
Het internet groeit zo hard dat het bijna niet bij te houden is. In 2024 zijn er meer dan 1,1 miljard websites, met 149 zettabyte aan data die overal rondslingert (en volgend jaar wordt dat naar verwachting zelfs 181 ZB). Dat zijn nogal wat digitale menukaarten. Maar het gekke is: slechts 4% van alle online content is vindbaar via zoekmachines. De rest zit verstopt in het 'deep web', onzichtbaar voor onze dagelijkse zoekopdrachten. Hoe zorgen zoekmachines en bedrijven er dan voor dat ze toch hun weg vinden in deze digitale jungle? Daar komt de webcrawler om de hoek kijken.
In deze gids leg ik je uit wat webcrawling precies inhoudt, hoe het werkt en waarom het belangrijk is – niet alleen voor techneuten, maar voor iedereen die meer uit online data wil halen. We maken het verschil tussen webcrawling en webscraping duidelijk (geloof me, dat is echt niet hetzelfde), laten praktijkvoorbeelden zien en bespreken zowel code- als no-code oplossingen (waaronder mijn favoriet, Thunderbit). Of je nu een nieuwsgierige beginner bent of als bedrijf meer uit het web wilt halen, je zit hier goed.
Wat is een Webcrawler? De Basis van Webcrawling
Laten we bij het begin beginnen. Een webcrawler (ook wel spider, bot of website crawler genoemd) is een automatisch programma dat het web systematisch afstruint, webpagina’s ophaalt en links volgt om nieuwe content te ontdekken. Zie het als een robot-bibliothecaris die begint met een lijst boeken (URL’s), elk boek leest en via de verwijzingen weer nieuwe boeken vindt. Zo werkt een crawler – maar dan met webpagina’s in plaats van boeken, en het internet als bibliotheek.
Het basisidee:
- Start met een lijst van URL’s (de zogenaamde 'seeds')
- Bezoek elke pagina en download de inhoud (HTML, afbeeldingen, enzovoort)
- Zoek hyperlinks op die pagina’s en voeg ze toe aan de wachtrij
- Herhaal – bezoek nieuwe links, ontdek meer pagina’s, enzovoort
De belangrijkste taak van een webcrawler is pagina’s ontdekken en in kaart brengen. Voor zoekmachines betekent dit: de inhoud van pagina’s kopiëren en terugsturen om te indexeren en analyseren. In andere gevallen halen gespecialiseerde crawlers specifieke gegevens op (daar komt webscraping om de hoek kijken – daarover straks meer).
Belangrijk om te onthouden:
Webcrawling draait om ontdekken en structureren van het web, niet alleen om data verzamelen. Het is de basis waarop zoekmachines als Google en Bing weten wat er allemaal online staat.
Hoe Werkt een Zoekmachine? De Rol van Crawlers
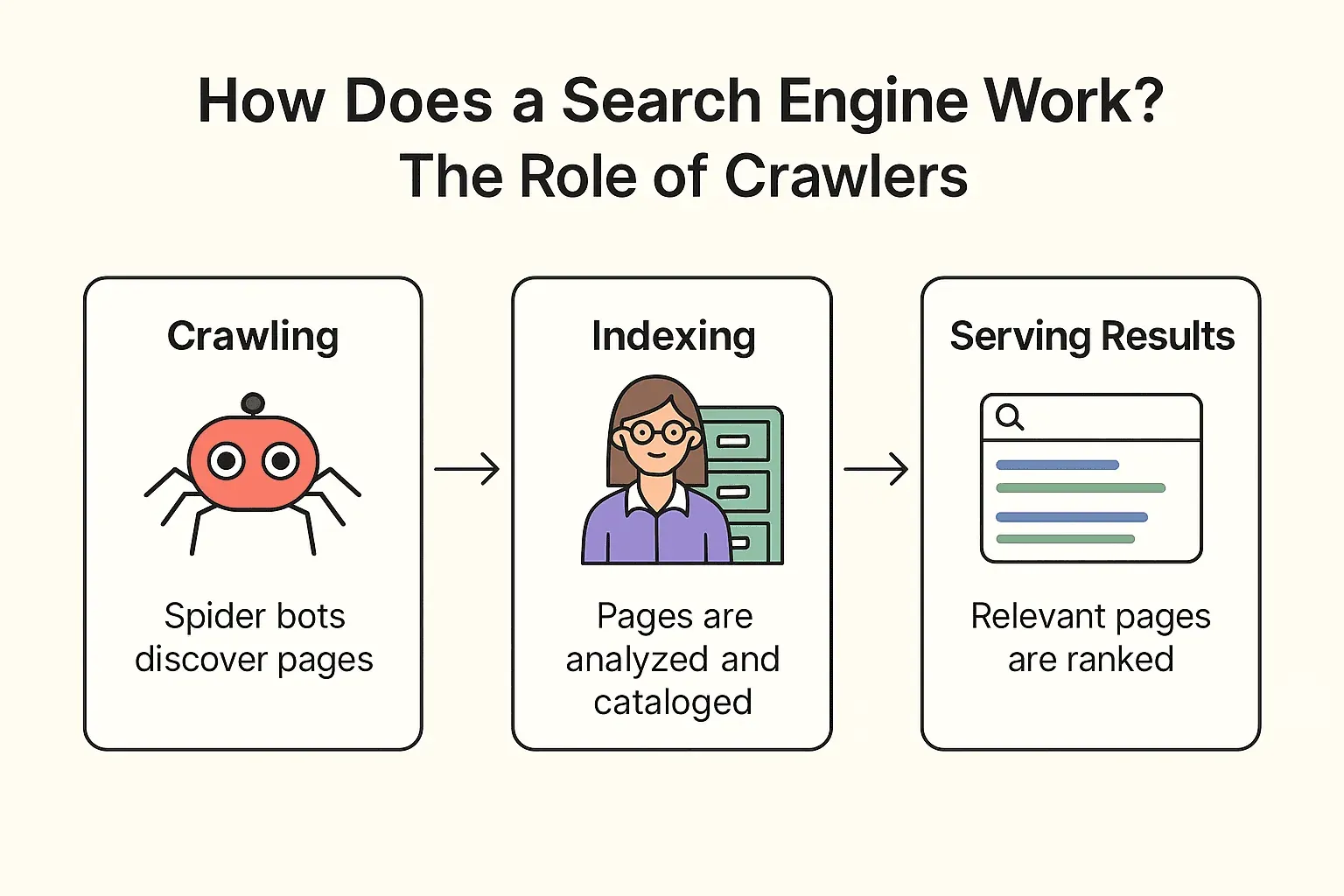
Hoe werkt Google (of Bing, of DuckDuckGo) nu eigenlijk? Het proces bestaat uit drie stappen: crawlen, indexeren en resultaten tonen (officiële uitleg van Google).
Laten we het vergelijken met een bibliotheek (want wie houdt er niet van een goede boekenmetafoor?):
-
Crawlen:
De zoekmachine stuurt zijn 'spider bots' (zoals Googlebot) het web op. Ze beginnen bij bekende pagina’s, halen de inhoud op en volgen links om nieuwe pagina’s te vinden – net als een bibliothecaris die elk boekenrek afgaat en via voetnoten weer nieuwe boeken ontdekt.
-
Indexeren:
Zodra een pagina gevonden is, analyseert de zoekmachine de inhoud, bepaalt waar het over gaat en slaat belangrijke info op in een gigantische digitale kaartenbak (de index). Niet elke pagina wordt opgenomen – sommige worden overgeslagen als ze geblokkeerd zijn, van lage kwaliteit zijn of dubbel zijn.
-
Resultaten tonen:
Zoek je bijvoorbeeld op “beste pizza bij mij in de buurt”, dan zoekt de zoekmachine in de index naar relevante pagina’s en rangschikt ze op basis van honderden factoren (zoals zoekwoorden, populariteit, actualiteit). Het resultaat? Een overzichtelijke lijst met webpagina’s die je direct kunt bekijken.
Leuk weetje:
Zoekmachines crawlen niet elke pagina op het web. Pagina’s achter een login, geblokkeerd door robots.txt of zonder inkomende links worden vaak nooit gevonden. Daarom melden bedrijven hun URL’s of sitemaps soms direct aan bij Google.
Webcrawling vs. Webscraping: Wat is het Verschil?
Hier wordt het interessant. Veel mensen halen 'webcrawling' en 'webscraping' door elkaar, maar het zijn echt verschillende dingen.
| Aspect | Web Crawling (Spidering) | Web Scraping |
|---|---|---|
| Doel | Zoveel mogelijk pagina’s ontdekken en indexeren | Specifieke data uit één of meerdere webpagina’s halen |
| Metafoor | Bibliothecaris die elk boek in de bibliotheek registreert | Student die alleen de belangrijkste aantekeningen uit een paar boeken overneemt |
| Resultaat | Lijst van URL’s of pagina-inhoud (voor indexering) | Gestructureerde dataset (CSV, Excel, JSON) met gerichte info |
| Gebruikers | Zoekmachines, SEO-specialisten, webarchieven | Bedrijfsteams in sales, marketing, onderzoek, enz. |
| Schaal | Enorm (miljoenen/miljarden pagina’s) | Gericht (tientallen, honderden of duizenden pagina’s) |
Bekijk hier een visuele vergelijking.
Kort samengevat:
- Webcrawling draait om pagina’s vinden (het web in kaart brengen)
- Webscraping draait om de gewenste data uit die pagina’s halen (informatie in een spreadsheet zetten)
De meeste zakelijke gebruikers (vooral in sales, e-commerce of marketing) zijn vooral geïnteresseerd in scraping – gestructureerde data verzamelen voor analyse – en niet in het crawlen van het hele web. Crawling is essentieel voor zoekmachines en grootschalige verkenning, terwijl scraping draait om gerichte data-extractie.
Waarom een Webcrawler Gebruiken? Praktische Zakelijke Toepassingen
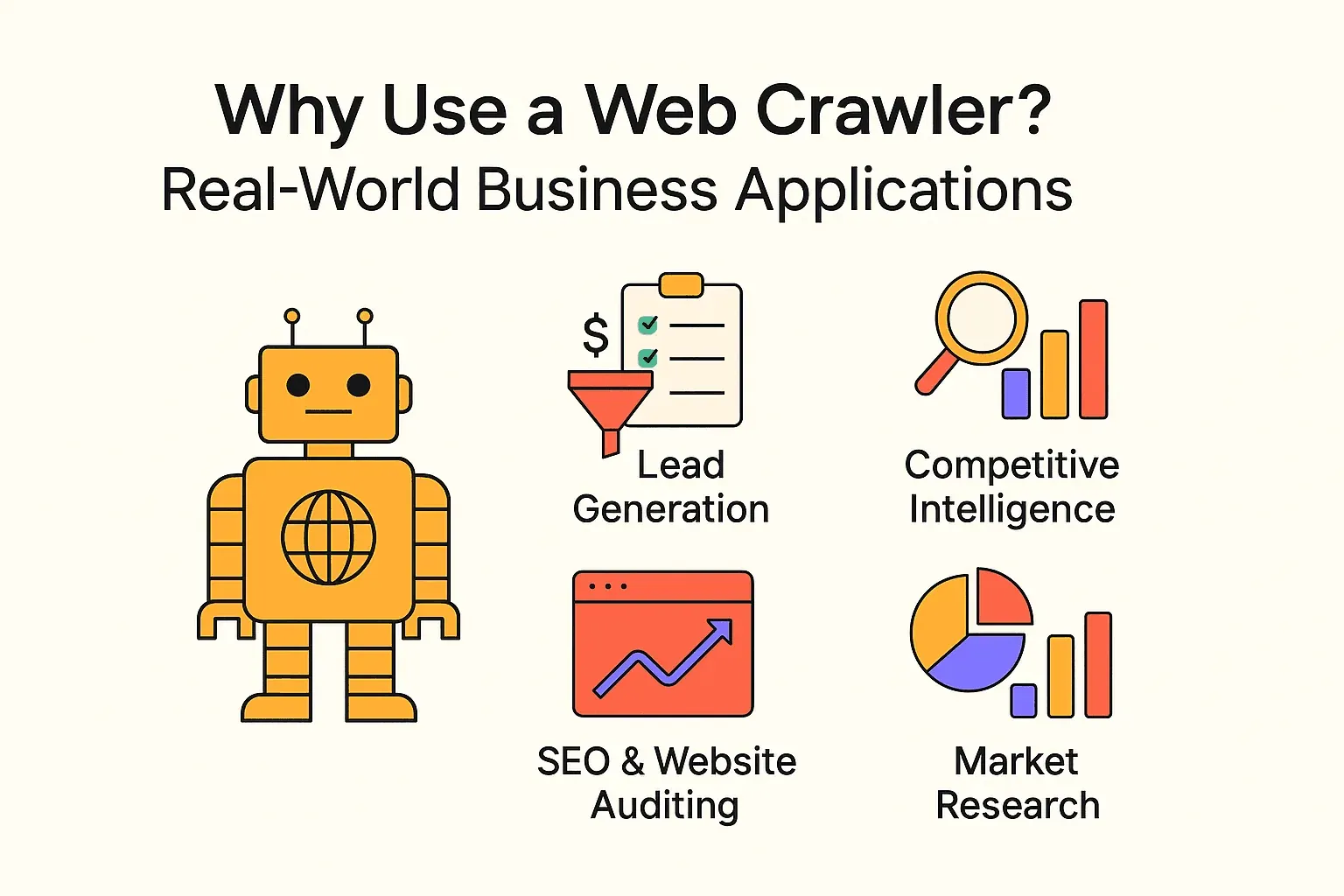
Webcrawling is niet alleen voor zoekmachines. Bedrijven van elke omvang gebruiken crawlers en webscrapers om waardevolle inzichten te krijgen en saaie taken te automatiseren. Enkele praktijkvoorbeelden:
| Toepassing | Gebruiker | Voordeel |
|---|---|---|
| Leadgeneratie | Salesteams | Automatisch prospects vinden, CRM vullen met nieuwe leads |
| Concurrentieanalyse | Retail, e-commerce | Prijzen, voorraad en productwijzigingen van concurrenten volgen |
| SEO & Website-audit | Marketing, SEO-teams | Kapotte links vinden, sitestructuur optimaliseren |
| Contentaggregatie | Media, onderzoek, HR | Nieuws, vacatures of openbare datasets verzamelen |
| Marktonderzoek | Analisten, productteams | Reviews, trends of sentiment op grote schaal analyseren |
- Groupon verdubbelde het aantal inkomende leads door leadgeneratie te automatiseren met webcrawling.
- 82% van de e-commercebedrijven en 71% van de financiële dienstverleners vertrouwen op webscraping voor hun besluitvorming.
- Webscraping kan tot 90% besparen op infrastructuurkosten en 60% op tijd vergeleken met handmatig data verzamelen.
Kortom: Als jij geen gebruikmaakt van webdata, doet je concurrent het waarschijnlijk wel.
Zelf een Webcrawler Bouwen met Python: Wat Moet Je Weten?
Ben je handig met code? Dan is Python dé taal om zelf een webcrawler te bouwen. Het basisrecept:
- Gebruik requests om webpagina’s op te halen
- Gebruik BeautifulSoup om HTML te ontleden en links/data te extraheren
- Schrijf lussen (of recursie) om links te volgen en meer pagina’s te crawlen
Voordelen:
- Maximale flexibiliteit en controle
- Je kunt complexe logica, eigen datastromen en database-integraties bouwen
Nadelen:
- Je hebt programmeerkennis nodig
- Onderhoud kan lastig zijn: verandert de website, dan werkt je script mogelijk niet meer
- Je moet zelf omgaan met anti-botmaatregelen, vertragingen en foutafhandeling
Eenvoudig Python-crawler voorbeeld:
Hier een simpel script dat citaten en auteurs ophaalt van quotes.toscrape.com:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
Wil je meerdere pagina’s crawlen, voeg dan logica toe om op de “Next”-knop te zoeken en door te gaan tot er geen pagina’s meer zijn.
Veelgemaakte fouten:
- Niet letten op robots.txt of crawlvertragingen (doe dat alsjeblieft wél)
- Geblokkeerd worden door anti-botsystemen
- Per ongeluk oneindige lussen crawlen (zoals kalenders die eindeloos doorgaan)
Stappenplan: Zelf een Simpele Webcrawler Bouwen met Python
Wil je zelf aan de slag met code? Hier een stappenplan voor een basis-crawler.
Stap 1: Je Python-omgeving Inrichten
Zorg dat Python geïnstalleerd is. Installeer dan de benodigde libraries:
pip install requests beautifulsoup4
Loop je tegen problemen aan? Controleer je Python-versie (python --version) en of pip werkt.
Stap 2: De Kern van je Crawler Schrijven
Het basispatroon:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited of depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Links extraheren
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
Tips:
- Beperk de crawl-diepte om oneindige lussen te voorkomen
- Houd bij welke URL’s je al bezocht hebt
- Respecteer robots.txt en voeg vertragingen toe (time.sleep(1)) tussen verzoeken
Stap 3: Data Extracten en Opslaan
Om data op te slaan kun je bijvoorbeeld naar een CSV- of JSON-bestand schrijven:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Auteur'])
# In je crawl-lus:
writer.writerow([text, author])
Of gebruik Python’s json-module voor JSON-output.
Belangrijke Aandachtspunten en Best Practices voor Webcrawling
Webcrawling is krachtig, maar brengt ook verantwoordelijkheid met zich mee (en het risico dat je IP wordt geblokkeerd). Zo blijf je netjes:
- Respecteer robots.txt: Controleer altijd het robots.txt-bestand van een site en houd je eraan.
- Crawl met beleid: Voeg altijd vertragingen toe tussen verzoeken (minimaal een paar seconden). Overbelast servers niet.
- Beperk je scope: Crawl alleen wat je nodig hebt. Stel limieten in voor diepte en domein.
- Identificeer jezelf: Gebruik een duidelijke User-Agent string.
- Houd je aan de wet: Scrape geen privé- of gevoelige informatie. Blijf bij openbare data.
- Wees ethisch: Kopieer geen complete websites en gebruik gescrapete data niet voor spam.
- Test rustig: Begin klein, schaal pas op als alles goed werkt.
Meer weten? Bekijk deze best practices gids.
Wanneer Kiezen voor Webscraping: Thunderbit voor Zakelijke Gebruikers
Gebruik AI om data van elke website te halen Get Started Free
Mijn eerlijke advies: tenzij je een eigen zoekmachine bouwt of complete sitestructuren wilt in kaart brengen, zijn webscraping tools voor de meeste zakelijke gebruikers de beste keuze.
Daar komt Thunderbit om de hoek kijken. Als medeoprichter en CEO ben ik misschien niet helemaal objectief, maar ik geloof echt dat Thunderbit de makkelijkste manier is voor niet-technische gebruikers om webdata te verzamelen.
Waarom Thunderbit?
- Supersnel starten: Klik op “AI Suggest Fields” en daarna op “Scrape” – klaar.
- AI-ondersteund: Thunderbit leest de pagina en stelt automatisch de beste kolommen voor (productnamen, prijzen, afbeeldingen, enz.).
- Bulk & PDF-ondersteuning: Haal data van de huidige pagina, meerdere URL’s tegelijk of zelfs uit PDF’s.
- Flexibele export: Download als CSV/JSON, of stuur direct naar Google Sheets, Airtable of Notion.
- Geen code nodig: Als je een browser kunt gebruiken, kun je met Thunderbit werken.
- Subpagina’s scrapen: Meer details nodig? Thunderbit bezoekt automatisch subpagina’s en verrijkt je data.
- Automatisch plannen: Stel terugkerende scrapes in met gewone taal (bijvoorbeeld “elke maandag om 9 uur”).
Probeer Thunderbit Chrome-extensie gratis
Wanneer kies je dan wél voor een crawler?
Wil je een complete website in kaart brengen (zoals voor een zoekindex of sitemap), dan is een crawler het juiste gereedschap. Maar wil je alleen gestructureerde data van specifieke pagina’s (zoals productlijsten, reviews of contactgegevens), dan is scrapen sneller, eenvoudiger en praktischer.
Samenvatting & Belangrijkste Inzichten
Samengevat:
- Webcrawling is hoe zoekmachines en grote dataprojecten het web ontdekken en in kaart brengen. Het draait om breedte – zoveel mogelijk pagina’s vinden.
- Webscraping draait om diepte – de specifieke data halen die jij nodig hebt. De meeste bedrijven hebben scraping nodig, niet crawling.
- Je kunt zelf een crawler coderen (Python is daar ideaal voor), maar het kost tijd, kennis en onderhoud.
- No-code en AI-tools zoals Thunderbit maken webdata toegankelijk voor iedereen – zonder te programmeren.
- Best practices zijn belangrijk: Werk altijd netjes, respecteer website-regels en gebruik data op een verantwoorde manier.
Begin je net? Kies een eenvoudig project – bijvoorbeeld productprijzen scrapen of leads verzamelen uit een bedrijvengids. Probeer een tool als Thunderbit voor een snelle start, of experimenteer met Python als je de techniek wilt leren.
Het web is een goudmijn aan informatie. Met de juiste aanpak haal je inzichten op die je helpen slimmer te werken, tijd te besparen en je bedrijf een voorsprong te geven.
Start met scrapen via Thunderbit
FAQ
- Wat is het verschil tussen webcrawling en webscraping?
Crawling zoekt en brengt pagina’s in kaart. Scraping haalt specifieke data uit die pagina’s. Crawling = ontdekken; scraping = extraheren.
- Is webscraping legaal?
Openbare data scrapen mag meestal, zolang je robots.txt en de gebruiksvoorwaarden respecteert. Vermijd privé- of auteursrechtelijk beschermde content.
- Moet ik kunnen programmeren om websites te scrapen?
Nee. Met tools als Thunderbit kun je met een paar klikken en AI data scrapen – zonder code.
- Waarom is niet het hele web geïndexeerd door Google?
Omdat het grootste deel achter logins, betaalmuren of blokkades zit. Slechts zo’n 4% is daadwerkelijk geïndexeerd.
Verder lezen
- FreeCodeCamp – Web Scraping met Python en BeautifulSoup
- Scrapy Officiële Tutorial
- Real Python – Webscraping met Selenium en Python
- Apify Academy: Web Scraping en Automatisering
Probeer AI-webscraper Get Started Free




