

Apollo list queries optimaliseren is niet alleen een technische oefening — het is eigenlijk een overlevingsskill voor iedereen die afhankelijk is van realtime nieuwsdata, geautomatiseerde nieuwsverwerking of snelle sales- en operations-workflows. Ik heb uit de eerste hand gezien hoe een trage list query een strak dashboard kan veranderen in een bottleneck, waardoor salesteams naar laadwieltjes blijven kijken en operations-mensen noodoplossingen in spreadsheets moeten bedenken. In een wereld waarin 60% van de tijd van salesmedewerkers al opgaat aan taken die niet aan verkopen bijdragen, telt echt elke milliseconde.
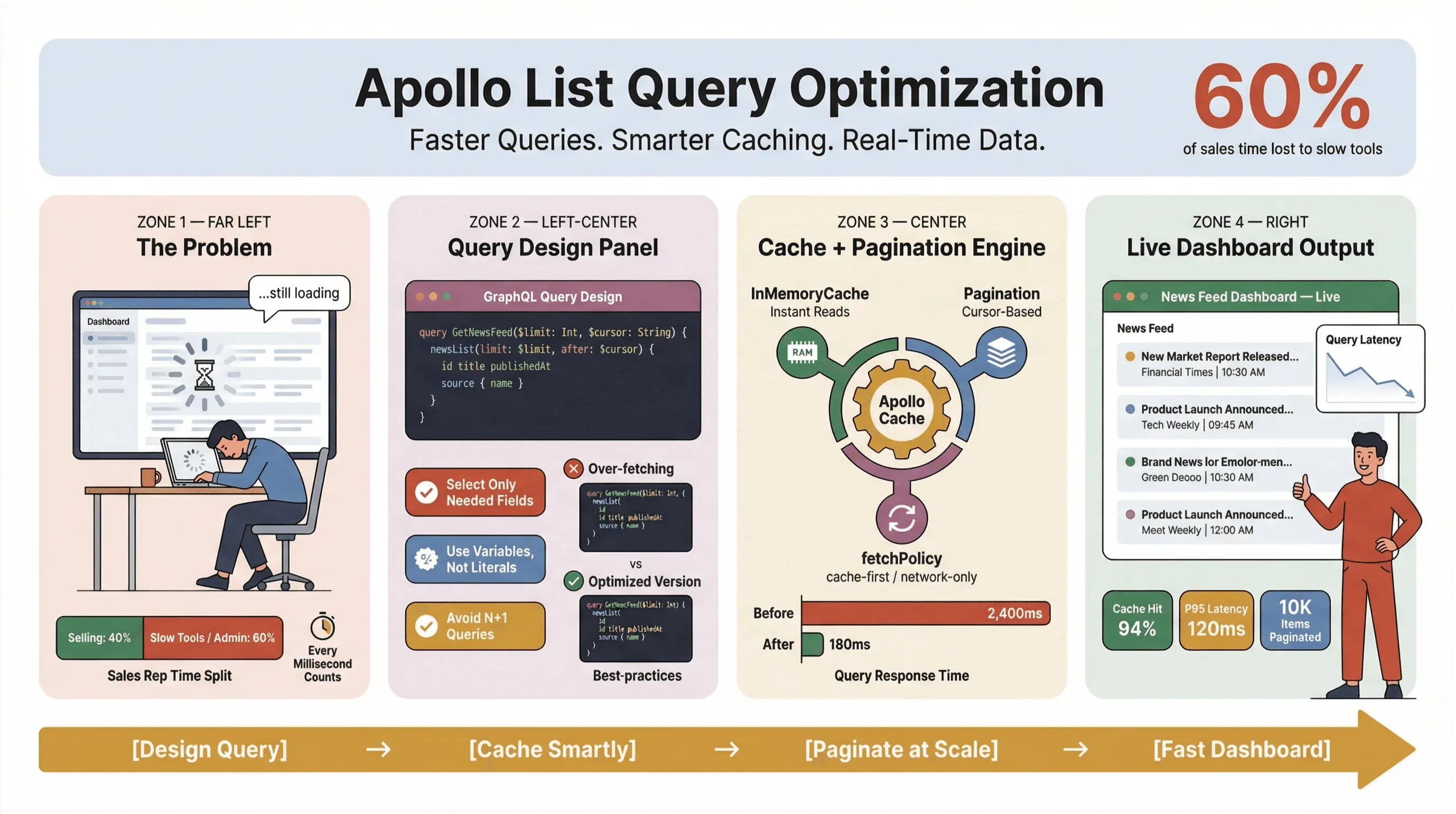
Dus hoe zorg je ervoor dat Apollo Client list queries snel, betrouwbaar en consistent blijven op schaal — zeker als je nieuws scrapt, leads opvolgt of dashboards aanstuurt die bedrijfskritisch zijn? In deze gids laat ik de aanpak zien die in productie overeind blijft: querydesign, caching, paginering en het koppelen van no-code tools zoals Thunderbit om het zware werk van nieuwsverwerking te automatiseren.
--- Of je nu developer bent, productmanager of gewoon degene op wie iedereen wijst als het dashboard traag is: dit is jouw playbook voor Apollo GraphQL list performance.
Probeer Thunderbit voor geautomatiseerde nieuwsverwerking
Waarom Apollo list queries optimaliseren? (apollo client list performance, optimize apollo list queries)
Laten we eerlijk zijn: niemand wil wachten tot nieuwsberichten of salesleads eindelijk geladen zijn. In zakelijke omgevingen — vooral als ze draaien op geautomatiseerde nieuwsverwerking of realtime data — zijn trage Apollo list queries niet alleen irritant voor gebruikers; ze kosten geld, vertragen beslissingen en duwen mensen terug richting handmatig werk. Doorlopende onderzoeken van het Slack Workforce Lab laten zien dat kantoorwerkers ongeveer een derde — en in recentere rapporten zelfs bijna 40% — van hun dag kwijt zijn aan repetitieve taken met weinig waarde, vaak omdat tools het werk verspreiden over trage schermen.
Dit gebeurt er als list queries niet geoptimaliseerd zijn:
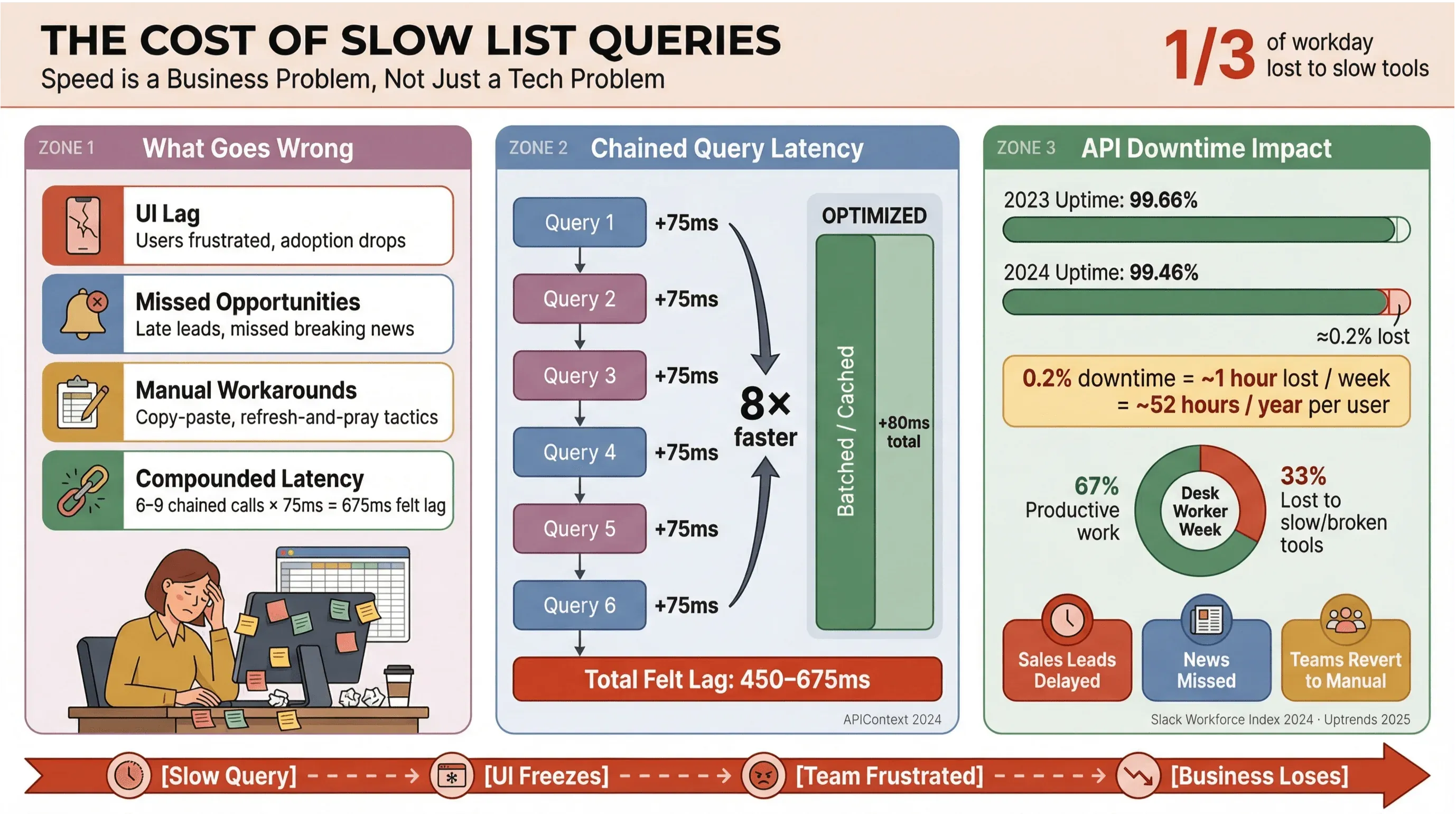
- Trage UI: Gebruikers merken vertraging op, wat leidt tot frustratie en minder adoptie.
- Gemiste kansen: In sales of nieuwsmonitoring kan zelfs een paar seconden vertraging betekenen dat je een warme lead of breaking news mist.
- Handmatige omwegen: Teams vallen terug op kopiëren/plakken, spreadsheets of “verversen en hopen”.
- Opgetelde vertraging: Elke trage API-call telt op — als je workflow 6 tot 9 afhankelijke queries triggert, kan een bescheiden 75 ms vertraging per call uitmonden in een voelbare lag van 450–675 ms (APIContext).
En het gaat niet alleen om snelheid. API-downtime neemt toe, waarbij de gemiddelde uptime in één jaar daalde van 99,66% naar 99,46% — goed voor bijna een uur productiviteitsverlies per week voor apps met veel lijsten. Als je bedrijf draait op realtime nieuwsdata, is dat een risico dat je niet zomaar kunt negeren.
De juiste datastructuur en velden kiezen (apollo graphql list best practices)
Een van de meest gemaakte fouten die ik zie (en ja, die heb ik zelf ook gemaakt) is elke list query behandelen alsof het een detailquery is. In GraphQL kun je precies ophalen wat je nodig hebt — dus gebruik dat voordeel. Te veel data ophalen is de vijand van performance, zeker in nieuws-scrapingtools en realtime dashboards.
Velden afstemmen op geautomatiseerde nieuwsverwerking
Stel dat je een nieuwsfeed bouwt. Heb je in je list query echt de volledige artikeltekst, alle tags, reacties en auteurbio’s nodig? Waarschijnlijk niet. Dit is het verschil:
Efficiënte list query:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Inefficiënte list query (niet doen):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
De eerste query is compact en efficiënt — perfect voor rangschikken, filteren en rijen renderen. De tweede? Dat is in vermomming een detailquery, die enorme payloads ophaalt en alles vertraagt (GraphQL spec, Apollo best practices).
Pro tip: gebruik een tweelaagse aanpak: haal in je lijst alleen lichte velden op en laad zware details (zoals volledige tekst of NLP-verrijking) pas wanneer de gebruiker een item opent of erover hovert.
Apollo Client cache inzetten voor snellere queries (apollo client list performance)
De cache van Apollo Client is de grootste hefboom voor list-query performance. Goed ingesteld kun je ermee:
- Herhaalde queries direct serveren (geen netwerkroundtrip)
- Serverbelasting en API-kosten verlagen
- Soepel heen-en-terug navigeren en filters wijzigen mogelijk maken
Maar caching is geen magie — het vraagt om een beetje configuratie en discipline.
Effectieve cache policies instellen
Apollo ondersteunt verschillende fetch policies:
| Policy | Wat het doet | Beste toepassing voor nieuwslijsten |
|---|---|---|
| cache-first | Leest uit de cache en haalt uit netwerk als iets ontbreekt | Lijsten opnieuw openen, filters wisselen, heen-en-terug navigatie |
| network-only | Haalt altijd uit het netwerk | Handmatig verversen, “laatste headlines” |
| cache-and-network | Geeft eerst cache terug en ververst daarna via netwerk | Snelle eerste weergave + achtergrondupdate (ideaal voor nieuwsfeeds) |
| no-cache | Haalt altijd op en slaat nooit op in cache | Eenmalige gevoelige queries (zeldzaam voor lijsten) |
Voor realtime nieuwsdata werk ik graag met cache-and-network — gebruikers zien meteen resultaat en krijgen daarna de update op de achtergrond. Let wel op UI-flikkering als je data bij verversen in een andere volgorde terugkomt (GitHub issue).
Tips voor cacheconfiguratie:
- Gebruik stabiele ID’s (
idof_id) voor normalisatie (Apollo cache docs). - Stem cachegrootte en garbage collection af op grote lijsten (memory management).
- Sla geen enorme, niet-genormaliseerde blobs op onder
ROOT_QUERY— dat kan je app vertragen (community report).
Paginering implementeren en aantallen beperken (apollo graphql list best practices)
Als je in één keer honderden of duizenden nieuwsartikelen of salesleads laadt, vraag je om problemen. Paginering is niet alleen een UX-feature — het is een noodzaak voor performance.
Apollo ondersteunt zowel offset-based als cursor-based paginering. Zo verhouden ze zich tot elkaar:
| Type paginering | Voordelen | Nadelen | Het meest geschikt voor |
|---|---|---|---|
| Offset-based | Simpel en makkelijk te implementeren | Kan items overslaan of dubbel tonen als data verschuift | Onveranderlijke of kleine lijsten |
| Cursor-based | Stabiel en goed bestand tegen dataveranderingen | Iets complexer | Nieuwsfeeds, grote lijsten |
Voor de meeste realtime nieuws- of leadlijsten is cursor-based paginering de juiste keuze. Je data blijft consistent, ook als er nieuwe items bijkomen of oude verdwijnen (GraphQL Foundation).
Apollo-pagineringstips:
- Stel
keyArgsin om cachekeys voor gepagineerde velden te sturen (docs). - Implementeer een
merge-functie om pagina’s in de cache samen te voegen. - Gebruik
fetchMoreom extra pagina’s te laden zonder eerdere resultaten te overschrijven.
Praktische pagineringspatronen voor nieuws-scrapingtools
Een typische UI voor nieuwsverwerking doet het volgende:
- Toont de nieuwste 20–50 headlines (alleen compacte velden)
- Laadt meer bij scrollen of via een “volgende pagina”-klik
- Haalt details pas op wanneer nodig
Zo blijft je UI snel, je API tevreden en je gebruikers productief.
Thunderbit koppelen voor geautomatiseerde nieuwsverwerking
Nu het belangrijkste punt: waar komt al die gestructureerde nieuwsdata eigenlijk vandaan? Daar komt Thunderbit om de hoek kijken.
Download de Thunderbit Chrome-extensie Get Started Free
Thunderbit is een no-code AI-webscraper als Chrome-extensie die nieuws-headlines, URL’s, bronnen, auteurs, publicatiedata, samenvattingen en afbeeldingen kan extraheren van vrijwel elke website — zonder code. Ik heb teams Thunderbit zien gebruiken om het volledige nieuwsverwerkingsproces te automatiseren en ongestructureerde webpagina’s om te zetten in schone, gestructureerde data die direct in een database of GraphQL API kan worden geladen.
Thunderbit combineren met Apollo voor realtime nieuwsdata
Dit is een workflow die ik erg sterk vind voor sales- en operations-teams die actuele nieuwsdata nodig hebben:
- Extractielaag: gebruik Thunderbit’s News Scraper template om op schema gestructureerde nieuwsdata van doelwebsites te halen.
- Opslaglaag: sla de gescrapete data op in een database die geoptimaliseerd is voor snelle opvraging.
- GraphQL-laag: expose via je API een
newsFeed-lijstveld en eennewsArticle(id)detailveld. - Clientlaag: gebruik Apollo Client om de lijst op te halen (lichte velden, gepagineerd) en details alleen op te vragen wanneer nodig.
Deze pipeline “scrape → store → query” zorgt ervoor dat je Apollo queries altijd werken met verse, gestructureerde data — zonder handmatig kopiëren/plakken of breekbare scripts.
Bonus: Thunderbit kan je lijsten ook verrijken met extra velden (zoals sentiment of categorie) via AI-gestuurde veldsuggesties, waardoor je nieuwsfeed nog slimmer wordt.
Stapsgewijze gids: Apollo list queries optimaliseren
Klaar om dit toe te passen? Dit is mijn vaste checklist voor optimalisatie van Apollo list queries:
-
Maak je queries compacter
- Vraag alleen velden op die nodig zijn om de lijst te renderen (titel, URL, timestamp, enz.).
- Verplaats zware velden (volledige tekst, afbeeldingen, verrijking) naar detailqueries.
-
Implementeer paginering
- Gebruik cursor-based paginering voor grote of dynamische lijsten.
- Stel
keyArgsenmerge-functies in voor correcte cachewerking.
-
Gebruik Apollo Cache slim
- Normaliseer entiteiten met stabiele ID’s.
- Kies de juiste fetch policy (
cache-and-networkis ideaal voor nieuws). - Stem cachegrootte en garbage collection af op je datavolume.
-
Integreer geautomatiseerde extractie
- Gebruik Thunderbit om nieuwsverwerking te automatiseren en je data actueel te houden.
- Exporteer gestructureerde data direct naar je database of spreadsheet.
-
Monitor en los problemen op
- Gebruik Apollo Client Devtools om queries, cache en performance te inspecteren.
- Let op grote cachewrites, te veel actieve watchers en haperende UI.
- Volg p95/p99-latency en foutpercentages (New Relic, Uptrends).
Query performance monitoren en troubleshooten
Apollo’s Devtools zijn hier echt een lifesaver. Je kunt ermee:
- Actieve queries en cachestatus inspecteren
- Dubbele queries of te veel watchers opsporen
- Grote cacheblobs of normalisatieproblemen identificeren
Zie je UI-lag of trage updates, check dan op:
- Te grote list queries (maak ze compacter)
- Slechte cache-normalisatie (fix je ID’s)
- Problemen met het samenvoegen van pagina’s (controleer je
keyArgsenmerge)
En vergeet niet tail latency te meten — niet alleen gemiddelden. Dáár zit vaak de echte frustratie voor gebruikers.
Traditionele versus AI-gedreven benaderingen voor nieuws-scraping
Eerlijk is eerlijk: vroeger betekende nieuws scrapen dat je custom scripts schreef, headless browsers moest temmen en maar moest hopen dat de lay-out van de site vannacht niet veranderde. Nu kun je met AI-gedreven tools zoals Thunderbit het hele proces automatiseren — geen code, geen gedoe.
| Aanpak | Sterktes | Beperkingen voor zakelijke gebruikers |
|---|---|---|
| Gescript scrapen | Volledig aanpasbaar, goedkoop op schaal | Veel onderhoud, engineeringtijd nodig |
| Beheerde scrapingplatforms | Snel op te starten, anti-botafhandeling wordt uit handen genomen | Nog steeds configuratie nodig, kosten groeien mee met gebruik |
| AI-gedreven extractie (Thunderbit) | Kan rommelige layouts aan, geen code nodig | Output moet worden gecontroleerd, integratie met je schema nodig |
| No-code visuele scrapers | Toegankelijk voor niet-technische gebruikers | Kan breken bij UI-wijzigingen, beperkte schaal |
| Proxy/unlocker-infrastructuur | Omzeilt blokkades, ondersteunt hoge throughput | Nog steeds extractielogica nodig, compliancerisico’s |
Juridische noot: openbaar beschikbare data scrapen is doorgaans legaal, maar respecteer altijd de gebruiksvoorwaarden en rate limits (Reuters).
Belangrijkste lessen voor Apollo GraphQL list best practices
Nog even de essentie op een rij:
- Optimaliseer op snelheid en helderheid: maak list queries compacter, gebruik paginering en cache agressief.
- Structuur is alles: haal alleen op wat je nodig hebt — zet zware velden in detailqueries.
- Cache is je vriend: gebruik Apollo’s normalisatie en fetch policies om data direct te serveren.
- Automatiseer extractie: tools zoals Thunderbit maken nieuwsverwerking en lijstverrijking toegankelijk voor iedereen.
- Monitor en verbeter: gebruik Devtools en observability-dashboards om knelpunten vroeg te signaleren.
Voor sales-, operations- en nieuwsteams betekent dit minder tijd wachten, meer tijd handelen — en een stuk minder Slack-berichten met “waarom is dit zo traag?”.
Conclusie: volgende stappen voor het optimaliseren van je Apollo list queries
Als je nog steeds zware, niet-gepagineerde of cache-onvriendelijke list queries draait, is dit het moment om te auditen en te upgraden. Begin klein: beperk je velden, voeg paginering toe en stem je cache af. Ga daarna een stap verder door tools voor geautomatiseerde extractie te integreren, zoals Thunderbit, zodat je data actueel en direct bruikbaar blijft.
Wil je dieper gaan? Bekijk de Apollo docs, de Thunderbit Blog of sluit je aan bij de Apollo Community voor praktijkervaring en troubleshooting. En als je klaar bent om je nieuwsverwerking te automatiseren, probeer dan zeker Thunderbit’s News Scraper template — een gamechanger voor iedereen die realtime data nodig heeft zonder gedoe.
Gebruik de Thunderbit News Scraper-template
Als je na het lezen maar één ding doet: beperk de veldselectie van je list query, voeg cursor-based paginering toe en kies een verstandige fetch policy. Alleen al die drie aanpassingen brengen een list query meestal van merkbare vertraging naar bijna onmerkbaar — en geven je de ruimte om je te richten op de data, niet op de laadstatus.
FAQs
1. Waarom worden Apollo list queries traag in realtime nieuws- of salesdashboards?
List queries kunnen traag worden als ze te veel data ophalen, geen paginering hebben of niet goed gecachet zijn. In workflows met hoge frequentie, zoals nieuwsmonitoring, stapelen zelfs kleine vertragingen zich op en leiden ze tot UI-lag en productiviteitsverlies.
2. Wat is de beste manier om Apollo list queries op te zetten voor geautomatiseerde nieuwsverwerking?
Vraag alleen de velden op die nodig zijn om je lijst te renderen, bijvoorbeeld titel, URL en timestamp. Zet zware velden zoals volledige artikels of afbeeldingen in detailqueries en gebruik paginering om payloads klein en snel te houden.
3. Hoe verbetert de cache van Apollo Client de performance van lijsten?
De cache van Apollo slaat eerder opgehaalde data op, waardoor herhaalde queries direct kunnen worden beantwoord. Goede cache-normalisatie en fetch policies zoals cache-and-network kunnen list views aanzienlijk versnellen en de serverbelasting verlagen.
4. Hoe kan Thunderbit helpen bij nieuwsverwerking en Apollo-integratie?
Thunderbit is een no-code AI-webscraper die gestructureerde nieuwsdata uit vrijwel elke website haalt. Je kunt het gebruiken om nieuwsverwerking te automatiseren en die data vervolgens in je database of GraphQL API te laden voor gebruik met Apollo Client.
5. Welke tools kan ik gebruiken om Apollo list-query performance te monitoren en troubleshooten?
Met de Apollo Client Devtools kun je queries, cachestatus en performance in realtime inspecteren. Combineer dat met observability-dashboards zoals New Relic of Uptrends om latency en foutpercentages te volgen en je querydesign stap voor stap te verbeteren.
Wil je meer tips over webscraping, automatisering en realtime dataworkflows? Bekijk dan de Thunderbit Blog voor verdiepende artikelen, tutorials en de nieuwste AI-gedreven productiviteitstips.
Probeer Thunderbit AI Web Scraper Get Started Free
Meer weten
- Hoe je Apollo-lijsten optimaliseert voor effectief leadbeheer
- Apollo Data Enrichment: functies, voordelen en AI-boost
- Hoe je Apollo prospecting onder de knie krijgt: een stapsgewijze gids
- Hoe je webscraper-paginering gebruikt voor efficiënte extractie
- Hoe je webscraper-paginering gebruikt voor efficiënte extractie




