

Heb je ooit geprobeerd om productprijzen, concurrentie-informatie of een lijst met potentiële klanten van het internet te halen? Dan weet je vast hoe het gaat: eindeloos klikken, kopiëren, plakken en weer opnieuw—tot je koffie koud is of je geduld opraakt. Webdata-extractie is tegenwoordig echt onmisbaar voor sales-, operations- en marketingteams. Het draait niet alleen om tijd besparen (al is dat een groot voordeel), maar vooral om het ontsluiten van waardevolle inzichten, het automatiseren van saaie klusjes en het sneller maken van slimme keuzes dan je concurrenten.
Ik heb zelf meegemaakt hoe een slimme webdata-extractie workflow een week handmatig uitzoekwerk kan terugbrengen tot een klusje van vijf minuten. Of je nu helemaal nieuw bent of je scraping-skills wilt aanscherpen, deze webdata-extractie handleiding neemt je stap voor stap mee door de basics, de valkuilen en de praktische aanpak—met zowel klassieke methodes als AI-tools zoals Thunderbit. Samen maken we van het web jouw persoonlijke databron.
Wat is webdata-extractie? De basics
Kort gezegd is webdata-extractie (ook wel webscraping genoemd) het automatisch verzamelen van info van websites en die omzetten naar een overzichtelijk formaat—zoals een spreadsheet of database—voor analyse of zakelijk gebruik. In plaats van urenlang te kopiëren en plakken, werkt een webscraper als een digitale assistent: hij speurt webpagina’s af, haalt precies de gegevens die je zoekt (denk aan prijzen, productnamen, e-mails, reviews) en zet ze netjes voor je klaar (Thunderbit Blog).
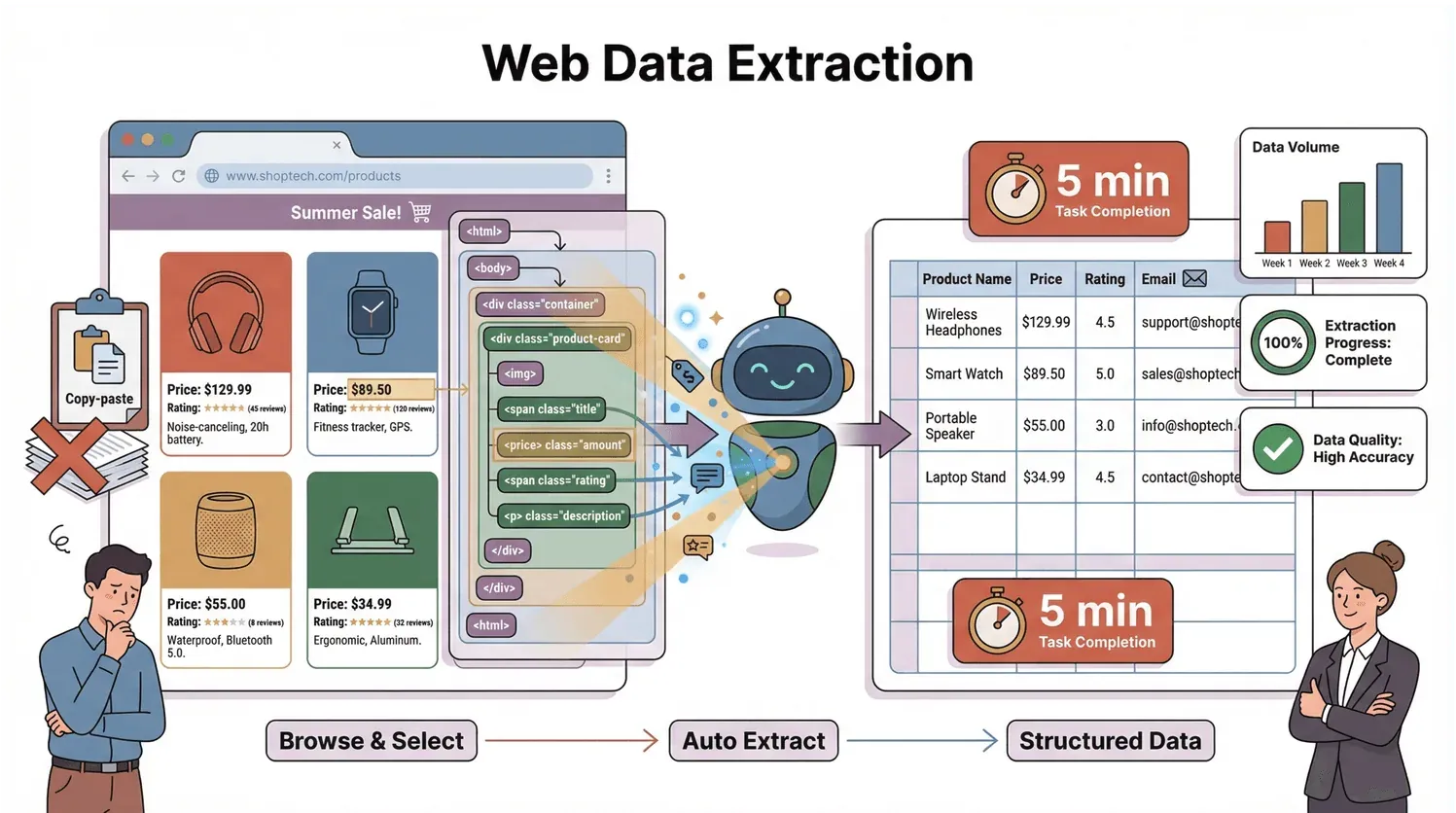
Hoe werkt dat dan? Elke webpagina heeft een bepaalde opbouw, de DOM (Document Object Model)—zie het als het bouwplan dat je browser (en elke scraper) vertelt waar alles staat. Een scraper leest dat bouwplan, zoekt de elementen die jij nodig hebt en zet ze om in rijen en kolommen. Het is alsof je een supergeorganiseerde assistent hebt die nooit moe wordt of afgeleid raakt door kattenfilmpjes.
Waarom webdata-extractie onmisbaar is voor sales en operations
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Laten we eerlijk zijn: webdata-extractie is geen hobby voor nerds—het is een echte gamechanger voor bedrijven. Daarom stappen steeds meer sales-, operations- en marketingteams in:
| Toepassing | Zakelijk voordeel | Praktisch resultaat |
|---|---|---|
| Leadgeneratie | Snel je salesfunnel vullen met gekwalificeerde leads | 70% ROI in 6 maanden; 40% meer kwalitatieve leads; honderden uren bespaard (Grepsr) |
| Prijsmonitoring | Dynamische prijzen, marges beschermen | 65% ROI in een half jaar; 12% meer omzet; 75% minder handwerk (Grepsr) |
| Concurrentieanalyse | Direct inzicht in de markt | 55% ROI voor luchtvaart; 68% ROI voor e-commerce trendanalyse (Grepsr) |
| Operationele monitoring | Voorkom lege schappen, optimaliseer je supply chain | 62% ROI voor wereldwijde retailer; geen onverwachte voorraadtekorten meer (Grepsr) |
En het draait niet alleen om rendement. Door webdata automatisch te verzamelen, kan je team zich focussen op strategie in plaats van eindeloos spreadsheets vullen. Sommige bedrijven hebben hun datakosten zelfs met 40% verlaagd (Browsercat), en de wereldwijde webscraping-markt groeit van $5 miljard in 2023 naar ruim $140 miljard in 2032 (Browsercat). Dat is een enorme kans.
Hoe werkt webdata-extractie: van DOM naar datatabel
Laten we even onder de motorkap kijken (zonder het te technisch te maken):
- Request: De scraper stuurt een verzoek naar de website en haalt de ruwe HTML op.
- Parse: Hij leest de DOM-structuur—de boomstructuur die alle elementen op de pagina organiseert.
- Extract: Hij zoekt de gewenste data (zoals prijzen, namen, e-mails) en zet ze om in een gestructureerde tabel (CSV, Excel, Google Sheets, enz.) (Thunderbit Blog).
De DOM begrijpen: de basis van webdata-extractie
Zie de DOM als de stamboom van een webpagina. Bovenaan staat het document, dat zich vertakt in <html>, dan <head> en <body>, enzovoort—tot aan elke <div>, <span> en elk stukje tekst (Dataprixa). Elk knooppunt in deze boom is een element dat je kunt targeten.
Wil je bijvoorbeeld de prijs van een product pakken, dan zoekt de scraper naar een <span class="price"> ergens binnen een <div> in de <body>. Het is alsof je je assistent vraagt: “Loop naar de keuken, open de koelkast, zoek de melk.” De DOM is de plattegrond; jouw scraper is de speurneus.
Let wel: moderne websites laden vaak content dynamisch met JavaScript. De data die je zoekt, staat dus soms niet in de eerste HTML, maar verschijnt pas als de pagina volledig geladen is en scripts zijn uitgevoerd. Je scraper moet dus de gerenderde DOM kunnen lezen, niet alleen de ruwe HTML (Dataprixa). Hier gaan veel klassieke scrapers de mist in—en blinken moderne tools juist uit.
Veelvoorkomende valkuilen bij webdata-extractie (en hoe je ze omzeilt)
Webscraping is niet altijd een eitje. Dit zijn de meest voorkomende struikelblokken—en hoe je ze slim omzeilt:
- Dynamische content & oneindig scrollen: Veel sites laden data pas als je scrolt of klikt. Als je scraper alleen de eerste HTML pakt, mis je veel. Oplossing: gebruik tools die JavaScript kunnen renderen of scrollen kunnen nadoen (Thunderbit doet dit automatisch) (Thunderbit Blog).
- Paginering & subpagina’s: Staat de data verspreid over meerdere pagina’s of verborgen in detailpagina’s? Zorg dat je tool “Volgende” knoppen kan volgen en subpagina’s kan openen. Thunderbit’s “Subpagina’s scrapen” is hier ideaal voor (Thunderbit Blog).
- Wijzigingen in website-structuur: Een kleine aanpassing in de site kan klassieke scrapers breken. AI-tools zoals Thunderbit passen zich automatisch aan, zodat je niet steeds scripts hoeft te repareren (Thunderbit Blog).
- Anti-scraping maatregelen: CAPTCHAs, IP-blokkades en limieten kunnen je tegenhouden. Scrape altijd netjes (langzamer, met willekeurige pauzes), gebruik browsertools die echte gebruikers nadoen en respecteer de regels van de site (Medium).
- Ongeordende of inconsistente data: Niet elke site is netjes opgebouwd. Soms heb je AI-prompts of aangepaste regels nodig om de juiste info te pakken (Thunderbit’s Field AI Prompt is hier superhandig).
Omgaan met dynamische pagina’s en JavaScript rendering
Sommige pagina’s tonen niet direct alle data—ze laden meer zodra je scrolt of klikt. Klassieke scrapers missen dit, maar browserextensies (zoals Thunderbit) zien wat jij ziet en kunnen alles pakken, zelfs bij oneindig scrollen of pop-ups (ScrapingBee).
Omgaan met anti-scraping maatregelen
Word je geblokkeerd of zie je CAPTCHAs? Vertraag je verzoeken, roteer je IP-adressen en gebruik browsertools die op echte gebruikers lijken. En check altijd de voorwaarden en robots.txt van de site (ScrapingBee).
Webdata-extractie tools vergelijken: Thunderbit vs. traditionele oplossingen
Er zijn veel manieren om data te scrapen—de ene makkelijker dan de andere. Zo verhouden de belangrijkste opties zich:
| Oplossing | Installatietijd | Vereiste kennis | Onderhoud | Functies & exportmogelijkheden |
|---|---|---|---|---|
| Handmatig kopiëren/plakken | Geen | Geen | Altijd handmatig | Geen automatisering; foutgevoelig |
| Eigen code (Python, etc.) | Uren–dagen | Programmeren + HTML | Hoog | Flexibel; export naar alles; hoge leercurve |
| Klassieke no-code tools | ~1 uur per site | Enige technische kennis | Gemiddeld | Visuele setup; ondersteunt paginering; gemiddelde leercurve |
| Thunderbit (AI no-code) | Minuten | Geen (gewoon Nederlands) | Laag (AI past aan) | AI-veldherkenning; subpagina’s; plannen; export naar Sheets/Excel/Notion |
Thunderbit springt eruit voor zakelijke gebruikers omdat het extreem eenvoudig is. Je hoeft geen code te kennen—beschrijf gewoon wat je wilt en de AI regelt de rest (Thunderbit Blog).
Waarom Thunderbit ideaal is voor zakelijke gebruikers
- Supersimpel: “AI Velden voorstellen” en dan “Scrapen.” Klaar.
- AI-veldherkenning: De AI leest de pagina en stelt de beste kolommen voor—geen giswerk.
- No-code, natuurlijke taal: Typ gewoon wat je wilt (“Haal alle productnamen en prijzen op”) en Thunderbit regelt het.
- Automatisch subpagina’s & paginering: Scrape alle pagina’s en detail-links met één klik.
- Snel exporteren: Stuur data direct naar Excel, Google Sheets, Notion of Airtable—zonder extra kosten.
- Cloud of browsermodus: Scrape in de cloud voor snelheid, of in je browser voor ingelogde pagina’s.
Thunderbit is gemaakt voor de praktijk—waar websites veranderen, data rommelig is en zakelijke gebruikers resultaat willen, geen gedoe.
Stapsgewijze webdata-extractie met Thunderbit
Klaar om zelf aan de slag te gaan (zonder vieze handen)? Zo haal je data van elke website met Thunderbit:
Stap 1: Installeer de Thunderbit Chrome-extensie
Ga naar de Chrome Web Store en voeg Thunderbit toe. Maak een gratis account aan—met de gratis versie kun je een paar pagina’s testen.
Stap 2: Navigeer naar de gewenste website
Open de site waarvan je data wilt scrapen. Log in als dat nodig is en scroll of klik zodat alle gewenste data zichtbaar is.
Stap 3: Open Thunderbit en geef je databehoefte aan
Klik op het Thunderbit-icoon. Je kunt:
- Op “AI Velden voorstellen” klikken zodat de AI kolommen voorstelt.
- Of een eigen prompt typen: “Haal productnaam, prijs en reviews op.”
Thunderbit laat een voorbeeld zien van de gevonden velden. Je kunt kolommen hernoemen, verwijderen of toevoegen.
Stap 4: Start de scraping
Klik op “Scrapen.” Thunderbit zet de data in een tabel. Zijn er meerdere pagina’s of subpagina’s, dan vraagt hij of je alles wilt scrapen—gewoon bevestigen.
Stap 5: Controleer en exporteer
Bekijk het resultaat. Mist er iets? Probeer je prompt anders te formuleren of zorg dat alle content geladen is. Tevreden? Klik op “Exporteren” om te downloaden als CSV, of stuur direct naar Google Sheets, Excel, Notion of Airtable.
Praktijkvoorbeeld: Amazon productreviews scrapen met Thunderbit
Stel, je wilt Amazon-reviews van een concurrerend product analyseren. Zo werkt het met Thunderbit:
- Ga naar de Amazon-productpagina en klik op “Bekijk alle reviews.”
- Activeer Thunderbit. Zie je de Amazon Reviews Scraper-template? Gebruik die—alle velden staan al goed ingesteld (Thunderbit Amazon Reviews Scraper).
- Klik op “Scrapen.” Thunderbit haalt namen, beoordelingen, reviewteksten, data en meer op—ook over meerdere pagina’s.
- Exporteer. Je hebt nu een spreadsheet klaar voor sentimentanalyse, concurrentieonderzoek of een snel “Wat vinden klanten belangrijk?”-rapport.
Wil je aanpassen? Gebruik een natuurlijke prompt: “Haal naam reviewer, aantal sterren, datum en reviewtekst op.” Thunderbit’s AI regelt de rest—zelfs als Amazon de layout aanpast.
Geavanceerde tips: aanpassen en automatiseren van webdata-extractie
Heb je de basis onder de knie? Met deze geavanceerde functies van Thunderbit haal je nog meer uit je workflow:
- Field AI Prompts: Voeg per veld instructies toe (bijv. “Alleen reviews met 1 of 2 sterren” of “Vertaal reviewtekst naar het Engels”).
- Geplande scraping: Stel terugkerende taken in (dagelijks, wekelijks, enz.) om je data actueel te houden—ideaal voor prijsmonitoring of leadgeneratie (Thunderbit Blog).
- AI-autovullen: Automatiseer formulieren of meerstapsprocessen (handig voor sites met zoekopdrachten of logins).
- Cloud scraping: Voor grote klussen kun je scrapes in de cloud draaien voor snelheid en betrouwbaarheid.
- Instant templates: Gebruik kant-en-klare sjablonen voor populaire sites als Amazon, Zillow, Yelp, LinkedIn en meer (Thunderbit Blog).
Je kunt Thunderbit zelfs integreren in je teamworkflow—exporteer naar Google Sheets, deel resultaten of koppel aan andere tools voor geautomatiseerde pipelines.
De toekomst van webdata-extractie: AI-trends en zakelijk effect
De beste webscraping-tools & software in 2025 Get Started Free
AI verandert het speelveld van webdata-extractie compleet:
- Veerkracht: AI-gedreven scrapers passen zich automatisch aan sitewijzigingen aan, waardoor onderhoud en uitval afnemen (GroupBWT).
- Agentive scraping: Bots kunnen nu navigeren, klikken en interacteren als een mens—en zo nieuwe databronnen ontsluiten.
- Continue datastromen: Bedrijven stappen over van eenmalige scrapes naar realtime, altijd-aan datastromen.
- Toegankelijkheid: No-code tools in gewone taal zoals Thunderbit maken webdata-extractie voor iedereen bereikbaar, niet alleen voor developers.
- Direct inzicht: De volgende stap is scraping combineren met AI-analyse—denk aan automatisch samenvatten van klantreviews en direct inzicht in pijnpunten.
Kortom: AI-gedreven webdata-extractie wordt net zo onmisbaar als spreadsheets of CRM-systemen. Teams die dit onder de knie hebben, lopen voorop—terwijl de rest nog steeds handmatig kopieert en plakt.
Samenvatting & belangrijkste punten
- Webdata-extractie maakt van het internet jouw persoonlijke database—leads, prijzen, reviews en meer automatisch verzamelen.
- De DOM is het bouwplan van elke webpagina; dit begrijpen is essentieel voor effectieve scraping.
- Veelvoorkomende valkuilen (dynamische content, anti-botmaatregelen, rommelige data) kun je vermijden met de juiste tools en wat kennis.
- Thunderbit maakt webdata-extractie voor iedereen toegankelijk: twee klikken, AI-veldherkenning, subpagina’s scrapen en direct exporteren naar je favoriete tools.
- AI is de toekomst—scraping wordt sneller, slimmer en betrouwbaarder voor zakelijke gebruikers.
Zelf proberen? Download Thunderbit en ontdek hoe makkelijk webdata-extractie kan zijn. Meer tips, verdiepingen en praktijkvoorbeelden vind je op de Thunderbit Blog.
Veelgestelde vragen
1. Wat is webdata-extractie en hoe werkt het?
Webdata-extractie (webscraping) is het automatisch verzamelen van informatie van websites en deze omzetten naar gestructureerde data, zoals een spreadsheet. Dit gebeurt door de DOM (Document Object Model) van de website te lezen, de gewenste data te selecteren en te exporteren voor analyse (Thunderbit Blog).
2. Wat zijn de grootste uitdagingen bij webdata-extractie?
De grootste obstakels zijn dynamische content (JavaScript-gegenereerde data), anti-scraping maatregelen (CAPTCHAs, IP-blokkades) en inconsistente of rommelige data. Moderne tools zoals Thunderbit gebruiken AI en browsergebaseerde scraping om deze uitdagingen te overwinnen (Medium).
3. Waarin verschilt Thunderbit van andere webscraping-tools?
Thunderbit is een AI-gedreven, no-code webscraper speciaal voor zakelijke gebruikers. Het biedt een tweestapsproces (“AI Velden voorstellen”, dan “Scrapen”), natuurlijke taalprompts, subpagina’s scrapen en directe export naar Excel, Google Sheets, Notion en Airtable (Thunderbit Blog).
4. Kan ik met Thunderbit data scrapen van dynamische of meerpagina-websites?
Zeker. Thunderbit verwerkt automatisch dynamische content (zoals oneindig scrollen of JavaScript-data) en kan met één klik meerdere pagina’s of subpagina’s scrapen (Thunderbit Blog).
5. Is webdata-extractie legaal?
Het scrapen van openbare data is meestal toegestaan, zeker voor zakelijke inzichten, maar controleer altijd de gebruiksvoorwaarden en robots.txt van de site. Vermijd het scrapen van persoonlijke of privégegevens en scrape verantwoord—overbelast websites niet en respecteer hun beleid (ScrapingBee).
Veel succes met scrapen—moge je spreadsheets altijd gevuld zijn, je data altijd actueel en je kopieer-plakdagen voorgoed voorbij.
Probeer AI-webscraper Get Started Free
Meer weten?




