gevoelige data.
- Thunderbit is gebouwd voor verantwoord scrapen, met functies en advies om je compliant te houden.
Kortom: scrape bewust, ethisch en vraag advies als je twijfelt. Goed uitgevoerd is webscraping een krachtig hulpmiddel voor je bedrijf—zonder juridische kopzorgen.
Meer weten over webscraping, compliance en automatisering? Bekijk onze of probeer zelf. Klaar om te starten? Download onze en ontdek hoe eenvoudig dataverzameling kan zijn—zonder juridische stress.
FAQ: Webscraping & Legaliteit
-
Is het legaal om openbare websites te scrapen?
Soms. Openbaar betekent niet altijd vrij te gebruiken. In de VS mag je meestal openbare data scrapen, maar check altijd de Terms of Service, vermijd persoonsgegevens en herpubliceer geen auteursrechtelijk beschermde content.
-
Wat is het grootste juridische risico?
Het scrapen van afgeschermde data, het negeren van ToS, of het zakelijk gebruiken van persoonsgegevens zonder toestemming—vooral in de EU onder de GDPR.
-
Mag ik LinkedIn of Amazon scrapen?
Misschien. LinkedIn-scraping werd door de rechter toegestaan (hiQ-zaak), maar LinkedIn blokkeert het nog steeds. Amazon staat sommige data toe, maar beperkt bots. Check altijd de ToS.
-
Hoe helpt Thunderbit bij compliance?
Thunderbit:
- Scrapet alleen zichtbare, openbare data
- Draait in de browser (geen server-side bots)
- Waarschuwt bij ToS-issues
- Houdt jouw data privé