
Webcrawlers zijn de onbezongen helden van het internet. Elke keer dat je een nieuw recept zoekt, de laatste prijzen van je favoriete sneakers checkt of hotels vergelijkt voor je volgende vakantie, is de kans groot dat een webcrawler daar al is langsgeweest om stilletjes informatie te verzamelen en te ordenen. Sterker nog: naar schatting wordt ongeveer de helft van al het internetverkeer inmiddels gegenereerd door bots en crawlers, niet door mensen — recente brancheonderzoeken schatten het aandeel van bots op 49–51%. Dat klopt: terwijl jij slaapt, brengen deze digitale verkenners het web onvermoeibaar in kaart, zodat alle informatie ter wereld maar één klik verwijderd is.
Maar wat zijn webcrawlers nu precies? Waarom zijn ze zo belangrijk voor bedrijven, onderzoekers en iedereen die afhankelijk is van actuele data? En hoe hebben moderne tools zoals Thunderbit webcrawling toegankelijk gemaakt voor iedereen, niet alleen voor programmeurs of techreuzen? Als iemand die jarenlang aan automatiserings- en AI-tools heeft gebouwd, heb ik van dichtbij gezien hoe webcrawlers zijn geëvolueerd van mysterieuze “spiders” tot onmisbare hulpmiddelen voor het dagelijks bedrijfsleven. Laten we erin duiken en de wereld van webcrawlers ontrafelen: wat ze zijn, hoe ze werken en waarom ze in 2026 de ruggengraat vormen van slimmere datatoegang.
Webcrawlers zijn de dataverkenners van het internet
Haal gegevens van elke website met AI Get Started Free
Dus, wat zijn webcrawlers eigenlijk? In de kern zijn webcrawlers (ook wel spiders of bots genoemd) geautomatiseerde programma’s die systematisch door het internet gaan, de ene webpagina na de andere bezoeken en ondertussen informatie verzamelen. Zie ze als ’s werelds meest onvermoeibare onderzoeksstagiairs — alleen slapen ze nooit, klagen ze nooit en kunnen ze in één dag miljoenen pagina’s bezoeken.
Een webcrawler begint met een lijst webadressen (ook wel “seeds” genoemd), bezoekt elk adres en volgt daarna de links die hij tegenkomt om nieuwe pagina’s te ontdekken. Terwijl hij rondkruipt, kopieert hij content, indexeert hij data en bouwt hij een kaart van het voortdurend veranderende weblandschap (Cloudflare). Zo weten zoekmachines zoals Google wat er online staat, en zo houden prijsvergelijkingssites en marktonderzoekstools hun data actueel.
Simpel gezegd: webcrawlers zijn de verkenners die het internet doorzoekbaar, vergelijkbaar en bruikbaar maken.
De vele gezichten van webcrawlers: typen en kernfuncties
 Niet elke webcrawler draagt dezelfde pet. Afhankelijk van hun missie bestaan crawlers in verschillende varianten, elk met een eigen specialiteit. Hier is een snelle rondleiding langs de belangrijkste typen die je tegenkomt:
Niet elke webcrawler draagt dezelfde pet. Afhankelijk van hun missie bestaan crawlers in verschillende varianten, elk met een eigen specialiteit. Hier is een snelle rondleiding langs de belangrijkste typen die je tegenkomt:
| Type | Kernfunctie | Typische toepassing |
|---|---|---|
| Zoekmachinecrawlers | Het web indexeren voor zoekresultaten | Googlebot, Bingbot die nieuwe websites indexeren |
| Dataminingcrawlers | Grote datasets verzamelen voor analyse | Marktonderzoek, academische studies |
| Prijsmonitoringcrawlers | Productprijzen en beschikbaarheid volgen | Prijsvergelijking in e-commerce, dynamische prijsstelling |
| Contentaggregatiecrawlers | Artikelen, nieuws of berichten verzamelen voor aggregatie | Nieuwsportalen, contentcuratie |
| Leadgeneratiecrawlers | Contactgegevens en bedrijfsdata extraheren | Sales prospecting, B2B-gidsen |
Laten we een paar hiervan wat verder uitdiepen:
Zoekmachinecrawlers
Als je een vraag in Google typt, vertrouw je op het werk van zoekmachinecrawlers. Deze bots zwerven 24/7 over het web, ontdekken nieuwe pagina’s, werken oude bij en indexeren content zodat die in zoekresultaten kan worden gevonden. Zonder crawlers zouden zoekmachines blind vliegen — geen idee hebben wat nieuw is, wat veranderd is of wat er überhaupt bestaat (TechTarget).
Datamining- en marktonderzoekcrawlers
Bedrijven en onderzoekers gebruiken crawlers om enorme hoeveelheden data te verzamelen voor analyse. Wil je weten hoe vaak een concurrent online wordt genoemd? Of het sentiment rond een nieuwe productlancering volgen? Dataminingcrawlers kunnen forums, reviews, social media en meer scannen en zo de chaotische webomgeving omzetten in gestructureerde inzichten (DataHut).
Prijsmonitoring- en producttrackingcrawlers
In de razendsnelle wereld van e-commerce veranderen prijzen en productdetails voortdurend. Prijsmonitoringcrawlers houden concurrenten in de gaten en waarschuwen bedrijven voor prijsdalingen, voorraadwijzigingen of nieuwe productlanceringen. Dat maakt dynamische prijsstrategieën mogelijk en helpt bedrijven concurrerend te blijven (AIMultiple).
Waarom webcrawlers essentieel zijn voor moderne datatoegang
Laten we eerlijk zijn: het internet is simpelweg te groot om handmatig bij te houden. Er zijn inmiddels meer dan 1,4 miljard websites (en dat aantal groeit nog steeds), met elke dag ongeveer een miljoen nieuwe erbij. Webcrawlers maken het mogelijk om:
- Dataverzameling op te schalen: in uren miljoenen pagina’s bezoeken, niet in maanden.
- Actueel te blijven: voortdurend wijzigingen, nieuwe content of breaking news monitoren.
- Dynamische, realtime informatie te benaderen: reageren op marktverschuivingen, prijswijzigingen of trending topics zodra ze gebeuren.
- Datagedreven beslissingen mogelijk te maken: alles aandrijven, van zoekmachines tot marktonderzoek, risicobeheer en financiële modellering (DEV Community).
In een wereld waarin data de ruggengraat vormt van digitale bedrijfsstrategie, zijn webcrawlers de motoren die de datastroom op gang houden.
Veelvoorkomende toepassingen van webcrawlers in verschillende sectoren
Webcrawlers zijn niet alleen iets voor techreuzen of zoekmachines. Zo zetten verschillende sectoren ze in:
| Sector | Toepassing | Voordeel |
|---|---|---|
| Sales | Leadgeneratie | Gerichte prospectlijsten samenstellen uit gidsen |
| E-commerce | Prijsmonitoring | Concurrentieprijzen, voorraad en productwijzigingen volgen |
| Marketing | Contentaggregatie | Nieuws, artikelen en social media-vermeldingen cureren |
| Vastgoed | Aggregatie van vastgoedaanbod | Aanbod uit meerdere bronnen combineren |
| Reizen | Tarief- en hotelvergelijking | Prijzen, beschikbaarheid en beleid monitoren |
| Finance | Risicomonitoring | Nieuws, filings en sentiment rond investeringen volgen |
Praktijkvoorbeeld:
Een makelaarskantoor gebruikt crawlers om vastgoedgegevens, foto’s en voorzieningen van meerdere woningsites binnen te halen, zodat klanten een uniforme, actuele marktweergave krijgen (DataHut).
Een e-commerce team zet crawlers in om SKU’s en prijzen van concurrenten te volgen en past de eigen strategie in realtime aan (AIMultiple).
Hoe webcrawlers werken: een stapsgewijs overzicht
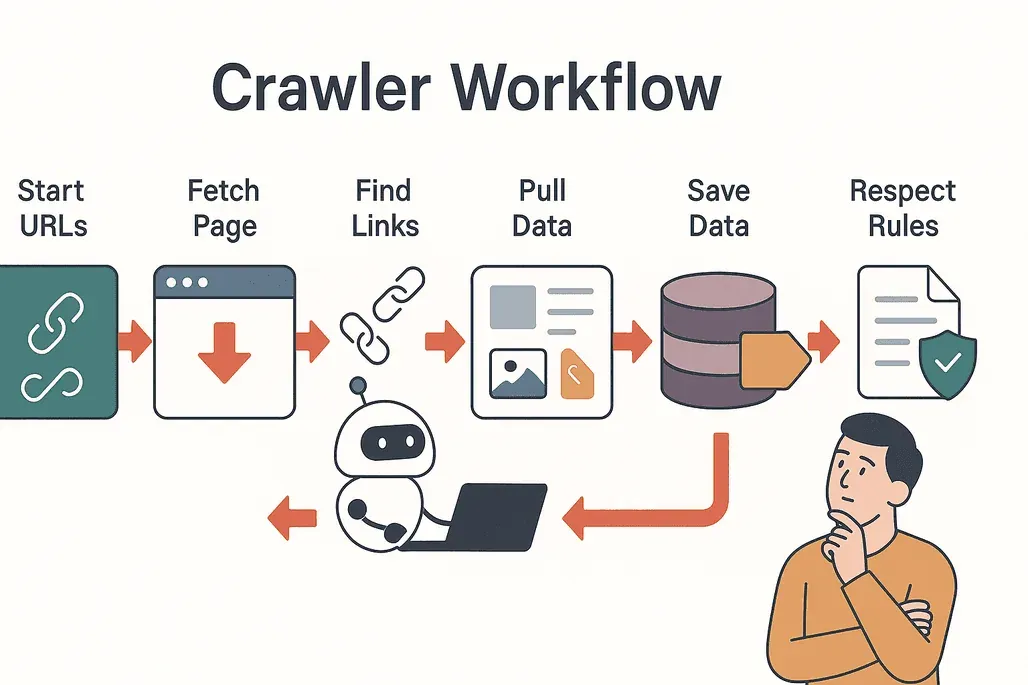 Laten we het proces ontleden. Zo werkt een typische webcrawler:
Laten we het proces ontleden. Zo werkt een typische webcrawler:
- Begin met seeds: de crawler start met een lijst start-URL’s.
- Bezoeken en ophalen: hij bezoekt elke pagina en downloadt de content.
- Links extraheren: de crawler vindt alle links op de pagina.
- Links volgen: nieuwe, nog niet bezochte links worden toegevoegd aan de wachtrij.
- Data extraheren: relevante informatie (tekst, afbeeldingen, prijzen, enz.) wordt gekopieerd en gestructureerd.
- Resultaten opslaan: de data wordt opgeslagen in een database of geëxporteerd voor analyse.
- Regels respecteren: de crawler controleert het
robots.txt-bestand van elke site om te zien wat is toegestaan en vermijdt afgeschermde delen (Cloudflare).
Best practices:
- Crawl netjes (overbelast servers niet).
- Respecteer privacy en wettelijke grenzen.
- Vermijd dubbele content en onnodige verzoeken.
Uitdagingen en aandachtspunten bij het gebruik van webcrawlers
Webcrawling is niet altijd een soepele rit. Dit zijn veelvoorkomende obstakels:
- Serverbelasting: te veel verzoeken kunnen een website vertragen of laten crashen.
- Dubbele content: crawlers kunnen dezelfde pagina’s opnieuw bezoeken of in lussen terechtkomen.
- Privacy en legaliteit: niet alle data mag zomaar worden gebruikt — controleer altijd de servicevoorwaarden en privacywetgeving.
- Technische barrières: sommige sites gebruiken CAPTCHA’s, dynamische content of anti-botmaatregelen om crawlers te blokkeren (DEV Community).
Tips voor succes:
- Gebruik respectvolle crawl-snelheden.
- Monitor wijzigingen in de websitestructuur.
- Blijf op de hoogte van regelgeving rond gegevensprivacy.
Thunderbit: webcrawlers toegankelijk maken voor iedereen
Hier wordt het interessant. Traditioneel betekende het opzetten van een webcrawler: code schrijven, instellingen configureren en urenlang troubleshooten. Maar met Thunderbit hebben we het omgedraaid.
Thunderbit is een AI-aangedreven webscraper Chrome-extensie, ontworpen voor zakelijke gebruikers — zonder code. Dit maakt het bijzonder:
- Instructies in natuurlijke taal: beschrijf gewoon welke data je wilt (“Haal alle productnamen en prijzen van deze pagina”), en de AI van Thunderbit regelt de rest.
- AI-gestuurde veldsuggesties: klik op “AI Suggest Fields” en Thunderbit leest de pagina en stelt de beste kolommen voor om te extraheren.
- Subpagina’s scrapen: meer details nodig? Thunderbit kan elke subpagina bezoeken (zoals productdetails of LinkedIn-profielen) en je dataset automatisch verrijken.
- Directe sjablonen: voor populaire sites (Amazon, Zillow, Shopify, enz.) gebruik je kant-en-klare sjablonen voor data-extractie met één klik.
- Makkelijk exporteren: stuur je data direct naar Excel, Google Sheets, Airtable of Notion — zonder extra stappen.
- Gratis data-export: download je resultaten als CSV of JSON, helemaal gratis.
Thunderbit wordt vertrouwd door meer dan 100.000 gebruikers wereldwijd, van salesteams tot e-commercebedrijven en vastgoedprofessionals.
Probeer Thunderbit AI Web Scraper gratis
Thunderbit versus traditionele webcrawlers
Laten we zien hoe Thunderbit zich verhoudt tot de ouderwetse aanpak:
| Functie | Thunderbit | Traditionele crawlers |
|---|---|---|
| Insteltijd | 2 klikken (AI regelt de setup) | Uren/dagen (handmatige configuratie, code) |
| Benodigde technische kennis | Geen (instructies in gewoon Nederlands) | Hoog (coderen, selectors, scripting) |
| Flexibiliteit | Werkt op elke site en past zich aan wijzigingen aan | Breekt bij lay-outwijzigingen |
| Subpagina’s scrapen | Ingebouwd, geen extra setup | Handmatig scripten vereist |
| Exportopties | Excel, Sheets, Airtable, Notion, CSV, JSON | Meestal alleen CSV/JSON |
| Onderhoud | AI past zich automatisch aan | Regelmatige handmatige fixes |
Met Thunderbit hoef je geen ontwikkelaar te zijn of uren te besteden aan het finetunen van instellingen. Gewoon aanwijzen, klikken en de AI het zware werk laten doen (Thunderbit Blog).
Aan de slag met webcrawlers via Thunderbit
Klaar om het te proberen? Zo begin je binnen een paar minuten met Thunderbit:
- Installeer de Thunderbit Chrome-extensie.
- Open de website die je wilt crawlen.
- Klik op het Thunderbit-pictogram en kies “AI Suggest Fields.” De AI stelt kolommen voor op basis van de inhoud van de pagina.
- Pas velden aan indien nodig en klik dan op “Scrape.” Thunderbit extraheert de data, inclusief van subpagina’s als je dat wilt.
- Exporteer je resultaten naar Excel, Google Sheets, Airtable, Notion of download ze als CSV/JSON.
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Dat is alles — geen scripts, geen code, geen hoofdpijn. Of je nu prijzen volgt, een leadlijst opbouwt of nieuws aggregeert, Thunderbit maakt van de meeste alledaagse webcrawltaken iets dat een niet-ontwikkelaar in één middag kan afronden.
Conclusie: webcrawlers zijn de sleutel tot slimmere datatoegang
Webcrawlers zijn de onzichtbare motoren achter onze digitale wereld: ze maken informatie toegankelijk, doorzoekbaar en bruikbaar voor iedereen. Van zoekmachines tot salesteams, van e-commerce tot vastgoed — crawlers zijn onmisbare tools geworden voor iedereen die betrouwbare, actuele data nodig heeft.
En dankzij moderne AI-tools zoals Thunderbit hoef je geen programmeur te zijn om hun kracht te benutten. Met slechts een paar klikken kan iedereen het web omzetten in een gestructureerde, bruikbare bron — en zo slimmere beslissingen en nieuwe kansen aanjagen.
Benieuwd wat webcrawlers voor jouw bedrijf kunnen doen? Download Thunderbit en begin vandaag nog met het verkennen van de verborgen data van het web. Voor meer tips en verdiepende artikelen kun je terecht op de Thunderbit Blog.
Probeer AI Web Scraper Get Started Free
Veelgestelde vragen
1. Wat is een webcrawler precies?
Een webcrawler is een geautomatiseerd programma (ook wel een spider of bot genoemd) dat systematisch door het internet navigeert, webpagina’s bezoekt, links volgt en informatie verzamelt voor indexering of analyse.
2. Hoe verschillen webcrawlers van webscrapers?
Webcrawlers zijn ontworpen om grote delen van het web te ontdekken en in kaart te brengen, vaak door links van pagina naar pagina te volgen. Webscrapers daarentegen richten zich op het extraheren van specifieke data uit gerichte pagina’s. Veel moderne tools (zoals Thunderbit) combineren beide functies.
3. Waarom zijn webcrawlers belangrijk voor bedrijven?
Webcrawlers geven bedrijven toegang tot actuele informatie op schaal — of het nu gaat om het monitoren van concurrentieprijzen, het aggregeren van content of het opbouwen van leadlijsten. Ze ondersteunen realtime besluitvorming en helpen bedrijven concurrerend te blijven.
4. Is het legaal om webcrawlers te gebruiken?
Webcrawling is over het algemeen legaal wanneer het verantwoord gebeurt en in overeenstemming is met de servicevoorwaarden en privacyregels van een website. Controleer altijd het robots.txt-bestand van een site en respecteer de regels rond gegevensprivacy.
5. Hoe maakt Thunderbit webcrawling eenvoudiger?
Thunderbit gebruikt AI om de setup, veldselectie en data-extractie te automatiseren. Met instructies in natuurlijke taal en directe sjablonen kan iedereen websites crawlen en data extraheren — zonder code of technische vaardigheden. Data kan direct worden geëxporteerd naar Excel, Google Sheets, Airtable of Notion voor onmiddellijk gebruik.
Meer weten




