Wat is een Amazon Webscraper
Een Amazon Webscraper is een handige tool of software die automatisch data van ophaalt. Die data kan bestaan uit productdetails, prijzen, reviews, voorraadstatus en meer. Het belangrijkste doel van een Amazon Webscraper is om grote hoeveelheden data te verzamelen voor marktonderzoek, prijsvergelijking of concurrentieanalyse. Je kunt ook gebruikersreviews verzamelen voor keyword research om beter inzicht te krijgen in de voor- en nadelen van producten.
Belangrijkste functies van een Amazon Webscraper
- Geautomatiseerde data-extractie: Zeg maar dag tegen het tijdrovende handmatig kopiëren en plakken van informatie. Een webscraper haalt automatisch de data die je nodig hebt van webpagina’s.
- Aanpasbaar scrapen: Je kunt de scraper afstemmen op specifieke datatags die passen bij jouw behoeften, zodat je gericht kunt analyseren.
- Data-export: Exporteer gescrapete data eenvoudig naar populaire formaten zoals Excel, CSV of JSON voor verdere analyse met verschillende data-tools.
- Regelmatige updates: Stel intervallen in om te scrapen, zodat je Amazon-productdatabase up-to-date blijft en je data actueel is.
- Review scrapen: In veel gevallen wil je de voor- en nadelen uit de reviewsectie halen voor concurrentieanalyse.

Waarom een Amazon Webscraper gebruiken
Amazon is een grote speler in de wereldwijde e-commerce, bekend om zijn enorme productaanbod, scherpe prijzen en soepele winkelervaring. Het biedt bedrijven een platform om potentiële klanten wereldwijd te bereiken en hun marktbereik uit te breiden. Consumenten vertrouwen Amazon als een belangrijk online winkelkanaal, wat verkopers een betrouwbare verkoopomgeving geeft. Bovendien stelt Amazons logistieke netwerk bedrijven in staat om snelle en efficiënte bezorgdiensten te benutten, wat de klanttevredenheid verhoogt. Amazon biedt ook verschillende marketingtools om de zichtbaarheid en verkoop van producten te vergroten, zoals gesponsorde productadvertenties en merkpromoties.
Voor e-commercebedrijven is het analyseren van verkoopdata op Amazon cruciaal. Met een Amazon Webscraper kunnen bedrijven data verzamelen om inzicht te krijgen in markttrends en consumentengedrag, en om productstrategieën en voorraadbeheer te optimaliseren. Zo kunnen bedrijven effectief groeien op het Amazon-platform, met meer omzet en merkbekendheid als basis voor duurzame groei. Zo kun je een Amazon Webscraper inzetten voor analyse:
Marktonderzoek
-
SKU-selectie
Het kiezen van de juiste SKU (Stock-Keeping Unit) is essentieel voor succes in e-commerce en heeft invloed op productassortiment, efficiëntie in de toeleveringsketen en voorraadbeheer. Met een Amazon Webscraper kun je nauwkeurige data uit miljoenen producten halen om verkooptrends en klantvoorkeuren te analyseren. Door bijvoorbeeld Amazon’s Product Detail Pages te scrapen, krijg je eenvoudig toegang tot belangrijke informatie zoals productprijzen, aantallen reviews en seller-ratings voor diepgaand marktonderzoek. Deze data helpt bepalen of een SKU marktpotentieel heeft en laat zien welke producten het best presteren. Door producten binnen dezelfde categorie te vergelijken, kunnen bedrijven hun productselectie optimaliseren, de voorraad van populaire SKU’s verhogen en de voorraad van trager lopende artikelen verlagen, waardoor de omloopsnelheid van de voorraad verbetert.
-
Klanttrends identificeren
Door een grote hoeveelheid productreviews, ratings en klantfeedback te scrapen, kan een webscraper je helpen om veranderingen in de vraag van consumenten snel te signaleren. Door reviewdata te analyseren, kun je bijvoorbeeld zien welke kenmerken consumenten het meest waarderen in een product, zoals “betaalbare prijs” of “duurzaamheid”. Die informatie is cruciaal voor productontwikkeling, prijsstrategie en marketingstrategie. Daarnaast kun je door data over aankoopfrequentie en verkooptrends in de tijd te scrapen seizoensschommelingen beter voorspellen en voorraad- en marketingactiviteiten op voorhand plannen.

Concurrentieanalyse
-
Prijsmonitoring
In een concurrerende markt is prijsmonitoring essentieel voor e-commercebedrijven. Een Amazon Webscraper helpt je om realtime productdata te scrapen en prijswijzigingen van concurrenten te volgen, zodat je prijzen concurrerend blijven. Deze functie is vooral waardevol voor dynamische prijsstrategieën. Door prijsinformatie van vergelijkbare producten te verzamelen, kunnen bedrijven flexibele prijsmodellen opstellen die prijzen automatisch aanpassen op basis van marktvraag, voorraadniveaus en prijzen van concurrenten om de winst te maximaliseren.
-
Review scrapen
beïnvloeden niet alleen de productverkoop, maar laten ook zien hoe de marktvraag verandert. Een Amazon Webscraper helpt bedrijven om een grote hoeveelheid klantfeedback te verzamelen. AI-gebaseerde webscrapers kunnen helpen met samenvatten en sentimentanalyse, zodat je inzicht krijgt in meningen van gebruikers over jouw producten en die van concurrenten, en zo je productontwerp of marketingstrategie snel kunt aanpassen.
Kostenvergelijking
Met een Amazon Webscraper kunnen bedrijven data verzamelen over prijzen, verzendkosten en promoties van vergelijkbare producten voor een uitgebreide kostenvergelijking. Door deze data te analyseren kunnen bedrijven hun kostenstructuur optimaliseren, onnodige uitgaven vermijden en winstmarges verhogen. Voor bedrijven die op Amazon naar leveranciers zoeken, geeft dit ook inzicht in de verzendkosten en verkoopprijzen van verschillende leveranciers, waardoor kosten dalen en concurrerende prijzen in de markt gewaarborgd blijven, wat uiteindelijk de brutowinstmarge verbetert.
Probeer AI te gebruiken voor webscraping
Probeer het zelf! Je kunt klikken, verkennen en de workflow uitvoeren terwijl je meekijkt.
Waarom AI gebruiken om Amazon-productdata te scrapen
Door de snelle opkomst van AI luiden AI-gestuurde Amazon Webscraper-tools een nieuw tijdperk in van dataverzameling, met veel gemak ten opzichte van traditionele webscrapingprocessen. AI maakt dataverzameling niet alleen efficiënter en nauwkeuriger, maar verlaagt ook de technische drempel aanzienlijk en biedt e-commercebedrijven meer innovatieve kansen.
Gebruiksvriendelijk voor niet-technische gebruikers
Voor gebruikers zonder technische achtergrond bieden AI-ondersteunde Amazon Webscraper-tools veel gemak. In tegenstelling tot traditionele scrapers waarvoor handmatige code en API-calls nodig zijn, geven gebruikers simpelweg hun scrapingvereisten op en selecteren ze de gewenste kolomnamen. AI genereert automatisch passende scrapeplannen en suggesties, waardoor gedoe met programmeren en complexe instellingen verdwijnt. Deze gebruiksvriendelijke functie helpt e-commerce teams om efficiënt data te verzamelen zonder gespecialiseerd technisch personeel, verhoogt de productiviteit en maakt het voor niet-technische medewerkers eenvoudig om geavanceerde dataverzamelingstools te gebruiken.
Snel en efficiënt
automatiseert het data-extractieproces en verhoogt de snelheid en efficiëntie van dataverzameling aanzienlijk. Ze kunnen snel complexe websitestructuren en dynamische content verwerken, doeldata nauwkeurig vastleggen, handmatige tussenkomst verminderen en de algehele scrapenauwkeurigheid verbeteren. Daarnaast kan de operationele kosten sterk verlagen en workflows optimaliseren, zodat bedrijven hoogwaardige data tegen lagere kosten kunnen verkrijgen en beslissingen beter onderbouwd kunnen nemen.
Intelligente analyse en suggesties
In vergelijking met traditionele webscrapers biedt het voordeel van intelligente workflowautomatisering. AI-tools kunnen data automatisch categoriseren, samenvatten en inzichten uit data genereren. Bedrijven kunnen AI bijvoorbeeld gebruiken om verschillende producten automatisch in vooraf gedefinieerde categorieën in te delen of grote hoeveelheden reviewdata te analyseren om keywords en sentimenttrends te extraheren, waardoor ze klantfeedback beter begrijpen en producten optimaliseren. AI kan ook aangepaste rapporten genereren op basis van gescrapete data en automatisch marktanalyse opstellen, zodat bedrijven snel populaire productkenmerken en mogelijke marktkansen herkennen.
Slimme output- en exportopties
Met een AI-gebaseerde Amazon webscraper kun je data slimmer uitvoeren. Traditionele codemethoden leveren meestal alleen CSV-bestanden op, terwijl AI-tools naast CSV ook gescrapete data automatisch kunnen exporteren naar samenwerkingsplatforms zoals Google Sheets en Notion, wat data-analyse en delen veel eenvoudiger maakt. Zo kun je data direct in Google Sheets importeren voor realtime analyse of integreren in teamtools voor samenwerking, zodat informatie soepel tussen afdelingen stroomt. Deze slimme manier van data-export helpt teams sneller beslissingen te nemen en vergroot de flexibiliteit en responsiviteit van het bedrijf.
Scrapen met : de
is een onlangs gelanceerde, krachtige en uitgebreide die is ontworpen om aan je databehoeften te voldoen. Met Thunderbit kunnen gebruikers eenvoudig data van Amazon verzamelen, of het nu gaat om productdetails, prijsbewegingen of klantreviews, en dit snel omzetten in waardevolle zakelijke inzichten. Zo kan Thunderbit e-commercebedrijven helpen hun concurrentiepositie te versterken.
Ga eerst naar de en voeg de Thunderbit toe aan je Chrome-browser. Log in met je Google-account of een ander e-mailadres.
 Vervolgens kun je Thunderbit’s ingebouwde voorgebouwde webscraper of gebruiken om . Zo werkt het:
Vervolgens kun je Thunderbit’s ingebouwde voorgebouwde webscraper of gebruiken om . Zo werkt het:
Optie 1: Gebruik Thunderbit’s voorgebouwde webscraper
heeft verschillende voorgebouwde webscraper-tools ontworpen en geoptimaliseerd op basis van gebruikersbehoeften, waaronder een scrape-module speciaal voor Amazon. Deze tools hebben vooraf ingestelde templates voor de complexe datastructuur van Amazon en grote hoeveelheden data verzameld, waardoor je zelf geen scrape-logica hoeft te ontwerpen en het proces sneller en efficiënter wordt voor dataverzameling.
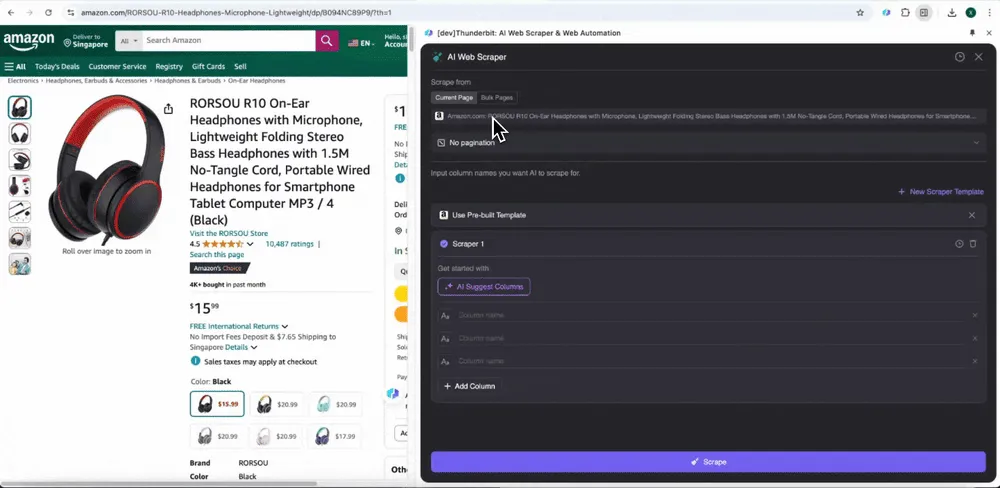
Wanneer je een pagina op Amazon opent, open je de webscraper in de Thunderbit-extensie. Je ziet dan twee voorgebouwde scrapers met uitgebreide kolomnamen. Vink simpelweg de kolomnamen aan die je wilt extraheren, en Thunderbit doet de rest.
-
Amazon SKU-reviews verzamelen
Deze tool biedt voorgebouwde kolomnamen zoals productnaam, product-URL, algemene productbeoordeling, gedetailleerde ratingverdeling, aantal productbeoordelingen, reviewtitel, auteursnaam, reviewinhoud, reviewland en keywords. Je kunt de vakjes aanvinken naast de kolomnamen die je wilt extraheren, op scrapen klikken en snel de SKU-reviewdata ophalen die je nodig hebt voor productreviewanalyse.
-
Amazon SKU-details verzamelen
Deze tool biedt voorgebouwde kolomnamen zoals productnaam, product-URL, merk, fabrikant, beginprijs, eindprijs, beschrijving, beoordeling, categorieën, leveringsopties en seller-URL. Vink de vakjes aan naast de kolomnamen die je wilt extraheren, klik op scrapen en haal snel de SKU-detaildata op die je nodig hebt. Of je nu leveranciers, fabrikanten en leveringsopties vergelijkt, marktonderzoek doet, de prijsconcurrentie van je SKU beoordeelt of de nieuwste verkooptrends begrijpt, deze SKU-detaildata kunnen je analyse ondersteunen.
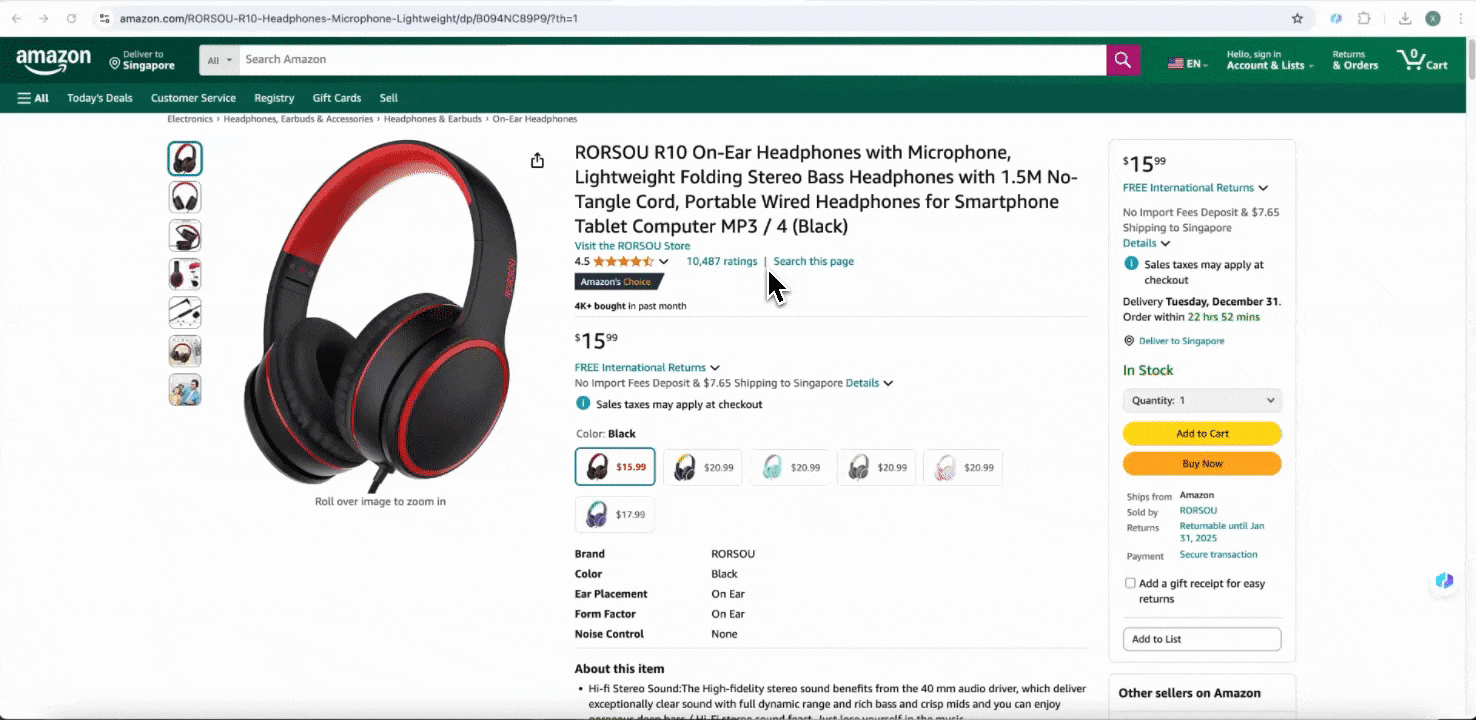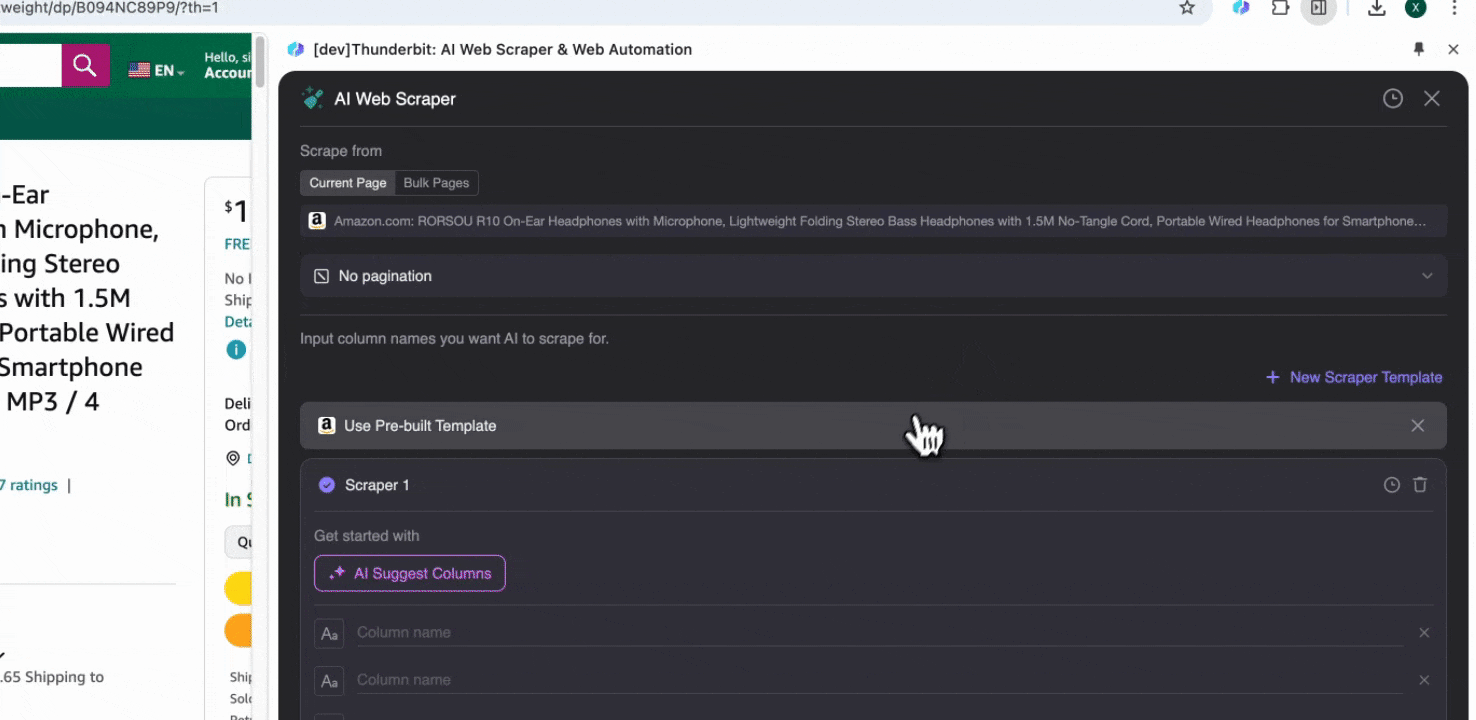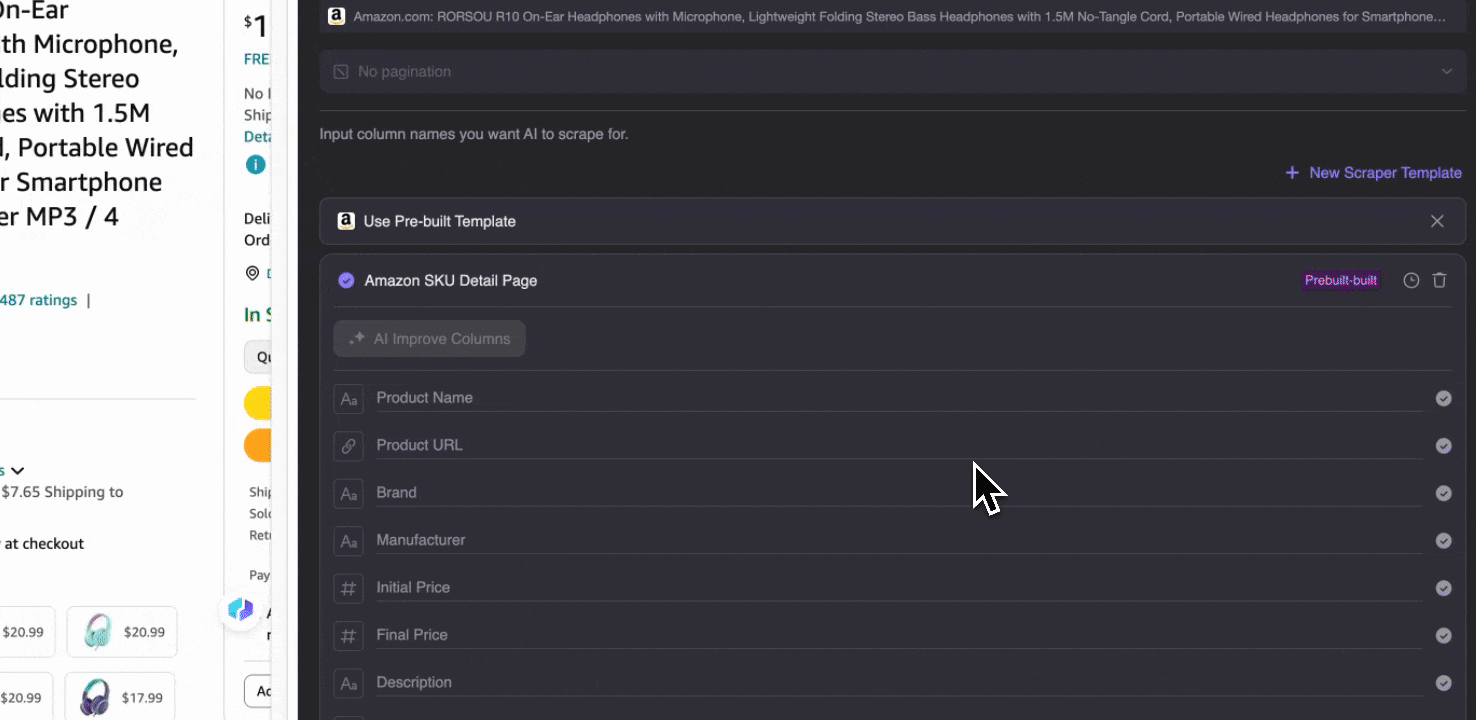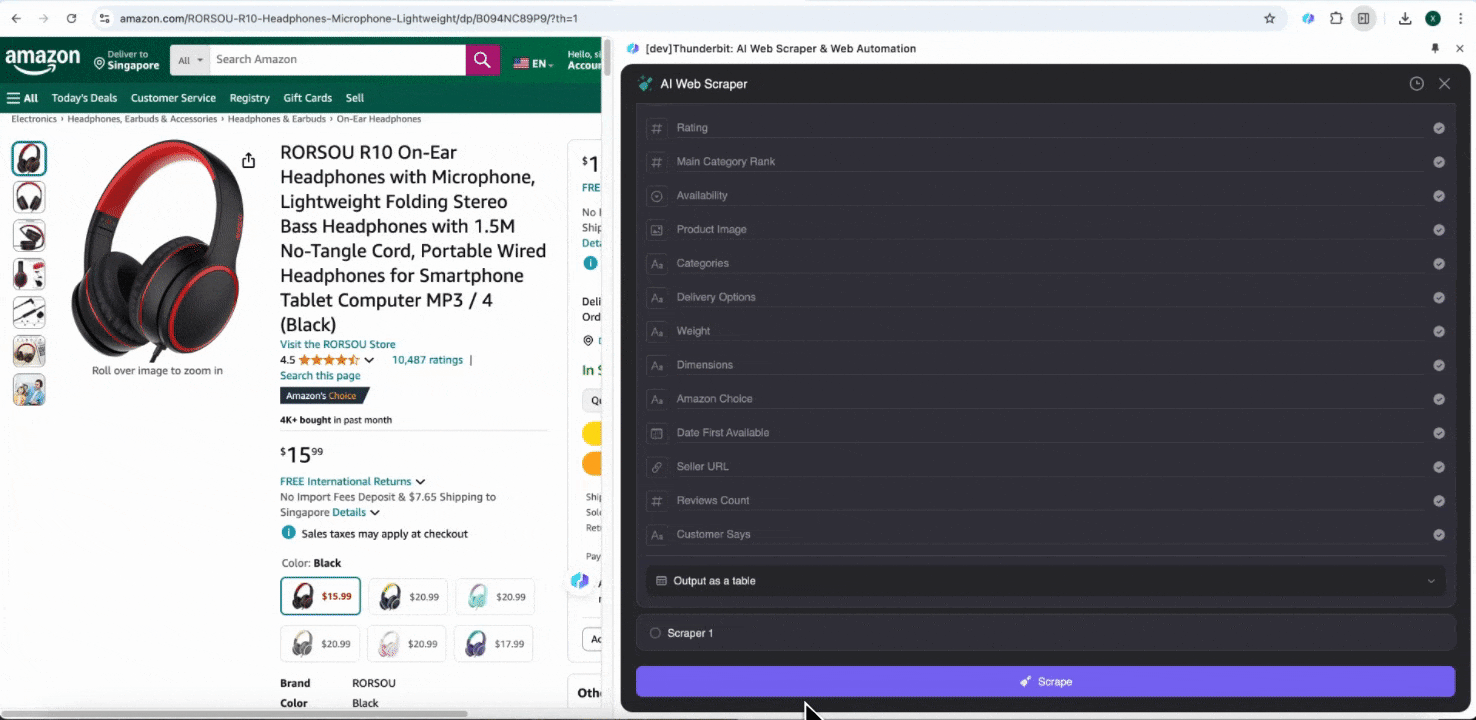
Optie 2: Gebruik Thunderbit’s AI Web Scraper
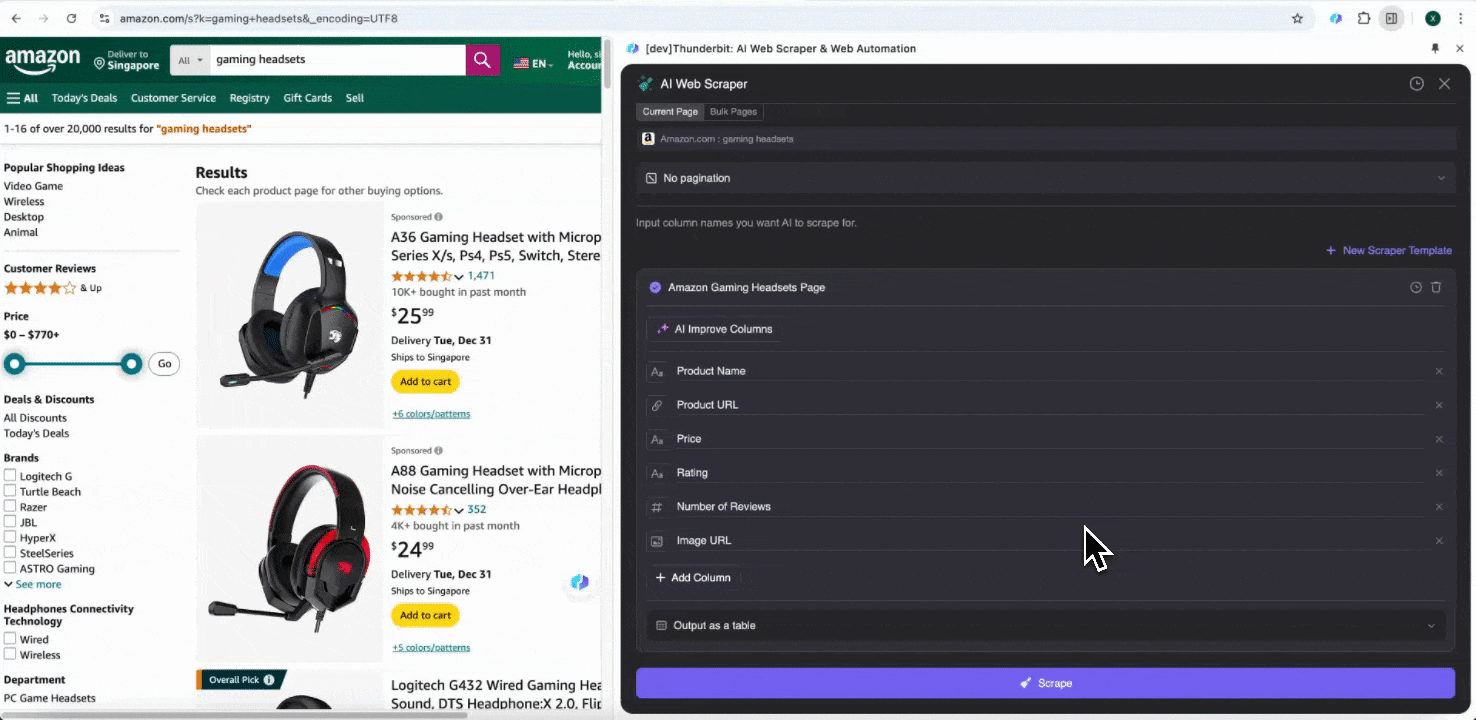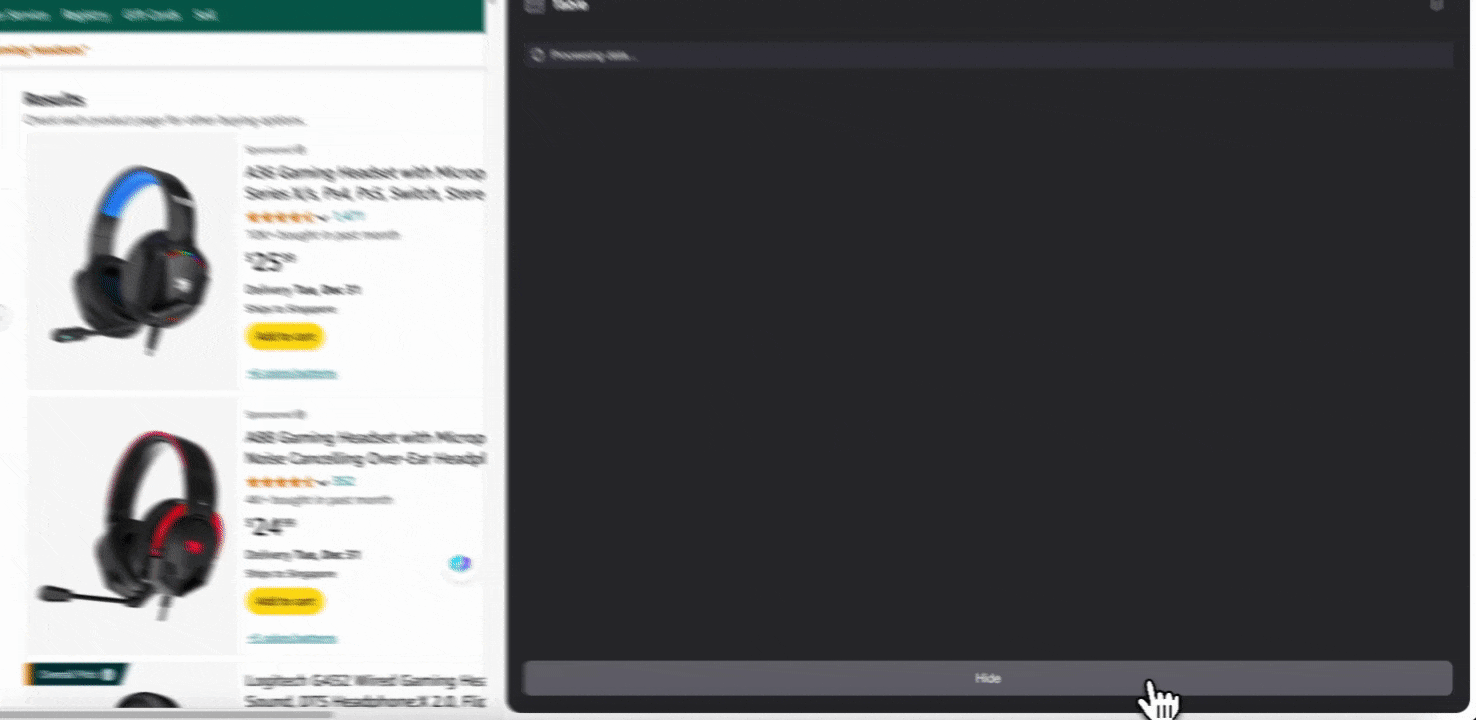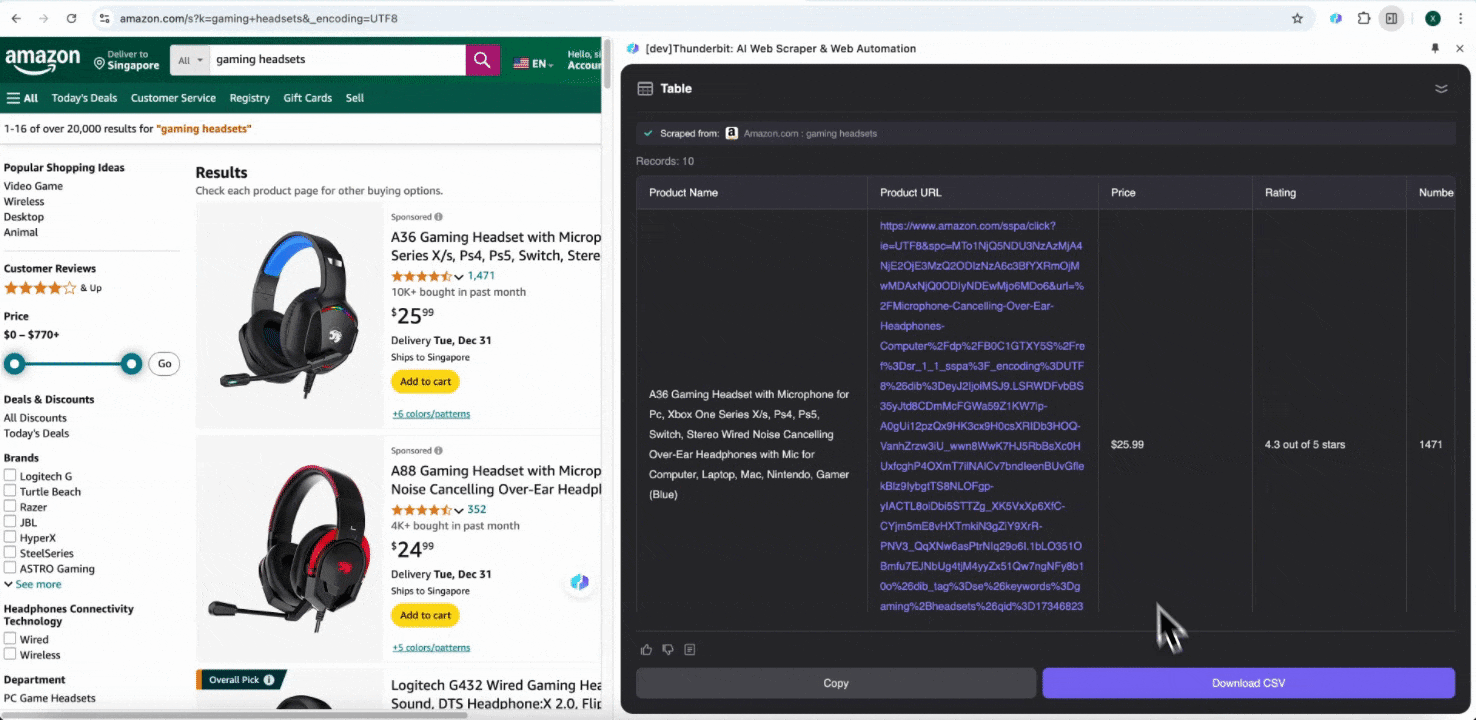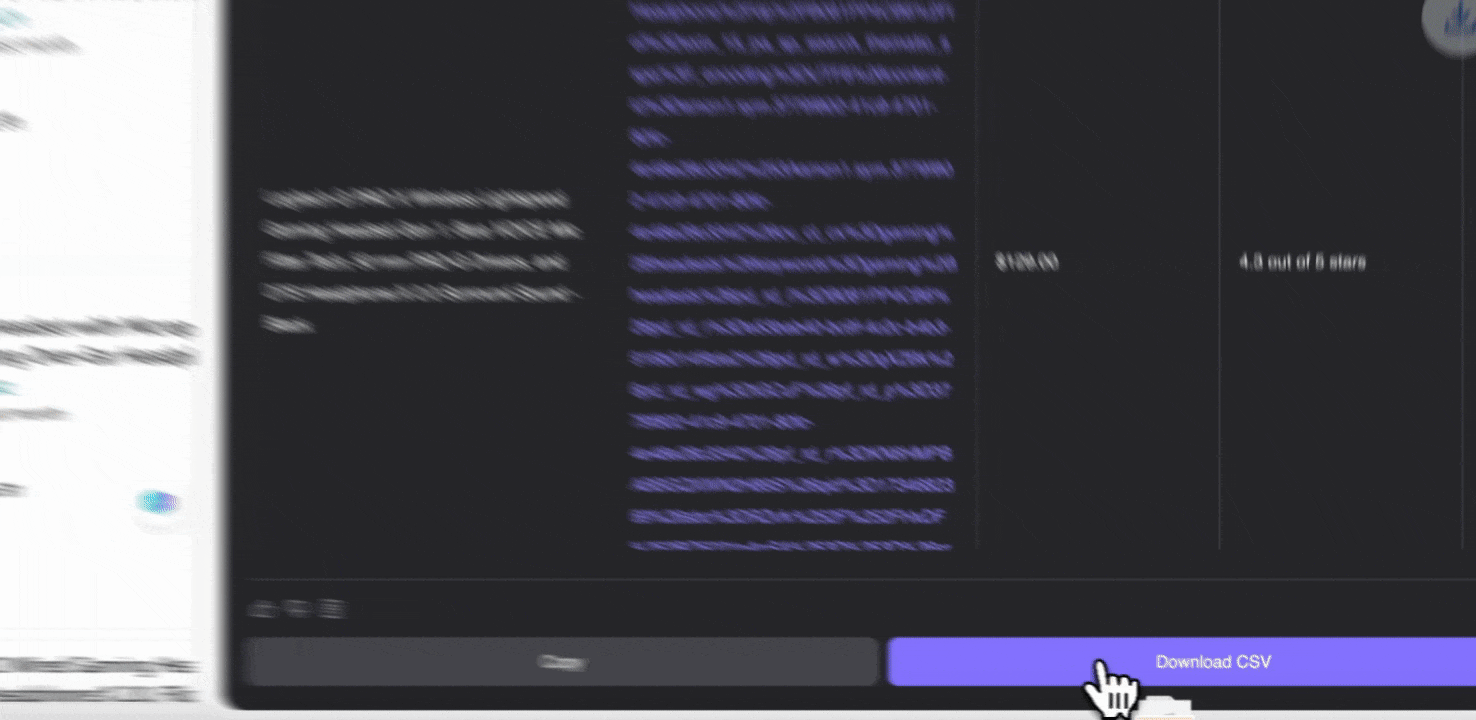
Stap 1: Open en klik op “” in de zijbalk
Open de in je Chrome-browser, zoek of navigeer naar de pagina waarvan je data wilt extraheren, klik vervolgens op het Thunderbit-icoon rechtsboven in je Chrome-browser om de Thunderbit-extensie te openen en klik op "."
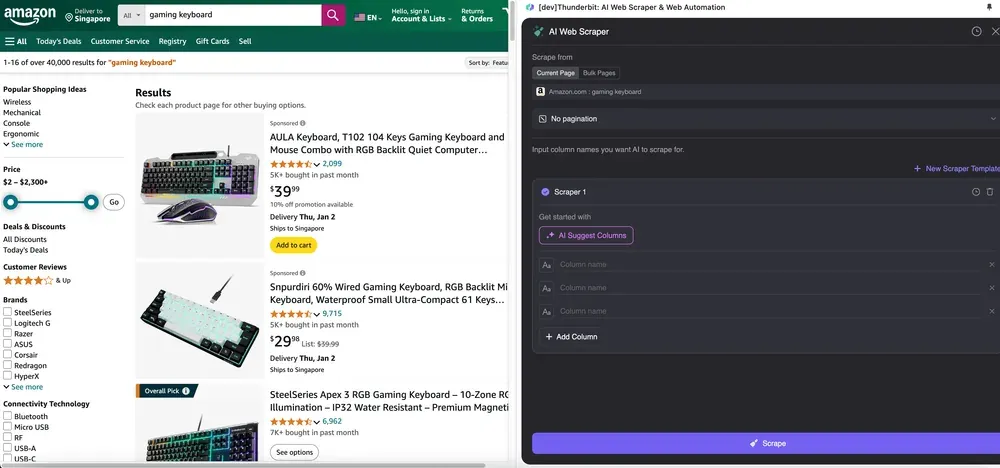
Stap 2: Pas de gegevensvelden aan die je wilt extraheren
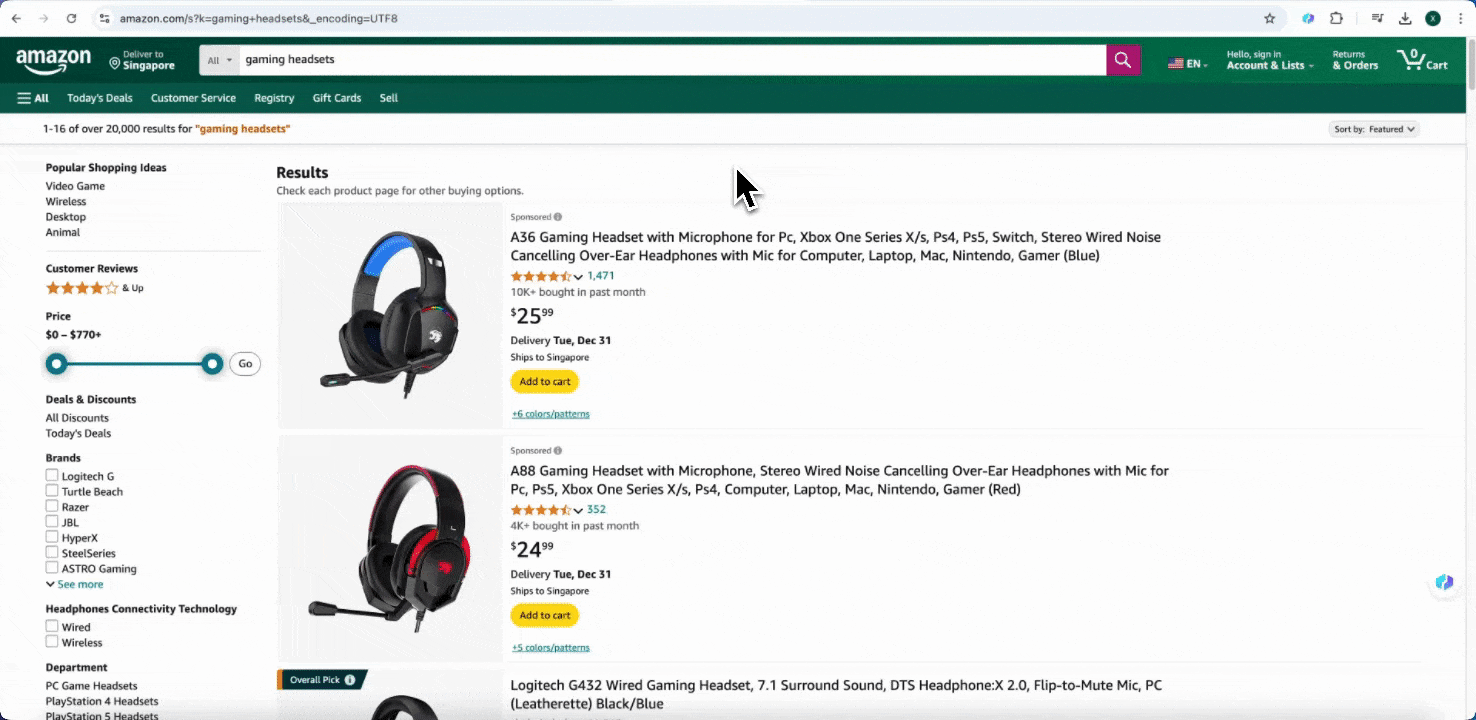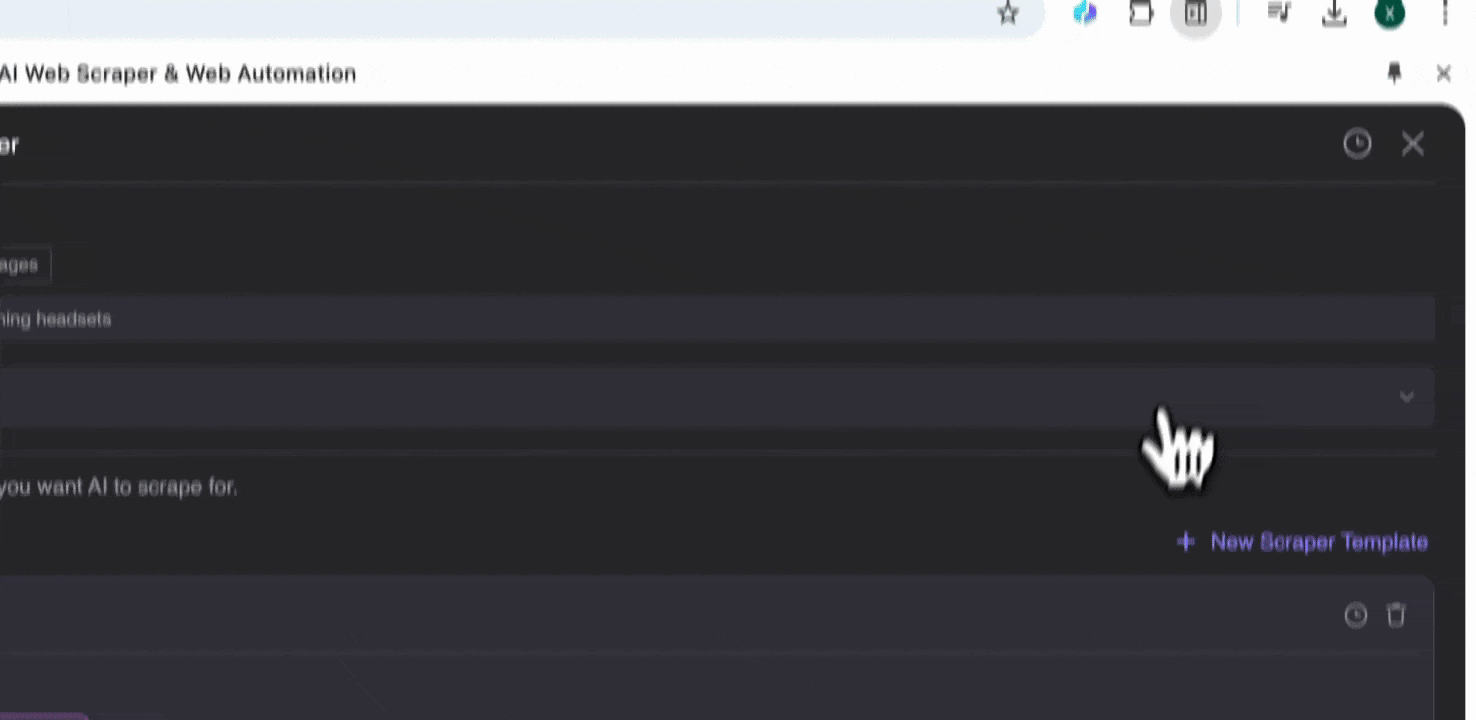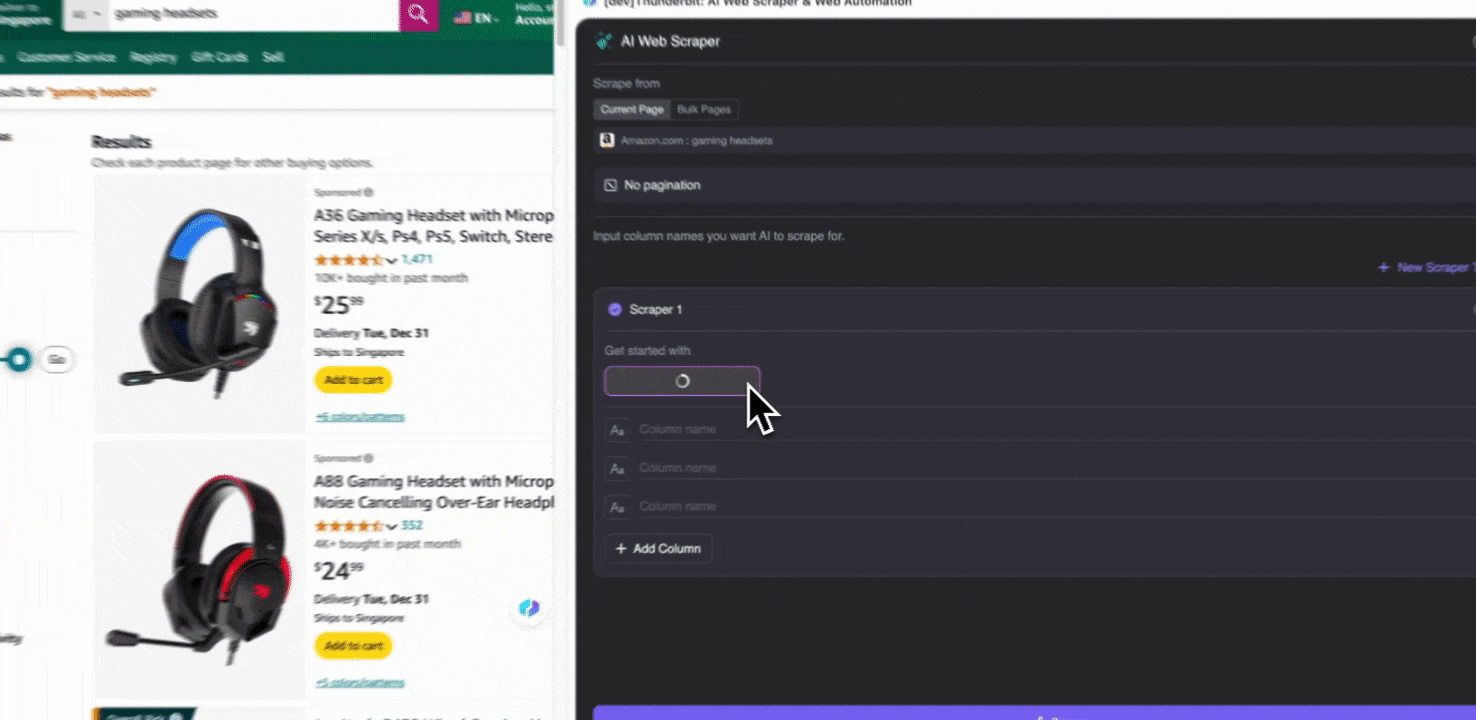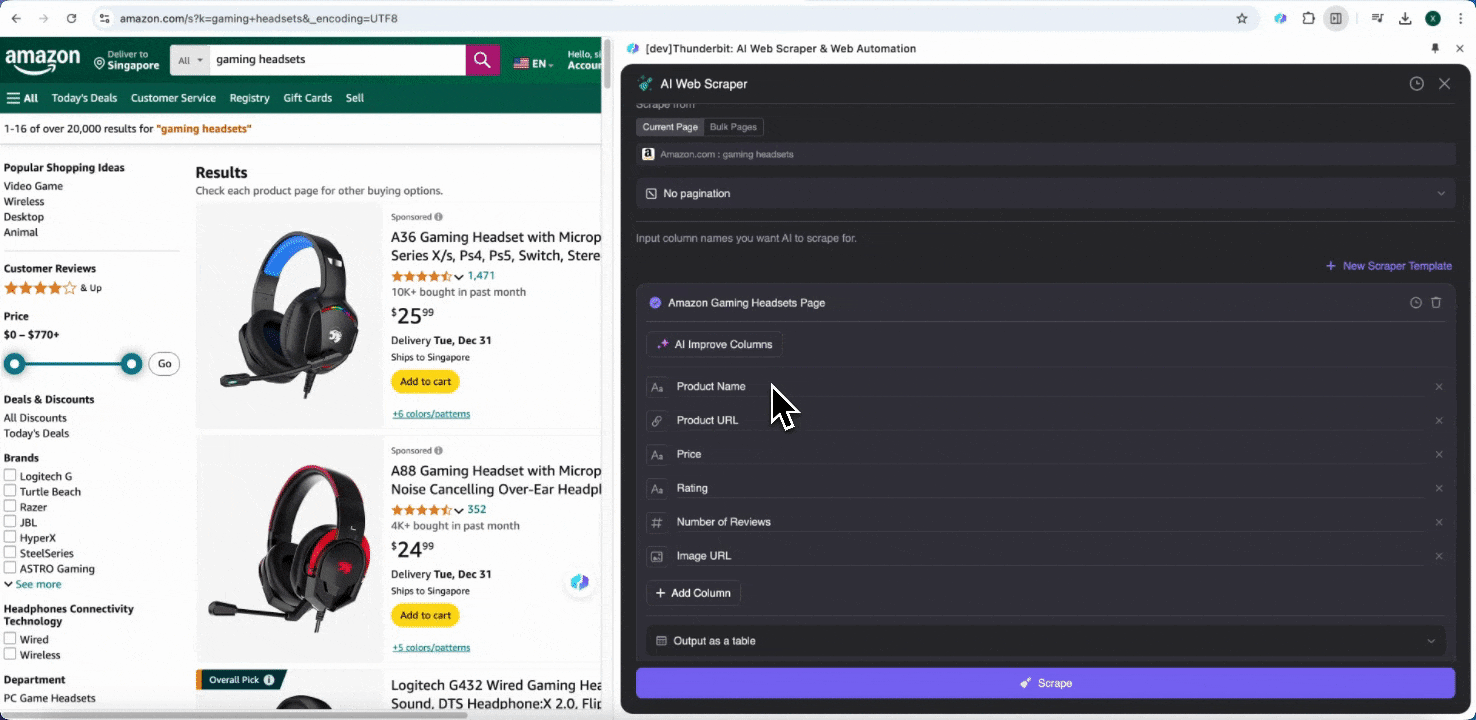
Weet je niet zeker welke datatags je nodig hebt? Klik dan op AI Suggest Columns zodat Thunderbit’s AI automatisch betrouwbare kolomnamen genereert. Je kunt ook in natuurlijke taal beschrijven welke datalabels je wilt en die invullen in het veld voor de kolomnaam. Kies pictogrammen om het gewenste gegevenstype om te schakelen, of dat nu een afbeelding, URL, tekst, getal of ander datatype is, en scrape de bijbehorende data.
Nadat je de eerste kolomnamen hebt ingevuld, kun je AI Improve Columns kiezen om AI je invoer verder te laten optimaliseren. Je kunt ook gedetailleerde kolominstructies toevoegen om je wensen verder te personaliseren. Je kunt bijvoorbeeld vragen dat de producttypekolom producten indeelt in mannen-, vrouwen-, kinder- en andere categorieën. Thunderbit zal elke data-entry in die kolom vervolgens in de vier door jou gedefinieerde categorieën indelen. Je kunt ook vragen dat Thunderbit alle prijzen in de prijskolom omzet naar de gewenste valuta tegen de actuele wisselkoers, zodat je eenvoudig de waarden krijgt die je voor analyse nodig hebt zonder je zorgen te maken over valuta-inconsistenties.
Ten slotte kun je de hoeveelheid data die je wilt aanpassen. Voor Amazon-productpagina’s kun je paginering aanklikken en het aantal pagina’s selecteren dat je wilt scrapen. Thunderbit bladert dan automatisch door de pagina’s en haalt alle data van elke pagina op.
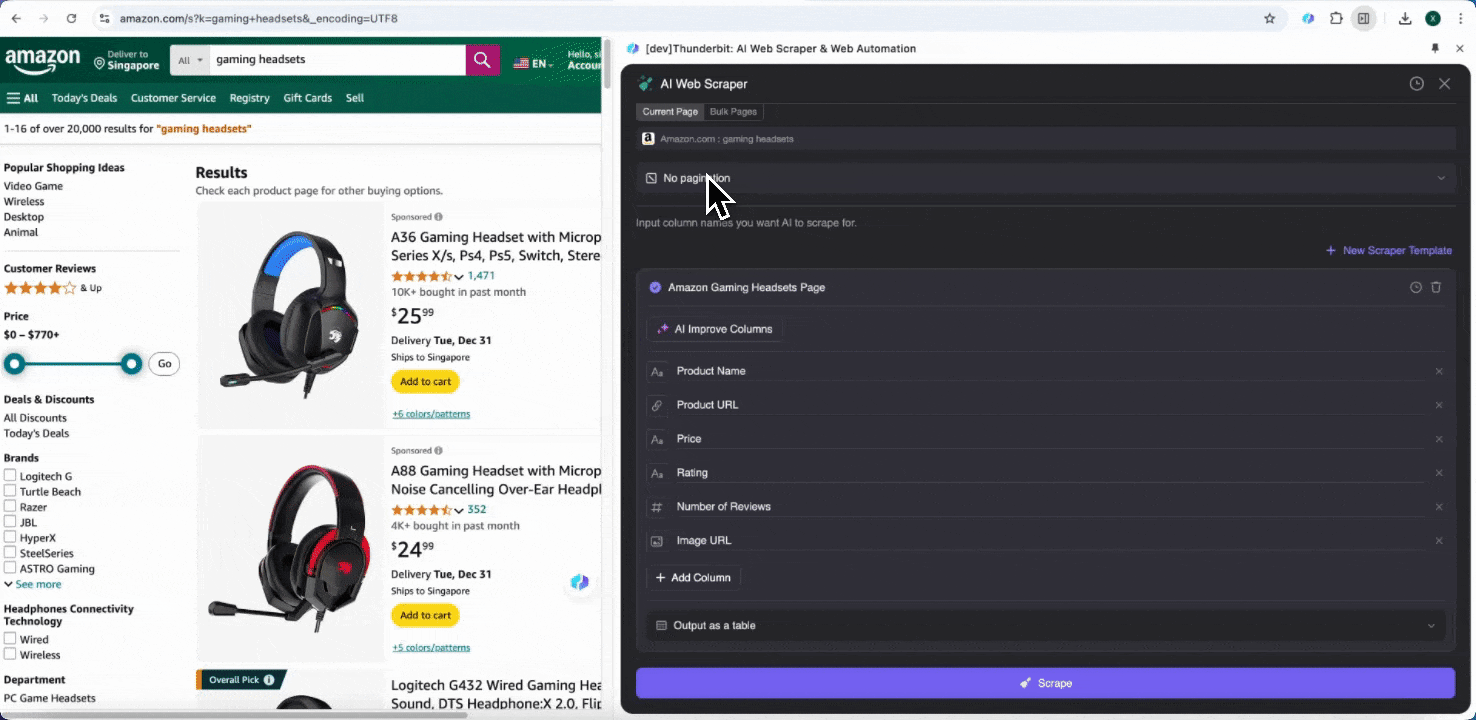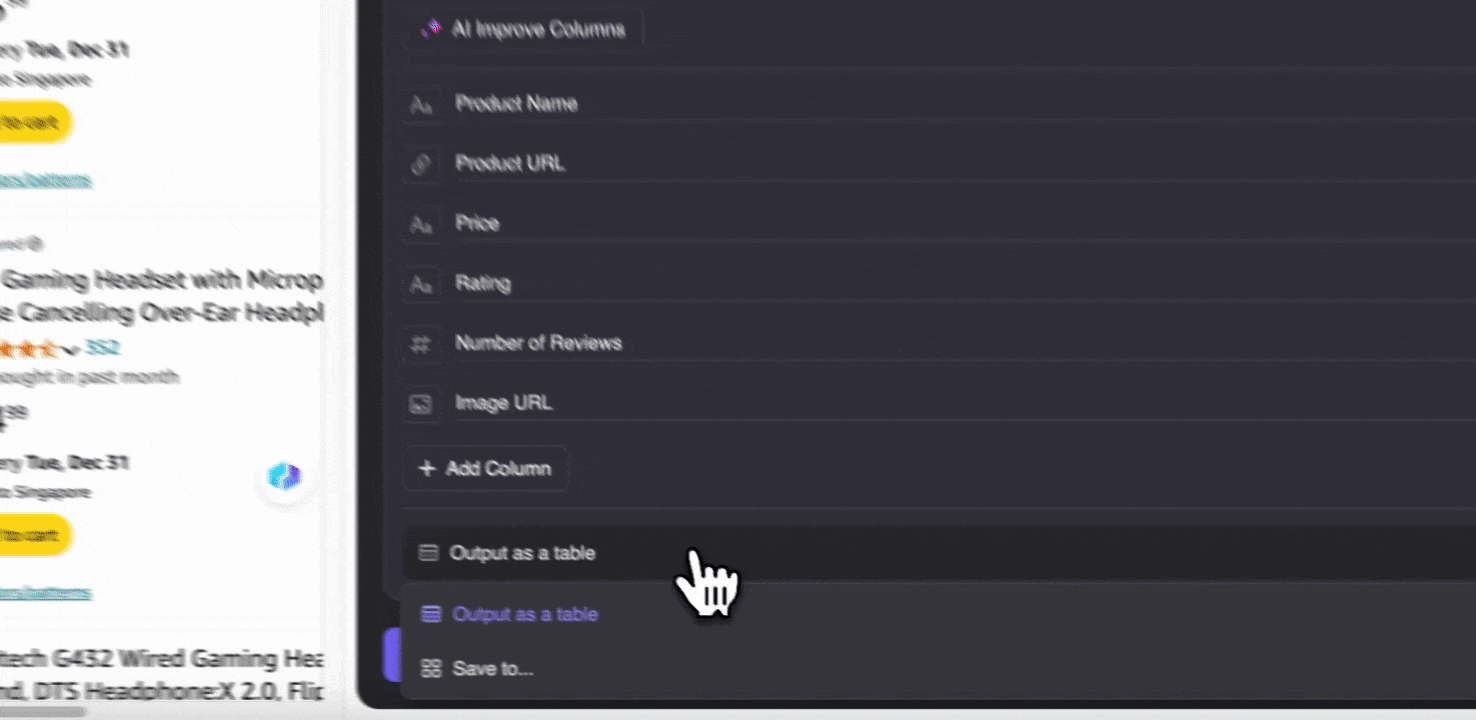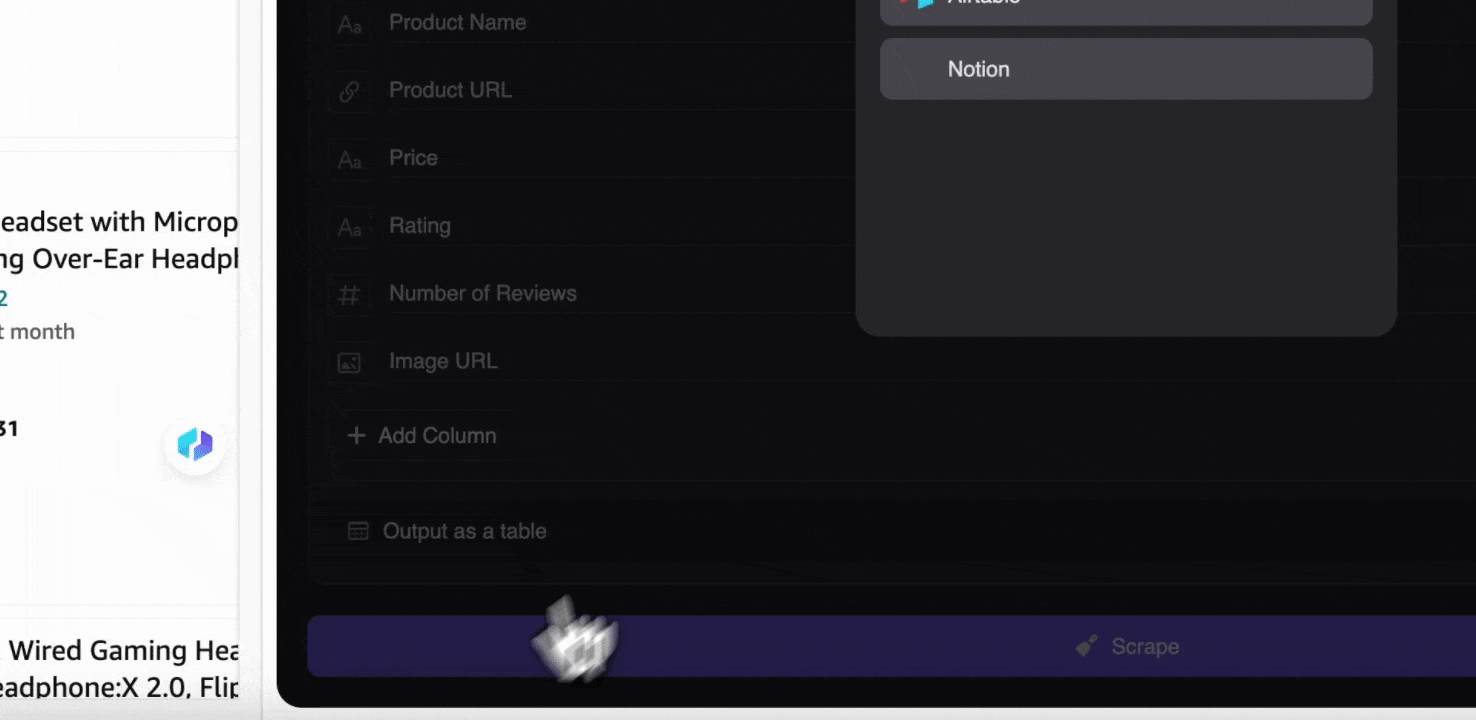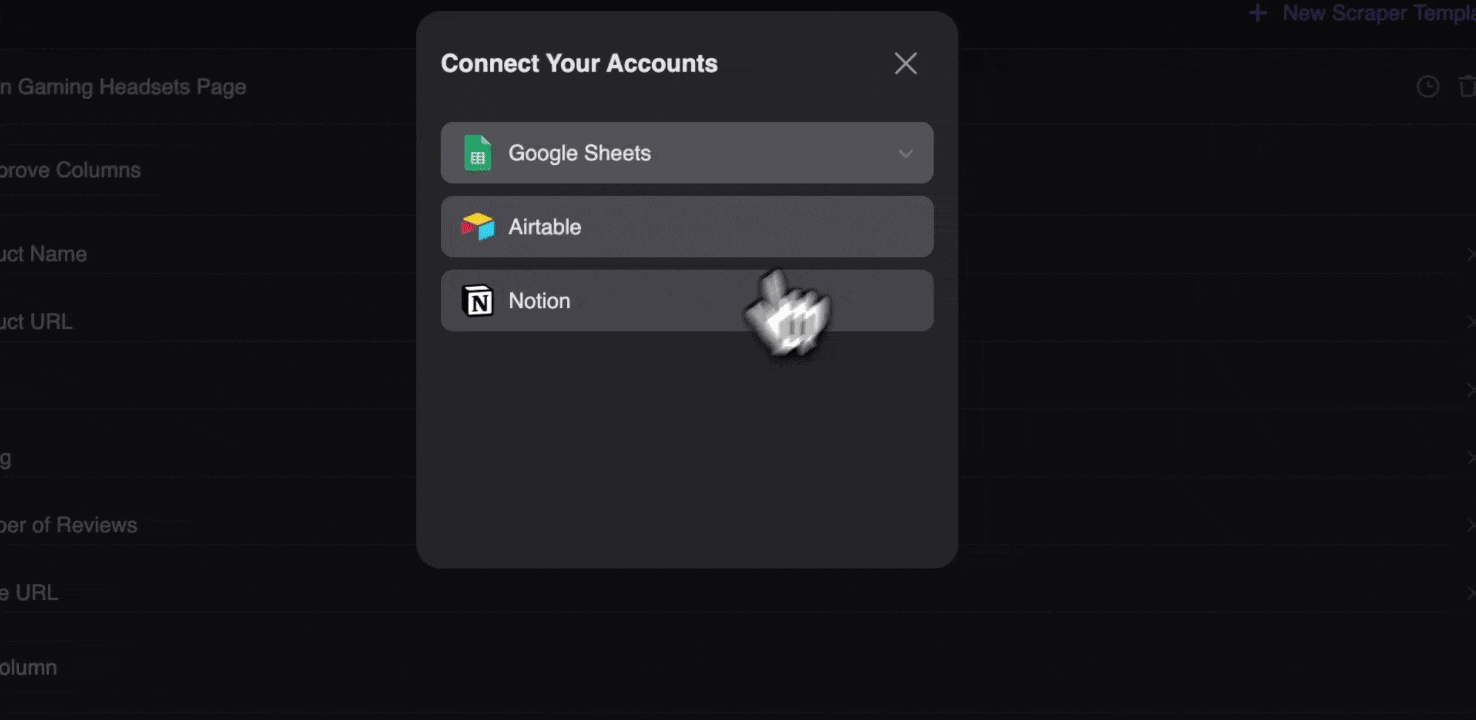
Stap 3: Download de gescrapete data of exporteer als tabel
Met de Thunderbit-webscraperextensie kun je . Kies als uitvoer een tabel, download vervolgens het CSV-bestand lokaal, of selecteer , Notion of Airtable. Log in op je account en exporteer rechtstreeks naar deze online samenwerkingsplatforms voor bestandsbeheer.
Scrapen met een traditionele webscraper
Naast de nieuwste AI-tools kun je ook traditionele webscrapertools met lichte code en API’s gebruiken om Amazon-productdata te scrapen.
: haal Amazon-productdata op in JSON-formaat met API
ScraperAPI biedt een efficiënte API voor het verzamelen van Amazon-data waarmee je productdetails, reviews, zoekresultaten en prijsinformatie van Amazon kunt scrapen en in een gestructureerd JSON-formaat terugkrijgt. Zo gebruik je de API om te scrapen.
Stap 1: Stel je Python-omgeving in
Zorg eerst dat je Python 3.8 of hoger hebt geïnstalleerd. Installeer daarna gangbare analysetools zoals Pandas en webscrapingbibliotheken zoals requests en BeautifulSoup. Deze bibliotheken helpen je eenvoudig data van webpagina’s te halen.
Stap 2: Maak een ScraperAPI-account aan
Ga naar de om een gratis account aan te maken en je API-sleutel te krijgen. Je kunt deze sleutel gebruiken om ScraperAPI in je code aan te roepen.
Stap 3: Bereid de code voor
Maak lokaal een aparte map aan en schrijf een Python-script om de data-extractie uit te voeren. Hieronder staat een basisworkflow:
- Pak de Amazon-zoek-URL: Zoek het gewenste product op Amazon en kopieer de URL van de resultatenpagina.
- Bouw requests op: ScraperAPI loopt automatisch door de eerste vijf pagina’s met zoekresultaten. De URL van elke pagina wordt opgebouwd door &page= en het betreffende paginanummer aan de basis-URL toe te voegen.
- Verzend requests en parse data: Gebruik de get()-methode om requests naar ScraperAPI te sturen. Als de request slaagt (statuscode 200), parse je de paginacontent om de gewenste ASIN (Amazon Standard Identification Number) eruit te halen.
- Haal gedetailleerde productdata op: Door het endpoint voor gestructureerde data aan te roepen, krijg je gedetailleerde productinformatie voor elke ASIN voor verdere data-analyse.
Stap 4: Raadpleeg meer tutorials
Voor meer gedetailleerde gebruiksgidsen kun je de raadplegen.
: voorkom blokkeringen en scrape op schaal
Bij het scrapen van Amazon-data zorgen anti-scrapingtechnieken zoals IP-blokkering, CAPTCHA’s en dynamische content vaak voor uitdagingen voor ontwikkelaars van scrapers. ScrapFly biedt een krachtige API om deze anti-scrapingmechanismen te omzeilen en soepele data-extractie mogelijk te maken.
De kernfuncties van ScrapFly zijn onder andere:
- : automatisch van IP-adres wisselen om IP-blokkering te voorkomen.
- : omgaan met dynamische content en JavaScript-gerenderde webpagina’s scrapen.
- : browsers aansturen om te scrollen, invoeren te doen en op elementen te klikken.
- : scrapen als HTML, JSON, tekst of Markdown.
Met slechts een paar regels code kun je ScrapFly gebruiken om Amazon-data te scrapen. Hier is een eenvoudig voorbeeld:
1import scrapfly_sdk
2# Maak een client aan
3client = scrapfly_sdk.ScraperClient(api_key="your_api_key")
4# Verstuur een request
5response = client.scrape(url="<https://www.amazon.com/s?k=product_name>")
6# Haal de teruggegeven data op
7print(response.json())Door ScrapFly te gebruiken kan je scraper verschillende anti-scrapingmechanismen van Amazon aan, waardoor de slagingskans van dataverzameling toeneemt. Of het nu gaat om eenvoudige extractie van productinformatie of complexe reviewanalyse, ScrapFly is een zeer praktische tool. Raadpleeg voor meer gedetailleerde gebruiksgidsen .
Scrapen met Python: traditionele codeermethoden
Voor technisch onderlegde mensen die vertrouwd zijn met coderen, kun je ook proberen Python-code te schrijven om Amazon-productdata te scrapen. Hieronder staat een eenvoudig voorbeeld als referentie.
Stap 1: Zet de basis klaar
Maak eerst een aparte map voor je project.
1mkdir amazonscraperInstalleer daarna de nodige bibliotheken in deze map.
1pip install beautifulsoup4
2pip install requestsMaak nu een Python-bestand aan met een naam naar keuze. Dit wordt het hoofdbestand waarin we onze code bewaren. Ik noem het amazon.py.
Stap 2: Doe een GET-request naar de doelsite
Laten we met de requests-bibliotheek een GET-request naar onze doelpagina doen.
1import requests
2from bs4 import BeautifulSoup
3target_url = "<https://www.amazon.com/s?k=gaming+headsets&_encoding=UTF8>"
4headers = {
5 "accept-language": "en-US,en;q=0.9",
6 "accept-encoding": "gzip, deflate, br",
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"
9}
10response = requests.get(target_url, headers=headers)Stap 3: Scrape Amazon-productdata
Nu moeten we bepalen wat we van de willen extraheren.
1# Controleer of het request succesvol was
2if response.status_code == 200:
3 # Parse de paginacontent
4 soup = BeautifulSoup(response.content, 'html.parser')
5 # Zoek alle productvermeldingen
6 products = soup.find_all('div', {'data-component-type': 's-search-result'})
7 # Loop door elk product en haal details op
8 for product in products:
9 # Haal producttitel op
10 title = product.h2.text.strip()
11 # Haal productprijs op
12 price = product.find('span', 'a-price')
13 if price:
14 price = price.find('span', 'a-offscreen').text.strip()
15 else:
16 price = "Prijs niet beschikbaar"
17 # Haal productbeoordeling op
18 rating = product.find('span', 'a-icon-alt')
19 if rating:
20 rating = rating.text.strip()
21 else:
22 rating = "Beoordeling niet beschikbaar"
23 # Print productdetails
24 print(f"Titel: \{title\}")
25 print(f"Prijs: \{price\}")
26 print(f"Beoordeling: \{rating\}")
27 print("-" * 40)
28else:
29 print(f"Kan de pagina niet ophalen. Statuscode: \{response.status_code\}")Veelgestelde vragen
1. Is het legaal om te scrapen?
Ja, het scrapen van openbare data op Amazon is legaal! Net als veel andere websites maakt Amazon zijn productvermeldingen en andere openbare informatie beschikbaar voor iedereen die wil browsen. Je kunt die vrij beschikbare data scrapen en verzamelen zonder de gebruiksvoorwaarden van Amazon te schenden.
2. Kan ik Thunderbit gratis uitproberen?
Ja, Thunderbit biedt gratis pagina-extractie en data-extractiefuncties. Hoewel sommige geavanceerde functies betaling kunnen vereisen, zijn de basisfuncties voor data-extractie .
3. Welke data kan ik van Amazon scrapen?
Je kunt allerlei data van Amazon scrapen, waaronder producttitels, prijzen, beschrijvingen, reviews, ratings en verkopersinformatie. Deze data kan waardevol zijn voor marktonderzoek, prijsmonitoring en concurrentieanalyse.
4. Hoe vaak moet ik Amazon-data scrapen?
De frequentie hangt af van het type data dat je zoekt. Als je prijzen of activiteiten van concurrenten volgt, wil je misschien dagelijks of wekelijks scrapen. Voor meer statische informatie, zoals productdetails, kan maandelijks scrapen voldoende zijn.
Meer lezen