

Mijn OpenRouter-dashboard liet op een dinsdag vóór de lunch al $47 aan kosten zien. Ik had misschien een dozijn codingtaken gedraaid — niets extreems, gewoon wat refactoring en een paar bugfixes. Toen viel het kwartje: OpenClaw stuurde standaard elk interactiemoment, inclusief achtergrondmatige heartbeat-pings, via Claude Opus van $15+ per miljoen tokens.
Als je zulke verrassingen kent — en afgaand op de forums zijn er genoeg mensen die dat meemaken ("Ik heb al 40 dollar uitgegeven en gebruik het nauwelijks," schreef een gebruiker) — dan laat deze gids zien hoe ik met een volledige audit en optimalisatie mijn maandelijkse kosten met ongeveer 90% heb teruggebracht. Niet alleen "schakel over naar een goedkoper model", maar een systematische analyse van waar tokens echt naartoe gaan, hoe je ze monitort, welke budgetmodellen in de praktijk overeind blijven voor agentisch werk, en drie kant-en-klare configuraties die je vandaag nog kunt plakken. Het hele proces kostte me een middag.
Wat is OpenClaw-tokenverbruik eigenlijk (en waarom staat het standaard zo hoog)?
Tokens zijn de rekeneenheid voor elke AI-interactie in OpenClaw. Zie ze als kleine stukjes tekst — grofweg 4 Engelse karakters per token. Elk bericht dat je stuurt, elk antwoord dat je ontvangt, elk achtergrondproces dat afgaat: alles wordt in tokens afgerekend.
Het probleem is dat de standaardinstellingen van OpenClaw zijn afgestemd op maximale prestaties, niet op minimale kosten. Standaard staat het primaire model op anthropic/claude-opus-4-5 — de duurste optie die er is. Heartbeat-pings? Die draaien ook op Opus. Sub-agents die worden opgestart voor neventaken? Ook Opus. Opus gebruiken voor een heartbeat-ping is alsof je een neurochirurg betaalt om een pleister op te plakken. Technisch kan het, maar het is absurd duur.
Veel gebruikers beseffen niet dat ze premiumtarieven betalen voor triviale achtergrondtaken. De standaardconfiguratie gaat er in feite van uit dat je altijd, voor alles, het beste model wilt — en rekent daar ook naar.
Waarom OpenClaw-tokenverbruik terugdringen meer oplevert dan alleen geld besparen
Het meest voor de hand liggende voordeel is lagere kosten. Maar er zijn ook secundaire voordelen die zich op de lange termijn opstapelen.
Goedkopere modellen zijn vaak ook sneller. Gemini 2.5 Flash-Lite draait ongeveer 214 tokens per seconde tegenover Opus rond de 51 — dat is 4x sneller bij elke interactie. GPT-OSS-120B op Cerebras haalt 1.917 tokens per seconde, grofweg 35x sneller dan Opus. In een agentische loop met 50+ tool-calling-stappen betekent dat verschil minuten in plaats van eindeloos wachten op Opus’ pijnlijke time-to-first-token van 13,6 seconden per ronde.
Je krijgt ook meer marge voordat je tegen rate limits aanloopt, minder afgeknepen sessies, en ruimte om op te schalen zonder dat je portemonnee meteen begint te stressen.
Geschatte besparingen per type gebruiker:
| Gebruikersprofiel | Geschatte maandkosten (standaard) | Na volledige optimalisatie | Maandelijkse besparing |
|---|---|---|---|
| Licht (~10 queries/dag) | ~$100 | ~$12 | ~88% |
| Gemiddeld (~50 queries/dag) | ~$500 | ~$90 | ~82% |
| Intensief (~200+ queries/dag) | ~$1.750 | ~$220 | ~87% |
Dit zijn geen hypothetische cijfers. Eén ontwikkelaar documenteerde dat hij van $600–750/maand naar $3–4/dag ging — een echte besparing van 90% — door modelrouting te combineren met de verborgen kostenlekken die later in deze gids aan bod komen.
OpenClaw-tokenverbruik ontleed: waar elke token echt naartoe gaat
Dit is het deel dat de meeste optimalisatiegidsen overslaan, terwijl het juist het belangrijkst is. Je kunt niets oplossen wat je niet ziet.
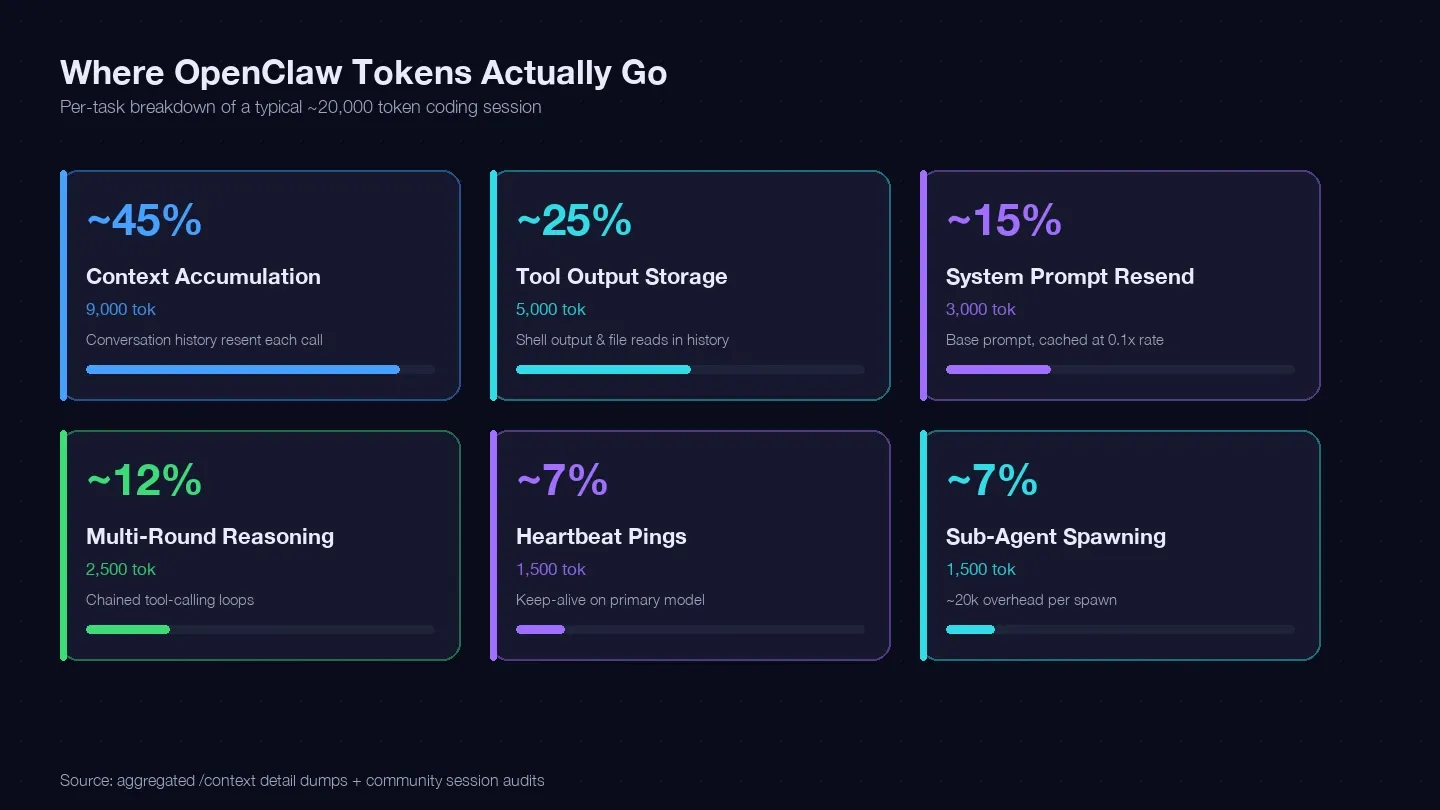
Ik heb meerdere sessies doorgelicht en vergeleken met de LaoZhang cost optimization guide en community /context-dumps om een tokenoverzicht te maken voor een typische losse codingtaak. Ongeveer 20.000 tokens gingen hieraan op:
| Tokencategorie | Typisch % van totaal | Voorbeeld (1 codingtaak) | Kun je dit sturen? |
|---|---|---|---|
| Contextopbouw (gespreksgeschiedenis wordt bij elke call opnieuw meegestuurd) | ~40–50% | ~9.000 tokens | Ja — /clear, /compact, kortere sessies |
| Tool-output-opslag (shell-output, bestandsreads die in de geschiedenis blijven staan) | ~20–30% | ~5.000 tokens | Ja — kleinere reads, beperk toolscope |
| System prompt opnieuw versturen (~15K basis) | ~10–15% | ~3.000 tokens | Gedeeltelijk — cache reads tegen 0,1x tarief |
| Meerronde redenering (gekoppelde tool-calling loops) | ~10–15% | ~2.500 tokens | Modelkeuze + betere prompts |
| Heartbeat / keep-alive pings | ~5–10% | ~1.500 tokens | Ja — configuratiewijziging |
| Sub-agent calls | ~5–10% | ~1.500 tokens | Ja — modelrouting |
De grootste post — contextopbouw — is je gespreksgeschiedenis die bij elke API-call opnieuw wordt meegestuurd. Eén echte sessiedump liet alleen al in de Messages-bucket 185.400 tokens zien, nog voordat het model überhaupt had geantwoord. De system prompt en tools voegden daar nog eens ~35.800 tokens aan vaste overhead aan toe.
De conclusie: als je sessies niet afsluit tussen losstaande taken, betaal je op elke beurt opnieuw om je volledige geschiedenis te versturen.
Hoe je OpenClaw-tokenverbruik monitort (je kunt niets verlagen wat je niet ziet)
Voordat je iets verandert, moet je inzicht krijgen in waar je tokens heen gaan. Meteen overstappen op "een goedkoper model" zonder monitoring is alsof je wilt afvallen zonder ooit op de weegschaal te gaan staan.
Check je OpenRouter-dashboard
Als je via OpenRouter routeert, is de Activity-pagina de makkelijkste dashboardoplossing zonder installatie. Je kunt filteren op model, provider, API-key en periode. In de Usage Accounting-weergave zie je prompt-, completion-, reasoning- en cached tokens per request uitgesplitst. Er is ook een Export-knop (CSV of PDF) voor analyses over een langere periode.
Waar je op moet letten: welk model de meeste tokens verbruikt, en of heartbeat- of sub-agent requests onverwacht grote kostenposten zijn.
Controleer je lokale API-logs
OpenClaw bewaart sessiedata in ~/.openclaw/agents.main/sessions/sessions.json, inclusief totalTokens per sessie. Je kunt ook openclaw logs --follow --json gebruiken voor realtime logging per request.
Eén belangrijke nuance: sessions.json totalTokens wordt niet bijgewerkt na compaction, dus het dashboard kan verouderde waarden van vóór de compaction tonen. Vertrouw op /status en /context detail boven de opgeslagen totalen.
Gebruik tracking van derden (voor gemiddelde tot intensieve gebruikers)
LiteLLM proxy geeft je een OpenAI-compatibele endpoint voor meer dan 100 providers en registreert automatisch de kosten per virtuele key, model, gebruiker en team. De sterkste functie: harde budgetten per key die ook na /clear blijven gelden — een ontspoorde sub-agent kan dus niet door een door jou ingestelde limiet heen schieten.
Helicone is nog eenvoudiger — een eenregelige base-URL-wissel waarmee je een Sessions-weergave krijgt die verwante requests bundelt. Eén prompt als “los deze bug op” die uitwaaiert naar 8+ sub-agent calls verschijnt dan als één sessieregel met de echte totaalkosten. Gratis tier: 10.000 requests/maand.
Snelle checks binnen OpenClaw
Voor dagelijkse controle doen deze vier in-sessie commando’s het werk:
/status— toont contextgebruik, laatste input/output-tokens en geschatte kosten/usage full— gebruiksfooter per response/context detail— tokenverdeling per bestand, skill en tool/compact [guidance]— forceert compaction met optionele focuszin
Draai /context detail vóór en na configuratiewijzigingen. Zo meet je of je optimalisaties echt effect hebben gehad.
De showdown van de goedkoopste OpenClaw-modellen: welke budget-LLM’s kunnen agentisch werk echt aan?
Hier gaat het in de meeste gidsen mis. Ze tonen een prijstabel, wijzen naar de goedkoopste rij en noemen het een dag. Benchmarks voorspellen echter niet hoe een model zich in echte agentische workflows gedraagt — iets wat de community luid en herhaaldelijk heeft aangegeven. Zoals een gebruiker het formuleerde: "benchmarks zijn niet genoeg om te begrijpen welke het beste werkt voor agentic AI."
De cruciale les: het goedkoopste model is niet altijd de goedkoopste uitkomst. Een model dat faalt en vier keer moet herkansen, kost meer dan een middenklassemodel dat in één keer slaagt. In productie-agenten moet je rekenen op een retry-rate van 5–10% — en als vijf LLM-calls aan elkaar zijn gekoppeld en stap vier faalt, dan wordt bij een naïeve retry gewoon het hele vijftal opnieuw uitgevoerd.
Hier is mijn capaciteitsmatrix, met een "Real Agentic Score" op basis van echte gebruikerservaringen in plaats van synthetische benchmarks:
| Model | Input $/1M | Output $/1M | Betrouwbaarheid bij tool-calls | Meertraps redenering | Real Agentic Score (1–5) | Beste inzet |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0,10 | $0,40 | Gemengd — soms loops | Basis | ⭐2,5 | Heartbeats, simpele lookups |
| GPT-OSS-120B | $0,04 | $0,19 | Voldoende | Voldoende | ⭐3,0 | Budget-experimenten, snelheid-kritische taken |
| DeepSeek V3.2 | $0,26 | $0,38 | Inconsistent (6 open issues) | Goed | ⭐3,0 | Zwaar redeneerwerk, minimale tool-calls |
| Kimi K2.5 | $0,38 | $1,72 | Goed (via :exacto) | Voldoende | ⭐3,5 | Simpele tot middelzware coding |
| MiniMax M2.5 / M2.7 | $0,28 | $1,10 | Goed | Goed | ⭐4,0 | Algemene coding-dagelijkse driver |
| Claude Haiku 4.5 | $1,00 | $5,00 | Uitstekend | Goed | ⭐4,5 | Betrouwbare middenklasse fallback |
| Claude Sonnet 4.6 | $3,00 | $15,00 | Uitstekend | Uitstekend | ⭐5,0 | Complexe meerstaps taken |
| Claude Opus 4.5/4.6 | $5,00 | $15,00 | Uitstekend | Uitstekend | ⭐5,0 | Alleen reserveren voor de moeilijkste problemen |
Een waarschuwing over DeepSeek en Gemini Flash voor tool-calling
DeepSeek V3.2 ziet er op papier geweldig uit — 72–74% op SWE-Bench, 11–36x goedkoper dan Sonnet. In de praktijk documenteren zes aparte GitHub-issues in Cline, Roo Code, Continue en NVIDIA NIM kapot tool-calling-gedrag. De kop-aan-kopconclusie van Composio: "DeepSeek V3.2 bouwde delen van de app, maar struikelde over uitvoering, snelheid en betrouwbaarheid." Zvi Mowshowitz vat het samen als: "oké en goedkoop, maar."
Gemini 2.5 Flash heeft een vergelijkbare kloof. Een Google AI Developers Forum-draad met de titel "Very frustrating experience with Gemini 2.5 function calling performance" begint met: "het function-calling-gedrag van Gemini-modellen is volledig onbetrouwbaar en onvoorspelbaar geworden."
OpenRouter wijst op een belangrijk detail: "de neiging van een model om tools aan te roepen en de nauwkeurigheid van die calls kan dramatisch verschillen tussen hosts met dezelfde weights." Als je goedkope modellen via OpenRouter routeert, let dan op de :exacto-tag — een stille providerwissel kan een betrouwbaar goedkoop model van de ene op de andere dag veranderen in een dure retry-loop.
Wanneer gebruik je welk model?
- Gemini Flash-Lite: Heartbeats, keep-alive pings, simpele Q&A. Nooit voor meerstaps tool-calling.
- MiniMax M2.5/M2.7: Je dagelijkse keuze voor algemene codingtaken. SWE-Pro 56,22, Terminal-Bench 2 57,0% voor een fractie van de prijs van Sonnet.
- Claude Haiku 4.5: De betrouwbare fallback wanneer goedkope modellen struikelen over tool-calls. Uitstekende betrouwbaarheid bij tool-calling voor ongeveer 3x lagere kosten dan Sonnet.
- Claude Sonnet 4.6: Complexe meerstaps agentische taken. Hier krijg je waar voor je geld.
- Claude Opus: Bewaar deze voor de moeilijkste problemen. Laat het nooit je standaard worden.
(Prijzen veranderen vaak — check altijd de actuele tarieven op OpenRouter of rechtstreeks bij de provider voordat je een configuratie vastlegt.)
De verborgen tokenlekken die de meeste gidsen overslaan
Forumgebruikers melden dat het uitschakelen van specifieke functies de kosten enorm verlaagt, maar geen enkele gids die ik vond biedt één gezamenlijke checklist van alle verborgen lekken met hun werkelijke tokenimpact. Hier is de volledige ontleding:
| Verborgen lek | Tokenkost per gebeurtenis | Hoe los je het op | Configuratiesleutel |
|---|---|---|---|
| Standaard heartbeat op Opus | ~100.000 tokens/run zonder isolatie | Haiku-override + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Opstarten van sub-agents | ~20.000 tokens per spawn nog vóór het werk begint | Routeer sub-agents naar Haiku | subagents.model |
| Volledige codebase-context laden | ~3.000–15.000 tokens per auto-explore | .clawignore voor node_modules, dist, lockfiles | .clawrules + .clawignore |
| Automatische geheugen-samenvatting | ~500–2.000 tokens/sessie | Uitschakelen of minder vaak laten draaien | memory: false of memory.max_context_tokens |
| Ophaopbouw van gespreksgeschiedenis | ~500+ tokens/turn (cumulatief) | Start nieuwe sessies tussen losstaande taken | /clear-discipline |
| MCP server tool-overhead | ~7.000 tokens voor 4 servers; 50.000+ voor 5+ | Houd MCP minimaal | Verwijder ongebruikte MCP’s |
| Skill/plugin-initialisatie | 200–1.000 tokens per geladen skill | Schakel ongebruikte skills uit | skills.entries.<name>.enabled: false |
| Agent Teams (plan mode) | ~7x de standaard sessiekosten | Alleen gebruiken voor écht parallel werk | Geef voorkeur aan sequentieel |
De heartbeat-kost verdient een eigen vermelding. Standaard lopen heartbeats elke 30 minuten op het primaire model (Opus). Door isolatedSession: true in te stellen daalt dat van ongeveer 100.000 tokens per run naar 2.000–5.000 tokens — een reductie van 95–98% op die ene post.
Drie snelle winstpunten waarmee je in minder dan twee minuten de meeste tokens bespaart
Alle drie zijn risicoloos en kosten minder dan twee minuten:
-
/cleartussen losstaande taken (5 seconden). Dit is de grootste tokenbesparing van allemaal. De forumconsensus schat dat dit 50–70% reductie oplevert alleen al door de sessiegeschiedenis te legen vóór je aan nieuw werk begint. Onthoud die Messages-bucket van 185k tokens uit de /context-dump?/clearwist die. -
/model haiku-4.5voor simpel werk (10 seconden). Tactisch wisselen van model levert 60–80% kostenreductie op bij routineklussen. Haiku verwerkt de meeste eenvoudige codingtaken, bestandsopzoekingen en commit messages prima. -
Maak
.clawruleskleiner dan 200 regels + voeg.clawignoretoe (90 seconden). Je regelsbestand wordt bij elk bericht opnieuw geladen. Bij 200 regels is dat ~1.500–2.000 tokens per turn; bij 1.000 regels belast je elk verzoek permanent met 8.000–10.000 tokens. In combinatie met een.clawignoredienode_modules/,dist/, lockfiles en gegenereerde code uitsluit, claimt één ontwikkelaar 92% tokenreductie door alleen deze discipline.
Stap voor stap: drie kant-en-klare configuraties om OpenClaw-tokenverbruik drastisch terug te brengen

Hieronder volgen drie complete, geannoteerde openclaw.json-configuraties — van "gewoon beginnen" tot "volledige optimalisatiestack". Elke config bevat inline opmerkingen en schattingen van de maandkosten.
Voordat je begint:
- Moeilijkheid: Beginner (Config A) → Intermediate (Config B) → Gevorderd (Config C)
- Benodigde tijd: ~5 minuten voor Config A, ~15 minuten voor Config C
- Wat je nodig hebt: OpenClaw geïnstalleerd, een teksteditor, toegang tot
~/.openclaw/openclaw.json
Config A: Beginner — gewoon geld besparen
Vijf regels. Geen complexiteit. Vervangt het standaardmodel van Opus naar Sonnet, schakelt memory-overhead uit en isoleert heartbeats naar Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // was Opus — direct 3-5x goedkoper
"heartbeat": {
"every": "55m", // afstemmen op 1u cache-TTL voor maximale cache-hits
"model": "anthropic/claude-haiku-4-5", // Haiku voor pings, niet Opus
"isolatedSession": true // ~100k → 2-5k tokens per run
}
}
},
"memory": { "enabled": false } // bespaart ~500-2k tokens/sessie
}
Wat je na het toepassen zou moeten zien: Run /status vóór en na. Je kosten per request zouden duidelijk moeten dalen, en heartbeat-items in je OpenRouter Activity-pagina zouden Haiku in plaats van Opus moeten tonen.
| Gebruiksniveau | Standaard (Opus) | Config A (Sonnet + Haiku heartbeats) | Besparing |
|---|---|---|---|
| Licht (~10 q/dag) | ~$100 | ~$35 | 65% |
| Gemiddeld (~50 q/dag) | ~$500 | ~$250 | 50% |
| Intensief (~200 q/dag) | ~$1.750 | ~$900 | 49% |
Config B: Intermediate — slimme driedelige routing
Sonnet als primaire keuze voor echt werk. Haiku voor sub-agents en compaction. Gemini Flash-Lite als budgetfallback wanneer Claude wordt afgeremd. Fallback-ketens vangen providerstoringen automatisch op.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // als Sonnet wordt afgeknepen
"google/gemini-2.5-flash-lite" // ultragoedkope laatste redmiddel
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 min < 1u cache-TTL = cache-hit
"model": "google/gemini-2.5-flash-lite", // centen per ping
"isolatedSession": true,
"lightContext": true // minimale context in heartbeat-calls
},
"subagents": {
"maxConcurrent": 4, // omlaag vanaf standaard 8
"model": "anthropic/claude-haiku-4-5" // sub-agents hebben geen Sonnet nodig
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // compaction-samenvattingen via Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Verwacht resultaat: Sub-agentvermeldingen in je logs zouden nu Haiku-prijzen moeten tonen. Heartbeats zouden bijna niets meer kosten. Je fallback-keten zorgt ervoor dat een Claude-storing je sessie niet stillegt — je valt dan netjes terug op Gemini.
| Gebruiksniveau | Standaard | Config B | Besparing |
|---|---|---|---|
| Licht | ~$100 | ~$20 | 80% |
| Gemiddeld | ~$500 | ~$150 | 70% |
| Intensief | ~$1.750 | ~$500 | 71% |
Config C: Power user — volledige optimalisatiestack
Per-sub-agent modeltoewijzing, contextcompaction vastgezet op Haiku, vision-routing naar Gemini Flash, strakke .clawrules + .clawignore, ongebruikte skills uitgeschakeld. Dit is de configuratie waarmee je in de 85–90% besparingsrange uitkomt.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // andere provider als backup
"minimax/minimax-m2-7", // goedkope dagelijkse fallback
"anthropic/claude-haiku-4-5" // laatste redmiddel
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // 's nachts geen heartbeats
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // omlaag vanaf standaard 20000
"imageModel": "google/gemini-3-flash" // vision-taken via goedkoop model
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // minimale memory
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Voorbeeld van per-subagent override — plak dit in ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Draait lint-/formatchecks en past triviale fixes toe
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
Minimaal bruikbare .clawignore — dit alleen al verkleint typische bootstraps van 150k tekens naar ongeveer 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Gebruiksniveau | Standaard | Config C | Besparing |
|---|---|---|---|
| Licht | ~$100 | ~$12 | 88% |
| Gemiddeld | ~$500 | ~$90 | 82% |
| Intensief | ~$1.750 | ~$220 | 87% |
Deze cijfers sluiten aan op twee onafhankelijke rapporten van echte gebruikers: Praney Behl’s gedocumenteerde $600–750/maand → $3–4/dag (90% reductie), en de LaoZhang-case studies met $943 → $347 (63%), $1.750 → $1.000 (64%), $200 → $70 (65%) na gedeeltelijke optimalisatie.
De /model-opdracht gebruiken om OpenClaw-tokenverbruik live te sturen
Het /model-commando wisselt het actieve model voor de volgende beurt terwijl je de volledige conversatiecontext behoudt — geen reset, geen verloren geschiedenis. Dit is de dagelijkse gewoonte die besparingen opbouwt.
Praktische workflow:
- Werk je aan een lastige refactor over meerdere bestanden? Blijf op Sonnet.
- Snelle vraag als "wat doet deze regex?"?
/model haiku, stel je vraag, daarna/model sonnetom terug te schakelen. - Commit message of documentatie bijschaven?
/model flash-lite, klaar.
Je kunt aliases instellen in openclaw.json onder commands.aliases om korte namen (haiku, sonnet, opus, flash) te koppelen aan volledige providerstrings. Scheelt telkens een paar toetsaanslagen.
De rekensom: 50 queries/dag op Sonnet is grofweg $3/dag. Diezelfde 50 queries verdeeld als 70/20/10 over Haiku/Sonnet/Opus komen uit op ongeveer $1,10/dag. Over een maand is dat $90 → $33 — 63% goedkoper zonder je tools te veranderen, alleen je gewoontes.
Bonus: OpenClaw-modelprijzen per provider volgen met Thunderbit
Volg modelprijzen per provider met AI Get Started Free
Met zoveel modellen en providers — OpenRouter, directe Anthropic API, Google AI Studio, DeepSeek, MiniMax — veranderen prijzen voortdurend. Anthropic verlaagde de Opus-outputprijs van de ene op de andere dag met ongeveer 67%. Google snoeide in december 2025 de gratis Gemini-limieten met 50–80%. Een statische prijsspreadsheet handmatig actueel houden is een verloren strijd.
Thunderbit lost dit op zonder scrapingcode. Het is een AI-webscraper Chrome-extensie die precies voor dit soort gestructureerde data-extractie is gebouwd.
De workflow die ik gebruik:
- Open de OpenRouter-modelpagina in Chrome en klik op Thunderbit’s "AI Suggest Fields". De pagina wordt gelezen en Thunderbit stelt kolommen voor — modelnaam, inputprijs, outputprijs, context window, provider.
- Klik op Scrape, en exporteer direct naar Google Sheets.
- Stel een geplande scrape in in gewoon Engels — "elke maandag om 9:00 uur de OpenRouter-modellenlijst opnieuw scrapen" — en het draait automatisch in de cloud.
Vanaf dat moment werkt je persoonlijke prijstracker zichzelf bij. Elk model dat plots 30% goedkoper wordt — of een provider die ineens een Exacto-tag krijgt — verschijnt op maandagochtend vanzelf in je spreadsheet, zonder dat jij iets hoeft te doen. We hebben meer geschreven over AI-data-extractie voor zakelijke toepassingen op onze blog.
Prijzen vergelijken op directe providerpagina’s (Anthropic, Google, DeepSeek)? Thunderbit’s subpage scraping volgt elke modellink naar de detailpagina en haalt de tarieven per provider op — handig als je wilt weten of Kimi K2.5 via OpenRouter goedkoper is dan direct via NVIDIA Build. Bekijk Thunderbit-prijzen voor de free tier en abonnementsdetails.
Belangrijkste lessen voor het verlagen van OpenClaw-tokenverbruik
Het framework: Begrijpen → Monitoren → Routeren → Optimaliseren.
Acties met de grootste impact, gerangschikt:
- Maak Opus niet je standaard. Zet je primaire model op Sonnet of MiniMax M2.7. Alleen dit al geeft een kostenreductie van 3–5x.
- Isoleer heartbeats. Zet
isolatedSession: trueen routeer heartbeats naar Gemini Flash-Lite. Daarmee verlaag je een lek van ~100k tokens naar ~2–5k. - Routeer sub-agents naar Haiku. Elke spawn laadt ongeveer 20k tokens aan context voordat er überhaupt werk wordt gedaan. Laat dat niet op Opus gebeuren.
- Gebruik consequent
/clear. Gratis, kost 5 seconden, en volgens de community levert dit meer op dan welke andere losse maatregel ook. - Voeg
.clawignoretoe. Doornode_modules, lockfiles en build-artifacts uit te sluiten, verklein je de bootstrap-context enorm. - Monitor met
/context detailvóór en na wijzigingen. Als je het niet kunt meten, kun je het niet verbeteren.
Het goedkoopste model hangt af van de taak. Gemini Flash-Lite voor heartbeats. MiniMax M2.7 voor dagelijks coderen. Haiku voor betrouwbare tool-calls. Sonnet voor complexe meerstaps taken. Opus alleen voor echt lastige problemen — en verder niet.
De meeste lezers kunnen in één middag al 50–70% besparen met Config A of B. De volledige 85–90% vraagt om een stapeling van alles hierboven — modelrouting, het dichten van verborgen lekken, .clawignore, sessiediscipline — maar het is haalbaar en het blijft werken.
FAQ’s
1. Hoeveel kost OpenClaw per maand?
Dat hangt volledig af van je configuratie, gebruiksvolume en modelkeuzes. Lichtgebruikers (~10 queries/dag) besteden met optimalisatie meestal $5–30/maand, of $100+ met de standaardinstellingen. Gemiddelde gebruikers (~50 queries/dag) zitten tussen $90–400/maand. Intensieve gebruikers kunnen op de standaardconfiguratie uitkomen op $600–2.000+/maand — een extreem geval dat gedocumenteerd werd, was $5.623 in één maand. Anthropic’s eigen interne telemetrie wijst op een mediaan van $13/ontwikkelaar/actieve-dag.
2. Wat is het goedkoopste OpenClaw-model dat nog goed werkt voor coderen?
MiniMax M2.5/M2.7 is de beste algemene dagelijkse keuze — goede betrouwbaarheid bij tool-calls, SWE-Pro 56,22, voor ongeveer $0,28/$1,10 per miljoen tokens. Voor heartbeats en simpele lookups is Gemini 2.5 Flash-Lite met $0,10/$0,40 moeilijk te verslaan. Claude Haiku 4.5 met $1/$5 is de betrouwbare middenklasse fallback wanneer je uitstekende tool-calling nodig hebt zonder Sonnet-prijzen te betalen.
3. Kan ik free-tier modellen gebruiken met OpenClaw?
Technisch gezien wel. GPT-OSS-120B is gratis via OpenRouter’s :free-tag en NVIDIA Build. Gemini Flash-Lite heeft een gratis tier (15 RPM, 1.000 requests/dag). DeepSeek geeft 5 miljoen gratis tokens bij aanmelding. Maar free tiers hebben stevige rate limits, lagere snelheid en vaak onbetrouwbare beschikbaarheid. Goedkope betaalde modellen — centen per miljoen tokens — zijn veel betrouwbaarder voor regulier gebruik.
4. Verlies ik context als ik midden in een gesprek wissel van model met /model?
Nee. /model behoudt je volledige sessiecontext — de volgende beurt gaat naar het nieuwe model met de complete geschiedenis intact. Dit is bevestigd in de conceptdocumentatie van OpenClaw en werkt op dezelfde manier in Claude Code. Je kunt dus probleemloos heen en weer schakelen tussen Haiku voor snelle vragen en Sonnet voor complex werk zonder iets kwijt te raken.
5. Wat is vandaag de snelste manier om mijn OpenClaw-rekening te verlagen?
Typ /clear tussen losstaande taken. Het is gratis, kost vijf seconden en wist de gespreksgeschiedenis die bij elke API-call opnieuw wordt meegestuurd. Eén echte sessie liet 185.000 tokens aan opgehoopte berichtgeschiedenis zien — alles daarvan werd bij elke beurt opnieuw verzonden en opnieuw afgerekend. Dat opschonen vóór je aan nieuw werk begint is de hoogste-ROI gewoonte die je kunt ontwikkelen.
Probeer Thunderbit voor AI-webscraping Get Started Free




