
Het internet zit bomvol data—zoveel zelfs dat het de drijvende kracht is achter moderne bedrijven. Of je nu in sales, e-commerce, vastgoed werkt of gewoon je concurrenten in de gaten wilt houden, het verschil maak je door de juiste info snel te vinden. Maar laten we eerlijk zijn: niemand heeft zin om urenlang te copy-pasten van websites naar spreadsheets. Hier komt webscraping om de hoek kijken, en geloof me: het is veel makkelijker dan je denkt.
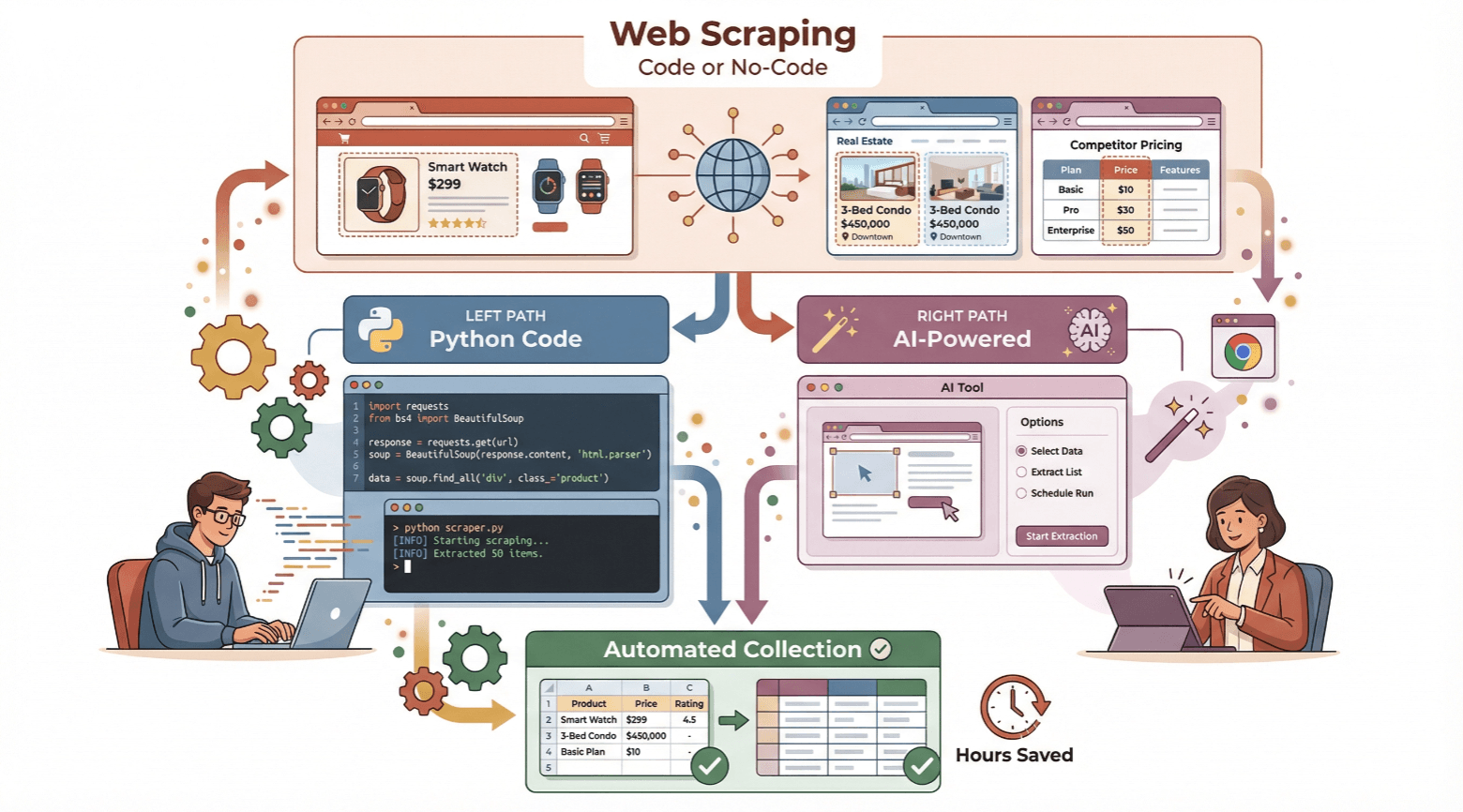
In deze gids neem ik je stap voor stap mee in hoe je een webscraper maakt—of je nu wilt leren coderen met Python, of liever zonder code aan de slag gaat met een AI-tool als . Ik leg de basis uit, laat beide methodes zien en help je kiezen wat het beste bij jou past. Klaar om tijd te besparen en de kracht van geautomatiseerde dataverzameling te ontdekken? Laten we beginnen.
Wat is een webscraper? De basis uitgelegd
Een webscraper is gewoon een tool—software of dienst—die automatisch info van websites haalt. Stel je voor dat je een lijst wilt van alle koffietentjes in jouw stad, inclusief adressen en telefoonnummers. Je kunt urenlang pagina’s doorspitten en alles handmatig kopiëren (hallo, muisarm), of je laat een webscraper het zware werk doen.
Zie een webscraper als een digitale assistent die webpagina’s leest, precies de data vindt die jij zoekt (zoals prijzen, productnamen of contactgegevens) en alles netjes in een spreadsheet of database zet. In plaats van eindeloos schakelen tussen browser en Excel, automatiseert de scraper het hele proces—van ophalen tot structureren en opslaan van de data.
Zo werkt het onder de motorkap:
- Request: De scraper stuurt een verzoek naar een webpagina en haalt de ruwe HTML op.
- Parse: Daarna analyseert hij de HTML om de juiste data te vinden (bijvoorbeeld de prijs in een
<span>-tag). - Extract: De data wordt eruit gehaald en opgeslagen in een gestructureerd formaat (CSV, Excel, Google Sheets, enz.).
Handmatig kopiëren is als graven met een theelepel. Webscraping is een graafmachine inzetten.
Waarom een webscraper maken belangrijk is voor bedrijven
Webscraping is allang niet meer alleen voor techneuten of data scientists—het is onmisbaar geworden voor iedereen die betrouwbare, actuele info nodig heeft. Maar liefst investeert inmiddels in datagedreven beslissingen, en de wereldwijde webscraping-markt zal naar verwachting verdubbelen tegen 2030.
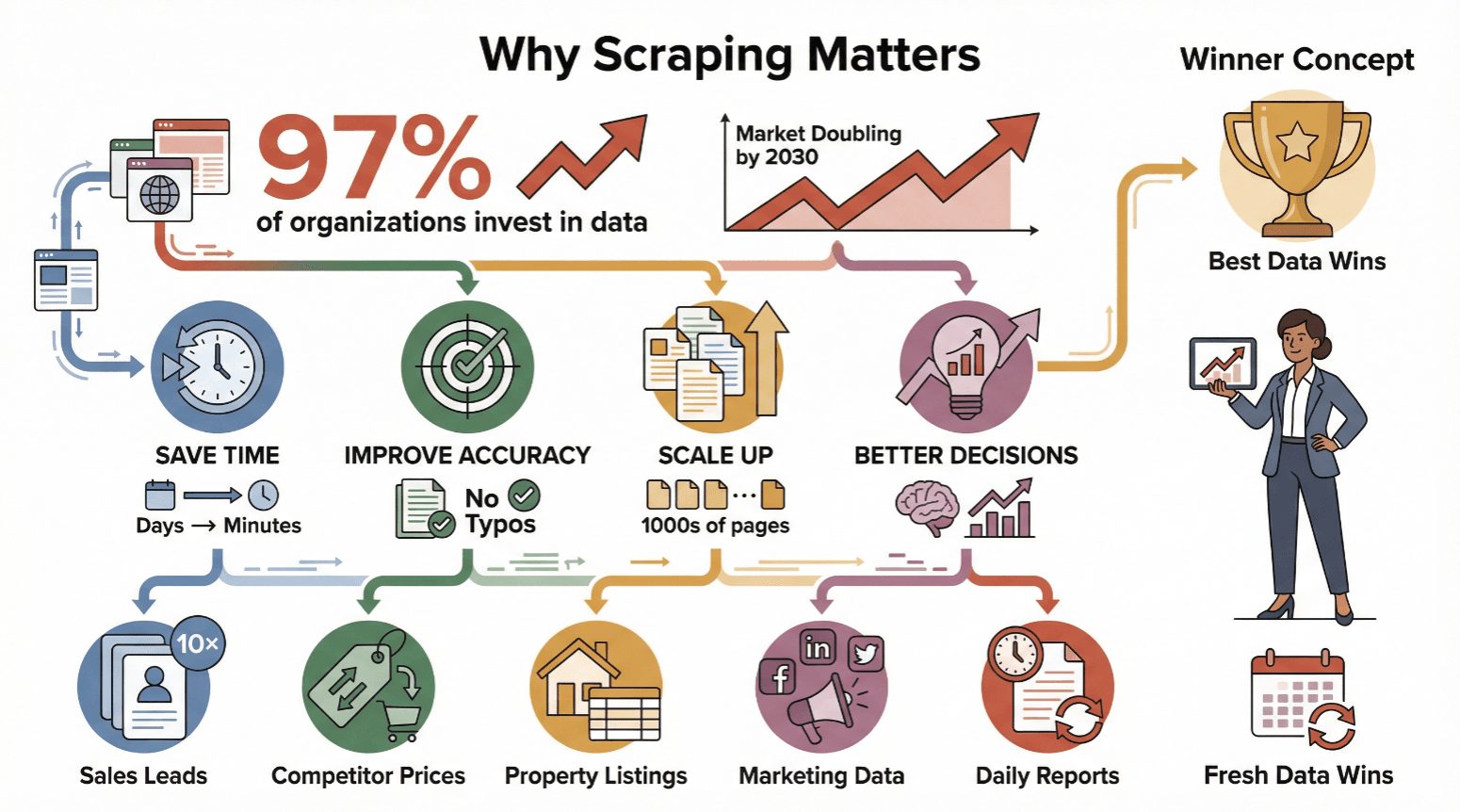
Waarom kiezen bedrijven van elke omvang voor webscraping?
- Tijdbesparing: Automatisch scrapen maakt van dagen werk een kwestie van minuten.
- Betere nauwkeurigheid: Software wordt niet moe en maakt geen typefouten.
- Schaalbaarheid: Haal moeiteloos data van duizenden pagina’s.
- Slimmere beslissingen: Actuele data betekent betere keuzes—of je nu prijzen aanpast, leads zoekt of trends volgt.
Enkele praktijkvoorbeelden:
| Toepassing | Voor wie | Resultaat |
|---|---|---|
| Leads verzamelen uit bedrijvengidsen | Sales teams | 10× meer leads, uren bespaard op prospectie |
| Prijzen van concurrenten monitoren op webshops | E-commerce managers | Direct prijs aanpassen, marges beschermen |
| Woningen verzamelen van vastgoedwebsites | Makelaars | Sneller deals vinden, altijd actuele marktdata |
| Marketingdata verzamelen van web/social media | Marketingteams | Gerichtere campagnes, betere prestatie-inzichten |
| Dagelijkse webdata-rapporten automatiseren | Operations, analisten | Lagere loonkosten, minder fouten, consistente en tijdige rapportages |
Kortom: wie de beste en meest actuele data heeft, loopt voorop.
Voor beginners: Zelf een eenvoudige webscraper maken met Python
Benieuwd hoe webscraping technisch werkt? Python is een ideale start. Zelfs als je nog nooit hebt geprogrammeerd, kun je in een paar stappen een basis-webscraper bouwen. Zo pak je het aan:
Je omgeving instellen
Installeer eerst Python op je computer. Download de nieuwste versie via en volg de instructies voor jouw besturingssysteem (Windows of Mac). Vink tijdens de installatie “Add Python to PATH” aan.
Open daarna je terminal of opdrachtprompt en installeer de benodigde libraries:
1pip install requests
2pip install bs4
3pip install pandasrequestshaalt webpagina’s op.bs4(Beautiful Soup) helpt je HTML te analyseren.pandasis handig om data op te slaan in CSV of Excel.
De website inspecteren
Voordat je code schrijft, moet je weten waar de data in de HTML staat. Open de website in Chrome, klik met rechts op de gewenste data (bijvoorbeeld een functietitel) en kies “Inspecteren.” Je ziet nu het HTML-element, bijvoorbeeld een <a>-tag met de class jobtitle. Noteer deze tags en klassen; die heb je straks nodig.
De scraper schrijven en uitvoeren
Stel, je wilt functietitels en bedrijfsnamen van een vacaturepagina halen. Zo ziet een simpel script eruit:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4URL = "https://example.com/jobs" # Vervang door jouw doel-URL
5response = requests.get(URL)
6soup = BeautifulSoup(response.text, 'html.parser')
7# Zoek alle functietitels en bedrijfsnamen (pas selectors aan indien nodig)
8titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
9companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
10# Opslaan als CSV
11df = pd.DataFrame({'Functietitel': titles, 'Bedrijf': companies})
12df.to_csv('jobs.csv', index=False)
13print("Scrapen voltooid! Data opgeslagen in jobs.csv")- Pas de URL en class-namen aan voor jouw website.
- Voer het script uit in je terminal:
python jouwscript.py - Open
jobs.csvom het resultaat te bekijken.
Tip: Voor complexere sites (met paginering of dynamische content) heb je mogelijk extra code of tools als Selenium nodig. Maar voor veel statische pagina’s werkt deze aanpak prima.
No-code gemak: Webscraper maken met Thunderbit
Wil je liever helemaal niet coderen? Dan is ideaal—een no-code, AI-webscraper speciaal voor zakelijke gebruikers. Met Thunderbit ga je van “ik heb deze data nodig” naar “hier is mijn spreadsheet” in slechts twee klikken.
Zo werkt het:
Stap 1: Installeer de Thunderbit Chrome-extensie
Ga naar de en voeg deze toe aan je browser. Maak een gratis account aan (met het gratis pakket kun je een paar pagina’s proberen).
Stap 2: Navigeer naar de gewenste website
Open de pagina die je wilt scrapen in Chrome. Log in indien nodig en scroll naar beneden om alle content te laden.
Stap 3: Geef aan welke data je zoekt
Klik op het Thunderbit-icoon om de zijbalk te openen. Je kunt nu:
- Op “AI Velden voorstellen” klikken, waarna Thunderbit’s AI de pagina scant en kolommen voorstelt (zoals “Productnaam”, “Prijs”, “Afbeelding”).
- Of een simpele prompt typen (bijvoorbeeld: “Haal alle boektitels en auteurs van deze pagina”).
Thunderbit’s AI stelt automatisch velden en gegevenstypen voor. Je kunt deze aanpassen, toevoegen of verwijderen.
Stap 4: Start je eerste scrape
Staan je velden goed? Klik dan op “Scrapen”. Thunderbit haalt de data op, regelt paginering indien nodig en toont alles overzichtelijk in een tabel. Wil je meer details van subpagina’s (zoals productpagina’s)? Klik op “Subpagina’s scrapen”—Thunderbit volgt dan elke link en haalt extra info op.
Stap 5: Controleer en exporteer je resultaten
Bekijk je data in de Thunderbit-tabel. Tevreden? Klik op “Exporteren” en kies je formaat: Excel, CSV, Google Sheets, Airtable, Notion of JSON. Exporteren is gratis en onbeperkt.
Dat is alles. Geen code, geen sjablonen, geen gedoe.
Traditionele vs. no-code webscraper: de vergelijking
Hoe verhouden beide methodes zich tot elkaar?
| Oplossing | Installatietijd | Vereiste kennis | Onderhoud | Flexibiliteit | Exportmogelijkheden |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Uren/dagen | Programmeren, HTML basis | Hoog (breekt snel) | Zeer hoog | CSV, Excel, JSON (via code) |
| Oudere no-code tools | 30-60 min | Enige technische kennis | Gemiddeld (handmatig) | Goed voor statische sites | CSV, Excel |
| Thunderbit (AI No-Code) | Minuten | Geen (gewoon Nederlands) | Laag (AI past zich aan) | Hoog (ook dynamische sites) | Excel, CSV, Sheets, Notion... |
Dankzij de AI van Thunderbit ben je minder tijd kwijt aan instellen en repareren, en kun je sneller met je data aan de slag.
Traditionele webscraper-problemen opgelost
Klassieke webscrapers hebben zo hun bekende valkuilen:
- Websitewijzigingen: Als een site zijn layout aanpast, werkt je code vaak niet meer. Thunderbit’s AI past zich automatisch aan, zodat je niet hoeft te herschrijven.
- Anti-botmaatregelen: Veel sites blokkeren scripts. Thunderbit werkt in je browser (met je eigen login/sessie) of in de cloud voor snelheid.
- Dynamische content: Pagina’s met oneindig scrollen of “Load More”-knoppen zijn lastig voor simpele scrapers. Thunderbit’s AI regelt automatisch scrollen en interactieve elementen.
- Data achter login: Met Thunderbit’s browsermodus kun je alles scrapen wat je in Chrome ziet.
Kortom, Thunderbit is gemaakt om de rommelige realiteit van moderne websites aan te kunnen—zodat jij dat niet hoeft te doen.
Efficiëntie verhogen: Thunderbit’s geavanceerde webscraping-functies
Thunderbit draait niet alleen om data verzamelen—maar om het snel, schoon en direct bruikbaar te maken. Enkele favoriete functies:
Automatische paginering en subpagina’s scrapen
Wil je honderden producten van meerdere pagina’s halen? Thunderbit herkent paginering (volgende knoppen, oneindig scrollen) en verzamelt alles in één keer. Meer details van subpagina’s? Klik op “Subpagina’s scrapen” en Thunderbit volgt elke link voor extra velden (zoals verkoperinformatie of productspecificaties).
AI-veldvoorstellen en datastructurering
Thunderbit’s AI raadt niet zomaar kolommen aan—het begrijpt de context. Het kan kolommen labelen, gegevenstypen toewijzen (tekst, getal, afbeelding, e-mail) en zelfs aangepaste instructies toepassen (zoals “alleen prijzen boven €100” of “vertaal beschrijvingen naar het Engels”). Je kunt prompts toevoegen om data te categoriseren, samenvatten of herformatteren tijdens het scrapen.
Sjablonen en direct scrapen
Voor populaire sites (Amazon, Zillow, Google Maps, Instagram) biedt Thunderbit kant-en-klare sjablonen—selecteer je site en alle velden staan direct goed. Geen instelwerk nodig.
Plannen en automatiseren
Dagelijks verse data nodig? Stel een schema in (“elke maandag om 9:00”) en Thunderbit scrapt automatisch, zodat je Google Sheet of database altijd up-to-date is.
Cloud- of lokaal scrapen
Kies of je scrapes in je browser draait (ideaal voor ingelogde of interactieve sites) of in de cloud (sneller voor openbare data—tot 50 pagina’s tegelijk).
Dankzij deze geavanceerde functies is Thunderbit een topkeuze voor bedrijven die betrouwbare, schaalbare en gebruiksvriendelijke webscraping zoeken.
Stappenplan: Zo maak je een webscraper met Thunderbit
Hier is je snelle checklist:
- Installeer Thunderbit: en maak een account aan.
- Open de gewenste website: Log in indien nodig, scroll om alles te laden.
- Open de Thunderbit-zijbalk: Klik op het extensie-icoon.
- Omschrijf je data: Klik op “AI Velden voorstellen” of typ je prompt.
- Controleer velden: Hernoem, voeg toe of verwijder kolommen.
- Klik op “Scrapen”: Laat Thunderbit het werk doen.
- (Optioneel) Subpagina’s scrapen: Voor diepere data, klik op “Subpagina’s scrapen.”
- Controleer resultaten: Bekijk de tabel op juistheid.
- Exporteer data: Kies Excel, CSV, Google Sheets, Notion, Airtable of JSON.
- Opslaan/sjabloon/plannen: Sla je setup op of plan terugkerende scrapes.
Tips bij problemen:
- Ontbreekt er data? Probeer je prompt anders te formuleren of gebruik aangepaste instructies.
- Voor dynamische content: zorg dat je in browsermodus werkt.
- Kom je aan je gratis limiet? Overweeg een upgrade voor meer pagina’s.
Samenvatting & belangrijkste punten
Een webscraper maken is allang niet meer alleen voor programmeurs. Of je nu zelf Python wilt leren of liever alles aan AI overlaat, de tools zijn toegankelijker dan ooit.
Onthoud vooral:
- Webscraping bespaart tijd, verhoogt nauwkeurigheid en maakt datagedreven werken mogelijk.
- Python is ideaal om te leren en voor maatwerk, maar vereist code en onderhoud.
- Thunderbit biedt een snelle, no-code oplossing—beschrijf wat je wilt en klik op “Scrapen.”
- Geavanceerde functies als automatische paginering, subpagina’s scrapen en AI-veldvoorstellen maken Thunderbit krachtig voor bedrijven.
- Je kunt Thunderbit gratis proberen en binnen enkele minuten resultaat zien.
Klaar om te stoppen met knippen en plakken en te starten met automatiseren? en ontdek hoe eenvoudig webscraping kan zijn. Meer leren? Bekijk de voor extra tips en tutorials.
Veelgestelde vragen
1. Moet ik kunnen programmeren om een webscraper te maken?
Nee! Met code (zoals Python + Beautiful Soup) heb je volledige controle, maar no-code tools als Thunderbit maken krachtige webscrapers mogelijk voor iedereen—gewoon met een paar klikken en een simpele prompt.
2. Welke data kan ik met Thunderbit scrapen?
Thunderbit kan tekst, getallen, afbeeldingen, e-mails, telefoonnummers en meer halen van vrijwel elke website—ook van pagina’s met paginering en subpagina’s. Er zijn ook sjablonen voor populaire sites.
3. Hoe gaat Thunderbit om met websites die hun layout veranderen?
Thunderbit’s AI past zich automatisch aan de meeste wijzigingen aan. In tegenstelling tot traditionele webscrapers die snel breken, blijft Thunderbit werken dankzij semantisch begrip.
4. Is webscraping legaal en veilig?
Webscraping is toegestaan zolang je alleen openbare data verzamelt en de gebruiksvoorwaarden van een site respecteert. Thunderbit stimuleert verantwoord gebruik en biedt functies om compliant te blijven.
5. Kan ik scrapes plannen of automatisch exporteren?
Ja! Met Thunderbit kun je scrapes plannen (dagelijks, wekelijks, enz.) en resultaten direct exporteren naar Google Sheets, Notion, Airtable, Excel of CSV—zonder handmatig werk.
Wil je je dataverzameling automatiseren? en ontdek hoe eenvoudig webscraping voor iedereen kan zijn.
Meer weten